最近很多团队都在尝试把大模型接入到自己的业务里,但真正落地时会发现一个问题:直接和大模型聊天并不等于拥有一个可用的业务助手。
比如我们想让 AI 回答公司产品文档、接口说明、运维手册、售后 FAQ 里的问题,如果只是直接问通用大模型,它很可能并不知道这些内部资料。即使模型能回答,也可能出现信息过期、回答不稳定、甚至凭空补充内容的情况。
这类场景更适合用 RAG 知识库问答来解决:先把自己的文档上传到知识库,用户提问时先从知识库中检索相关内容,再把检索结果交给大模型生成回答。这样模型回答时就有了明确的上下文依据。
本文我会用 Dify 的「知识库 + 聊天机器人」模板,接入蓝耘 MaaS 模型服务,并在 LLM 节点中选择 GLM-5.1 作为知识库问答模型,从 0 搭建一个可以基于文档回答问题的企业知识库助手。

文章目录
-
- [一、为什么选择蓝耘 MaaS + Dify](#一、为什么选择蓝耘 MaaS + Dify)
- 二、准备工作
-
- [1. 蓝耘元生代账号](#1. 蓝耘元生代账号)
- [2. 蓝耘 MaaS API Key](#2. 蓝耘 MaaS API Key)
- [3. Dify 工作空间](#3. Dify 工作空间)
- [4. 测试知识库文档](#4. 测试知识库文档)
- [三、在 Dify 中接入蓝耘 MaaS 的 GLM-5.1 模型](#三、在 Dify 中接入蓝耘 MaaS 的 GLM-5.1 模型)
-
- [1. 打开模型供应商设置](#1. 打开模型供应商设置)
- [2. 选择 OpenAI-API-compatible 兼容供应商](#2. 选择 OpenAI-API-compatible 兼容供应商)
- [3. 添加 GLM-5.1 模型并填写蓝耘 MaaS 配置信息](#3. 添加 GLM-5.1 模型并填写蓝耘 MaaS 配置信息)
- [4. 保存模型](#4. 保存模型)
- 四、创建知识库并导入企业互联网业务文档
-
- [1. 新建知识库](#1. 新建知识库)
- [2. 上传测试文档](#2. 上传测试文档)
- [3. 配置分段策略](#3. 配置分段策略)
- [4. 配置索引和检索方式](#4. 配置索引和检索方式)
- [5. 等待索引完成](#5. 等待索引完成)
- [五、选择「知识库 + 聊天机器人」模板创建应用](#五、选择「知识库 + 聊天机器人」模板创建应用)
-
- [1. 从模板创建应用](#1. 从模板创建应用)
- [2. 查看模板工作流](#2. 查看模板工作流)
- 六、配置知识检索节点
-
- [1. 选择知识库](#1. 选择知识库)
- [2. 设置查询变量](#2. 设置查询变量)
- [3. 调整检索参数](#3. 调整检索参数)
- [七、配置 LLM 节点并选择蓝耘 MaaS 模型](#七、配置 LLM 节点并选择蓝耘 MaaS 模型)
-
- [1. 选择 GLM-5.1 模型](#1. 选择 GLM-5.1 模型)
- [2. 配置上下文](#2. 配置上下文)
- [3. 编写系统提示词](#3. 编写系统提示词)
- [4. 设置模型参数](#4. 设置模型参数)
- 八、运行预览并测试问答效果
-
- [测试 1:基础命中问题](#测试 1:基础命中问题)
- [测试 2:流程型问题](#测试 2:流程型问题)
- [测试 3:知识库外问题](#测试 3:知识库外问题)
- 测试记录表
- 九、优化知识库助手的几个实用方法
-
- [1. 优化文档结构](#1. 优化文档结构)
- [2. 调整分段](#2. 调整分段)
- [3. 降低模型随机性](#3. 降低模型随机性)
- [4. 强化 Prompt 约束](#4. 强化 Prompt 约束)
- [5. 保留引用来源](#5. 保留引用来源)
