参考

一、环境准备
# 更新系统
sudo apt update && sudo apt upgrade -y
# 安装Docker
sudo apt install docker.io -y #安装不了要换(清华、阿里等)源
sudo systemctl start docker #现在启动
sudo systemctl enable docker #开机自启动
# 验证Docker安装
docker --version
# 创建专用目录
mkdir ~/hadoop-docker && cd ~/hadoop-docker
准备一个 hadoop-3.3.0.tar.gz

二、创建Docker网络
Hadoop集群需要容器间通信,我们先创建专用网络:
docker network create \
--driver bridge \
--subnet=172.19.0.0/16 \
hadoop-net验证网络情况
bash
docker network inspect hadoop-net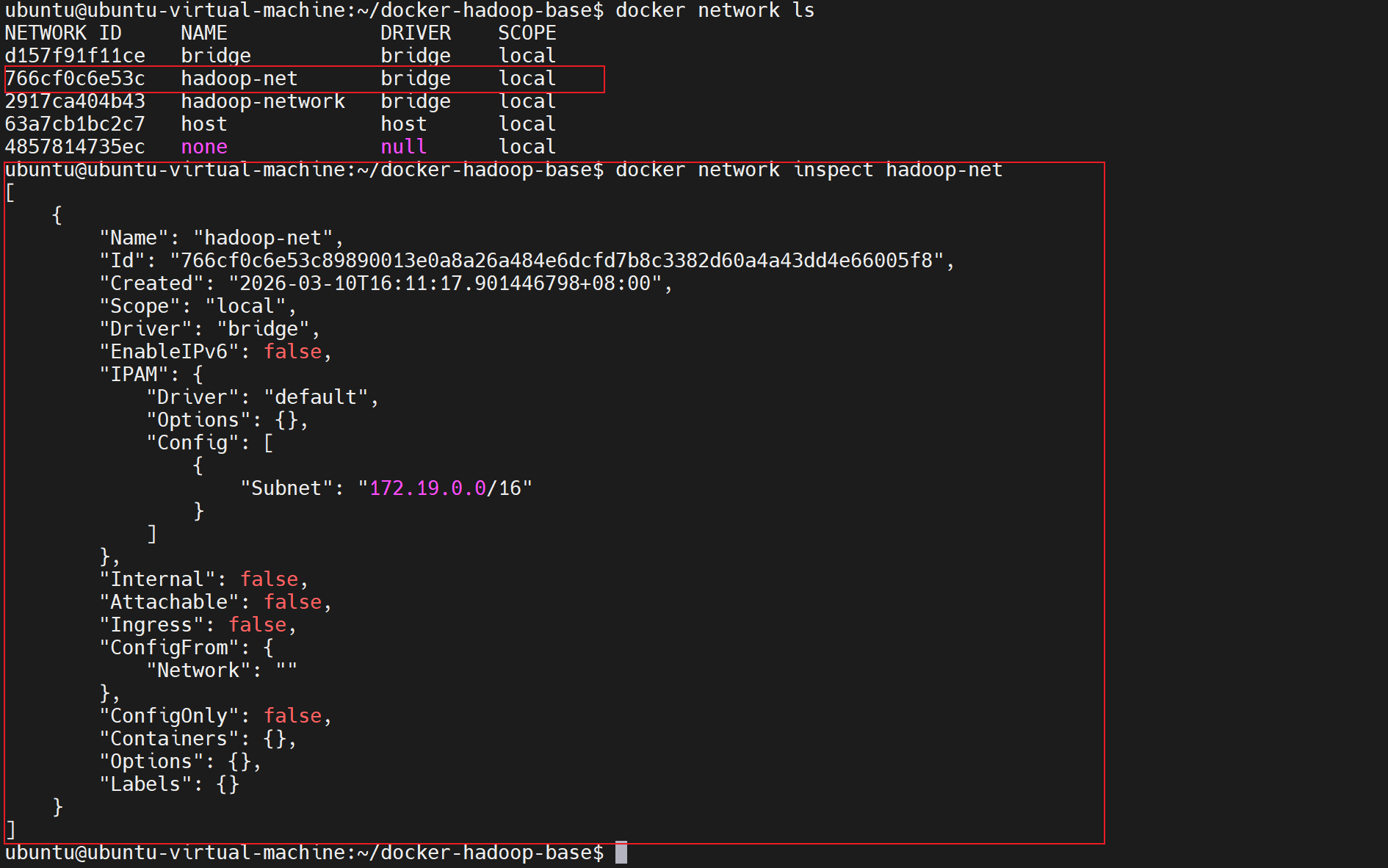
三、构建基础 镜像
创建启动脚本:
bash
sudo nano entrypoint.sh内容:
bash
#!/bin/bash
# 启动SSH服务
service ssh start
# 生成SSH密钥(如果不存在)
if [ ! -f ~/.ssh/id_rsa ]; then
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys
fi
# 保持容器运行
tail -f /dev/null创建Dockerfile:
bash
sudo nano Dockerfile内容如下:
bash
FROM ubuntu:22.04
# 设置时区避免交互提示
ENV DEBIAN_FRONTEND=noninteractive
# 安装基础工具
RUN apt update && apt install -y \
openssh-server \
openjdk-11-jdk \
wget \
vim \
net-tools \
iputils-ping \
dnsutils
# 配置SSH
RUN mkdir /var/run/sshd
RUN echo 'root:root' | chpasswd
RUN sed -i 's/#PermitRootLogin prohibit-password/PermitRootLogin yes/' /etc/ssh/sshd_config
