回顾:简介→功能→flask应用五行代码→路由详解→模版渲染Jinja2
1、 数据库集成(Flask-SQLAlchemy)
1.1、 什么是Flask-SQLAlchemy?
Flask-SQLAlchemy 是 Flask 官方推荐的数据库扩展,它将 Flask 的简洁灵活 与 SQLAlchemy 的强大ORM功能 完美结合。
| 特性 | 说明 |
|---|---|
| ORM框架 | 对象关系映射,用Python类操作数据库 |
| 轻量级 | 核心极简,按需扩展 |
| 多数据库支持 | MySQL、PostgreSQL、SQLite等 |
| 会话管理 | 自动处理数据库会话 |
1.2、 为什么选择ORM?
传统SQL操作痛点 → ORM方式优势
├─ SQL注入风险 → 参数自动转义
├─ 不同数据库语法差异 → 统一接口
├─ 重复编写CRUD代码 → 内置方法
└─ 对象与关系转换繁琐 → 自动映射1.3、 Flask-SQLAlchemy 与 Navicat 的区别
虽然两者都与数据库相关,但它们的定位、用途和功能完全不同。简单来说:
Flask-SQLAlchemy 是代码层面的数据库操作工具 ,而 Navicat 是可视化的数据库管理工具。
1.3.1、 核心对比表
| 对比维度 | Flask-SQLAlchemy | Navicat |
|---|---|---|
| 本质 | Python ORM框架/库 | 数据库管理GUI软件 |
| 使用方式 | 编写Python代码 | 图形界面点击操作 |
| 运行环境 | 应用程序内部 | 独立的桌面/服务器应用 |
| 目标用户 | 后端开发者 | DBA、开发者、数据分析师 |
| 收费情况 | 开源免费 | 商业软件(需付费) |
| 主要功能 | 数据库CRUD操作、ORM映射 | 数据浏览、SQL执行、数据导入导出、备份恢复 |
| 支持数据库 | 通过驱动支持多种数据库 | 原生支持多种数据库 |
| 是否需要安装 | pip安装Python包 | 下载安装客户端软件 |
1.3.2、 功能对比详解
1.3.2.1、 Flask-SQLAlchemy 的核心功能
┌─────────────────────────────────────────┐
│ Flask-SQLAlchemy │
├─────────────────────────────────────────┤
│ ✅ 对象关系映射(ORM) │
│ ✅ 在Python代码中操作数据库 │
│ ✅ 自动会话管理 │
│ ✅ 模型定义与迁移 │
│ ✅ 集成到Flask应用 │
│ ✅ 查询构建与执行 │
│ ❌ 无图形界面 │
│ ❌ 不能直接浏览数据 │
└─────────────────────────────────────────┘使用示例:
# 在代码中操作数据库
user = User.query.filter_by(username='john').first()
user.email = 'new@example.com'
db.session.commit()1.3.2.2、 Navicat 的核心功能
┌─────────────────────────────────────────┐
│ Navicat │
├─────────────────────────────────────────┤
│ ✅ 图形化数据浏览与编辑 │
│ ✅ SQL查询编辑器(带语法高亮) │
│ ✅ 数据导入/导出(Excel、CSV等) │
│ ✅ 数据库备份与恢复 │
│ ✅ 表结构设计与管理 │
│ ✅ 数据同步与结构同步 │
│ ✅ 用户权限管理 │
│ ✅ 监控与诊断工具 │
│ ❌ 不能集成到应用程序代码中 │
└─────────────────────────────────────────┘使用场景:
- 查看数据库表结构和数据
- 手动执行SQL语句测试
- 导出查询结果为Excel
- 备份和恢复数据库
- 比较两个数据库的差异
1.3.3、 实际工作流中的关系
┌──────────────────────────────────────────────────────────────┐
│ 典型开发工作流 │
├──────────────────────────────────────────────────────────────┤
│ │
│ ┌─────────────┐ ┌─────────────┐ │
│ │ 开发阶段 │ │ 运维/调试 │ │
│ │ │ │ 阶段 │ │
│ │ Flask- │ 代码 │ │ │
│ │ SQLAlchemy │ ──────→ │ 数据库 │ │
│ │ (写代码操作) │ 操作 │ 服务器 │ │
│ └─────────────┘ └──────┬──────┘ │
│ │ │
│ │ 可视化 │
│ ↓ │
│ ┌─────────────┐ │
│ │ Navicat │ │
│ │ (查看/调试) │ │
│ └─────────────┘ │
│ │