- [6. 复杂场景再使用问题分类模板](#6. 复杂场景再使用问题分类模板)
- 十、常见问题排查
-
- [1. Dify 中保存模型失败](#1. Dify 中保存模型失败)
- [2. 模型能调用,但知识库没有召回内容](#2. 模型能调用,但知识库没有召回内容)
- [3. 回答和知识库内容不一致](#3. 回答和知识库内容不一致)
- [4. 知识库外问题仍然被模型回答](#4. 知识库外问题仍然被模型回答)
- [十一、蓝耘 MaaS 在这个场景里的价值](#十一、蓝耘 MaaS 在这个场景里的价值)
- 总结
一、为什么选择蓝耘 MaaS + Dify
在这个方案里,Dify 和蓝耘 MaaS 承担的角色并不一样。
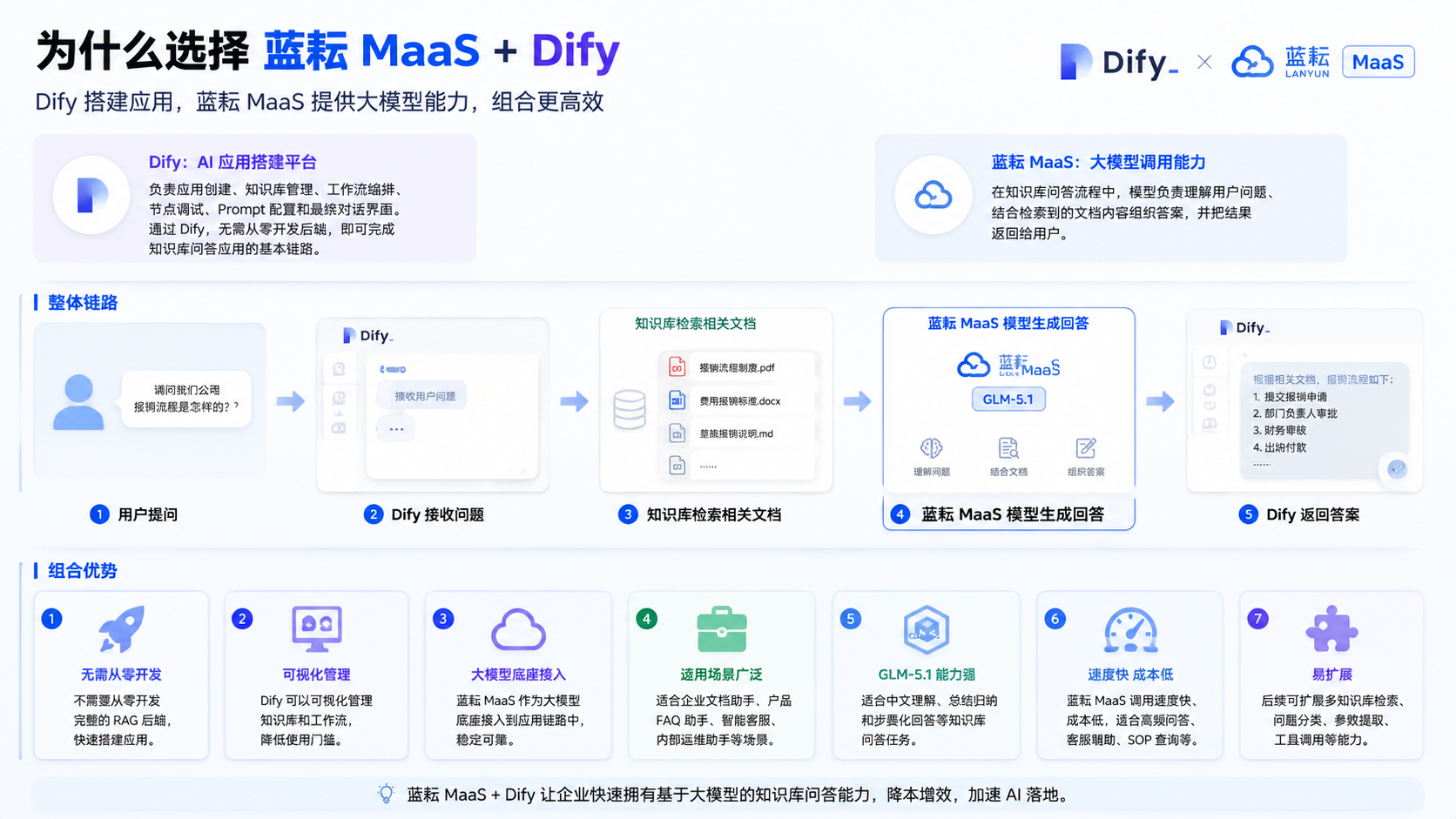
Dify 更像是 AI 应用搭建平台。它负责应用创建、知识库管理、工作流编排、节点调试、Prompt 配置和最终对话界面。通过 Dify,我们可以不用从零写后端,就完成一个知识库问答应用的基本链路。
蓝耘 MaaS 则提供大模型调用能力。在知识库问答流程中,模型主要负责理解用户问题、结合检索到的文档内容组织答案,并把结果返回给用户。
两者结合以后,整体链路可以理解为:
text
用户提问 -> Dify 接收问题 -> 知识库检索相关文档 -> 蓝耘 MaaS 模型生成回答 -> Dify 返回答案这套组合的优势是比较清晰的:
- 不需要从零开发完整的 RAG 后端。
- Dify 可以可视化管理知识库和工作流。
- 蓝耘 MaaS 可以作为大模型底座接入到应用链路中。
- 适合快速验证企业文档助手、产品 FAQ 助手、智能客服、内部运维助手等场景。
- GLM-5.1 适合承担知识库问答中的中文理解、总结归纳和步骤化回答任务。
- 蓝耘 MaaS 调用速度快、成本低,适合企业内部高频问答、客服辅助、运营 SOP 查询等场景。
- 后续可以继续扩展多知识库检索、问题分类、参数提取、工具调用等能力。
二、准备工作
正式开始前,需要准备以下内容。
1. 蓝耘元生代账号
首先需要有蓝耘元生代账号,并进入蓝耘 MaaS 相关控制台。本文会用蓝耘 MaaS 提供的 API Key 和模型服务接入 Dify
2. 蓝耘 MaaS API Key
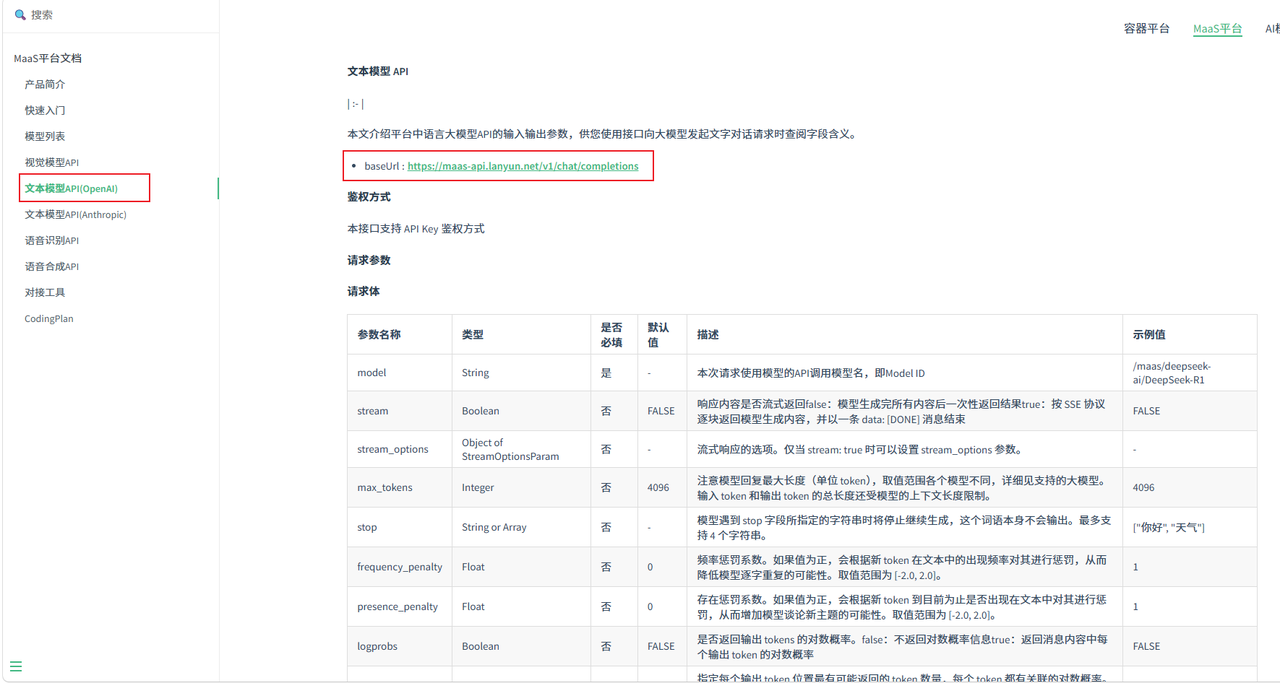
进入蓝耘 MaaS 控制台后,
在左侧导航栏找到 API管理 / 密钥管理 ,点击"创建 API Key"。
💡 注意 :复制并保存好生成的
sk-xxxxxxxxxxxxxxxx
进入蓝耘的【模型广场】,挑选你想要使用的模型并记录下确切的名称。这里强烈推荐处理复杂逻辑极佳的: glm-5.1
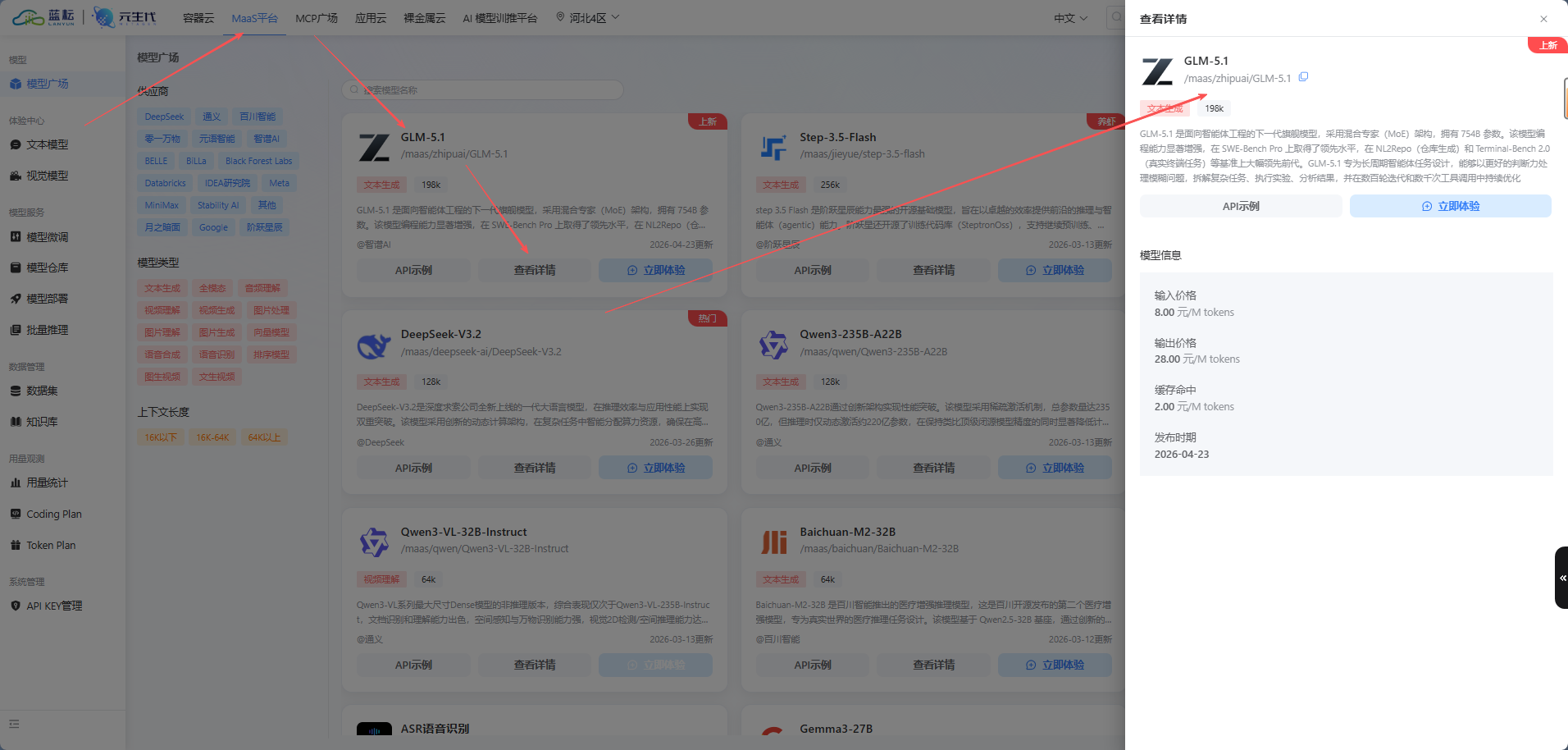
- 点击查看详情,你可以看到该模型在蓝耘平台的唯一调用名称为:
/maas/zhipuai/GLM-5.1。记下这串字符。
记录通用 Base URL:
- 接口地址固定为:
https://maas-api.lanyun.net/v1
3. Dify 工作空间
Dify 可以使用云端版,也可以使用本地部署版。本文重点演示操作链路,所以不展开 Dify 的安装部署过程。
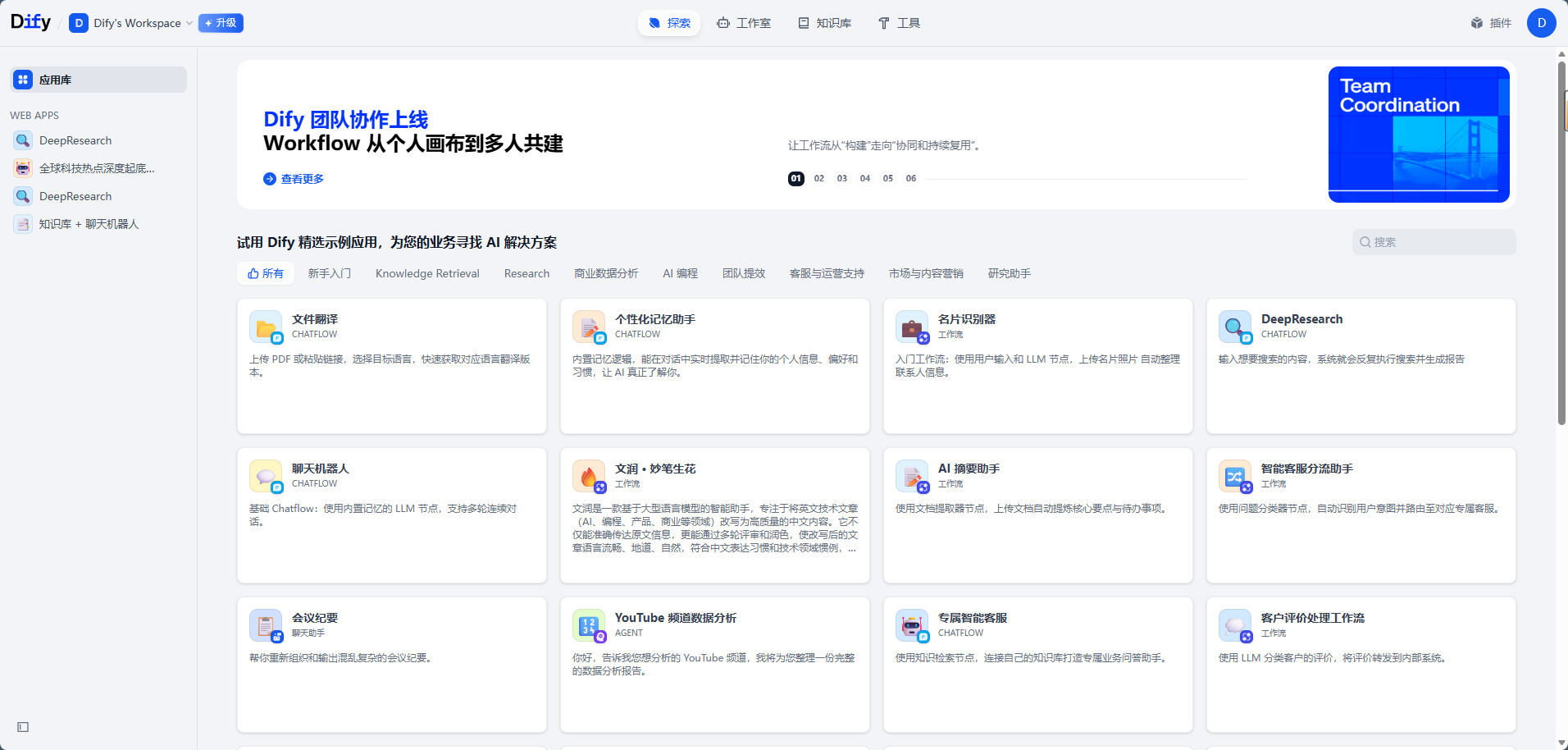
如果你已经有 Dify 工作空间,直接登录即可。如果是本地部署,需要确认 Dify 能正常访问,并且模型供应商配置、知识库、应用创建功能都可用。
4. 测试知识库文档
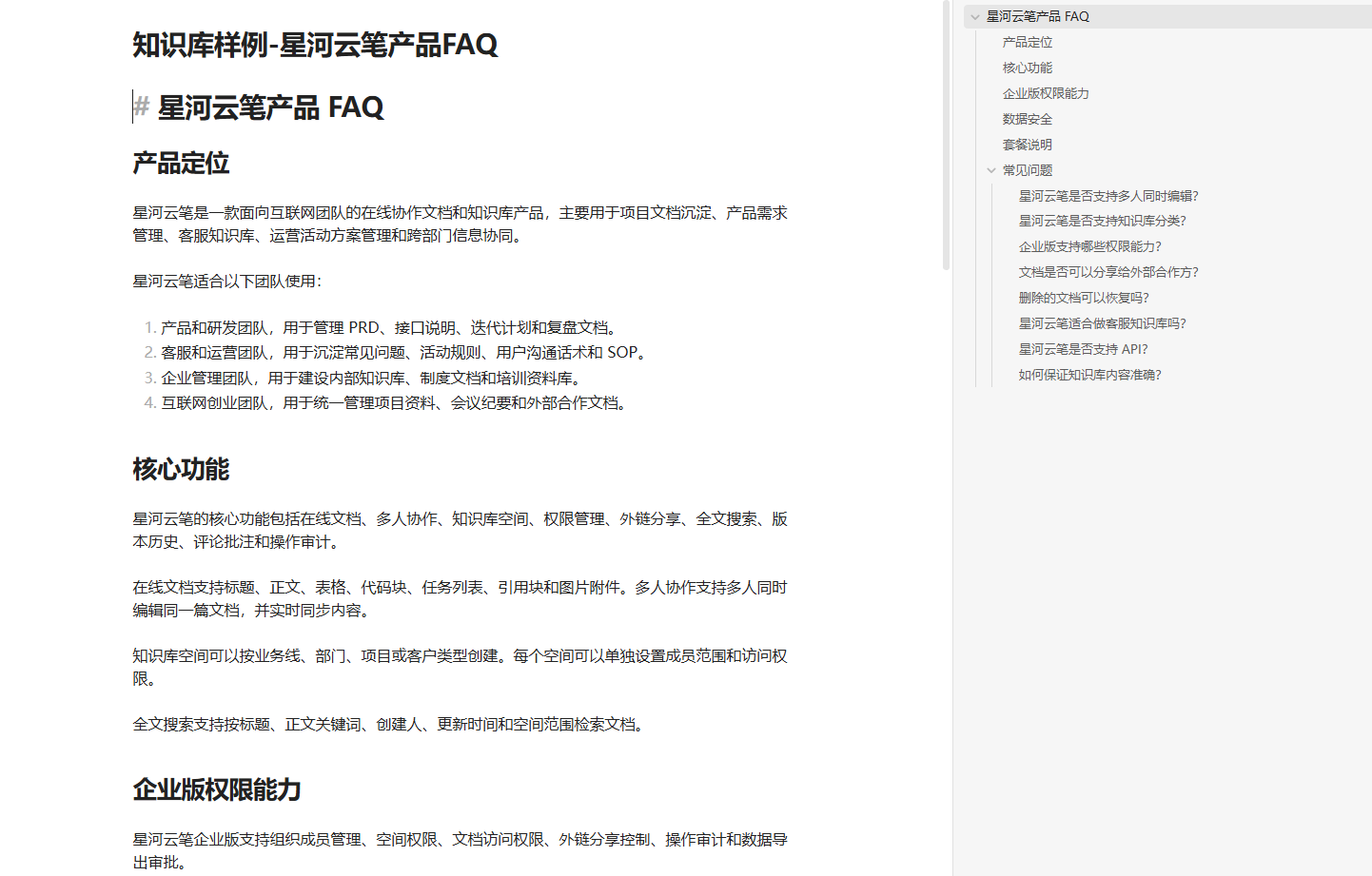
建议准备知识库测试文档
比如:
- 产品 FAQ 文档。
- API 接入说明。
- 运维操作手册。
- 项目 README。
- 企业内部制度说明。
如果只是演示,可以先准备一份 Markdown 文档,例如:
markdown
# 蓝耘 MaaS 接入 FAQ
## 如何获取 API Key?
登录蓝耘元生代控制台,进入 MaaS 服务相关页面,在 API Key 管理区域创建或复制 Key。
## 接入第三方工具时需要哪些参数?
通常需要 API Key、API endpoint URL 和模型名称。具体字段名称以第三方工具的模型供应商配置页面为准。
## 为什么不建议在截图中展示完整 API Key?
API Key 具有调用权限,公开后可能带来安全风险,因此在文章、视频和截图中都应打码处理。我这里先用了两份虚拟的文档做测试
三、在 Dify 中接入蓝耘 MaaS 的 GLM-5.1 模型
接下来先把蓝耘 MaaS 的模型接入 Dify。只有模型配置成功,后面的知识库问答应用才能正常生成回答。
由于 Dify 版本会持续更新,不同版本的菜单名称可能略有差异,但整体思路基本一致:进入模型供应商设置,添加 OpenAI-API-compatible 兼容模型服务,然后填入 API Key、API endpoint URL 和模型名称。
1. 打开模型供应商设置
登录 Dify 后,进入工作空间,点击右上角头像或工作空间设置入口,找到「模型供应商」相关菜单。
2. 选择 OpenAI-API-compatible 兼容供应商
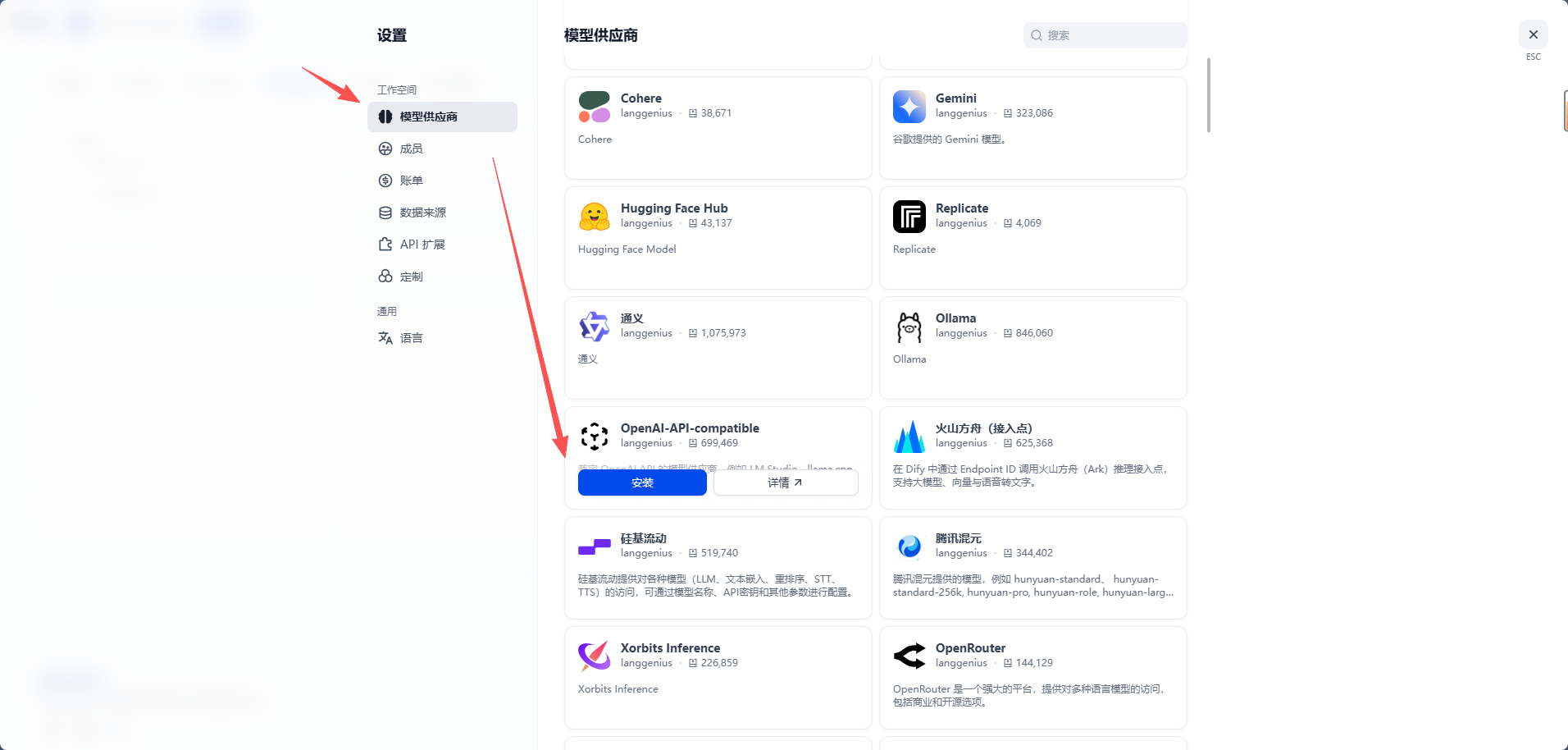
在模型供应商页面中,查找「OpenAI-API-compatible」或类似的兼容模型配置入口。
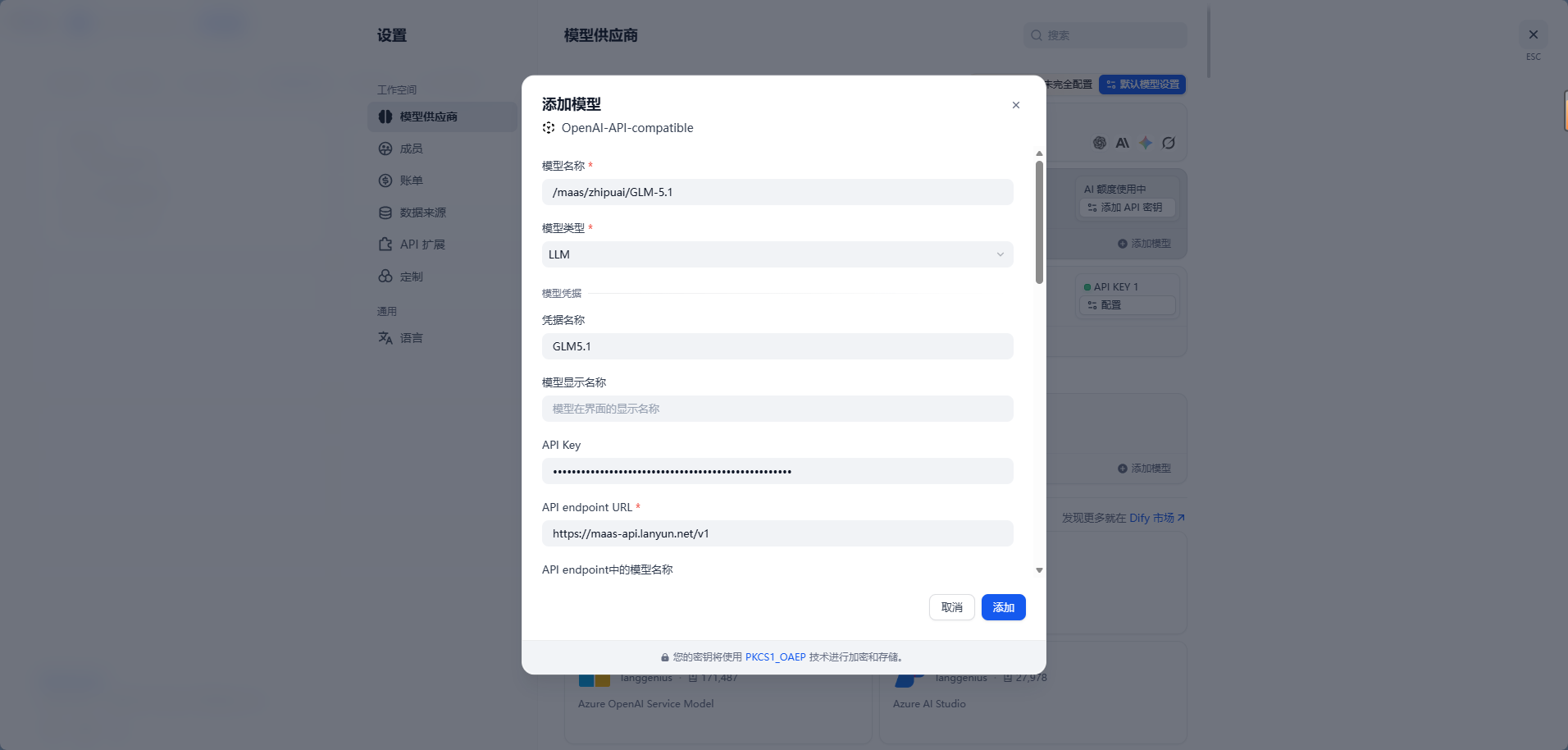
3. 添加 GLM-5.1 模型并填写蓝耘 MaaS 配置信息
进入配置页面后,通常需要填写以下内容:
| 配置项 | 填写内容 |
|---|---|
| API Key | 蓝耘 MaaS 控制台中创建的 API Key |
| API endpoint URL | 蓝耘 MaaS 控制台提供的接口地址, https://maas-api.lanyun.net/v1 |
| 模型类型 | LLM |
| 模型名称 | 蓝耘控制台中 GLM-5.1 对应的完整调用名称/maas/zhipuai/GLM-5.1 |
| 显示名称 | GLM-5.1,便于后续在 Dify 的 LLM 节点中选择 |
 |
4. 保存模型
配置完成后,点击保存。
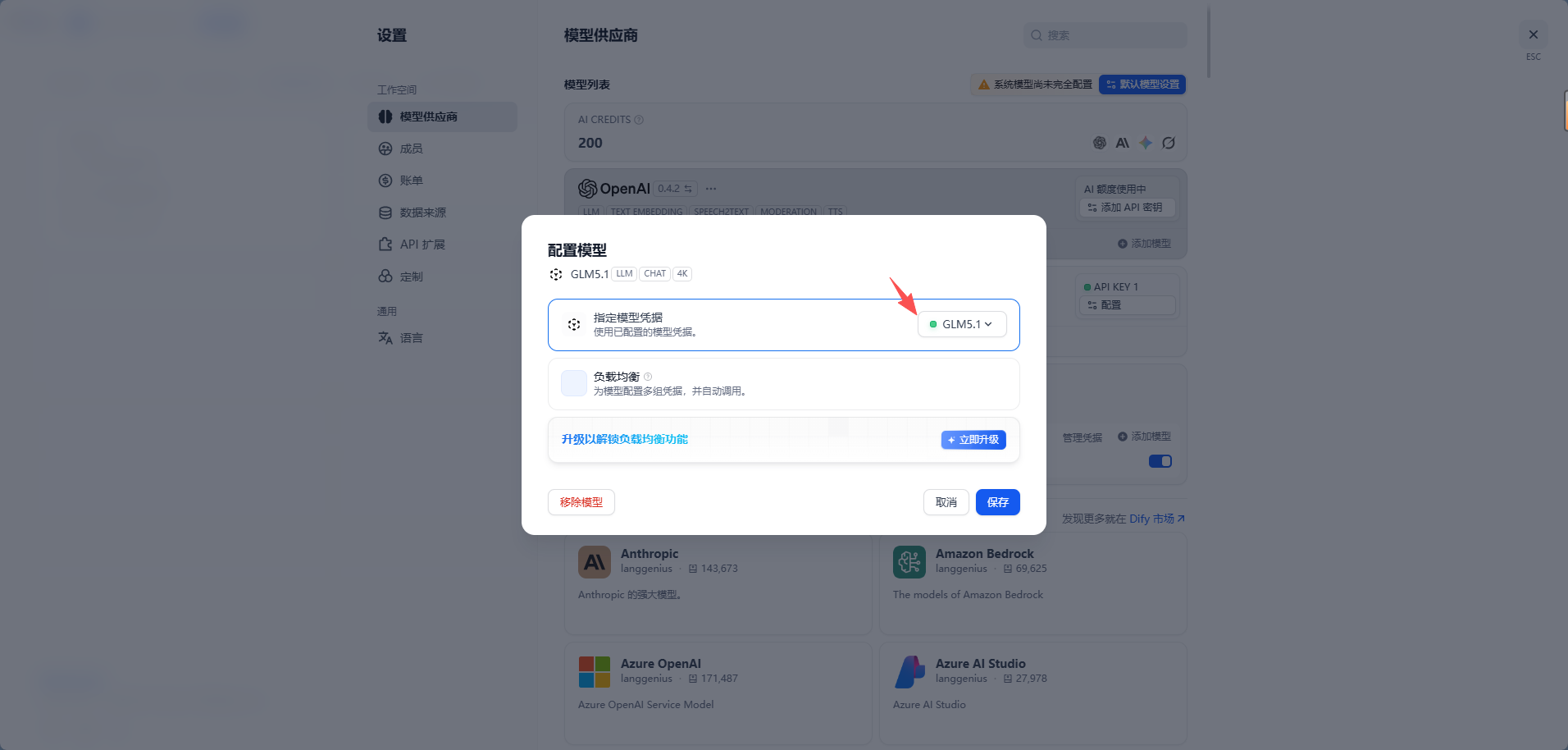
如果显示绿色标识就表示模型已可用
四、创建知识库并导入企业互联网业务文档
模型接入完成后,下一步创建知识库。知识库的作用是保存我们自己的文档,并在用户提问时检索相关片段。
Dify 官方文档中也提到,知识库可以把内部公司文档、FAQ、标准操作指南等内容处理为结构化数据,供大模型查询和使用。它的核心价值是让模型不只依赖预训练知识,而是结合我们上传的实时文档回答问题。
1. 新建知识库
在 Dify 左侧菜单中找到「知识库」或「Knowledge」,点击创建知识库。
知识库名称可以写得具体一些,例如:
text
星河云笔企业知识库名称越清楚,后面在应用中绑定知识库时越不容易选错。
