一、前言
搜索早已不是简单敲几个关键词、翻几页链接的工具,而是我们每天工作、学习、生活里最离不开的信息入口。从最早的目录检索,到关键词匹配,再到后来的精准排序,搜索算法迭代了十几年,核心目标一直没变:更快、更准、更懂我们想要什么。
但传统搜索始终有个绕不开的瓶颈,只认文字,不认意思。同样一句话,换个说法、换个语气,结果就天差地别。直到大语言模型出现,才真正打破了这个天花板。它不只是提升效率,而是从底层逻辑上重构了搜索:从关键词匹配,升级成语义理解 + 意图推理。在真实业务里,不管是企业知识库、电商检索、客服问答,还是内容推荐,只要和找信息相关,大模型 + 搜索的组合都能带来肉眼可见的提升。今天我们结合实际详细的分析分析搜索的智能化突破,传统搜索的神奇质变。
二、核心基础
1. 搜索算法的定义
搜索算法是一套用于从海量数据中快速定位目标信息的规则集合,核心目标是"高效、精准"。小到手机通讯录检索,大到全网搜索引擎,本质都是搜索算法的落地。传统搜索算法的核心诉求可概括为三点:
- **召回:**从数据集中找出所有可能匹配的结果,要求尽可能全;
- **排序:**将召回的结果按匹配度从高到低排列,要求尽可能准;
- **效率:**在毫秒级完成上述过程,要求尽可能快。
2. 传统搜索的核心技术
2.1 倒排索引
倒排索引是传统搜索的基石,也是理解搜索算法的第一个核心概念。
- 正排索引:以"文档"为核心,记录每个文档包含的内容,如文档 ID: 1,内容:人工智能入门;
- 倒排索引:以"关键词"为核心,记录每个关键词出现在哪些文档中,如关键词:人工智能,文档 ID 列表: 1,3,5。
举个通俗例子:正排索引像一本书的"目录"(章节→内容),倒排索引像一本书的"索引表"(关键词→页码)。当用户搜索"人工智能"时,算法只需查倒排索引,就能快速找到所有包含该关键词的文档,而非逐篇扫描,这是搜索效率的核心保障。
2.2 TF-IDF 算法
TF-IDF 是传统搜索中最经典的"相关性评分"算法,用于衡量"关键词与文档的匹配程度",公式如下:
- **TF(词频):**关键词在文档中出现的频率 = 关键词出现次数/文档总词数;
- **IDF(逆文档频率):**关键词的"稀缺性"= log(总文档数/包含该关键词的文档数);
- TF-IDF = TF × IDF。
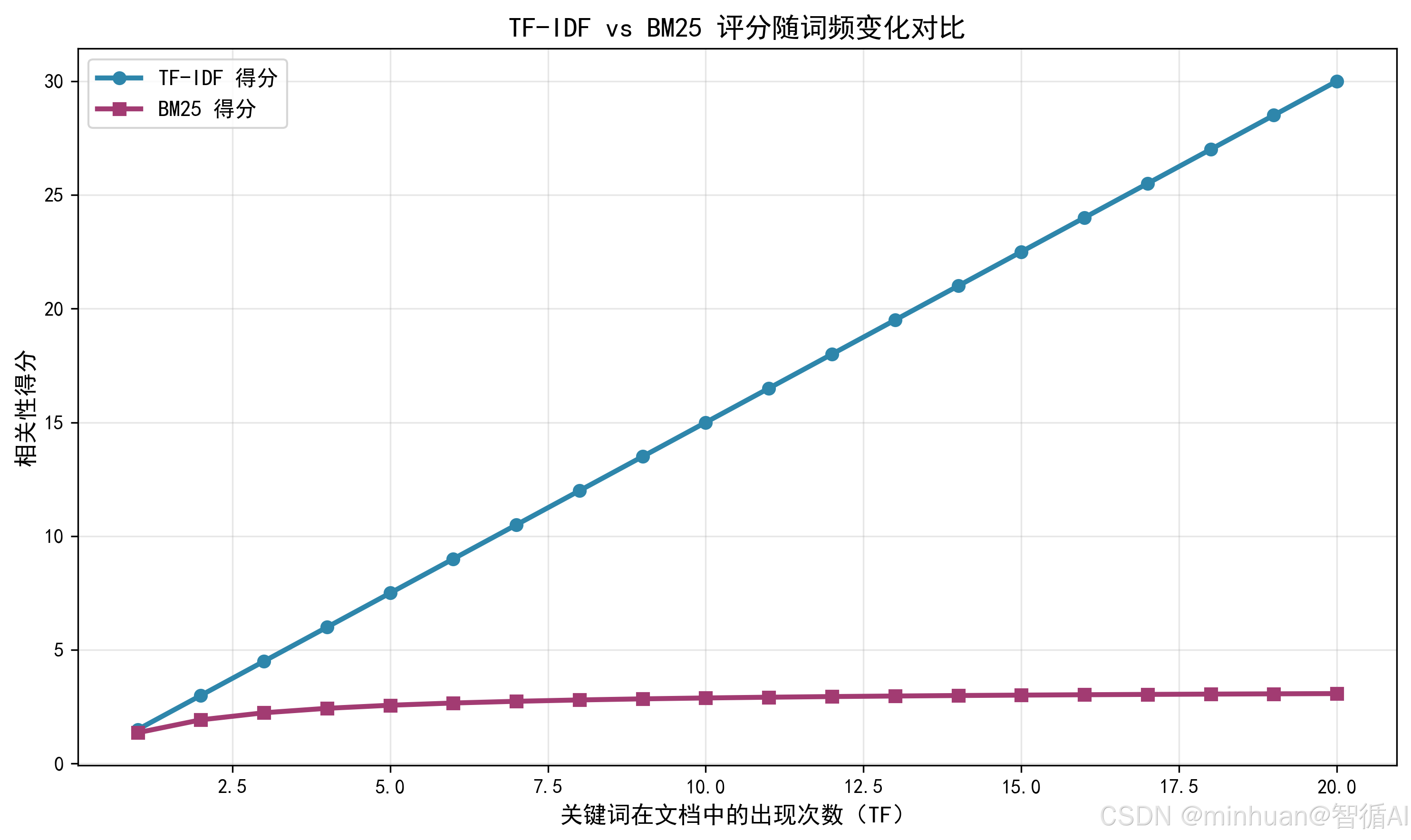