└──────────────────────────────────────────────────────────────┘两者配合使用:
开发时 :用 Flask-SQLAlchemy 编写代码操作数据库
调试时 :用 Navicat 查看数据是否正确写入
维护时 :用 Navicat 执行批量SQL、备份数据
分析时:用 Navicat 导出数据进行报表分析
一句话总结:
- 🟢 Flask-SQLAlchemy 构建应用🟢 Navicat辅助开发和调试
1.3.4、 使用场景
| 场景 | 推荐工具 |
|---|---|
| 在Web应用中操作数据库 | Flask-SQLAlchemy |
| 查看/浏览数据库数据 | Navicat |
| 执行临时SQL查询 | Navicat |
| 数据导入导出 | Navicat |
| 数据库备份恢复 | Navicat |
| 自动化数据处理 | Flask-SQLAlchemy |
| 生产环境应用逻辑 | Flask-SQLAlchemy |
| 数据库结构对比 | Navicat |
1.3.5、 类似工具对比
| 类别 | 工具示例 |
|---|---|
| ORM框架(类似Flask-SQLAlchemy) | Django ORM、Peewee、Tortoise ORM |
| 数据库管理工具(类似Navicat) | DBeaver、MySQL Workbench、DataGrip、phpMyAdmin |
2、 安装与配置
2.1、 安装,验证
2.1.1、 打包下载:
bash
pip install -r requirements.txt
bash
#requirements.txt
# Flask 核心
Flask==3.0.0
# 数据库
Flask-SQLAlchemy==3.1.1
Flask-Migrate==4.0.5
PyMySQL==1.1.0
python-dotenv==1.2.12.1.2、 pip安装包
pip install flask-sqlalchemy flask-migrate pymysql2.1.3、 conda安装包
# 激活你的conda环境
conda activate your_env_name
# 从conda-forge频道安装
conda install -c conda-forge flask-sqlalchemy pymysql
conda install -c conda-forge flask-migrate 

2.1.4、 验证:
bash
conda list flask
conda list pymysql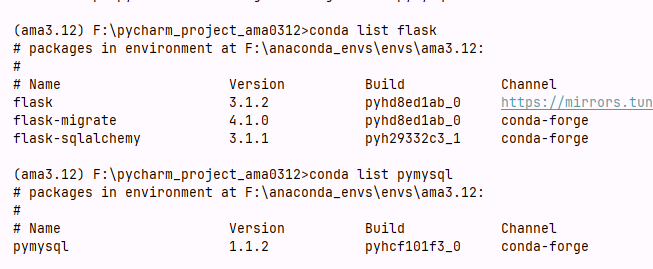
2.2、 Flask-SQLAlchemy 项目执行前配置
2.2.1、 BAT创建项目架构

创建项目文件bat:
@echo off
cd flask_simple && chcp 65001&& type nul > flask_simple\app.py && type nul > flask_simple\models.py && type nul > flask_simple\config.py&& echo FINISH!2.2.1.1、 扩展:
| 命令 | 作用 |
|---|---|
mkdir |
创建目录 |
type nul > 文件 |
创建空文件 |
chcp 65001 |
设置 UTF-8 编码 |
@echo off |
隐藏命令回显 |
2.2.2、 安全配置
| 场景 | 建议 |
|---|---|
| 开发环境 | 可用默认值或 .env 文件 |
| 生产环境 | ❌ 不要使用代码中的默认值,必须用.env |
| 密钥生成 | 使用 secrets.token_hex(32) 生成随机密钥 |
| 版本控制 | .env 文件加入 .gitignore,不要提交到仓库 |
2.2.2.1、 .env模版
创建 .env 文件(与代码同级目录):
# .env 配置文件 (模版)
# 数据库连接地址
ATABASE_URL=mysql+pymysql://用户名:密码@主机:端口/新数据库名?charset=utf8mb4
# Flask 安全密钥随机生成 (python -c "import secrets; print(secrets.token_hex(32))")
SECRET_KEY=your-secret-key-here
# 调试模式 (生产环境请设为 False)
EBUG=True2.2.2.2、 .gitignore

2.2.2.3、 sectet key使用步骤
2.2.2.3.1、 生成安全密钥的方法:
终端:
import secrets
print(secrets.token_hex(32)) # 生成64字符随机密钥2.2.2.3.2、 秘钥配置:
环境变量方式(推荐 ✅)
代码中的 os.environ.get('SECRET_KEY') 会从系统环境变量中读取,设置方法如下:
| 系统 | 设置方法 |
|---|---|
| Linux/Mac | export SECRET_KEY=your-secret-key |
