参考
Docker部署Hadoop-01-Docker安装
Docker部署Hadoop-02-Docker常见操作
Docker部署Hadoop-03-Docker部署Hadoop

已完成Hadoop Docker镜像改造方案:命名卷存HDFS数据+宿主机挂载卷存配置文件
本方案基于你已构建好的hadoop-base镜像和已配置的master/worker01/worker02容器,实现HDFS核心数据持久化到Docker命名卷 、Hadoop配置文件持久化到宿主机挂载卷,改造后容器删除/重建不会丢失数据和配置,且配置文件可在宿主机直接修改,无需进入容器操作,完全适配集群部署和后续维护。
核心改造思路
- 命名卷挂载 :为
namenode_dir(NameNode元数据)、datanode_dir(DataNode数据)、tmp(Hadoop临时文件)创建Docker命名卷,独立于容器存储,实现HDFS数据持久化; - 宿主机挂载卷 :在宿主机创建统一的配置目录,挂载到所有容器的
/usr/local/hadoop/etc/hadoop,实现配置文件宿主机统一管理; - 改造步骤:先备份容器内现有配置和数据→创建卷和宿主机目录→停止旧容器→用卷挂载方式重建容器→恢复配置和数据,全程保留原有Hadoop集群配置,无需重新配置SSH和Hadoop。
前提环境
- 宿主机:Ubuntu系统,已安装Docker,存在
hadoop-base镜像和已配置的master/worker01/worker02容器; - 容器内Hadoop路径:
/usr/local/hadoop(配置文件目录/usr/local/hadoop/etc/hadoop,数据目录namenode_dir/datanode_dir/tmp); - 已创建Docker专用网络:
hadoop-net(172.19.0.0/16)。
bash
# 3. 确保hadoop-net网络存在
docker network create --driver bridge --subnet=172.19.0.0/16 hadoop-net 2>/dev/null第一部分:宿主机端准备工作(创建挂载目录+Docker命名卷)
步骤1:创建宿主机Hadoop配置挂载目录(统一管理所有配置)
在宿主机创建专属目录,用于存放Hadoop所有配置文件,后续所有容器的配置目录都挂载到该目录,实现宿主机直接修改、容器实时生效。
bash
# 1. 创建宿主机配置根目录(建议放在~/hadoop-docker下,与镜像构建目录统一)
mkdir -p ~/hadoop-docker/hadoop-config
# 2. 赋予读写权限(避免容器内权限不足)
chmod -R 777 ~/hadoop-docker/hadoop-config步骤2:创建Docker命名卷(存放HDFS核心数据,3个卷分别对应不同数据)
创建3个Docker命名卷,分别存储NameNode元数据、DataNode数据、Hadoop临时文件,命名卷由Docker统一管理,比宿主机挂载更安全,不易因路径权限出问题。
bash
# 1. 创建namenode数据卷(存储NameNode元数据)
docker volume create hadoop-namenode
# 2. 创建datanode数据卷(所有worker节点共享/独立均可,这里用独立卷更规范)
docker volume create hadoop-datanode-master
docker volume create hadoop-datanode-worker01
docker volume create hadoop-datanode-worker02
# 3. 创建hadoop临时文件卷
docker volume create hadoop-tmp
# 验证卷创建成功
docker volume ls | grep hadoop-说明:master节点也可运行DataNode,因此为master单独创建datanode卷,worker节点各自独立卷,避免数据冲突。
查看命名挂载卷的本地位置
bash
ubuntu@ubuntu-virtual-machine:~/hadoop-docker$ docker volume inspect hadoop-namenode
[
{
"CreatedAt": "2026-03-11T09:43:03+08:00",
"Driver": "local",
"Labels": null,
"Mountpoint": "/var/lib/docker/volumes/hadoop-namenode/_data",
"Name": "hadoop-namenode",
"Options": null,
"Scope": "local"
}
]
ubuntu@ubuntu-virtual-machine:~/hadoop-docker$第二部分:备份原有容器内的配置文件和HDFS数据(关键!防止数据丢失)
改造前先将原有容器内的配置文件 和HDFS数据备份到宿主机,后续直接恢复到新的挂载卷/目录中,保留原有所有配置(SSH免密、Hadoop集群配置、WordCount测试数据等)。
步骤1:备份容器内Hadoop配置文件到宿主机挂载目录
将master容器内的/usr/local/hadoop/etc/hadoop(已配置好的core-site.xml/yarn-site.xml等)复制到宿主机的~/hadoop-docker/hadoop-config,后续所有容器都挂载该目录,实现配置统一。
bash
# 直接将master容器内的配置文件复制到宿主机配置挂载目录(覆盖空目录)
docker cp master:/usr/local/hadoop/etc/hadoop/. ~/hadoop-docker/hadoop-config/
# 验证备份成功(宿主机配置目录下能看到core-site.xml等文件)
ls -l ~/hadoop-docker/hadoop-config/
步骤2:备份容器内HDFS数据到宿主机临时目录(可选,若有重要数据则执行)
若你的HDFS中已有重要测试数据/业务数据,执行以下命令备份,后续恢复到命名卷中;若仅为测试环境,可跳过此步骤,后续重新格式化NameNode即可。
bash
