目录
[API 后端架构](#API 后端架构)
[Web 前端架构](#Web 前端架构)
[RAG 知识体系](#RAG 知识体系)
[PostgreSQL 数据库](#PostgreSQL 数据库)
本文将全面介绍 Dify 的系统架构,阐述了主要组件如何协同工作以提供 LLM 应用程序开发平台。涵盖了高级架构、部署选项、核心子系统以及外部集成。
总体架构
Dify 采用基于微服务的架构,将前端 Web 应用程序与后端 API 服务分离。该系统旨在实现可扩展性,并可在各种环境中部署,包括自托管安装和云部署。
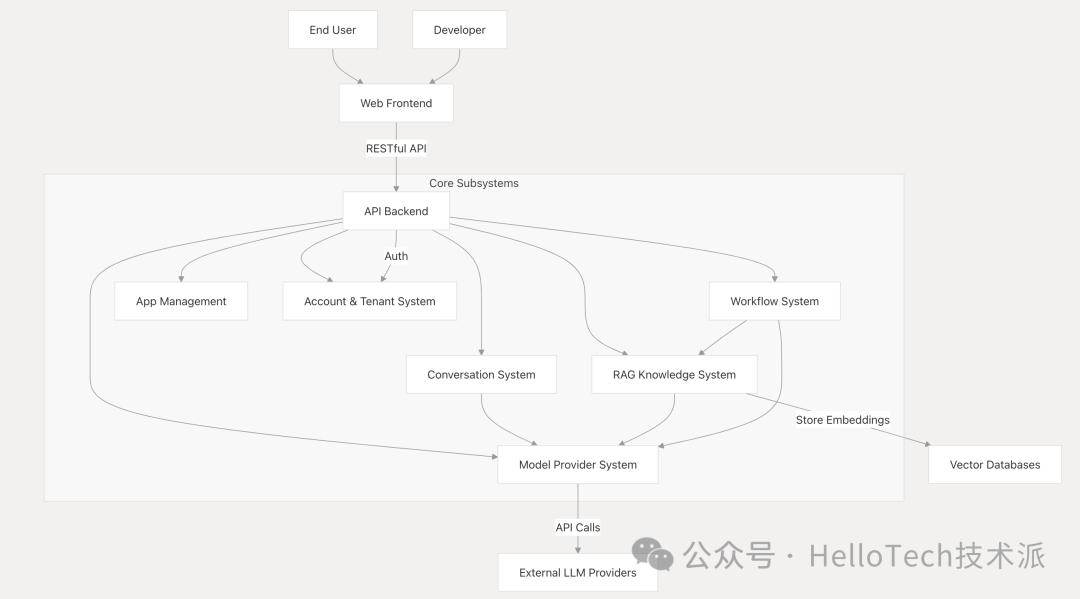
该架构包括:
-
Web 前端 :基于 Next.js 的 Web 应用程序,为创建应用程序的开发人员和与已部署应用程序交互的最终用户提供界面。
-
API 后端 :基于 Flask 的 API 服务器,处理来自前端的请求并协调核心子系统。
-
核心子系统 :
-
对话系统(Conversation System) :管理聊天和完成交互
-
RAG 知识系统 :处理文档、索引和检索
-
工作流系统 :支持创建复杂的AI工作流
-
模型提供商系统 :与各种 LLM 提供商集成
-
帐户和租户系统 :管理用户、工作区和身份验证
-
-
外部集成 :
-
LLM 提供商(OpenAI、Azure、Anthropic 等)
-
矢量数据库(Weaviate、Qdrant、Milvus 等)
-
