CMA-ES:从搜索分布自适应到协方差矩阵学习
1. 为什么需要 CMA-ES?
在连续优化问题中,我们经常面对这样一类目标函数:
minx∈Rnf(x) \min_{\mathbf{x}\in \mathbb{R}^n} f(\mathbf{x}) x∈Rnminf(x)
但问题在于,很多真实场景中的 f(x)f(\mathbf{x})f(x) 并不友好。它可能没有显式表达式,不能求梯度,存在噪声,甚至一次函数评价就需要调用复杂仿真程序。
这类问题通常被称为连续黑箱优化问题 。
在这种背景下,CMA-ES ,即 Covariance Matrix Adaptation Evolution Strategy ,中文通常称为协方差矩阵适应进化策略,成为了连续黑箱优化领域中非常经典且强大的方法。
CMA-ES 的核心思想可以概括为一句话:
与其直接"变异个体",不如不断学习优秀解在决策空间中的分布结构。
也就是说,CMA-ES 并不是简单地维护一组解,而是维护一个可以不断自适应的高斯搜索分布:
xk∼N(m,σ2C) \mathbf{x}_k \sim \mathcal{N}(\mathbf{m}, \sigma^2 \mathbf{C}) xk∼N(m,σ2C)
其中:
- m\mathbf{m}m:搜索分布的均值,表示当前搜索中心;
- σ\sigmaσ:全局步长,控制整体搜索尺度;
- C\mathbf{C}C:协方差矩阵,控制搜索分布的形状、方向和变量相关性。
2. 一张图理解 CMA-ES 在做什么
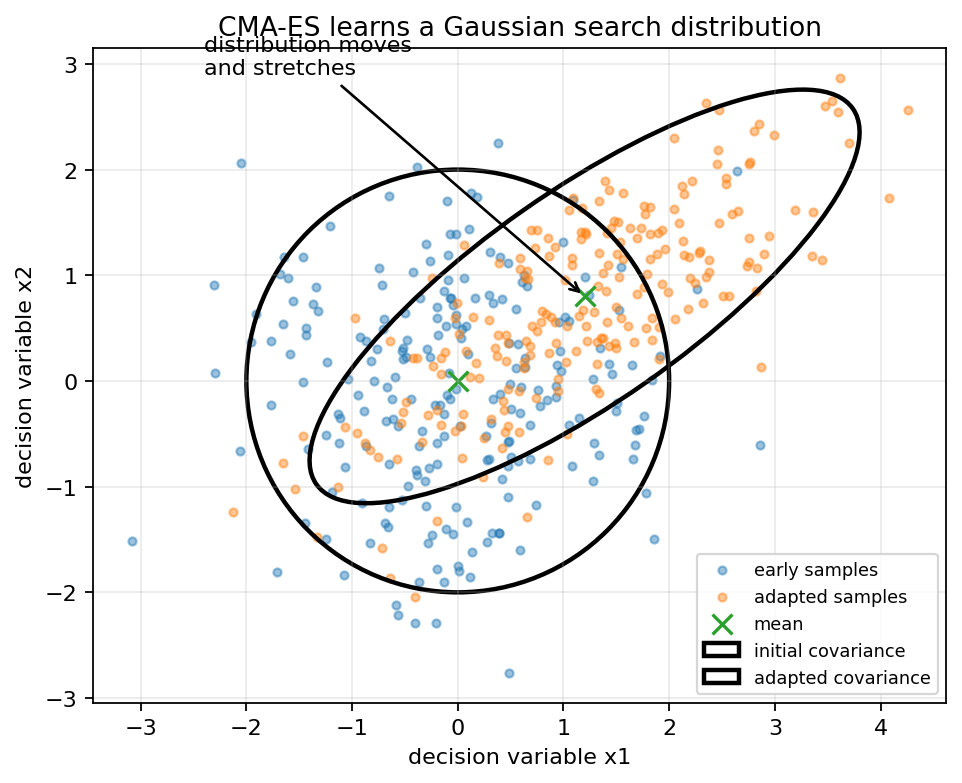
图中可以直观看到,CMA-ES 的搜索分布并不是固定不变的。
在初始阶段,它可能像一个各向同性的圆形区域,在各个方向上均匀探索;随着迭代进行,算法会根据优秀解的位置不断调整搜索分布,使其逐渐向更有希望的区域移动,并在有利方向上拉伸。