RUN sed -i 's/#PasswordAuthentication yes/PasswordAuthentication yes/' /etc/ssh/sshd_config
# 安装Hadoop
#ENV HADOOP_VERSION=3.4.1
#ENV HADOOP_URL=https://downloads.apache.org/hadoop/common/hadoop-$HADOOP_VERSION/hadoop-$HADOOP_VERSION.tar.gz
#RUN wget $HADOOP_URL -O hadoop.tar.gz && \
# tar -xzvf hadoop.tar.gz -C /usr/local/ && \
# rm hadoop.tar.gz && \
# mv /usr/local/hadoop-$HADOOP_VERSION /usr/local/hadoop
# 复制本地Hadoop安装包(核心修改:不再从网上下载)
ENV HADOOP_VERSION=3.3.0
COPY ./hadoop-$HADOOP_VERSION.tar.gz /tmp/
# 安装Hadoop(使用本地包)
RUN tar -xzvf /tmp/hadoop-$HADOOP_VERSION.tar.gz -C /usr/local/ \
&& rm /tmp/hadoop-$HADOOP_VERSION.tar.gz \
&& mv /usr/local/hadoop-$HADOOP_VERSION /usr/local/hadoop \
&& chown -R root:root /usr/local/hadoop
# 设置环境变量
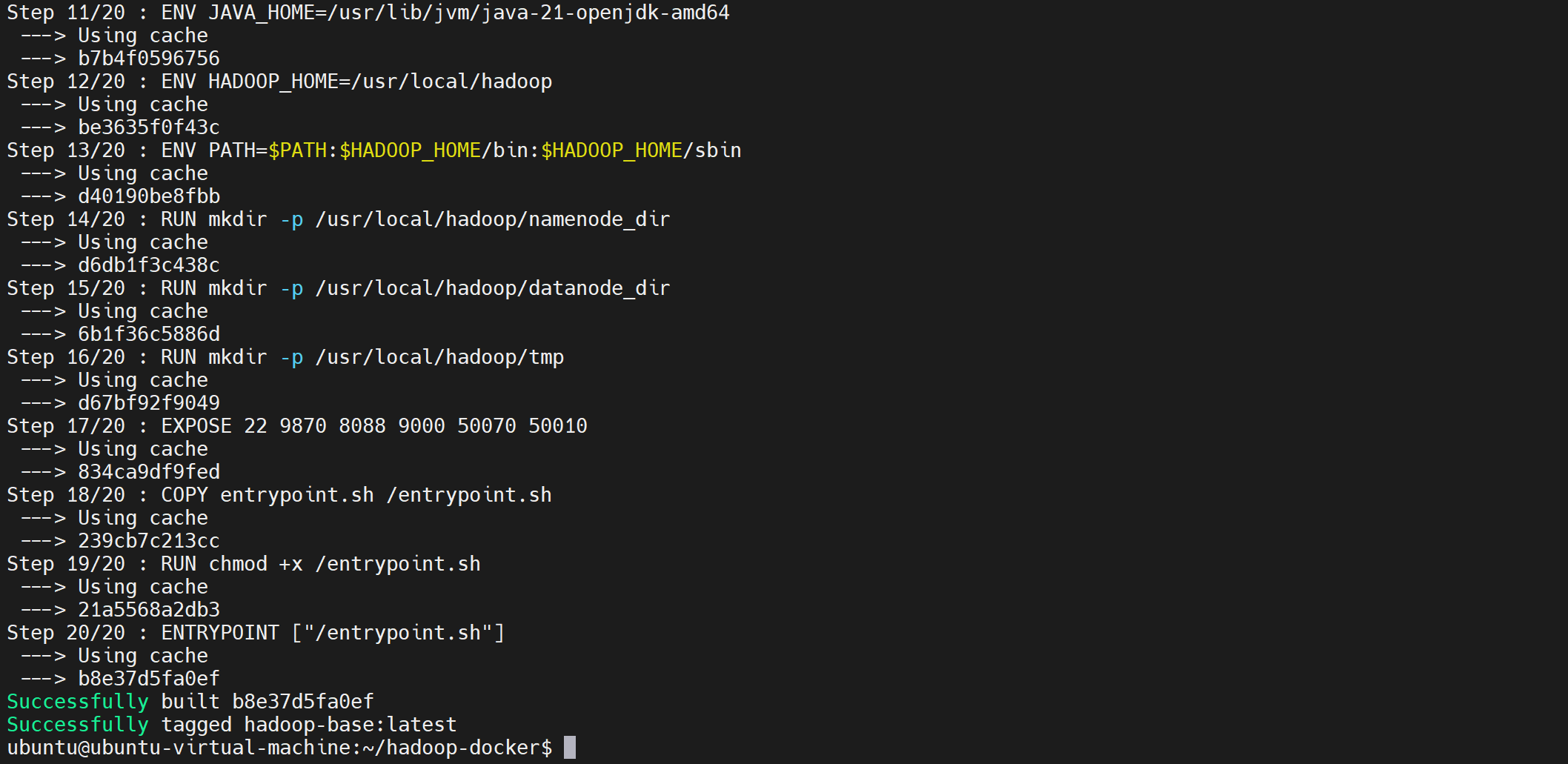
ENV JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
ENV HADOOP_HOME=/usr/local/hadoop
ENV HADOOP_MAPRED_HOME=/usr/local/hadoop # 新增这一行
ENV PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# 创建数据目录
RUN mkdir -p /usr/local/hadoop/namenode_dir
RUN mkdir -p /usr/local/hadoop/datanode_dir
RUN mkdir -p /usr/local/hadoop/tmp
# 暴露端口
EXPOSE 22 9870 8088 9000 50070 50010
