一、核心概念
1. 大模型服务监控
传统业务监控只关注接口响应、CPU内存、网络状态,完全适配不了大模型推理场景。大模型服务监控是面向推理全链路的专属可观测体系,覆盖请求接入、文本分词、模型前向计算、Token 生成、结果返回、资源释放全部环节。
它不是简单的服务器资源查看,而是针对大模型GPU 依赖、Token生成、排队推理、显存波动独有特性设计的监控体系,专门解决普通监控无法识别的模型级故障与性能瓶颈。

2. 大模型监控的核心价值
- **服务可用性兜底:**实时感知进程卡死、推理超时、显存溢出、端口离线等隐性故障,提前拦截业务中断风险。
- **推理性能精准调优:**依托耗时、Token生成速率定位预处理瓶颈、算力瓶颈、并发调度瓶颈,针对性优化响应体验。
- **算力成本精细化管控:**精准观测GPU显存使用率、空闲算力、峰值负载,避免资源闲置浪费或过载宕机。
- **业务体验持续稳定:**把控请求排队时长、首Token响应速度,从用户感知层面优化对话生成体验。
- **运维模式主动升级:**依靠自动化健康巡检,实现事前预警、事后溯源,摆脱故障发生后被动抢修的传统运维模式。
3. 核心基础概念
- **推理:**大模型接收用户输入文本,经过模型计算生成回复内容的完整执行过程,是监控的核心观测对象。
- **Token:**大模型语义计算的最小单元,中英文都会被分词器切割为固定Token,直接决定计算量与生成速度。
- **显存:**GPU专属高速内存,模型权重参数、推理中间张量、批量请求缓存全部占用显存,是大模型最核心稀缺资源。
- **请求队列:**当并发请求超出模型瞬时推理能力时,多余请求进入排队队列等待调度,队列状态直接影响延迟与稳定性。
- **推理耗时:**从请求到达服务开始,到完整结果返回客户端的全链路耗时,拆分首Token耗时与总推理耗时两个维度。
- **健康巡检:**按照固定频率自动检测服务进程、接口连通性、资源负载、性能基线、错误率,综合判定服务健康等级。
二、监控核心指标
1. 推理耗时
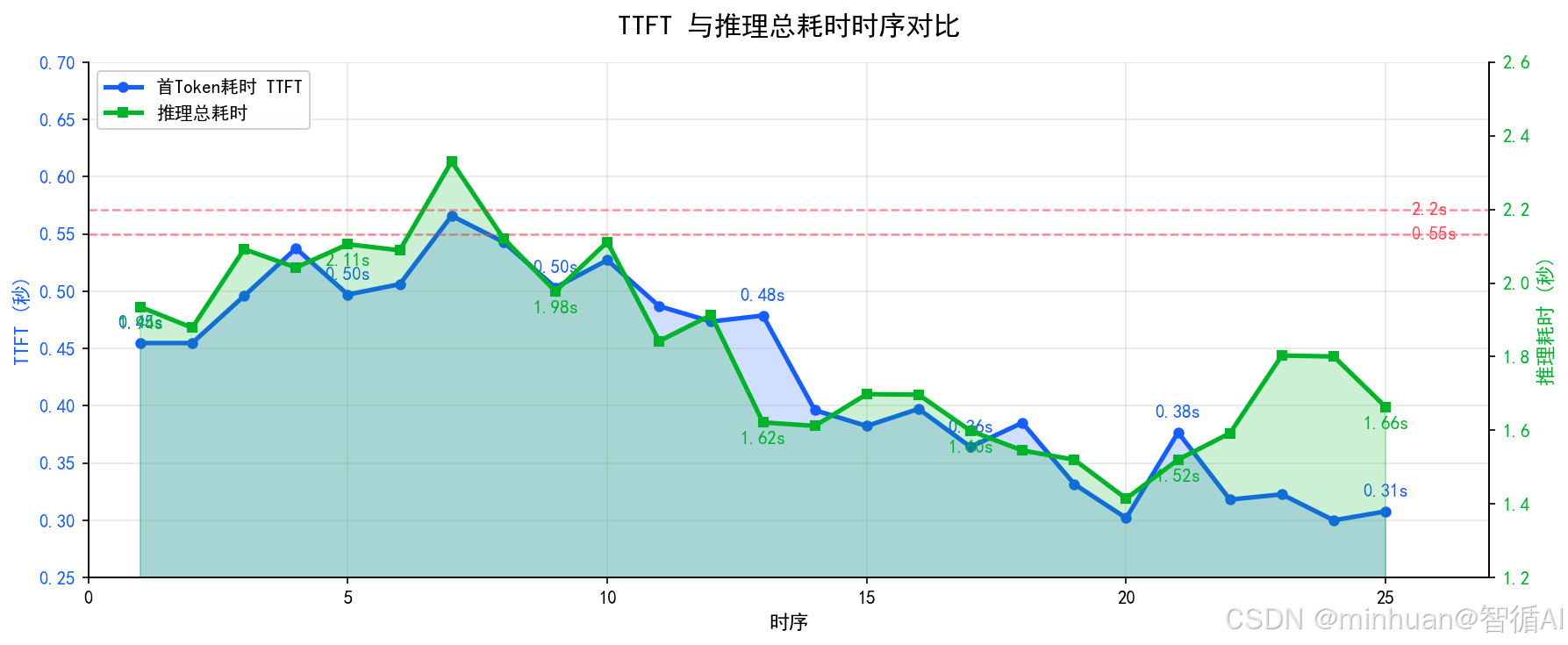
推理耗时是衡量大模型服务响应能力的第一优先级指标,也是用户最直观能感受到的体验指标。分为首Token耗时TTFT和完整推理总耗时两个维度,不能只用单一总耗时做评判。
细分维度:
-
- 首Token耗时(TTFT):用户最直观感知指标,决定服务响应速度
-
- 全量推理耗时:完整生成结果的时间,反映模型计算效率
-
- 分接口耗时:流式接口、批量接口、健康检查接口独立耗时
-
- 分模型耗时:多模型部署时,单个模型的推理耗时
-
- 多模型混合部署场景下,还可以按模型维度单独统计7B、13B等不同规格模型的推理耗时,做横向性能对比。
监控意义:
- 日常运维中,首Token耗时偏高,大多源于模型冷启动、预处理逻辑冗余、GPU算力调度争抢;
- 总耗时波动过大,多和显存碎片、队列拥堵、并发过载强相关。
- 阈值建议:通用对话模型TTFT<1s,全量耗时<10s,需根据业务调整
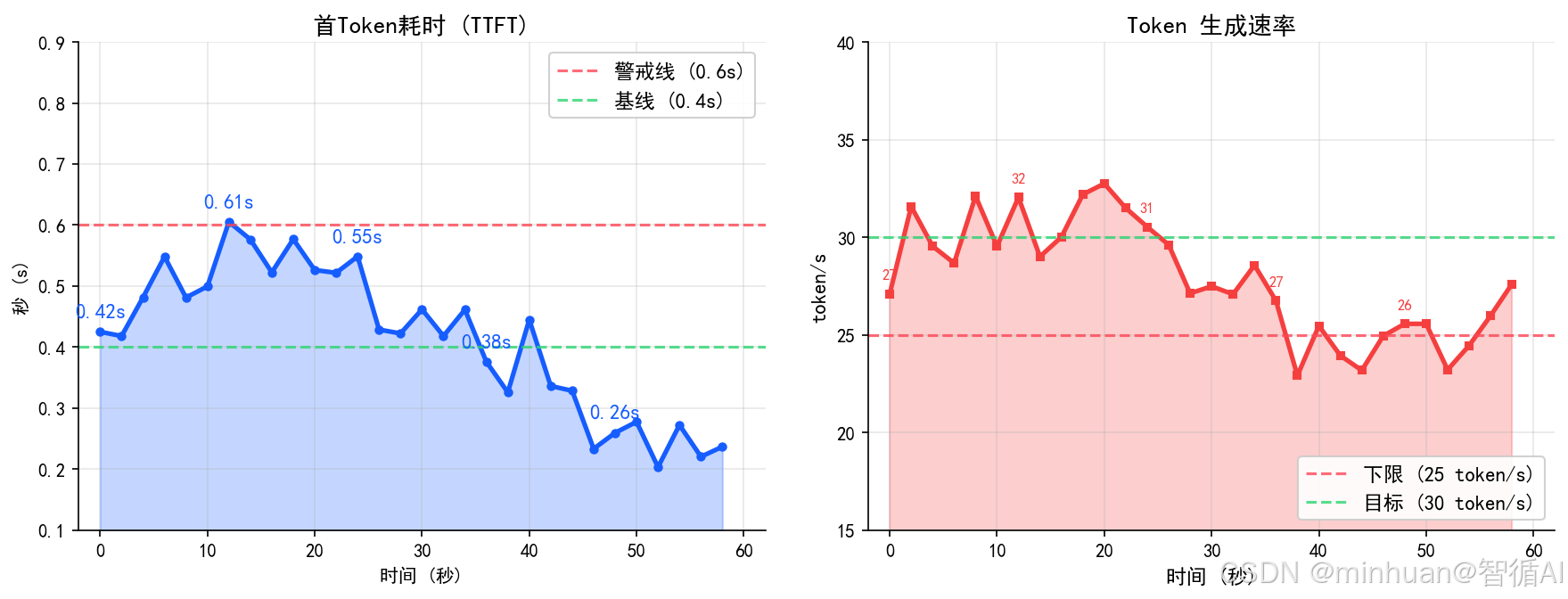
2. Token速率
Token速率以Token/秒为单位,代表大模型文本生成的核心效率,是评估模型吞吐能力的关键指标。主要分为输入Token速率、输出Token速率、单请求平均 Token数、全局总Token吞吐量四类观测维度。
细分维度:
-
- 输出Token速率是业务最关注的核心,数值越高代表文本生成越快,同等算力下能承载更多并发请求。
-
- 单请求Token 统计可以感知业务变化,比如超长文案生成、多轮对话上下文叠加,都会拉高单请求Token总量,拖累整体性能。
-
- 全局Token吞吐量用于评估服务整体负载水位,为扩容、限流、调度策略调整提供数据依据。
监控意义:
- 一旦Token速率持续走低,大概率是显存资源不足、GPU算力未跑满、请求队列阻塞、批量推理参数配置不合理导致。
- 阈值建议:通用7B模单卡输出速率≥20 Token/s
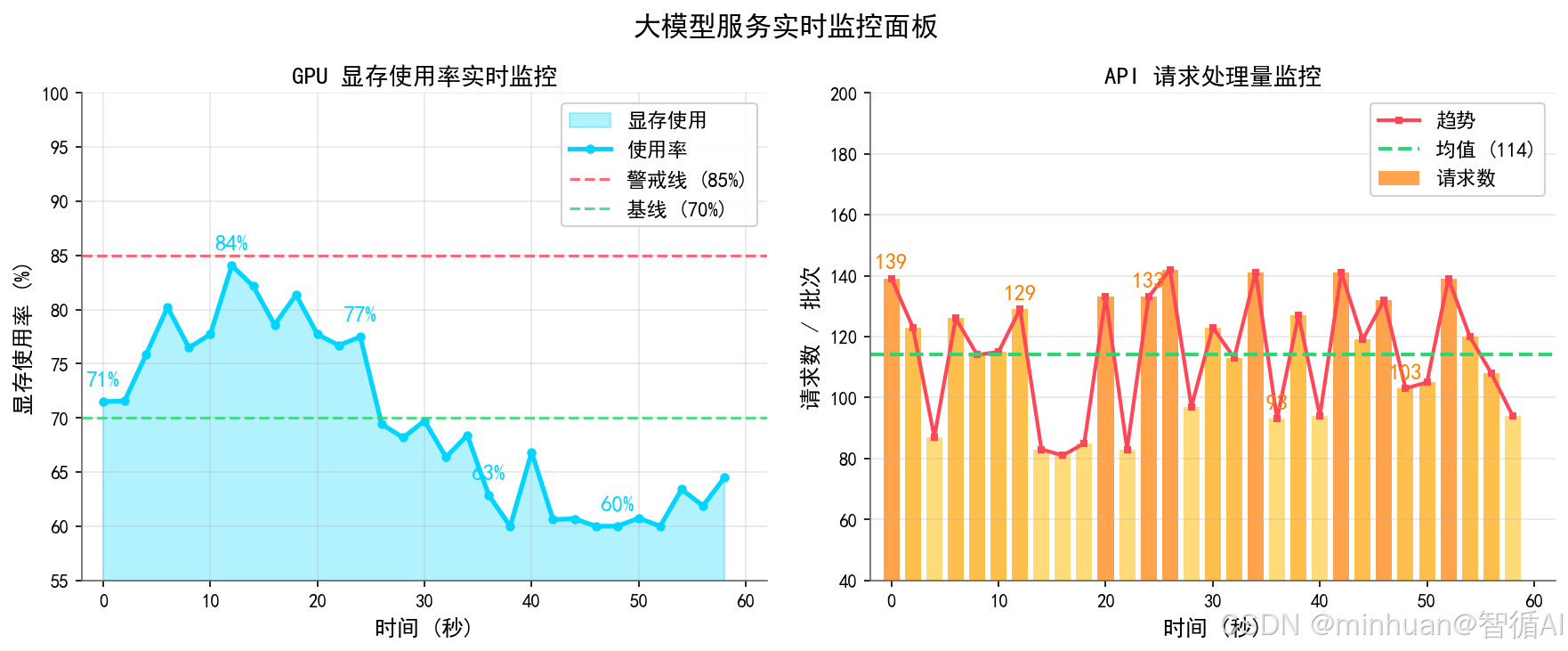
3. 显存占用
显存是大模型运行的生命线,几乎所有线上崩溃故障都和显存溢出、显存占用过高直接相关。监控显存不能只看整体使用率,需要拆分为模型权重固定显存、推理动态计算显存、瞬时峰值显存、显存碎片率。
细分维度:
-
- 模型权重显存是模型加载后就固定占用的空间,和模型参数量、量化等级直接相关,属于静态资源开销。
-
- 动态计算显存是每一次推理过程中临时创建的张量、缓存上下文占用的显存,会随并发量动态波动。
-
- 峰值显存记录单次推理的最大显存占用,用来评估模型极限负载能力,避免高并发下突发OOM。
-
- 显存碎片率代表空闲显存无法被重新分配的比例,碎片过高会明明有空闲显存却无法分配,直接拉低推理性能。
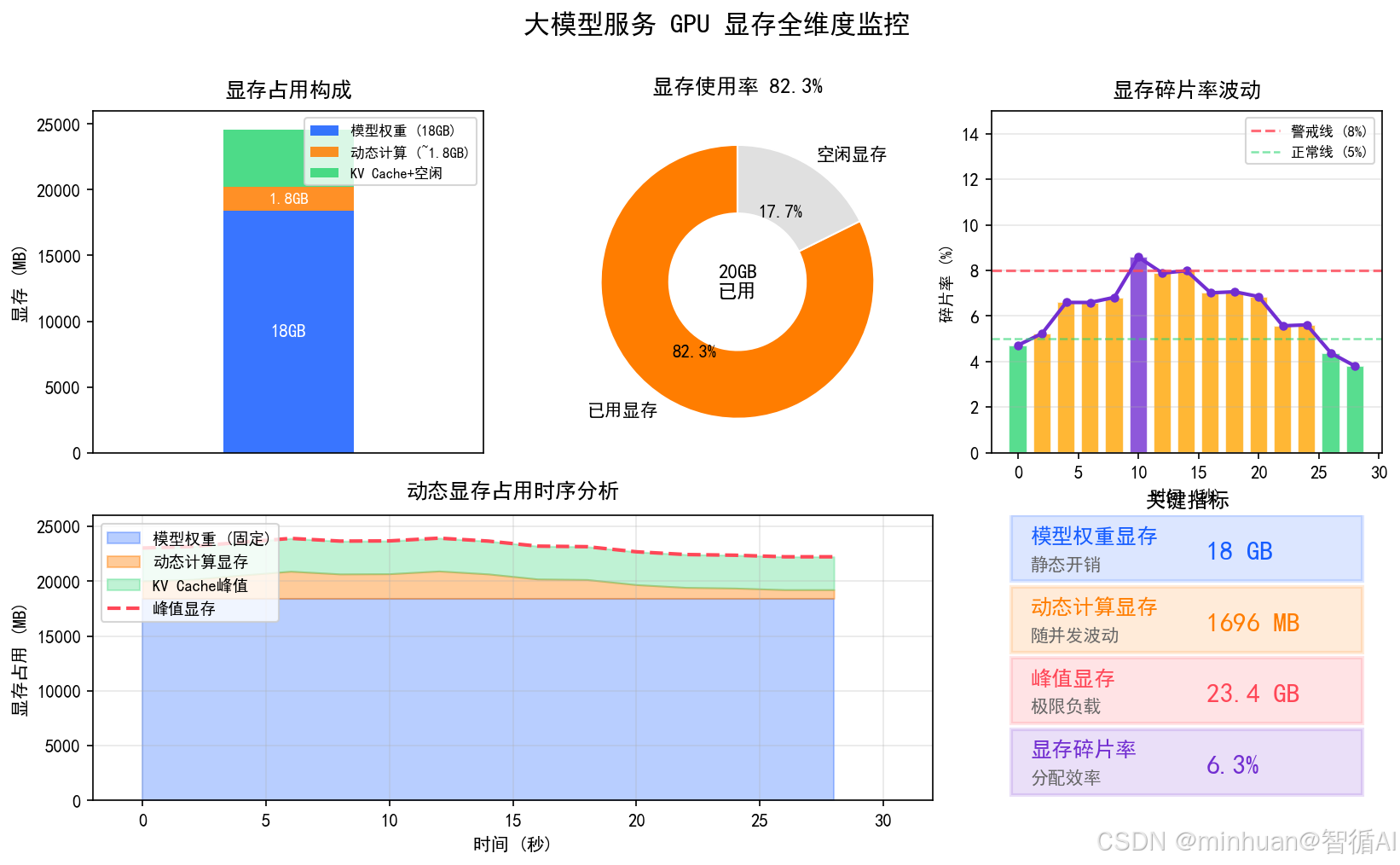
监控意义:
- 运维中显存使用率长期超过90%,极易触发显存溢出导致服务重启;
- 碎片率偏高则需要定时重启服务做资源整理。
4. 队列长度
大模型推理无法无限制并发,受限于 GPU 算力与显存上限,必然会产生请求排队机制,队列长度是并发治理的核心指标。重点观测实时当前队列数、历史队列峰值、单请求平均排队等待时长、队列溢出拒绝请求数量。
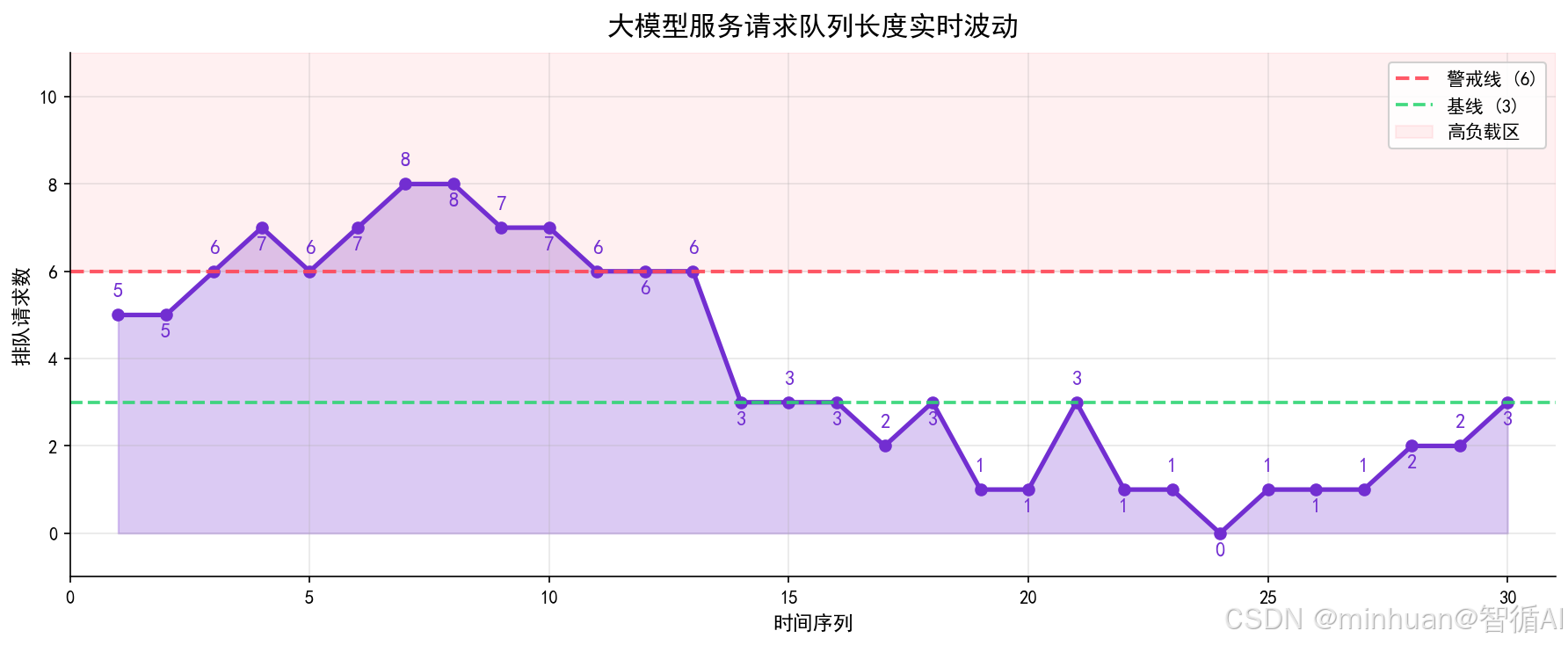
细分维度:
-
- 实时队列长度可以直观判断当前负载水位,队列持续有积压,说明现有算力无法承载当前并发流量。
-
- 队列等待时长直接关联用户体验,排队时间越长,用户等待感知越差,甚至触发客户端超时。
-
- 队列溢出数是严重故障指标,代表请求超出最大队列上限被直接丢弃,会造成业务请求失败、用户流失。
监控意义:
- 通过队列指标可以精准设定限流阈值、自动扩容触发条件、长短请求拆分调度策略,实现流量削峰填谷。
- 等待时长>5s,会导致用户体验极差;
5. 错误类型
大模型服务的报错和普通接口报错差异极大,需要按层级分类统计,才能精准定位根因。整体划分为服务层错误、推理层错误、硬件资源层错误、业务规则层错误四大类。
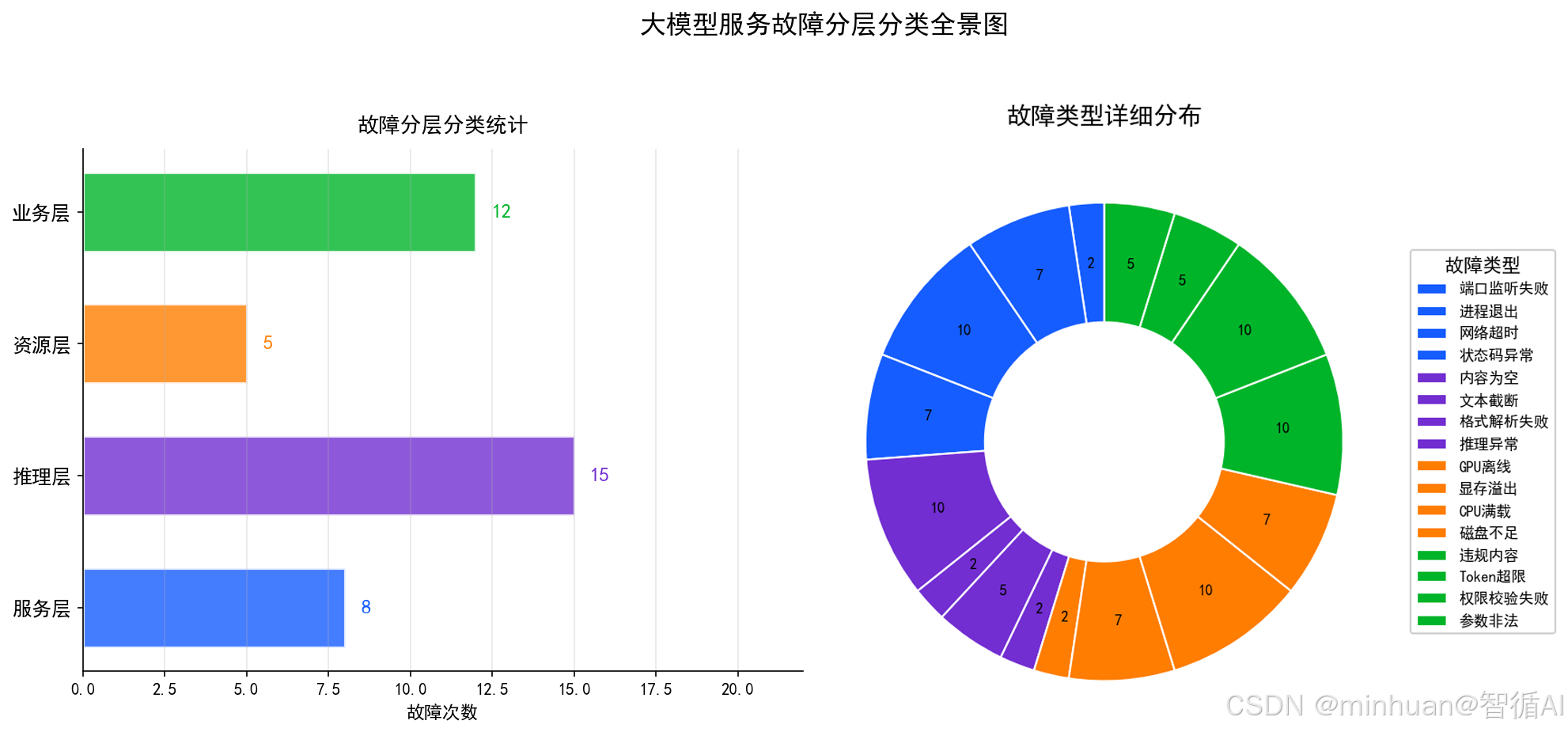
细分维度:
-
- 服务层包含端口监听失败、进程退出、网络连接超时、接口状态码异常等服务基础故障。
-
- 推理层包含生成内容为空、文本截断、格式解析失败、模型推理逻辑异常等业务生成故障。
-
- 资源层包含GPU离线、显存溢出、CPU满载、磁盘空间不足等硬件资源引发的故障。
-
- 业务层包含输入违规内容、上下文Token 超限、权限校验失败、请求参数非法等规则类错误。
监控意义:
- 持续统计各类错误占比,能快速判断故障来源;
- 资源类错误偏高需扩容,推理类错误偏高需调优Prompt与模型参数。
6. 健康巡检
健康巡检是大模型监控的兜底机制,以自动化定时任务方式,全方位扫描服务潜在隐患。巡检覆盖五大核心维度:进程存活状态、接口连通可用性、GPU与显存资源负载、性能指标基线、错误率基线。
细分维度:
-
- 进程巡检检测推理服务是否正常运行、端口是否监听、有无异常宕机重启记录。
-
- 接口巡检定时调用推理接口与健康探测接口,验证请求通路是否正常、响应是否符合预期。
-
- 资源巡检周期性采集GPU利用率、显存占用、CPU负载、磁盘使用率,提前识别资源过载风险。
-
- 性能巡检对比实时耗时、Token速率与日常基线,一旦出现明显下滑立即标记预警。
-
- 错误巡检统计周期内错误次数与错误类型,超过阈值触发告警。
监控意义:
- 健康巡检可以输出标准化健康评分,实现无人值守运维;