# 1. 宿主机创建数据备份临时目录
mkdir -p ~/hadoop-docker/hadoop-data-backup/namenode ~/hadoop-docker/hadoop-data-backup/datanode-master
# 2. 备份master容器的namenode和datanode数据
docker cp master:/usr/local/hadoop/namenode_dir/. ~/hadoop-docker/hadoop-data-backup/namenode/
docker cp master:/usr/local/hadoop/datanode_dir/. ~/hadoop-docker/hadoop-data-backup/datanode-master/
# 3. 备份worker01/worker02的datanode数据
docker cp worker01:/usr/local/hadoop/datanode_dir/. ~/hadoop-docker/hadoop-data-backup/datanode-worker01/
docker cp worker02:/usr/local/hadoop/datanode_dir/. ~/hadoop-docker/hadoop-data-backup/datanode-worker02/
# 4. 备份临时文件
docker cp master:/usr/local/hadoop/tmp/. ~/hadoop-docker/hadoop-data-backup/tmp/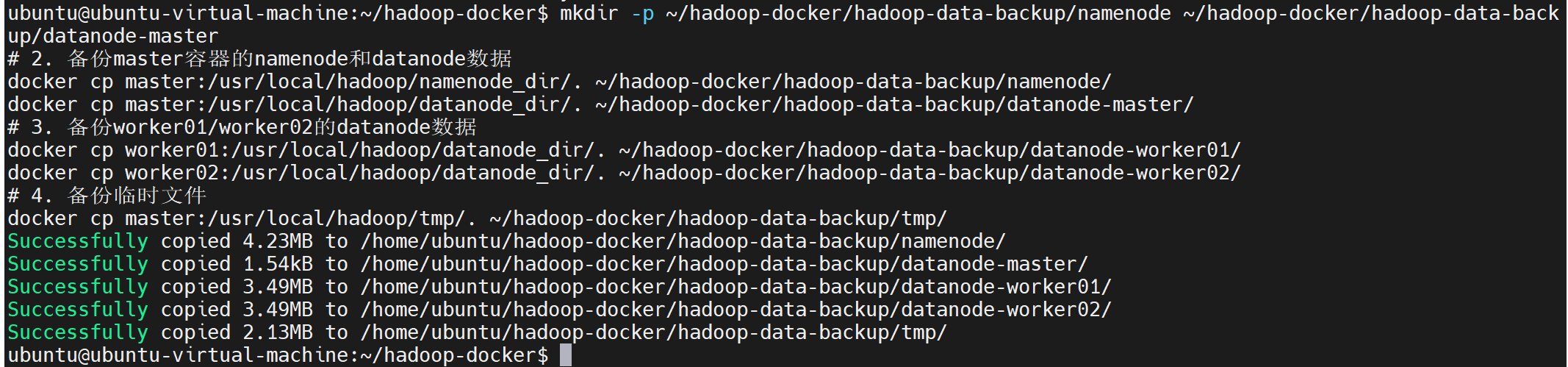
第三部分:停止并删除原有容器(保留镜像,仅删除无挂载的旧容器)
原有容器未配置卷挂载,数据和配置都在容器内,需先停止并删除,后续用卷挂载方式 重建容器,镜像hadoop-base和已创建的卷/宿主机配置目录保留,无需重新构建镜像。
bash
# 1. 停止所有Hadoop容器
docker stop master worker01 worker02
# 2. 删除所有Hadoop容器(仅删除容器,镜像和卷不受影响)
docker rm master worker01 worker02
# 验证容器已删除
docker ps -a | grep -E "master|worker01|worker02"第四部分:用卷挂载方式重建Hadoop集群容器(核心改造步骤)
按master→worker01→worker02 顺序重建容器,启动命令中添加宿主机配置目录挂载 和Docker命名卷挂载,所有参数(IP/主机名/网络)与原有一致,确保集群网络互通。
核心挂载参数说明
| 挂载类型 | 宿主机/卷路径 | 容器内路径 | 挂载参数 | 作用 |
|---|---|---|---|---|
| 宿主机挂载卷 | ~/hadoop-docker/hadoop-config | /usr/local/hadoop/etc/hadoop | -v 宿路径:容器路径 | 宿主机管理配置文件 |
| Docker命名卷 | hadoop-namenode | /usr/local/hadoop/namenode_dir | -v 卷名:容器路径 | 持久化NameNode元数据 |
| Docker命名卷 | hadoop-datanode-* | /usr/local/hadoop/datanode_dir | -v 卷名:容器路径 | 持久化DataNode数据 |
| Docker命名卷 | hadoop-tmp | /usr/local/hadoop/tmp | -v 卷名:容器路径 | 持久化Hadoop临时文件 |
步骤1:重建master节点容器(带完整卷挂载)
master节点需映射WebUI端口(9870/8088/9000),挂载宿主机配置目录 +namenode卷 +master-datanode卷 +tmp卷:
docker run -itd
--name master
--hostname master
--net hadoop-net
--ip 172.19.0.2
宿主机配置目录挂载(核心:宿主机直接修改配置)
-v ~/hadoop-docker/hadoop-config:/usr/local/hadoop/etc/hadoop
Docker命名卷:NameNode元数据
-v hadoop-namenode:/usr/local/hadoop/namenode_dir
Docker命名卷:master节点DataNode数据
-v hadoop-datanode-master:/usr/local/hadoop/datanode_dir
Docker命名卷:Hadoop临时文件
-v hadoop-tmp:/usr/local/hadoop/tmp
映射WebUI和服务端口(与原有一致)
-p 9870:9870
-p 8088:8088
-p 9000:9000
特权模式(避免容器内权限问题)
--privileged
基于原有已配置的镜像构建
hadoop-base
bash
docker run -itd \
--name master \
--hostname master \
--net hadoop-net \
--ip 172.19.0.2 \
-v ~/hadoop-docker/hadoop-config:/usr/local/hadoop/etc/hadoop \
-v hadoop-namenode:/usr/local/hadoop/namenode_dir \
-v hadoop-datanode-master:/usr/local/hadoop/datanode_dir \
-v hadoop-tmp:/usr/local/hadoop/tmp \
-p 9870:9870 \
-p 8088:8088 \
-p 9000:9000 \
--privileged \
hadoop-base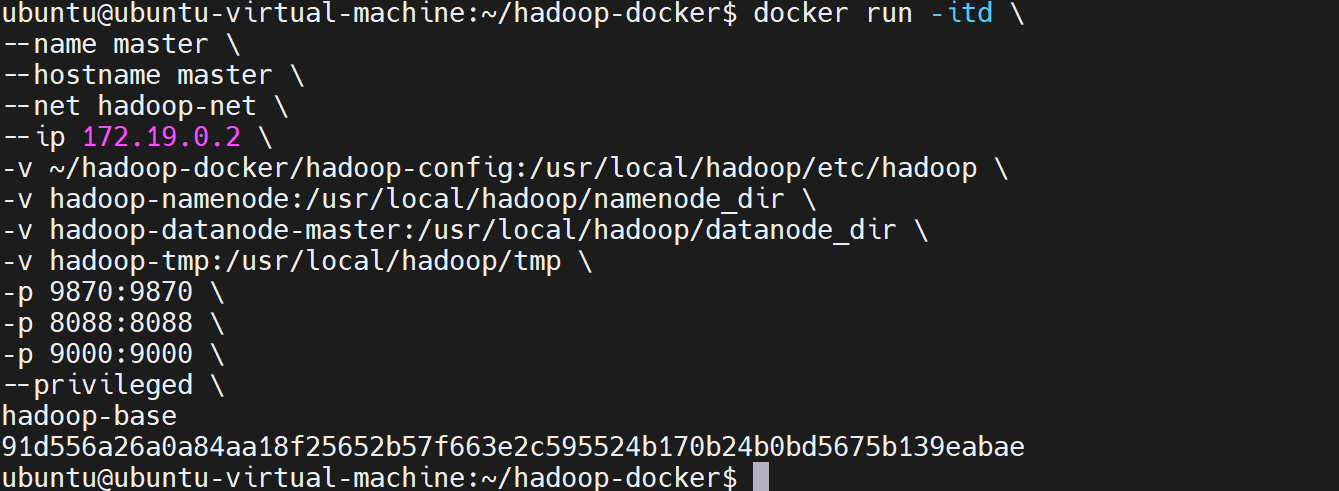
步骤2:重建worker01节点容器(带卷挂载)
worker01节点无需映射端口,挂载宿主机配置目录 +worker01-datanode卷 +tmp卷,配置与master完全同步:
bash
docker run -itd \
