目录
[3.1 整体架构](#3.1 整体架构)
[3.1.1 骨干网络Backbone Network](#3.1.1 骨干网络Backbone Network)
[3.1.2 文本感知引导 Text-Aware Guidance](#3.1.2 文本感知引导 Text-Aware Guidance)
[3.1.3 物理感知引导 Physics-Aware Guidance](#3.1.3 物理感知引导 Physics-Aware Guidance)
[3.1.4 感知融合模型 Perceptual Fusion Model](#3.1.4 感知融合模型 Perceptual Fusion Model)
[3.2 损失函数](#3.2 损失函数)
文章标题:《Exploiting Diffusion Prior for Real-World Image Dehazing with Unpaired Training》
作者:Yunwei Lan
期刊 :AAAI 2025
论文链接![]() https://arxiv.org/pdf/2503.15017v1
https://arxiv.org/pdf/2503.15017v1
代码链接:https://github.com/ywxjm/Diff-Dehazer
一、摘要
无配对训练(Unpaired training) 已被验证为是用于真实场景去雾的最有效范式之一,通过从无配对的真实世界有雾和清晰图像中学习。由于特征表示有限以及对现实世界先验的利用不足,当前方法在各种真实场景中的泛化能力有限。受到扩散模型在生成朦胧和清晰图像方面强大生成能力 的启发,利用扩散先验进行真实世界图像去雾,并提出了一个名为 Diff-Dehazer 的无配对框架。具体来说,在CycleGAN(一个经典的无配对学习框架) 中利用扩散先验作为双射映射学习器。考虑到物理先验包含了真实世界数据的关键统计信息,通过将物理先验整合到框架中,进一步挖掘真实世界的知识。此外,文中提出了一种新的方法,通过去除图像和文本模态中的退化现象,充分利用扩散模型的表示能力,从而提高去雾效果。
**CycleGAN(循环生成对抗网络)**一种无监督的用于图像到图像的转换的深度学习模型,能够在没有成对训练样本的情况下,实现两个图像域之间的转换。其核心思想是通过对抗训练和循环一致性损失确保转换的合理性和可逆性。
二、引言