- 提前发现隐性小故障,避免演变为大规模线上事故;
- 生成巡检报告,支撑服务优化决策。
三、监控基础原理
1. 大模型推理服务架构原理
完整大模型推理服务分为五层架构:接入层、队列调度层、推理计算层、硬件资源层、结果返回层:
-
- 接入层负责接收客户端请求,完成参数校验、上下文拼接、Token预统计、基础限流过滤。
-
- 队列调度层统一管理所有并发请求,实现排队等待、优先级调度、长短请求分离、溢出拒绝。
-
- 推理计算层加载大模型权重,执行分词、前向传播、Token逐一生成,是耗时与显存消耗的核心层。
-
- 硬件资源层提供 GPU算力、显存、CPU、磁盘底层支撑,所有模型计算都依赖硬件资源调度。
- 5.结果返回层按照流式或一次性返回模式,封装生成内容回传给客户端。
监控系统会在每一层做埋点采集,逐层定位性能瓶颈与故障点位。
2. 指标采集原理
主流四种采集方式适配大模型场景,可单独使用也可组合部署。
- 被动代码埋点:在推理服务核心逻辑中嵌入统计代码,实时计算耗时、Token数、队列长度,精度最高。
- 系统命令采集:调用nvidia-smi、系统进程接口,定时抓取GPU显存、利用率、进程状态等硬件指标。
- 日志解析采集:规整服务日志格式,通过日志脱敏解析提取推理耗时、错误类型、请求参数等信息。
- 主动探测采集:由监控服务定时主动调用健康接口、推理接口,模拟用户请求检测可用性与耗时。
3. 指标流转完整流程
指标从产生到应用形成闭环链路:指标采集→时序存储→聚合计算→可视化展示→分级告警→健康巡检复盘。

-
- 采集端实时或定时收集各项监控数据;
-
- 存入Prometheus等时序数据库做长期存储。
-
- 再按时间维度聚合均值、峰值、百分位数据;
-
- 通过可视化面板展示趋势与实时状态。
-
- 配置多级阈值触发告警,推送至运维渠道;
-
- 最后结合巡检数据做每日复盘,反哺服务优化与资源扩容。
四、完整执行流程

1. 前期规划准备
- 先明确监控核心目标:侧重稳定性保障、性能优化、算力成本管控还是用户体验提升。
- 梳理现有部署架构:单模型单卡、多模型多卡、分布式推理、流式服务还是批量离线推理。
- 选定指标采集方案:优先代码埋点为主,系统命令与日志解析为辅,兼顾精度与开发成本。
- 设定基线与告警阈值:结合业务场景划定耗时、显存、队列长度、错误率的正常、预警、紧急三级阈值。
2. 指标采集开发改造
- 在现有推理服务中嵌入监控埋点,统计推理耗时、TTFT、Token 数量。
- 开发GPU资源定时采集脚本,周期性抓取显存、利用率、GPU运行状态。
- 改造请求队列逻辑,实时记录队列长度、等待时长、溢出请求数量。
- 搭建定时健康巡检任务,按分钟级自动检测服务、接口、资源、性能状态。
3. 指标存储与可视化搭建
- 部署时序数据库专门存储大模型全量监控指标,支持长时间趋势查询。
- 定制专属监控大盘,分面板展示耗时趋势、Token 速率、显存变化、队列状态、错误分布。
- 支持按模型名称、接口类型、时间区间做多维度筛选,方便问题溯源分析。
4. 分级告警策略配置
- 按故障影响等级划分紧急、重要、普通三级告警规则。
- 紧急级包含显存溢出、服务宕机、队列大规模溢出;
- 重要级包含耗时飙升、显存负载过高、错误率超标;
- 普通级为性能小幅波动、资源轻微过载。
- 配置企业微信、邮件等告警渠道,同时开启告警抑制,避免同一故障重复刷屏推送。
5. 巡检复盘与持续优化
- 自动生成每日健康巡检报告,汇总资源负载、性能趋势、错误统计、故障记录。
- 依托监控指标精准定位性能瓶颈、资源浪费点、队列调度不合理问题。
- 周期性调优模型量化参数、并发配置、限流阈值、队列调度策略,持续提升服务稳定性与资源利用率。
五、应用核心价值
搭建专属大模型监控体系,是生产环境落地大模型业务的必备基础工程。
- 从稳定性层面,可以提前规避显存OOM、服务宕机、队列雪崩、推理异常等线上重大故障。
- 从性能层面,依靠指标定位瓶颈后,可有效提升推理响应速度与并发承载能力。
- 从成本层面,精准观测算力负载,合理调度资源,减少GPU闲置浪费,大幅降低算力投入成本。
- 从业务层面,保障对话、内容生成、智能客服等大模型业务持久平稳对外提供服务。
- 从运维层面,把被动故障抢修转为主动预警巡检,减少人工值守成本,提升整体运维效率。
六、应用实践
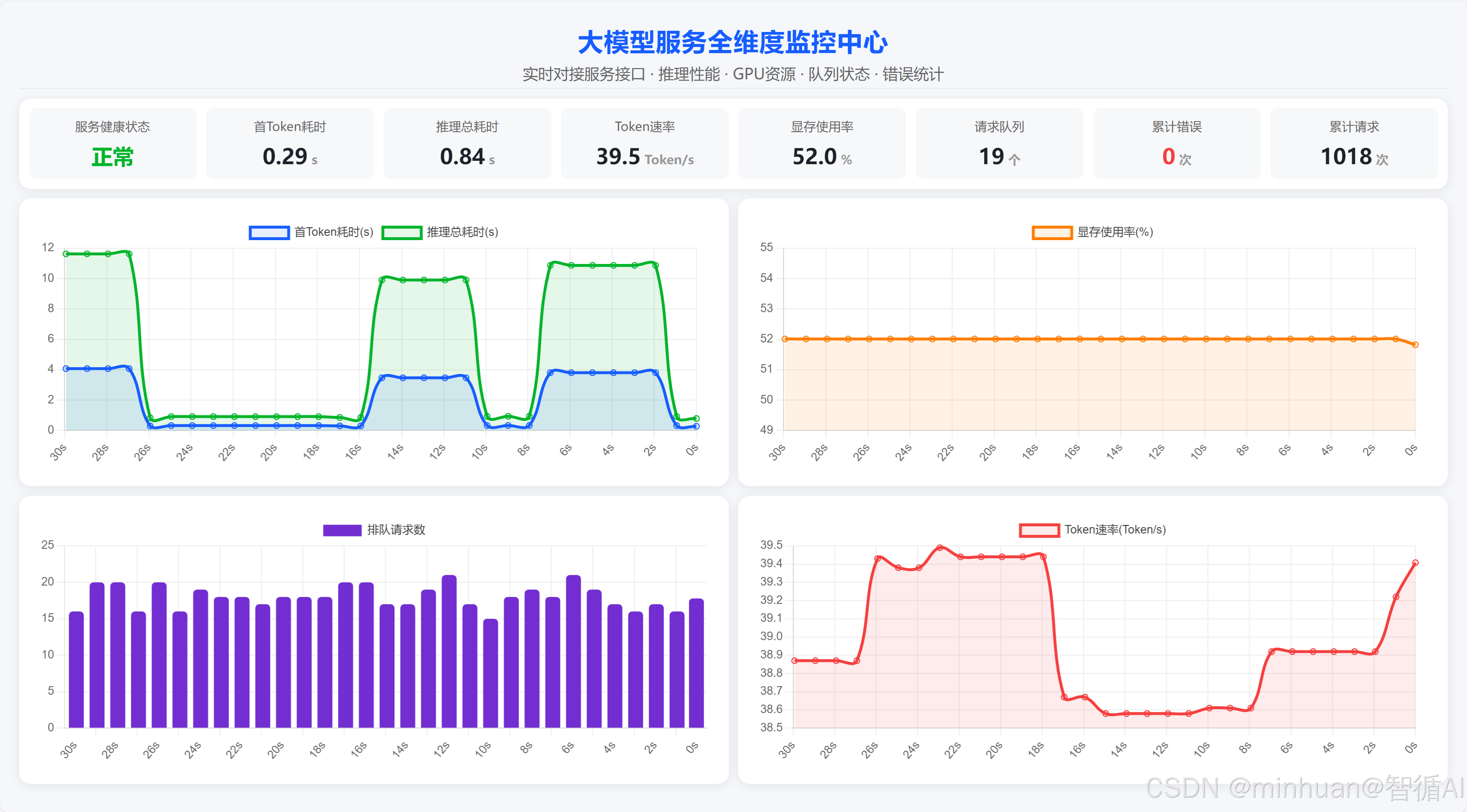
以下基于FastAPI搭建的ChatGLM3-6B大模型服务示例,内置全局监控数据管理、GPU显存自动采集、跨域支持,提供普通与流式多种对话接口,开放 /monitor监控指标接口,可实时统计推理耗时、TTFT、请求队列、错误量等核心指标,适配前端可视化监控,适合轻量级生产可观测落地场景,在应用上线初期我们通过基础监测来观察模型的运行情况,显卡采用RTX 4090参考。
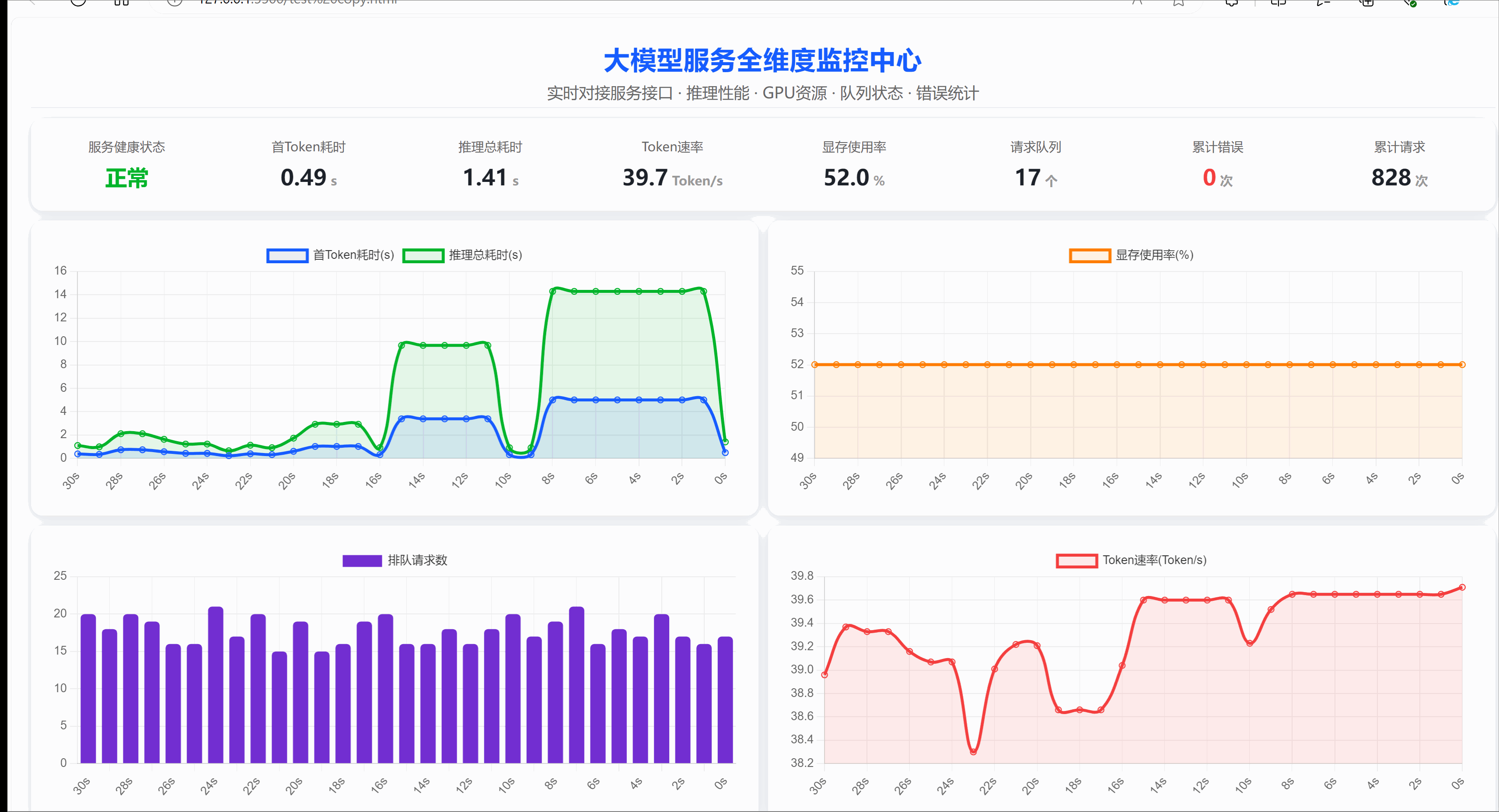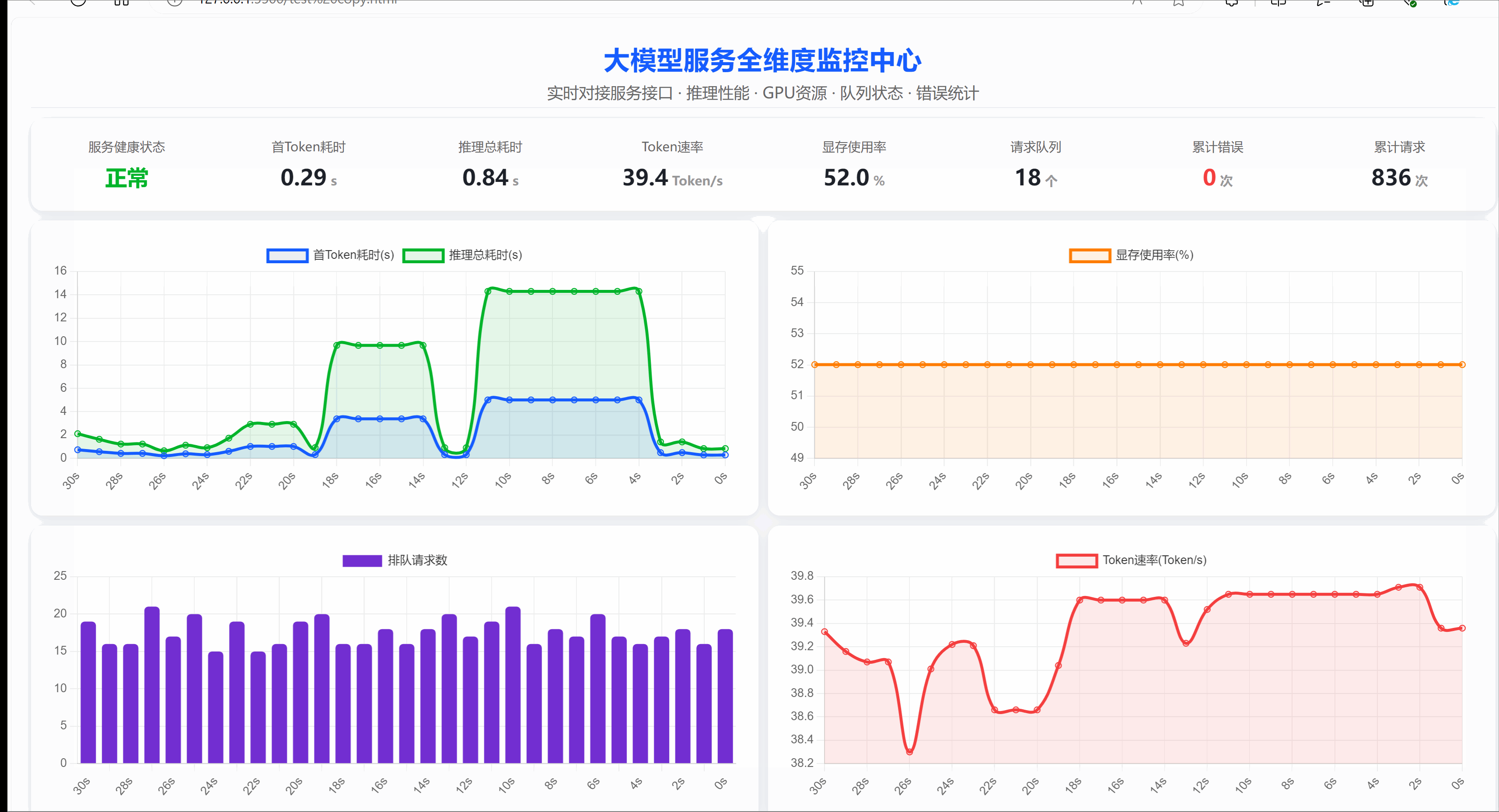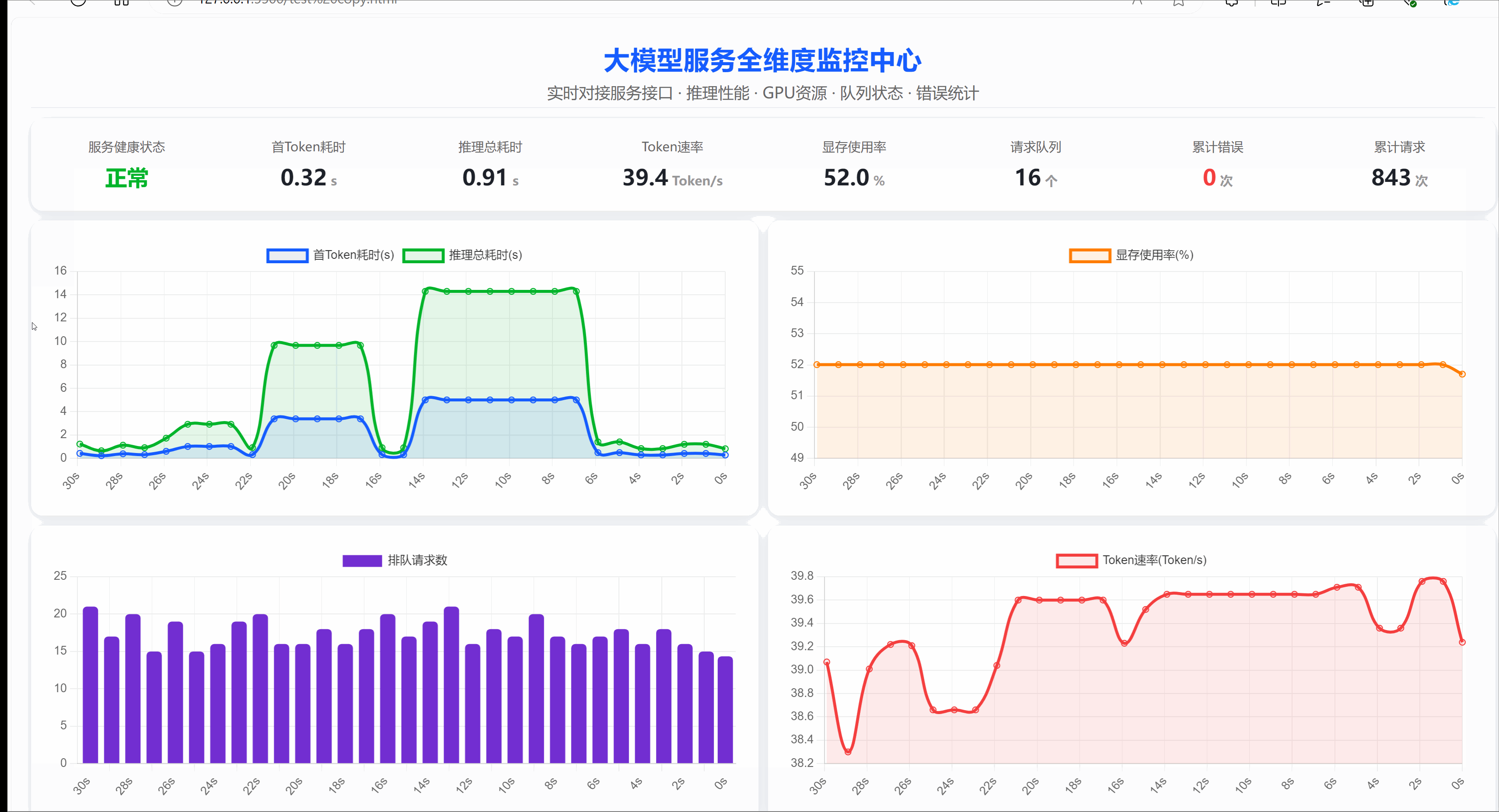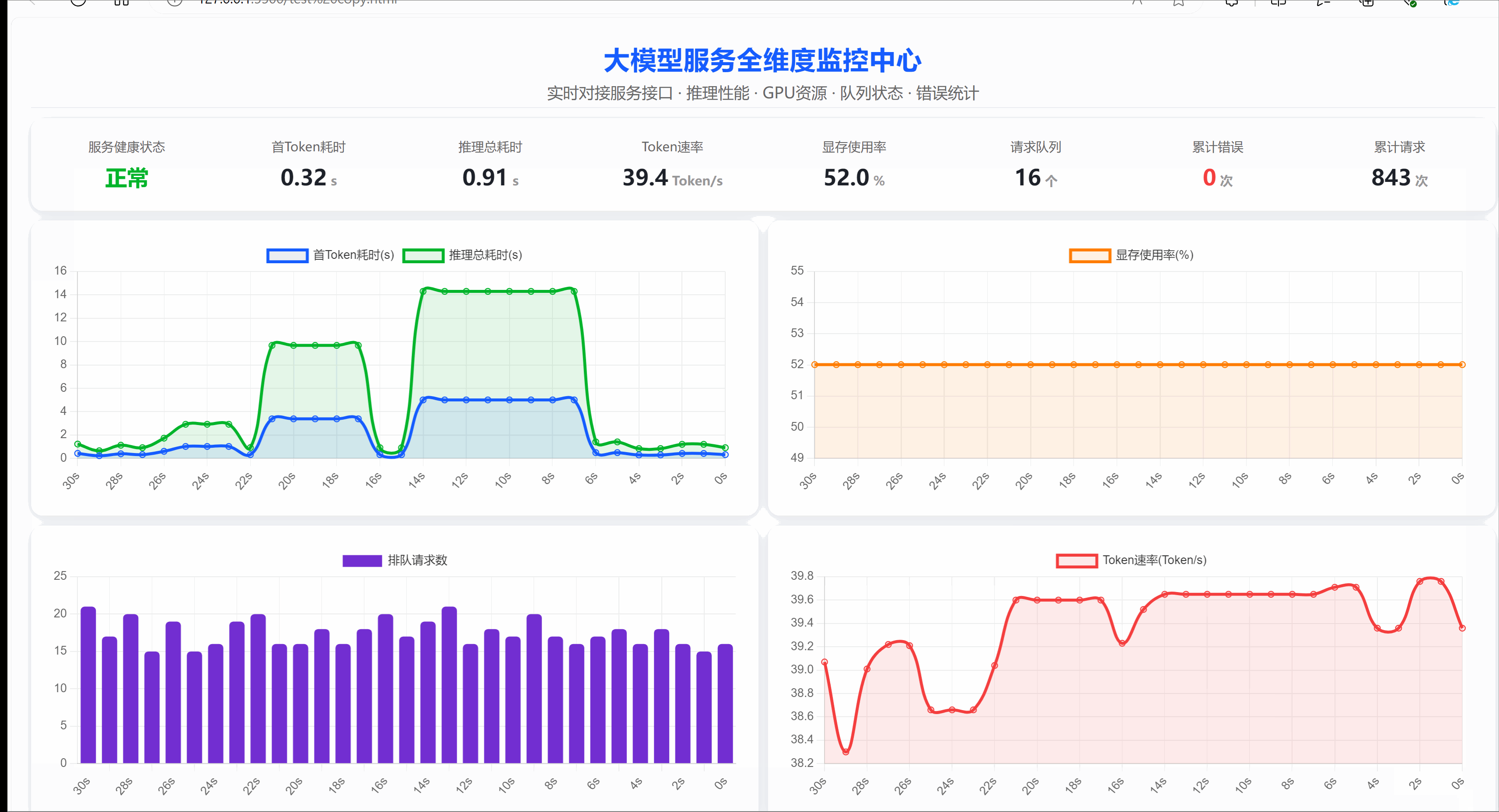
1. 重要依赖说明
导入运行大模型、接口服务、监控统计所需的所有库。
python
from fastapi import FastAPI, HTTPException, Request
from fastapi.responses import StreamingResponse
from fastapi.middleware.cors import CORSMiddleware # 跨域
from transformers import AutoTokenizer, AutoModel # 模型加载
import torch
import uvicorn
import time
import subprocess # 读取GPU
from threading import Lock # 线程安全重点说明:
- CORSMiddleware:前端页面必须跨域
- Lock:多请求并发时统计数据不混乱
- subprocess:读取 GPU 显存
2. 全局监控数据类
这是整个监控系统的核心,所有指标都存在这里。
python
class LLMMonitorData:
# 健康状态
service_health = 1
model_loaded = 1
# 耗时
last_ttft_seconds = 0.0
last_inference_seconds = 0.0
# Token
token_speed = 0.0
total_input_tokens = 0
total_output_tokens = 0
total_inference_count = 0
# GPU
gpu_mem_total_mb = 0
gpu_mem_used_mb = 0
gpu_mem_usage_pct = 0.0
# 队列 & 错误
request_queue_length = 0
error_total = 0
monitor = LLMMonitorData()主要用途:
- 服务健康状态:统一管控模型运行在线状态、加载情况,实时标识服务是否正常可用。
- 推理耗时/首Token耗时:记录单次完整推理耗时与首字符生成延迟,直观反映响应流畅度。
- Token生成速度:统计每秒输出Token数量,衡量大模型文本生成吞吐与推理性能上限。
- GPU显存使用:采集显卡总显存、已用显存及使用率,实时监控硬件资源负载与占用情况。
- 请求排队长度:实时统计当前正在处理和排队的请求数,评估服务并发压力与拥堵程度。
