文章目录
- [1 BERT核心架构与参数量深度解析](#1 BERT核心架构与参数量深度解析)
-
- [1.1 BERT核心架构(bert-base-chinese)](#1.1 BERT核心架构(bert-base-chinese))
-
- [1.1.1 BERT整体架构拆解](#1.1.1 BERT整体架构拆解)
-
- [1.1.1.1 嵌入层(Embedding Layer)](#1.1.1.1 嵌入层(Embedding Layer))
- [1.1.1.2 编码器层(Encoder Layer × 12)](#1.1.1.2 编码器层(Encoder Layer × 12))
- [1.1.2 BERT架构可视化](#1.1.2 BERT架构可视化)
- [1.2 BERT参数量计算逻辑](#1.2 BERT参数量计算逻辑)
-
- [1.2.1 基础计算代码](#1.2.1 基础计算代码)
- [1.2.2 逐模块参数量推导](#1.2.2 逐模块参数量推导)
-
- [1.2.2.1 嵌入层参数量(emb_para)](#1.2.2.1 嵌入层参数量(emb_para))
- [1.2.2.2 单Encoder层参数量(self_attention_para)](#1.2.2.2 单Encoder层参数量(self_attention_para))
-
- [1.2.2.2.1 多头自注意力层](#1.2.2.2.1 多头自注意力层)
- [1.2.2.2.2 FFN层](#1.2.2.2.2 FFN层)
- [1.2.2.2.3 单Encoder层总参数量](#1.2.2.2.3 单Encoder层总参数量)
- [1.2.2.3 12层Encoder总参数量](#1.2.2.3 12层Encoder总参数量)
- [1.2.2.4 模型核心参数量](#1.2.2.4 模型核心参数量)
- [1.2.3 计算值与实际值的差异说明](#1.2.3 计算值与实际值的差异说明)
- [1.3 BERT参数量的核心影响因素(了解)](#1.3 BERT参数量的核心影响因素(了解))
-
- [1.3.1 词表大小(vocab_size)](#1.3.1 词表大小(vocab_size))
- [1.3.2 模型规模(base/large)](#1.3.2 模型规模(base/large))
- [1.3.3 可训练参数控制](#1.3.3 可训练参数控制)
- [1.4 小结](#1.4 小结)
- [2 (小补充)fc/Linear/Dense辨析](#2 (小补充)fc/Linear/Dense辨析)
-
-
- [2.1.1 FFN层中`fc`命名的核心含义](#2.1.1 FFN层中