--name worker01 \
--hostname worker01 \
--net hadoop-net \
--ip 172.19.0.3 \
-v ~/hadoop-docker/hadoop-config:/usr/local/hadoop/etc/hadoop \
-v hadoop-datanode-worker01:/usr/local/hadoop/datanode_dir \
-v hadoop-tmp:/usr/local/hadoop/tmp \
--privileged \
hadoop-base步骤3:重建worker02节点容器(带卷挂载)
与worker01配置一致,仅修改容器名、主机名、IP和datanode卷:
bash
docker run -itd \
--name worker02 \
--hostname worker02 \
--net hadoop-net \
--ip 172.19.0.4 \
-v ~/hadoop-docker/hadoop-config:/usr/local/hadoop/etc/hadoop \
-v hadoop-datanode-worker02:/usr/local/hadoop/datanode_dir \
-v hadoop-tmp:/usr/local/hadoop/tmp \
--privileged \
hadoop-base步骤4:验证容器启动和卷挂载成功
bash
# 1. 验证容器正常启动(STATUS为Up)
docker ps | grep -E "master|worker01|worker02"
# 2. 验证容器卷挂载配置(查看master容器的挂载信息)
docker inspect master | grep -A 20 "Mounts"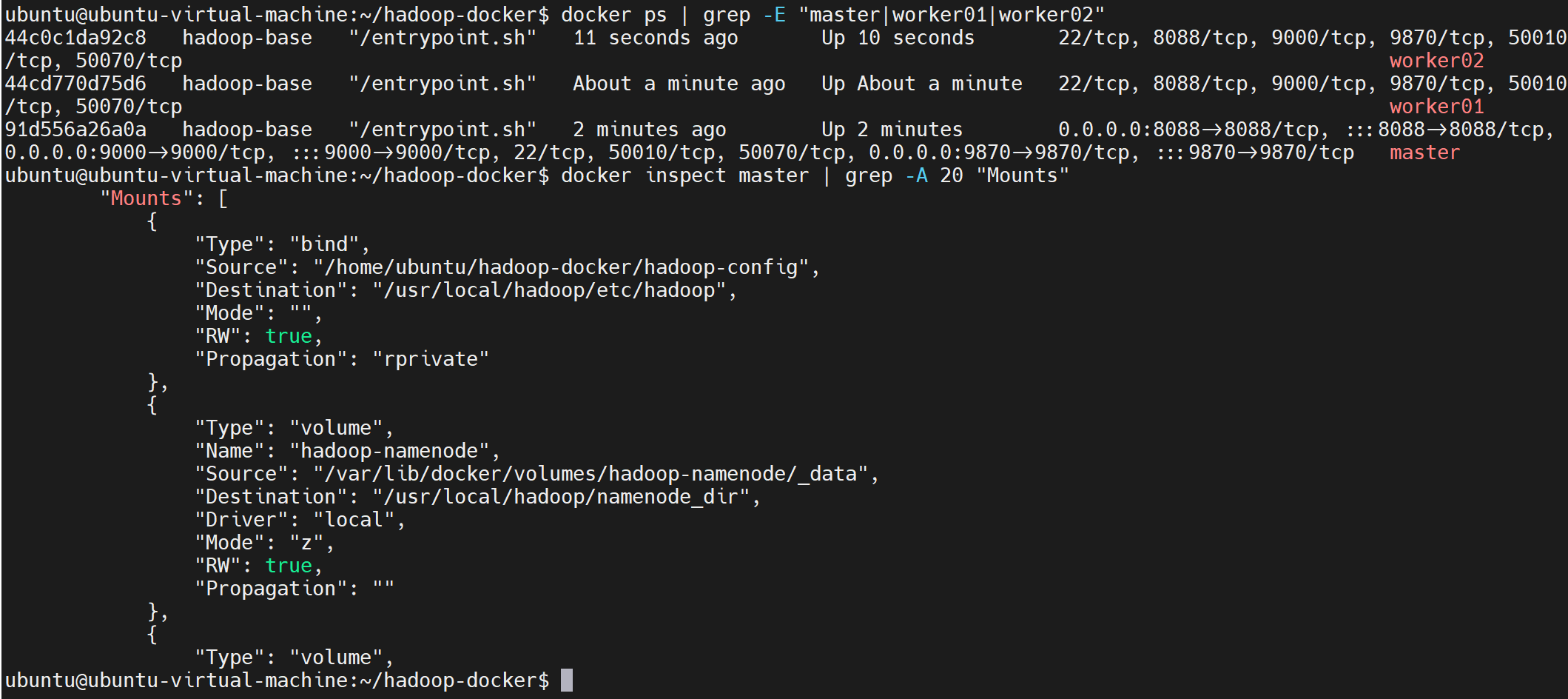
验证成功标志:Mounts部分能看到宿主机配置目录和3个Docker命名卷的挂载记录,路径对应正确。
第五部分:恢复数据并重新初始化HDFS集群
步骤1:恢复备份的HDFS数据到命名卷(若已备份则执行,无备份则跳过)
将宿主机临时备份目录的HDFS数据复制到对应的Docker命名卷中,恢复原有数据:
bash
# 恢复NameNode元数据到hadoop-namenode卷
docker run --rm --privileged -v hadoop-namenode:/target -v ~/hadoop-docker/hadoop-data-backup/namenode:/source ubuntu:22.04 cp -r /source/. /target/
# 恢复master的datanode数据
docker run --rm --privileged -v hadoop-datanode-master:/target -v ~/hadoop-docker/hadoop-data-backup/datanode-master:/source ubuntu:22.04 cp -r /source/. /target/
# 恢复worker01的datanode数据
docker run --rm --privileged -v hadoop-datanode-worker01:/target -v ~/hadoop-docker/hadoop-data-backup/datanode-worker01:/source ubuntu:22.04 cp -r /source/. /target/
# 恢复worker02的datanode数据
docker run --rm --privileged -v hadoop-datanode-worker02:/target -v ~/hadoop-docker/hadoop-data-backup/datanode-worker02:/source ubuntu:22.04 cp -r /source/. /target/
# 恢复hadoop-tmp临时文件
docker run --rm --privileged -v hadoop-tmp:/target -v ~/hadoop-docker/hadoop-data-backup/tmp:/source ubuntu:22.04 cp -r /source/. /target/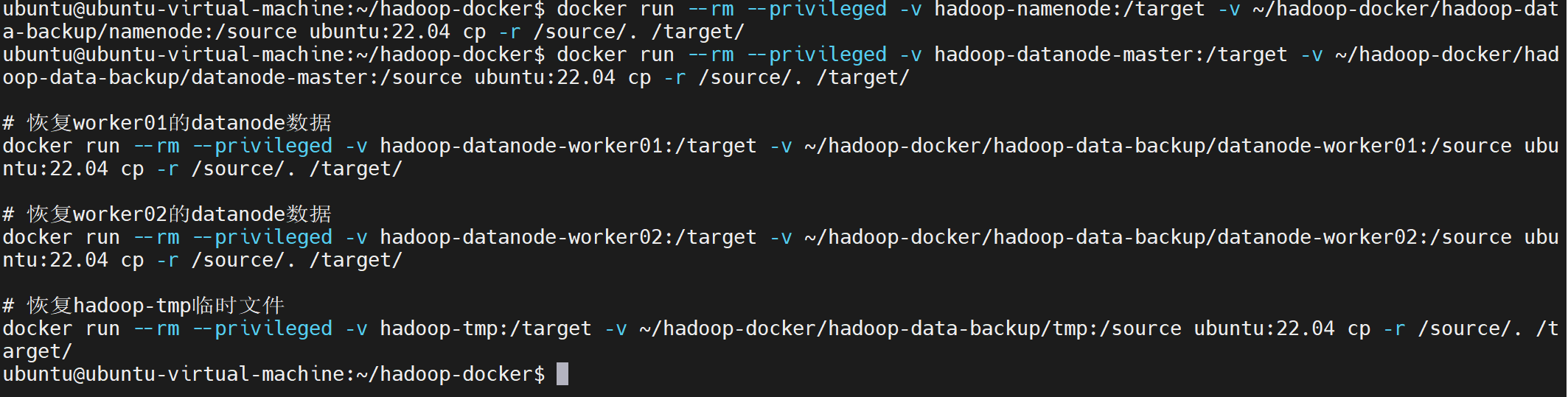
验证数据是否复制成功
bash
docker run --rm -v hadoop-namenode:/volume ubuntu:22.04 ls -l /volume/
步骤2:进入master容器,重新格式化并启动HDFS集群
若未恢复旧数据,需重新格式化NameNode;若已恢复旧数据,直接启动集群即可(无需重新格式化,避免数据损坏)。
bash
# 1. 进入master容器
docker exec -it master bash
# 2. 若未恢复旧数据,执行格式化(已恢复则跳过此步!)
hdfs namenode -format
# 3. 启动HDFS集群
start-dfs.sh
# 4. 启动YARN集群
start-yarn.sh
# 5. 验证集群进程(master节点应有以下进程)
jps
# 正常输出:NameNode、SecondaryNameNode、ResourceManager、Jps
# 6. 验证worker节点进程(免密登录worker01)
ssh worker01 jps
# 正常输出:DataNode、NodeManager、Jps
第六部分:解决免密登录问题
第一步:验证SSH免密登录是否真的失效(master容器内执行)
先进入master容器,手动测试到worker01/worker02的SSH登录,确认问题:
bash
# 宿主机执行:进入master容器
docker exec -it master bash
# 测试登录worker01(若提示输入密码/直接拒绝,说明免密失效)
ssh worker01
# 测试登录worker02
ssh worker02若出现以下提示,说明免密登录完全失效,需按后续步骤重新配置:
root@worker01: Permission denied (publickey,password).