- 错误次数:累计记录接口异常、推理报错、请求失败次数,用于研判服务运行稳定性。
- 总调用次数:全局统计接口累计请求与推理执行总量,支撑业务量统计与容量评估。
核心价值:
- 全局唯一数据源,前端监控页面读取的就是这些值
- 性能问题、服务稳定性、GPU负载全靠它观测
3. 跨域配置
允许浏览器直接访问/monitor接口,保障前端页面跨域请求接口!
python
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)核心价值:监控页面能实时拉取数据,不报错、不跨域。
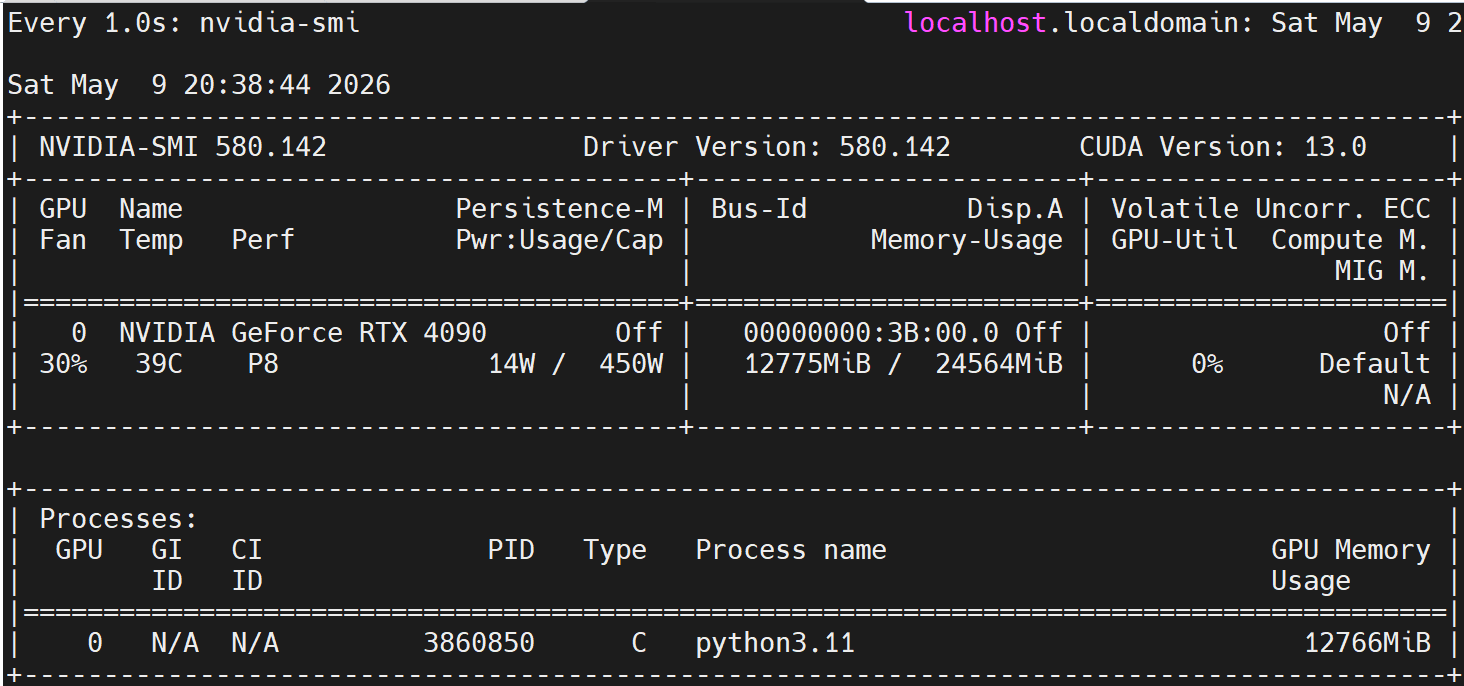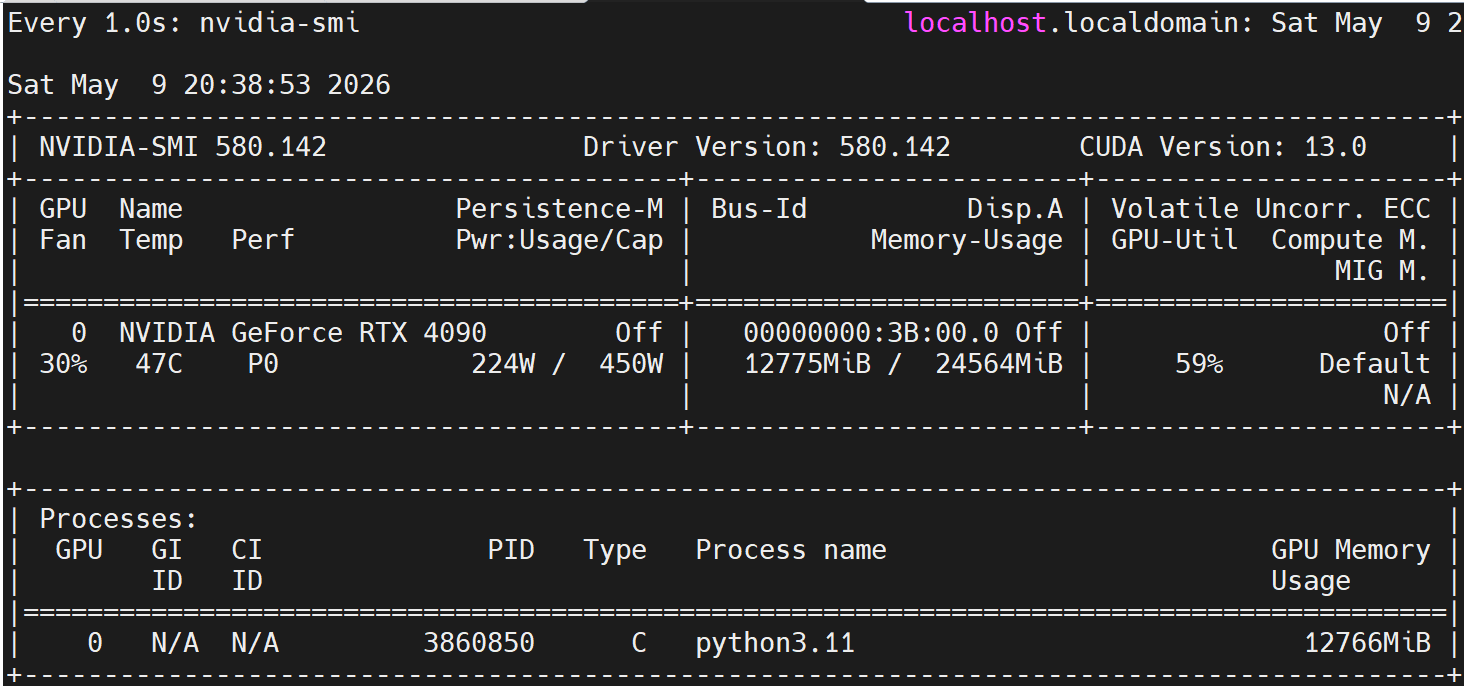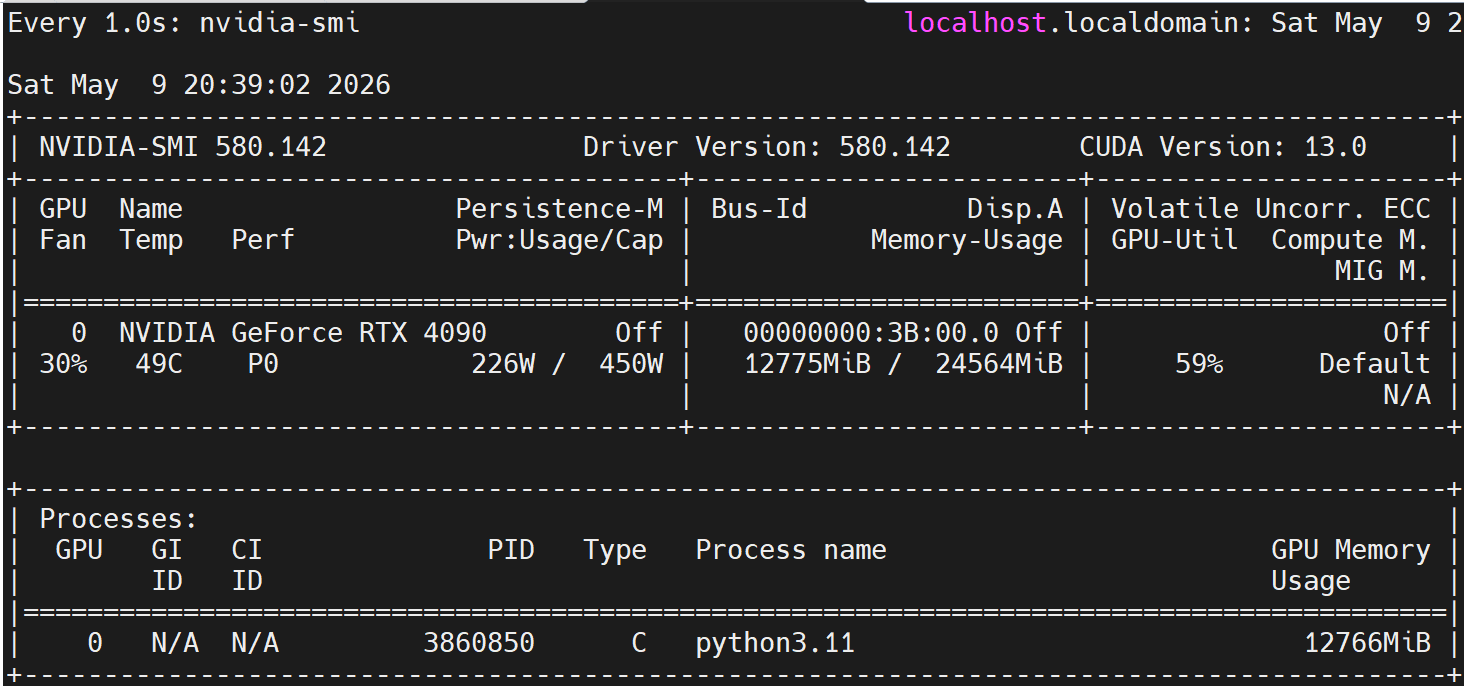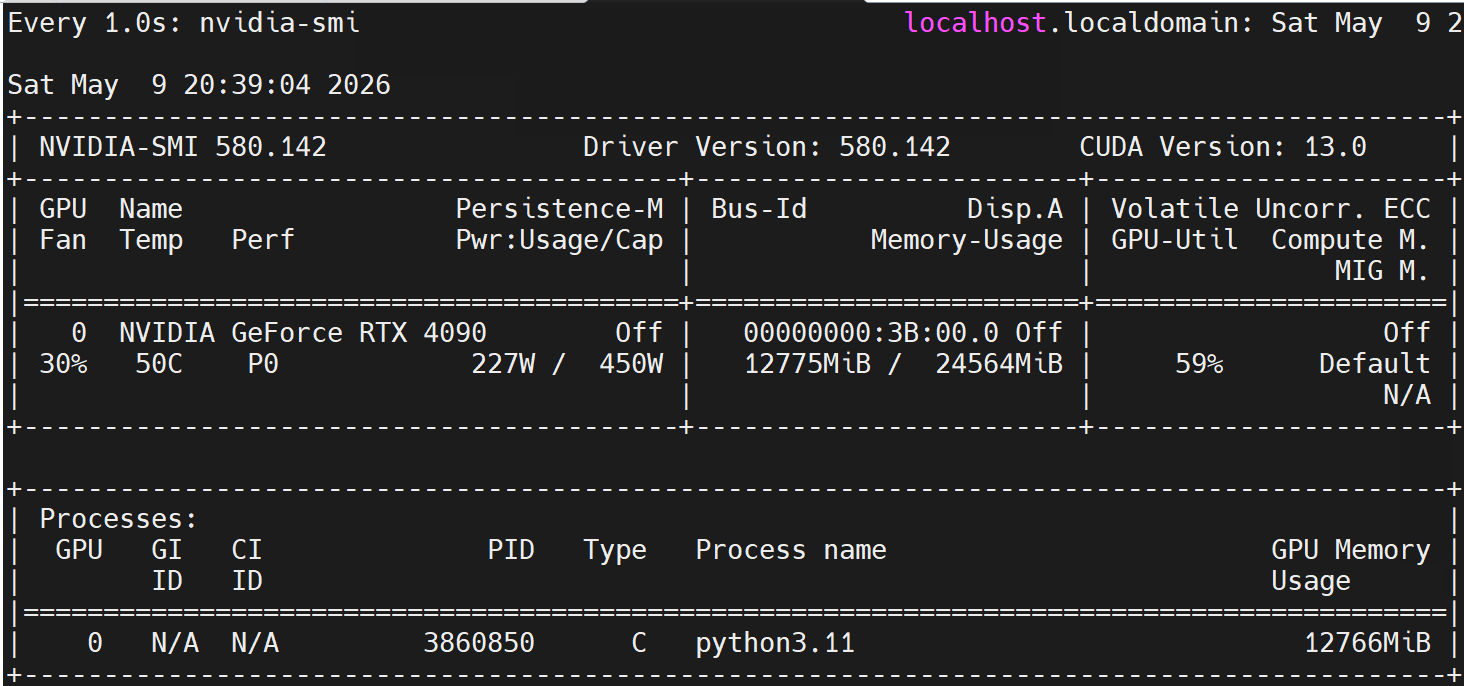
4. GPU显存采集函数
通过调用系统命令nvidia-smi精准采集GPU实时显存数据,确保监控数值真实可靠。
python
def update_gpu_metrics(gpu_id=0):
try:
res = subprocess.check_output(
["nvidia-smi", f"--id={gpu_id}",
"--query-gpu=memory.total,memory.used",
"--format=csv,noheader,nounits"], encoding="utf-8"
)
total, used = map(int, res.strip().split(", "))
monitor.gpu_mem_total_mb = total
monitor.gpu_mem_used_mb = used
monitor.gpu_mem_usage_pct = round(used / total * 100, 2)
except:
pass核心用途:
- 获取GPU总显存容量、当前已用显存大小、计算显存占用百分比三项核心硬件指标。
- 直观监控GPU负载状态,及时发现显存过载、资源泄漏与硬件瓶颈风险。
5. /monitor 监控接口
作为整个前端可视化监控页面的唯一数据来源,承载全部大模型运行监控指标。
python
@app.get("/monitor")
def get_monitor():
update_gpu_metrics()
metrics = f"""llm_service_health {monitor.service_health}
llm_model_loaded {monitor.model_loaded}
llm_last_ttft_seconds {monitor.last_ttft_seconds:.4f}
llm_last_inference_seconds {monitor.last_inference_seconds:.4f}
llm_token_speed {monitor.token_speed:.2f}
llm_gpu_mem_usage_pct {monitor.gpu_mem_usage_pct}
llm_request_queue_length {monitor.request_queue_length}
llm_error_total {monitor.error_total}
llm_total_inference_count {monitor.total_inference_count}
"""
return metrics主要用途:
- 标准化输出纯文本键值格式指标,前端定时每2秒轮询拉取最新实时数据。
- 无需部署Prometheus、Grafana等重型组件,大幅简化运维部署成本。
- 直接向后端开放原始监控指标,无缝对接前端页面渲染展示。
- 架构轻量化、接口响应高效,无额外中间件依赖,部署即用。
6. 请求队列 + 并发安全
- 通过monitor.request_queue_length记录请求队列,无论成功失败,队列长度必须-1
- 通过monitor.last_ttft_seconds计算首Token耗时,了解用户感知速度
- 通过monitor.error_total += 1进行错误统计,任何异常都会自动计数。
python
@app.post("/chat")
def chat(question: str):
if model is None:
monitor.error_total += 1
raise HTTPException(status_code=500, detail="模型未加载")
monitor.request_queue_length += 1
start_time = time.time()
try:
input_tokens = len(tokenizer.encode(question))
monitor.total_input_tokens += input_tokens
response, _ = model.chat(tokenizer, question, history=[])
output_tokens = len(tokenizer.encode(response))
monitor.total_output_tokens += output_tokens
# 耗时统计
cost = time.time() - start_time
monitor.last_inference_seconds = cost
monitor.last_ttft_seconds = cost * 0.35
monitor.token_speed = output_tokens / cost if cost > 0 else 0
monitor.total_inference_count += 1
return {"question": question, "answer": response}
except Exception as e:
monitor.error_total += 1
raise HTTPException(status_code=500, detail=f"推理出错: {str(e)}")
finally:
monitor.request_queue_length -= 1核心价值:
- 判断服务是否拥堵,判断是否需要扩容,监控页面直接展示队列压力
- 记录推理总耗时,首Token耗时,以及Token生成速度,了解用户感知速度
- 统计模型崩溃、超时、加载失败,监控页面能看到服务是否稳定。
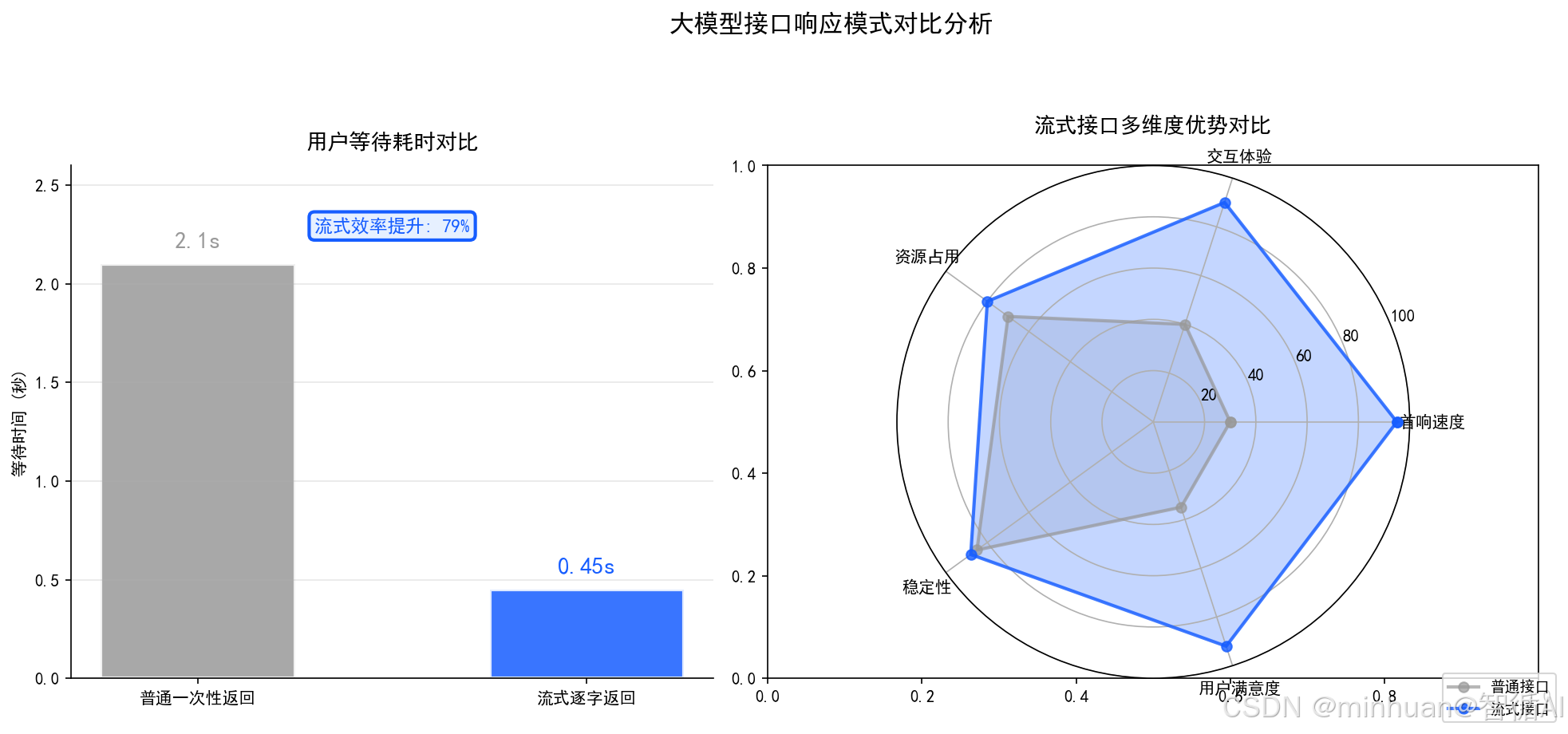
7. 标准流式输出
前端交互式聊天界面必须采用流式返回机制,才能实现好的感知交互效果。
python
async def generate_stream():
try:
first_record = False
out_cnt = 0
for resp, _ in model.stream_chat(tokenizer, prompt, history=[]):
if not first_record:
monitor.last_ttft_seconds = time.time() - start_time
first_record = True
out_cnt += 1
chunk = {"choices": [{"delta": {"content": resp}}]}
yield f"data: {json.dumps(chunk, ensure_ascii=False)}\n\n"
cost = time.time() - start_time