大气散射模型及其公式这里不再进行介绍,具体参考:以下博客的3.1章节。Reading paperAn All-in-One Network for Dehazing and Beyond-CSDN博客
先前的方法(基于物理先验的去雾方法、基于深度学习的去雾方法)主要利用合成配对数据进行训练,因为获取真实世界中的雾霾和清晰图像对几乎是不可能的。尽管性能有所提升,但由于训练的网络缺乏来自雾霾图像的真实世界信息,这种配对训练范式在实际去雾场景中往往难以泛化表现不佳。
为了解决无配对训练的瓶颈,有学者考虑了图像去雾的非配对训练,以便从真实世界的雾霾图像中发现可用信息,并建模真实世界雾霾图像与清晰图像之间的特定映射。无配对训练的关键问题是如何在有雾图像和去雾图像之间施加结构一致性约束,从而抑制由未配对的真实清晰图像引起的错位信息的影响。
CycleGAN 通过利用一个框架来保持映射域与原始域之间的一致性,为无配对训练提供了一个经典的解决方案。该方法被多个研究采用,并显示出良好的实际去雾性能。然而,这些方法在训练图像数量有限的情况下难以实现有效表示,从而导致性能不佳。 同时,受到扩散模型强大表示能力的启发,一些方法采用了预训练和微调模式,利用扩散先验来提升去雾效果,然而,由于这些方法依赖于无法模拟真实场景的合成配对训练数据,它们在若干真实场景中仍存在局限性。
为解决以上问题,本文提出了一种有效的用于真实世界图像去雾的范式结构,名为Diff-Dehazer。因为单纯继承非配对训练框架而不考虑真实雾霾场景的物理特性,图像去雾将会表现出次优的去雾性能,因此本文将物理先验整合到框架中。此外,观察到文本描述可以通过提供丰富的高级语义来改善生成的图像,这在之前的研究中已经验证了其有效性。因此,我们采用多模态范式,将文本和图像结合以提高去雾效果。
本文的主要贡献有以下四个方面:
(1)采用预训练的稳定扩散模型作为CycleGAN框架的基础,以利用其在对真实世界数据建模的强大表征能力。
(2)我们通过物理先验 (在以往的研究中被严重忽视)提升图像去雾的泛化能力(generalization ability),并在框架中提出了物理感知引导(Physics-Aware Guidance,PAG)。
(3)我们利用储存在文本模态中的丰富高级语义信息,在框架中提出了文本感知引导(Text-Aware Guidance,TAG)以引导图像去雾的文本指导。
