第 12 篇:深度学习学习路线总结:从入门到科研与工程应用
深度学习入门专栏 · 第 12 篇
适合读者:已经阅读前两篇内容,希望继续系统学习深度学习核心方法与实践流程的初学者
摘要
本文对深度学习入门专栏进行阶段性总结,给出从基础概念到科研与工程应用的学习路线。文章梳理 Python、数学基础、机器学习概念、神经网络、CNN、序列模型、Transformer、实验设计和模型部署之间的关系,并区分科研路线与工程路线的侧重点。通过能力地图和实践建议,帮助读者制定后续学习与项目训练计划。
关键词: 学习路线;深度学习入门;科研训练;工程实践;项目能力;模型部署
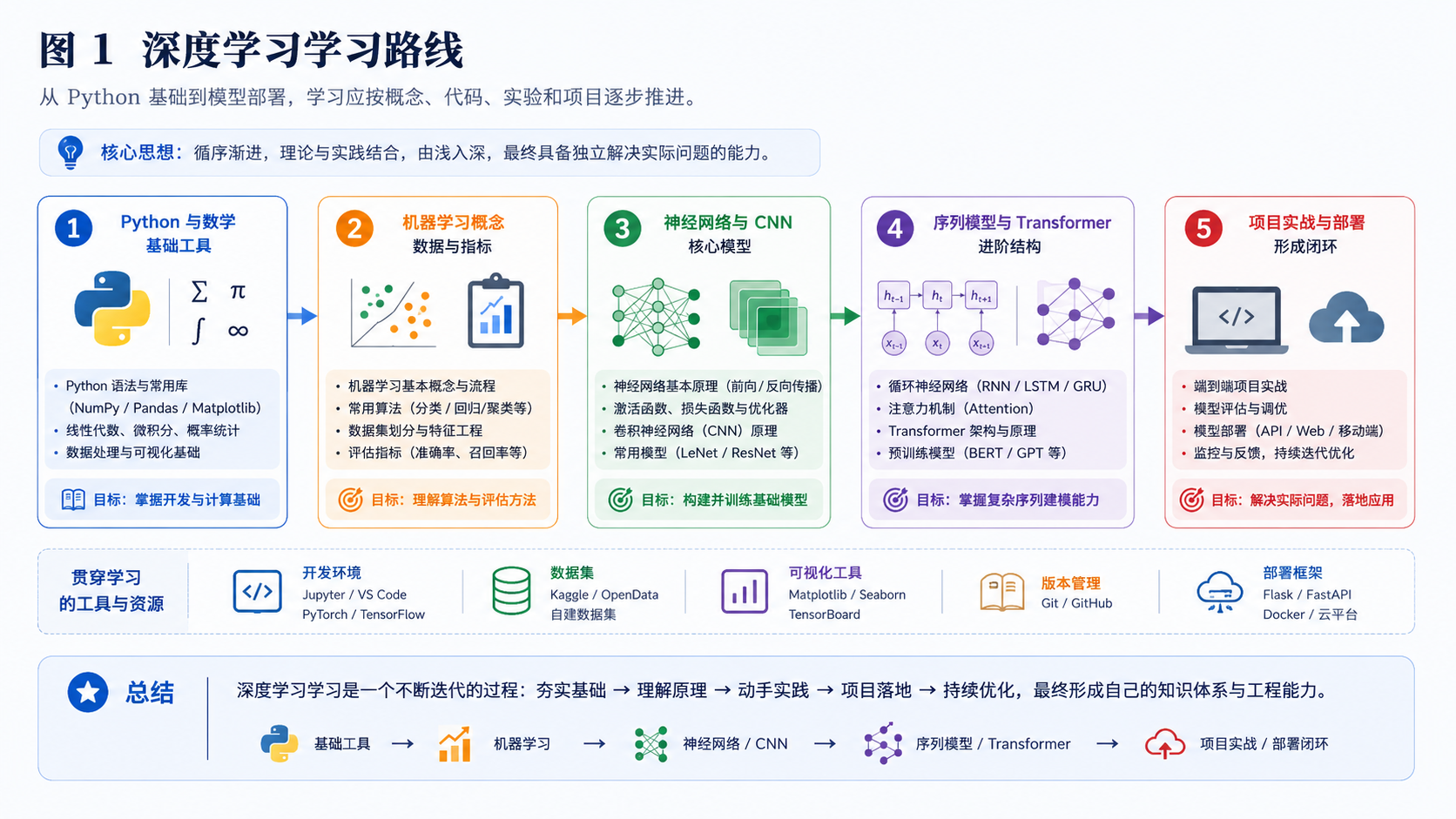
1. 学习路线要形成闭环
深度学习初学者容易追逐模型名称:CNN、RNN、Transformer、扩散模型。但真正稳定的学习路线应该围绕能力闭环展开:理解数据,理解模型,能训练,能评估,能解释,能部署。这个闭环的每个环节都至关重要,缺一不可。
1. 理解数据:这是所有工作的起点。你需要能够分析数据的分布、质量、偏差和潜在问题。例如,在图像分类任务中,需要检查类别是否平衡、图像分辨率是否一致、是否存在标注错误。在自然语言处理任务中,需要了解文本的长度分布、词汇表大小、是否存在噪声或缺失值。对数据的深刻理解能帮助你选择合适的数据预处理方法、增强策略,甚至发现数据本身定义的问题。
2. 理解模型:不仅仅是知道某个模型的网络结构图,更要理解其设计动机、核心假设和适用场景。例如,CNN 利用卷积核的局部连接和权重共享来捕获图像的平移不变性;RNN 通过循环结构处理序列数据的时序依赖;Transformer 则通过自注意力机制直接建模全局依赖关系,摆脱了序列顺序的束缚。理解模型还包括知道其计算复杂度、参数量级以及如何根据任务规模选择合适的模型大小。