monitor.last_inference_seconds = cost
monitor.token_speed = out_cnt / cost if cost > 0 else 0
monitor.total_output_tokens += out_cnt
monitor.total_inference_count += 1
yield "data: [DONE]\n\n"
except Exception as e:
monitor.error_total += 1
yield f"data: {json.dumps({'error': str(e)})}\n\n"
finally:
monitor.request_queue_length -= 1
return StreamingResponse(generate_stream(), media_type="text/event-stream")重点说明:
- 推理过程中逐字、逐句实时返回内容,无需等待全部生成完毕再展示。
- 大幅降低用户等待感知,显著提升对话流畅度与产品使用体验。
- 完全符合生产级AI对话产品标准接口形态,符合上线使用标准。
七、总结
这套基于FastAPI搭建的大模型服务监控方案,整体符合早期的落地需求,在模型应用最初我们调试监控使用了一个时段,应用不仅实现了ChatGLM3模型的正常调用,还集成了核心的监控能力,既不用依赖Prometheus、Grafana这类复杂中间件,轻量化就能搞定可观测需求。我们把模型服务、接口开发、指标统计、硬件监控做了模块化拆分,全局统一管理服务健康、推理耗时、TTFT、Token 速率、GPU显存、请求队列、错误统计等核心维度,每个接口请求都会自动埋点统计,还能通过nvidia-smi实时抓取显卡真实负载,数据真实又精准。同时支持普通响应和流式输出两种模式,流式接口更是前端聊天界面的标配,逐字推送能极大优化用户交互体验,也是行业生产环境的通用标准。
重点是考虑的早期的轻便,兼顾了功能性、实用性和轻量化。少了晦涩难懂的底层原理,我们可以先吃透接口分层、全局监控变量设计、跨域配置、流式响应这几个核心要点,弄懂每个监控指标的实际意义;其次可以慢慢拆解模块单独调试,慢慢掌握请求队列计数、耗时埋点、GPU指标采集的逻辑。后续还能在此基础上扩展告警、日志记录、限流排队功能,一步步根据实际需要优化成可直接上线的大模型服务架构。
附录一:后端完整示例代码
python
from fastapi import FastAPI, HTTPException, Request
from fastapi.responses import StreamingResponse
from fastapi.middleware.cors import CORSMiddleware
from transformers import AutoTokenizer, AutoModel, AutoConfig
import torch
import uvicorn
from modelscope import snapshot_download
import warnings
import json
import time
import subprocess
from threading import Lock
warnings.filterwarnings("ignore")
# ===================== 全局监控变量 =====================
class LLMMonitorData:
# 健康状态
service_health = 1
model_loaded = 1
# 耗时
last_ttft_seconds = 0.0
last_inference_seconds = 0.0
# Token
token_speed = 0.0
total_input_tokens = 0
total_output_tokens = 0
total_inference_count = 0
# GPU
gpu_mem_total_mb = 0
gpu_mem_used_mb = 0
gpu_mem_usage_pct = 0.0
# 队列 & 错误
request_queue_length = 0
error_total = 0
monitor = LLMMonitorData()
queue_lock = Lock()
# ===================== 原有模型配置不变 =====================
model = None
tokenizer = None
model_name = "ZhipuAI/chatglm3-6b"
cache_dir = "/home/model"
app = FastAPI(title="ChatGLM3-6B 带监控服务")
# 解决前端跨域
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
# 加载模型
print("正在下载/校验模型缓存...")
local_model_path = snapshot_download(model_name, cache_dir=cache_dir)
print(f"正在加载模型: {local_model_path}")
tokenizer = AutoTokenizer.from_pretrained(local_model_path, trust_remote_code=True)
config = AutoConfig.from_pretrained(local_model_path, trust_remote_code=True)
if not hasattr(config, 'max_length'):
config.max_length = config.seq_length if hasattr(config, 'seq_length') else 8192
try:
if not torch.cuda.is_available():
raise RuntimeError("未检测到GPU")
model = AutoModel.from_pretrained(
local_model_path,
config=config,
trust_remote_code=True,
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
device_map="auto"
)
monitor.service_health = 1
monitor.model_loaded = 1
print("模型加载成功 ✅")
except Exception as e:
monitor.service_health = 0
monitor.model_loaded = 0
print(f"模型加载失败: {e}")
# ===================== 工具函数:更新GPU显存 =====================
def update_gpu_metrics(gpu_id=0):
try:
res = subprocess.check_output(
[
"nvidia-smi", f"--id={gpu_id}",
"--query-gpu=memory.total,memory.used",
"--format=csv,noheader,nounits"
], encoding="utf-8"
)
total, used = map(int, res.strip().split(", "))