关系数据库(PostgreSQL)
-
缓存系统(Redis)
-
部署架构
Dify 使用 Docker 进行容器化部署,方便在各种环境中部署。系统由多个可独立扩展的服务组成。
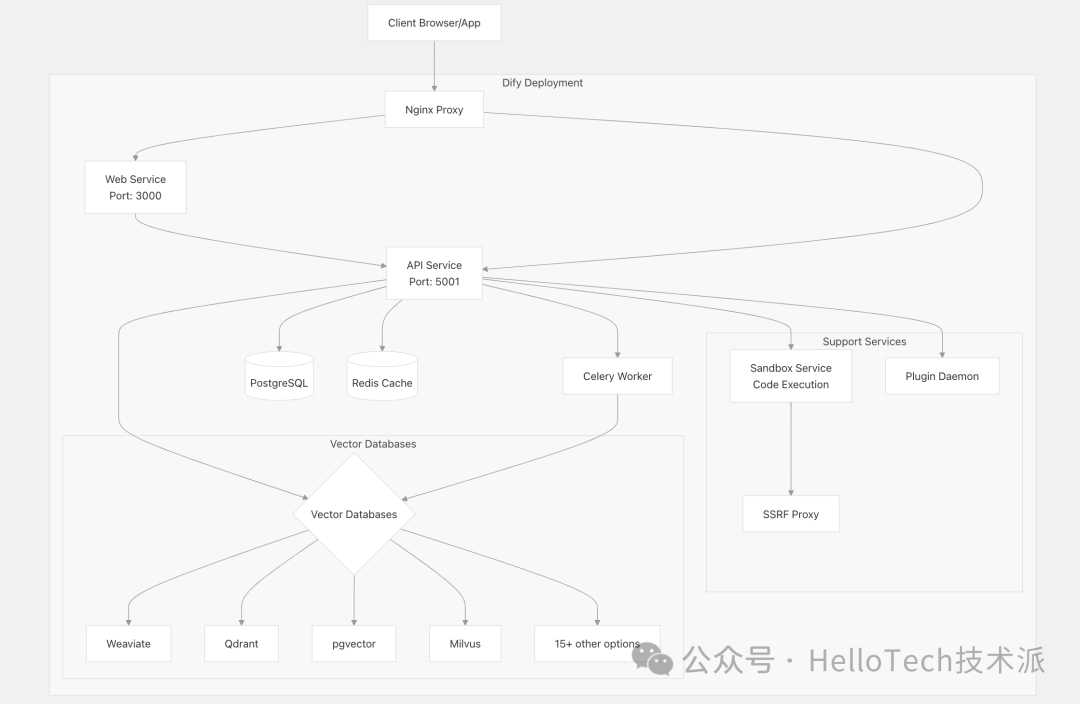
关键部署组件:
-
API 服务 :公开 REST API 端点的 Flask 应用程序。
-
端口:5001
-
使用
langgenius/dify-apiDocker 镜像进行容器化
-
-
Web 服务 :Next.js 前端应用程序。
-
端口:3000
-
使用
langgenius/dify-webDocker 镜像进行容器化
-
-
Worker Service :用于处理异步任务的Celery工作器。
-
与 API 服务相同的代码库,但以工作模式运行
-
处理文档处理和索引等任务
-
-
Support Services:
-
沙盒 :用于安全代码执行
-
插件守护进程(Plugin Daemon) :用于管理插件
-
SSRF 代理 :用于防止服务器端请求伪造攻击
-
-
数据库和缓存 :
-
PostgreSQL用于结构化数据
-
Redis 用于缓存和Celery任务队列
-
矢量数据库(可配置:Weaviate、Qdrant、Milvus 等)
-
-
Nginx :充当 Web 和 API 服务的反向代理
核心子系统
API 后端架构
API 后端使用 Flask 构建,并采用模块化设计模式。它为前端公开 REST 端点,并通过各种服务和控制器处理业务逻辑。