# 启动脚本
COPY entrypoint.sh /entrypoint.sh
RUN chmod +x /entrypoint.sh
ENTRYPOINT ["/entrypoint.sh"]
构建镜像:
bash
docker build -t hadoop-base .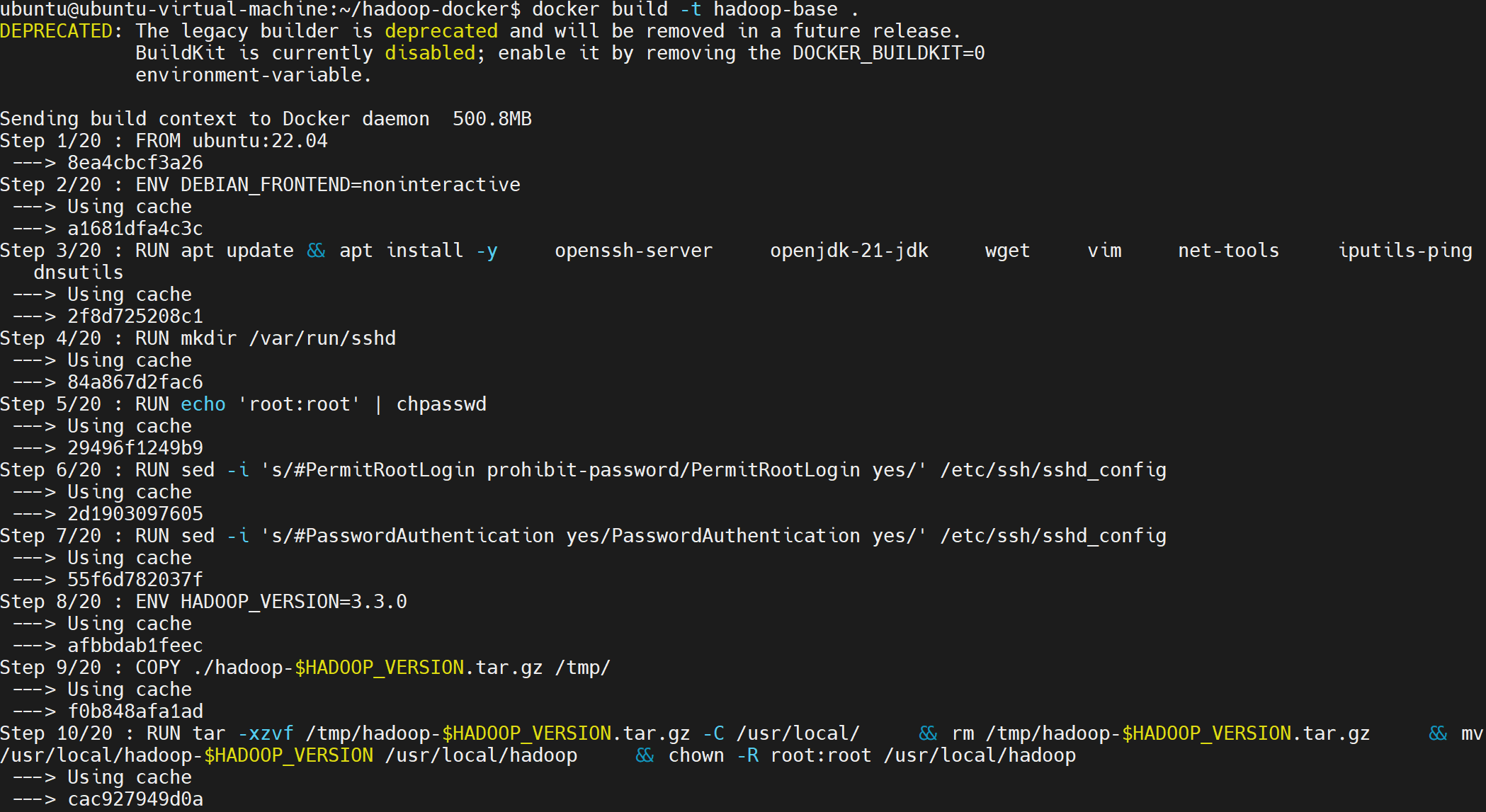
如果需要删除镜像
bash
构建镜像:
```bash
docker rmi hadoop-base:latest## 四、启动Hadoop集群
1. 启动Master节点
```bash
docker run -itd \
--name master \
--hostname master \
--net hadoop-net \
--ip 172.19.0.2 \
-p 9870:9870 \
-p 8088:8088 \
-p 9000:9000 \
hadoop-base
- 启动Worker节点
bash
docker run -itd \
--name worker01 \
--hostname worker01 \
--net hadoop-net \
--ip 172.19.0.3 \
hadoop-base
docker run -itd \
--name worker02 \
--hostname worker02 \
--net hadoop-net \
--ip 172.19.0.4 \
hadoop-base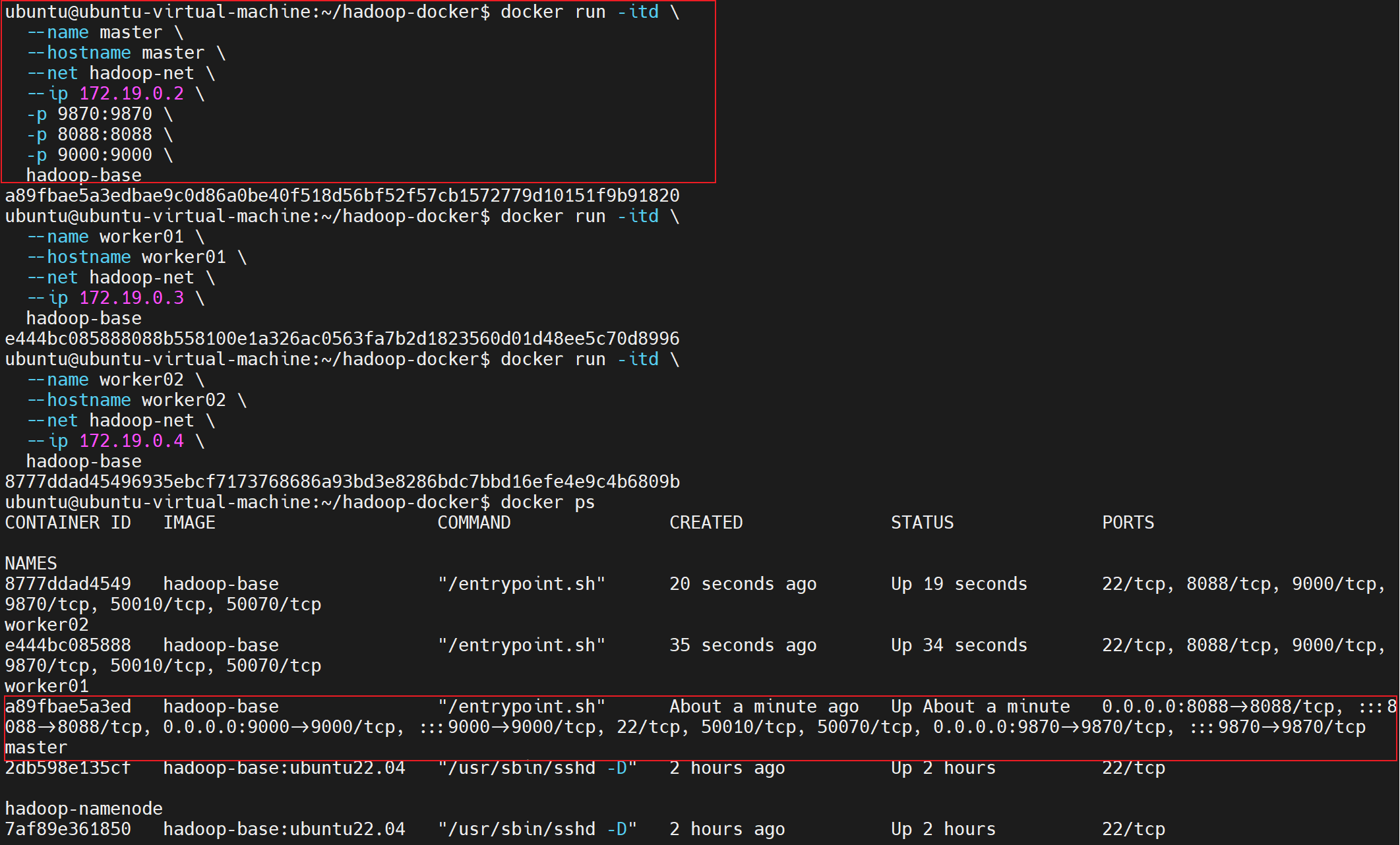
五、配置主机解析
在Master节点中:
bash
docker exec master bash -c "echo '172.19.0.2 master' >> /etc/hosts"
docker exec master bash -c "echo '172.19.0.3 worker01' >> /etc/hosts"
docker exec master bash -c "echo '172.19.0.4 worker02' >> /etc/hosts"在Worker01节点中:
bash
docker exec worker01 bash -c "echo '172.19.0.2 master' >> /etc/hosts"
docker exec worker01 bash -c "echo '172.19.0.3 worker01' >> /etc/hosts"