2. 上传测试文档
进入知识库创建流程后,上传刚才准备好的测试文档。
Dify 支持多种文本内容来源,常见的本地文件包括 TXT、Markdown、DOCX、HTML、PDF 等,也支持部分结构化数据和在线数据源。具体支持范围以当前 Dify 版本页面为准。
本文建议优先使用 Markdown 或 DOCX,因为这两类文档更适合保留标题层级和段落结构,后面做分段预览时也更容易观察效果。
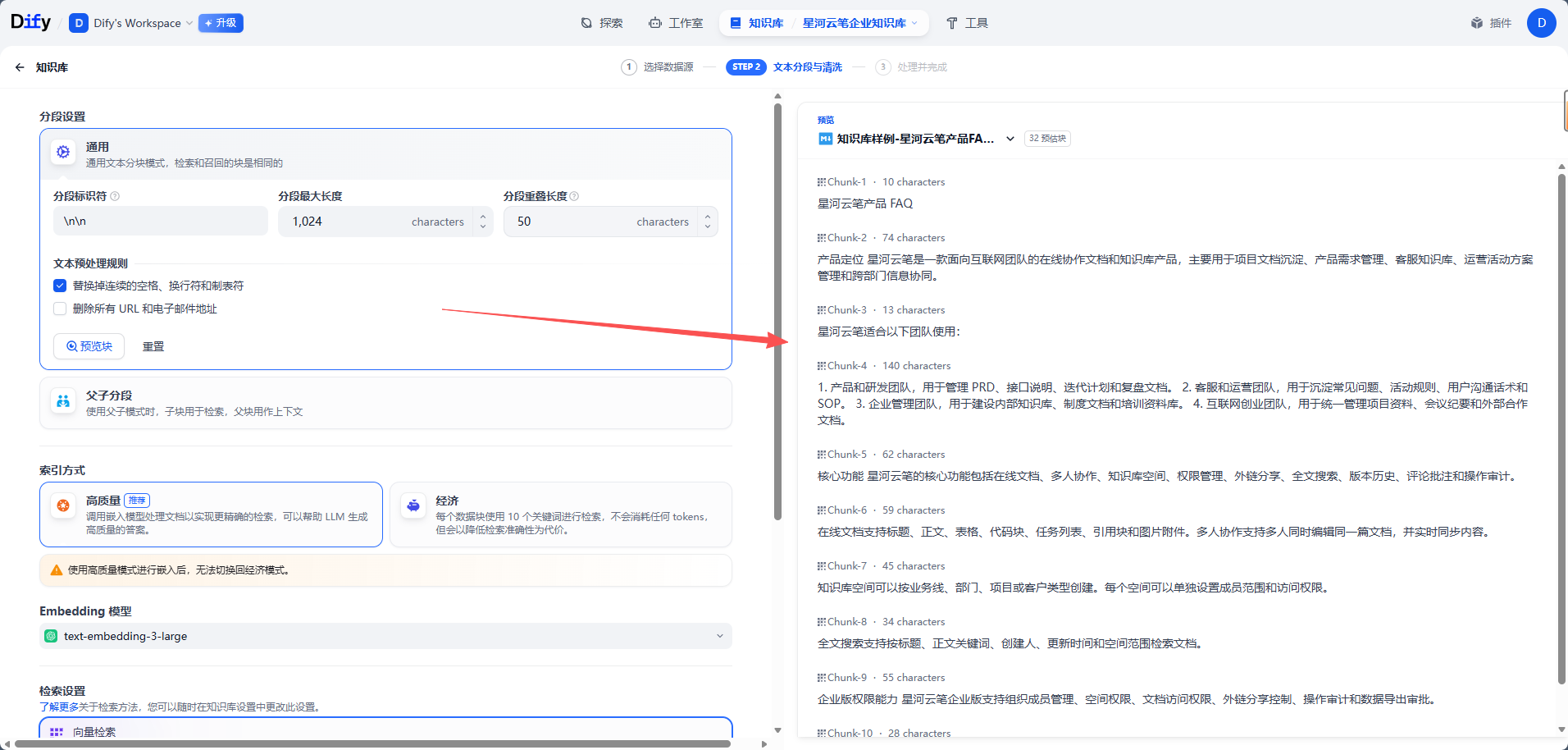
3. 配置分段策略
上传文档后,Dify 会进入文本处理和分段配置流程。分段的质量会直接影响后面的检索效果。
如果分段太长,一个片段里混入了太多信息,模型可能会拿到无关内容。如果分段太短,单个片段又可能缺少上下文,导致回答不完整。
我的建议是:
- FAQ 类文档可以按「问题 + 答案」组织,每个问题尽量形成一个独立片段。
- 接口文档可以按「接口说明 + 参数表 + 示例 + 错误码」组织。
- 操作手册可以按步骤分段,每段保留完整操作链路。
- 标题要清晰,不要把多个主题混在同一个段落里。
在 Dify 的分段预览页,可以检查切分后的片段是否自然。如果一个片段看起来已经能独立回答一个问题,通常就是比较理想的状态。
4. 配置索引和检索方式
接着配置索引方式和检索方式。不同 Dify 版本的配置项可能有所差异,常见配置包括索引方式、检索模式、Top K、Score Threshold、Rerank 等。
对于第一版知识库助手,建议先使用默认或推荐配置,确保链路跑通。后面如果发现召回不准,再逐步调整。
几个参数可以这样理解:
- Top K:返回最相关的前几个片段。
- Score Threshold:相似度低于阈值的片段不返回。
- Rerank:对初步召回结果重新排序,提高相关性。
如果文档规模不大,先用默认配置通常就能完成演示。如果文档很多、问题类型复杂,再考虑提高检索精度。
5. 等待索引完成
配置完成后,等待 Dify 处理文档。处理完成后,可以进入知识库详情页查看文档状态。
如果状态显示完成,说明文档已经被处理为可检索内容。此时可以打开文档片段,检查是否有乱码、分段异常或标题丢失。
其次,免费版因为单次只能处理一个文档 所以需要分两次上传文件
本文准备了两份可直接上传的企业互联网业务样例文档:
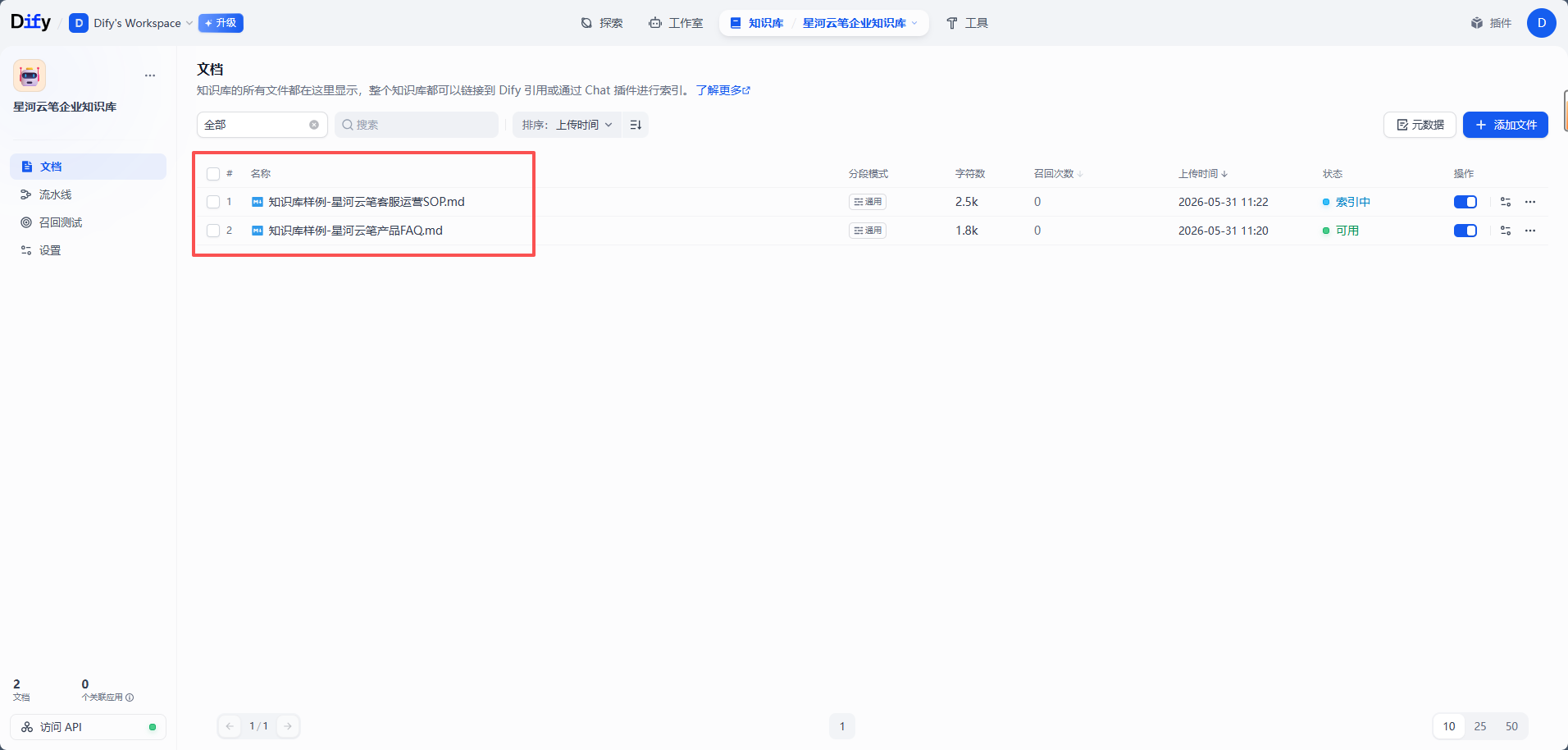
知识库样例-星河云笔产品FAQ.md知识库样例-星河云笔客服运营SOP.md
这个虚拟业务叫「星河云笔」,定位为面向互联网团队的在线协作文档和知识库产品。第一份文档适合测试产品功能、套餐、权限、数据安全等问答;第二份文档适合测试客服流程、故障排查、工单升级和运营活动规则问答。
五、选择「知识库 + 聊天机器人」模板创建应用
完成知识库后,就可以创建应用了。
Dify 在应用模板里提供了多个知识库相关模板。
1. 从模板创建应用
在 Dify 工作台点击「创建应用」,选择「从应用模板创建」。
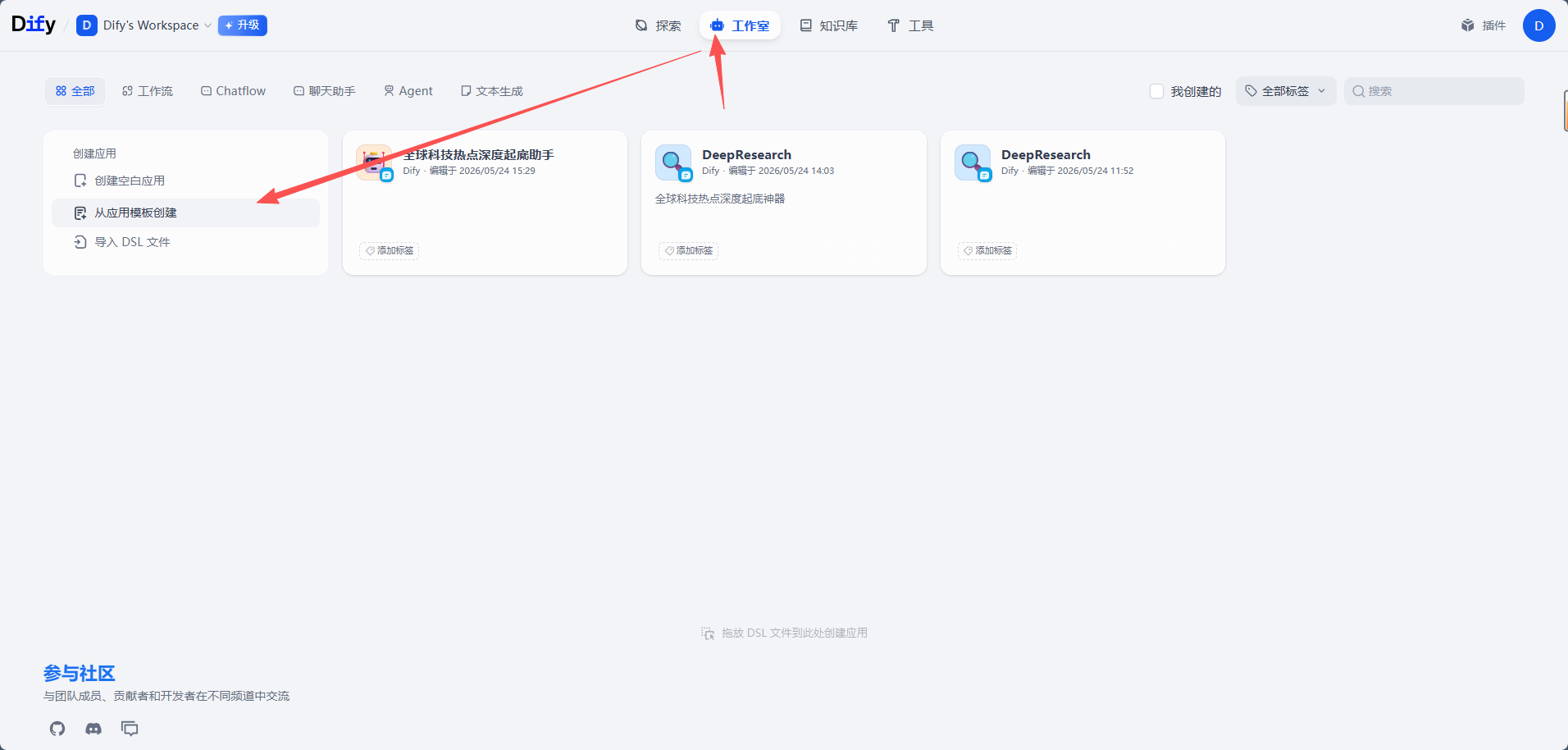
搜索关键词:
text