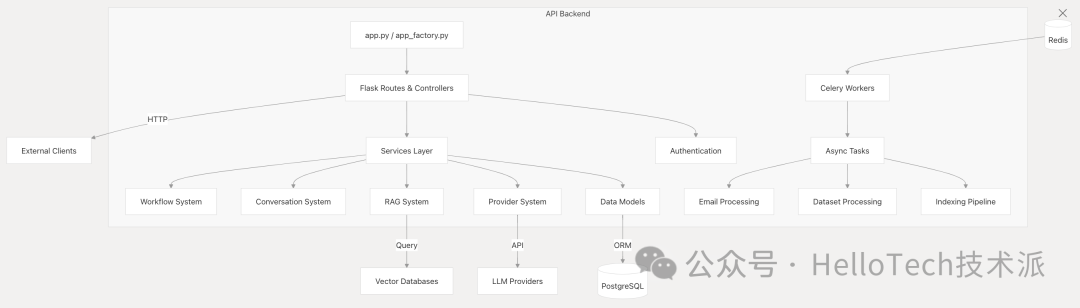
关键组件:
-
Entry Points:
-
app.py:主应用程序入口点 -
app_factory.py:用于创建 Flask 应用程序的工厂模式
-
-
控制器层(Controllers Layer) :按功能组织的 HTTP 请求处理程序
-
位于
api/controllers/ -
实现 REST API 端点
-
-
服务层(Services Layer) :业务逻辑实现
-
位于
api/services/ -
封装核心功能
-
-
数据模型 :SQLAlchemy ORM 模型
-
位于
api/models/ -
定义数据库模式和关系
-
-
异步处理 :
-
Celery workers 用于后台任务
-
处理资源密集型操作,如文档索引
-
Web 前端架构
Web 前端采用 Next.js 和 React 构建,为开发人员和最终用户提供现代、响应迅速的用户界面。
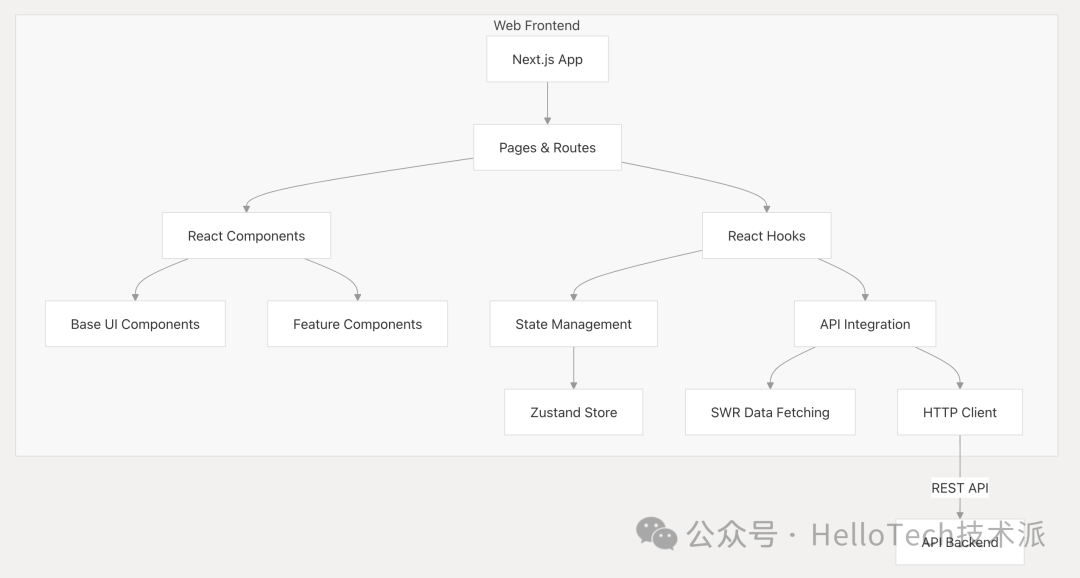
关键组件:
-
Next.js 应用程序 :服务器端渲染的 React 应用程序
-
位于
web/app/ -
实现开发人员和最终用户界面
-
-
组件库 :可重复使用的 UI 组件
-
基础组件(按钮、输入等)
-
复杂特征特定组件
-
-
状态管理 :主要使用 Zustand 进行状态管理
-
处理复杂的 UI 状态