3. 能训练:掌握如何将模型和数据结合起来,通过优化算法(如 SGD、Adam)最小化损失函数。这包括设置合适的学习率、批次大小、训练轮数,使用学习率调度和早停等技巧防止过拟合。更重要的是,要能诊断训练过程中的问题,如梯度消失/爆炸、损失不下降、准确率震荡等,并知道如何调整超参数或修改模型结构来解决。
4. 能评估:训练出的模型必须在独立的验证集和测试集上进行公正的评估。选择合适的评估指标(如准确率、精确率、召回率、F1 分数、AUC-ROC)至关重要。要避免数据泄露,确保测试集完全独立于训练和调参过程。评估不仅是看一个最终数字,还要进行误差分析,查看模型在哪些样本上犯错,错误模式是什么,从而指导后续的模型改进。
5. 能解释:随着模型复杂度增加(尤其是深度学习),模型的可解释性变得愈发重要。你需要能够解释模型的预测依据,例如通过可视化 CNN 的卷积核激活、生成注意力热图、或使用 LIME、SHAP 等工具进行事后解释。在科研中,可解释性有助于验证模型是否学到了有意义的特征;在工程中,它有助于建立用户信任和满足监管要求。
6. 能部署:将训练好的模型转化为实际可用的服务。这涉及模型导出、优化(如量化、剪枝)、封装成 API 接口、集成到现有系统,并确保其在高并发下的性能、稳定性和可维护性。部署还包含持续的监控、日志记录、模型版本管理和 A/B 测试。
这个闭环是一个迭代的过程。例如,部署后收集的真实数据可能反过来揭示训练数据未覆盖的分布,从而需要重新理解数据并迭代模型。形成这样的闭环思维,才能从"调包侠"成长为能够独立解决实际问题的深度学习从业者。
2. 科研路线与工程路线
科研更强调问题定义、创新点、对比实验、消融分析和结论表达。工程更强调数据管道、推理效率、系统稳定、监控和可维护性。
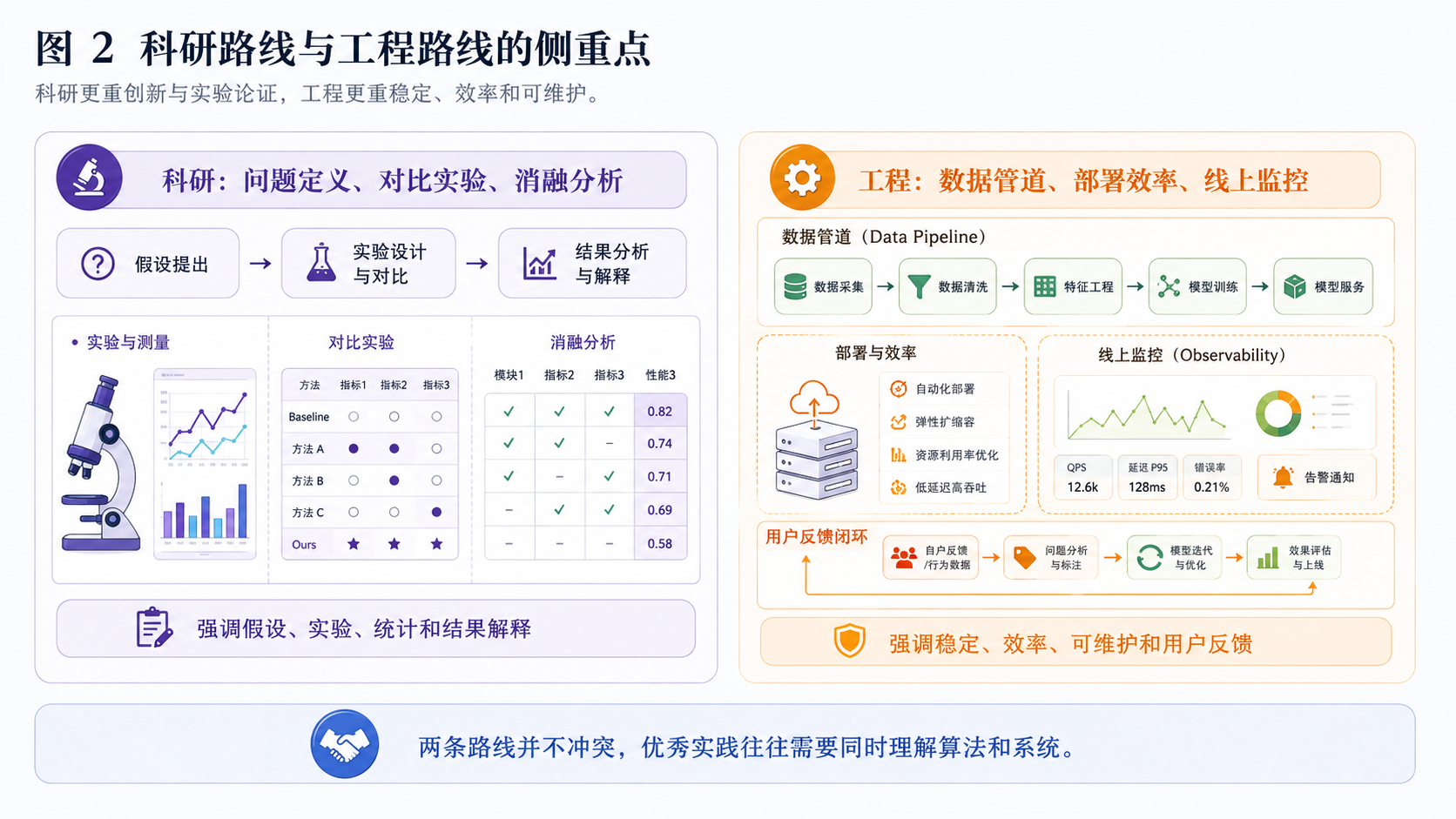
两条路线并不冲突。好的科研需要规范实验,好的工程也需要理解模型机制。
3. 能力地图
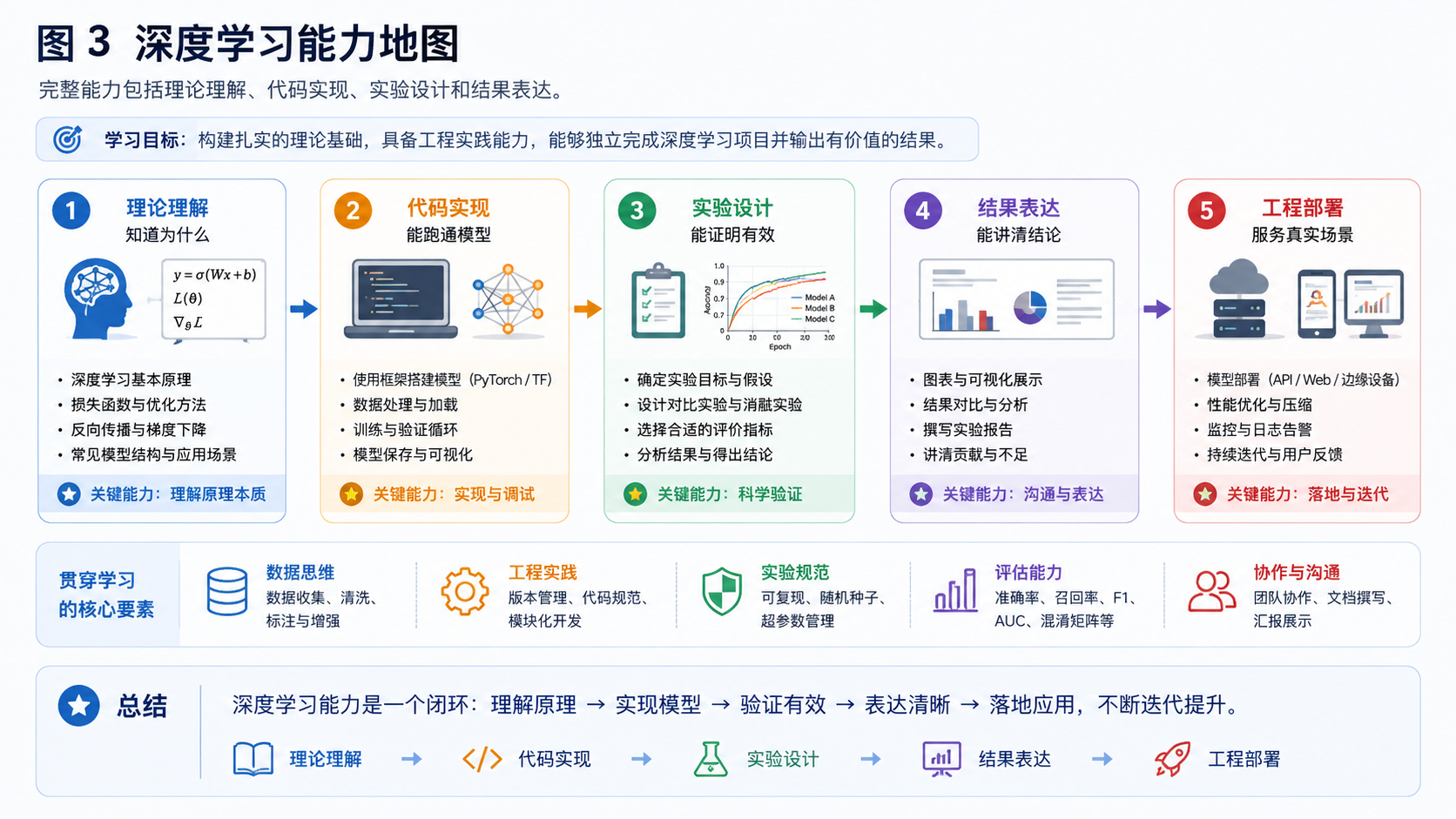
完整能力包括理论理解、代码实现、实验设计、结果表达和工程部署。只会调用模型不等于掌握深度学习。