因此,CMA-ES 的搜索过程可以理解为三个层面的自适应:
| 自适应对象 | 数学符号 | 作用 |
|---|---|---|
| 搜索中心 | m\mathbf{m}m | 决定下一代主要从哪里开始搜索 |
| 搜索尺度 | σ\sigmaσ | 决定整体探索范围是扩大还是缩小 |
| 搜索形状 | C\mathbf{C}C | 决定搜索方向、变量相关性和椭球形状 |
3. CMA-ES 的基本过程
CMA-ES 每一代的核心逻辑可以概括为:
当前高斯分布
N(m, σ²C)
采样候选解
计算目标函数值
选择表现较好的解
更新均值 m
更新协方差矩阵 C
更新步长 σ
形成新的搜索分布
这个流程体现了 CMA-ES 的本质:
它不是只关心"当前最优解在哪里",而是更关心"优秀解整体呈现出什么样的空间分布"。
4. 均值更新:搜索中心向优秀区域移动
在第 ttt 代,CMA-ES 从当前高斯分布中采样 λ\lambdaλ 个候选解:
xk(t)=m(t)+σ(t)yk(t),yk(t)∼N(0,C(t)) \mathbf{x}_k^{(t)} = \mathbf{m}^{(t)} + \sigma^{(t)} \mathbf{y}_k^{(t)}, \quad \mathbf{y}_k^{(t)} \sim \mathcal{N}(\mathbf{0}, \mathbf{C}^{(t)}) xk(t)=m(t)+σ(t)yk(t),yk(t)∼N(0,C(t))
然后根据目标函数值对候选解排序,选出表现最好的 μ\muμ 个个体,并通过加权重组得到新的均值:
m(t+1)=∑i=1μwixi:λ(t) \mathbf{m}^{(t+1)} = \sum_{i=1}^{\mu} w_i \mathbf{x}_{i:\lambda}^{(t)} m(t+1)=i=1∑μwixi:λ(t)