-
管理应用程序数据
-
-
API 集成 :与后端 API 通信
-
使用 SWR 进行数据获取和缓存
-
I为不同的端点实现 API 客户端
-
RAG 知识体系
RAG(检索增强生成)知识系统负责处理文档、创建嵌入、将其存储在向量数据库中,并检索相关信息以进行 LLM 上下文增强。
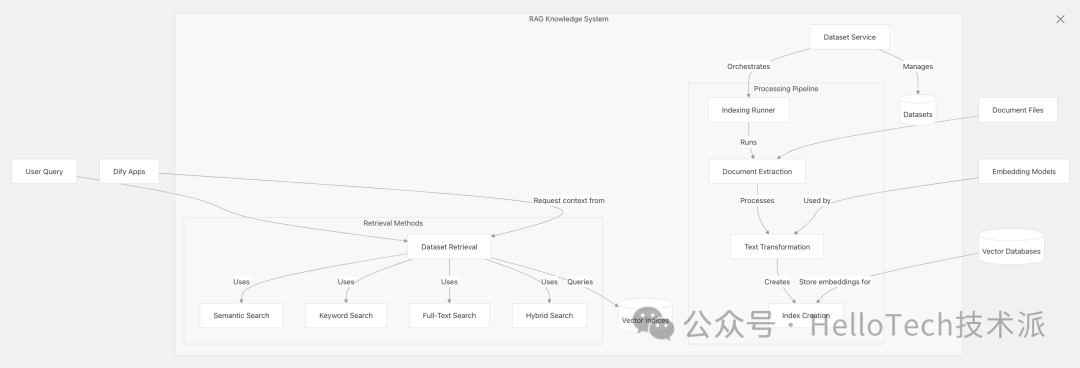
关键组件:
-
数据集服务 :管理文档数据集
-
创建并配置数据集
-
处理文档上传和处理
-
-
Indexing Runner :通过 ETL 管道处理文档
-
提取:从各种文档格式中获取文本
-
转换:对文本进行分块、清理和准备
-
加载:创建嵌入并存储在矢量数据库中
-
-
检索系统 :支持多种检索方式
-
使用向量嵌入进行语义搜索
-
关键词搜索
-
全文搜索
-
结合多种方法的混合方法
-
-
矢量存储工厂 :摘要矢量数据库实现
-
支持多种矢量数据库(Weaviate、Qdrant、Milvus 等)
-
提供创建和查询向量存储的统一接口
-
模型提供者系统
模型提供程序系统与各种 LLM 提供程序集成,并管理模型交互。它为不同类型的模型提供统一的接口,并安全地处理凭证。
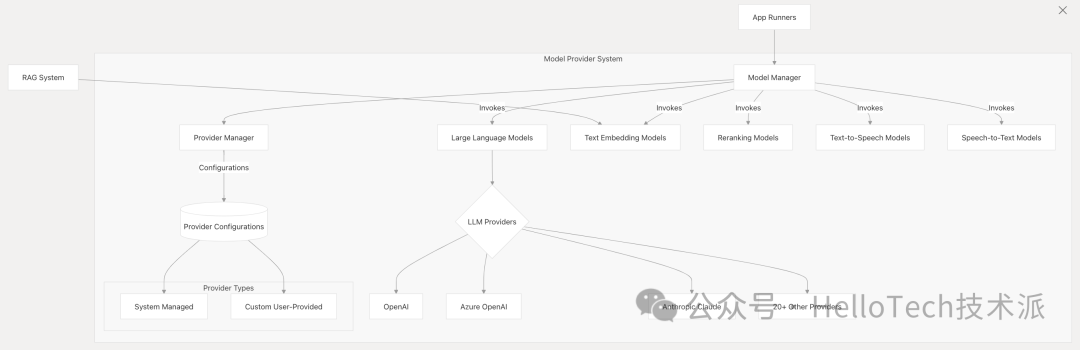
关键组件:
-
模型管理器 :模型交互的中央界面
-
支持不同的模型类型(LLM、嵌入、重新排序等)
-
处理模型选择和后备策略
-
-
提供商管理器 :管理提供商配置