docker exec worker01 bash -c "echo '172.19.0.4 worker02' >> /etc/hosts"在Worker02节点中:
bash
docker exec worker02 bash -c "echo '172.19.0.2 master' >> /etc/hosts"
docker exec worker02 bash -c "echo '172.19.0.3 worker01' >> /etc/hosts"
docker exec worker02 bash -c "echo '172.19.0.4 worker02' >> /etc/hosts"六、配置SSH免密登录
进入Master容器:
bash
docker exec -it master bash生成SSH密钥:这一个步骤不用执行,已经执行过了
bash
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa配置免密登录:
bash
# 将公钥复制到所有节点
ssh-copy-id master
ssh-copy-id worker01
ssh-copy-id worker02
bash
# 测试免密登录
ssh worker01 hostname # 应返回 worker01
ssh worker02 hostname # 应返回 worker02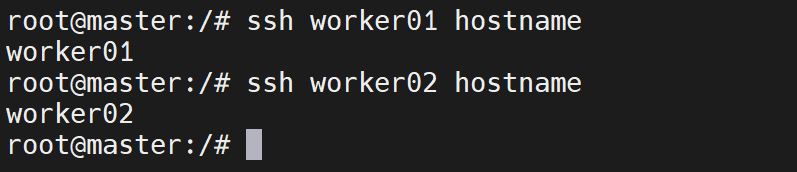
如果 ssh-copy-id worker01 出现错误,可以按照下面的解决方案
bash
# 这个是命令说明不用执行
ssh-copy-id master
# 等价
# 手动复制公钥(替代 ssh-copy-id master)
cat ~/.ssh/id_rsa.pub | ssh root@master "mkdir -p ~/.ssh && cat >> ~/.ssh/authorized_keys && chmod 600 ~/.ssh/authorized_keys && chmod 700 ~/.ssh"步骤 1:先登录 worker01 容器,检查并修复 SSH 配置
bash
# 从宿主机直接进入 worker01 容器(绕开 SSH,直接操作)
docker exec -it worker01 bash
# 1. 重置 root 密码为 root(确保密码正确)
echo 'root:root' | chpasswd
# 2. 确认 SSH 配置中开启密码登录(关键)
sed -i 's/#PermitRootLogin prohibit-password/PermitRootLogin yes/' /etc/ssh/sshd_config
