ZooKeeper的工作原理与实现
▲ 工作原理和角色
ZooKeeper通过其独特的设计和实现,为分布式系统提供了高可用性和一致性保障,成为了核心角色。它通过高可用性、高性能和一致性等特性,为分布式系统提供了强健的保障。其实现过程包括多个关键组件的协同工作,共同构成了ZooKeeper在分布式系统中的核心角色。
▲ 单点故障解决
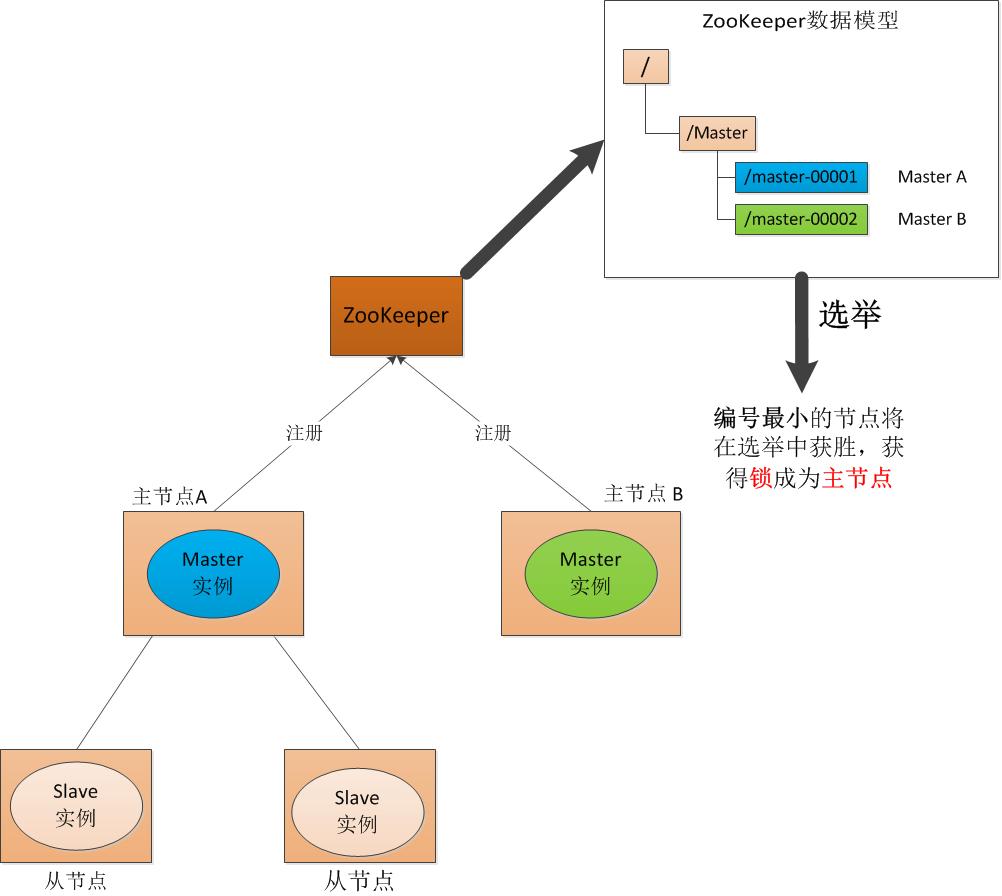
ZooKeeper通过其特有的Master选举机制,有效解决了分布式系统中的单点故障问题。这一机制确保了在系统出现故障时,能够迅速选出新的Master节点,从而保证了分布式系统的稳定性和可用性。ZooKeeper通过其Master选举功能,确保了系统在任何时候都只有一个Master节点在服务。这样一来,系统能及时选出新的Master节点来接替故障节点,从而持续稳定地提供服务。
▲ 运行模式
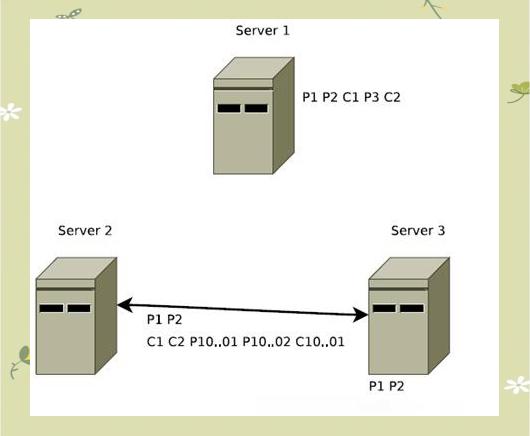
ZooKeeper服务存在两种不同的运行模式。首先是"独立模式",在这种模式下,仅运行一个ZooKeeper服务器,其设置相对简单,通常仅适用于测试环境。然而,这种模式无法提供高可用性和恢复性。在实际生产环境中,ZooKeeper通常以"复制模式"运行,该模式要求在一个计算机集群上部署ZooKeeper,这个集群被称为"集合体"。通过这种模式,可以确保ZooKeeper的高可用性和恢复性,从而为分布式系统提供稳定的单点故障解决方案。
在复制模式下,只要超过半数的机器保持可用,ZooKeeper便能持续提供服务。每个Follower节点都存储着Leader节点数据的副本,确保数据视图的一致性,共同提供服务。
▲ 读写机制
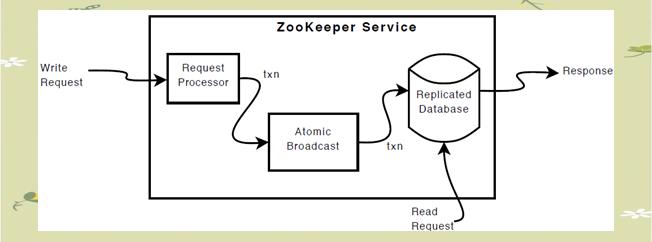
ZooKeeper的设计理念是为分布式系统提供一种非锁机制的Wait Free同步服务。它简化了文件创建和读写操作,并通过版本比对实现更新操作,从而允许客户端根据此机制自行实现锁逻辑。这种设计有助于防止因并发更新导致的数据不一致问题。