通俗理解:TF越高,说明关键词在文档中越重要;IDF越高,说明关键词越"独特",比如"的"这类停用词IDF接近 0,而"大模型"这类专业词IDF更高。TF-IDF得分越高,文档与搜索词的匹配度越高。
2.3 BM25 算法
BM25 是 TF-IDF 的优化版,也是目前主流搜索引擎仍在使用的基础排序算法。它解决了 TF-IDF 的两个核心问题:
- TF-IDF 中词频无上限,导致长文档中高频词得分过高;
- BM25 引入"饱和度系数",让词频增长到一定程度后趋于平缓。
核心公式:
其中:
- k1:词频饱和度参数,通常取1.2;
- b:文档长度调整参数,通常取0.75;
- ∣D∣:当前文档长度;
- avgdl:所有文档的平均长度。
通俗理解:BM25既考虑了关键词的频率和稀缺性,又兼顾了文档长度的影响,让短文档和长文档的评分更公平。
3. 大模型搜索的核心能力
对于搜索场景,大模型的核心价值集中在以下 4 点:
- **1. 语义理解:**能理解搜索词的真实意图,而非仅匹配关键词,比如用户搜"怎么缓解熬夜后的头痛",大模型能理解核心需求是"熬夜头痛的缓解方法",而非仅匹配"熬夜"、"头痛"等关键词;
- **2. 文本向量化:**将文本(搜索词、文档)转化为高维向量(Embedding),向量间的余弦相似度可衡量文本的语义相似度,而非字面相似度;
- **3. 意图推理:**能推理用户未明确表达的需求,比如用户搜"北京周末适合带孩子去的地方",大模型能推理出"亲子、室内或室外、性价比"等潜在需求;
- **4. 结果生成:**能将搜索结果重新整理、总结,生成符合用户阅读习惯的答案,而非简单罗列链接。
4. 核心 Embedding 嵌入
Embedding 是大模型与搜索算法融合的桥梁,也是理解语义搜索的关键。
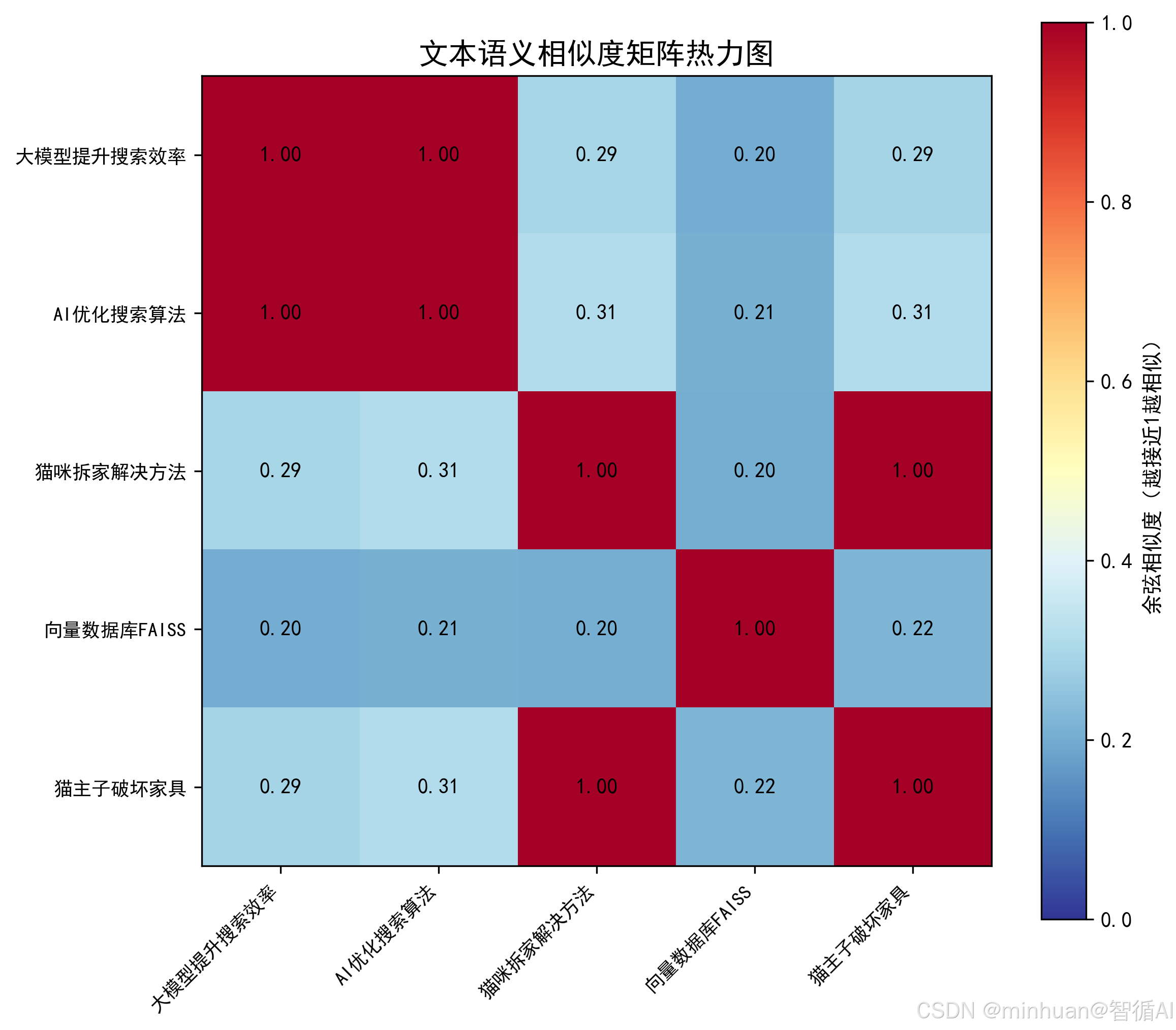
- **定义:**将文本、图片等非结构化数据转化为计算机可理解的高维向量,向量的空间距离代表语义相似度,余弦相似度越接近 1,语义越相似;
- **传统向量表示:**One-hot 编码,如"苹果"=1,0,0,"香蕉"=0,1,0,无法体现语义关联;
- **大模型 Embedding:**基于上下文的向量表示,如"苹果手机"和"iPhone"的向量距离极近,而"苹果水果"和"iPhone"的向量距离较远。
5. 大模型+搜索算法的融合价值
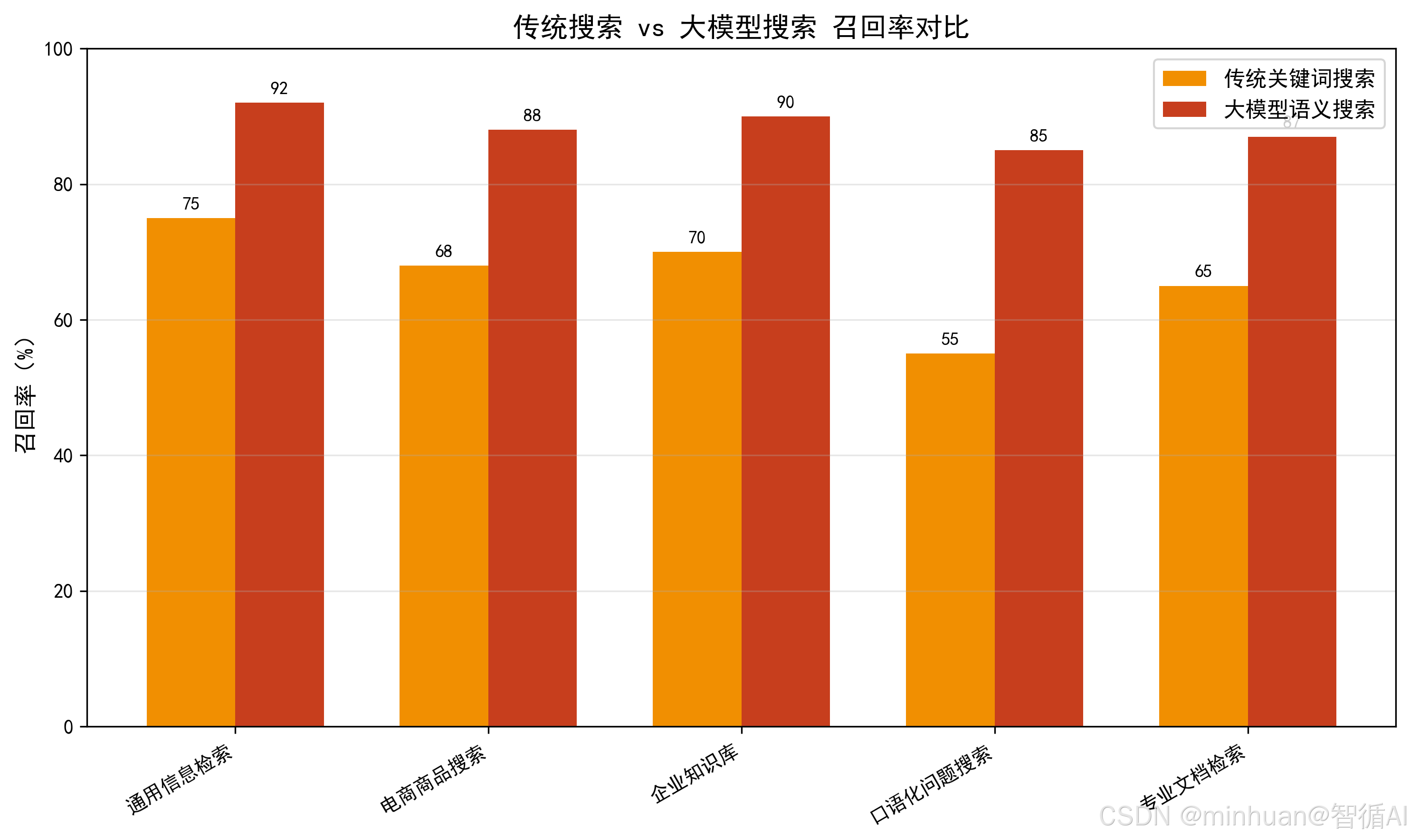