(4)为了促进这一主题的进一步研究,我们构建了一个非配对的真实世界数据集,包含6519张雾图和11293张清晰图像。
三、主要内容
3.1 整体架构
根据CycleGAN,我们为真实世界数据的无配对训练建立了一个雾化------去雾循环,以及雾化和去雾过程。在训练过程中,真实的雾霾图像被转换为伪清晰图像,然后再转化回循环雾霾图像
。相反的顺序,对真实清晰图像
也应用类似的过程。
图1是整体架构。黑色箭头表示训练过程,蓝色箭头表示推理过程。
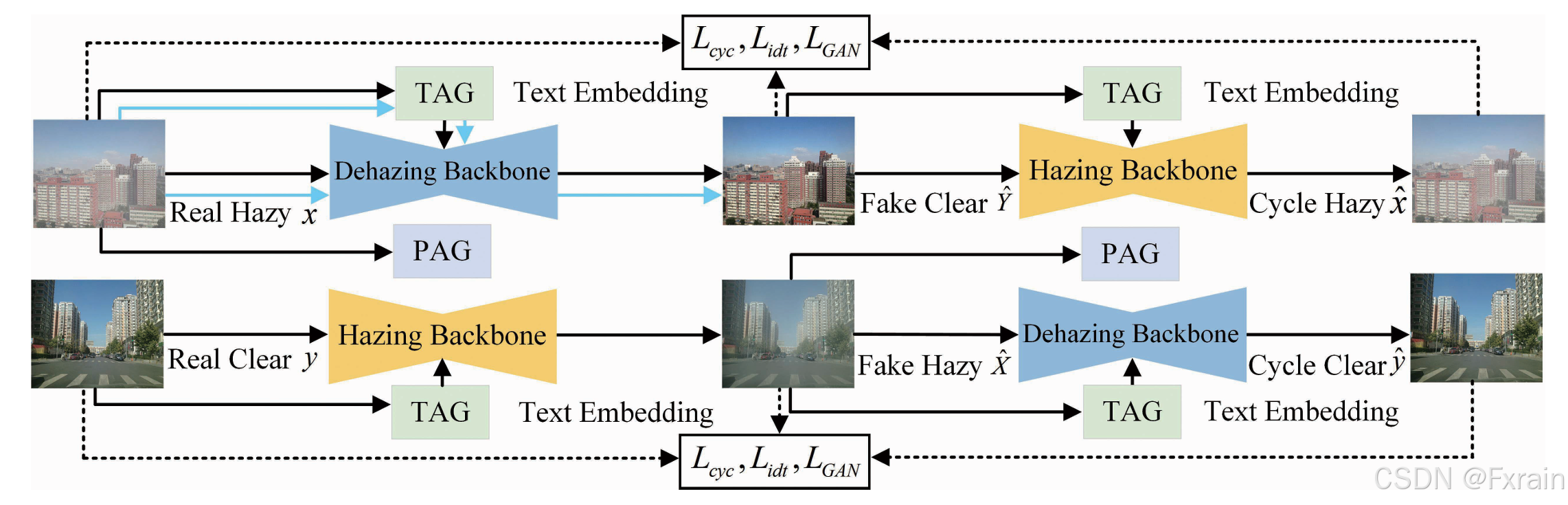 图1 Diff-Dehazer整体架构
图1 Diff-Dehazer整体架构
雾化过程包括一个雾化主干(hazing backbone)和文本感知引导(Text-Aware Guidance,TAG)。
去雾过程包含三个组件:去雾主干(dehazing backbone)、物理感知引导(Physics-Aware Guidance)和文本感知引导(TAG)。
使用循环一致性约束来训练框架。经过训练后,可以仅通过去雾过程从模糊的图像中获得清晰的图像(参见图1中的蓝色箭头)。
3.1.1 骨干网络Backbone Network
SD Turbo(v2.1)作为Stable Diffusion(SD)2.1的蒸馏版本,因为它允许在一步中生成大量高质量的图像,因此使用其作为雾化和去雾的骨干,如图2所示。
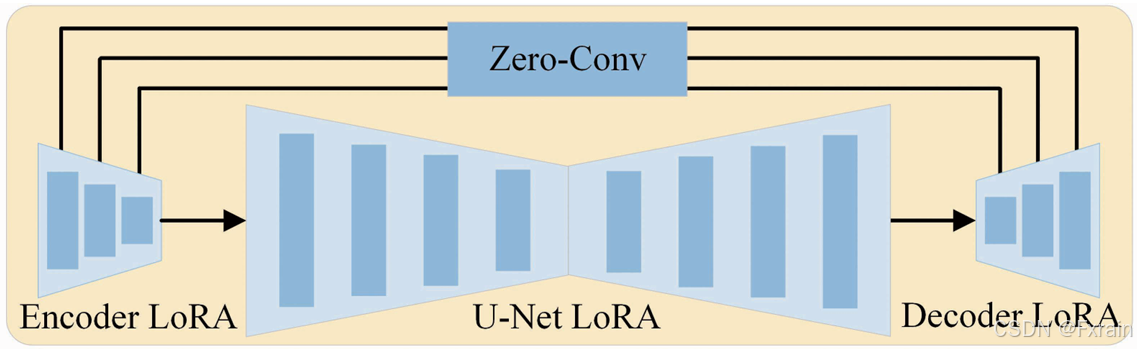 图2 骨干网络
图2 骨干网络
**这个网络包含三个主要组件:VAE的编码器和解码器,以及U-Net模块。**注意雾化和去雾的骨干网络共享相同的 U-Net,并使用两个独立的 VAE。为了高效利用扩散先验信息(封装在SSD Turbo中),使用LoRA适配器进行训练,而不是从零开始训练。具体来说,只更新主干网络的输入层以及额外的LoRA适配器,同时保持其余模型参数冻结。
之前基于SD的图像恢复方法通常首先通过预训练的VAE将图像从像素空间映射到潜在空间,然后在VAE潜在空间中进行恢复过程。一旦VAE特征由扩散模型生成,恢复的图像会通过VAE的解码器转换回像素空间。然而,这些方法不能直接应用于图像去雾,因为在高度压缩的空间中进行去雾不可避免地会导致图像信息的显著丢失。因此,最终恢复的图像在多个方面(例如局部细节和纹理)与原始图像存在明显差异,保真度明显较低。为了在去雾过程中保留源图像的细节,在VAE的编码器和解码器之间实现了一个跳跃连接。
