练习题目:Training-WWW-Robots
练习网站(攻防世界):https://adworld.xctf.org.cn/
解题步骤
1、打开题目场景
在这个小小的训练挑战中,你将了解Repbots_exclusion_standard。
robots.txt文件被网络爬虫用于检查它们是否被允许爬取和索引你的网站,或者只是网站的部分内容。
有时这些文件会暴露目录结构,而不是保护内容不被爬取。
祝你玩得开心!
2、利用Robots协议
发现根目录下有一个 f10g.php 的文件,访问这个文件内容

3、访问网站根目录的 f10g.php 文件
得到正确答案

知识点讲解:Web 安全信息收集:robots.txt 的原理、利用与防御实战
⚠️ 警告: 本文仅用于授权测试和安全学习,未经授权扫描目标属于违法行为。
一、写在前面:关于「Repbots」的纠正
在安全圈交流时,我听到过新手说「Repbots 漏洞」。其实这是一个口误,正确的术语是 Robots 协议 ,具体体现在网站根目录下的 robots.txt 文件。
虽然它不是传统意义上的「漏洞」,但在信息收集阶段,robots.txt往往是攻击者眼中的「藏宝图」。
几年前,我负责某系统的安全评估。渗透测试同事只花了一分钟,访问了 目标网站/robots.txt,发现里面Disallow了一个 /backup_2023.zip 路径。直接访问该路径,下载到了包含数据库账号密码的备份文件。
全程未利用任何技术漏洞,仅靠一个配置文件。 这就是 robots.txt 的安全价值。
二、robots.txt 原理详解
2.1 什么是 Robots 协议?
Robots Exclusion Protocol(机器人排除协议)是网站告诉搜索引擎爬虫(如 Google、百度)哪些页面可以抓取,哪些不可以的国际标准。
本质: 它是一个君子协议,没有强制约束力。
2.2 文件位置
固定位于网站根目录下:
http://example.com/robots.txt
https://example.com/robots.txt2.3 基本语法
|----------------|---------|-------------------------------------------|
| 字段 | 说明 | 示例 |
| User-agent | 指定爬虫名称 | User-agent: * (所有爬虫) |
| Disallow | 禁止抓取的路径 | Disallow: /admin/ |
| Allow | 允许抓取的路径 | Allow: /admin/login.php |
| Sitemap | 网站地图位置 | Sitemap: http://example.com/sitemap.xml |
示例文件:
User-agent: *
Disallow: /admin/
Disallow: /backup/
Allow: /public/
Sitemap: http://example.com/sitemap.xml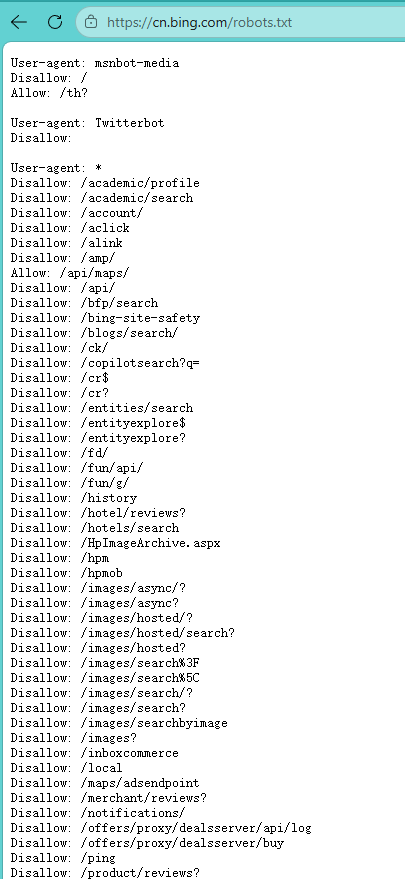
图片内容: 浏览器访问 https://cn.bing.com/robots.txt 显示的文件内容。
目的: 展示 robots.txt 的真实样子。
2.4 常见误区(关键)
误区: 「Disallowed 的路径是受保护的,访问不了。」
真相: Disallow 只是请求爬虫别来,不代表禁止用户访问。 任何知道路径的人都可以直接访问。
安全风险: 把敏感路径写在 robots.txt 里,等于主动告诉攻击者哪里有问题。
三、安全视角:如何利用 robots.txt