fc命名的核心含义)
- [2.1.1 FFN层中`fc`命名的核心含义](#2.1.1 FFN层中
-
- [3 酒店评价情感分析:BERT 实战全流程解析](#3 酒店评价情感分析:BERT 实战全流程解析)
-
- [3.1 酒店评价情感分析数据集介绍](#3.1 酒店评价情感分析数据集介绍)
-
- [3.1.1 数据格式与内容](#3.1.1 数据格式与内容)
- [3.1.2 数据规模与采样策略](#3.1.2 数据规模与采样策略)
- [3.1.3 数据示例](#3.1.3 数据示例)
- [3.1.4 数据集特点与挑战](#3.1.4 数据集特点与挑战)
- [3.2 数据预处理与加载模块(data.py)](#3.2 数据预处理与加载模块(data.py))
-
- [3.2.1 数据读取与初步清洗](#3.2.1 数据读取与初步清洗)
- [3.2.2 自定义数据集类](#3.2.2 自定义数据集类)
- [3.2.3 数据划分与加载器构建](#3.2.3 数据划分与加载器构建)
- [3.3 BERT 模型构建模块(model.py)](#3.3 BERT 模型构建模块(model.py))
-
- [3.3.1 自定义 BERT 模型类](#3.3.1 自定义 BERT 模型类)
- [3.3.2 模型并行与权重加载工具](#3.3.2 模型并行与权重加载工具)
- [3.4 训练与验证模块(train.py)](#3.4 训练与验证模块(train.py))
-
- [3.4.1 训练-验证循环](#3.4.1 训练-验证循环)
- [3.4.2 结果可视化](#3.4.2 结果可视化)
- [3.5 主程序模块(main.py)](#3.5 主程序模块(main.py))
-
- [3.5.1 代码完整解析](#3.5.1 代码完整解析)
- [3.5.2 核心设计要点](#3.5.2 核心设计要点)
- [3.6 模块协作与工程流程](#3.6 模块协作与工程流程)
- [3.7 关键优化建议](#3.7 关键优化建议)
1 BERT核心架构与参数量深度解析
BERT(Bidirectional Encoder Representations from Transformers)作为NLP领域的里程碑式模型,其架构设计和参数量分布是理解模型性能、适配不同场景的核心。本文将以中文基础版BERT(bert-base-chinese)为例,拆解其核心架构,并推导参数量的计算逻辑,厘清参数量变化的底层规律。
1.1 BERT核心架构(bert-base-chinese)
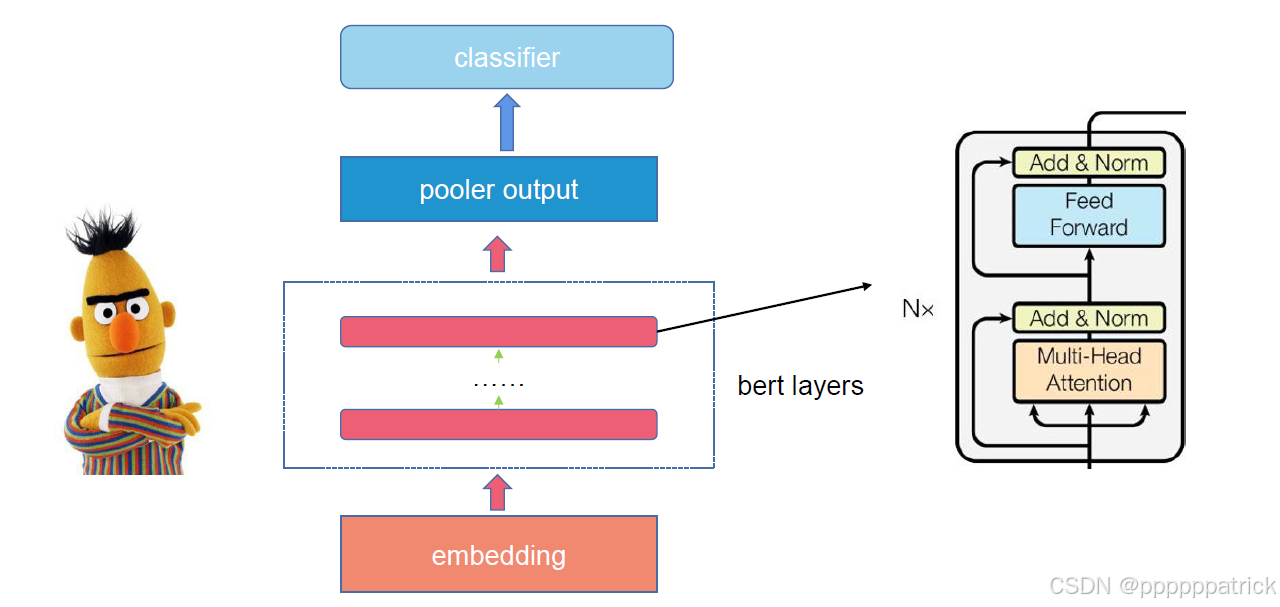