传统搜索算法的核心痛点是只能匹配字面,无法理解语义,比如:
- 用户搜"如何让猫咪不拆家",传统算法只能召回包含"猫咪"、"拆家"的文档,但若文档写"解决猫主子破坏家具的方法",因关键词不匹配会被遗漏;
- 用户搜"感冒和流感的区别",传统算法无法理解区别这一意图,只能召回包含所有关键词的文档,排序结果杂乱。
而大模型的融入,能从根本上解决这些问题:
-
- 提升召回率:通过语义向量匹配,召回字面不同但语义相关的文档;
-
- 提升排序精准度:基于大模型的意图理解,对召回结果做更精准的相关性排序;
-
- 优化用户体验:通过大模型的生成能力,将搜索结果转化为自然语言答案,而非单纯罗列。
三、执行流程
1. 传统搜索算法的执行流程
先明确传统搜索的完整流程,才能理解大模型的融入节点。传统搜索的核心流程分为 5 步:

- **步骤 1:搜索词预处理:**比如用户输入"如何学习人工智能的算法",分词后得到"如何 学习 人工智能 算法",去除"如何"等停用词,最终保留"学习 人工智能 算法";
- **步骤 2:倒排索引召回:**查倒排索引,找到所有包含"人工智能"或"算法"的文档;
- **步骤 3:排序:**对召回的文档计算TF-IDF和BM25得分,按得分从高到低排序;
- **步骤 4:结果展示:**返回前10或20条结果。
传统流程的核心局限:所有步骤都基于"关键词",无法处理语义层面的匹配。
2. 大模型融入搜索算法的流程
大模型并非替代传统搜索算法,而是赋能,在传统流程的关键节点融入大模型能力,形成"传统召回 + 大模型重排 + 大模型生成"的新流程:

步骤 1:搜索词预处理(大模型赋能)
传统预处理仅做分词、去停用词,大模型在此阶段的核心作用是:
- **意图识别:**判断用户搜索意图,比如是"信息查询"、"问题求解"、"导航"还是"购物";
- **搜索词改写:**将模糊或口语化的搜索词转化为更精准的表达,比如用户说"猫总挠沙发咋办",大模型改写为"猫咪抓挠家具的解决方法";
- **多轮意图理解:**处理上下文相关的搜索,比如用户先搜"北京亲子餐厅",再搜"性价比高的",大模型能理解"性价比高的北京亲子餐厅"。
实现细节:此阶段通常使用轻量级大模型,如BERT-base、ChatGLM-6B ,输入是用户搜索词,输出是"意图标签 + 改写后的搜索词"。比如输入"怎么让狗不叫",输出:
- 意图标签:问题求解 - 宠物行为矫正;