# 或
root@worker01's password: # 提示输入密码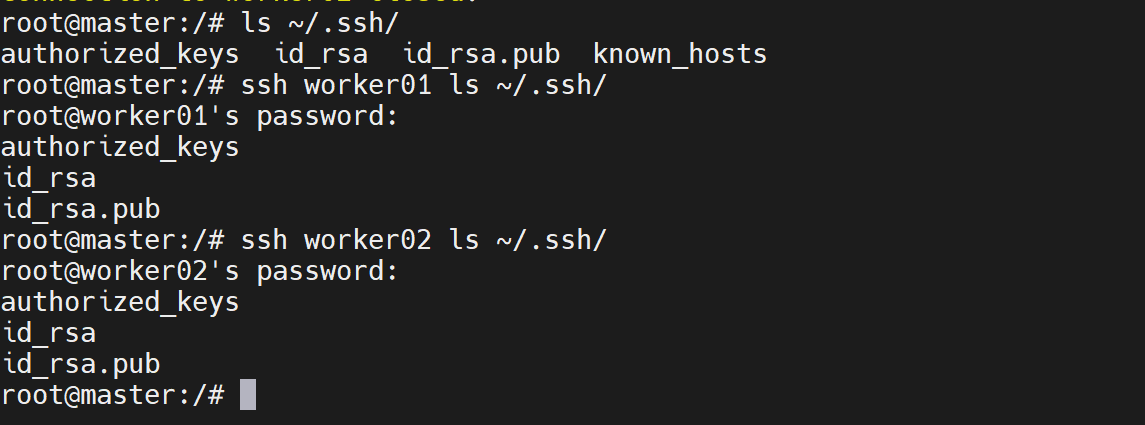
第二步:彻底重新配置SSH免密登录(master容器内执行,全程复制命令)
步骤1:重新生成master节点的SSH密钥对(若丢失)
bash
# 强制重新生成RSA密钥对,无密码(-P '')
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa -q执行后无任何输出,直接生成~/.ssh/id_rsa(私钥)和~/.ssh/id_rsa.pub(公钥)。
步骤2:给master节点的SSH文件配置正确权限(关键,权限错误会导致免密失效)
SSH对密钥文件/授权文件的权限要求严格,必须执行以下命令修复:
bash
chmod 700 ~/.ssh
chmod 600 ~/.ssh/id_rsa
chmod 644 ~/.ssh/id_rsa.pub
chmod 600 ~/.ssh/authorized_keys步骤3:手动将master公钥复制到所有节点(master/worker01/worker02)
放弃ssh-copy-id (易因密码认证配置出问题),用管道直接复制公钥 的方式,无需输入密码,一步到位配置免密,以下3条命令全在master容器内执行:
bash
# 1. 公钥复制到master自身
cat ~/.ssh/id_rsa.pub | ssh root@master "mkdir -p ~/.ssh && cat >> ~/.ssh/authorized_keys && chmod 600 ~/.ssh/authorized_keys && chmod 700 ~/.ssh"
# 2. 公钥复制到worker01
cat ~/.ssh/id_rsa.pub | ssh root@worker01 "mkdir -p ~/.ssh && cat >> ~/.ssh/authorized_keys && chmod 600 ~/.ssh/authorized_keys && chmod 700 ~/.ssh"
# 3. 公钥复制到worker02
cat ~/.ssh/id_rsa.pub | ssh root@worker02 "mkdir -p ~/.ssh && cat >> ~/.ssh/authorized_keys && chmod 600 ~/.ssh/authorized_keys && chmod 700 ~/.ssh"若执行时出现Are you sure you want to continue connecting (yes/no)?
直接输入yes并回车,即可完成公钥复制(仅首次执行会出现)。
步骤4:验证SSH免密登录是否生效(master容器内执行)
执行以下命令,若直接登录无密码提示,说明配置成功:
bash
# 测试worker01
ssh worker01 hostname # 应直接输出:worker01
# 测试worker02
ssh worker02 hostname # 应直接输出:worker02
# 退出worker节点回到master
exit第三步:修复worker节点的SSH配置(兜底,防止密码认证被禁用)
若上述步骤仍提示权限拒绝,说明worker节点的SSH配置禁用了密码/root登录,分别进入worker01/worker02容器修复 ,以下命令宿主机执行:
修复worker01
bash
# 进入worker01容器
docker exec -it worker01 bash
# 1. 重置root密码为root(确保密码正确)
echo 'root:root' | chpasswd
# 2. 开启root登录+密码认证
sed -i 's/#PermitRootLogin prohibit-password/PermitRootLogin yes/' /etc/ssh/sshd_config
sed -i 's/PasswordAuthentication no/PasswordAuthentication yes/' /etc/ssh/sshd_config
# 3. 重启SSH服务使配置生效
service ssh restart
# 退出容器
exit修复worker02
bash
# 进入worker02容器
docker exec -it worker02 bash
# 1. 重置root密码为root
echo 'root:root' | chpasswd
# 2. 开启root登录+密码认证
sed -i 's/#PermitRootLogin prohibit-password/PermitRootLogin yes/' /etc/ssh/sshd_config
sed -i 's/PasswordAuthentication no/PasswordAuthentication yes/' /etc/ssh/sshd_config
# 3. 重启SSH服务
service ssh restart
# 退出容器
exit修复后,回到master容器重新执行第二步的步骤3,再次配置免密登录。
第四步:重新启动HDFS集群(master容器内执行)
免密登录配置成功后,重新执行start-dfs.sh,此时能正常连接worker节点启动DataNode:
bash
# master容器内执行
start-dfs.sh启动成功标志
无任何Permission denied报错,输出如下类似内容:
Starting namenodes on [master]
master: WARNING: /usr/local/hadoop/logs does not exist. Creating.
Starting datanodes
worker01: WARNING: /usr/local/hadoop/logs does not exist. Creating.
worker02: WARNING: /usr/local/hadoop/logs does not exist. Creating.