-
安全地存储 API 密钥和端点
-
支持系统管理和用户提供的凭证
-
-
模型类型 :
-
大型语言模型(LLM):用于文本生成
-
文本嵌入模型:用于向量表示
-
重新排序模型:用于提高搜索相关性
-
文本转语音:用于音频生成
-
语音转文本:用于转录
-
-
提供商集成 :
-
支持 20 多家模型提供商
-
为所有提供商提供标准化接口
-
凭证管理和 API 密钥轮换
-
对话系统
对话系统管理用户与 LLM 之间的交互。它处理聊天记录、消息格式和上下文管理。
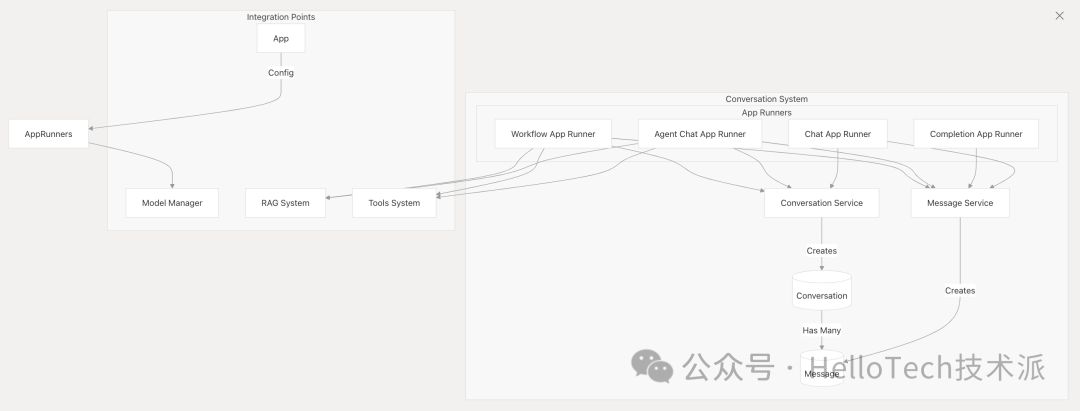
关键组件:
-
对话服务 :管理对话会话
-
创建和更新对话
-
维护对话状态和元数据
-
-
消息服务 :处理单个消息
-
处理用户输入
-
格式化模型响应
-
存储消息历史记录
-
-
App Runners:实现不同类型的应用程序
-
聊天(Chat):用于多轮对话
-
完成(Completion):适用于单回合互动
-
代理聊天(Agent Chat):用于使用工具的代理交互
-
工作流程(Workflow):适用于复杂的多步骤工作流程
-
-
Integration Points:
-
应用程序配置
-
用于文本生成的模型集成
-
RAG 用于知识检索
-
代理功能工具
-
工作流系统(WorkflowSystem)
工作流系统允许创建和执行复杂的 AI 工作流,将 LLM 交互与工具、分支逻辑和数据转换相结合。