| Windows CMD | set SECRET_KEY=your-secret-key |
| Windows PowerShell | $env:SECRET_KEY="your-secret-key" |
| 永久设置 | 添加到 ~/.bashrc、~/.zshrc 或系统环境变量 |
| 编辑 .env 文件(开发环境推荐) |
#.env 配置文件
# Flask 安全密钥 (粘贴秘钥)
SECRET_KEY=your-secret-key-here 2.2.2.3.3、 使用安全密钥的方法:
python-dotenv 加载:

2.3、 项目配置
2.3.1、 方法1:终端配置:
┌─────────────────────────────────────────────────────────────────┐
│ 终端完整操作流程 │
├─────────────────────────────────────────────────────────────────┤
│ # 登录 MySQL │
│ mysql -u root -p │
│ 1. 创建数据库(flask_simple) │
│ mysql> CREATE DATABASE ama_simple CHARACTER SET utf8mb4; │
│ │
│ 2. 创建用户(ama_simple) │
│ mysql> CREATE USER 'ama_simple'@'localhost' IDENTIFIED BY 'pwd';│
│ │
│ 3. 授权 │
│ mysql> GRANT ALL PRIVILEGES ON flask_simple.* TO 'ama_flask'@'localhost'; │
│ │
│ 4. 刷新权限 │
│ mysql> FLUSH PRIVILEGES; │
│ │
│ 5. 更新 Flask 配置 │
│ SQLALCHEMY_DATABASE_URI = 'mysql+pymysql://...' │
│ │
│ 6. 运行 Flask 应用 │
│ python app.py │
│ (db.create_all() 会自动创建表) │
│ EXIT; │
│ │
└─────────────────────────────────────────────────────────────────┘2.3.2、 方法2:Navicat配置:
2.3.2.1、 MySQL database创建:
强烈建议不要将"创建数据库"的代码写在 app.py 或 models.py 中。
2.3.2.1.1、 ❌ 为什么不建议在 Python 代码里创建数据库?
权限问题 :Python 程序连接的数据库用户(如 ama_vip)通常只有"读写表"的权限,没有"创建/删除数据库"的高级权限。如果在代码里强行创建,会报错 Access denied。
职责分离 :
-
数据库管理员 (DBA) 负责创建"仓库"(Database)。
-
程序代码 负责在仓库里建"货架"(Tables)和放"货物"(Data)。
安全性:自动创建数据库可能会误删生产环境的重要数据。
2.3.2.1.2、 ✅ 正确做法:在哪里执行?
应该在 数据库管理工具 或 命令行终端 中执行一次即可,之后不需要再管它。
方法一:在 Navicat 中执行(推荐,最直观)
打开 Navicat,连接到 ama_local。
点击顶部菜单栏的 "查询" (Query) -> "新建查询" (New Query) 。
在弹出的空白窗口中输入以下 SQL 语句:
sql
-- 如果不存在则创建 flask_simple 数据库,并设置字符集为 utf8mb4
REATE DATABASE IF NOT EXISTS flask_simple DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;点击 "运行" (Run) 按钮(通常是绿色的播放图标)。
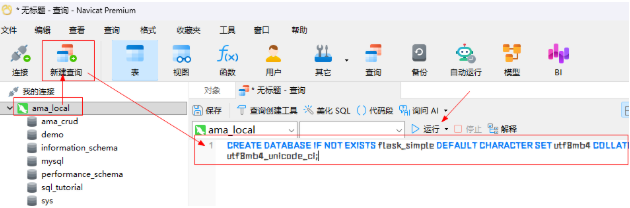
在左侧刷新一下,你应该能看到 flask_simple 数据库出现了。

方法二:在命令行终端执行
如果你更喜欢用命令行:
打开终端(CMD 或 PowerShell)。
登录 MySQL:
bash
mysql -u root -p(输入 root 密码)
进入 MySQL 提示符 mysql> 后,输入:
sql
REATE DATABASE IF NOT EXISTS flask_simple DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
exit;2.3.2.2、 USER创建

2.3.2.3、 PRIVILEGES授权
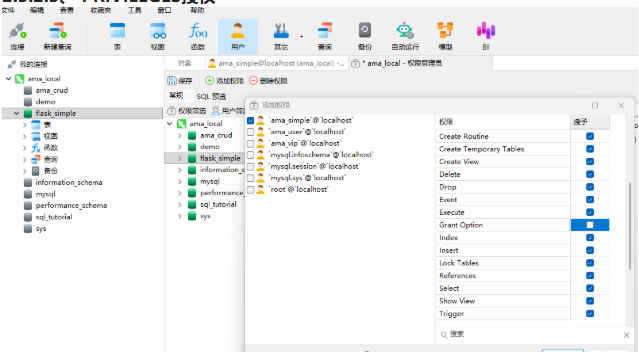
通常情况下,不需要勾选 Grant Option。
对于开发项目(使用 ama_simple 用户连接 Flask 应用),取消勾选是更安全、更标准的做法。
2.3.2.3.1、 Grant Option 是什么?