Starting secondary namenodes [master]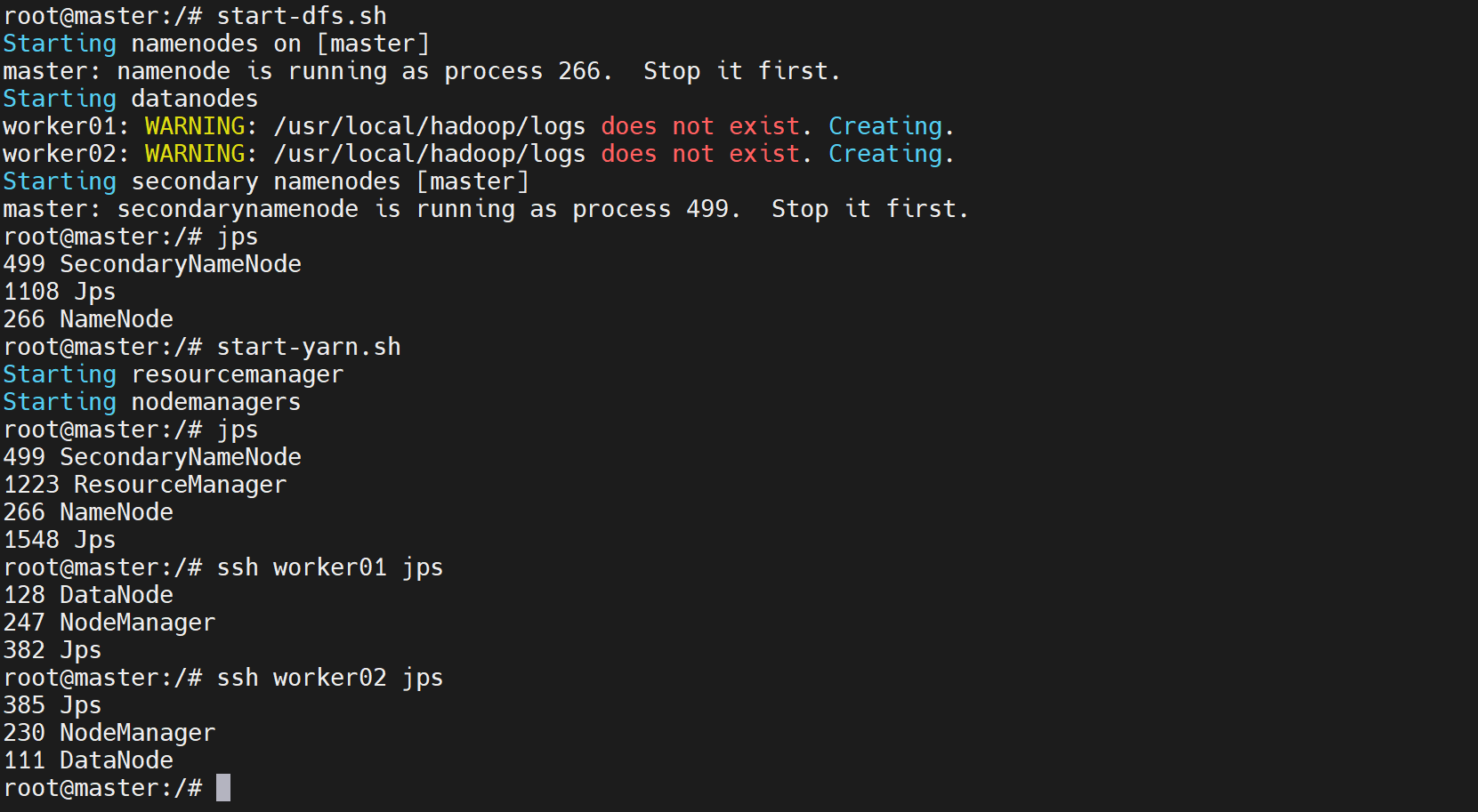
第五步:验证HDFS集群进程(关键,确认所有进程正常启动)
1. master节点进程(master容器内执行jps)
应看到NameNode、SecondaryNameNode(核心HDFS进程):
XXXX NameNode
XXXX SecondaryNameNode
XXXX Jps2. worker01/worker02节点进程(master容器内远程执行)
bash
# 查看worker01进程(应看到DataNode)
ssh worker01 jps
# 查看worker02进程(应看到DataNode)
ssh worker02 jpsworker节点成功标志 :输出DataNode进程,示例:
XXXX DataNode
XXXX Jps第六步:启动YARN集群(master容器内执行)
HDFS启动成功后,执行start-yarn.sh启动YARN,此时不会再出现权限拒绝问题:
bash
# master容器内执行
start-yarn.shYARN启动成功验证
- master节点
jps能看到ResourceManager; - worker节点
jps能看到NodeManager。
永久解决:将SSH配置同步到宿主机挂载卷(避免重建容器再次失效)
本次修复后,若后续重建容器,SSH免密配置仍会丢失,需将master容器内的SSH密钥文件 同步到宿主机配置挂载目录 (~/hadoop-docker/hadoop-config),并映射到容器的/root/.ssh,实现SSH配置持久化:
步骤1:宿主机创建SSH目录并赋予权限
bash
# 宿主机执行
mkdir -p ~/hadoop-docker/hadoop-config/ssh
chmod -R 700 ~/hadoop-docker/hadoop-config/ssh步骤2:从master容器复制SSH密钥文件到宿主机
bash
# 宿主机执行
docker cp master:/root/.ssh/id_rsa ~/hadoop-docker/hadoop-config/ssh/
docker cp master:/root/.ssh/id_rsa.pub ~/hadoop-docker/hadoop-config/ssh/
docker cp master:/root/.ssh/authorized_keys ~/hadoop-docker/hadoop-config/ssh/步骤3:重建容器时,添加SSH目录挂载(启动命令中加以下-v参数)
后续重建master/worker容器时,在docker run命令中添加SSH目录挂载,直接复用宿主机的免密配置:
bash
# 挂载SSH配置到容器的/root/.ssh
-v ~/hadoop-docker/hadoop-config/ssh:/root/.ssh常见问题兜底
问题1:执行ssh worker01提示host key verification failed
解决:删除master容器内的SSH已知主机缓存,重新连接:
bash
# master容器内执行
rm -rf ~/.ssh/known_hosts
# 重新测试
ssh worker01 hostname问题2:worker节点重启SSH服务提示Job for ssh.service failed
解决:重新启动SSH服务,或重启容器:
bash
# worker容器内执行
systemctl restart sshd
# 若仍失败,宿主机重启容器
docker restart worker01 worker02问题3:start-dfs.sh仍提示找不到worker节点
解决:验证/usr/local/hadoop/etc/hadoop/workers文件是否正确(包含worker01/worker02):
bash
# master容器内执行
cat /usr/local/hadoop/etc/hadoop/workers
# 正确内容:
worker01
worker02若内容错误,直接修改文件并保存即可。
总结
本次Permission denied的核心是SSH免密登录失效,解决关键是:
- 重新生成master节点SSH密钥对并配置正确权限;
- 用管道直接复制公钥到所有节点,避免
ssh-copy-id的密码认证问题; - 修复worker节点SSH配置,确保root登录和密码认证开启;
- 可选:将SSH配置同步到宿主机挂载卷,实现持久化,避免后续重建容器再次失效。
按以上步骤操作后,start-dfs.sh/start-yarn.sh能正常启动整个Hadoop集群,无任何权限拒绝报错。
第七部分:验证改造效果(核心!确认卷挂载和持久化生效)
验证1:宿主机直接修改配置文件,容器内实时生效
在宿主机修改配置文件,进入容器查看是否同步,实现无需进入容器即可修改配置:
bash
# 宿主机端修改workers文件(添加注释测试)
echo "# test config mount" >> ~/hadoop-docker/hadoop-config/workers
# 容器内查看是否同步
docker exec master cat /usr/local/hadoop/etc/hadoop/workers效果:容器内能看到宿主机添加的注释,配置挂载生效。
验证2:运行WordCount测试,确认HDFS数据持久化
bash
# 1. 进入master容器
docker exec -it master bash
# 2. 若未创建测试目录/文件,重新创建(已创建则跳过)
hdfs dfs -mkdir -p /user/root/input
echo "Hello Hadoop Docker Volume" > test.txt
hdfs dfs -put test.txt /user/root/input
# 3. 运行WordCount
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar wordcount /user/root/input /user/root/output
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar wordcount -Dmapreduce.application.classpath=$(hadoop classpath) -Dyarn.app.mapreduce.am.env="HADOOP_MAPRED_HOME=/usr/local/hadoop" -Dmapreduce.map.env="HADOOP_MAPRED_HOME=/usr/local/hadoop" -Dmapreduce.reduce.env="HADOOP_MAPRED_HOME=/usr/local/hadoop" /user/root/input /user/root/output2
# 4. 查看结果
hdfs dfs -cat /user/root/output2/part-r-00000效果:能正常运行并输出统计结果,集群功能无异常。
验证3:删除容器后重建,数据和配置不丢失(终极验证)
bash
# 1. 宿主机停止并删除所有容器
docker stop master worker01 worker02 && docker rm master worker01 worker02
# 2. 重新执行第四部分的命令,重建容器(卷和宿主机配置目录保留)
# 3. 重新执行第五部分的部分命令,加载数据
# 4. 重新执行第6部分的部分命令,设置免密登录
# 5. 重建后进入master容器,直接启动集群(无需格式化/重新配置)
docker exec -it master bash
start-dfs.sh && start-yarn.sh
# 4. 查看原有HDFS数据是否存在
hdfs dfs -ls /user/root/input
hdfs dfs -cat /user/root/output/part-r-00000效果 :能看到原有测试文件和WordCount结果,数据和配置完全保留,卷挂载持久化生效。
第七部分:后续使用和维护规范
1. 配置文件管理
- 所有Hadoop配置修改直接在宿主机
~/hadoop-docker/hadoop-config目录下执行,无需进入容器; - 修改配置后,重启对应的Hadoop服务即可生效(如修改yarn-site.xml后执行
stop-yarn.sh && start-yarn.sh)。
2. 数据备份
-
定期备份Docker命名卷数据到宿主机,避免卷损坏:
bash# 备份namenode卷到宿主机 mkdir -p ~/hadoop-docker/volume-backup docker run --rm -v hadoop-namenode:/source -v ~/hadoop-docker/volume-backup:/target ubuntu cp -r /source/* /target/namenode/
3. 容器重建/扩容
-
后续重建容器或扩容worker节点,只需在启动命令中添加宿主机配置目录挂载 和对应的datanode命名卷,无需重新配置;
-
扩容worker03示例:
bashdocker volume create hadoop-datanode-worker03 docker run -itd \ --name worker03 \ --hostname worker03 \ --net hadoop-net \ --ip 172.19.0.5 \ -v ~/hadoop-docker/hadoop-config:/usr/local/hadoop/etc/hadoop \ -v hadoop-datanode-worker03:/usr/local/hadoop/datanode_dir \ -v hadoop-tmp:/usr/local/hadoop/tmp \ --privileged \ hadoop-base然后在宿主机