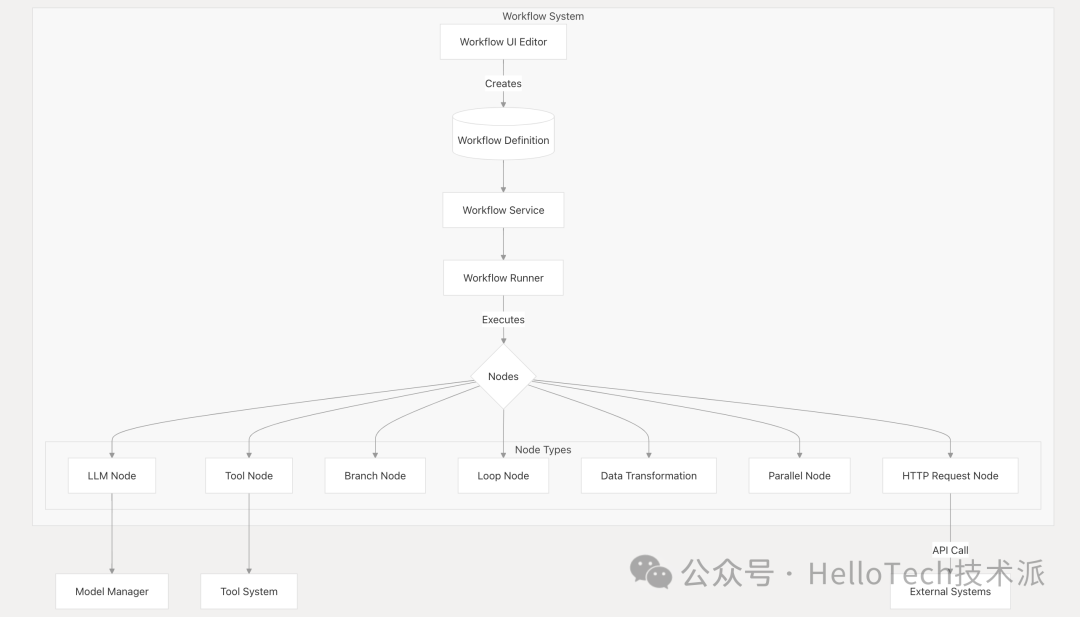
关键组件:
-
工作流编辑器 :用于创建和编辑工作流的用户界面
-
基于节点的可视化编辑
-
节点参数配置
-
测试和调试工作流程
-
-
工作流服务 :管理工作流定义
-
存储工作流配置
-
处理版本控制和发布
-
-
工作流运行器 :执行工作流
-
遍历工作流图
-
管理执行状态
-
处理错误恢复
-
-
节点类型 :
-
LLM:用于文本生成
-
工具:用于使用外部工具和插件
-
分支:用于条件逻辑
-
循环:用于迭代
-
数据转换:用于处理数据
-
并行:用于并发执行
-
HTTP:用于外部 API 调用
-
存储和数据库
Dify 使用多种存储系统来管理不同类型的数据。
PostgreSQL 数据库
PostgreSQL 是结构化数据的主要关系数据库。
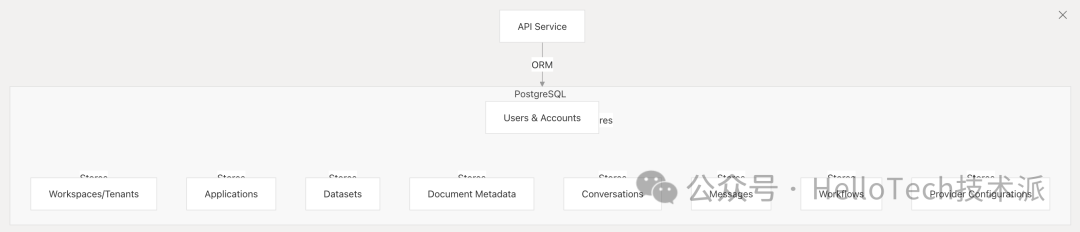
关键方面:
-
数据库配置 :
-
可配置的连接参数
-
连接池性能
-
支持 pgvector 扩展(可选)
-
-
关键表 :
-
Users and accounts 用户和帐户
-
Tenants (workspaces) 租户(工作区)
-
Applications 应用
-
Datasets and documents 数据集和文档
-
Conversations and messages 对话和消息
-
Workflows and nodes 工作流程和节点
-