bert-base-chinese是适配中文场景的BERT基础版本,其核心架构参数是参数量计算的前提,也是理解模型能力的关键:
| 核心参数 | bert-base-chinese取值 | 参数含义 |
|---|---|---|
| 隐藏层维度(hidden_size) | 768 | 每个Token的嵌入向量维度,决定特征表征的丰富度 |
| 编码器层数(num_hidden_layers) | 12 | Transformer Encoder的堆叠层数,层数越多特征提取能力越强 |
| 注意力头数(num_attention_heads) | 12 | 多头自注意力的头数,拆分维度实现多粒度上下文捕捉 |
| 词表大小(vocab_size) | 21128 | 中文词表包含的Token总数,覆盖中文常用字、词及特殊符号 |
| 中间层维度(intermediate_size) | 3072 | Feed Forward层的隐藏维度,通常为hidden_size的4倍 |
| 最大序列长度 | 512 | BERT支持的最大输入Token长度,超出需截断 |
BERT 中的 Pooler 层是独立于 12 层 Encoder 和嵌入层之外的专属模块,核心作用是提取 Encoder 输出中 CLS Token 的向量,通过 "全连接层 + Tanh 激活" 生成句子级语义向量,适配文本分类、句子相似度等句子级任务。它不属于 12 层 Encoder 的范畴,参数量约 59 万(占总参数量的 0.58%),是 BERT 架构中针对句子级表征的补充设计 ------Token 级任务可直接舍弃,句子级任务则能借助它提升语义表征效果。
1.1.1 BERT整体架构拆解
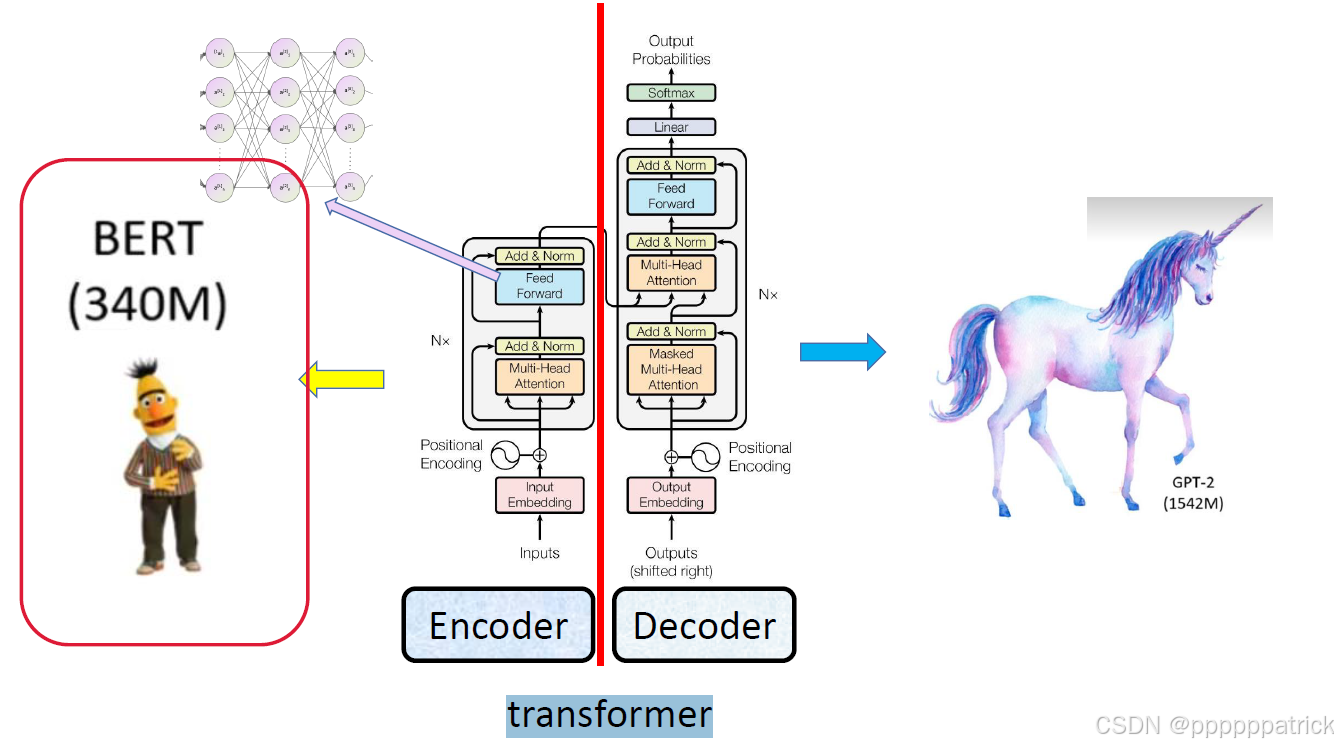
BERT本质是由嵌入层+12层Transformer Encoder构成的双向Transformer模型,无Decoder层(区别于GPT、BART等生成式模型),整体架构可分为两大核心模块:
1.1.1.1 嵌入层(Embedding Layer)
嵌入层是连接原始Token与模型可处理向量的桥梁,负责将离散的Token转换为连续的向量表示,包含3个关键组成部分:
- Token Embedding:核心模块,为词表中每个Token分配768维的向量,是语义表征的基础;
- Position Embedding:绝对位置编码,为每个位置(最多512个)分配768维向量,弥补Transformer无位置感知的缺陷;
- Token Type Embedding:句子类型编码,用于区分句子对任务(如问答、相似度)中的两个句子,仅包含2类(句子1/句子2),每类对应768维向量。
