Excel Python:飞速搞定数据分析与处理

第四部分 使用 xlwings 对 Excel 应用程序进行编程
第十一章 Python 包跟踪器
本章会构建一个典型的商业应用程序 ,它可以从互联网上下载数据并存储到数据库 中,然 后再将数据在 Excel 中进行可视化 。在此过程中你会认识到 xlwings 在这样的应用程序开发过程中扮演着怎样的角色,也能看到将 Python 连接至外部系统有多容易。在尝试构建一个十分接近真实情况且简单易懂的项目的过程中,我想到了 Python 包追踪器 。这个 Excel 工具可以显示某个 Python 包每年发布的次数。虽然这只是一个案例研究,但是实际上你可能会发现这个工具可以用来了解一个 Python 包是否处于积极开发的状态。
在对这个应用程序有了一个大致的了解后,为了能够理解它的代码,首先需要研究如下问题:如何才能从互联网上下载数据以及如何与数据库交互。然后再学习 Python 中的异常处理。当我们涉足应用程序开发时,异常处理是一个很重要的概念。学完这些基础知识之 后,我们会研究 Python 包追踪器的各个组件,了解它们是如何相互协作的。本章在最后会研究如何调试 xlwings 代码。和前两章一样,本章也需要在 Windows 或 macOS 中安装 Microsoft Excel。首先来试用一下 Python 包追踪器。
11.2 核心功能
本节会介绍 Python 包跟踪器的核心功能:如何通过 Web API 获取数据以及如何查询数据库。会向你展示如何处理异常,这是在编写应用程序代码时无法避免的话题。先从 Web API 开始。
11.2.1 Web API
Web API 是应用程序从互联网上获取数据的最受欢迎的方法之一:API 代表 application programming interface(应用程序编程接口 ),它定义了你如何通过编程与应用程序交互。 因此 Web API 指的就是通过网络(通常是互联网)访问的 API。要理解 Web API 的工作原理,需要先后退一步,(通过简单的语言)了解一下当你在浏览器中打开一个 Web 页面时发生了什么:在地址栏中输入 URL 后,浏览器会向服务器发送了一个 GET 请求,请求获 取你想要的 Web 页面。浏览器使用 HTTP 协议 与服务器通信,GET 请求 是 HTTP 协议的 一种方法。当服务器接收到请求时,它会传回所请求的 HTML 文档 进行响应,你的浏览器上会显示这个 HTML 文档中的内容:你的 Web 页面已成功加载。HTTP 协议还提供了一些其他的方法。除了 GET 请求,最常见的还有 POST 请求,我们用它来向服务器发送数据 (比如在 Web 页面上填写联系人表单)。
为了与人类用户交互,服务器会传回精美的 HTML 页面。这没有什么问题,但是应用程序并不关心页面的设计,它们只对数据感兴趣。因此,发送给 Web API 的 GET 请求和请求一个 Web 页面是类似的,但是通常你都会得到 JSON 格式的数据而不是 HTML 格式的 页面。JSON 代表 JavaScript Object Notation(JavaScript 对象记法 ),它是一种几乎可以被任何编程语言理解 的数据结构 。因此 JSON 是在不同系统之间交换数据的理想选择。虽然 JSON 使用的是 JavaScript 的语法,但是它和 Python 中的(嵌套)字典和列表非常接近。 两者的区别如下。
- JSON 只接受双引号字符串。
- JSON 使用 null,而 Python 使用 None。
- JSON 使用小写的 true 和 false,而 Python 使用的是首字母大写的版本。
- JSON 只接受字符串作为键,而 Python 的字典接受各种对象作为键。
标准库中的 json 模块可以将 Python 字典转换为 JSON 字符串,反之亦然:
In [1]: import json
In [2]: # Python字典......
user_dict = {"name": "Jane Doe",
"age": 23,
"married": False,
"children": None,
"hobbies": ["hiking", "reading"]}
In [3]: # ......通过json.dumps转换为JSON字符
# 串("dump string")。 indent参数是
# 可选的,它可以美化打印格式
user_json = json.dumps(user_dict, indent=4)