- 含义 :它代表"转授权力"。
- 作用 :如果勾选了它,意味着
ama_simple这个用户不仅可以自己操作数据库,还可以把权限分配给其他新用户 。- 例如:
ama_simple`` 可以创建一个新用户xiaoming,并允许xiaoming` 删除所有数据。
- 例如:
2.3.2.3.2、 为什么您不需要它?
您的 Flask 程序(app.py)只需要做以下事情:
- ✅ 增删改查数据 (
Select,Insert,Update,Delete) - ✅ 创建/修改表结构 (
Create,Alter,Index,Drop- 用于db.create_all()) - ✅ 锁定表 (
Lock Tables- 某些事务需要)
您的程序不需要去做"创建新用户"或"给其他人分权限"这种管理员才做的事。
2.3.2.3.3、 安全风险
如果勾选了 Grant Option:
- SQL 注入风险放大:万一您的代码有漏洞被黑客攻击,黑客不仅能偷数据,还能利用这个权限创建一个新的超级管理员账号,彻底接管您的数据库服务器。
- 误操作风险:代码逻辑错误可能导致意外修改了权限体系。
2.3.2.3.4、 ✅ 建议操作
取消勾选 Grant Option(就像您截图中那样,保持空白)。
确保其他关键权限是勾选的:
-
Select,Insert,Update,Delete(基础读写) -
Create,Drop,Alter(建表、删表、改表结构) -
Index(创建索引) -
Create Temporary Tables(临时表) -
Lock Tables(锁表) -
References(外键约束) -
Trigger(触发器,虽然 Flask 常用不到,但给了也无妨) -
Event(事件调度,可选)
2.3.2.4、 更新Flask URI
2.3.2.4.1、 🔧 接下来:修改代码以使用新数据库
数据库创建好后,你需要告诉 app.py 去连接它
修改 .env 文件:
ini
# 找到 DATABASE_URL 这一行,修改数据库名为 flask_simple
# 格式:mysql+pymysql://用户名:密码@主机:端口/新数据库名?charset=utf8mb4
ATABASE_URL=mysql+pymysql://ama_flask:YOUR_PASSWORD@127.0.0.1:3306/flask_simple?charset=utf8mb4
SECRET_KEY=your-secret-key-here
EBUG=True(记得把 YOUR_PASSWORD 换成真实的密码)
3、 项目需求文档:轻量级博客系统后端 API (MVP 版本)
3.1、 项目概述
本项目旨在构建一个基于 Python Flask 框架和 SQLAlchemy ORM 的轻量级博客系统后端。系统需实现用户注册管理与文章发布的核心功能,采用 RESTful 风格接口,支持前后端分离架构。
3.1.1、 核心目标
- 零依赖部署:使用 SQLite 数据库,无需额外安装数据库服务,开箱即用。
- 安全性:用户密码必须加密存储,敏感配置通过环境变量管理。
- 健壮性:具备完善的输入校验、外键完整性检查及全局异常处理机制。
- 可扩展性:采用工厂模式创建应用,支持开发与生产环境配置隔离。
3.2、 技术栈要求
- 语言: Python 3.8+
- Web 框架: Flask
- ORM: SQLAlchemy
- 数据库 : SQLite (文件型,存储于
instance/目录) - 安全库: Werkzeug (用于密码哈希)
- 数据格式: JSON
3.3、 功能模块需求
3.3.1、 配置管理模块 (config.py)
- 环境隔离 :系统必须支持至少两种运行模式:
- 开发模式 (Development) :开启调试模式 (
DEBUG=True),开启 SQL 语句打印 (ECHO=True),便于排查问题。 - 生产模式 (Production):关闭调试模式,关闭 SQL 打印,确保性能与安全。
- 开发模式 (Development) :开启调试模式 (
- 安全密钥 :
SECRET_KEY必须优先从操作系统环境变量读取;若未设置,仅允许在开发环境下使用默认硬编码值。 - 数据库路径 :数据库文件路径需动态生成,统一存放在项目根目录下的
instance文件夹中,文件名固定为demo.db。 - 性能优化 :必须关闭 SQLAlchemy 的修改追踪信号 (
TRACK_MODIFICATIONS = False) 以节省内存。
3.3.2、 数据模型模块 (models.py)
系统需定义以下两个核心数据模型:
3.3.2.1、 A. 用户模型 (User)
- 字段要求 :
id: 主键,自增整数。username: 字符串 (最大80字符),唯一且必填。email: 字符串 (最大120字符),唯一且必填。password_hash: 字符串 (最大256字符),必填,严禁存储明文密码。created_at: 时间戳,默认为当前 UTC 时间。
