【🔍深度矩阵】Intel DPT-SwinV2单目测距新突破

在计算机视觉领域,单目深度估计一直是一个极具挑战性的研究方向。随着深度学习技术的飞速发展,特别是Transformer架构在计算机视觉任务中的卓越表现,Intel推出的DPT-SwinV2模型为单目深度估计带来了革命性的突破。本文将深入探讨这一技术的核心原理、实现方法及其在各领域的应用前景。
单目深度估计的挑战与机遇
单目深度估计的目标是从单张图像中推断出场景的深度信息,这一技术在生成式AI、三维重建和自动驾驶等领域有着广泛的应用。然而,由于从单个图像中提取深度信息是一个欠约束问题,传统方法往往难以取得令人满意的结果。
近年来,基于学习的方法,特别是MiDaS系列的提出,通过数据集混合和尺度-平移不变损失函数的设计,显著提升了单目深度估计的性能。MiDaS不断演进,从最初的卷积神经网络架构逐步引入了更强大的Transformer编码器,如ViT、BEiT、Swin和SwinV2等,为深度估计任务提供了更强大的特征提取能力。
SwinV2架构的革命性突破
Swin Transformer(Swin代表Shifted window)是一种层次化的Transformer架构,其核心创新在于引入了移位窗口机制。这种设计通过将自注意力计算限制在非重叠的局部窗口内,同时允许跨窗口连接,既提高了计算效率,又保留了全局信息交互的能力。
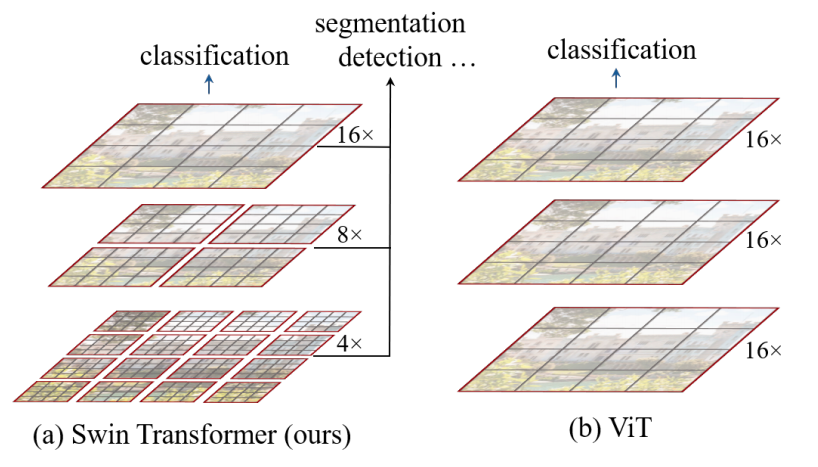
Swin Transformer在多个计算机视觉任务中表现出色,在COCO目标检测测试集上达到58.7的box AP和51.1的mask AP,在ADE20K语义分割验证集上获得53.5的mIoU,大幅超越了之前的模型。这一强大的特征提取能力使其成为深度估计任务的理想选择。
DPT-SwinV2模型详解
MiDaS 3.1 DPT模型采用SwinV2作为骨干网络,结合了Dense Prediction Transformer(DPT)架构,在1.4百万张图像上进行了训练,专门用于单目深度估计任务。该模型在论文《Vision Transformers for Dense Prediction》中首次提出,并在GitHub仓库中开源。
与前版本的MiDaS v3.0仅使用普通的Vision Transformer (ViT)不同,MiDaS v3.1引入了多种编码器架构,包括BEiT、Swin、SwinV2、Next-ViT和LeViT,为深度估计任务提供了更多选择。其中,基于SwinV2的模型在保持高性能的同时,显著提升了计算效率。
模型架构与特点
DPT-SwinV2模型采用了层次化的特征提取策略,通过SwinV2编码器提取多尺度特征,然后通过精心设计的解码器生成高分辨率的深度图。这种设计使得模型能够同时捕捉全局语义信息和局部细节,生成更加精确的深度估计。
输入图像 → SwinV2编码器 → 多尺度特征融合 → DPT解码器 → 深度图该模型支持多种分辨率输入,包括384×384和512×512,并提供不同规模的变体(Large、Base、Tiny),以适应不同计算资源和精度需求。
性能评估与比较
在多个标准测试集上,DPT-SwinV2模型展现了卓越的性能。下表展示了不同模型在MIX-6数据集上的零样本迁移表现:
| 模型 | HRWSI RMSE | Blended MVS REL | ReDWeb RMSE |
|---|---|---|---|
| BEiT 384-L | 0.068 | 0.070 | 0.076 |
| SwinV2-L | 0.0708 | 0.0724 | 0.0826 |
| ViT-L | 0.071 | 0.072 | 0.082 |
| Next-ViT-L | 0.075 | 0.073 | 0.085 |
| ConvNeXt-XL | 0.075 | 0.075 | 0.085 |
从表中可以看出,SwinV2模型在各种评估指标上均表现优异,特别是在保持高性能的同时,显著降低了计算复杂度。值得注意的是,SwinV2-L模型在零样本迁移任务中表现接近甚至超越了某些专用模型,这得益于其强大的特征提取能力和泛化性能。
实践应用与代码实现
环境配置
在使用DPT-SwinV2模型前,需要确保PyTorch和Transformers库的版本兼容。经过测试,以下版本组合能够稳定运行:
python
import torch
import transformers
print(torch.__version__)
print(transformers.__version__)输出:
'2.2.1+cpu'
'4.37.2'安装命令:
bash
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu基础使用方法
以下是使用DPT-SwinV2模型进行零样本深度估计的基本代码:
python
import torch
import numpy as np
from PIL import Image
from transformers import pipeline
# 使用pipeline API
pipe = pipeline(task="depth-estimation", model="Intel/dpt-swinv2-large-384")
result = pipe("http://images.cocodataset.org/val2017/000000181816.jpg")