sed -i 's/#PasswordAuthentication yes/PasswordAuthentication yes/' /etc/ssh/sshd_config
# 3. 重启 SSH 服务,让配置生效
service ssh restart
# 4. 退出 worker01 容器
exit步骤 2:重新执行 ssh-copy-id worker01(验证)
回到 master 容器的终端,重新执行命令:
bash
# 在 master 容器内执行
ssh-copy-id worker01- 此时会提示
Are you sure you want to continue connecting (yes/no/[fingerprint])?,输入yes; - 接着提示
root@worker01's password:,输入root(你重置后的密码),回车即可成功。
步骤 3:同理修复 worker02(如果有)
bash
# 宿主机执行:进入 worker02 容器
docker exec -it worker02 bash
# 重置密码+开启SSH密码登录
echo 'root:root' | chpasswd
sed -i 's/#PermitRootLogin prohibit-password/PermitRootLogin yes/' /etc/ssh/sshd_config
sed -i 's/#PasswordAuthentication yes/PasswordAuthentication yes/' /etc/ssh/sshd_config
service ssh restart
exit
# master 容器内执行:复制公钥到 worker02
ssh-copy-id worker02步骤 4:验证免密登录是否生效
bash
# 在 master 容器内测试
ssh worker01 # 应直接登录,无密码提示
ssh worker02 # 同理七、配置Hadoop集群
- 创建配置文件目录
bash
mkdir /usr/local/hadoop/etc/hadoop/config
cd /usr/local/hadoop/etc/hadoop/config- 创建core-site.xml
bash
vi core-site.xml内容:
bash
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
</configuration>- 创建hdfs-site.xml
bash
vi hdfs-site.xml内容:
bash
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop/namenode_dir</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/datanode_dir</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>- 创建mapred-site.xml
bash
vi mapred-site.xml内容:
bash
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
</configuration>- 创建yarn-site.xml
bash
vi yarn-site.xml内容:
bash
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>
$HADOOP_HOME/etc/hadoop,
$HADOOP_HOME/share/hadoop/common/*,
$HADOOP_HOME/share/hadoop/common/lib/*,
$HADOOP_HOME/share/hadoop/hdfs/*,
$HADOOP_HOME/share/hadoop/hdfs/lib/*,
$HADOOP_HOME/share/hadoop/mapreduce/*,
$HADOOP_HOME/share/hadoop/mapreduce/lib/*,
$HADOOP_HOME/share/hadoop/yarn/*,
$HADOOP_HOME/share/hadoop/yarn/lib/*
</value>
</property>
</configuration>- 创建workers文件
bash
vi workers内容:
bash
worker01
worker02- 配置环境变量
bash
vi /usr/local/hadoop/etc/hadoop/hadoop-env.sh添加
bash
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root- 分发配置到Worker节点
bash
# 在Master容器中执行
for worker in worker01 worker02; do
scp -r $HADOOP_HOME/etc/hadoop/config/* $worker:$HADOOP_HOME/etc/hadoop/