print(user_json)
{
"name": "Jane Doe",
"age": 23,
"married": false,
"children": null,
"hobbies": [
"hiking",
"reading"
]
}
In [4]: # 将JSON字符串转换为原生Python数据结构
json.loads(user_json)
Out[4]: {'name': 'Jane Doe',
'age': 23,
'married': False,
'children': None,
'hobbies': ['hiking', 'reading']}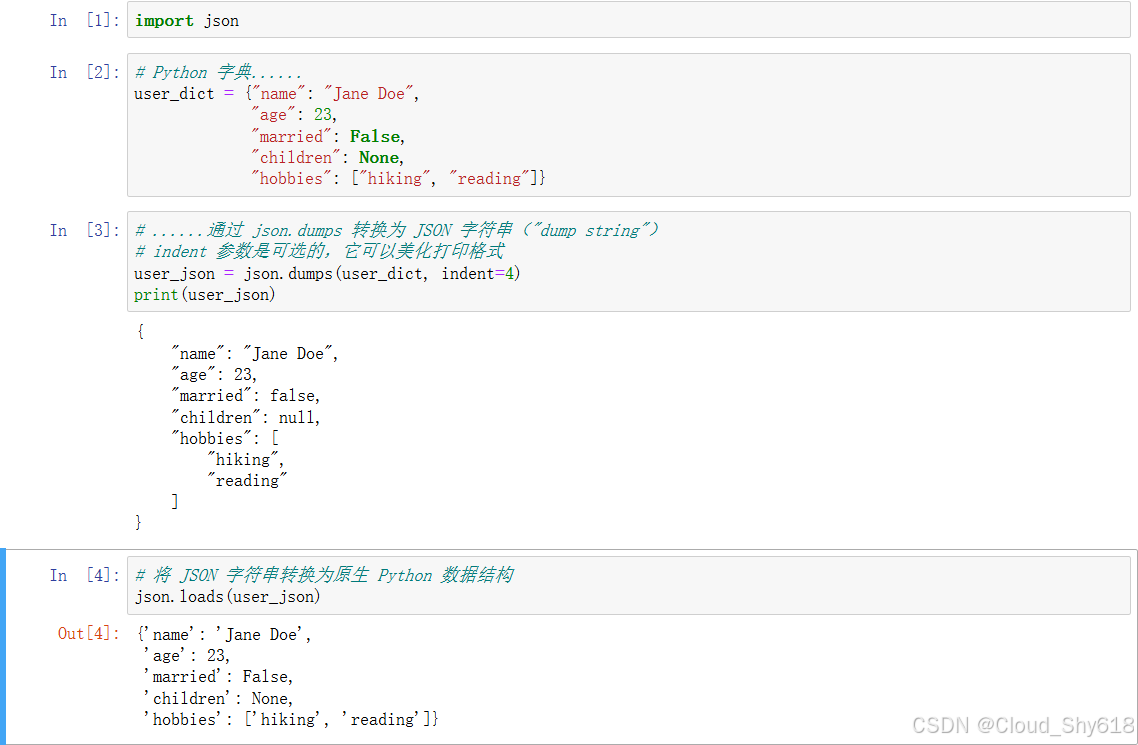
REST API : 除了 Web API,你还会经常看到 REST 或 RESTful API 这样的术语。REST 代表 representational state transfer(描述性状态迁移 ),它定义了一种遵循某些约束 的 Web API。REST 的要义是以无状态资源 的形式获取信息。无状态意味着每个发送给 REST API 的请求都完全独立于任何其他请求,并且每个请求必须始终提供所请求的完整信息集合。注意,REST API 这个术语常常被误用为指代任意的 Web API,哪怕它并不遵循 REST 的约束。
消费 Web API 通常都十分简单(马上就会看到如何在 Python 中消费),大多数服务会提供 Web API。
如果你想下载你收藏的 Spotify 播放列表,那么可以发起如下的 GET 请求(参见 Spotify Web API 参考文档):
GET https://api.spotify.com/v1/playlists/playlist_id不过要使用这些 API,你需要通过认证,一般来说你需要一个账户 以及一个与请求一起发出去的令牌(token)。对于 Python 包跟踪器来说,我们需要从 PyPI 上获取数据,进而获得指定包的发布信息。幸运的是,由于 PyPI 的 Web API 不需要任何认证,因此我们就少了一件需要担心的事。在 PyPI JSON API 文档中,你可以看到只存在两个端点(endpoint, 指追加到常用基础 URL 后面的 URL 片段):
GET /project_name/json
GET /project_name/version/json第二个端点返回了和第一个端点相同的信息,只不过是针对特定版本的。对于 Python 包跟踪器来说,我们使用第一个端点就可以获得关于包的发布情况的信息,接下来看看具体是如何工作的。在 Python 中,与 Web API 交互的最简单方法是使用 Anaconda 中预装的 Requests 包。执行如下命令从 PyPI 上获取有关 pandas 的数据:
In [5]: import requests
In [6]: response = requests.get("https://pypi.org/pypi/pandas/json")
response.status_code
Out[6]: 200每个响应都带有一个 HTTP 状态码,比如 200 表示 OK,而 404 表示 Not Found(未找到)。 你可以在 Mozilla 的 Web 文档中找到 HTTP 状态码的完整列表(链接:HTTP 响应状态码 - HTTP | MDN)。

你可能对 404 很熟悉,每当你点开一个死链或是输入了不存在的地址,浏览器就会显示 404。类似地,如果你在 GET 请求中包含了一个 PyPI 上没有的包名,则也会得到 404。要查看响应的内容,最简单的方法就是调用响应对象的 json 方法,这个方法会把响应的 JSON 字符串转换成 Python 字符串:
In [7]: response.json()响应非常长,为了让你理解其结构,这里只打印出很短的一部分:
Out[7]: {
'info': {
'bugtrack_url': None,
'license': 'BSD',
'maintainer': 'The PyData Development Team',
'maintainer_email': 'pydata@googlegroups.com',
'name': 'pandas'
},
'releases': {
'0.1': [
{
'filename': 'pandas-0.1.tar.gz',
'size': 238458,
