在使用Visual Studio 2026(下简称VS)进行编程的过程中,可能会出现如下的问题。
问题描述
例:程序中有:
cprintf("中文提示信息");在编译后正常,但是在读取由UTF编码的文件时,会出现乱码,如:
html滚滚长江东逝水会变成:
html锘?/ 婊氭粴闀挎睙涓滈€濇按锛屾氮鑺辨窐灏借嫳闆勩€ //第一种乱码而按照网上的教程,设定
chcp 65001*(让控制台改用UTF-8编码显示文字)*后,则会出现:
html������ // 第二种乱码
问题分析
首先,Windows默认的编码形式为GBK(汉字内码扩展规范,代码页936)。它本质上是一个区域性字符集解决方案。而UTF-8(代码页65001)是Unicode字符集的一种可变长度编码实现方式,旨在统一表示全球所有语言的字符。它与ASCII编码完全兼容,已成为电子邮件、网页及跨平台应用中的主流编码。因此,UTF-8是现代应用开发、跨平台及国际化项目的首选编码,我们在编写程序的时候也应当使用UTF-8编码。
VS的默认编码是UTF-8,但是进行编译的结果以及调试时的命令行窗口默认使用的都是GBK编码 。这就导致了第一种情况:在调试时的窗口以及cmd中,中文提示信息都能显示正常,但在面对UTF-8的文本时,cmd就会出现第一种乱码,即**"古文码"。这是以GBK方式读取UTF-8编码的中文所产生的现象。这时我们可以使用chcp 65001来解决第一种乱码,但中文提示信息就会变成第二种乱码,即 "口字码"**。
对于以下几个体系,有:
- Windows 系统与控制台:默认使用GBK 编码(代码页 936),控制台的输入、输出均按 GBK 解析字节流;
- VS 文件保存与编译:VS 默认将源码文件保存为UTF-8 无签名(无 BOM)格式,但编译器默认按系统编码(GBK)解析源码,导致源码中的中文字符串被编译器按 GBK 解析为错误的字节流;
- UTF-8 文件读取:程序读取 UTF-8 编码文件时,得到的是 UTF-8 格式的字节流,若直接输出到 GBK 编码的控制台,字节流解析错误就会产生乱码。
下面给出我尝试过的几种解决办法以及其无法解决问题的原因。
- 使用