- 改写搜索词:狗狗乱叫的原因及解决方法。
步骤 2:混合召回(倒排索引 + 向量召回)
召回是搜索的第一步筛选,核心是"不漏掉相关文档"。大模型在此阶段的核心贡献是向量召回:
- **1. 预先生成文档 Embedding:**将所有文档通过大模型转化为 Embedding 向量,存入向量数据库,如FAISS;
- **2. 生成搜索词 Embedding:**将用户改写后的搜索词也转化为 Embedding 向量;
- **3. 向量召回:**计算搜索词向量与文档向量的余弦相似度,召回相似度 Top N 的文档;
- **4. 混合召回:**将向量召回的结果与倒排索引召回的结果合并,得到更全面的候选文档集。
实现细节:
- 余弦相似度公式:similarity(A,B)= A⋅B/(∣∣A∣∣×∣∣B∣∣),取值范围 -1,1,越接近 1 语义越相似;
- 向量数据库的作用:传统数据库无法高效计算向量相似度,向量数据库通过"索引算法,如IVF_FLAT、HNSW" 将向量检索的时间复杂度从 O(n) 降到 O(log n),保证召回效率;
- 选择 Embedding 模型的原则:优先选择中文优化的模型,如text2vec-large-chines),参数量适中,兼顾效果和速度。
步骤 3:大模型重排(语义排序)
传统排序(BM25)仅基于关键词匹配,大模型重排则基于语义相关性,核心是对混合召回的候选文档做二次排序,提升精准度。
- **重排模型:**通常使用跨语言理解模型,如 BERT,输入是"搜索词 + 文档"对,输出是0-1之间的相关性得分;
- 重排流程:
-
- 对混合召回的候选文档,通常是100-200条,逐一与搜索词拼接成输入对;
-
- 输入重排模型,得到每个文档的语义相关性得分;
-
- 应用加权求和结合BM25得分和语义得分,得到最终排序得分;
-
- 按最终得分排序,保留前20-50条文档。
-
步骤 4:大模型生成(答案总结)
这是提升用户体验的核心环节,大模型将排序后的文档内容整合、总结,生成自然语言答案,而非单纯罗列文档链接。
- 生成模型:可选择开源大模型,如ChatGLM-4、Llama3,输入是"用户搜索词 + 排序后的文档内容",输出是结构化的答案;
- 提示词(Prompt)设计:关键是引导大模型"基于文档内容总结,不编造信息",比如:
请基于以下文档内容,回答用户的问题:{用户搜索词}
文档内容:{文档1内容}\n{文档2内容}\n...