- 业务逻辑 :
- 密码加密 :提供
set_password(password)方法,内部调用哈希算法将明文转为密码。 - 密码验证 :提供
check_password(password)方法,用于验证输入密码是否匹配哈希值。 - 关联关系 :与文章模型建立一对多 关系。需配置反向引用 (
backref='author'),以便通过文章对象直接访问作者信息。
- 密码加密 :提供
3.3.2.2、 B. 文章模型 (Post)
- 字段要求 :
id: 主键,自增整数。title: 字符串 (最大200字符),必填。content: 文本类型 (Text),必填,支持长文本。created_at: 时间戳,默认为当前 UTC 时间。user_id: 外键,关联User.id,必填。
- 约束要求 :
- 必须建立数据库级外键约束,确保删除用户时受保护的文章数据一致性(或阻止删除)。
3.3.3、 应用控制与路由模块 (app.py)
系统需采用工厂模式 (create_app) 初始化应用,并实现以下 API 接口:
3.3.3.1、 A. 用户管理接口
注册用户
- **路径**: `POST /api/users`
- **输入**: JSON `{ "username": "...", "email": "...", "password": "..." }`
- **逻辑**:
- 校验必填字段。
- **查重**:检查用户名或邮箱是否已存在,若存在返回 `400 Bad Request`。
- 调用模型层的 `set_password` 进行加密。
- 提交事务至数据库。
- **输出**: 成功返回 `201 Created` 及用户信息;失败返回对应错误码。获取用户列表
- **路径**: `GET /api/users`
- **逻辑**: 查询所有用户,格式化时间字段。
- **输出**: JSON 数组,包含用户基本信息(不含密码哈希)。3.3.3.2、 B. 文章管理接口
发布文章
- **路径**: `POST /api/posts`
- **输入**: JSON `{ "title": "...", "content": "...", "user_id": 1 }`
- **逻辑**:
- 校验必填字段。
- **完整性检查**:根据 `user_id` 查询用户,若用户不存在,返回 `400 Bad Request` (提示"用户不存在"),**禁止**直接依赖数据库外键报错。
- 创建文章记录并提交。
- **输出**: 成功返回 `201 Created` 及文章详情(含作者名)。获取文章列表 (分页)
- **路径**: `GET /api/posts`
- **参数**: 支持 `page` (页码,默认1) 和 `per_page` (每页数量,默认5)。
- **逻辑**:
- 按创建时间**倒序**排列。
- 执行分页查询。
- **内容摘要**:返回的 `content` 字段若超过 50 字,需自动截断并追加 `...`。
- 利用 ORM 反向引用获取作者用户名。
- **输出**: JSON 对象,包含文章列表、当前页、总页数等元数据。3.3.3.3、 全局异常处理
- 404 错误 : 捕获所有资源未找到错误,统一返回 JSON
{ "error": "资源未找到" }。 - 500 错误 : 捕获服务器内部错误。
- 关键动作 : 必须执行
db.session.rollback()回滚当前事务,防止脏数据写入。 - 输出 : 返回 JSON
{ "error": "服务器内部错误" },状态码 500。
- 关键动作 : 必须执行
3.4、 非功能性需求
3.4.1、 安全性
- 密码安全: 数据库中严禁出现明文密码。
- 密钥管理 : 生产环境部署时,必须配置
SECRET_KEY环境变量。 - 防注入: 所有数据库操作必须通过 SQLAlchemy ORM 进行,禁止拼接 SQL 字符串。
3.4.2、 可维护性
- 目录结构: 遵循标准 Flask 结构,配置文件、模型文件、应用入口文件分离。
- 实例文件夹 : 运行时产生的数据库文件必须位于
instance/目录,该目录应被版本控制系统 (Git) 忽略。
3.4.3、 性能
- 分页限制: 列表接口必须强制分页,防止单次请求拉取全量数据导致内存溢出。
- 信号关闭: 必须关闭不必要的 ORM 信号追踪。
3.5、 验收标准 (Acceptance Criteria)
启动测试 : 在开发模式下运行 app.py,程序应自动创建 instance/demo.db 文件及对应的数据表,无报错。
注册测试 :
-
发送合法注册请求 -> 返回 201,数据库中密码字段为哈希值。
-
发送重复用户名请求 -> 返回 400,提示用户名已存在。
发文测试 : -
使用不存在的