'upload_time': '2009-12-25T23:58:31'
},
{
'filename': 'pandas-0.1.win32-py2.5.exe',
'size': 313639,
'upload_time': '2009-12-26T17:14:35'
}
]
}
} 要获得 Python 包跟踪器所需的所有发布信息及其日期列表,可以执行如下代码以遍历 releases 字典:
In [8]: releases = []
for version, files in response.json()['releases'].items():
releases.append(f"{version}: {files[0]['upload_time']}")
releases[:3] # 显示列表的前3个元素
Out[8]: ['0.1: 2009-12-25T23:58:31',
'0.10.0: 2012-12-17T16:52:06',
'0.10.1: 2013-01-22T05:22:09']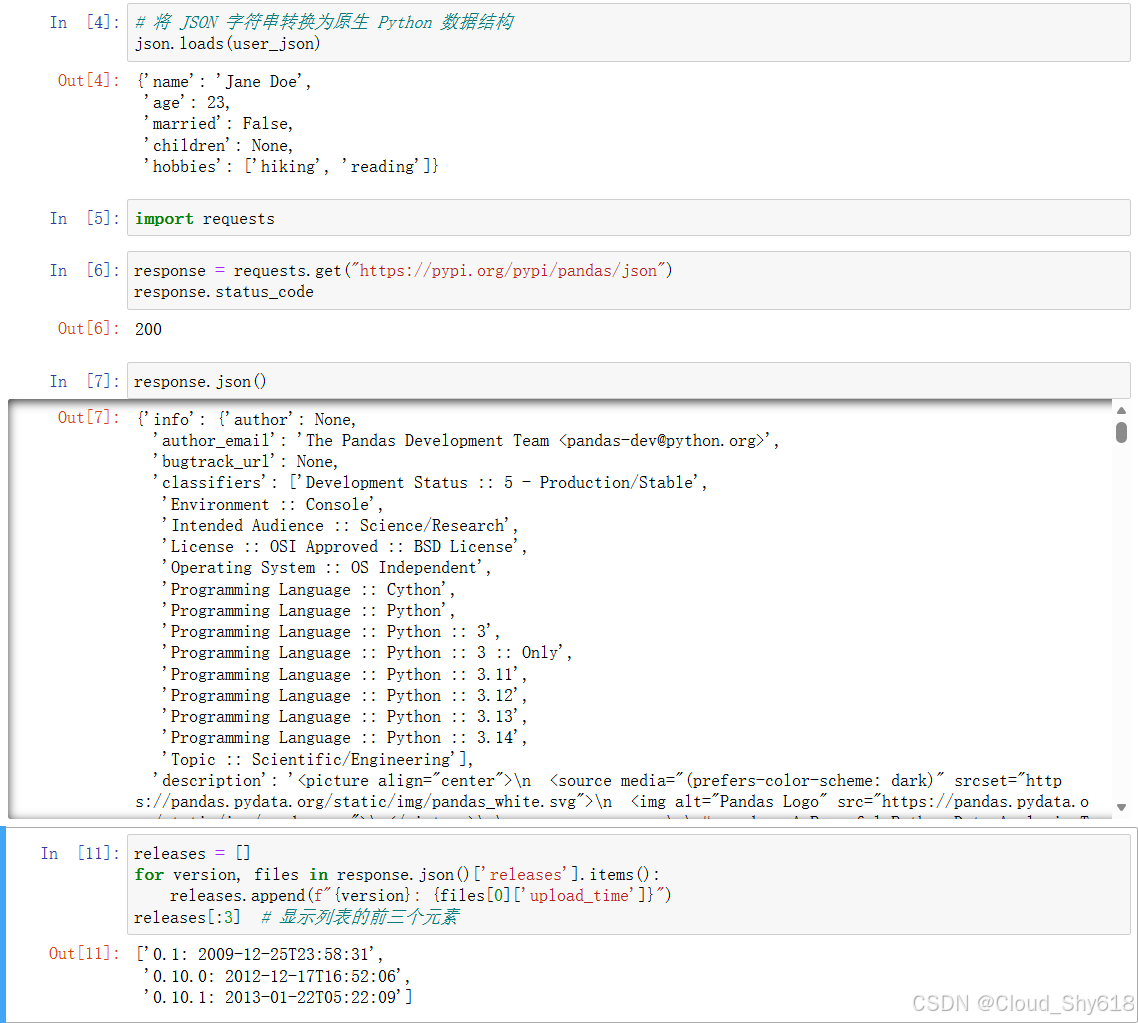
注意,这里任意挑选了列表中第一次出现的包的发布时间戳。特定的版本通常都有对应多个 Python 版本和操作系统的包。你可能还记得第 5 章中提到过,pandas 有一个可以从 JSON 字符串返回 DataFrame 的 read_json 方法。不过这个方法在这里帮不上忙,因为从 PyPI 上传回的响应的结构无法被直接转换为 DataFrame。
本节对 Web API 进行了简单的介绍,以便你理解它们在 Python 包跟踪器的代码库中所发挥的作用。现在来看看在我们的应用程序中如何与数据库以及其他会用到的外部系统进行通信。
11.2.2 数据库
为了在没有连接到互联网时也能使用来自 PyPI 的数据,你需要将下载的数据保存起来。虽然可以将 JSON 响应以文本文件形式保存到磁盘上,但还有一种更好的解决方案,那就是使用数据库。这样你就可以更加方便地查询数据了。Python 包跟踪器使用的是 SQLite ,这是一个关系数据库 (relational database)。关系数据库系统这个名字就来源于关系(relation),这里的关系指的是数据库表本身 (并非数据表之间的关系,这是一 种常见的错误认识):它们的最终目标是保持数据完整性 。为了实现这一目标,关系数据库将数据分割成不同的表 这是一个被称为规范化(normalization)的过程 并且应用约束以避免不一致和冗余的数据 。关系数据库使用 SQL(structured query language,结构化查询语言 )来执行数据库查询。最受欢迎的关系数据库系统有 SQL Server、Oracle、 PostgreSQL 和 MySQL。作为 Excel 用户,你可能还对基于文件的 Microsoft Access 数据库比较熟悉。
NoSQL 数据库(非关系型):如今 NoSQL 数据库已然成了关系数据库的强力竞争者。NoSQL 数据库会保存冗余数据以实现下述优势。
- **无数据表连接:**由于关系数据库将数据划分成了多张表,因此你常常需要通过连接操作来结合两张甚至更多张表的信息,有时候这样的操作会很慢。NoSQL 数据库不需要这样的操作,因此在执行某些类型的查询时可以获得更好的性能。
- 无数据库迁移: 在使用关系数据库时,每当需要修改表结构时(比如添加新列或者新表),你都必须进行数据库迁移(migration)。迁移指的是一种将数据库转化为所需结构的脚本。这让新版本的应用程序的部署过程变得更加复杂,甚至有可能造成停工。使用 NoSQL 数据库更容易避免这种问题。
- 伸缩性强: NoSQL 数据库更易于分布 到多台服务器上,因为其没有相互依赖的表。也就是说, 使用 NoSQL 数据库的应用程序可以在用户基数急剧增长时得到更强的伸缩性。
NoSQL 数据库有很多风格。一些数据库以键--值形式 存储数据,也就是说类似于 Python 字典(如 Redis);其他一些数据库可以保存(通常是 JSON 格式的)文档(如 MongoDB)。有些数据库设置可以将关系数据库与 NoSQL 数据库相结合:PostgreSQL 恰巧成了 Python 社区中最受欢迎的数据库,它在传统上是关系数据库,但是也允许将数据以 JSON 格式存储,兼具通过 SQL 执行查询的能力。