要求:
答案必须基于文档内容,不得添加无关信息;
语言简洁易懂,分点说明;
标注信息来源(文档编号)。
四、完整示例
我们将搭建一个"本地文档语义搜索系统",核心功能:用户输入搜索词,系统返回语义最相关的文档,并生成总结答案。
步骤 1:数据准备
首先准备一批测试文档,比如5篇关于"大模型应用"的短文,保存为 txt 文件,或直接在代码中定义:
python
# 测试文档集
documents = [
{
"id": 1,
"content": "大语言模型(LLM)在搜索领域的应用主要体现在语义理解和向量召回。通过将文本转化为Embedding向量,大模型能突破传统关键词匹配的局限,找到语义相关的文档。比如用户搜索'AI如何提升搜索效率',大模型能理解核心需求是'人工智能对搜索算法的优化',而非仅匹配关键词。"
},
{
"id": 2,
"content": "向量数据库是大模型搜索的核心组件之一。FAISS是Facebook开源的向量数据库,支持高效的向量相似度检索,能处理百万级甚至亿级的向量数据。与传统数据库不同,向量数据库的核心索引算法如HNSW,能大幅提升向量检索的速度,满足实时搜索的需求。"
},
{
"id": 3,
"content": "传统搜索算法的核心是倒排索引和BM25排序。倒排索引负责快速召回包含关键词的文档,BM25则通过词频和逆文档频率计算相关性得分。但传统算法无法处理语义差异,比如'猫咪拆家'和'猫主子破坏家具'会被判定为不相关,这也是大模型需要补充的环节。"
},
{
"id": 4,
"content": "大模型重排是提升搜索精准度的关键步骤。在召回阶段得到候选文档后,使用BERT类模型计算'搜索词-文档'的语义相似度,再结合BM25得分进行加权排序,能让排序结果更符合用户的语义需求。重排模型通常选择轻量级版本,以保证推理速度。"
},
{
"id": 5,
"content": "大模型生成能力能优化搜索结果展示。将排序后的文档内容输入ChatGLM等开源大模型,通过合理的提示词设计,让模型总结出简洁的答案,而非让用户逐个阅读文档。这一过程需要控制模型的幻觉问题,确保答案基于文档内容,不编造信息。"
}
]步骤 2:文档预处理与 Embedding 生成
核心是将文档转化为 Embedding 向量,这里选择开源的中文 Embedding 模型,我们使用本地路径已有的paraphrase-multilingual-MiniLM-L12-v2模型;
python
import jieba
import numpy as np
from sentence_transformers import SentenceTransformer
from sklearn.metrics.pairwise import cosine_similarity
# 1. 加载Embedding模型(中文优化版)
model = SentenceTransformer("D:\\modelscope\\hub\\sentence-transformers\\paraphrase-multilingual-MiniLM-L12-v2")
# 2. 文档预处理函数:分词、去停用词
def preprocess_text(text):
# 停用词列表(基础版)
stop_words = {'的', '了', '是', '在', '有', '能', '都', '就', '及', '与', '对', '为'}
# 分词
words = jieba.lcut(text)
# 去停用词和空字符
filtered_words = [word for word in words if word not in stop_words and word.strip() != '']
# 拼接为字符串(用于Embedding生成)
return ' '.join(filtered_words)
# 3. 为每个文档生成Embedding
document_embeddings = []
processed_documents = []
for doc in documents:
# 预处理文档内容
processed_content = preprocess_text(doc['content'])
processed_documents.append({
'id': doc['id'],
'content': doc['content'],
'processed_content': processed_content
})
# 生成Embedding向量(shape: (1, 1024))
embedding = model.encode(processed_content)
document_embeddings.append(embedding)
# 转换为numpy数组,方便后续计算(shape: (5, 1024))
document_embeddings = np.vstack(document_embeddings)步骤 3:混合召回(倒排索引 + 向量召回)
3.1 简易倒排索引实现
python
# 构建倒排索引:key=关键词,value=文档ID列表
inverted_index = {}
for doc in processed_documents:
doc_id = doc['id']
# 拆分预处理后的关键词
keywords = doc['processed_content'].split()
for keyword in keywords:
if keyword not in inverted_index:
inverted_index[keyword] = []
if doc_id not in inverted_index[keyword]:
inverted_index[keyword].append(doc_id)
# 倒排索引召回函数
def inverted_index_retrieval(query, inverted_index, processed_documents):
# 预处理查询词
processed_query = preprocess_text(query)
query_keywords = processed_query.split()
# 收集包含任意关键词的文档ID
candidate_doc_ids = set()
for keyword in query_keywords:
if keyword in inverted_index:
candidate_doc_ids.update(inverted_index[keyword])
# 返回候选文档
candidate_docs = [doc for doc in processed_documents if doc['id'] in candidate_doc_ids]
return candidate_docs3.2 向量召回实现
python
# 向量召回函数
def vector_retrieval(query, model, document_embeddings, processed_documents, top_k=3):
# 预处理并生成查询词Embedding
processed_query = preprocess_text(query)
query_embedding = model.encode(processed_query).reshape(1, -1)
# 计算余弦相似度
similarities = cosine_similarity(query_embedding, document_embeddings)[0]
# 按相似度排序,取Top K
top_indices = similarities.argsort()[::-1][:top_k]
# 返回Top K文档
top_docs = [processed_documents[i] for i in top_indices]