depth = result["depth"]
depth.show()高级应用
对于需要更精细控制的场景,可以直接使用模型进行推理:
python
from transformers import AutoImageProcessor, AutoModelForDepthEstimation
import torch
# 加载模型和处理器
processor = AutoImageProcessor.from_pretrained("Intel/dpt-swinv2-large-384")
model = AutoModelForDepthEstimation.from_pretrained("Intel/dpt-swinv2-large-384")
# 加载并预处理图像
image = Image.open("example.jpg")
inputs = processor(images=image, return_tensors="pt")
# 深度估计
with torch.no_grad():
outputs = model(**inputs)
predicted_depth = outputs.predicted_depth
# 后处理
output = predicted_depth.squeeze().cpu().numpy()
formatted = (output * 255 / np.max(output)).astype("uint8")
depth = Image.fromarray(formatted)
depth.save("depth_map.jpg")
应用场景与行业影响
DPT-SwinV2模型的强大性能使其在多个领域展现出巨大的应用潜力:
自动驾驶与机器人导航
在自动驾驶系统中,精确的场景深度信息对于障碍物检测、路径规划和场景理解至关重要。DPT-SwinV2模型可以实时从车载摄像头获取的图像中估计深度,为决策系统提供关键的环境感知能力。
增强现实与虚拟现实
AR/VR应用需要精确理解场景的几何结构,以便实现虚拟对象与真实场景的自然融合。DPT-SwinV2提供的深度信息可以显著提升AR/VR应用的沉浸感和真实感。
三维重建与数字孪生
从单张图像生成深度图是三维重建的重要步骤。DPT-SwinV2模型可以辅助从二维图像生成初步的三维模型,为后续的精细重建提供基础。在数字孪生领域,这种技术可以快速构建物理世界的数字化表示。
医学影像分析
在医学影像领域,深度信息可以帮助医生更好地理解解剖结构。DPT-SwinV2模型可以从医学图像中估计深度,辅助诊断和治疗规划。
视频处理与内容创作
在视频处理中,深度信息可以用于场景分割、对象跟踪和特效生成。内容创作者可以利用DPT-SwinV2从视频中提取深度信息,实现更丰富的视觉效果。
模型局限性与未来发展方向
尽管DPT-SwinV2模型在单目深度估计任务中取得了显著进展,但仍存在一些局限性:
-
零样本迁移的局限性:虽然模型在零样本迁移任务中表现良好,但在特定场景下可能仍需微调以获得最佳性能。
-
计算资源需求:大型模型如SwinV2-L对计算资源要求较高,在边缘设备上的部署面临挑战。
-
极端场景的处理:在光照变化剧烈、纹理稀疏或镜面反射等极端场景下,深度估计的准确性可能受到影响。
未来,DPT-SwinV2模型的发展方向可能包括:
- 轻量化模型设计,使其能够在资源受限的设备上高效运行
- 结合多模态信息(如红外、深度传感器数据)提升深度估计的鲁棒性
- 引入时序信息,提升视频序列中深度估计的一致性
- 探索自监督学习方法,减少对标注数据的依赖
伦理考量与责任使用
随着深度估计技术的广泛应用,相关的伦理问题也日益凸显。DPT-SwinV2模型可能被用于生成误导性内容、侵犯隐私或进行其他有害活动。因此,开发者和使用者应当:
-
了解模型局限性:认识到深度估计可能存在误差,避免在关键安全应用中过度依赖模型输出。
-
尊重隐私:在使用深度估计技术处理图像时,应尊重个人隐私和数据保护法规。
-
防范偏见:注意训练数据可能存在的偏见,避免模型输出强化社会偏见。
-
透明度:在应用深度估计技术的系统中,适当披露AI的使用,维护用户知情权。
结论与展望
DPT-SwinV2模型代表了单目深度估计领域的最新进展,通过结合SwinV2 Transformer的强大特征提取能力和DPT架构的密集预测能力,实现了深度估计精度和效率的显著提升。从自动驾驶到AR/VR,从三维重建到医学影像,这一技术正在多个领域展现其变革潜力。
随着技术的不断进步,我们可以期待更强大、更高效的深度估计模型的出现,推动计算机视觉技术在更多场景中的应用。同时,我们也需要关注技术发展带来的伦理挑战,确保AI技术的负责任使用。
正如Intel官方视频《MiDaS Depth Estimation - Intel Technology》所展示的,深度估计技术正在不断突破边界,为数字世界与物理世界的连接提供新的可能性。在线体验这一技术,探索深度估计的无限可能。
的伦理挑战,确保AI技术的负责任使用。
正如Intel官方视频《MiDaS Depth Estimation - Intel Technology》所展示的,深度估计技术正在不断突破边界,为数字世界与物理世界的连接提供新的可能性。在线体验这一技术,探索深度估计的无限可能。
深度矩阵系列将持续关注计算机视觉前沿技术,深入解析各类创新算法与实用工具。如果您对本文内容有任何疑问或建议,欢迎在社区论坛参与讨论。同时,也欢迎关注我们的技术博客,获取更多深度技术解析。