我们要使用的数据库是 SQLite。同 Microsoft Access 一样,SQLite 是基于文件的数据库。 与只能在 Windows 中工作的 Microsoft Access 相比,SQLite 可以在任何支持 Python 的平台 上工作。不过,SQLite 无法构建像 Microsoft Access 那样的用户界面,可以让 Excel 负责这 一部分。
在了解如何使用 Python 连接数据库并构建 SQL 查询之前,先来看一看包跟踪器的数据库的结构。然后作为本节的总结,我们会了解一下 SQL 注入,这是数据库驱动的应用程序的常见漏洞。
1、包跟踪器的数据库
Python 包跟踪器的数据库再简单不过了,因为它只有两张表 :packages 表保存的是包名 ,而 package_versions 表保存的是版本字符串和上传日期 。这两张表可以通过 package_ id 进行连接 :package_versions 表不会每行都保存 package_name,而是会将其规范化到 packages 表。这样可以避免数据冗余,比如,包名的修改只需要修改整个数据库中的一个字段就可以完成。为了更好地理解这个数据库在装入 xlwings 和 pandas 的数据后是什么样 子,来看一下表 11-1 和表 11-2。
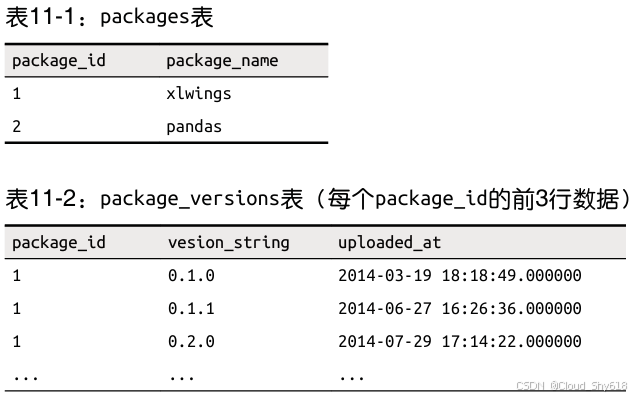

图 11-3 是从语义上展示两张表的数据库图。你可以读出表和列的名称,获得主键和外键的信息。
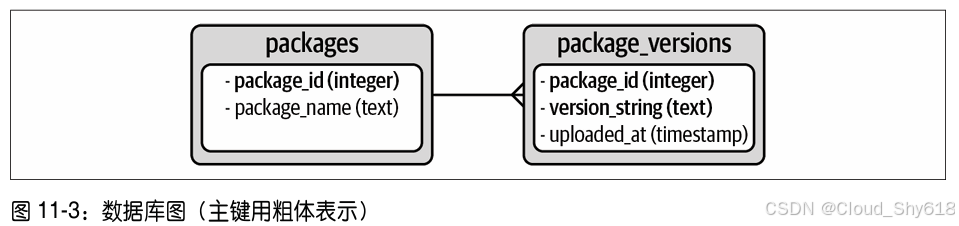
主键 : 关系数据库要求每张表必须有一个主键(primary key)。主键是可以唯一标识一行(行也被称作记录)的一列或多列。对于 packages 表来说,主键是 package_id;对于 package_ versions 表来说,主键是所谓的复合键(composite key), 即 package_id 和 version_string。
外键: package_versions 表中的 package_id 列对于 packages 表中的 package_id 列来说是一个外键(foreign key), 图 11-3 中是用连接两张表的线段表示的:外键是一种约束 ,对于我们来说,它能够确保package_versions 表中的每一个 package_id 在 packages 表中也存在,这可以保证数据完整性 。图 11-3 中直线右端的分叉显示出了关系的性质:一个 package 可以有多个 package_version,这就叫作一对多(one-to-many)关系。
要查看数据库表的内容以及执行 SQL 查询,可以安装一个叫作 SQLite 的 VS Code 扩展 (请参阅 SQLite 扩展的文档以了解更多细节),也可以使用专门的 SQLite 管理软件,这类软件非常多。不过,这里会使用 Python 来执行 SQL 查询。先来看看如何连接到数据库。
2、数据库连接
要在 Python 中连接数据库,你需要一个驱动(driver),也就是知道如何与你所使用的数据库进行通信的 Python 包。每种数据库都需要不同的驱动,而每种驱动又使用了不同的语法。不过幸运的是有一个很强大的名为 SQLAlchemy 的包可以解决这个问题。 SQLAlchemy 将不同数据库和驱动之间的大部分差异抽象了出来 ,很多时候我们将其用作对象关系映射程序(object relational mapper,ORM)。它会把数据库记录转化为 Python 对象。对于很多(虽然不是所有)开发者来说,ORM 使用起来更加自然。为了保持内容的简洁,我会忽略 ORM 的功能,只使用 SQLAlchemy 来简化 SQL 查询。在使用 pandas 以 DataFrame 的形式读写数据库时,实际上 SQLAlchemy 也在幕后工作。利用 pandas 执行数据库查询涉及 3 个层次的包------pandas、SQLAlchemy 和数据库驱动,如下图所示。在三层中的任意一层都可以执行数据库查询。
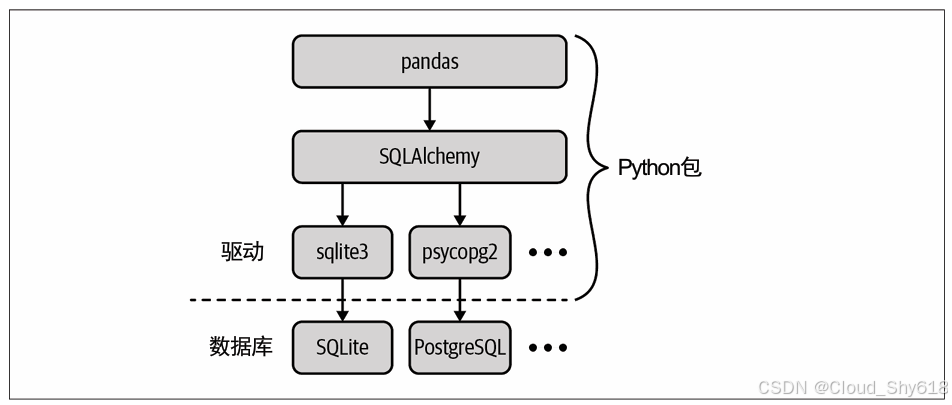
下表展示了在默认情况下 SQLAlchemy 对于不同数据库所使用的驱动(有些数据库可以通过多种驱动连接)。它也给出了各数据库的连接字符串的格式。我们会在实际执行 SQL 查询时用到连接字符串。

除 SQLite 以外的数据库在连接 时都需要密码。由于连接字符串是 URL,因此如果密码中包含特殊字符,就必须对密码进行 URL 编码。可以像下面这样打印出 URL 编码后的密码:
In [9]: import urllib.parse
In [10]: urllib.parse.quote_plus("pa$$word")
Out[10]: 'pa%24%24word'
前文介绍了连接数据库所需的 3 个不同层次的组件:pandas、SQLAlchemy 和数据库驱动。 下面通过执行一些 SQL 查询来了解它们之间的区别。
3、SQL 查询
SQL 是一种声明式语言 (declarative language),也就是说你会告诉数据库你想要什么而不是你想做什么。有些查询读起来就像普通的英语一样:
SELECT * FROM packages这条查询告诉数据库你想要从 packages 表中选择所有的列。在生产代码中,比起使用通配符 * 选择所有列,你可能更愿意显式地指定 每一列,因为这样会使查询出错率更低。
SELECT package_id, package_name FROM packages数据库查询和 pandas DataFrame
SQL 是基于集合 的语言,这意味着你是在操作行的集合而不是遍历每一行。 这和 pandas DataFrame 的工作方式是类似的。下面的 SQL 查询:
SELECT package_id, package_name FROM packages对应着下面的 pandas 表达式(假设 packages 是一个 DataFrame)。
packages.loc[:, ["package_id", "package_name"]]下面的示例代码使用了 packagetracker.db 文件,你可以在配套代码库的 packagetracker 文件夹中找到。就像本章开头所展示的那样,这个例子假设你已经通过 Python 包跟踪器的 Excel 前段将 xlwings 和 pandas 添加到了数据库,不然的话则只会得到空白的结果。沿着前面的三层结构图从下往上,首先通过驱动直接创建 SQL 查询,然后使用 SQLAlchemy,最后使用 pandas:
In [11]: # 先从 import 开始
import sqlite3
from sqlalchemy import create_engine
import pandas as pd
In [12]: # SQL 查询:"从 packages 表中选择所有的列"
sql = "SELECT * FROM packages"
In [13]: # 选项 1:数据库驱动(sqlite3 是标准库的一部分)
# 将数据库连接用作上下文管理器可以自动提交事务,
# 发生错误时会进行回退
with sqlite3.connect("packagetracker/packagetracker.db") as con:
cursor = con.cursor() # 需要一个游标来执行 SQL 查询
result = cursor.execute(sql).fetchall() # 返回所有记录
result
Out[13]: [(1, 'xlwings'), (2, 'pandas')]
In [14]: # 选项 2:SQLAlchemy
# create_engine 需要数据库的连接字符串作为参数
# 在这里可以通过连接对象的方法执行查询
engine = create_engine("sqlite:///packagetracker/packagetracker.db")
with engine.connect() as con:
result = con.execute(sql).fetchall()
result
Out[14]: [(1, 'xlwings'), (2, 'pandas')]
In [15]: # 选项 3:pandas
# 为 read_sql 提供表名以作为参数来读取整张表
# pandas 需要一个在前面例子中用过的 SQLAlchemy 引擎
df = pd.read_sql("packages", engine, index_col="package_id")
df
Out[15]: package_name
package_id
1 xlwings
2 pandas
In [16]: # read_sql 也接受 SQL 查询作为参数
pd.read_sql(sql, engine, index_col="package_id")
Out[16]: package_name
package_id
1 xlwings
2 pandas
In [17]: # DataFrame 方法 to_sql 会将 DataFrame 写入表中