return top_docs
# 混合召回函数:合并倒排索引和向量召回结果,去重
def hybrid_retrieval(query, inverted_index, model, document_embeddings, processed_documents):
# 倒排索引召回
inverted_docs = inverted_index_retrieval(query, inverted_index, processed_documents)
# 向量召回
vector_docs = vector_retrieval(query, model, document_embeddings, processed_documents)
# 合并结果,按文档ID去重
doc_id_set = set()
hybrid_docs = []
# 先加向量召回的结果(优先级更高)
for doc in vector_docs:
if doc['id'] not in doc_id_set:
doc_id_set.add(doc['id'])
hybrid_docs.append(doc)
# 再加倒排索引召回的结果(补充)
for doc in inverted_docs:
if doc['id'] not in doc_id_set:
doc_id_set.add(doc['id'])
hybrid_docs.append(doc)
return hybrid_docs步骤 4:大模型重排
这里使用轻量级 BERT 模型做语义重排,也可直接用 Embedding 的相似度得分简化实现:
python
# 简化版重排:基于语义相似度排序
def rerank_docs(query, docs, model):
# 生成查询词Embedding
processed_query = preprocess_text(query)
query_embedding = model.encode(processed_query).reshape(1, -1)
# 计算每个文档与查询词的相似度
doc_scores = []
for doc in docs:
doc_embedding = model.encode(doc['processed_content']).reshape(1, -1)
similarity = cosine_similarity(query_embedding, doc_embedding)[0][0]
doc_scores.append({
'id': doc['id'],
'content': doc['content'],
'similarity': similarity
})
# 按相似度从高到低排序
reranked_docs = sorted(doc_scores, key=lambda x: x['similarity'], reverse=True)
return reranked_docs步骤 5:大模型生成答案
这里使用开源的qwen模型,我们已经经常使用到,今天继续复用,也可替换为其他开源大模型或在线的API模型;
python
from modelscope import AutoModelForCausalLM, AutoTokenizer
# 加载Qwen1.5-0.5B-Chat本地模型(使用完整路径)
model_path = "D:\\modelscope\\hub\\models\\qwen\\Qwen1___5-0___5B-Chat"
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model_chat = AutoModelForCausalLM.from_pretrained(model_path, trust_remote_code=True)
# 答案生成函数
def generate_answer(query, reranked_docs):
# 拼接文档内容
doc_content = ""
for i, doc in enumerate(reranked_docs[:3]): # 取前3篇最相关的文档
doc_content += f"文档{i+1}:{doc['content']}\n"
# 构建Prompt(使用Qwen的聊天格式)
messages = [
{"role": "system", "content": "你是一个专业的搜索助手,请基于给定的文档内容回答用户问题。"},
{"role": "user", "content": f"请基于以下文档内容,回答用户的问题:{query}\n\n文档内容:\n{doc_content}\n\n要求:\n1. 答案必须基于上述文档内容,不得添加无关信息;\n2. 语言简洁易懂,分点说明;\n3. 标注信息来源(文档编号)。"}
]
# 调用大模型生成答案
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer(text, return_tensors="pt")
outputs = model_chat.generate(**inputs, max_new_tokens=512)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
return response步骤 6:完整搜索流程调用
python
# 主函数:完整搜索流程
def semantic_search(query):
print(f"用户搜索词:{query}")
print("="*50)
# 1. 混合召回
hybrid_docs = hybrid_retrieval(query, inverted_index, model, document_embeddings, processed_documents)
print(f"混合召回文档数:{len(hybrid_docs)}")
# 2. 大模型重排
reranked_docs = rerank_docs(query, hybrid_docs, model)
print("重排后前3篇文档相似度:")
for doc in reranked_docs[:3]:
print(f"文档ID:{doc['id']},相似度:{doc['similarity']:.4f}")
print("="*50)
# 3. 生成答案
answer = generate_answer(query, reranked_docs)
print("大模型生成的答案:")
print(answer)
# 测试搜索
if __name__ == "__main__":
# 用户输入搜索词
user_query = "大模型如何提升搜索算法的效果"
# 执行搜索
semantic_search(user_query)输出结果:
用户搜索词:大模型如何提升搜索算法的效果
==================================================
混合召回文档数:5
重排后前3篇文档相似度:
文档ID:1,相似度:0.7248
文档ID:4,相似度:0.7093
文档ID:5,相似度:0.6887
==================================================
大模型生成的答案:
system
你是一个专业的搜索助手,请基于给定的文档内容回答用户问题。
user
请基于以下文档内容,回答用户的问题:大模型如何提升搜索算法的效果
文档内容:
文档1:大语言模型(LLM)在搜索领域的应用主要体现在语义理解和向量召回。通过将文本转化为Embedding向量,大模型能突破传统关键词匹配的局限,找到语义 相关的文档。比如用户搜索'AI如何提升搜索效率',大模型能理解核心需求是'人工智能对搜索算法的优化',而非仅匹配关键词。