知识库这里选择第二个,也就是「知识库 + 聊天机器人」。
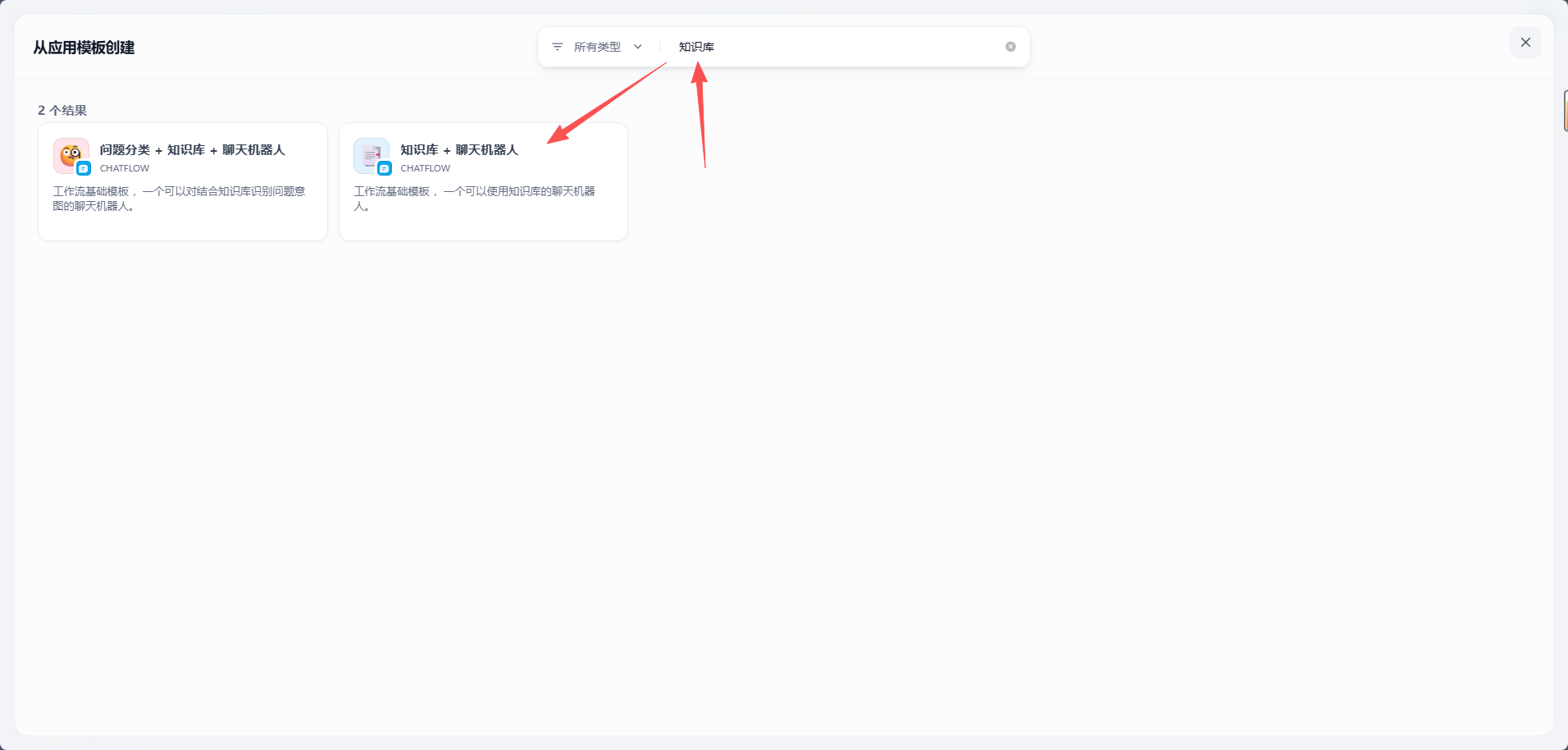
原因很简单:它的流程更直接,主链路是用户提问、知识检索、LLM 生成、直接回复,刚好覆盖知识库问答的核心能力。
找到「知识库 + 聊天机器人」模板,点击进入详情页,然后选择「从此模板创建应用」。
2. 查看模板工作流
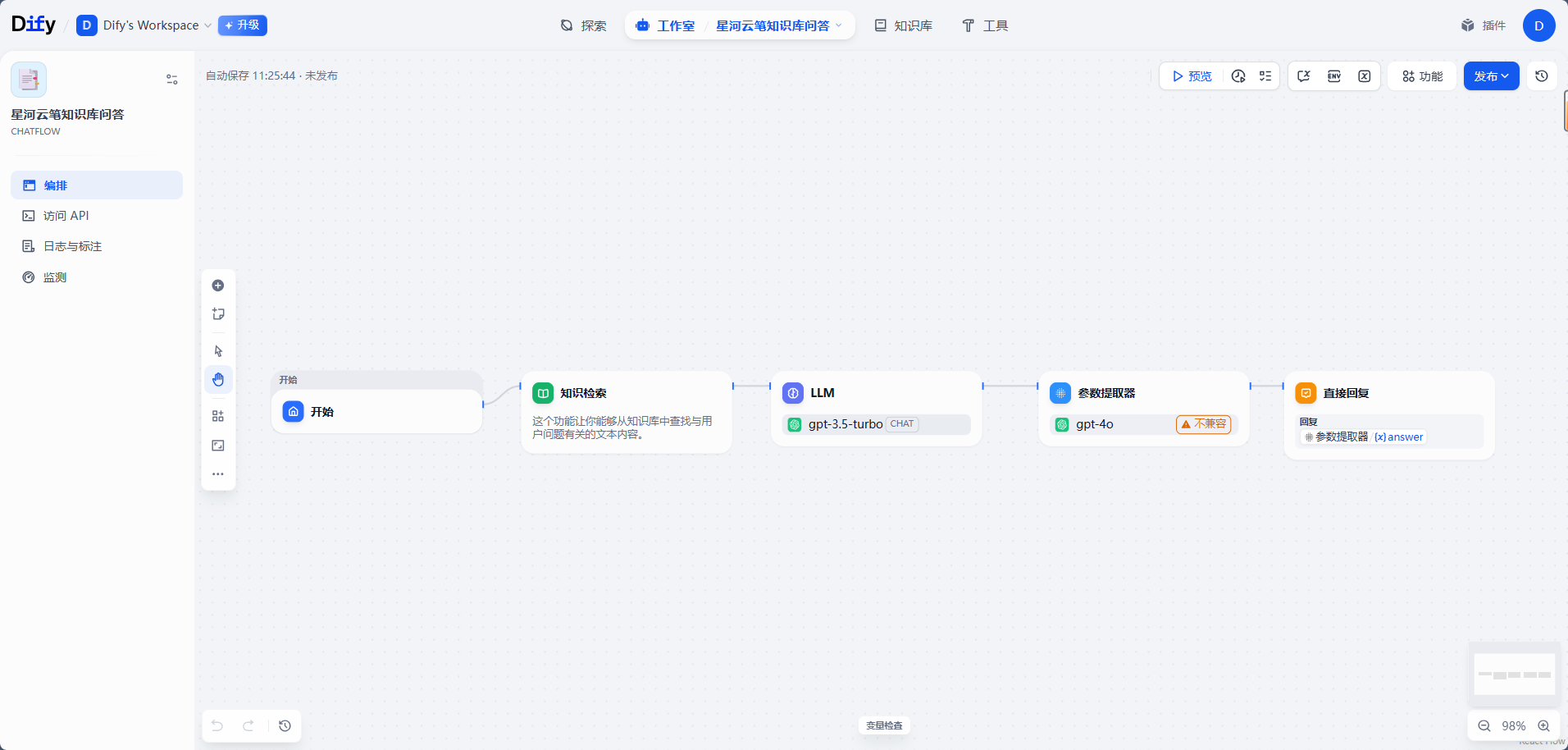
进入模板详情后,可以看到这个模板的大致流程:
text
开始 -> 知识检索 -> LLM -> 参数提取器 -> 直接回复其中核心节点是「知识检索」和「LLM」。
知识检索节点负责从知识库里查找和用户问题相关的内容。Dify 官方文档中说明,知识检索节点会把检索结果作为上下文传给下游节点,例如 LLM 节点。
LLM 节点负责根据用户问题和检索到的上下文生成回答。
直接回复节点负责把最终答案返回给用户。
至于参数提取器,在一些应用里可以用来提取结构化字段。对于简单知识库问答来说,可以先保留模板默认配置。如果实际调试中发现暂时用不上,也可以后续简化流程,但第一版建议先不要急着删除节点,避免影响模板原有链路。
六、配置知识检索节点
应用创建完成后,进入应用编排页面,先配置知识检索节点。
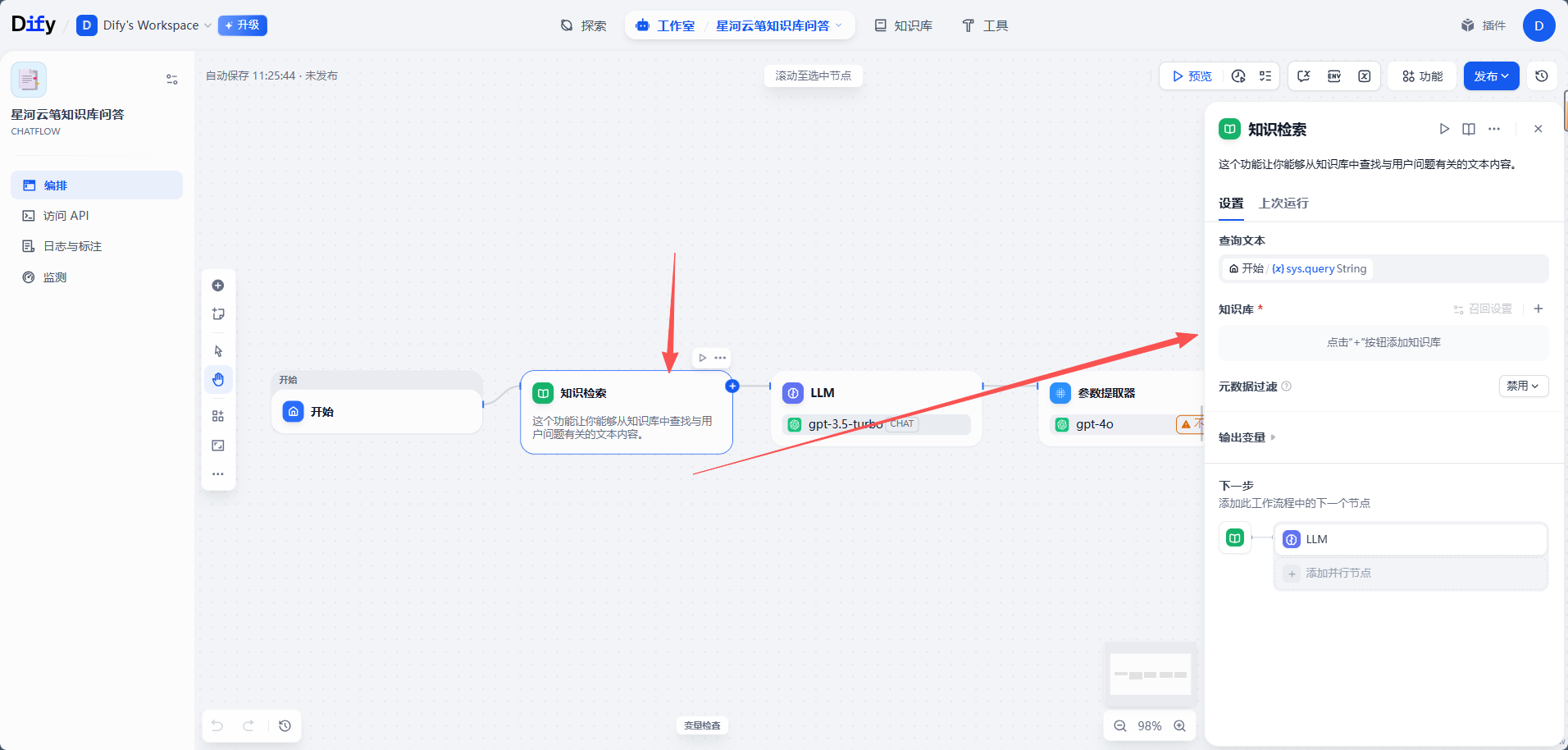
1. 选择知识库
点击「知识检索」节点,在右侧配置面板中选择刚才创建的知识库,例如:
text
星河云笔企业知识库如果有多个知识库,建议只选择和当前应用强相关的知识库。第一版不要一次绑定太多知识库,否则不方便判断回答到底来自哪里。
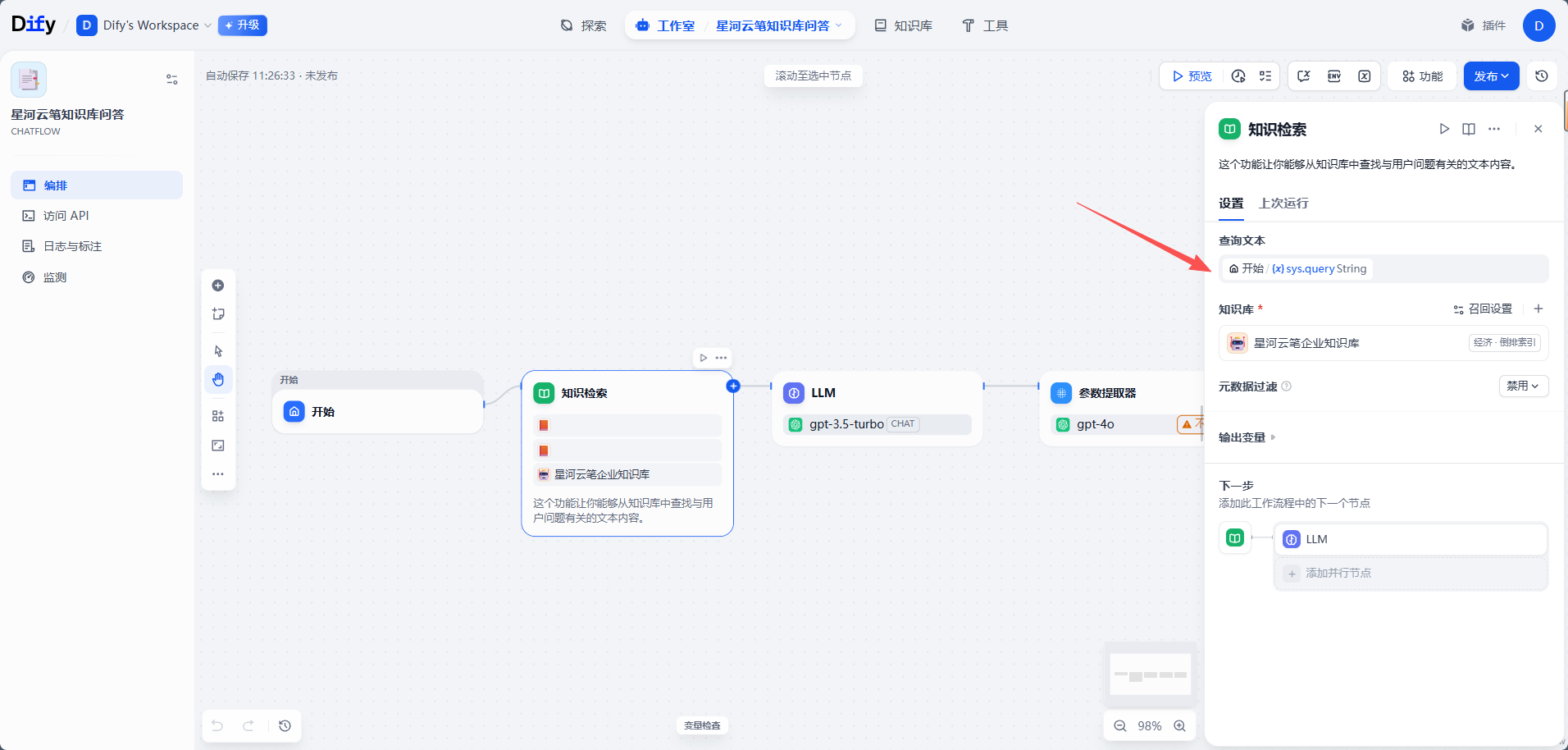
2. 设置查询变量
知识检索节点需要知道"拿什么内容去检索"。在聊天机器人场景中,一般使用用户输入作为查询内容。
选择用户输入变量后,流程含义就是:用户问什么,知识检索节点就用这个问题去知识库里找相关片段。
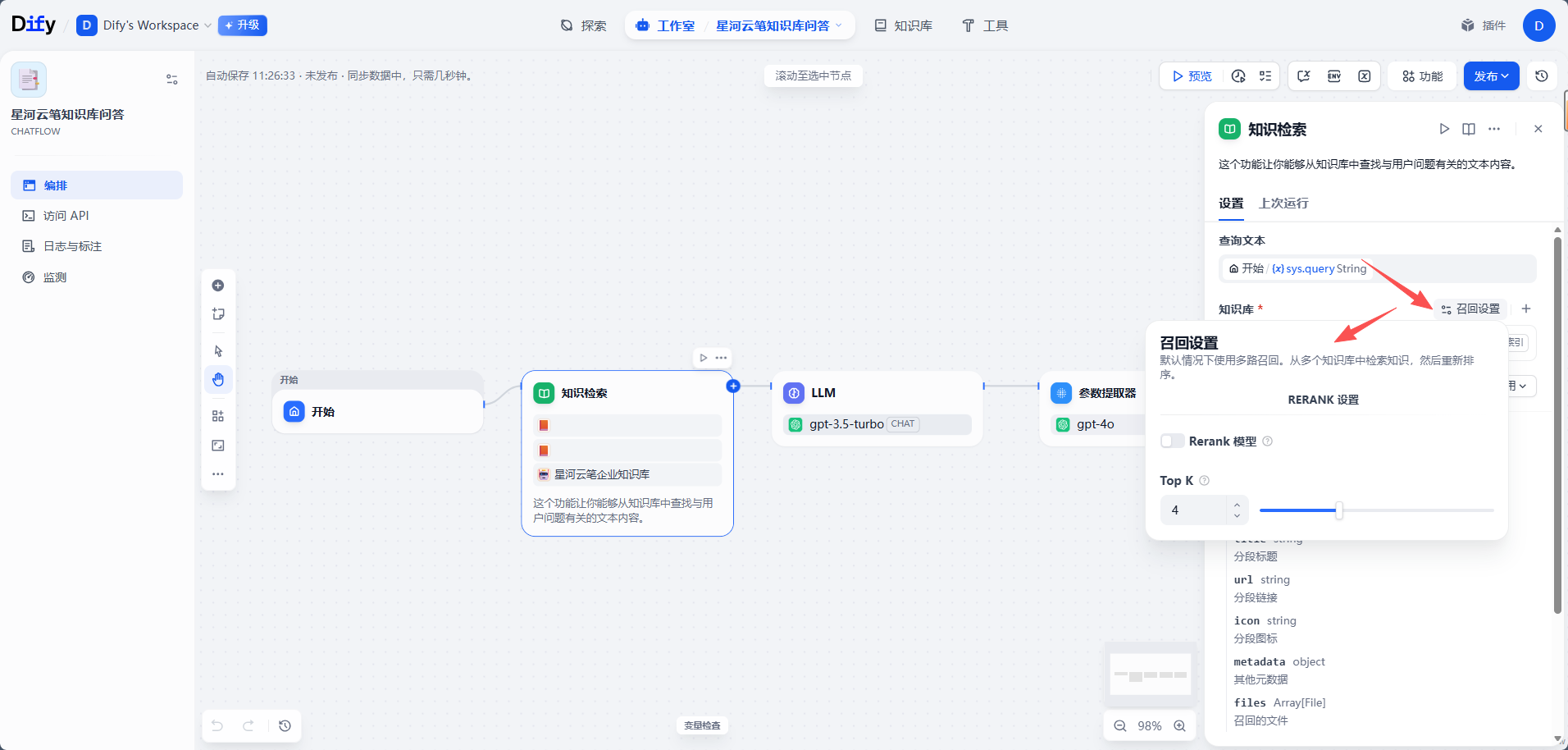
3. 调整检索参数
Top K、Score Threshold、Rerank 等参数,可以先使用默认值。等应用跑通后,再根据实际效果调整。
简单理解:
- Top K 越大,返回的片段越多,但也可能带入无关内容。
- Score Threshold 越高,召回越严格,但可能漏掉一些相关片段。
- Rerank 可以提升排序质量,但需要相应模型或服务支持。
第一版建议以稳定跑通为主,不要一开始就把阈值调得太高。
七、配置 LLM 节点并选择蓝耘 MaaS 模型
接下来配置 LLM 节点。这个节点会调用蓝耘 MaaS 模型生成最终回答。
1. 选择 GLM-5.1 模型
点击 LLM 节点,在模型选择区域选择前面配置好的蓝耘 MaaS 模型,也就是 GLM-5.1。
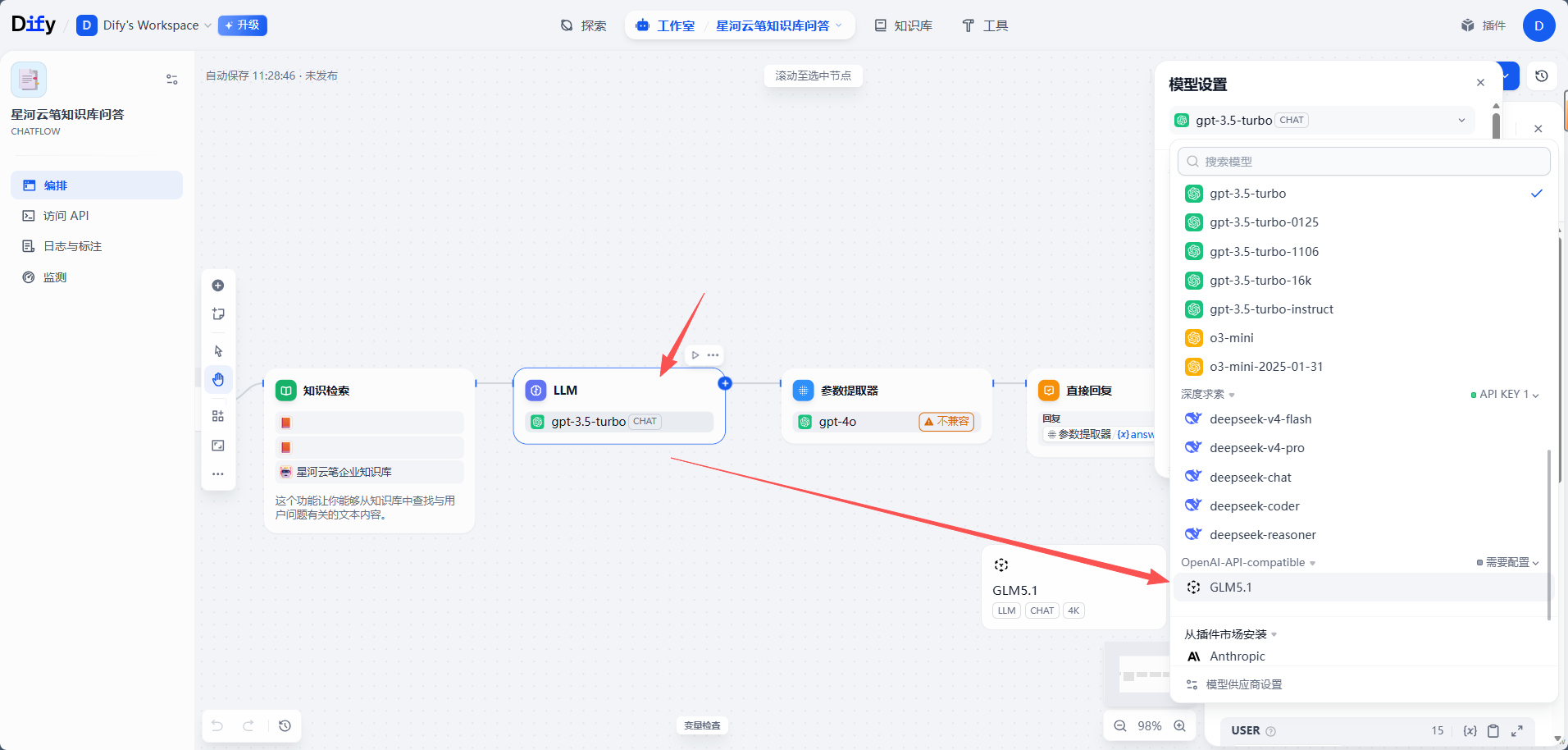
如果模型列表中没有看到 GLM-5.1,可以回到「模型供应商」检查:
- 模型是否保存成功。
- 模型名称是否添加正确。