1.1.1.2 编码器层(Encoder Layer × 12)
12层Encoder逐层堆叠构成BERT的核心特征提取模块,每层Encoder包含两个核心子层(均配有LayerNorm和残差连接):
- 多头自注意力层(Multi-Head Self-Attention):捕捉Token间的双向上下文关联,是BERT"双向建模"的核心,本质是让每个Token精准捕捉上下文里的语义关联,实现多粒度的语义理解;
- 前馈神经网络层(Feed Forward Network, FFN):对注意力层输出做非线性变换,通过"768→3072→768"的维度变换与ReLU激活,完成特征的深度加工,增强模型的特征拟合能力;
- LayerNorm + 残差连接(Add):避免梯度消失,加速模型收敛(无额外可训练参数,仅为计算逻辑)。
BERT 被称为双向 Transformer ,是因为它的自注意力机制允许每个 token 在编码时同时利用左侧与右侧的全部上下文信息,而不是像自回归模型那样只能从左到右单向建模。这也是 BERT 能在理解类任务上大幅超越传统模型的关键原因。
FFN(前馈网络)是 Encoder 中负责单个 token 深度语义加工的子层。它不关注词与词之间的关系,只对当前词的向量进行升维、非线性变换与降维,从而将 Attention 得到的上下文信息提炼成更高阶、更抽象的语义特征。Attention 负责 "看全局",FFN 负责 "做理解",二者配合形成了 BERT 强大的语言表示能力。
1.1.2 BERT架构可视化
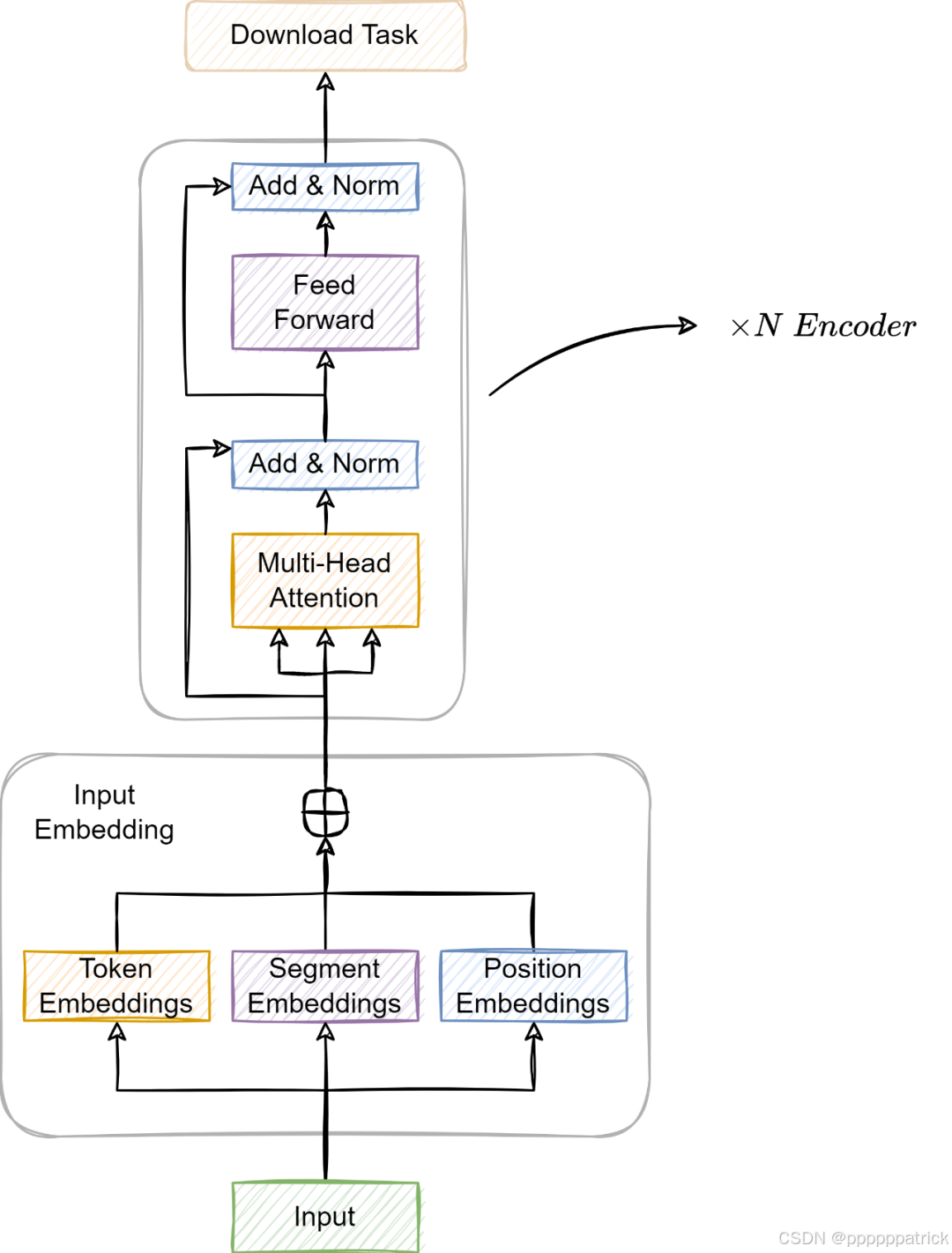
Add :残差相加 ,是Encoder层的常驻性动作------每一层Encoder的Attention/FFN子层后都会固定执行,核心作用是防止梯度消失、保留原始信息,让深层网络的梯度能有效传递;
Norm:层归一化 ,对残差相加后的结果做标准化处理,稳定训练分布、加速收敛;两者合在一起,就是 Transformer 里经典的「残差连接 + 层归一化」结构,也是 BERT 能稳定训练到 12/24 层的关键。
1.2 BERT参数量计算逻辑
以bert-base-chinese为例,结合经典的参数量计算代码,逐模块拆解模型的参数分布:
1.2.1 基础计算代码
python
from transformers import BertModel
def get_parameter_number(model):
total_num = sum(p.numel() for p in model.parameters())