# if_exists 必须为 fail、append、replace 三者之一,
# 它定义了在表已经存在的情况下会发生什么
df.to_sql("packages2", con=engine, if_exists="append")
In [18]: # 前面的命令创建了一张名为 "packages2" 的新表,
# 并将 DataFrame df 中的记录插入表中,
# 在后面可以进行验证
pd.read_sql("packages2", engine, index_col="package_id")
Out[18]: package_name
package_id
1 xlwings
2 pandas
In [19]: # 通过 SQLAlchemy 执行 "drop table" 命令再次删除这张表
with engine.connect() as con:
con.execute("DROP TABLE packages2")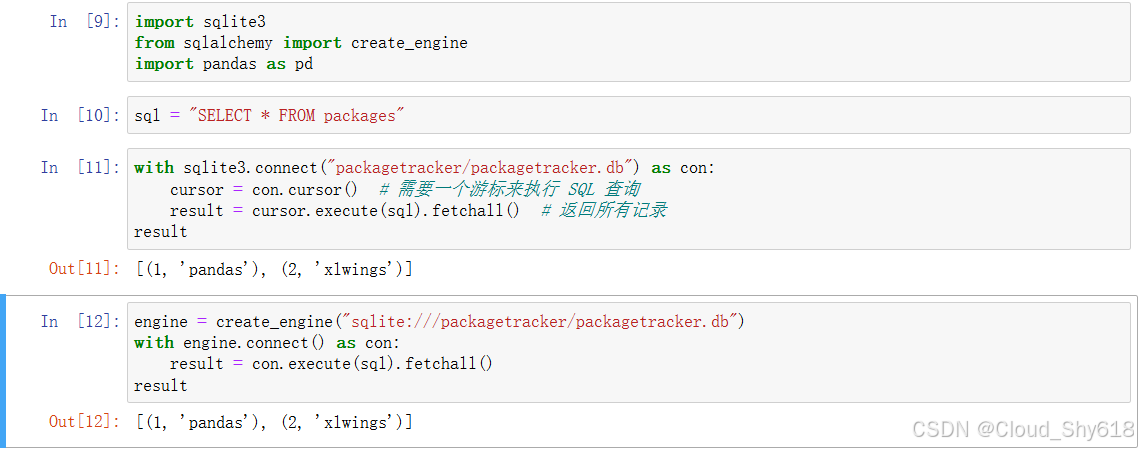
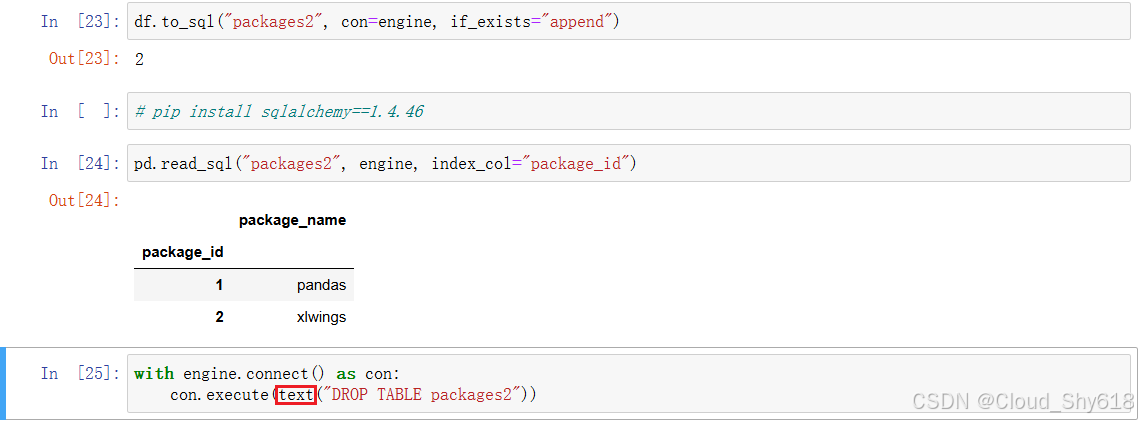
**注意:**在执行这段代码:
df = pd.read_sql("packages", engine, index_col="package_id")
df会报错: AttributeError: 'Connection' object has no attribute 'exec_driver_sql',这个问题的本质是 SQLAlchemy 版本兼容问题。这里,博主改写一下代码使其符合 SQLAlchemy 2.x 版本。
from sqlalchemy import text
df = pd.read_sql(text("SELECT * FROM packages"), engine, index_col="package_id")
df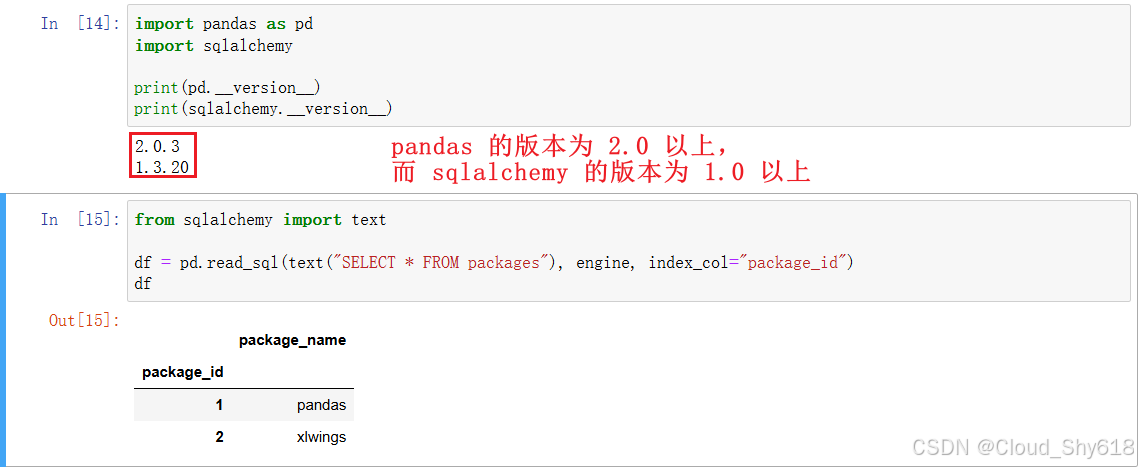
因此,在后续的代码里,我们都需要进行相应的修改,才能正常执行。

然后,为了避免后续的报错,我们需要升级一下 sqlalchemy 版本:
pip install sqlalchemy==1.4.46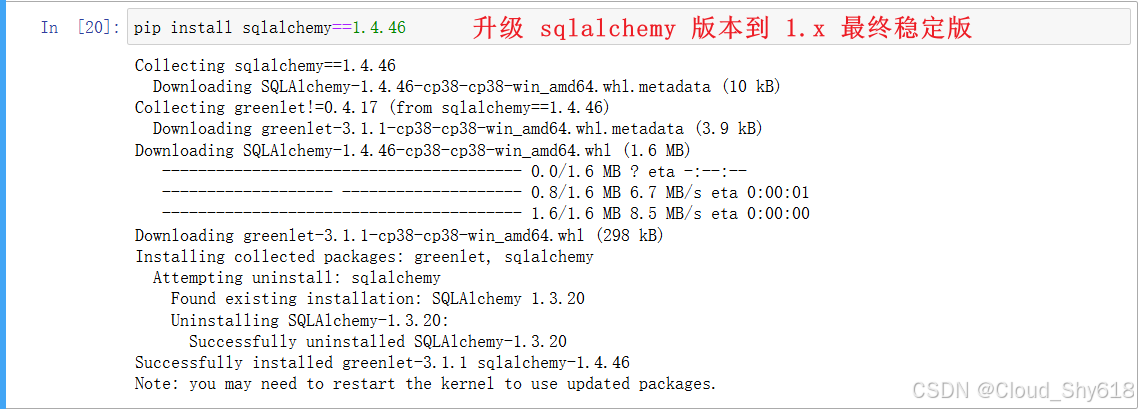
升级成功后需要重新启动内核,再重新执行先前的代码。按照下图中修改后的代码执行即可运行成功。
是用数据库驱动、SQLAlchemy 还是 pandas 来执行查询很大程度上取决于你的偏好。我个人更喜欢 SQLAlchemy 带来的细粒度控制,并且还可以用同样的语法操作不同的数据库。 不过,从另一方面来说,pandas 的 read_sql 在以 DataFrame 方式获取查询结果时更加方便。
SQLite 中的外键 : 有点儿令人诧异的是,SQLite 在执行查询时,默认不遵循外键约束 。然而, 如果你使用的是 SQLAlchemy,则可以轻松地强制执行外键约束,请参见 SQLAlchemy 的文档。在 pandas 中执行查询时这种方法也有效。你可以在配套代码库的 packagetracker 文件夹的 database.py 模块的顶部找到相应的代码。
4、SQL 注入
如果你没有为 SQL 查询设置好安全措施 ,那么图谋不轨的用户可能就会通过向数据输入字段中注入 SQL 语句来执行各种 SQL 代码。比如,他们并没有在 Python 包管理器的下拉菜单中选择 xlwings 之类的包名,而是发送了一条可能会修改查询本身的 SQL 代码。这可能会暴露敏感信息或者执行类似于删除表之类的破坏性操作。那么如何防止这类问题呢?首先来看一下下面的数据库查询,在你选择 xlwings 并点击 Show History(显示历史)时,包 跟踪器会执行该查询:
SELECT v.uploaded_at, v.version_string
FROM packages p
INNER JOIN package_versions v ON p.package_id = v.package_id
WHERE p.package_id = 1这条查询将两张表连接在一起,只返回了 package_id 为 1 的行。为了帮助你理解这条查询,利用第 5 章中学到的知识来解释。如果 packages 和 package_versions 是 pandas DataFrame,那么你就可以写成下面这样:
df = packages.merge(package_versions, how="inner", on="package_id")
df.loc[df["package_id"] == 1, ["uploaded_at", "version_string"]]这里将 package_id 硬编码为 1,但是为了能够根据所选的包返回对应的行, 我们需要一个变量。有了第 3 章中关于 f 字符串的知识后,你可能会想到将 SQL 查询的最后一行改成下面这样:
f"WHERE p.package_id = {package_id}"虽然从技术上来说这是可行的,但是绝不能这样做,因为这会为 SQL 注入敞开大门,比如某人可能会发送 '1 OR TRUE' 而不是一个表示 package_id 的整数。这样的查询会返回整张表的行而不是 package_id 为 1 的行。因此,应该只使用 SQLAlchemy 提供的占位符语法 (以冒号开头):
In [21]: # :package_id是占位符
sql = """
SELECT v.uploaded_at, v.version_string
FROM packages p
INNER JOIN package_versions v ON p.package_id = v.package_id
WHERE p.package_id = :package_id
ORDER BY v.uploaded_at
"""
In [22]: # 使用SQLAlchemy
with engine.connect() as con:
result = con.execute(text(sql), package_id=1).fetchall()
result[:3] # 打印前3条记录
Out[22]: [('2014-03-19 18:18:49.000000', '0.1.0'),
('2014-06-27 16:26:36.000000', '0.1.1'),
('2014-07-29 17:14:22.000000', '0.2.0')]
In [23]: # 使用pandas
pd.read_sql(text(sql), engine, parse_dates=["uploaded_at"],
params={"package_id": 1},
index_col=["uploaded_at"]).head(3)
Out[23]: version_string
uploaded_at
2014-03-19 18:18:49 0.1.0
2014-06-27 16:26:36 0.1.1
2014-07-29 17:14:22 0.1.2 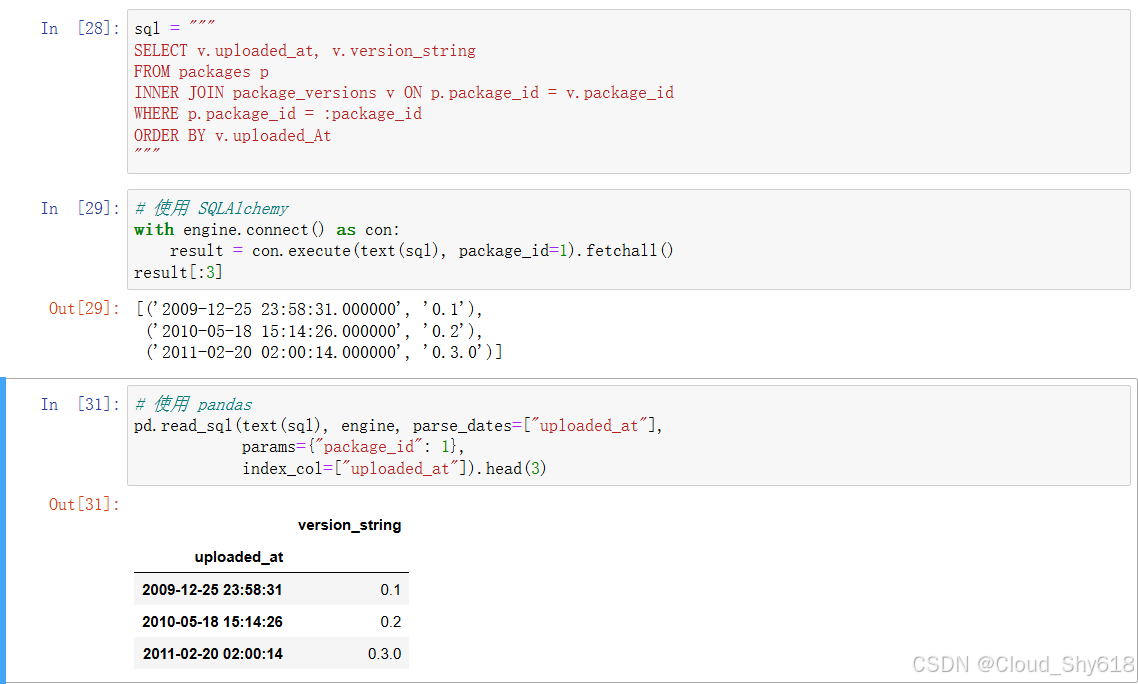
用 SQLAlchemy 的 text 函数包装 SQL 查询的好处在于你可以在不同的数据库中使用统一的占位符语法。否则,你就需要使用各个数据库驱动所用的占位符,比如 sqlite3 会使用 ?,而 psycopg2 会使用 %s。
你可能不以为然,认为这并不是什么大问题,因为这个工具的用户能够直接使用 Python, 从而也能够在数据库上执行任意的代码。但是如果某天你把你的 xlwings 原型转化成一个 Web 应用程序,那么这就是大问题了。所以最好还是在一开始就把这个问题处理妥当。 除了 Web API 和数据库,还有一个主题目前没有提及,但是它对于稳健的软件开发来说是必不可少的,那就是异常处理。下面来看看如何进行异常处理。
11.2.3 异常
第 1 章在举例说明 VBA 的 GoTo 机制已经落后时提到过异常处理。本节会向你展示 Python 如何使用 try/except 机制来处理程序中的错误。每当有些东西脱离你的控制时, 错误就会(且一定会)发生。例如,在你尝试发送邮件时,邮件服务器可能停止运行了。 或者在你的程序需要访问一个文件时文件不见了,而对 Python 包跟踪器来说,这可能是数据库文件。处理用户输入时,必须对用户输入的毫无意义的内容有所准备。我们来实践一下。如果下面的函数以 0 为参数进行调用,那么你会得到一个 ZeroDivisionError 异常:
In [24]: def print_reciprocal(number):
result = 1 / number
print(f"The reciprocal is: {result}")