Provider configurations 提供程序配置
-
Vector数据库
Dify 支持多种向量数据库选项,用于存储 RAG 系统中使用的嵌入。
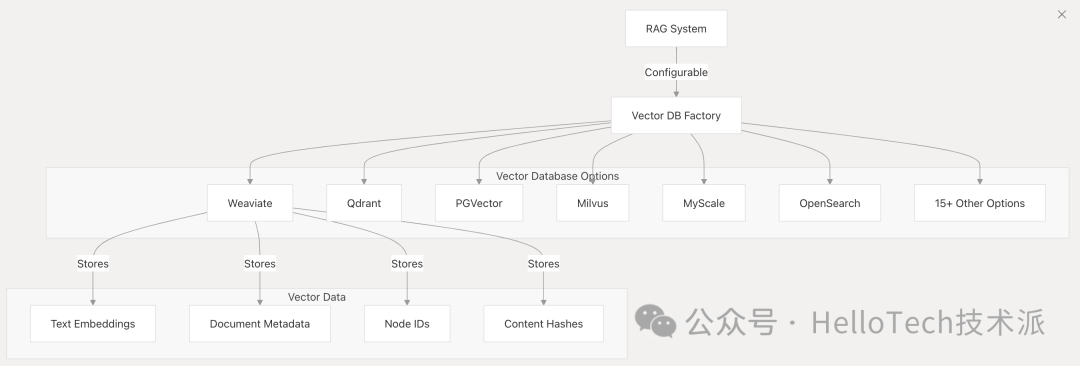
主要特点:
-
向量工厂抽象 :
-
不同向量数据库的统一接口
-
基于配置的动态实例化
-
支持运行时切换
-
-
支持的向量数据库 :
-
Weaviate (default)
-
Qdrant
-
PGVector(PostgreSQL 扩展)
-
Milvus
-
MyScale
-
OpenSearch
-
以及 15+ 个其他选项
-
-
向量数据存储 :
-
Text embeddings 文本嵌入
-
Document metadata 文档元数据
-
Node IDs for retrieval 用于检索的节点 ID
-
Content hashes for deduplication 用于重复数据删除的内容哈希
-
文件存储
Dify 使用可配置的存储系统进行文件上传和文档存储。
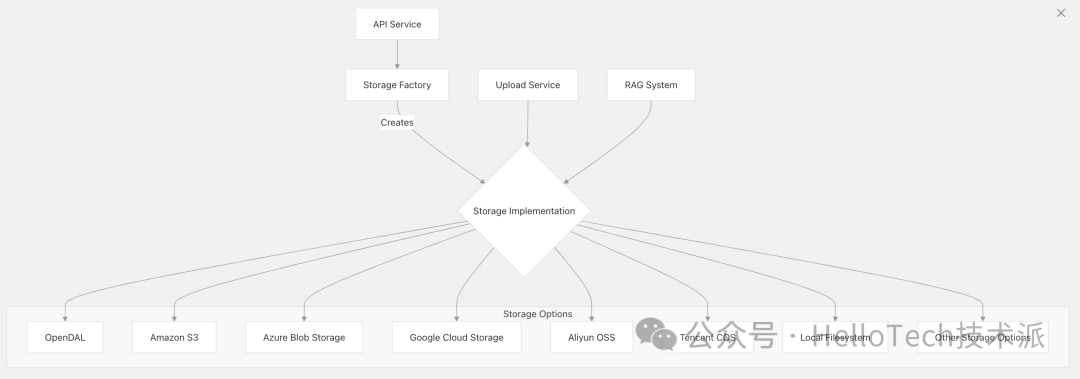
主要特点:
-
存储工厂模式 :
-
不同存储后端的抽象
-
统一的文件操作界面
-
运行时配置
-
-
支持的存储选项 :
-
OpenDAL(默认,支持多个后端)
-
Amazon S3
-
Azure Blob Storage
-
Google Cloud Storage
-