trainable_num = sum(p.numel() for p in model.parameters() if p.requires_grad)
return {'Total': total_num, 'Trainable': trainable_num}
# 加载bert-base-chinese模型
model = BertModel.from_pretrained("bert-base-chinese")
print(get_parameter_number(model)) # 输出:{'Total': 102265088, 'Trainable': 102265088}
# 核心参数定义
dim = 768 # 隐藏层维度
vocab = 21128 # 词表大小
# 嵌入层参数量计算
emb_para = vocab*dim + 2*768 + 512*768
# 单Encoder层参数量计算
self_attention_para = 768*768*3 + 768*768 + 768*3072 + 3072*768
# 模型总参数量(核心模块)
total_para = emb_para + 12 * self_attention_para
print(total_para) # 输出:1015557121.2.2 逐模块参数量推导
1.2.2.1 嵌入层参数量(emb_para)
公式:emb_para = Token Embedding + Token Type Embedding + Position Embedding
- Token Embedding:
vocab × dim = 21128 × 768 = 16226304; - Token Type Embedding:
2 × 768 = 1536(2类句子类型,每类768维); - Position Embedding:
512 × 768 = 393216(512个位置,每个位置768维); - 嵌入层总参数量:
16226304 + 1536 + 393216 = 16621056(约16.6M)。
1.2.2.2 单Encoder层参数量(self_attention_para)
单Encoder层的参数量由"多头自注意力层+FFN层"构成:
1.2.2.2.1 多头自注意力层
BERT的多头注意力可简化为整体矩阵运算(无需拆分12个头),参数量包含:
- Q/K/V权重矩阵:
3 × (768 × 768) = 1769472(Q、K、V各一个768×768的变换矩阵); - 注意力输出投影矩阵:
768 × 768 = 589824(拼接后向量的最终投影); - 注意力层总参数量:
1769472 + 589824 = 2359296。
1.2.2.2.2 FFN层