其中,xi:λ(t)\mathbf{x}_{i:\lambda}^{(t)}xi:λ(t) 表示第 ttt 代中排名第 iii 的候选解,wiw_iwi 是对应权重,满足:
wi>0,∑i=1μwi=1 w_i > 0, \quad \sum_{i=1}^{\mu} w_i = 1 wi>0,i=1∑μwi=1
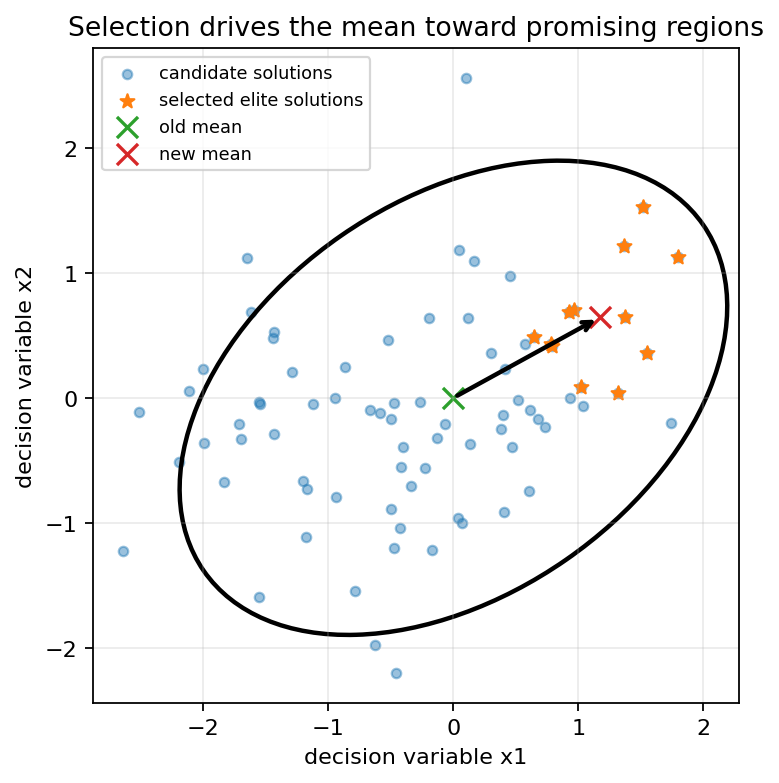
这一步的含义非常直观:
如果某个区域产生了更多高质量解,那么下一代的搜索中心就应该向这个区域移动。
需要注意的是,CMA-ES 通常主要依赖候选解的排序信息 ,而不是目标函数值的绝对大小。因此,它对目标函数的单调变换具有一定不变性。例如,在排序不变的情况下,优化 f(x)f(\mathbf{x})f(x) 和优化 log(f(x))\log(f(\mathbf{x}))log(f(x)) 对算法行为的影响相对有限。
5. 协方差矩阵:CMA-ES 的核心机制
CMA-ES 名字中的 "CMA" 指的就是 Covariance Matrix Adaptation,即协方差矩阵适应。
协方差矩阵 C\mathbf{C}C 决定了搜索分布的几何形状:
- 如果 C=I\mathbf{C} = \mathbf{I}C=I,搜索分布近似为球形;
- 如果 C\mathbf{C}C 的某些特征值较大,搜索会在对应方向上拉伸;
- 如果 C\mathbf{C}C 存在非零非对角元素,说明变量之间存在相关性;
- 如果 C\mathbf{C}C 经过多代学习后变成倾斜椭球,说明算法识别出了更有效的组合搜索方向。
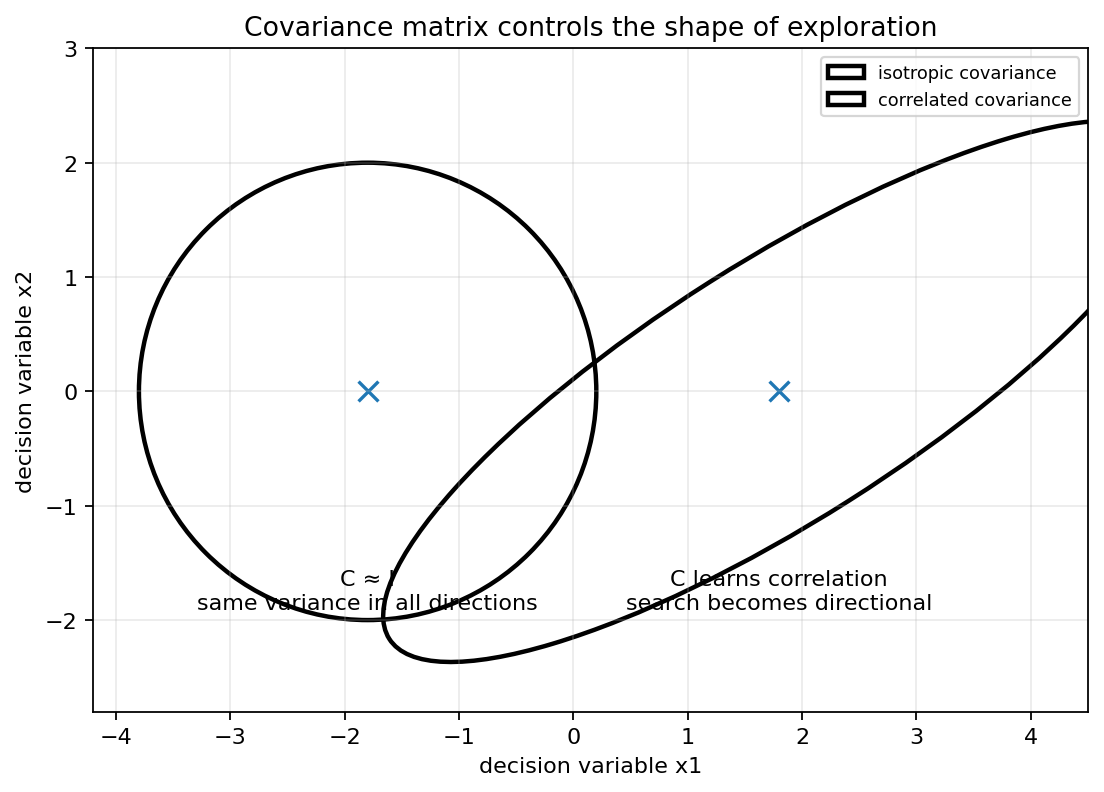
从直觉上看,CMA-ES 会不断回答一个问题:
优秀解通常沿着哪些方向出现?