scp $HADOOP_HOME/etc/hadoop/hadoop-env.sh $worker:$HADOOP_HOME/etc/hadoop/
done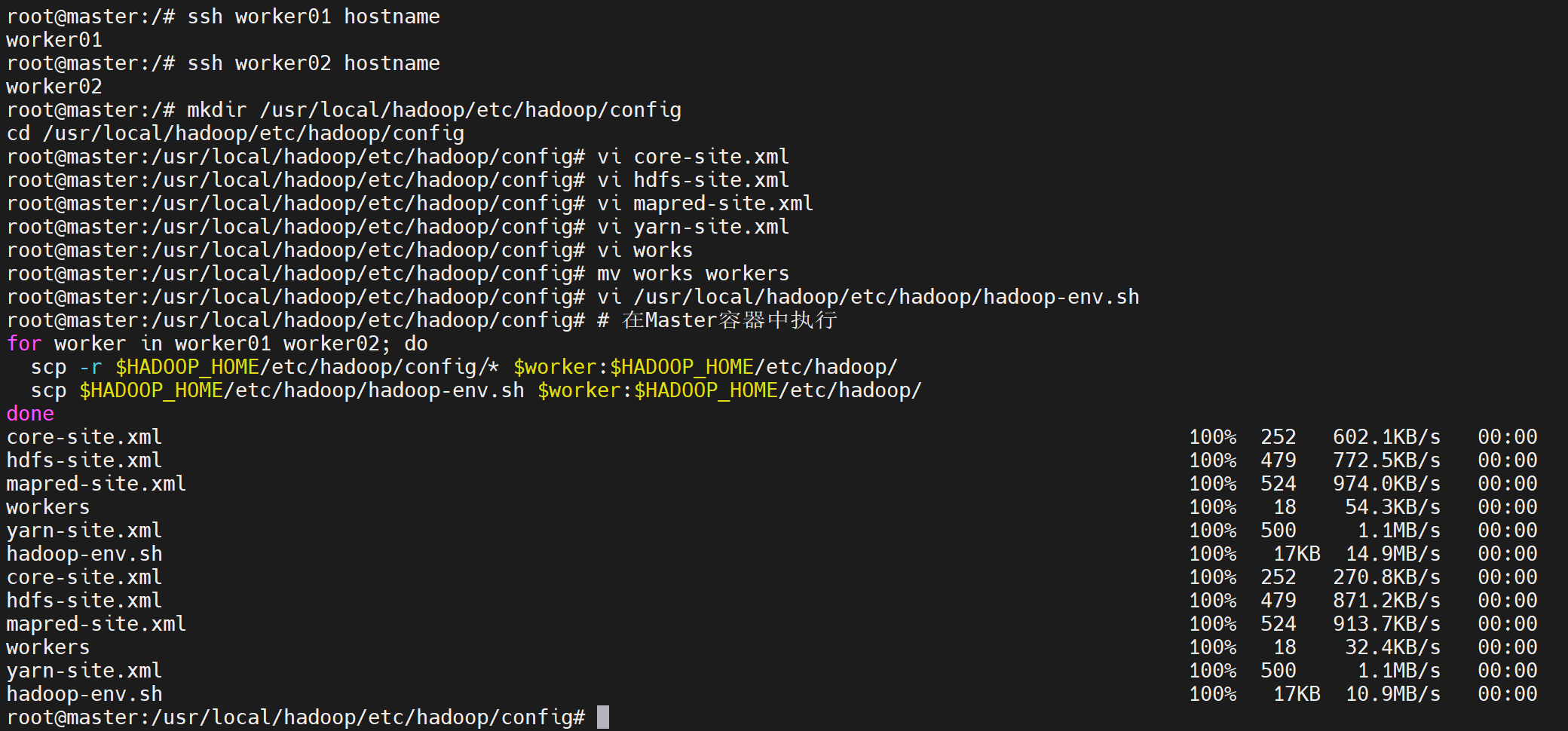
在把master容器中的文件覆盖到/etc/hadoop中
bash
# 进入 Hadoop 配置根目录
cd /usr/local/hadoop/etc/hadoop/
# 强制覆盖:将 config 目录下的所有配置文件复制到当前目录(覆盖原有文件)
cp -f config/* ./
# 验证覆盖结果(查看核心文件是否已更新)
ls -l core-site.xml hdfs-site.xml yarn-site.xml mapred-site.xml workers八、启动Hadoop集群
- 格式化NameNode
bash
hdfs namenode -format成功标志:看到Storage directory has been successfully formatted信息
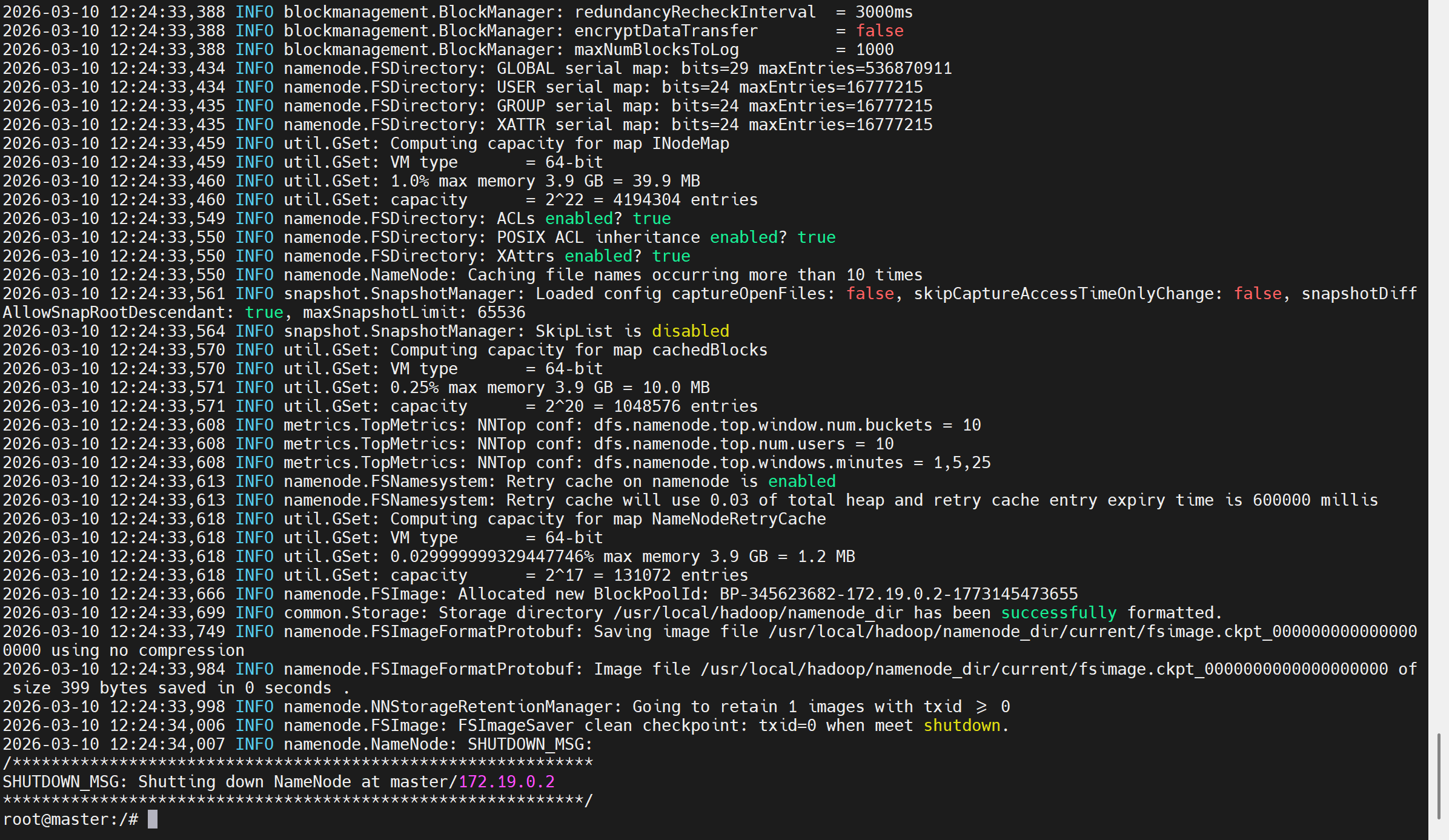
如果失败,需要重新格式化,格式化前,删除原有的数据
bash
# 清空 NameNode 元数据目录(namenode_dir)
rm -rf /usr/local/hadoop/namenode_dir/*
# 清空 DataNode 数据目录(datanode_dir)
rm -rf /usr/local/hadoop/datanode_dir/*
# 清空 Hadoop 临时目录(tmp)
rm -rf /usr/local/hadoop/tmp/*
# 验证清空结果(目录为空,输出 total 0)
echo "=== 验证目录清空结果 ==="
ls -l /usr/local/hadoop/namenode_dir/
ls -l /usr/local/hadoop/datanode_dir/
ls -l /usr/local/hadoop/tmp/
- 启动HDFS
bash
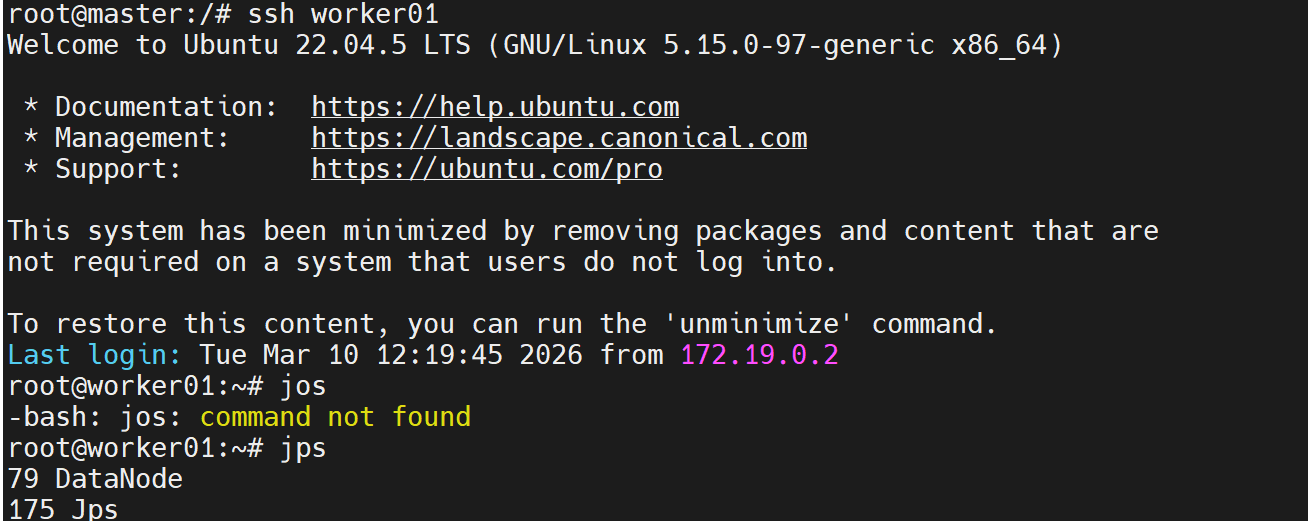
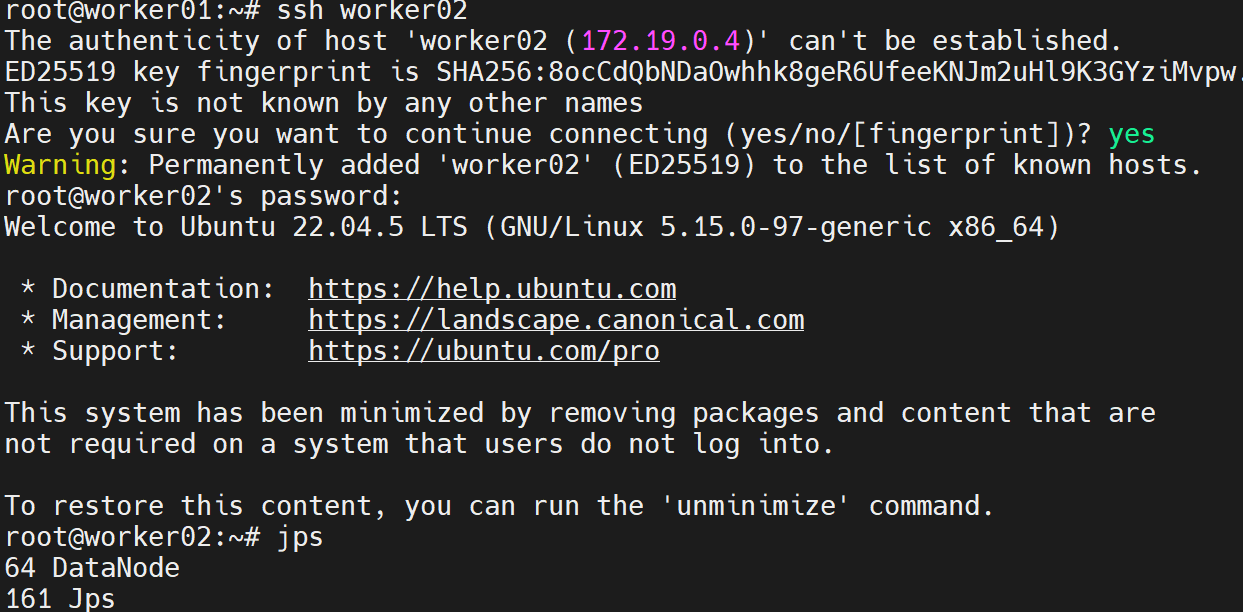
start-dfs.sh验证:
bash
jps应看到:
xxxxx NameNode
xxxxx DataNode
xxxxx SecondaryNameNode
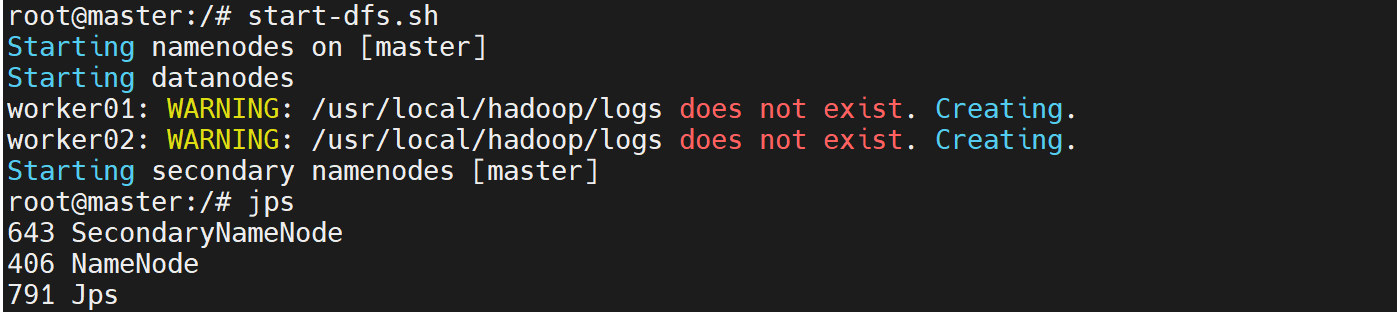
- 启动YARN
bash
start-yarn.sh验证
bash