user_id发文 -> 返回 400,提示用户不存在。 -
使用存在的
user_id发文 -> 返回 201,可通过GET /api/posts查到该文章及作者名。
分页测试 : 插入 12 篇文章,请求GET /api/posts?page=2&per_page=5,应只返回第 6-10 篇文章,且内容超过 50 字的已被截断。
异常测试: 模拟一个除以零错误或强制抛出异常,确认返回的是 JSON 格式的 500 错误,且数据库中没有产生半截数据(通过检查事务回滚日志或数据一致性)。
3.6、 交付物
config.py: 配置管理代码。models.py: 数据库模型定义代码。app.py: 应用入口及路由逻辑代码。requirements.txt: 项目依赖列表 (Flask, Flask-SQLAlchemy 等)。
4、基于 Flask 框架和 SQLAlchemy ORM 的轻量级后端应用项目思路
一、整体架构逻辑:分层与解耦
以下三个文件遵循了经典的 Web 开发分层模式,体现了高内聚、低耦合的设计思想:
-
配置层 (
config.py):- 职责:集中管理所有环境变量和常量(如数据库链接、密钥、调试开关)。
- 逻辑:通过继承实现不同环境(开发/生产)的配置隔离,确保代码在不同部署场景下无需修改核心逻辑。
-
数据模型层 (
models.py):- 职责:定义数据库结构(ORM 映射),将 Python 类映射为数据库表。
- 逻辑:封装数据操作逻辑(如密码加密/验证),业务逻辑不直接操作 SQL,而是操作对象。
-
应用控制层 (
app.py):- 职责:作为程序入口,负责初始化应用、注册路由、处理 HTTP 请求并协调模型层。
- 逻辑 :采用工厂模式 (
create_app) 创建应用实例,便于测试和多实例部署;路由函数负责接收请求、调用模型、返回响应。
二、分部深度解析
1. 配置模块 (config.py) ------ 系统的基石
- 基类设计 (
Config) :- 定义了所有环境共用的配置。
- 安全性 :
SECRET_KEY优先从环境变量读取,防止硬编码泄露。 - 数据库 :动态构建 SQLite 路径 (
sqlite:///.../instance/demo.db),确保跨平台兼容。 - 性能优化 :
SQLALCHEMY_TRACK_MODIFICATIONS = False关闭了不必要的信号追踪,节省内存。
- 环境继承 :
DevelopmentConfig:开启DEBUG=True和SQLALCHEMY_ECHO=True,方便开发时实时查看报错和 SQL 语句。ProductionConfig:关闭调试和 SQL 打印,提升生产环境性能和安全性。
- 配置字典 :
config = {...}提供了一个统一的入口,app.py只需传入字符串(如'development')即可加载对应配置类。
2. 模型模块 (models.py) ------ 数据的骨架
- ORM 映射 :
db = SQLAlchemy():延迟初始化,先在models.py定义,后在app.py绑定应用,避免循环导入。- User 模型 :
- 字段约束:
unique=True保证用户名/邮箱唯一,nullable=False保证必填。 - 关系定义 :
posts = db.relationship('Post', ...)建立了一对多关系(一个用户多篇博文)。backref='author'自动在Post模型上添加了author属性,方便反向查询。 - 业务封装 :
set_password和check_password方法内部调用werkzeug.security,实现了密码的自动哈希存储和验证,严禁明文存密码。
- 字段约束:
- Post 模型 :
- 外键关联:
user_id = db.Column(..., ForeignKey('user.id'))物理连接两表。 - 数据类型:
Text类型适合存储长文章内容。
- 外键关联:
3. 应用模块 (app.py) ------ 逻辑的枢纽
- 工厂模式 (
create_app) :- 这是 Flask 推荐的最佳实践。它不是全局创建一个
app,而是通过函数动态创建。 - 流程 :创建实例 -> 加载配置 -> 初始化扩展 (
db.init_app) -> 创建表 (仅开发环境) -> 注册路由。 - 上下文管理 :
with app.app_context():确保在创建数据库表时能访问到app.config。
- 这是 Flask 推荐的最佳实践。它不是全局创建一个
- 路由与业务逻辑 :
- 用户接口 (
/api/users) :- POST :接收 JSON -> 校验必填项 -> 查重 -> 实例化 User -> 调用
set_password加密 -> 提交会话 (db.session.commit())。 - GET:查询所有用户 -> 列表推导式格式化时间 -> 返回 JSON。