- 当前工作空间是否能使用该模型。
- 模型类型是否适用于聊天或文本生成。
2. 配置上下文
LLM 节点需要拿到知识检索节点返回的结果。Dify 官方文档中说明,知识检索节点会输出检索结果变量,LLM 节点可以把这个变量作为上下文使用。
在 LLM 节点中找到「上下文」,选择知识检索节点的输出结果。
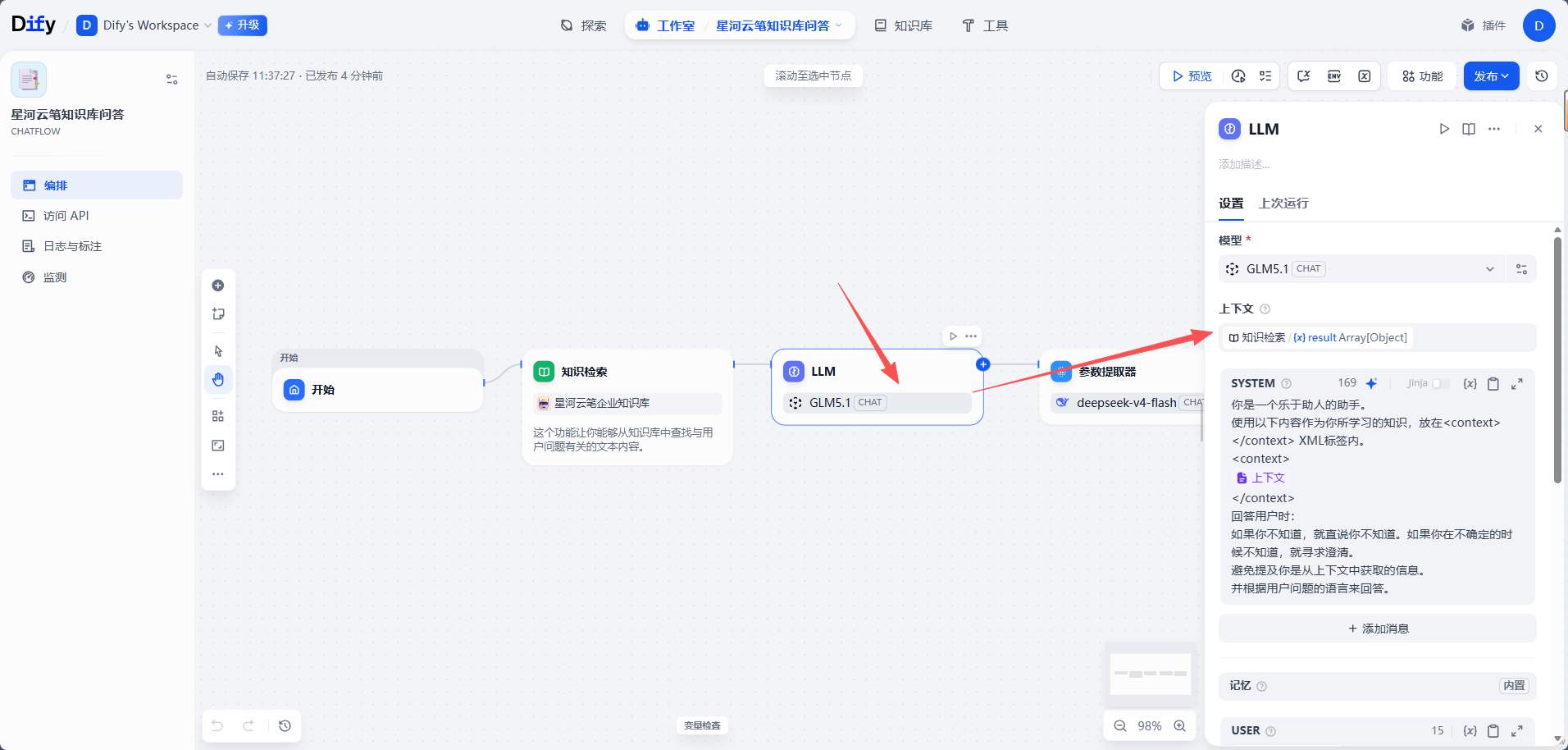
这样模型生成回答时,就不是只看用户问题,而是同时参考知识库检索出来的内容。
3. 编写系统提示词
为了减少模型自由发挥,建议在 LLM 节点中写一段明确的系统提示词。
可以使用下面这段:
text
你是一个企业知识库问答助手。请优先基于知识库检索到的内容回答用户问题。
回答要求:
1. 如果知识库中有明确依据,请分点回答,并尽量给出操作步骤。
2. 如果知识库中没有相关内容,请明确说明"当前知识库中没有找到相关依据",不要编造答案。
3. 如果问题涉及配置项、接口地址、模型名称或费用信息,请提醒用户以控制台或官方页面的实时信息为准。
4. 回答要简洁、准确,避免输出与问题无关的内容。
用户问题:
{{用户输入变量}}
知识库检索结果:
{{知识检索结果变量}}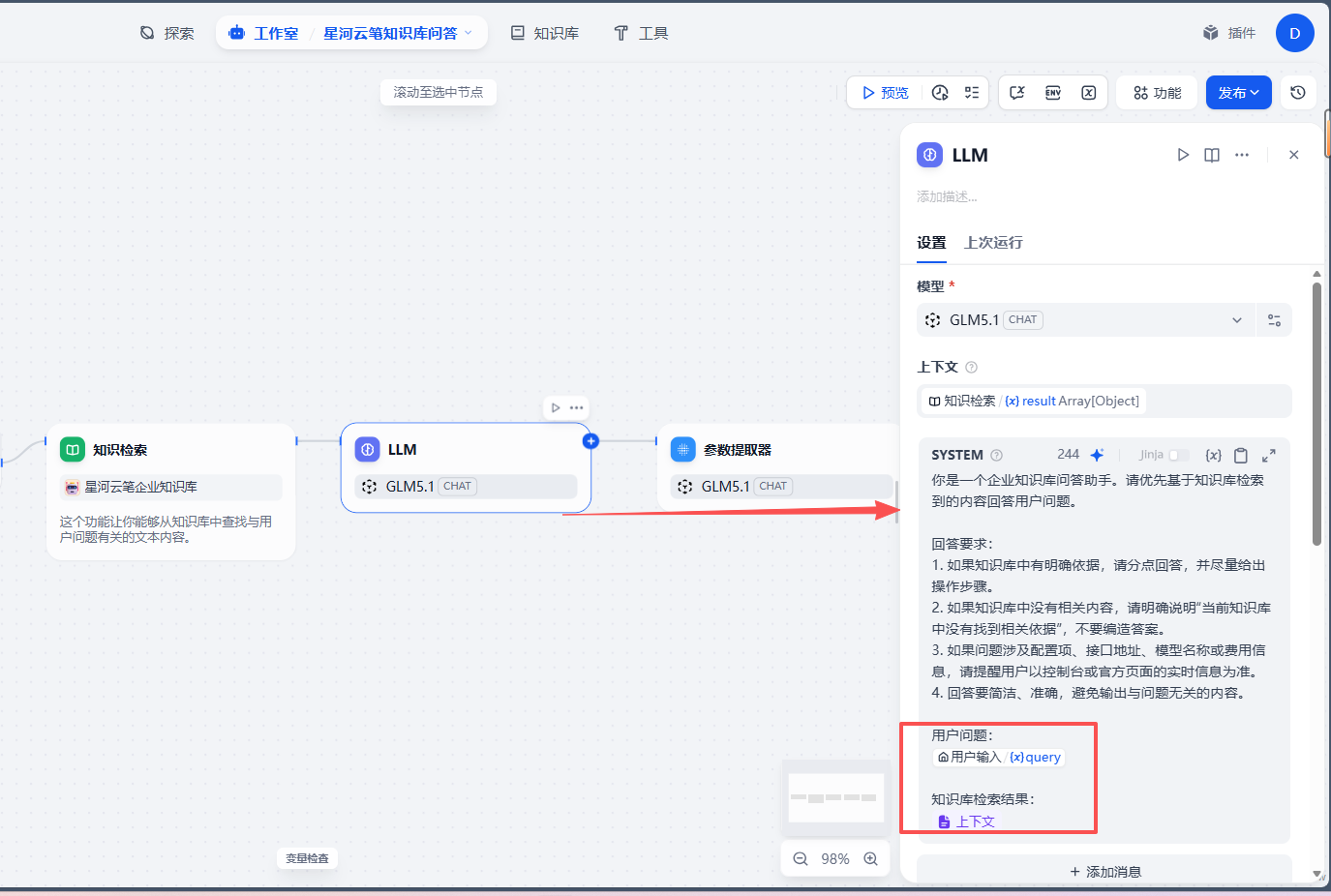
4. 设置模型参数
知识库问答应用更看重准确和稳定,不适合把随机性调得太高。
可以先参考下面的设置思路:
| 参数 | 建议 |
|---|---|
| Temperature | 0.2 - 0.5 |
| Max Tokens | 根据回答长度设置,先保持默认或适当提高 |
| Top P | 保持默认即可 |
| 上下文长度 | 根据模型能力和文档长度设置 |
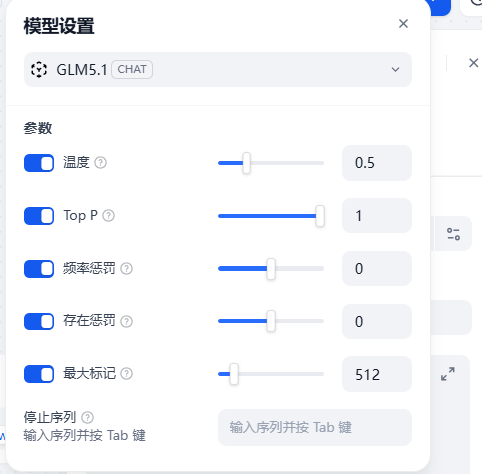 |
如果你希望回答更稳定,可以降低 Temperature。如果你希望回答更自然,可以略微提高,但不建议在知识库问答里调得太高。
八、运行预览并测试问答效果
配置完成后,点击预览或运行,开始测试这个知识库助手。
为了验证它不是"看起来能回答",而是真的基于知识库工作,建议至少做三类测试。
测试 1:基础命中问题
测试问题:
text
星河云笔的企业版支持哪些权限能力?预期结果:
助手应该从知识库中找到企业版权限相关内容,并回答类似:
text
星河云笔企业版支持组织成员管理、空间权限、文档访问权限、外链分享控制、操作审计和数据导出审批等能力。管理员可以按团队、项目或角色配置不同访问范围。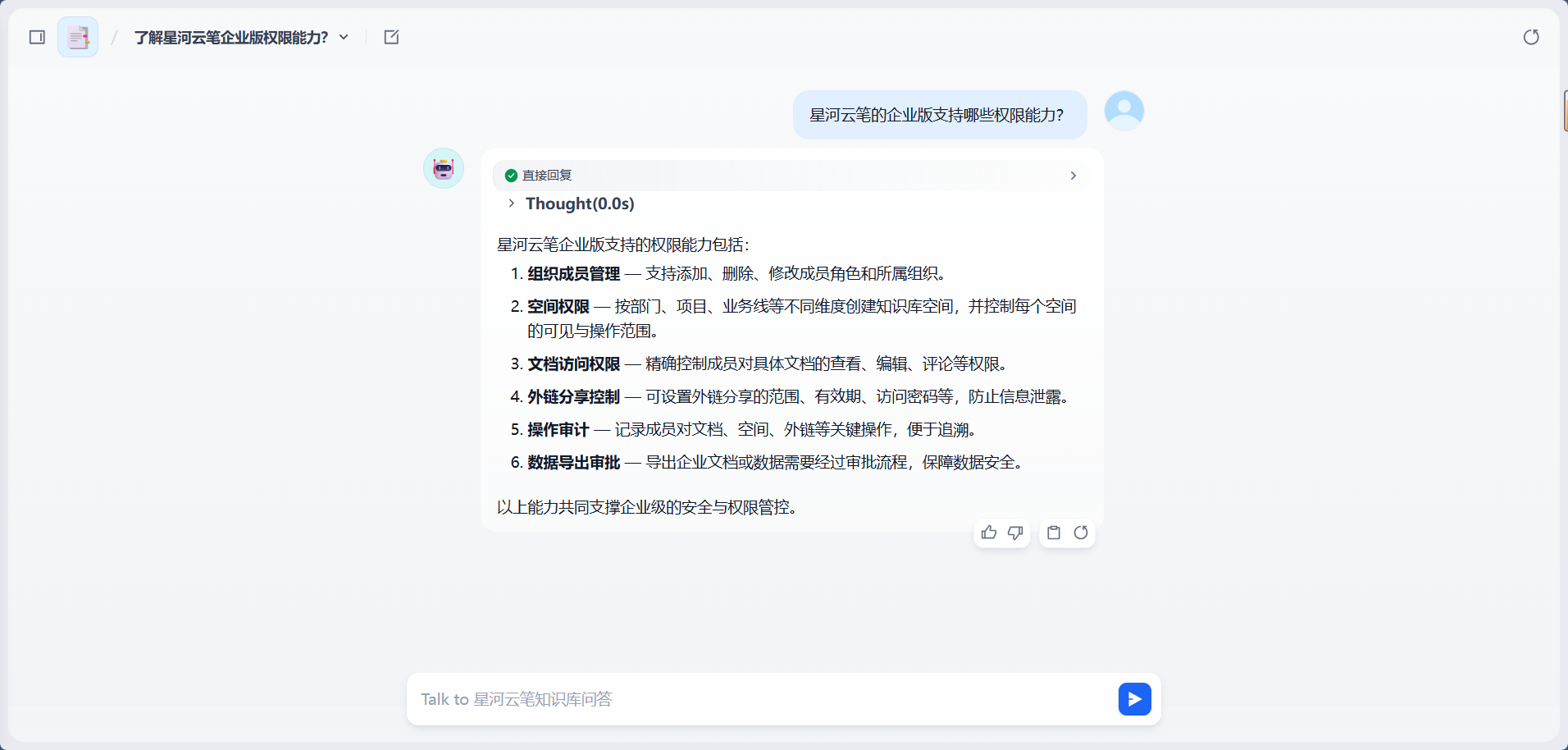
观察重点:
- 是否回答了企业版权限能力。
- 是否能分点说明不同权限场景。
- 是否能引用或基于知识库内容回答。
可以看到应用不仅把知识库的内容答上来了,还自行补充了相关内容
测试 2:流程型问题
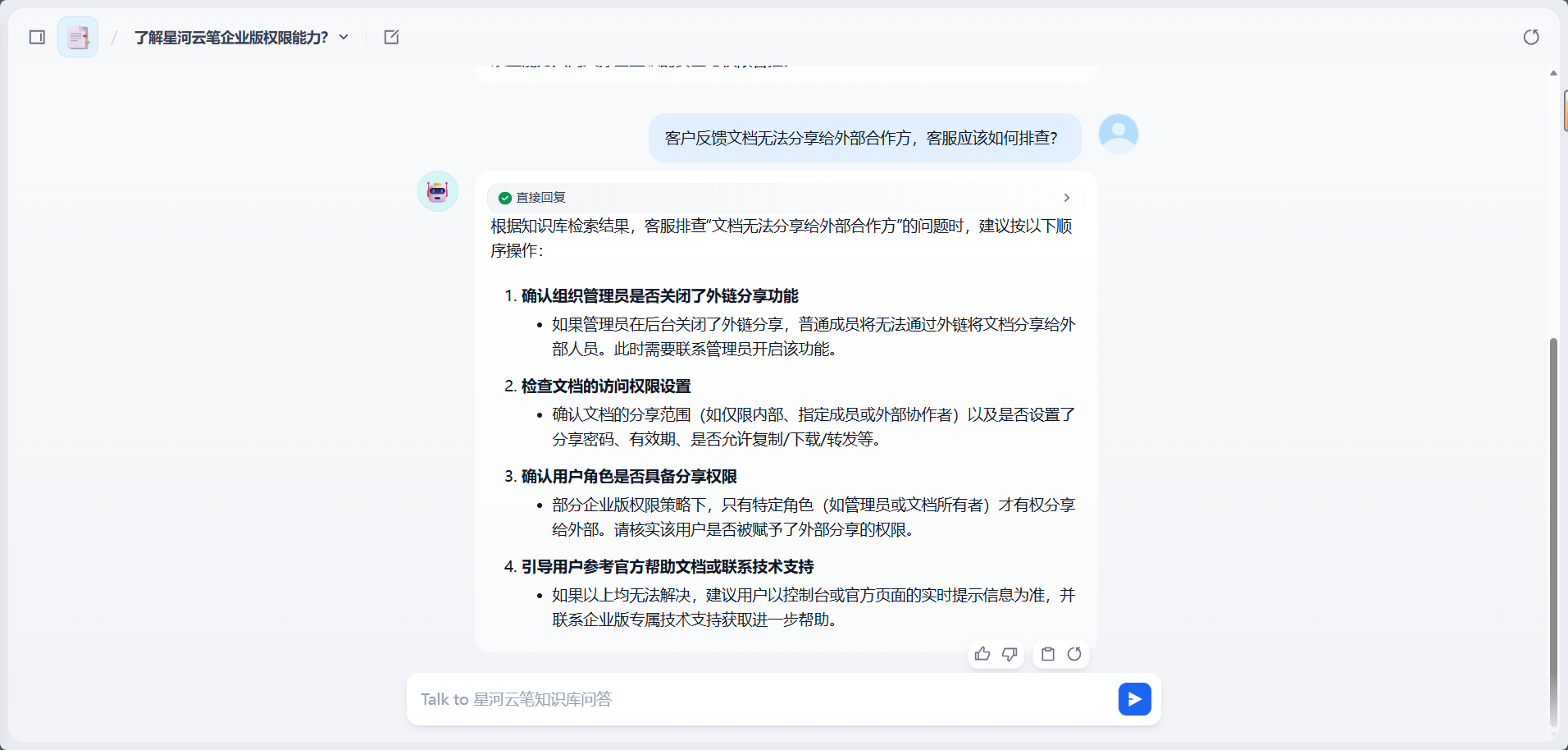
测试问题:
text
客户反馈文档无法分享给外部合作方,客服应该如何排查?预期结果:
助手应该根据 SOP 文档列出排查步骤,例如检查空间外链策略、文档权限、企业管理员安全设置等