4. 代码示例:检查学习进度
python
tasks = {
"理解损失函数": True,
"能训练 CNN": True,
"会做误差分析": False,
"能部署模型": False
}
done = sum(tasks.values())
print(f"已完成 {done}/{len(tasks)} 项")运行结果:
text
已完成 2/4 项5. 代码示例:确定下一步重点
python
weak_points = ["误差分析", "模型部署"]
for item in weak_points:
print("下一步重点:", item)运行结果:
text
下一步重点: 误差分析
下一步重点: 模型部署常见误区
误区一:只记概念名称,不理解适用场景。
深度学习概念必须放回任务中理解。CNN 适合图像,是因为它利用了空间局部性;RNN 适合序列,是因为它显式处理时间顺序;Transformer 强大,是因为它能直接建模全局依赖。
误区二:训练集结果好就认为模型好。
训练集表现只能说明模型对已见样本拟合得好。真正重要的是验证集和测试集表现,尤其是测试集是否独立、是否没有参与调参。
误区三:忽略数据质量。
标注错误、样本偏差、类别不平衡和数据泄漏会直接破坏实验结论。很多项目失败不是模型不够先进,而是数据基础不可靠。
误区四:把代码跑通等同于掌握原理。
会调用框架只是第一步。能解释模型为什么有效、为什么失败、如何设计对照实验和如何分析错误样本,才是真正形成能力。
实践建议
学习本篇内容时,可以按"三步法"推进。第一步,先用纸笔画出数据从输入到输出的流程,确认自己知道每一步在做什么。第二步,运行文中的代码,并至少修改一个参数观察结果变化。第三步,尝试用自己的话解释三张配图,尤其要说清楚每个模块解决了什么问题。
对初学者来说,小实验比大工程更重要。一个能完全解释清楚的小例子,往往比一个复制粘贴的大模型更能建立长期能力。
本篇小结
本篇围绕"深度学习学习路线总结:从入门到科研与工程应用"展开,重点解释了相关概念为什么出现、解决什么问题,以及它在深度学习完整流程中的位置。需要记住的是:深度学习不是模型名称、公式和代码片段的堆叠,而是数据、结构、损失、优化、评估和应用场景共同构成的系统方法。理解核心机制,再通过小代码和小实验验证,是最稳妥的学习方式。
参考文献与推荐阅读
1 LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015 , 521 , 436--444. https://doi.org/10.1038/nature14539
2 Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning . MIT Press, 2016. https://www.deeplearningbook.org/
3 Nielsen, M. A. Neural Networks and Deep Learning . Determination Press, 2015. http://neuralnetworksanddeeplearning.com/
4 Géron, A. Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow , 3rd ed.; O'Reilly Media, 2022.
5 PyTorch Documentation. https://pytorch.org/docs/stable/index.html
6 Stanford CS231n: Convolutional Neural Networks for Visual Recognition. https://cs231n.stanford.edu/
7 Stanford CS224N: Natural Language Processing with Deep Learning. https://web.stanford.edu/class/cs224n/