- POST :接收 JSON -> 校验必填项 -> 查重 -> 实例化 User -> 调用
- 文章接口 (
/api/posts) :- POST :校验标题和用户ID -> 检查用户是否存在 (外键完整性保护) -> 创建文章。
- GET :实现分页逻辑 (
paginate),限制单次返回数据量,防止大数据量拖垮服务。截取内容前50字作为摘要。
- 用户接口 (
- 错误处理 :
- 全局捕获 404 和 500 错误,统一返回 JSON 格式错误信息。
- 事务回滚 :在 500 错误中执行
db.session.rollback(),防止因异常导致数据库处于不一致状态。
5、 Flask SIMPLE 项目代码
效果呈现:
A、创建两个用户:

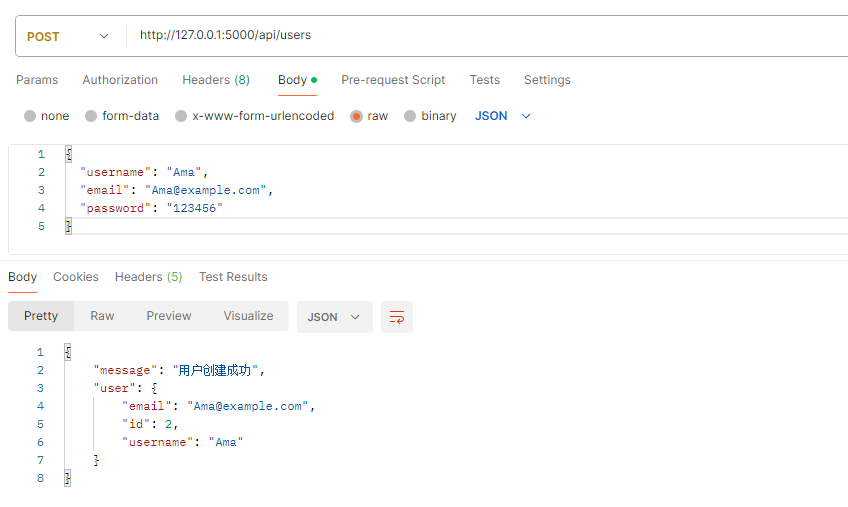
B、创建博客:


C、测试多页输出:
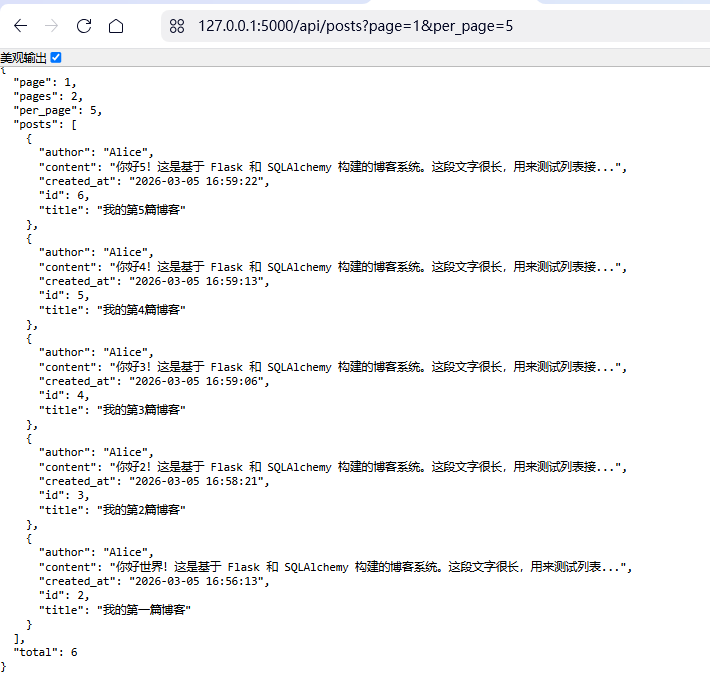
代码(完整代码请移步资源下载,0积分既可下载)

5.1、 app.py
python
# ============================================================================
# 文件:app.py
# 说明:Flask 应用主入口(最简化版本)
# ============================================================================
from flask import Flask, jsonify, request
from config import config
from models import db, BlogUser, BlogPost
from dotenv import load_dotenv
load_dotenv()
def create_app(config_name='default'):
"""
应用工厂函数
负责创建和配置 Flask 应用实例
参数:
config_name: 配置名称,可选 'development', 'production', 'default'
返回:
配置好的 Flask 应用实例
"""
# 创建 Flask 应用实例
# __name__ 用于确定应用的根目录,方便查找模板和静态文件
app = Flask(__name__)
# 加载配置
# from_object 从配置类中加载所有大写属性到 app.config
# 初始化数据库扩展
# 将 db 对象与当前 app 实例绑定
db.init_app(app)
# 创建数据库表(仅开发环境)
# ----- 注册路由 -----
@app.route('/')
def index():
"""
首页路由
返回欢迎信息
"""
@app.route('/api/users', methods=['POST'])
def create_user():
"""
创建用户接口
请求体:{"username": "张三", "email": "test@example.com", "password": "123456"}
"""
# 获取 JSON 数据
data = request.get_json()
# 简单验证
# 检查用户名是否已存在
# 创建新用户对象
# 使用模型方法加密密码
# 添加到会话
# 提交事务(保存到数据库)
@app.route('/api/users', methods=['GET'])
def get_users():
"""
获取所有用户接口
返回用户列表
"""
# 查询所有用户
users = BlogUser.query.all()
# 转换为字典列表
@app.route('/api/posts', methods=['POST'])
def create_post():
"""
创建文章接口
请求体:{"title": "标题", "content": "内容", "blog_user_id": 1}
"""
# 检查用户是否存在
# 创建新文章
@app.route('/api/posts', methods=['GET'])
def get_posts():
"""
获取所有文章接口
支持分页:GET /api/posts?page=1&per_page=5
"""
# 获取分页参数
# 分页查询
# paginate 方法返回分页对象
# 转换为字典列表
# ----- 错误处理 -----
@app.errorhandler(404)
def not_found(error):
"""404 错误处理"""
return jsonify({'error': '资源未找到'}), 404
@app.errorhandler(500)
def internal_error(error):
"""500 错误处理"""