Aliyun OSS
-
Tencent COS
-
本地文件系统
-
许多其他提供商
-
-
用例 :
-
RAG 系统文件上传
-
用户文件附件
-
应用程序资产
-
系统配置
Dify 使用全面的配置系统,支持环境变量、配置文件和运行时设置。
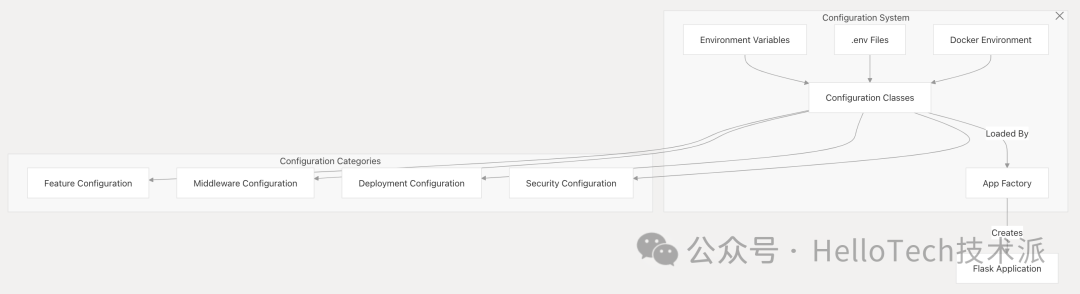
关键方面:
-
配置来源 :
-
环境变量
-
.env文件 -
Docker 环境变量
-
Command-line arguments 命令行参数
-
-
配置类别 :
-
功能配置:控制应用程序功能
-
中间件配置:数据库、缓存、存储设置
-
部署配置:运行时设置
-
安全配置:认证、加密等。
-
-
执行 :
-
使用 Pydantic 的配置类
-
类型验证和默认值
-
基于环境的动态加载
-
开发和部署流程
Dify 的开发和部署工作流程,如下图:
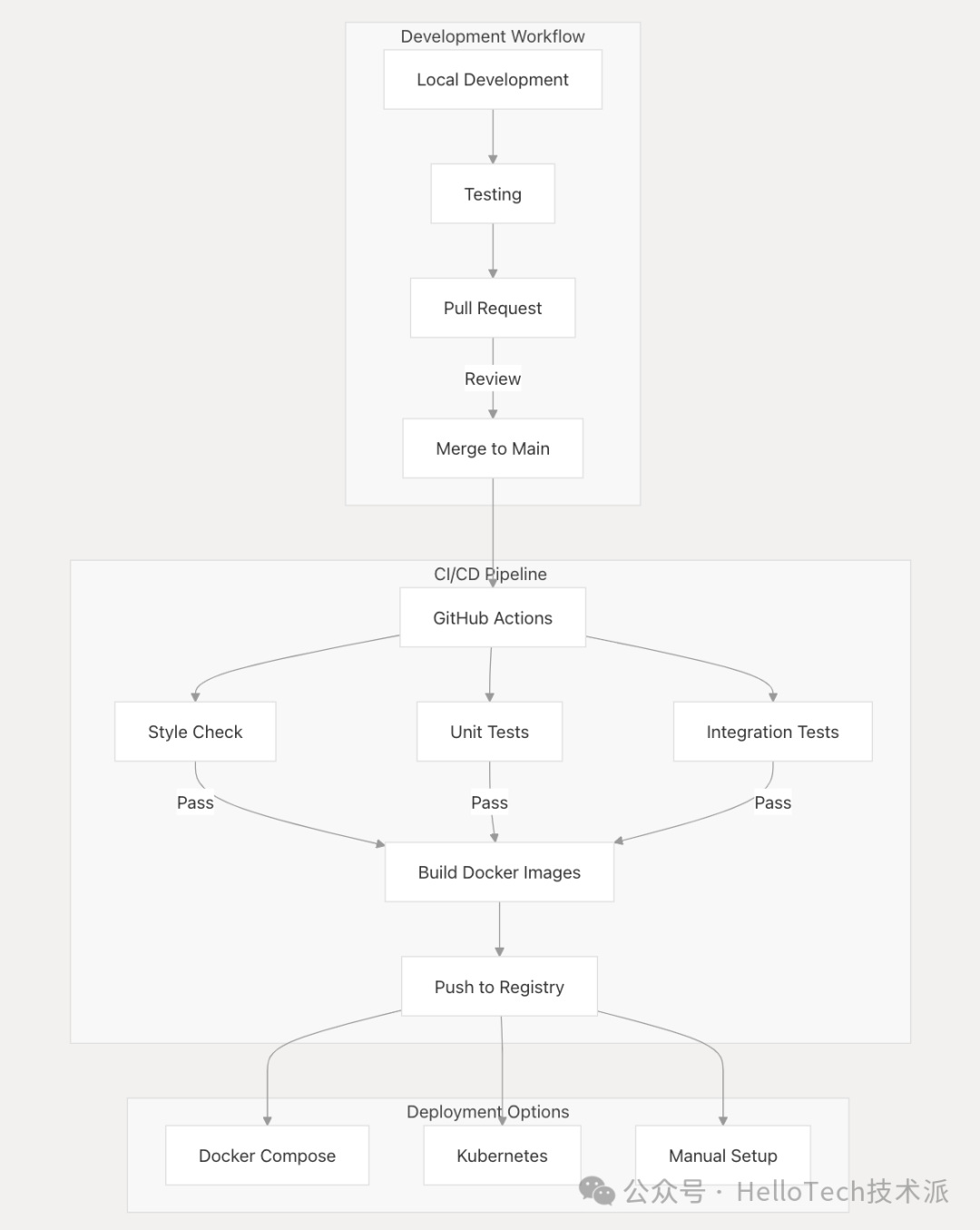
关键方面:
-
开发工作流程 :
-
使用 Docker Compose 进行本地开发
-
本地运行测试
-
带有代码审查的拉取请求流程
-
-
CI/CD Pipeline:
-
GitHub Actions 自动化
-
样式检查和 linting
-
单元和集成测试
-
构建和推送 Docker 镜像
-
-
部署选项 :
-
Docker Compose 部署(推荐)
-
Kubernetes 部署
-
手动设置和配置
-
参考资料