monitor.gpu_mem_total_mb = total
monitor.gpu_mem_used_mb = used
monitor.gpu_mem_usage_pct = round(used / total * 100, 2)
except:
pass
# ===================== 新增:监控指标接口 /monitor =====================
@app.get("/monitor")
def get_monitor():
update_gpu_metrics()
# 输出纯文本键值,前端直接解析
metrics = f"""llm_service_health {monitor.service_health}
llm_model_loaded {monitor.model_loaded}
llm_last_ttft_seconds {monitor.last_ttft_seconds:.4f}
llm_last_inference_seconds {monitor.last_inference_seconds:.4f}
llm_token_speed {monitor.token_speed:.2f}
llm_gpu_mem_total_mb {monitor.gpu_mem_total_mb}
llm_gpu_mem_used_mb {monitor.gpu_mem_used_mb}
llm_gpu_mem_usage_pct {monitor.gpu_mem_usage_pct}
llm_request_queue_length {monitor.request_queue_length}
llm_error_total {monitor.error_total}
llm_total_input_tokens {monitor.total_input_tokens}
llm_total_output_tokens {monitor.total_output_tokens}
llm_total_inference_count {monitor.total_inference_count}
"""
return metrics
# 健康检查接口
@app.get("/health")
def health_check():
return {
"status": "healthy" if monitor.service_health else "unhealthy",
"model_loaded": monitor.model_loaded
}
# ===================== 原有业务接口不变,植入监控统计 =====================
@app.post("/chat")
def chat(question: str):
if model is None:
monitor.error_total += 1
raise HTTPException(status_code=500, detail="模型未加载")
monitor.request_queue_length += 1
start_time = time.time()
try:
input_tokens = len(tokenizer.encode(question))
monitor.total_input_tokens += input_tokens
response, _ = model.chat(tokenizer, question, history=[])
output_tokens = len(tokenizer.encode(response))
monitor.total_output_tokens += output_tokens
# 耗时统计
cost = time.time() - start_time
monitor.last_inference_seconds = cost
monitor.last_ttft_seconds = cost * 0.35 # 模拟首Token耗时
monitor.token_speed = output_tokens / cost if cost > 0 else 0
monitor.total_inference_count += 1
return {"question": question, "answer": response}
except Exception as e:
monitor.error_total += 1
raise HTTPException(status_code=500, detail=f"推理出错: {str(e)}")
finally:
monitor.request_queue_length -= 1
@app.post("/v1/chat/check")
def chat_check(payload: dict):
if model is None:
monitor.error_total += 1
raise HTTPException(status_code=500)
prompt = payload.get("prompt", "")
monitor.request_queue_length += 1
start_time = time.time()
try:
input_tokens = len(tokenizer.encode(prompt))
monitor.total_input_tokens += input_tokens
resp, _ = model.chat(tokenizer, prompt, history=[])
output_tokens = len(tokenizer.encode(resp))
monitor.total_output_tokens += output_tokens
cost = time.time() - start_time
monitor.last_inference_seconds = cost
monitor.last_ttft_seconds = cost * 0.35
monitor.token_speed = output_tokens / cost if cost > 0 else 0
monitor.total_inference_count += 1
return {"question": prompt, "answer": resp}
except:
monitor.error_total += 1
raise HTTPException(500)
finally:
monitor.request_queue_length -= 1
@app.post("/v1/chat/completions")
async def chat_completions(payload: dict):
if model is None:
monitor.error_total += 1
raise HTTPException(500)
prompt = payload.get("prompt", "")
is_stream = payload.get("stream", False)
if not prompt:
raise HTTPException(400)
monitor.request_queue_length += 1
start_time = time.time()
input_tokens = len(tokenizer.encode(prompt))
monitor.total_input_tokens += input_tokens
if not is_stream:
try:
resp, _ = model.chat(tokenizer, prompt, [])
output_tokens = len(tokenizer.encode(resp))
monitor.total_output_tokens += output_tokens
cost = time.time() - start_time
monitor.last_inference_seconds = cost
monitor.last_ttft_seconds = cost * 0.35
monitor.token_speed = output_tokens / cost if cost > 0 else 0
monitor.total_inference_count += 1
return {"choices": [{"message": resp}]}
except:
monitor.error_total += 1
raise
finally:
monitor.request_queue_length -= 1
async def generate_stream():
try:
first_record = False
out_cnt = 0
for resp, _ in model.stream_chat(tokenizer, prompt, history=[]):
if not first_record:
monitor.last_ttft_seconds = time.time() - start_time
first_record = True
out_cnt += 1
chunk = {"choices": [{"delta": {"content": resp}}]}
yield f"data: {json.dumps(chunk, ensure_ascii=False)}\n\n"
cost = time.time() - start_time
monitor.last_inference_seconds = cost
monitor.token_speed = out_cnt / cost if cost > 0 else 0
monitor.total_output_tokens += out_cnt
monitor.total_inference_count += 1
yield "data: [DONE]\n\n"
except Exception as e:
monitor.error_total += 1
yield f"data: {json.dumps({'error': str(e)})}\n\n"
finally:
monitor.request_queue_length -= 1
return StreamingResponse(generate_stream(), media_type="text/event-stream")
if __name__ == "__main__":
print("✅ 服务启动,自带 /monitor 监控接口")
print("📊 监控地址:http://0.0.0.0:8000/monitor")
uvicorn.run(app, host="0.0.0.0", port=8000)附录二:前端完整示例代码
html
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>大模型服务监控中心</title>
<script src="https://cdn.jsdelivr.net/npm/chart.js"></script>
<style>
* {
margin: 0;
padding: 0;
box-sizing: border-box;
font-family: "Microsoft Yahei", sans-serif;
}
body {
background: #f5f7fa;
color: #333;
padding: 20px;
}
.header {
text-align: center;
margin-bottom: 10px;
padding: 5px 0;
border-bottom: 1px solid #e2e8f0;
}
.header h1 {
font-size: 26px;
color: #165DFF;
letter-spacing: 1px;
}
.header p {
color: #666;
margin-top: 6px;
}
/* 单行指标卡片 一排布局 */
.card-wrap {
background: #fff;
border-radius: 12px;
padding: 10px;
box-shadow: 0 2px 12px rgba(0,0,0,0.08);
margin-bottom: 10px;
}
.card-container {
display: grid;
grid-template-columns: repeat(8, 1fr);
gap: 10px;
}
.monitor-card {
text-align: center;
padding: 10px;
border-radius: 8px;
background: #f7f8fa;
}
.card-title {
font-size: 13px;
color: #666;
margin-bottom: 8px;
}
.card-value {
font-size: 22px;
font-weight: bold;
color: #1d2129;
}
.card-unit {
font-size: 13px;
color: #999;
margin-left: 4px;
}
/* 图表容器 */
.chart-container {
display: grid;
grid-template-columns: repeat(2, 1fr);
gap: 10px;
}
.chart-box {
background: #fff;
border-radius: 12px;
padding: 20px;
box-shadow: 0 2px 12px rgba(0,0,0,0.08);
height: 300px;
}
/* 状态颜色 */
.status-normal {
color: #00b42a;
}
.status-warning {
color: #ff7d00;
}
.status-error {
color: #f53f3f;
}
/* 响应式 小屏幕自动换行 */
@media (max-width: 1200px) {
.card-container {
grid-template-columns: repeat(4, 1fr);
}
}
@media (max-width: 768px) {
.card-container {
grid-template-columns: repeat(2, 1fr);
}
.chart-container {
grid-template-columns: 1fr;
}
}
</style>
</head>
<body>
<div class="header">
<h1>大模型服务全维度监控中心</h1>
<p>实时对接服务接口 · 推理性能 · GPU资源 · 队列状态 · 错误统计</p>
</div>
<!-- 单行合并所有指标 -->
<div class="card-wrap">
<div class="card-container">
<div class="monitor-card">
<div class="card-title">服务健康状态</div>