在授权渗透测试中,robots.txt 是信息收集的第一步。
3.1 直接访问查看
操作步骤:
- 打开浏览器或 Burp Suite
- 访问
http://目标域名/robots.txt - 分析 Disallow 后的路径
工具命令:
curl http://target.com/robots.txt3.2 敏感路径识别
看到 Disallow 路径后,重点关注的关键词:
|------------|--------|------------------------|
| 关键词 | 潜在风险 | 验证方法 |
| /admin/ | 后台管理入口 | 直接访问,尝试弱口令 |
| /backup/ | 备份文件 | 尝试下载 .zip/.sql/.bak 文件 |
| /config/ | 配置文件 | 尝试读取数据库密码 |
| /api/ | 接口文档 | 测试未授权访问 |
| /test/ | 测试页面 | 可能存在调试漏洞 |
| /old/ | 旧版本系统 | 可能存在已知漏洞 |
3.3 结合目录扫描工具
robots.txt 暴露的路径,可以作为目录扫描工具(如 Dirsearch、Gobuster)的自定义字典。
Dirsearch 示例:
# 将 robots.txt 中的路径提取出来,作为字典
dirsearch -u http://target.com -w robots_paths.txt对本地搭建的dwva靶站进行扫描
# 由于本地的靶站的robots.txt没有路径,所以就不是用字典进行扫描
dirsearch -u http://192.168.6.100:8080 
优势: 比暴力扫描更精准,减少被封 IP 的风险。
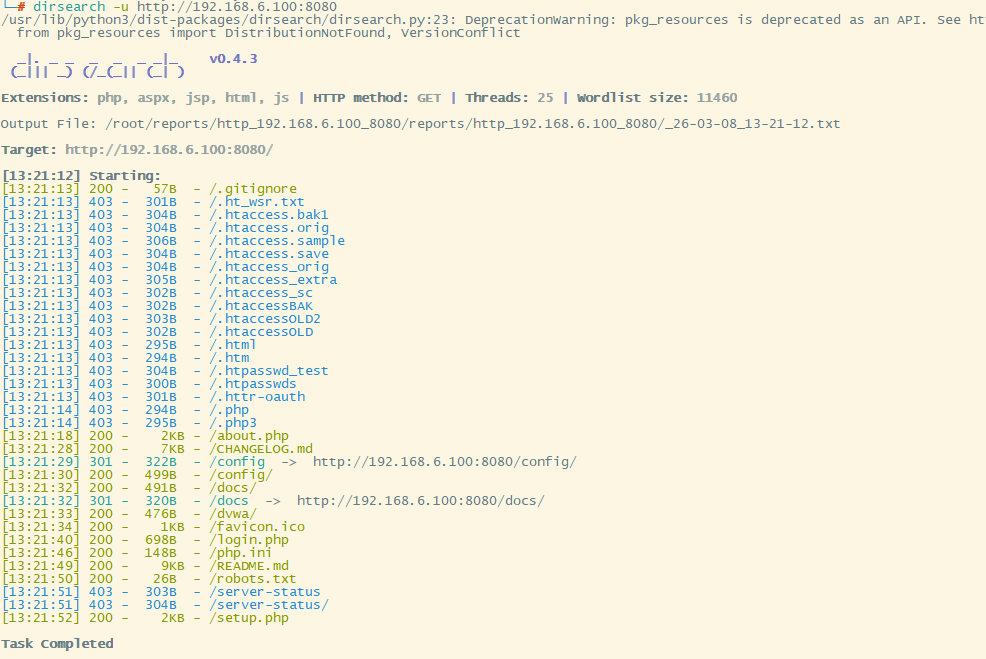
[200]:状态码(成功访问)[403]:权限拒绝(目录存在但无访问权限)
图片内容: 使用 Dirsearch 进行扫描的结果。
目的: 展示工具联动用法。
四、实战案例:三个真实场景
4.1 案例一:后台路径泄露
场景: 某企业官网,前台无任何漏洞。
过程:
- 访问
/robots.txt - 发现
Disallow: /manage_system_v2/ - 直接访问
http://target.com/manage_system_v2/ - 发现未设防的后台登录页
结果: 通过弱口令进入后台,获取权限。
教训: 后台路径不应通过 robots.txt 隐藏,应使用强认证。
4.2 案例二:数据库备份文件下载
场景: 某电商系统迁移后,旧数据未清理。
过程:
- 访问
/robots.txt - 发现
Disallow: /db_backup_20230501.sql - 直接访问该 URL
- 浏览器开始下载 SQL 文件
结果: 文件中包含所有用户表结构和管理员密码哈希。
教训: 备份文件绝对不能放在 Web 目录下,更不能在 robots.txt 中引用。
4.3 案例三:API 接口未授权访问
场景: 某 APP 后端接口。
过程:
- 访问
/robots.txt - 发现
Disallow: /api/v1/internal/ - 访问该路径,发现返回 JSON 数据
- 测试发现无需 Token 即可调用
结果: 获取内部用户数据。
教训: 接口安全依赖认证机制,而非路径隐藏。
五、防御方案:如何正确配置
5.1 核心原则:安全不靠隐匿
Security by Obscurity(隐匿式安全)是无效的。
不要指望通过 robots.txt 隐藏敏感路径来保护安全。攻击者不用爬虫,照样可以访问。
5.2 正确配置建议