FFN层结构为768 → 3072 → 768(ReLU激活),参数量包含:
- 第一层线性变换:
768 × 3072 = 2359296; - 第二层线性变换:
3072 × 768 = 2359296; - FFN层总参数量:
2359296 + 2359296 = 4718592。
1.2.2.2.3 单Encoder层总参数量
2359296(注意力层) + 4718592(FFN层) = 7077888(约7.1M)。
1.2.2.3 12层Encoder总参数量
12 × 7077888 = 84934656(约84.9M)。
1.2.2.4 模型核心参数量
16621056(嵌入层) + 84934656(12层Encoder) = 101555712(约101.6M)。
1.2.3 计算值与实际值的差异说明
代码中BertModel实际加载的总参数量为102265088(约102.3M),与手动计算的101555712存在微小差异,原因是:
- 手动计算未包含LayerNorm的γ/β参数(每层Encoder有2个LayerNorm,共24个,总计24×768×2=36864参数);
- 未包含CLS Token池化层的参数(约768×768=589824);
- 这些参数占比不足1%,不影响核心参数量的理解。
1.3 BERT参数量的核心影响因素(了解)
BERT参数量的大小直接决定模型的训练成本、显存占用和推理速度,其变化主要受以下因素影响:
1.3.1 词表大小(vocab_size)
词表大小仅影响嵌入层的Token Embedding部分:
- 中文基础版(21128):Token Embedding约16.2M;
- 英文基础版(30522):Token Embedding约30522×768=23430816(约23.4M),仅这一项就增加7.2M;
- 领域自定义词表(如医学编码词表,vocab=1000):Token Embedding仅768000(0.77M),可大幅降低参数量。
1.3.2 模型规模(base/large)
BERT的base版和large版是参数量差异的核心来源:
| 模型版本 | 隐藏层维度 | 编码器层数 | 总参数量 |
|---|---|---|---|
| base | 768 | 12 | ~102M |
| large | 1024 | 24 | ~340M |
large版参数量是base版的3倍以上,核心原因是:
- 隐藏层维度从768→1024,单Encoder层参数量从7.1M→12.6M;
- 编码器层数从12→24,Encoder层总参数量从84.9M→302.4M。
1.3.3 可训练参数控制