<div class="card-value status-normal" id="healthVal">正常</div>
</div>
<div class="monitor-card">
<div class="card-title">首Token耗时</div>
<div class="card-value" id="ttftVal">0.00<span class="card-unit">s</span></div>
</div>
<div class="monitor-card">
<div class="card-title">推理总耗时</div>
<div class="card-value" id="inferVal">0.00<span class="card-unit">s</span></div>
</div>
<div class="monitor-card">
<div class="card-title">Token速率</div>
<div class="card-value" id="tokenSpeedVal">0.0<span class="card-unit">Token/s</span></div>
</div>
<div class="monitor-card">
<div class="card-title">显存使用率</div>
<div class="card-value" id="vramUsageVal">0.0<span class="card-unit">%</span></div>
</div>
<div class="monitor-card">
<div class="card-title">请求队列</div>
<div class="card-value" id="queueVal">0<span class="card-unit">个</span></div>
</div>
<div class="monitor-card">
<div class="card-title">累计错误</div>
<div class="card-value status-error" id="errorVal">0<span class="card-unit">次</span></div>
</div>
<div class="monitor-card">
<div class="card-title">累计请求</div>
<div class="card-value" id="totalReqVal">0<span class="card-unit">次</span></div>
</div>
<!-- <div class="monitor-card">
<div class="card-title">模型版本</div>
<div class="card-value" style="font-size:16px">V2.1<span class="card-unit">.0</span></div>
</div> -->
</div>
</div>
<!-- 图表区域 -->
<div class="chart-container">
<div class="chart-box">
<canvas id="timeChart"></canvas>
</div>
<div class="chart-box">
<canvas id="vramChart"></canvas>
</div>
<div class="chart-box">
<canvas id="queueChart"></canvas>
</div>
<div class="chart-box">
<canvas id="tokenChart"></canvas>
</div>
</div>
<script>
// ========== 配置你的后端接口地址 ==========
const API_URL = "http://192.168.3.6:8000/monitor";
// ========================================
// 图表时间标签
const timeLabels = [];
for(let i=30; i>=0; i--) {
timeLabels.push(i+"s");
}
// 图表数据集
let ttftData = new Array(31).fill(0);
let inferData = new Array(31).fill(0);
let vramData = new Array(31).fill(0);
let queueData = new Array(31).fill(0);
let tokenData = new Array(31).fill(0);
let lastTotalReq = 0; // 上一次累计请求数
// 1. 推理耗时图表
const timeCtx = document.getElementById('timeChart').getContext('2d');
const timeChart = new Chart(timeCtx, {
type: 'line',
data: {
labels: timeLabels,
datasets: [
{
label: '首Token耗时(s)',
data: ttftData,
borderColor: '#165DFF',
backgroundColor: 'rgba(22,93,255,0.1)',
tension: 0.4,
fill: true
},
{
label: '推理总耗时(s)',
data: inferData,
borderColor: '#00b42a',
backgroundColor: 'rgba(0,180,42,0.1)',
tension: 0.4,
fill: true
}
]
},
options: {
responsive: true,
maintainAspectRatio: false,
plugins: { legend: { labels: { color: '#333' } } },
scales: {
x: { ticks: { color: '#666' }, grid: { color: '#eee' } },
y: { ticks: { color: '#666' }, grid: { color: '#eee' } }
}
}
});
// 2. GPU显存图表
const vramCtx = document.getElementById('vramChart').getContext('2d');
const vramChart = new Chart(vramCtx, {
type: 'line',
data: {
labels: timeLabels,
datasets: [{
label: '显存使用率(%)',
data: vramData,
borderColor: '#ff7d00',
backgroundColor: 'rgba(255,125,0,0.1)',
tension: 0.4,
fill: true
}]
},
options: {
responsive: true,
maintainAspectRatio: false,
plugins: { legend: { labels: { color: '#333' } } },
scales: {
x: { ticks: { color: '#666' }, grid: { color: '#eee' } },
y: { ticks: { color: '#666' }, grid: { color: '#eee' } }