3.1.2 文本感知引导 Text-Aware Guidance
文本特征被证明能够为生成模型提供丰富的高级语义,并且已经在稳定扩散中展示了其有效性。基于此发现,本文预计将进一步将文本信息整合到框架中,以通过文本特征增强去雾过程。图3展示了文本感知引导(TAG)。具体来说,该模块首先使用一个预训练的图像描述器为输入图像生成一个描述,然后将提取的描述用于后续处理。注意,在推理任何真实世界的有雾图像时,用户可以根据自己的需求手动自定义文本描述。
与当前方法中显式使用文本描述不同,我们从以下两个角度引入TAG。一方面,通过去除与雾相关的词语(例如,"雾霾"、"雾"等),来精炼这些描述,从而在文本模态中显式地促进图像去雾 。另一方面,我们通过无分类器指导 利用正向和负向提示来提高去雾图像的质量,其中精炼后的描述作为正向提示。考虑到雾霾属性可能过于复杂而无法用显式词语描述,我们通过文本反演从成千上万的真实雾天图像中学习提示,以整体方式隐式描绘雾霾属性。通过获得的正向和负向提示,我们通过CILP的文本编码器实现更全面的语义指导 ,并进一步提升图像质量。至于雾化过程,我们首先通过BLIP-2直接获取图像描述,然后将与雾相关的词语与提取的描述结合,作为正向提示。对于负向提示,我们设置为空文本。
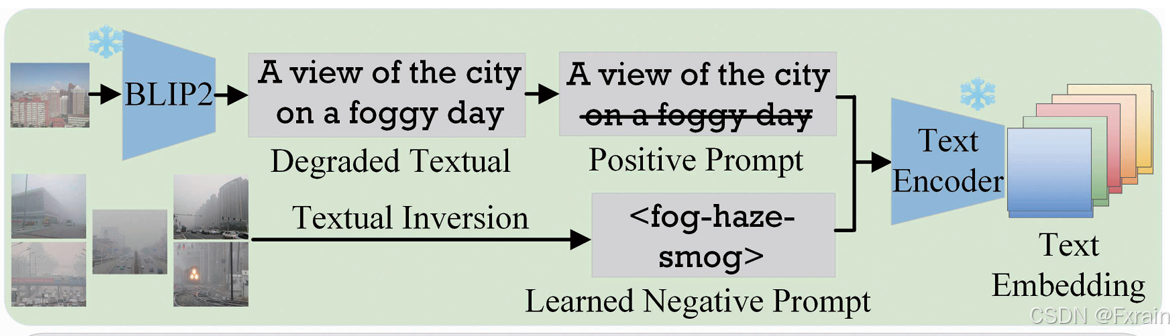 图3 文本感知引导
图3 文本感知引导
3.1.3 物理感知引导 Physics-Aware Guidance
先前的研究表明,使用物理先验更有可能去除雾霾,尤其是在现实场景中,因为这些先验是基于大量现实清晰图像的统计规律。因此我们将物理先验引入框架,并为图像去雾引入物理感知引导(PAG),如图4所示。
与之前的方法不同,我们研究了各种物理先验,并将两个表现良好的先验,即 DCP (暗通道先验)和 BCCR (边界约束与上下文正则化)集成到框架中 。在获得初步去雾结果 J、大气光 A 和透射率图 t 后,我们通过 ASM (大气散射模型)重建雾图像并设计物理损失。通过微调去雾主干网络,模型遵循基本的物理原理,实现更有效的去雾和物理感知。
