
深度学习里最常见的数据形态就是:标量、向量、矩阵、张量。你只要把线性代数这章吃透,后面梯度、线性回归、softmax、CNN 的维度变化都会顺很多。
本文按李沐的顺序:线性代数概念 → 用 PyTorch 实现 → 按轴求和 → 矩阵计算套路。
1. 标量 / 向量 / 矩阵 / 张量:深度学习的数据"四件套"
-
标量(scalar) :一个数,比如损失
loss=2.3 -
向量(vector) :一串数,比如一个样本的特征
x∈R^d -
矩阵(matrix) :二维表,比如一批样本
X∈R^{n×d} -
张量(tensor) :更高维,比如图像 batch
N×C×H×W
PyTorch 里都用 torch.Tensor 表示,维度通过 shape 看。
import torch
x = torch.tensor(3.14) # 标量
v = torch.arange(4) # 向量 shape=(4,)
A = torch.arange(12).reshape(3, 4) # 矩阵 shape=(3,4)
T = torch.randn(2, 3, 4) # 张量 shape=(2,3,4)
print(x.shape, v.shape, A.shape, T.shape)2. 向量的核心运算:加法、数乘、点积(dot)
2.1 逐元素运算(elementwise)
v = torch.tensor([1., 2., 3.])
u = torch.tensor([10., 20., 30.])
print(v + u) # [11,22,33]
print(v * u) # 逐元素乘
print(2 * v) # 数乘2.2 点积(dot product):最常见的"相似度/加权和"
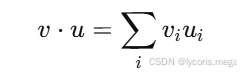
v = torch.tensor([1., 2., 3.])
u = torch.tensor([10., 20., 30.])
print(torch.dot(v, u)) # 1*10 + 2*20 + 3*30 = 140直觉:点积 = "对应维度相乘再求和",后面线性层
y = Xw本质就是大量点积。
3. 矩阵运算:转置、矩阵乘法、Hadamard 乘法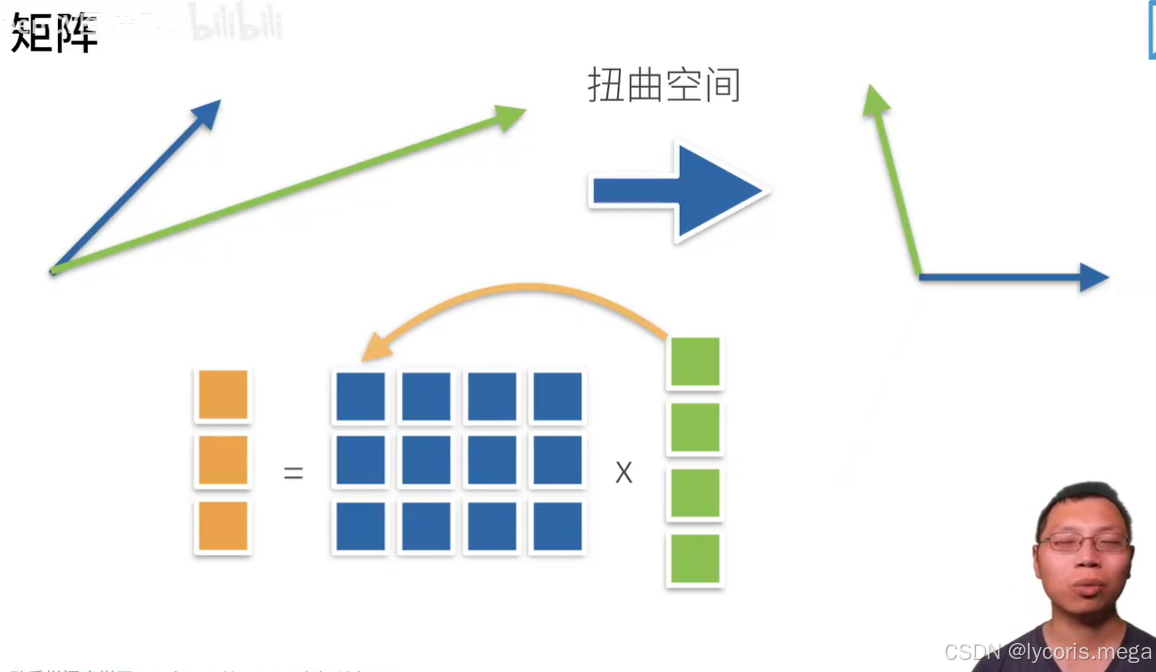
3.1 转置(transpose)
A = torch.arange(12).reshape(3, 4)
print(A.T) # (4,3)3.2 两种"乘法"别混了
1)逐元素乘(Hadamard product):形状必须一样
A = torch.ones(2, 3)
B = torch.full((2, 3), 2.)