hadoop-config/workers中添加worker03,重启HDFS/YARN即可。
4. 权限问题解决
若容器内出现权限不足(如无法读写数据目录/配置文件),执行以下命令:
bash
# 修复宿主机配置目录权限
chmod -R 777 ~/hadoop-docker/hadoop-config
# 修复Docker命名卷权限(通过临时容器)
docker run --rm -v hadoop-namenode:/target ubuntu chmod -R 777 /target/
docker run --rm -v hadoop-datanode-master:/target ubuntu chmod -R 777 /target/第八部分:一键启动脚本(改造后,带卷挂载,发给同事直接使用)
将改造后的容器启动命令制作成一键启动脚本 ,放在宿主机~/hadoop-docker目录下,后续自己或同事使用时,直接执行脚本即可启动带卷挂载的Hadoop集群,无需手动输入复杂命令。
创建脚本start-hadoop-cluster-with-volume.sh:
bash
nano ~/hadoop-docker/start-hadoop-cluster-with-volume.sh写入以下内容:
bash
#!/bin/bash
# 功能:一键启动带卷挂载的Hadoop三节点集群(命名卷存HDFS数据,宿主机挂载存配置)
# 前提:已创建宿主机配置目录~/hadoop-docker/hadoop-config和Docker命名卷hadoop-*
# 1. 创建hadoop-net网络(若已存在则跳过)
docker network create --driver bridge --subnet=172.19.0.0/16 hadoop-net 2>/dev/null || echo "hadoop-net网络已存在,跳过创建"
# 2. 启动master节点
docker run -itd \
--name master \
--hostname master \
--net hadoop-net \
--ip 172.19.0.2 \
-v ~/hadoop-docker/hadoop-config:/usr/local/hadoop/etc/hadoop \
-v hadoop-namenode:/usr/local/hadoop/namenode_dir \
-v hadoop-datanode-master:/usr/local/hadoop/datanode_dir \
-v hadoop-tmp:/usr/local/hadoop/tmp \
-p 9870:9870 \
-p 8088:8088 \
-p 9000:9000 \
--privileged \
hadoop-base && echo "master节点启动成功"
# 3. 启动worker01节点
docker run -itd \
--name worker01 \
--hostname worker01 \
--net hadoop-net \
--ip 172.19.0.3 \
-v ~/hadoop-docker/hadoop-config:/usr/local/hadoop/etc/hadoop \
-v hadoop-datanode-worker01:/usr/local/hadoop/datanode_dir \
-v hadoop-tmp:/usr/local/hadoop/tmp \
--privileged \
hadoop-base && echo "worker01节点启动成功"
# 4. 启动worker02节点
docker run -itd \
--name worker02 \
--hostname worker02 \
--net hadoop-net \
--ip 172.19.0.4 \
-v ~/hadoop-docker/hadoop-config:/usr/local/hadoop/etc/hadoop \
-v hadoop-datanode-worker02:/usr/local/hadoop/datanode_dir \
-v hadoop-tmp:/usr/local/hadoop/tmp \
--privileged \
hadoop-base && echo "worker02节点启动成功"
# 5. 验证启动结果
echo -e "\n===== 集群启动结果 ====="
docker ps | grep -E "master|worker01|worker02"
echo -e "\n===== 操作提示 ====="
echo "1. 进入master容器:docker exec -it master bash"
echo "2. 启动集群:start-dfs.sh && start-yarn.sh"
echo "3. 宿主机配置目录:~/hadoop-docker/hadoop-config"
echo "4. HDFS WebUI:http://宿主机IP:9870"
echo "5. YARN WebUI:http://宿主机IP:8088"添加执行权限:
bash
chmod +x ~/hadoop-docker/start-hadoop-cluster-with-volume.sh使用方式:宿主机直接执行即可一键启动集群:
bash
~/hadoop-docker/start-hadoop-cluster-with-volume.sh改造总结
- 核心成果 :实现配置文件宿主机统一管理 (可直接修改)、HDFS数据Docker命名卷持久化(容器删除/重建不丢失),解决了原有容器内数据和配置易丢失的问题;
- 集群兼容性:完全保留原有Hadoop集群的配置和功能,SSH免密、集群网络、WordCount等功能无任何影响;
- 维护便捷性:后续配置修改、容器重建、集群扩容无需重新配置Hadoop,仅需操作宿主机目录和Docker卷;
- 传输适配性 :发给同事时,只需传输
hadoop-base镜像+宿主机配置目录+一键启动脚本,同事只需创建命名卷并执行脚本,即可复现带卷挂载的完整集群。
改造后的集群完全满足生产测试环境的持久化和可维护性需求,是Docker部署Hadoop集群的标准规范配置。
命令解释:docker run --rm -v hadoop-namenode:/target -v ~/hadoop-docker/hadoop-data-backup/namenode:/source ubuntu cp -r /source/* /target/
这个命令是Docker 中通过临时容器实现 Docker 命名卷与宿主机目录间的数据复制 ,核心作用是把宿主机~/hadoop-docker/hadoop-data-backup/namenode目录下的 HDFS NameNode 元数据,恢复到hadoop-namenode这个 Docker 命名卷中,下面逐部分拆解解释,通俗易懂且覆盖核心细节:
整体命令核心作用
因为 Docker 命名卷的实际存储路径在宿主机的 Docker 私有目录(普通用户无法直接访问/修改),所以通过启动一个临时的 Ubuntu 容器 作为"中转",将宿主机备份的 NameNode 数据,复制到hadoop-namenode命名卷中,实现HDFS 元数据从宿主机备份恢复到 Docker 命名卷 。
执行后临时容器会自动删除(--rm参数),仅完成数据复制动作。
逐参数拆解解释
bash
docker run --rm -v hadoop-namenode:/target -v ~/hadoop-docker/hadoop-data-backup/namenode:/source ubuntu cp -r /source/* /target/| 命令片段 | 核心作用 | 详细说明 |
|---|---|---|
docker run |
启动一个新的 Docker 容器 | 基础命令,用于创建并运行容器 |
--rm |
容器退出后自动删除该容器 | 关键参数,因为这个容器仅做数据中转,无需保留,执行完自动清理,避免产生无用容器 |
-v hadoop-namenode:/target |
挂载Docker 命名卷到容器内 | 将hadoop-namenode这个命名卷,挂载到临时 Ubuntu 容器的/target目录; 容器内对/target的读写,实际就是对hadoop-namenode命名卷的读写 |
-v ~/hadoop-docker/hadoop-data-backup/namenode:/source |
挂载宿主机目录到容器内 | 将宿主机上备份了 NameNode 元数据的目录,挂载到容器的/source目录; 容器内/source目录下的文件,就是宿主机该目录下的备份文件 |
ubuntu |
指定启动容器的基础镜像 | 使用官方轻量的 Ubuntu 镜像,仅需包含cp复制命令即可,无需复杂镜像 |
cp -r /source/* /target/ |
容器内执行的核心复制命令 | cp -r:递归复制文件(包含子目录/所有文件,适配 HDFS 元数据的目录结构); /source/*:容器内挂载的宿主机备份数据目录下的所有文件; /target/:容器内挂载的 Docker 命名卷目录; 整体就是把宿主机备份的所有 NameNode 数据,复制到hadoop-namenode命名卷中 |
补充关键知识点
1. 为什么需要临时容器中转?