测试 3:知识库外问题
测试问题可以故意问一个知识库里没有的内容,例如:
text
星河云笔明年会不会推出海外独立站版本?如果测试文档中没有相关信息,理想回答应该是:
text
当前知识库中没有找到相关依据。建议以官方公告或控制台实时信息为准。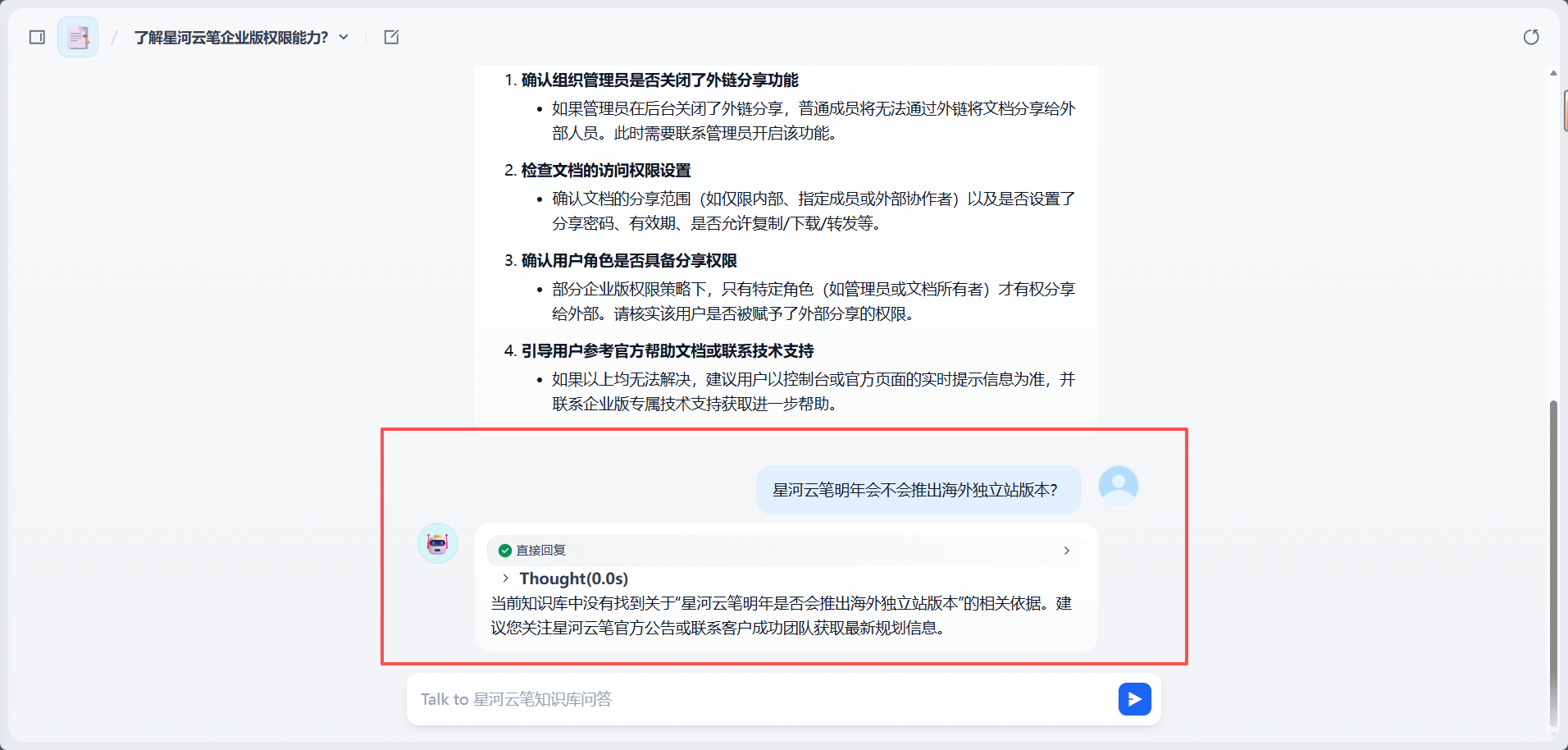
这个测试很重要。知识库助手不是回答得越多越好,而是应该知道什么时候不能回答。对于企业内部应用来说,减少无依据回答比输出一段看起来很完整的话更重要。(想必经常用豆包的人肯定能理解)
测试记录表
| 测试问题 | 是否命中知识库 | 回答效果 | 结论 |
|---|---|---|---|
| 星河云笔的企业版支持哪些权限能力? | 是 | 能回答组织、空间、文档和外链权限 | 符合预期 |
| 客户反馈文档无法分享给外部合作方,客服应该如何排查? | 是 | 能按 SOP 给出排查步骤 | 符合预期 |
| 星河云笔明年会不会推出海外独立站版本? | 否 | 提示知识库无依据,建议查看官方信息 | 符合预期 |
九、优化知识库助手的几个实用方法
第一版跑通以后,可以继续优化知识库助手的回答质量。
1. 优化文档结构
知识库问答的效果,很大程度取决于文档本身。
不推荐上传一整篇没有标题、没有层级、多个主题混在一起的长文档。更推荐把内容整理成结构清楚的形式
对于 FAQ 场景,「问题 + 答案」格式通常比大段说明更适合检索。
2. 调整分段
如果测试时发现回答缺少上下文,可以检查分段是否太短。如果回答总是夹杂无关内容,可以检查分段是否太长。
比较理想的片段应该满足:
- 单个片段围绕一个主题。
- 片段里保留必要上下文。
- 标题和正文对应清楚。
- 不把多个不相关问题放在一个片段里。
3. 降低模型随机性
知识库问答应用通常不是写小说,也不是做创意生成,而是要准确、稳定、可追溯。
所以 Temperature 可以设置得低一些,例如 0.2 到 0.5。这样模型更倾向于基于上下文稳妥回答。
4. 强化 Prompt 约束
Prompt 中最好明确写出:
- 优先基于知识库回答。
- 没有依据时不要编造。
- 涉及实时信息时提醒用户以官方页面为准。
- 尽量分点输出步骤。
这类约束能明显提升知识库助手的可靠性。
5. 保留引用来源
Dify 官方文档中提到,当使用知识检索的上下文变量时,Dify 可以跟踪引用来源,让用户看到信息来源。
对于企业知识库助手来说,引用来源非常重要。它可以帮助用户判断答案来自哪份文档,也方便后续排查回答错误。
6. 复杂场景再使用问题分类模板
本文选择的是「知识库 + 聊天机器人」模板,因为它适合单知识库或单业务场景。
如果后续要做更复杂的客服应用,可以考虑「问题分类 + 知识库 + 聊天机器人」模板。例如:
- 售前咨询走产品知识库。
- 售后问题走故障处理知识库。
- 账号计费问题走费用说明知识库。
- 无法分类的问题转人工或给出兜底回复。
这种方案更强,但配置成本也更高,可以根据自身情况考虑
十、常见问题排查
1. Dify 中保存模型失败