print(A * B) # 逐元素2)矩阵乘法(matrix multiplication):线性代数里的乘法
A = torch.randn(2, 3)
B = torch.randn(3, 4)
C = A @ B # 或 torch.matmul(A, B)
print(C.shape) # (2,4)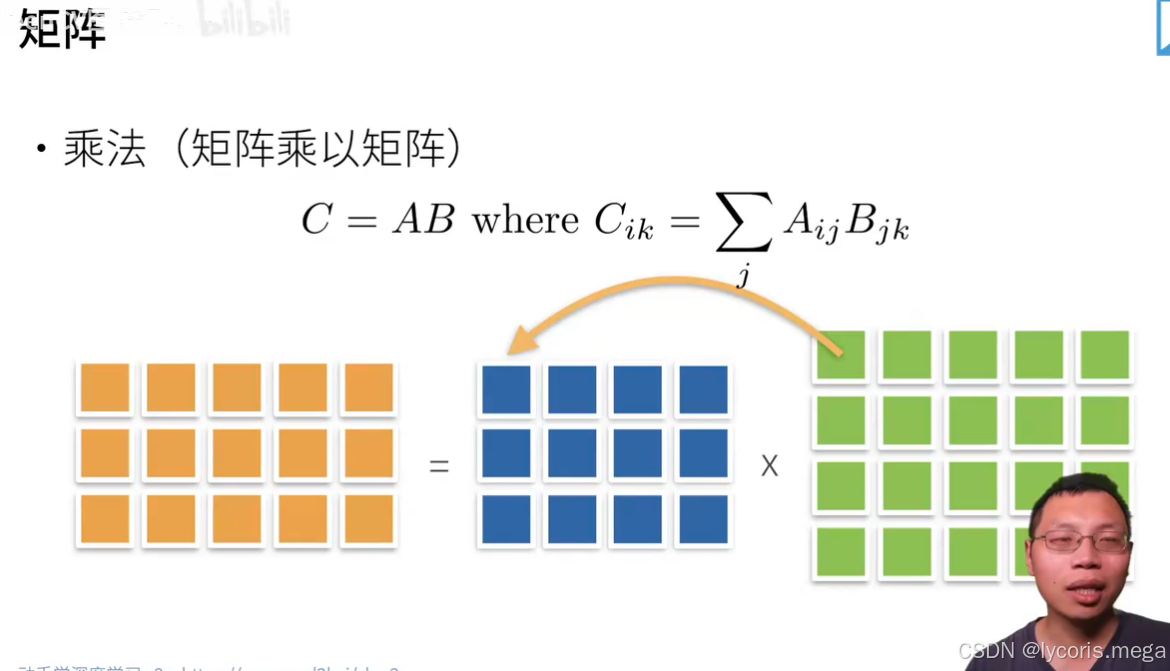
记忆法:
*是逐元素;@才是矩阵乘法。
4. 范数(Norm):衡量"向量/矩阵有多大"
深度学习里最常用的两个:

4.1 L2 范数(欧氏长度)
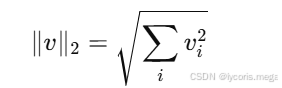
v = torch.tensor([3., 4.])
print(torch.norm(v)) # 54.2 L1 范数(绝对值和)
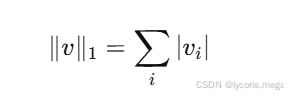
v = torch.tensor([1., -2., 3.])
print(torch.norm(v, p=1)) # 6直觉:L2 更像"距离",L1 更像"稀疏惩罚"(后面正则化会出现)。


5. 按特定轴求和:sum(dim=?)