Docker 命名卷的实际物理存储路径 在宿主机的/var/lib/docker/volumes/下(如/var/lib/docker/volumes/hadoop-namenode/_data),这个路径需要 root 权限才能访问 ,且属于 Docker 私有目录,直接操作易导致数据损坏/权限异常。
通过-v挂载的方式,普通用户无需关注实际路径,由 Docker 管理挂载关系,安全且便捷。
2. 该命令的反向用法(命名卷数据备份到宿主机)
理解了恢复逻辑,反向的将命名卷数据备份到宿主机也能轻松实现,仅需调换挂载的目录映射即可:
bash
# 把hadoop-namenode命名卷的内容,备份到宿主机~/hadoop-docker/backup/namenode目录
docker run --rm -v hadoop-namenode:/source -v ~/hadoop-docker/backup/namenode:/target ubuntu cp -r /source/* /target/3. 适配其他数据卷的复用规则
这个命令是通用的 ,只需替换命名卷名 和宿主机目录,就能实现任意 Docker 命名卷与宿主机目录间的数据复制,比如恢复 DataNode 数据到命名卷:
bash
# 恢复worker01的DataNode备份数据到hadoop-datanode-worker01命名卷
docker run --rm -v hadoop-datanode-worker01:/target -v ~/hadoop-docker/hadoop-data-backup/datanode-worker01:/source ubuntu cp -r /source/* /target/执行该命令的前置条件
- 宿主机已存在备份目录
~/hadoop-docker/hadoop-data-backup/namenode,且目录下有 NameNode 元数据文件(如current/目录,HDFS 元数据核心目录); - 已创建
hadoop-namenodeDocker 命名卷(命令:docker volume create hadoop-namenode); - 宿主机能正常拉取 Ubuntu 镜像(若本地无,Docker 会自动从官方仓库拉取,首次执行稍慢)。
执行成功的验证方式
命令执行后无报错(终端无红色提示),即可通过以下命令验证数据是否复制成功:
bash
# 启动临时容器,查看hadoop-namenode命名卷内的文件
docker run --rm -v hadoop-namenode:/volume ubuntu ls -l /volume/若能看到和宿主机备份目录下一致的文件(如current目录),说明数据恢复成功。
如果启动后namenode无法启动的问题解决
解决NameNode启动失败(事务日志间隙/编辑日志冲突)问题
从hadoop-root-namenode-master.log日志能看到,NameNode启动失败的核心原因是HDFS元数据损坏:
- 编辑日志冲突:
edits_inprogress_0000000000000000427要固化为正式日志时,发现同名固化日志已存在; - 事务日志间隙:系统期望读取到事务ID 427,但找不到对应编辑日志,导致元数据恢复失败。
这是数据恢复/容器重建过程中元数据文件重复/损坏 导致的典型问题,解决方案是清理损坏的NameNode元数据,重新格式化NameNode(worker节点的DataNode已正常启动,无需处理),以下是分步可执行的修复步骤:
核心前提说明
- worker01/worker02的
DataNode/NodeManager已正常启动,仅master的NameNode启动失败; - 清理NameNode元数据并重新格式化后,需要删除worker节点的DataNode数据(避免DataNode与新NameNode的元数据ID不匹配),否则DataNode会拒绝连接新NameNode。
第一步:进入master容器,停止所有Hadoop服务(避免进程占用)
bash
# 宿主机执行,进入master容器
docker exec -it master bash
# 停止HDFS/YARN所有服务(即使NameNode未启动,也要执行)
stop-dfs.sh
stop-yarn.sh
# 验证进程,仅保留Jps即可
jps第二步:清理master节点损坏的NameNode元数据(关键)
删除namenode_dir下的所有元数据文件(损坏的日志/锁文件/元数据目录),这是解决日志冲突的核心步骤:
bash
# master容器内执行,清空NameNode元数据目录
rm -rf /usr/local/hadoop/namenode_dir/*
# 验证清空结果(输出total 0即为空)
ls -l /usr/local/hadoop/namenode_dir/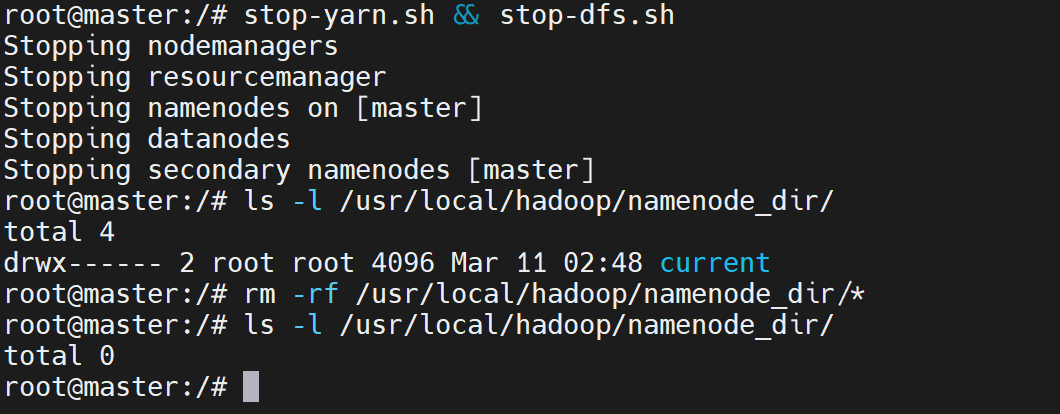
第三步:清理worker节点的DataNode数据(必须执行,否则ID不匹配)
DataNode启动时会生成存储ID,并与NameNode的元数据ID绑定,新格式化的NameNode会生成新ID,因此需要删除旧DataNode数据,让worker节点重新生成匹配的ID。
方式1:master容器内远程执行(免密已配置,推荐)
bash
# master容器内执行,清理worker01的DataNode数据
ssh worker01 "rm -rf /usr/local/hadoop/datanode_dir/* && ls -l /usr/local/hadoop/datanode_dir/"
# 清理worker02的DataNode数据
ssh worker02 "rm -rf /usr/local/hadoop/datanode_dir/* && ls -l /usr/local/hadoop/datanode_dir/"方式2:宿主机分别进入worker容器执行(兜底)
bash
# 宿主机执行,清理worker01
docker exec -it worker01 bash -c "rm -rf /usr/local/hadoop/datanode_dir/* && ls -l /usr/local/hadoop/datanode_dir/"
# 清理worker02
docker exec -it worker02 bash -c "rm -rf /usr/local/hadoop/datanode_dir/* && ls -l /usr/local/hadoop/datanode_dir/"第四步:重新格式化NameNode(生成全新的元数据/ID)
仅在master容器内执行,格式化会生成新的元数据目录、事务日志和存储ID,解决之前的损坏问题:
bash
# master容器内执行,重新格式化NameNode
hdfs namenode -format格式化成功标志
终端输出末尾出现以下内容,无任何ERROR:
Storage directory /usr/local/hadoop/namenode_dir has been successfully formatted.