setlocale(LC_ALL, ".UTF-8");(需要<locale.h>),这个方法无效的原因是该函数未配置 VS 编译参数时单独使用无效,但配合/utf-8编译参数后,能正常设置 C 标准库的本地化编码,让printf等函数正确输出 UTF-8 中文,所以会重复问题的情况; - 使用
SetConsoleOutputCP(65001);(需要<Windows.h>) ,这个方法来自Microsoft Learn的官方网站。原问题的链接在此。提问者和回答者讨论了与之类似的"system("chcp 65001");"。以及powershell的适配问题。这个方法无效的原因是:该函数本身能正常修改控制台输出编码为 UTF-8,单独使用乱码的原因是源码未按 UTF-8 编译(编译器仍按 GBK 解析 UTF-8 源码,导致字符串编码错误) - 方法一和方法二同时使用。导致程序在cmd上无反应。暂不清楚其成因,推测是CMD 的 UTF-8 解析规则触发了输出缓冲区阻塞。
- 在Windows设置中的"更改系统区域设置"中勾选**"Beta版:使用Unicode UTF-8提供全球语言支持"**。这会引发一些未知的新问题。
解决方法
-
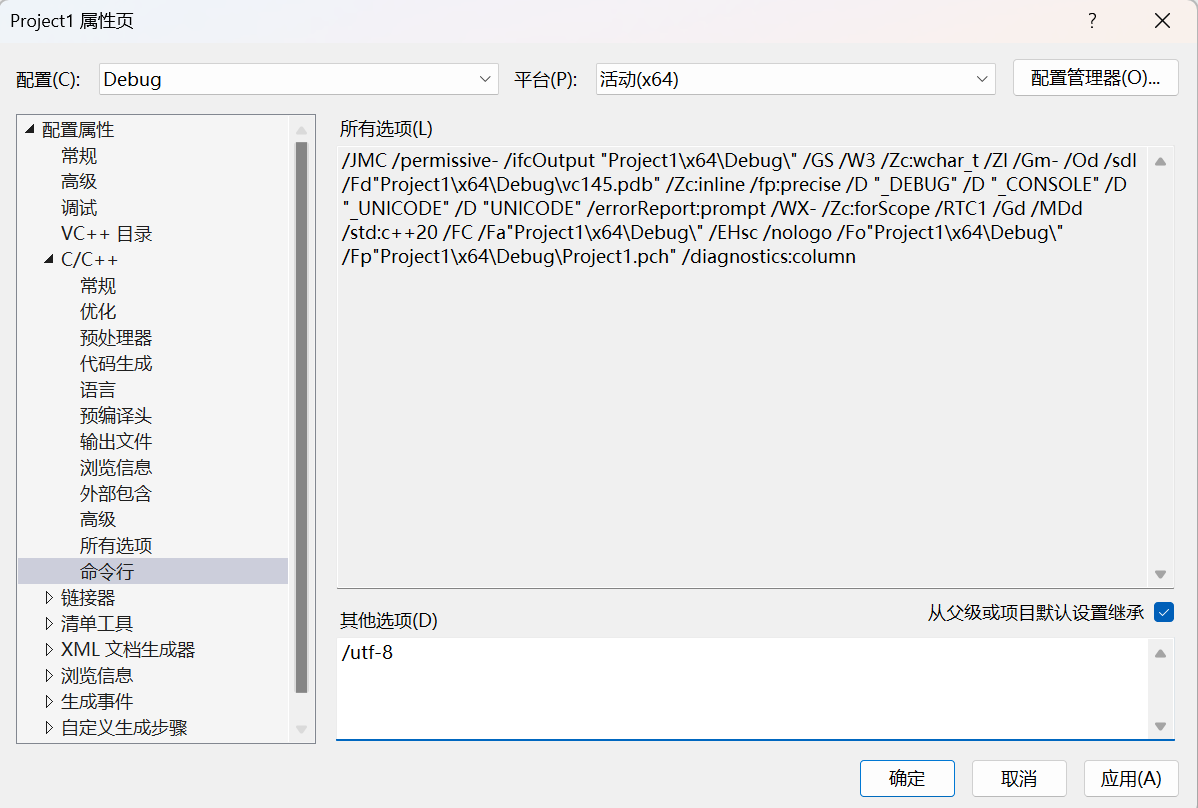
先在VS的解决方案资源管理器中右键工程名,找到"属性"。
-
在"属性"中找到**"配置属性"------"C/C++"------"命令行"**,并在"其他选项"中输入
/utf-8,该参数的作用是让编译器按 UTF-8 解析源码(来源见此)。
-
在程序内使用
SetConsoleOutputCP(65001);。这会使得调试命令行窗口也使用UTF-8编码。 -
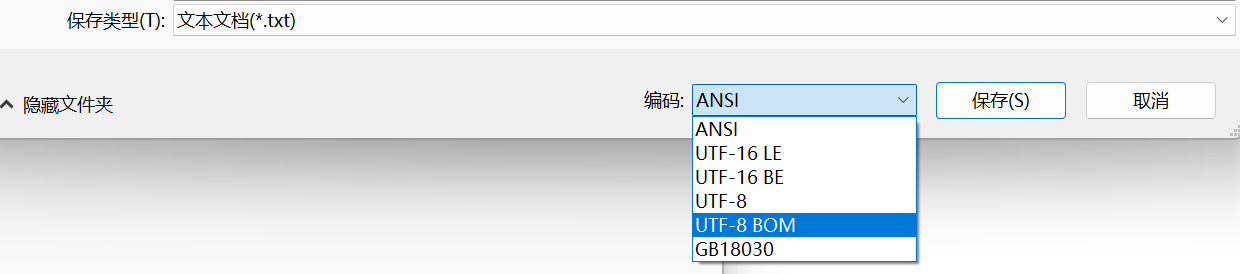
在**"工具"------"选项"------"环境"------"文档"内,勾选"使用特定编码保存文件","保存编码"选择"Unicode(UTF-8带签名)"**。
带签名的UTF-8编码可以使编译器自动识别UTF-8编码。

此外,还可以改变记事本存储文本的编码。只需要选择**"文件"------"另存为"**即可选择编码。