db.session.rollback() # 回滚数据库事务
return jsonify({'error': '服务器内部错误'}), 500
return app
# 程序入口
if __name__ == '__main__':
# 创建应用实例
app = create_app('default')
app.run(port=5000, debug=True)5.2、 models.py
python
# ============================================================================
# 文件:models.py
# 说明:数据库模型定义(ORM 映射)
# ============================================================================
from datetime import datetime
from flask_sqlalchemy import SQLAlchemy
# 创建 SQLAlchemy 实例
# 这里先不绑定 app,在 app.py 中通过 init_app() 绑定
db = SQLAlchemy()
class BlogUser(db.Model):
"""
用户模型
对应数据库中的 user 表
"""
# 表名(可选,不写则默认使用类名小写)
__tablename__ = 'blog_user'
# ----- 字段定义 -----
# 主键,Integer 表示整数类型,primary_key=True 表示主键
id = db.Column(db.Integer, primary_key=True)
# 用户名,String(80) 表示最大 80 字符,unique=True 表示唯一
username = db.Column(db.String(80), unique=True, nullable=False)
......此处省略......
def __repr__(self):
"""
对象的字符串表示,方便调试
"""
def set_password(self, password):
"""
设置密码(自动加密)
使用 Werkzeug 的密码哈希功能
"""
def check_password(self, password):
"""
验证密码
返回 True 或 False
"""
class BlogPost(db.Model):
"""
文章模型
对应数据库中的 post 表
"""
__tablename__ = 'blog_post'
# ----- 字段定义 ----
# 外键,指向 user 表的 id 字段
# ForeignKey 建立表间关联
def __repr__(self):
return f'<Post {self.title}>'5.3、 config.py
python
# ============================================================================
# 文件:config.py
# 说明:Flask 应用配置文件
# ============================================================================
import os
from datetime import timedelta
# 获取当前文件所在目录的绝对路径
basedir = os.path.abspath(os.path.dirname(__file__))
class Config:
"""
基础配置类
存放所有环境共用的配置项
"""
# ----- 安全配置 -----
# 密钥:用于 session 加密、CSRF 保护等
# os.environ.get() 尝试从环境变量获取,如果没有则使用默认值
# Session 过期时间设置为 7 天
# ----- 数据库配置 -----
# 使用 SQLite 数据库(无需安装数据库服务器,适合学习和开发)
# sqlite:/// 表示使用 SQLite,后面是数据库文件路径
# ----- 分页配置 -----
class DevelopmentConfig(Config):
"""
开发环境配置
继承 Config 类,覆盖开发环境特定配置
"""
class ProductionConfig(Config):
"""
生产环境配置
继承 Config 类,覆盖生产环境特定配置
"""
# 配置字典,方便根据环境名称选择对应的配置类
config = {
'development': DevelopmentConfig,
'production': ProductionConfig,
'default': DevelopmentConfig # 默认使用开发配置
}