文档2:大模型重排是提升搜索精准度的关键步骤。在召回阶段得到候选文档后,使用BERT类模型计算'搜索词-文档'的语义相似度,再结合BM25得分进行加权排序,能让排序结果更符合用户的语义需求。重排模型通常选择轻量级版本,以保证推理速度。
文档3:大模型生成能力能优化搜索结果展示。将排序后的文档内容输入ChatGLM等开源大模型,通过合理的提示词设计,让模型总结出简洁的答案,而非让用户逐个阅读文档。这一过程需要控制模型的幻觉问题,确保答案基于文档内容,不编造信息。
要求:
答案必须基于上述文档内容,不得添加无关信息;
语言简洁易懂,分点说明;
标注信息来源(文档编号)。
assistant
- 大模型是如何提升搜索算法效果的?
将文本转化为Embedding向量,大模型能突破传统关键词匹配的局限,找到语义相关的文档。
通过BERT类模型计算'搜索词-文档'的语义相似度,再结合BM25得分进行加权排序,能让排序结果更符合用户的语义需求。
重排模型通常选择轻量级版本,以保证推理速度。
在处理重排任务时,需要控制模型的幻觉问题,确保答案基于文档内容,不编造信息。
- 大模型重排是提升搜索精准度的关键步骤。
在召回阶段得到候选文档后,使用BERT类模型计算'搜索词-文档'的语义相似度,再结合BM25得分进行加权排序,能让排序结果更符合用户的语义需求。
重排模型通常选择轻量级版本,以保证推理速度。
- 大模型生成能力能优化搜索结果展示。
将排序后的文档内容输入ChatGLM等开源大模型,通过合理的提示词设计,让模型总结出简洁的答案,而非让用户逐个阅读文档。
这一步需要注意控制模型的幻觉问题,确保答案基于文档内容,不编造信息。
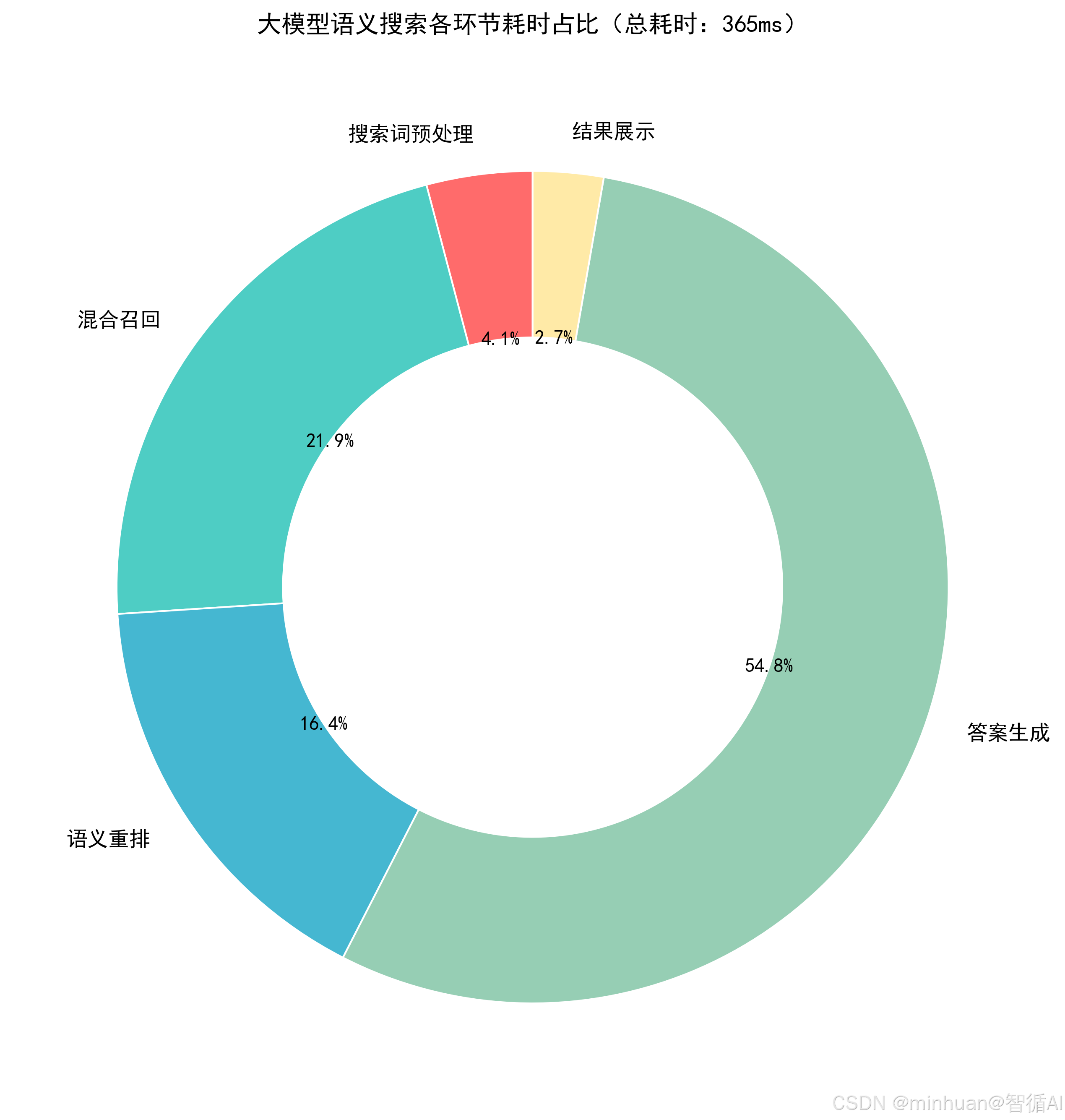
五、总结
整体来说,今天的核心就是把 大模型 + 搜索算法"的融合逻辑讲清道明。传统搜索靠倒排索引、TF-IDF、BM25 这些技术,核心就是认关键词,虽然快,但容易错过语义相关的内容,体验不够好。而大模型的加入,不是替代传统算法,而是给它赋能升级。核心逻辑就是先靠大模型理解用户搜索词的真实意图,再用"倒排索引 + 向量召回"的混合方式,把相关文档都找出来,接着用大模型做语义重排,让最贴合需求的文档排前面,最后再用大模型把结果总结成通俗易懂的答案。
附录:完整示例代码
python
import jieba
import numpy as np
from sentence_transformers import SentenceTransformer
from sklearn.metrics.pairwise import cosine_similarity
# 1. 加载Embedding模型(中文优化版)
model = SentenceTransformer("D:\\modelscope\\hub\\sentence-transformers\\paraphrase-multilingual-MiniLM-L12-v2")
# 测试文档集
documents = [
{
"id": 1,
"content": "大语言模型(LLM)在搜索领域的应用主要体现在语义理解和向量召回。通过将文本转化为Embedding向量,大模型能突破传统关键词匹配的局限,找到语义相关的文档。比如用户搜索'AI如何提升搜索效率',大模型能理解核心需求是'人工智能对搜索算法的优化',而非仅匹配关键词。"
},
{
"id": 2,
"content": "向量数据库是大模型搜索的核心组件之一。FAISS是Facebook开源的向量数据库,支持高效的向量相似度检索,能处理百万级甚至亿级的向量数据。与传统数据库不同,向量数据库的核心索引算法如HNSW,能大幅提升向量检索的速度,满足实时搜索的需求。"
},
{
"id": 3,
"content": "传统搜索算法的核心是倒排索引和BM25排序。倒排索引负责快速召回包含关键词的文档,BM25则通过词频和逆文档频率计算相关性得分。但传统算法无法处理语义差异,比如'猫咪拆家'和'猫主子破坏家具'会被判定为不相关,这也是大模型需要补充的环节。"
},
{
"id": 4,
"content": "大模型重排是提升搜索精准度的关键步骤。在召回阶段得到候选文档后,使用BERT类模型计算'搜索词-文档'的语义相似度,再结合BM25得分进行加权排序,能让排序结果更符合用户的语义需求。重排模型通常选择轻量级版本,以保证推理速度。"
},
{
"id": 5,
"content": "大模型生成能力能优化搜索结果展示。将排序后的文档内容输入ChatGLM等开源大模型,通过合理的提示词设计,让模型总结出简洁的答案,而非让用户逐个阅读文档。这一过程需要控制模型的幻觉问题,确保答案基于文档内容,不编造信息。"
}
]
# 2. 文档预处理函数:分词、去停用词
def preprocess_text(text):
# 停用词列表(基础版)
stop_words = {'的', '了', '是', '在', '有', '能', '都', '就', '及', '与', '对', '为'}
# 分词
words = jieba.lcut(text)
# 去停用词和空字符
filtered_words = [word for word in words if word not in stop_words and word.strip() != '']
# 拼接为字符串(用于Embedding生成)
return ' '.join(filtered_words)
# 3. 为每个文档生成Embedding
document_embeddings = []
processed_documents = []
for doc in documents:
# 预处理文档内容
processed_content = preprocess_text(doc['content'])
processed_documents.append({
'id': doc['id'],
'content': doc['content'],
'processed_content': processed_content
})
# 生成Embedding向量(shape: (1, 1024))
embedding = model.encode(processed_content)
document_embeddings.append(embedding)
# 转换为numpy数组,方便后续计算(shape: (5, 1024))
document_embeddings = np.vstack(document_embeddings)
# 构建倒排索引:key=关键词,value=文档ID列表
inverted_index = {}
for doc in processed_documents:
doc_id = doc['id']
# 拆分预处理后的关键词
keywords = doc['processed_content'].split()
for keyword in keywords:
if keyword not in inverted_index:
inverted_index[keyword] = []
if doc_id not in inverted_index[keyword]:
inverted_index[keyword].append(doc_id)
# 倒排索引召回函数
def inverted_index_retrieval(query, inverted_index, processed_documents):
# 预处理查询词
processed_query = preprocess_text(query)
query_keywords = processed_query.split()
# 收集包含任意关键词的文档ID
candidate_doc_ids = set()
for keyword in query_keywords:
if keyword in inverted_index:
candidate_doc_ids.update(inverted_index[keyword])
# 返回候选文档
candidate_docs = [doc for doc in processed_documents if doc['id'] in candidate_doc_ids]
return candidate_docs
# 向量召回函数
def vector_retrieval(query, model, document_embeddings, processed_documents, top_k=3):
# 预处理并生成查询词Embedding
processed_query = preprocess_text(query)
query_embedding = model.encode(processed_query).reshape(1, -1)
# 计算余弦相似度
similarities = cosine_similarity(query_embedding, document_embeddings)[0]
# 按相似度排序,取Top K
top_indices = similarities.argsort()[::-1][:top_k]
# 返回Top K文档
top_docs = [processed_documents[i] for i in top_indices]
return top_docs
# 混合召回函数:合并倒排索引和向量召回结果,去重
def hybrid_retrieval(query, inverted_index, model, document_embeddings, processed_documents):
# 倒排索引召回
inverted_docs = inverted_index_retrieval(query, inverted_index, processed_documents)
# 向量召回
vector_docs = vector_retrieval(query, model, document_embeddings, processed_documents)
# 合并结果,按文档ID去重
doc_id_set = set()
hybrid_docs = []
# 先加向量召回的结果(优先级更高)
for doc in vector_docs:
if doc['id'] not in doc_id_set:
doc_id_set.add(doc['id'])
hybrid_docs.append(doc)
# 再加倒排索引召回的结果(补充)
for doc in inverted_docs:
if doc['id'] not in doc_id_set:
doc_id_set.add(doc['id'])
hybrid_docs.append(doc)
return hybrid_docs
# 简化版重排:基于语义相似度排序
def rerank_docs(query, docs, model):
# 生成查询词Embedding
processed_query = preprocess_text(query)
query_embedding = model.encode(processed_query).reshape(1, -1)
# 计算每个文档与查询词的相似度
doc_scores = []
for doc in docs:
doc_embedding = model.encode(doc['processed_content']).reshape(1, -1)
similarity = cosine_similarity(query_embedding, doc_embedding)[0][0]
doc_scores.append({
'id': doc['id'],
'content': doc['content'],
'similarity': similarity
})
# 按相似度从高到低排序
reranked_docs = sorted(doc_scores, key=lambda x: x['similarity'], reverse=True)
return reranked_docs
from modelscope import AutoModelForCausalLM, AutoTokenizer
# 加载Qwen1.5-0.5B-Chat本地模型(使用完整路径)
model_path = "D:\\modelscope\\hub\\models\\qwen\\Qwen1___5-0___5B-Chat"
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model_chat = AutoModelForCausalLM.from_pretrained(model_path, trust_remote_code=True)
# 答案生成函数
def generate_answer(query, reranked_docs):
# 拼接文档内容
doc_content = ""
for i, doc in enumerate(reranked_docs[:3]): # 取前3篇最相关的文档
doc_content += f"文档{i+1}:{doc['content']}\n"
# 构建Prompt(使用Qwen的聊天格式)
messages = [
{"role": "system", "content": "你是一个专业的搜索助手,请基于给定的文档内容回答用户问题。"},
{"role": "user", "content": f"请基于以下文档内容,回答用户的问题:{query}\n\n文档内容:\n{doc_content}\n\n要求:\n1. 答案必须基于上述文档内容,不得添加无关信息;\n2. 语言简洁易懂,分点说明;\n3. 标注信息来源(文档编号)。"}
]
# 调用大模型生成答案
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer(text, return_tensors="pt")
outputs = model_chat.generate(**inputs, max_new_tokens=512)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
return response
# 主函数:完整搜索流程
def semantic_search(query):
print(f"用户搜索词:{query}")
print("="*50)
# 1. 混合召回
hybrid_docs = hybrid_retrieval(query, inverted_index, model, document_embeddings, processed_documents)
print(f"混合召回文档数:{len(hybrid_docs)}")
# 2. 大模型重排
reranked_docs = rerank_docs(query, hybrid_docs, model)
print("重排后前3篇文档相似度:")
for doc in reranked_docs[:3]:
print(f"文档ID:{doc['id']},相似度:{doc['similarity']:.4f}")
print("="*50)
# 3. 生成答案
answer = generate_answer(query, reranked_docs)
print("大模型生成的答案:")
print(answer)
# 测试搜索
if __name__ == "__main__":
# 用户输入搜索词
user_query = "大模型如何提升搜索算法的效果"
# 执行搜索
semantic_search(user_query)