jps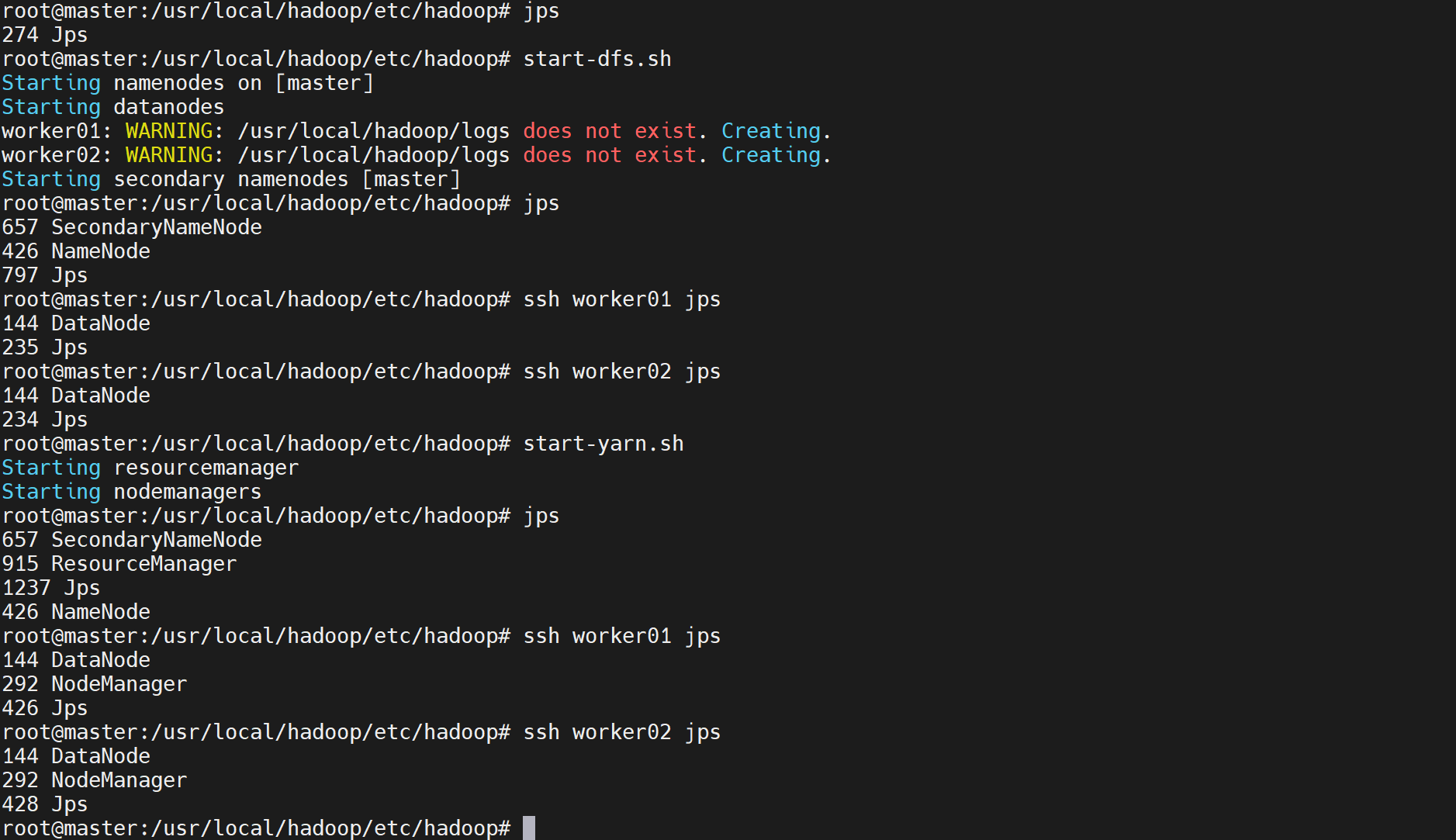
九、验证集群功能
- 创建测试目录
bash
hdfs dfs -mkdir -p /user/root/input- 上传测试文件
bash
echo "Hello Hadoop World" > test.txt
hdfs dfs -put test.txt /user/root/input- 查看HDFS内容
bash
hdfs dfs -ls /user/root/input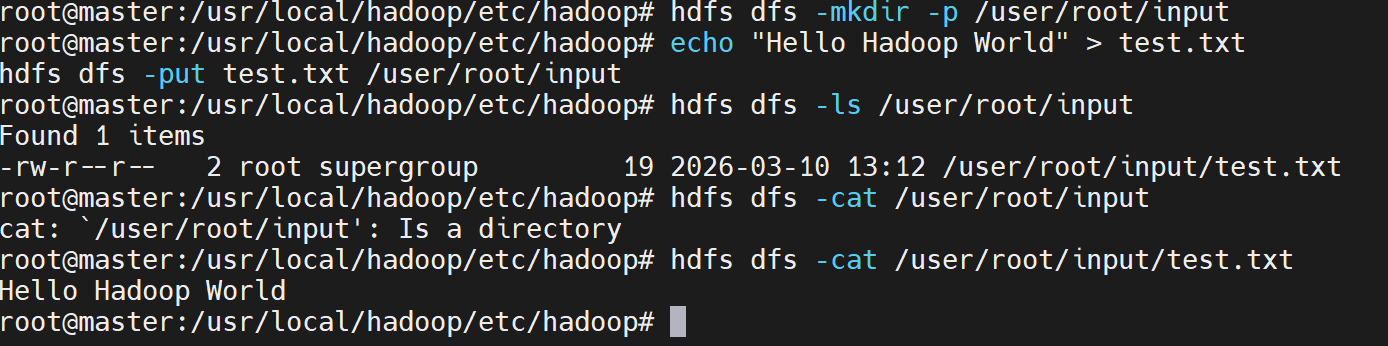
- 运行WordCount示例
bash
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar wordcount /user/root/input /user/root/output如果出现问题,可以强制执行
bash
# 终极兜底命令(复制粘贴直接运行)
hadoop jar \
$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar \
wordcount \
-Dmapreduce.application.classpath=$(hadoop classpath) \
-Dyarn.app.mapreduce.am.env="HADOOP_MAPRED_HOME=/usr/local/hadoop" \
-Dmapreduce.map.env="HADOOP_MAPRED_HOME=/usr/local/hadoop" \
-Dmapreduce.reduce.env="HADOOP_MAPRED_HOME=/usr/local/hadoop" \
/user/root/input \
/user/root/output- 查看结果
bash
hdfs dfs -cat /user/root/output/part-r-00000应看到:

重新设置全局的环境变量,在master中,这个方法也没有生效
bash
echo "export HADOOP_MAPRED_HOME=/usr/local/hadoop" >> /etc/profile
source /etc/profile
# 同步到 worker 节点
for node in worker01 worker02; do
ssh $node "echo 'export HADOOP_MAPRED_HOME=/usr/local/hadoop' >> /etc/profile && source /etc/profile"
done