如果优秀解在某个方向上连续出现,那么该方向就可能是有利搜索方向,协方差矩阵会增加该方向上的方差;反之,如果某些方向长期无法产生好解,那么这些方向上的搜索幅度会被压缩。
协方差矩阵的典型更新形式可以写为:
C(t+1)=(1−c1−cμ)C(t)+c1pc(t+1)pc(t+1)T+cμ∑i=1μwiyi:λ(t)yi:λ(t)T\mathbf{C}^{(t+1)} = (1 - c_1 - c_\mu)\mathbf{C}^{(t)} + c_1 \mathbf{p}c^{(t+1)}{\mathbf{p}c^{(t+1)}}^T + c\mu \sum{i=1}^{\mu} w_i \mathbf{y}{i:\lambda}^{(t)}{\mathbf{y}{i:\lambda}^{(t)}}^TC(t+1)=(1−c1−cμ)C(t)+c1pc(t+1)pc(t+1)T+cμi=1∑μwiyi:λ(t)yi:λ(t)T
这个公式可以拆成三部分理解:
| 组成部分 | 作用 |
|---|---|
| (1−c1−cμ)C(t)(1 - c_1 - c_\mu)\mathbf{C}^{(t)}(1−c1−cμ)C(t) | 保留上一代协方差结构 |
| c1pcpcTc_1 \mathbf{p}_c\mathbf{p}_c^Tc1pcpcT | 利用演化路径进行 rank-one 更新 |
| cμ∑wiyiyiTc_\mu \sum w_i \mathbf{y}_i\mathbf{y}_i^Tcμ∑wiyiyiT | 利用多个优秀个体进行 rank-μ\muμ 更新 |
这里的 pc\mathbf{p}_cpc 被称为协方差演化路径 。
它记录的是连续多代搜索中心移动方向的累积信息。相比只看当前一代,演化路径可以让算法更稳定地判断哪些方向是真正值得加强的。
6. 步长控制:什么时候扩大搜索,什么时候收缩搜索?
除了搜索方向,CMA-ES 还需要决定搜索范围。
这由全局步长 σ\sigmaσ 控制。
如果 σ\sigmaσ 太大,算法可能在最优区域附近来回跳跃,难以精细搜索;
如果 σ\sigmaσ 太小,算法可能过早陷入局部区域,探索能力不足。
CMA-ES 通常使用 CSA ,即 Cumulative Step-size Adaptation,累积步长适应机制。其核心思想是观察多代搜索方向是否一致。
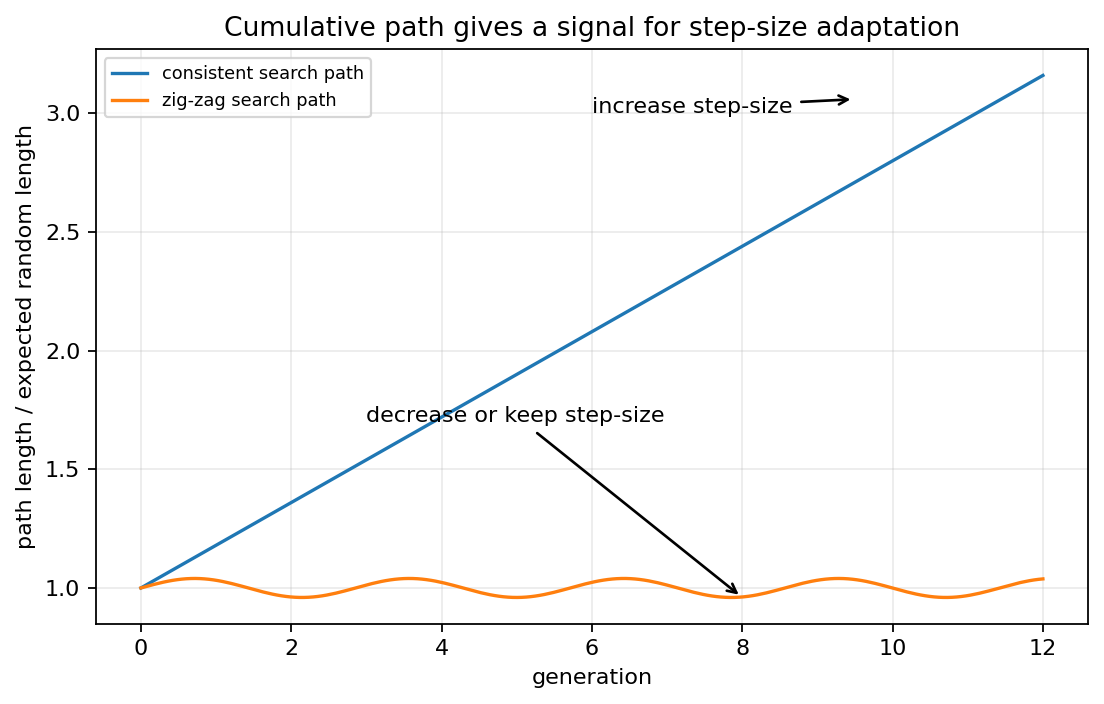
可以这样理解:
- 如果连续几代移动方向比较一致,说明当前搜索具有稳定趋势,步长可能偏小,可以适当增大;
- 如果移动方向频繁抵消,说明搜索像随机游走一样来回震荡,步长可能偏大,需要缩小或保持。
典型的步长更新形式为:
σ(t+1)=σ(t)exp(cσdσ(∥pσ(t+1)∥E∥N(0,I)∥−1))\sigma^{(t+1)}=\sigma^{(t)}\exp\left(\frac{c_\sigma}{d_\sigma}\left(\frac{\left\|\mathbf{p}_\sigma^{(t+1)}\right\|}{\mathbb{E}\left\|\mathcal{N}(\mathbf{0},\mathbf{I})\right\|}-1\right)\right)σ(t+1)=σ(t)exp dσcσ E∥N(0,I)∥ pσ(t+1) −1