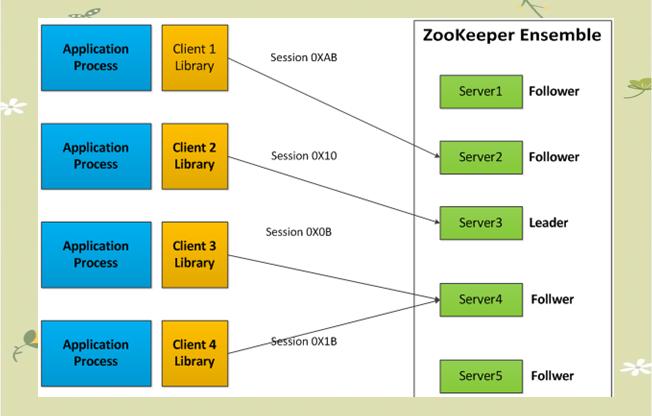
在ZooKeeper集群中,每个Server都承担着保存数据副本的责任。为了确保数据的一致性,ZooKeeper采用了简洁的同步机制。所有写请求都会被集中处理,由领导者负责更新并广播给跟随者。只有当超过半数的跟随者成功将修改持久化后,领导者才会确认此次更新,并向客户端反馈成功消息。

02ZooKeeper的保证
▲ CAP理论
在分布式系统中,CAP理论为我们提供了关于一致性和可用性之间平衡的重要见解。该理论指出,分布式系统在面临网络分区等故障时,无法同时保证一致性、可用性和分区容错性这三者。具体来说,C代表一致性,即数据在系统内部各节点之间能够同步更新;A代表可用性,即系统能够提供良好的响应性能;而P则代表分区容错性,即系统在面对网络分区等故障时,能够保持可用性。
▲ ZooKeeper与CAP理论
ZooKeeper也是一种分布式系统,其数据一致性方面存在多种观点。有人认为它提供强一致性服务(通过sync操作),有人认为是单调一致性,还有人认为是最终一致性。不论哪种观点,ZooKeeper在分区容错性和可用性方面都做出了折中,这与CAP理论相吻合。ZooKeeper在CAP理论框架下优化了分区容错性和可用性,以适应不同的应用场景。
03ZooKeeper的原理
▲ 原理概述
ZooKeeper的核心在于其原子广播机制,这种机制通过Zab协议得以实现,该协议保证了集群中各个server的同步。Zab协议包含两种模式:恢复模式和广播模式。
▲ Zab协议分析
Zab协议,作为ZooKeeper的核心组件,负责确保数据在分布式系统中的一致性。它通过广播模式工作,其中服务器会接收并处理客户端的请求。所有写请求都会被集中处理,由领导者负责更新并广播给跟随者。
新加入的server会在恢复模式下启动,发现并同步leader的状态后,也会参与消息的广播。ZooKeeper服务将持续处于广播状态,直至leader崩溃或leader失去大部分follower的支持。

▲ 广播模式
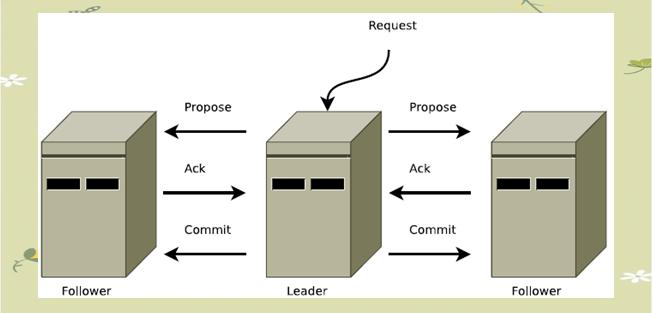
广播模式在Zab协议中扮演着核心角色,其运作方式类似于一个精简的两阶段提交协议。在此模式下,领导者负责发起请求并收集选票,最终进行提交。广播协议在Zab协议中占据核心地位,它利用TCP的FIFO信道进行所有通讯,确保消息的有序传递。

Leader会将已deliver的消息广播至所有Follower。Follower收到Proposal后,会将其写入磁盘,并尽可能进行批量写入。一旦写入成功,Follower会向Leader发送ACK确认。
▲ 恢复模式
在Zab协议中,当Leader出现故障时,协议会转入恢复模式。此模式的目的是重新选举出一个新的Leader,并确保所有Server最终达到一致的状态。为了成功选举出新的Leader,我们需要一个高效的算法,该算法能在大多数情况下保证Leader的存活。

这种设计消除了"中止"带来的复杂性,使得只要达到指定数量的机器确认提议,即可进行下一步操作,无需等待所有机器的回应。