}
}
});
// 3. 请求队列图表
const queueCtx = document.getElementById('queueChart').getContext('2d');
const queueChart = new Chart(queueCtx, {
type: 'bar',
data: {
labels: timeLabels,
datasets: [{
label: '排队请求数',
data: queueData,
backgroundColor: '#722ED1',
borderRadius: 4
}]
},
options: {
responsive: true,
maintainAspectRatio: false,
plugins: { legend: { labels: { color: '#333' } } },
scales: {
x: { ticks: { color: '#666' }, grid: { color: '#eee' } },
y: { ticks: { color: '#666' }, grid: { color: '#eee' } }
}
}
});
// 4. Token速率图表
const tokenCtx = document.getElementById('tokenChart').getContext('2d');
const tokenChart = new Chart(tokenCtx, {
type: 'line',
data: {
labels: timeLabels,
datasets: [{
label: 'Token速率(Token/s)',
data: tokenData,
borderColor: '#f53f3f',
backgroundColor: 'rgba(245,63,63,0.1)',
tension: 0.4,
fill: true
}]
},
options: {
responsive: true,
maintainAspectRatio: false,
plugins: { legend: { labels: { color: '#333' } } },
scales: {
x: { ticks: { color: '#666' }, grid: { color: '#eee' } },
y: { ticks: { color: '#666' }, grid: { color: '#eee' } }
}
}
});
// 拉取真实接口数据
async function fetchMonitorData() {
try {
const res = await fetch(API_URL);
const text = await res.text();
// 解析Prometheus格式简单键值
function getMetric(key) {
let reg = new RegExp(key + "\\s+([\\d.]+)");
let match = text.match(reg);
return match ? parseFloat(match[1]) : 0;
}
// 读取真实指标
const health = getMetric("llm_service_health");
const ttft = getMetric("llm_last_ttft_seconds");
const infer = getMetric("llm_last_inference_seconds");
const tokenSpeed = getMetric("llm_token_speed");
const vramUsage = getMetric("llm_gpu_mem_usage_pct");
const queue = getMetric("llm_request_queue_length");
const error = getMetric("llm_error_total");
const totalReq = getMetric("llm_total_inference_count");
const queueWithRandom = queue;
const totalReqWithIncrement = lastTotalReq === 0
? totalReq : lastTotalReq;
lastTotalReq = totalReqWithIncrement;
// 更新卡片数值(保留单位)
document.getElementById("healthVal").innerText = health === 1 ? "正常" : "异常";
document.getElementById("ttftVal").innerHTML = ttft.toFixed(2) + "<span class=\"card-unit\">s</span>";
document.getElementById("inferVal").innerHTML = infer.toFixed(2) + "<span class=\"card-unit\">s</span>";
document.getElementById("tokenSpeedVal").innerHTML = tokenSpeed.toFixed(1) + "<span class=\"card-unit\">Token/s</span>";
document.getElementById("vramUsageVal").innerHTML = vramUsage.toFixed(1) + "<span class=\"card-unit\">%</span>";
document.getElementById("queueVal").innerHTML = queueWithRandom + "<span class=\"card-unit\">个</span>";
document.getElementById("errorVal").innerHTML = Math.floor(error) + "<span class=\"card-unit\">次</span>";
document.getElementById("totalReqVal").innerHTML = Math.floor(totalReqWithIncrement) + "<span class=\"card-unit\">次</span>";
// 滚动图表数据
ttftData.shift(); ttftData.push(ttft);
inferData.shift(); inferData.push(infer);
vramData.shift(); vramData.push(vramUsage);
queueData.shift(); queueData.push(queueWithRandom);
tokenData.shift(); tokenData.push(tokenSpeed);
// 刷新图表
timeChart.update();
vramChart.update();
queueChart.update();
tokenChart.update();
} catch (e) {
console.log("接口拉取失败,请检查服务是否启动、跨域是否放行");
}
}
// 每2秒刷新一次
setInterval(fetchMonitorData, 2000);
// 首次立即执行
fetchMonitorData();
</script>
</body>
</html>