In [25]: print_reciprocal(0) # 此处会引发错误 ---------------------------------------------------------------------------
ZeroDivisionError Traceback (most recent call last)
<ipython-input-25-095f19ebb9e9> in <module> ----> 1 print_reciprocal(0) # 此处会引发错误
<ipython-input-24-88fdfd8a4711> in print_reciprocal(number)
1 def print_reciprocal(number): ----> 2 result = 1 / number
3 print(f"The reciprocal is: {result}")
ZeroDivisionError: division by zero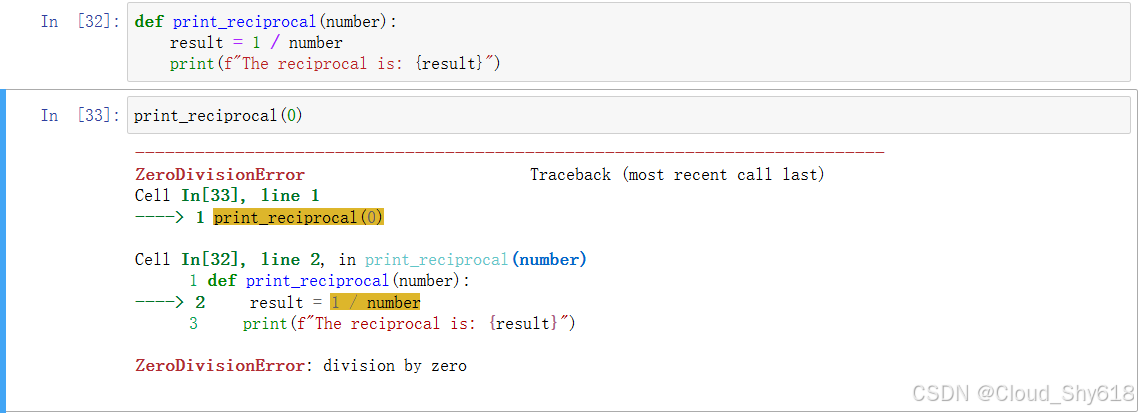
应对这样的错误,可以使用 try/except 语句(这和第 1 章中 VBA 的例子是等效的):
In [26]: def print_reciprocal(number):
try:
result = 1 / number
except Exception as e:
# as e 令 Exception 对象为变量 e
# repr 代表对象的 "printable representation"(可打印表示法),
# 它会返回代表错误信息的字符串
print(f"发生错误:{repr(e)}")
result = "N/A"
else:
print("没有错误发生!")
finally:
print(f"倒数为:{result}")每当 try 块中发生错误时,代码的执行位置就会移至 except 块,你可以在这里处理错误: 可以为用户提供一些有用的反馈,或是将错误写入日志文件。else 分句只在 try 块中没有错误发生时执行,而 finally 块总是会执行,无论是否发生错误。通常,你只会写 try 和 except 这两个代码块。下面来看看输入不同值时函数的输出:
In [27]: print_reciprocal(10)
没有错误发生!
倒数为:0.1
In [28]: print_reciprocal("a")
发生错误:TypeError("unsupported operand type(s) for /: 'int'
and 'str'")
倒数为:N/A
In [29]: print_reciprocal(0)
发生错误:ZeroDivisionError('division by zero')
倒数为:N/A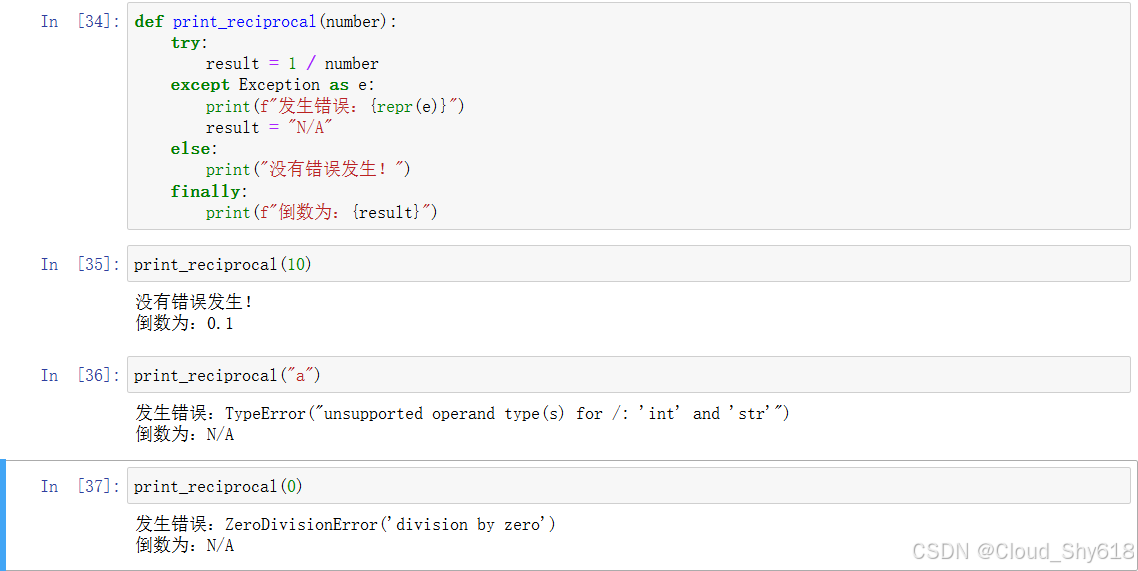
像这样使用 except 语句意味着 try 块中发生的任何异常都会导致代码转入 except 块继续执行。一般来说你并不想这样做,而是想要检查尽可能具体的错误是否发生,且只处理那些你预料到可能会发生的错误。你的程序可能会因为一些完全预料不到的事情发生错误, 这类错误很难去调试。为了改进这一点,可以将函数重写成下面这样,只检查能够预料到的两类错误(省略了 else 语句和 finally 语句):
In [30]: def print_reciprocal(number):
try:
result = 1 / number
print(f"倒数为:{result}")
except (TypeError, ZeroDivisionError):
print("请输入0以外的任意数字。")
In [31]: print_reciprocal("a")
请输入0以外的任意数字。
如果你想针对异常情况进行不同的处理,那么可以像下面这样分别处理:
In [32]: def print_reciprocal(number):
try:
result = 1 / number
print(f"倒数为:{result}")
except TypeError:
print("请输入数字。")
except ZeroDivisionError:
print("0的倒数未定义。")
In [33]: print_reciprocal("a")
请输入数字。
In [34]: print_reciprocal(0)
0的倒数未定义。
现在你已经知道了如何进行错误处理,也了解了 Web API 和数据库,并且做好了进入下一节的准备。下一节会研究 Python 包跟踪器的各个组件。