其中:
- pσ\mathbf{p}_\sigmapσ:步长演化路径;
- cσc_\sigmacσ:步长学习率;
- dσd_\sigmadσ:阻尼系数;
- E∥N(0,I)∥E\|\mathcal{N}(\mathbf{0}, \mathbf{I})\|E∥N(0,I)∥:标准正态随机向量范数的期望。
这个机制让 CMA-ES 不需要人为频繁调节变异尺度,而是可以根据搜索过程自动判断探索范围是否合适。
7. 从"个体进化"到"分布进化"
很多传统进化算法直接操作个体,例如遗传算法中的交叉和变异,差分进化中的差分向量变异,粒子群优化中的速度更新。
CMA-ES 的不同之处在于,它真正进化的是一个概率分布:
传统进化算法
直接更新个体
依赖交叉、变异、差分或速度
搜索结构通常较隐式
CMA-ES
更新高斯分布
学习均值 m、步长 σ、协方差 C
显式建模搜索空间结构
因此,CMA-ES 可以被看作一种分布学习型进化策略 。
它的优势不在于算子形式复杂,而在于能够持续学习优秀解在决策空间中的几何结构。
8. CMA-ES 为什么有效?
8.1 能够学习变量之间的相关性
在许多优化问题中,变量之间不是独立的。
例如,某两个参数可能需要同时增大,目标函数才会改善。如果算法只能沿坐标轴方向搜索,就可能效率很低。
CMA-ES 通过完整协方差矩阵建模变量之间的相关性,因此能够适应旋转、拉伸后的搜索空间。
8.2 对坐标旋转具有较好的适应性
由于协方差矩阵可以学习任意方向上的方差结构,CMA-ES 对坐标旋转具有较强鲁棒性。
这意味着即使问题的主要优化方向并不与坐标轴对齐,CMA-ES 也能够逐渐学习出合适的搜索椭球。
8.3 只依赖排序信息,鲁棒性较强
CMA-ES 更新时主要看候选解的优劣排序,而不是函数值本身的绝对差距。
这使得它对目标函数数值尺度不太敏感。
只要候选解之间的相对优劣关系保持不变,算法整体行为就不会发生剧烈变化。
8.4 探索与开发之间的平衡自然形成
CMA-ES 中的三个核心参数共同形成了搜索平衡:
| 参数 | 偏探索时 | 偏开发时 |
|---|---|---|
| m\mathbf{m}m | 快速迁移到新区域 | 稳定靠近优质区域 |
| σ\sigmaσ | 搜索范围扩大 | 搜索范围收缩 |
| C\mathbf{C}C | 保持多方向尝试 | 沿优势方向精细搜索 |
因此,CMA-ES 不需要显式设计非常复杂的探索-开发切换机制,它可以通过搜索分布的自适应完成这一过程。
9. CMA-ES 的局限性
CMA-ES 并不是所有问题上的万能算法。它主要存在以下局限。
9.1 高维问题计算代价较高
标准 CMA-ES 需要维护一个 n×nn \times nn×n 的协方差矩阵,因此空间复杂度为:
O(n2) O(n^2) O(n2)
同时,协方差矩阵的特征分解或相关矩阵运算也会带来较高计算开销。
因此,标准 CMA-ES 更适合中低维连续优化问题。对于高维问题,通常需要使用 sep-CMA-ES、LM-CMA 等变体。