|----------------|-------------------------------|------|
| 做法 | 说明 | 推荐度 |
| 公开路径可写入 | 正常页面路径可写入 robots.txt | ✅ 推荐 |
| 敏感路径不写入 | 后台、备份、配置路径不要写进 robots.txt | ✅ 必须 |
| 使用权限控制 | 敏感路径通过登录/鉴权保护 | ✅ 必须 |
| 移除备份文件 | 生产环境不要留存 .sql/.zip 备份 | ✅ 必须 |
| 返回 403/404 | 敏感路径直接禁止访问,而不是 Disallow | ✅ 推荐 |
5.3 安全配置示例
❌ 危险配置:
User-agent: *
Disallow: /admin/
Disallow: /config/database.yml
Disallow: /backup/full.zip分析:直接告诉攻击者这三个地方有东西。
✅ 安全配置:
User-agent: *
Allow: /
# 敏感路径根本不提,直接在服务器层禁止访问服务器层禁止(Nginx 示例):
location /admin/ {
deny all;
return 403;
}六、自查清单
发布网站前,对照此表检查 robots.txt:
- 是否包含后台管理路径(/admin/, /manage/)?
- 是否包含备份文件路径(.sql, .zip, .bak)?
- 是否包含配置文件路径(.yml, .conf, .env)?
- 是否包含测试环境路径(/test/, /dev/)?
- 敏感路径是否已通过权限控制(登录/鉴权)保护?
- 服务器是否对敏感路径返回 403 而非仅靠 robots.txt?
- 是否使用了 HTTPS 协议传输 robots.txt?
七、常见问题 Q&A
Q:robots.txt 能被删除吗?
A:可以。如果不需要搜索引擎收录,可以删除该文件。但删除后,爬虫可能会尝试抓取所有路径。
Q:隐藏 robots.txt 文件本身安全吗?
A:没用。攻击者会尝试访问 /robots.txt,如果返回 404,他们会认为没有限制,反而更放心地扫描。
Q:如何防止攻击者利用 robots.txt?
A:不要在里面写敏感路径。真正的安全靠权限控制(Authentication & Authorization),不靠隐藏路径。
Q:搜索引擎会遵守 robots.txt 吗?
A:正规搜索引擎(Google、百度)会遵守。但恶意爬虫和攻击工具完全无视。
Q:有没有工具自动分析 robots.txt 风险?
A:有。Burp Suite 插件、OWASP ZAP、以及在线工具(如 robotools.com)都可以分析。
八、信息收集中的位置
在 Web 安全测试流程中,robots.txt 属于信息收集阶段。
1. 信息收集 (Whois, DNS, robots.txt, 端口扫描)
↓
2. 漏洞扫描 (SQL 注入,XSS, 命令注入)
↓
3. 漏洞利用 (获取权限,数据提取)
↓
4. 后渗透 (维持权限,横向移动)
↓
5. 报告与修复robots.txt 是第 1 步中最简单也最容易忽视的一环。
总结
我在安全行业多年,见过太多因为一个 robots.txt 配置失误导致的数据泄露。
核心要点:
- robots.txt 是给爬虫看的,不是给黑客看的防线。
- 敏感路径千万不要写进 robots.txt。
- 真正的安全靠权限控制,不靠隐匿路径。
- 信息收集阶段,必看 robots.txt。
每天一个网络安全小知识分享;
免责声明: 本文所有内容仅供学习与授权测试使用,未经授权的攻击行为属于违法,请务必在法律允许范围内进行安全研究。