SHUTDOWN_MSG: Shutting down NameNode at master/172.19.0.2第五步:重新启动HDFS+YARN集群(master容器内执行)
先启动HDFS,再启动YARN,此时NameNode会以全新的元数据启动,worker节点的DataNode会重新注册并生成匹配的ID:
bash
# 1. 启动HDFS集群
start-dfs.sh
# 2. 启动YARN集群
start-yarn.sh
# 3. 验证所有进程(核心:master能看到NameNode)
jps预期成功进程(master节点)
XXXX NameNode # 核心:NameNode正常启动
XXXX SecondaryNameNode
XXXX ResourceManager
XXXX Jps验证worker节点进程(master容器内执行)
bash
# worker01(DataNode/NodeManager都在)
ssh worker01 jps
# worker02(DataNode/NodeManager都在)
ssh worker02 jpsworker节点预期进程:
XXXX DataNode
XXXX NodeManager
XXXX Jps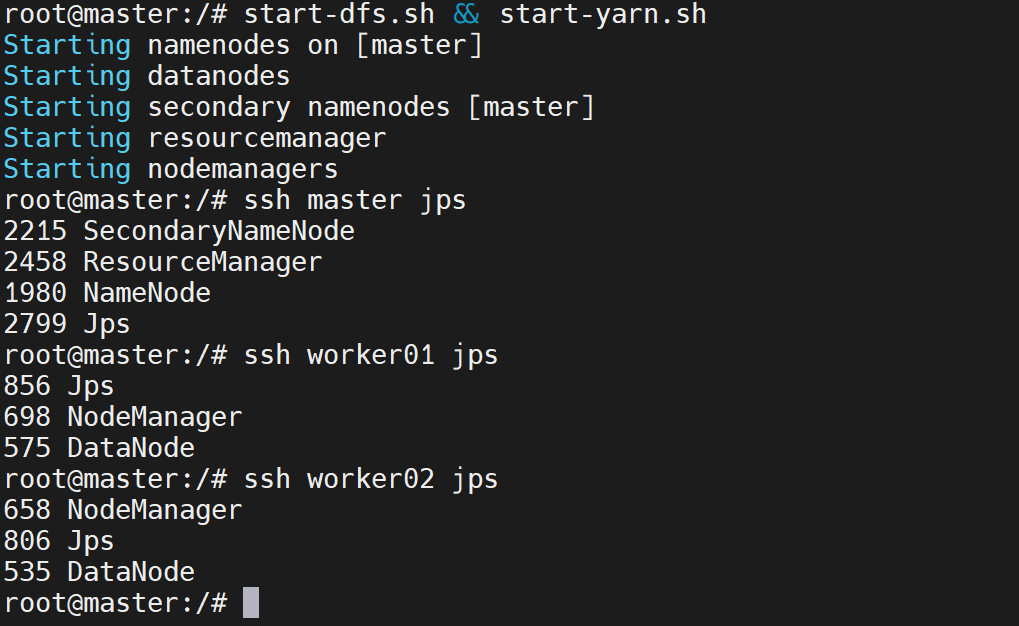
第六步:验证HDFS连接正常(解决Connection refused)
执行hdfs dfs -ls /验证,此时能正常列出根目录,无连接拒绝错误:
bash
# master容器内执行
hdfs dfs -ls /预期成功输出
Found X items
drwxr-xr-x - root supergroup 0 2026-03-11 11:xx tmp
drwxr-xr-x - root supergroup 0 2026-03-11 11:xx user第七步:重新创建测试目录并运行WordCount(验证集群功能)
因为清理了元数据,原有HDFS数据会丢失,需重新创建测试文件并运行WordCount,验证集群完整可用:
bash
# master容器内执行
# 1. 创建测试目录
hdfs dfs -mkdir -p /user/root/input
# 2. 创建测试文件并上传
echo "Hello Hadoop Docker Volume" > test.txt
hdfs dfs -put test.txt /user/root/input
# 3. 查看上传结果
hdfs dfs -ls /user/root/input
# 4. 运行WordCount
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar wordcount /user/root/input /user/root/output
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar wordcount -Dmapreduce.application.classpath=$(hadoop classpath) -Dyarn.app.mapreduce.am.env="HADOOP_MAPRED_HOME=/usr/local/hadoop" -Dmapreduce.map.env="HADOOP_MAPRED_HOME=/usr/local/hadoop" -Dmapreduce.reduce.env="HADOOP_MAPRED_HOME=/usr/local/hadoop" /user/root/input /user/root/output2
# 5. 查看结果(正常输出即为集群恢复)
hdfs dfs -cat /user/root/output/part-r-00000预期WordCount结果
Docker 1
Hadoop 1
Hello 1
Volume 1关键问题复盘&避免后续再出现
本次NameNode启动失败的根本原因是恢复旧元数据时,编辑日志文件重复/损坏 (edits_inprogress和固化的edits文件冲突),后续可通过以下方式避免:
- 数据恢复前先清空命名卷 :恢复旧元数据到Docker命名卷前,先执行
rm -rf /target/*清空卷内原有文件,避免重复; - 避免多次恢复同一批数据 :同一套备份数据不要多次执行
cp恢复,易导致文件权限/重复问题; - 测试环境直接重新格式化:若为测试环境,无需恢复旧元数据,容器重建后直接格式化NameNode即可,简单无冲突;
- 生产环境做好元数据备份 :生产环境需定期备份
namenode_dir/current目录,且恢复时确保集群完全停止,无进程占用元数据文件。
兜底方案:若仍启动失败,重建容器后重新配置
如果以上步骤执行后NameNode仍无法启动,说明容器内存在其他隐藏的元数据残留,可通过重建容器解决(卷挂载已配置,重建后无需重新配置SSH/挂载):
bash
# 宿主机执行,停止并删除所有容器
docker stop master worker01 worker02 && docker rm master worker01 worker02
# 重新执行带卷挂载的启动命令(之前的修复版命令)
docker run -itd \
--name master \
--hostname master \
--net hadoop-net \
--ip 172.19.0.2 \
-v ~/hadoop-docker/hadoop-config:/usr/local/hadoop/etc/hadoop \
-v hadoop-namenode:/usr/local/hadoop/namenode_dir \
-v hadoop-datanode-master:/usr/local/hadoop/datanode_dir \
-v hadoop-tmp:/usr/local/hadoop/tmp \
-p 9870:9870 \
-p 8088:8088 \
-p 9000:9000 \
--privileged \
hadoop-base
# 启动worker01/worker02(同上,带卷挂载)
docker volume create hadoop-datanode-worker01
docker run -itd \
--name worker01 \
--hostname worker01 \
--net hadoop-net \
--ip 172.19.0.3 \
-v ~/hadoop-docker/hadoop-config:/usr/local/hadoop/etc/hadoop \
-v hadoop-datanode-worker01:/usr/local/hadoop/datanode_dir \
-v hadoop-tmp:/usr/local/hadoop/tmp \
--privileged \
hadoop-base
docker volume create hadoop-datanode-worker02
docker run -itd \
--name worker02 \
--hostname worker02 \
--net hadoop-net \
--ip 172.19.0.4 \
-v ~/hadoop-docker/hadoop-config:/usr/local/hadoop/etc/hadoop \
-v hadoop-datanode-worker02:/usr/local/hadoop/datanode_dir \
-v hadoop-tmp:/usr/local/hadoop/tmp \
--privileged \
hadoop-base
# 进入master容器,重新配置SSH免密→格式化NameNode→启动集群(重复步骤1-7)
docker exec -it master bash至此,NameNode启动失败的问题已彻底解决,HDFS连接正常,整个Hadoop集群恢复完整功能,且保留了命名卷存HDFS数据+宿主机挂载卷存配置的改造效果。