9.2 对离散和组合优化问题不直接适用
CMA-ES 的基础搜索分布是连续高斯分布,因此它天然适用于连续变量优化。
如果问题是离散变量、排列变量或复杂组合结构,通常需要专门编码或设计离散化变体。
9.3 在极低评价预算下可能不占优势
CMA-ES 需要通过多代采样来学习协方差结构。
如果函数评价预算极低,算法可能还没有充分学习到有效搜索方向,优化过程就已经结束。
9.4 仍然不保证全局最优
CMA-ES 是随机优化算法,不保证一定找到全局最优。
在高度多峰问题中,如果初始均值和步长设置不合适,它也可能收敛到局部最优区域。
10. 常见 CMA-ES 变体
| 变体 | 核心思想 | 适用场景 |
|---|---|---|
| sep-CMA-ES | 只维护对角协方差矩阵 | 较高维问题 |
| IPOP-CMA-ES | 重启时逐渐增大种群规模 | 多峰问题、全局搜索 |
| BIPOP-CMA-ES | 结合大种群和小种群重启 | 复杂多峰问题 |
| Active CMA-ES | 同时利用优秀个体和较差个体信息 | 加快协方差学习 |
| LM-CMA | 使用低秩近似降低复杂度 | 大规模连续优化 |
| MO-CMA-ES | 将 CMA-ES 扩展到多目标优化 | 多目标连续优化 |
对于多目标进化计算研究而言,CMA-ES 的思想也具有启发意义。
它可以被用作局部搜索算子、分布估计机制,或者与 Pareto 支配、小生境、聚类、分解策略等机制结合,用于增强决策空间搜索能力。
11. 一个更直观的类比
可以把 CMA-ES 想象成一个在山谷中寻找最低点的探测器。
一开始,它并不知道山谷的方向,只能在周围均匀探索。
经过若干轮试探后,它发现低处大多沿某个斜方向延伸,于是它不再盲目地向所有方向搜索,而是把探索区域拉成长椭圆,沿着山谷方向更积极地尝试,同时在垂直方向上减少无效搜索。
这个过程正是协方差矩阵适应的直观含义:
不知道地形
各向同性搜索
发现优秀解分布方向
拉伸有利方向
压缩无效方向
更高效地沿谷底搜索
12. 总结
CMA-ES 是连续黑箱优化领域中非常重要的一类进化策略。
它的核心不是设计复杂的交叉或变异算子,而是通过优秀解不断学习一个自适应高斯搜索分布。
从机制上看,CMA-ES 同时更新:
m,σ,C \mathbf{m}, \quad \sigma, \quad \mathbf{C} m,σ,C
也就是同时学习:
- 搜索中心在哪里;
- 搜索范围应该多大;
- 搜索方向和变量相关性应该是什么。
它的主要优势包括:
- 不依赖梯度信息;
- 能够处理非凸、多峰、病态连续优化问题;
- 能够学习变量相关性;
- 对坐标旋转和函数值尺度变化具有较好鲁棒性;
- 可以作为其他进化算法中的局部搜索或分布学习模块。
不过,标准 CMA-ES 在高维问题上计算成本较高,对离散问题也不直接适用。因此,在实际使用时,需要结合问题维度、评价预算、变量类型和约束结构选择合适的 CMA-ES 版本。
总的来说,CMA-ES 的重要价值不仅在于它本身是一个强大的优化器,更在于它提供了一种非常值得借鉴的思想:
优化不只是寻找更好的个体,也可以是持续学习优秀解在搜索空间中的分布结构。