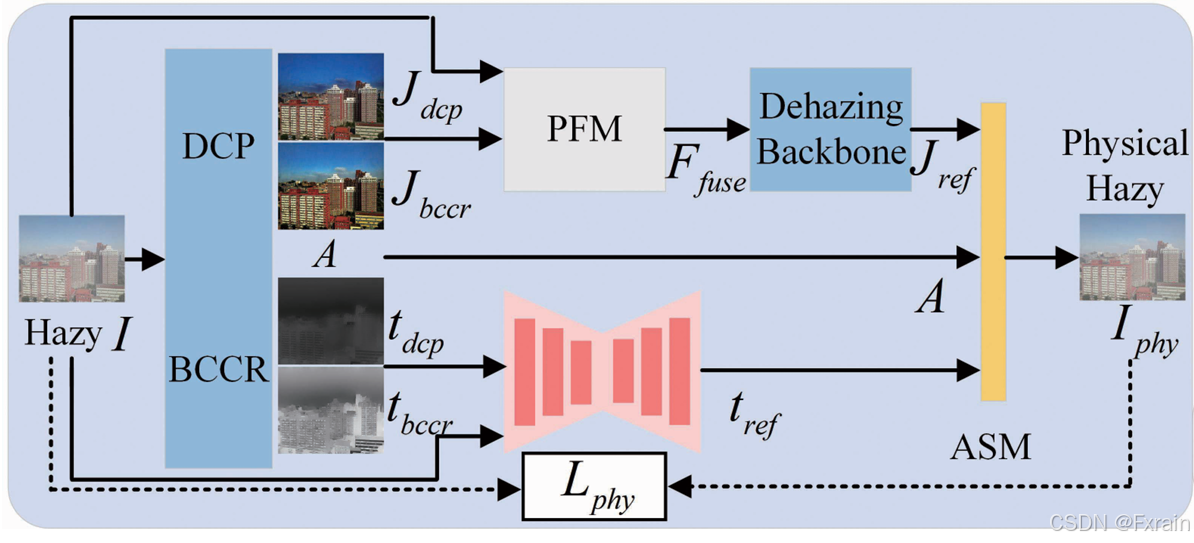 图4 物理感知引导
图4 物理感知引导
模糊图像重建 :为了利用由 DCP 和 BCCR 去雾的清晰图像中封装的物理先验,我们将它们视为用于雾图像重建的清晰图像,从而迫使模型更多地学习真实世界雾的物理特性。在各种应用场景下,我们观察到 或
在某些区域中的表现优于另一者,我们进一步对它们进行精细化处理,而不是直接应用。对于
和
,我们将它们进行拼接并输入U-Net,以获得精细化的传输图
。鉴于输入图像包含源信息,我们将其作为输入,并与传输图一起输入U-Net。
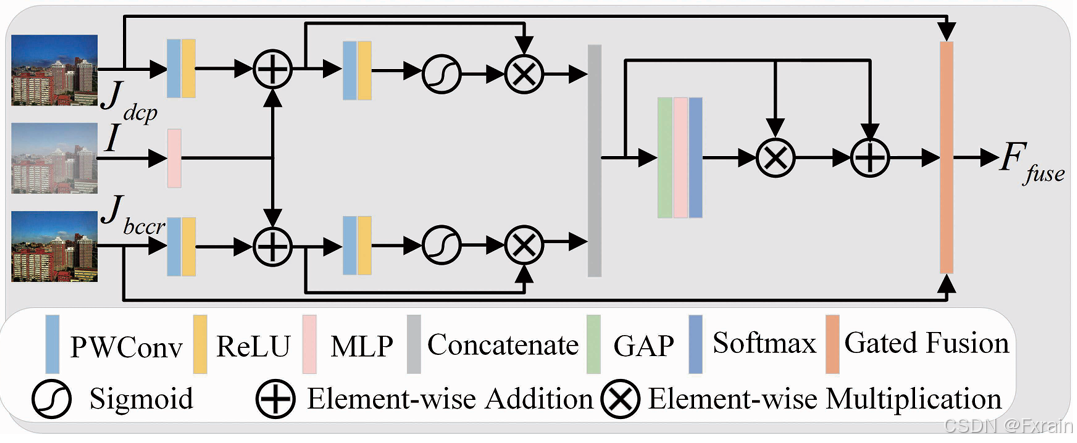
3.1.4 感知融合模型 Perceptual Fusion Model
为了结合 和
的优势,我们引入了感知融合模型(Perceptual Fusion Model,PFM)来有效融合它们,从而获得复合图像
。在我们的框架中,去雾主干不仅能够从有雾的输入中恢复清晰的图像,还能够增强清晰输入的图像质量 。因此,我们将去雾主干视为一个精炼网络,并将
输入其中,以获得一个具有增强自然细节和物理感知的精炼清晰图像
。通过这样做,我们可以使用精炼的
、
和
重建一个更合格的雾化图像
,从而施加更合理的物理约束。
PFM架构如图5所示。我们利用点卷积层、ReLU 和 MLP 从 、
和
中提取潜在特征 。为了保留在初始去雾图像中可能丢失的任何信息 ,我们将
的特征添加到
和
的特征中。引导特征通过点卷积层、ReLU、Sigmoid 和残差连接获得。随后,我们使用全局平均池化、MLP 和 Softmax 对它们进行拼接和重新加权 。拼接后的特征随后乘以获得的权重,并通过残差连接产生粗融合特征 。最后,我们通过门控融合 重新加权
和
的比例,从而得到精融合结果
。
3.2 损失函数
根据CycleGAN,我们将所提出的模型的训练损失设计为:
这里 ,
,
和
分别代表 循环一致性损失(cycle consistency loss)、先验损失(prior loss)、身份损失(identity loss)和GAN损失(GAN loss)。
,
和
是用于控制
,
和
权重的对应超参数。
另外,鉴于使用物理先验,我们设计物理损失为:
其中 指由ASM重建的有雾图像。
表示涉及真实/虚假雾图像的整体符号。