优先检查 API Key、API endpoint URL、模型名称是否正确。
如果是本地部署 Dify,还要确认服务器是否能访问蓝耘 MaaS 接口。
2. 模型能调用,但知识库没有召回内容
可能原因包括:
- 知识库没有完成索引。
- 查询变量配置错误。
- 文档分段质量较差。
- Score Threshold 设置过高。
- 上传文档里没有相关内容。
可以先在知识库内测试检索,再回到应用工作流里检查知识检索节点。
3. 回答和知识库内容不一致
可以从三个方面优化:
- 降低 Temperature。
- 强化 Prompt 中"必须基于知识库回答"的要求。
- 检查 LLM 节点是否正确接收知识检索结果作为上下文。
4. 知识库外问题仍然被模型回答
这通常说明 Prompt 约束不够,或者检索结果中混入了弱相关片段。
可以在 Prompt 中增加明确要求:
text
如果检索结果不足以回答问题,请直接说明知识库中没有找到相关依据,不要使用常识补全。同时可以适当提高 Score Threshold,减少弱相关内容进入上下文。
十一、蓝耘 MaaS 在这个场景里的价值
通过这次实操,可以看到蓝耘 MaaS 在 Dify 知识库应用中扮演的是模型底座角色。
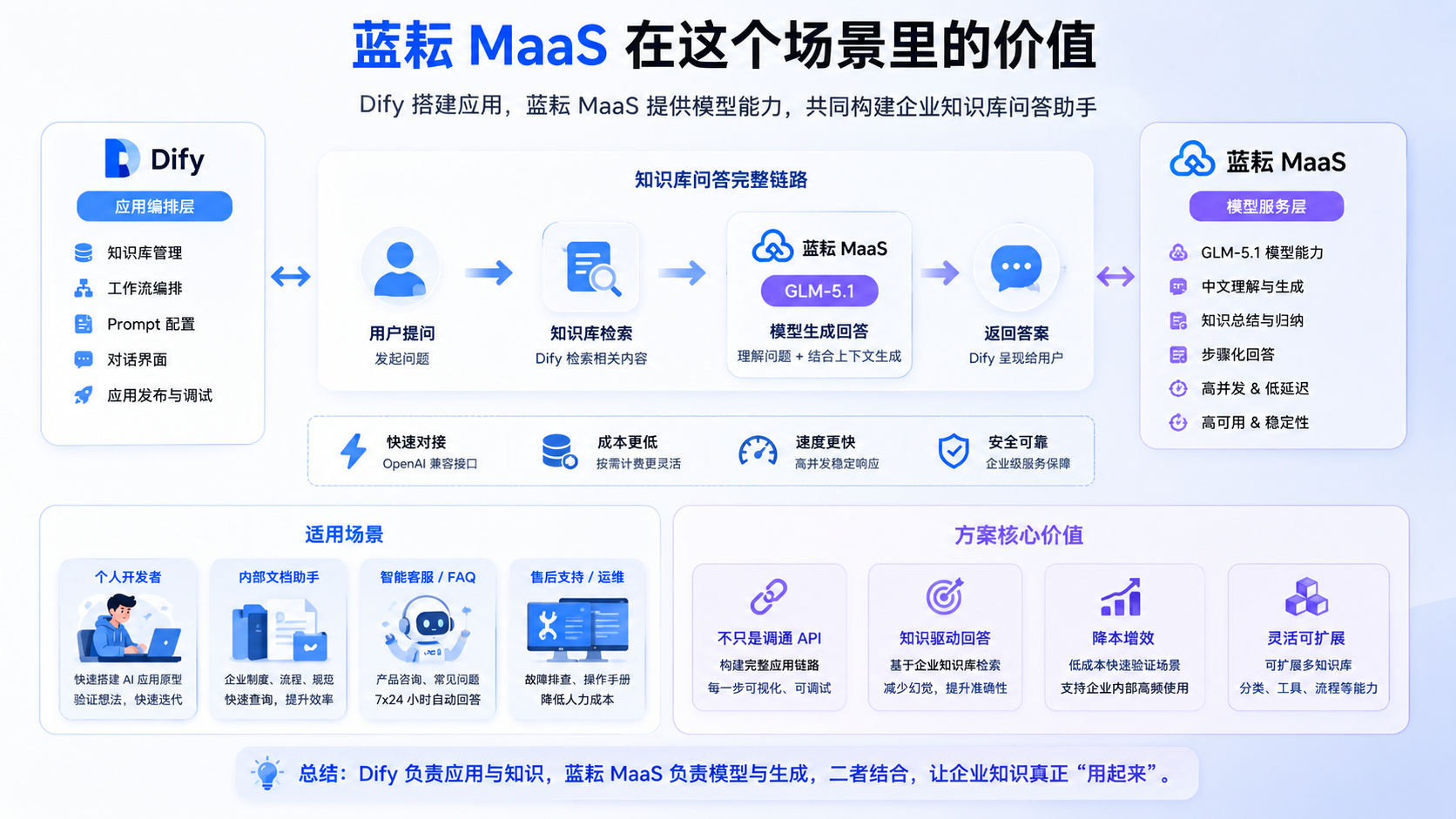
Dify 负责把知识库、工作流、Prompt 和对话界面组织起来,而蓝耘 MaaS 负责提供模型生成能力。用户提问后,Dify 先从知识库中检索相关内容,再把问题和上下文交给蓝耘 MaaS 模型生成答案。
对于个人开发者来说,这种组合适合快速做 AI 应用原型。比如先把产品文档、博客文章、项目 README 上传到 Dify,再通过蓝耘 MaaS 模型完成问答生成,很快就能得到一个可演示的知识库助手。
对于团队来说,它也适合验证内部文档助手、智能客服、售后 FAQ、运维手册问答等场景。前期不用投入太多后端开发成本,就能先验证业务流程和问答效果。本文选择 GLM-5.1 作为知识库问答模型,主要考虑它在中文业务理解、知识总结和步骤化回答方面比较适合企业知识库场景;配合蓝耘 MaaS 较快的调用速度和较低的使用成本,更适合企业内部高频使用。
更重要的是,这个方案不是单纯"调通一个 API",而是把模型服务放进了真实应用链路里:知识库创建、检索、上下文传递、模型生成、答案返回,每一步都能在 Dify 中看到和调试。
总结
本文使用 Dify 的「知识库 + 聊天机器人」模板,完成了一个基于蓝耘 MaaS 的知识库问答助手。
如果你想快速验证一个知识库问答应用,Dify + 蓝耘 MaaS 是一条比较容易上手的路径。Dify 降低了应用编排和知识库管理的门槛,蓝耘 MaaS 则提供模型服务能力。本文使用 GLM-5.1 搭建企业知识库助手,既能验证文档问答链路,也能体现蓝耘 MaaS 在调用速度和成本方面对企业场景的友好度。
如果你也想体验蓝耘 MaaS,可以进入蓝耘元生代官网注册账号,在 MaaS 服务中创建 API Key,并按照本文步骤把 GLM-5.1 接入 Dify。建议首次体验时先准备一份结构清晰的小型文档,从知识库问答场景开始验证模型接入和应用效果。