这一节是很多人第一次被 "dim/axis" 搞懵的地方。核心:dim 是"要被消掉的那个维度"。
A = torch.arange(12).reshape(3, 4)
print(A)
# [[0,1,2,3],
# [4,5,6,7],
# [8,9,10,11]]
print(A.sum()) # 全部求和 -> 标量
print(A.sum(dim=0)) # 按列求和 -> shape=(4,)
print(A.sum(dim=1)) # 按行求和 -> shape=(3,)-
dim=0:把第 0 维(行维)消掉 → "每一列加起来" -
dim=1:把第 1 维(列维)消掉 → "每一行加起来" -
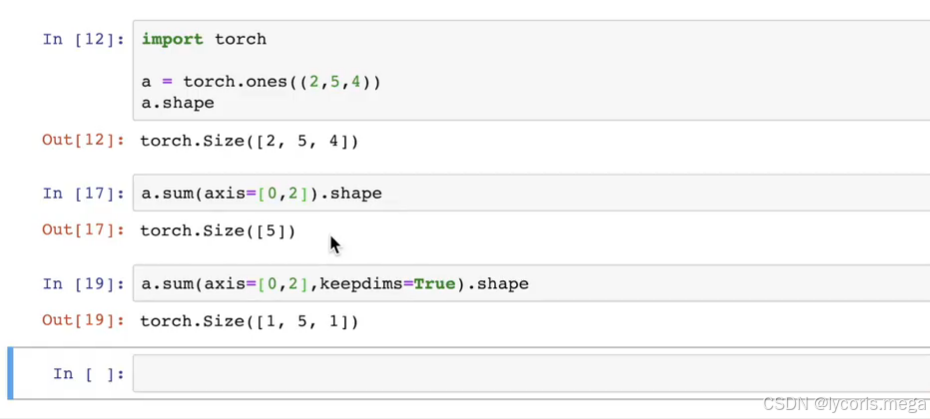
保持维度:keepdim=True(很关键)
print(A.sum(dim=1, keepdim=True).shape) # (3,1)后面做广播、做归一化、做 softmax 时,
keepdim=True很常用,不然维度对不上。
6. 矩阵计算套路:batch 视角 + 广播 + 维度对齐

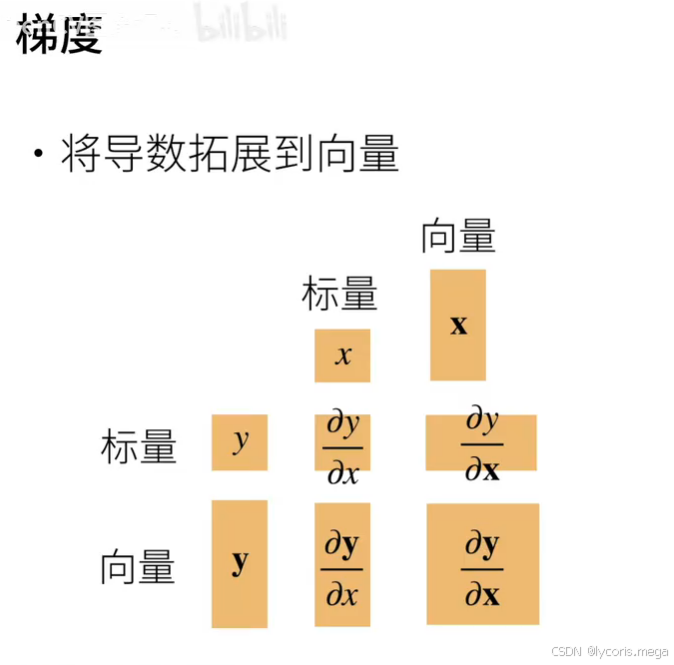

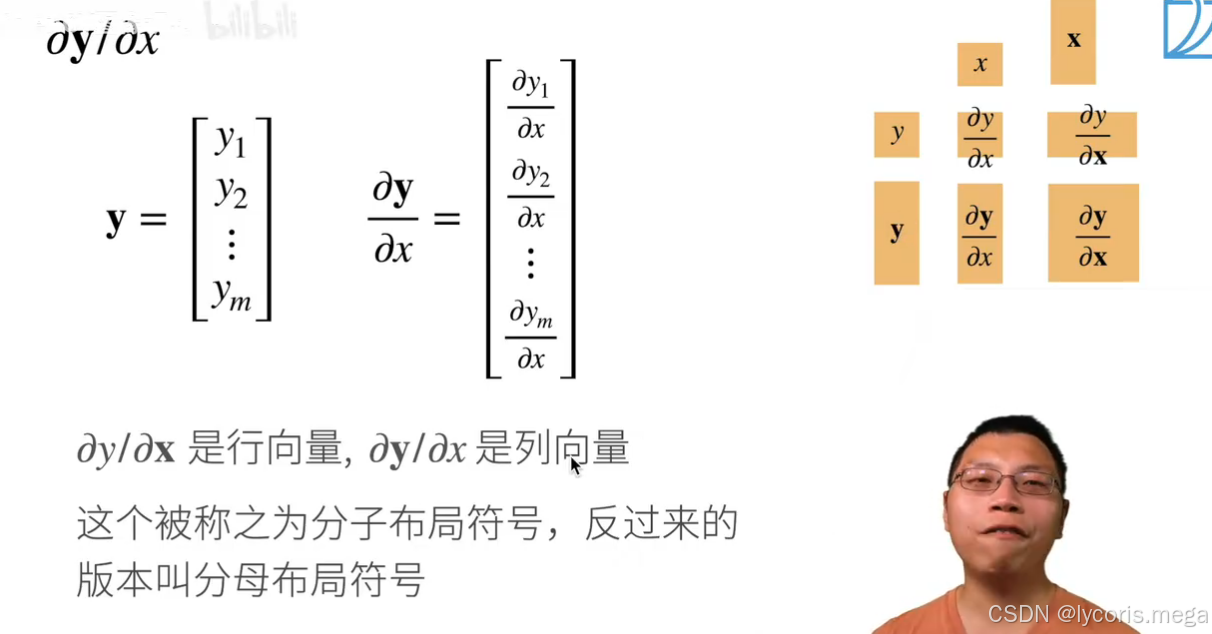


深度学习里你经常面对的是:batch 维度 N 叠在最前面。
比如一个 batch 的特征矩阵:X.shape = (N, d)
权重:w.shape = (d, 1)
线性回归输出:y_hat = X @ w → (N,1)
N, d = 4, 3
X = torch.randn(N, d)
w = torch.randn(d, 1)
b = torch.randn(1)
y_hat = X @ w + b # b 会自动广播到 (N,1)
print(y_hat.shape) # (4,1)广播规则(broadcasting)在这里非常重要
-
维度从后往前对齐
-
相等 ✅ 或者其中一个是 1 ✅
7. 本章最常见的坑
- 把
*当成矩阵乘法
-
逐元素:
A * B -
矩阵乘:
A @ B/torch.matmul
sum(dim=0)和sum(dim=1)搞反
-
dim=0→ 列求和 -
dim=1→ 行求和
- 忘记
keepdim=True导致后面广播失败
- 做归一化/softmax 时尤其常见
-
形状不对但你以为是"数学错了"
其实是
shape错了:养成习惯print(X.shape)。
结语:线性代数学到什么程度算够?
对深度学习来说,你至少要能做到:
-
看懂
X @ w + b的维度流动 -
熟练
sum(dim=?) / keepdim -
搞清楚
*vs@ -
知道范数是"大小/正则化"的基础概念