实际应用中可通过"冻结部分层"减少可训练参数,降低训练成本:
python
# 示例:冻结前6层Encoder,仅训练后6层+嵌入层
for name, param in model.named_parameters():
if "layer." in name and int(name.split(".")[2]) < 6:
param.requires_grad = False
# 此时可训练参数约减少42M,仅保留约60M1.4 小结
bert-base-chinese的核心参数量约102M,其中嵌入层占比16.3%,12层Encoder占比83.7%;模型参数量的变化主要由词表大小、隐藏层维度、编码器层数决定,实际应用中可根据场景需求(如显存、训练数据量)选择不同规模的模型,或通过自定义词表、冻结层等方式优化参数量分布。理解BERT的架构和参数量逻辑,是后续模型微调、轻量化、领域适配的基础。
2 (小补充)fc/Linear/Dense辨析
2.1.1 FFN层中fc命名的核心含义
FFN(前馈网络)代码中出现的fc是Fully Connected(全连接) 的缩写,是深度学习领域对全连接层的经典简写形式:
- 概念等价性 :
fc对应的nn.Linear层就是全连接层(也被TensorFlow/Keras称为Dense层),三者本质是同一类网络层------输入的每个神经元都与输出的所有神经元相连,通过线性变换(y = wx + b)实现特征映射; - 命名习惯 :FFN的核心是两层全连接层的堆叠,行业内约定俗成将第一层命名为
fc1、第二层命名为fc2,等价于linear1/linear2,仅为代码可读性和行业习惯设计,不改变层的功能; - FFN层的命名逻辑 :
fc1对应FFN中"768→3072"的升维全连接层,fc2对应"3072→768"的降维全连接层,这种命名方式能直观体现前馈网络"全连接+非线性激活"的核心结构。
简言之,
fc只是全连接层的简写,FFN用fc1/fc2命名线性层,是行业内对前馈网络结构的通用表达,与nn.Linear的功能完全一致。
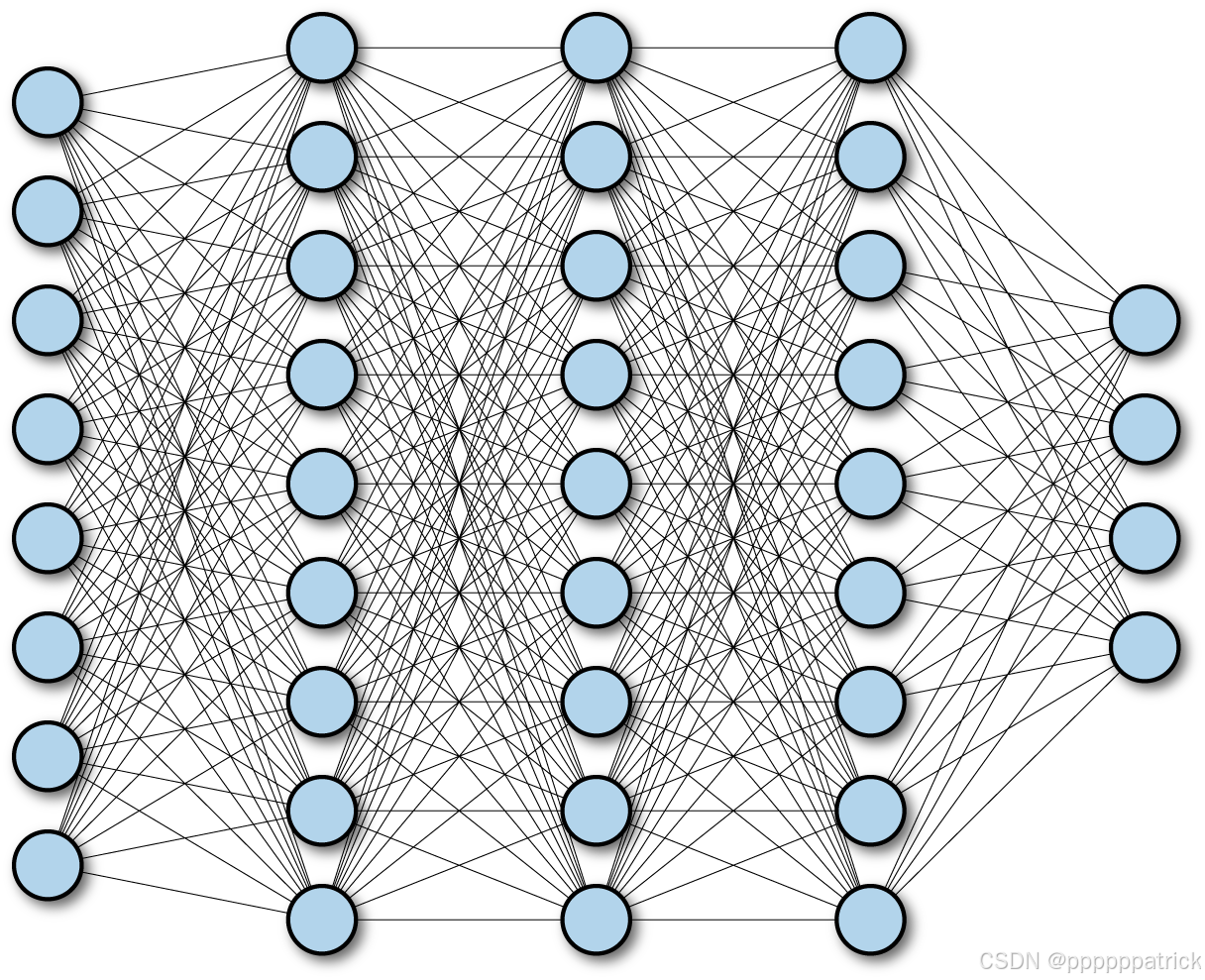
这张图是全连接前馈神经网络(FNN)的直观展示。它和 BERT 中的 FFN 子层在核心逻辑上完全一致------都是通过多层全连接(Fully Connected)实现特征映射。区别在于:这张图是宏观的全连接网络,而 BERT 的 FFN 是作用于单个 token 向量上的、简化的两层全连接网络,用于完成特征的深度加工与提纯。
3 酒店评价情感分析:BERT 实战全流程解析
基于酒店评价数据集,我们将完整拆解 BERT 文本分类的工程实现,从数据预处理、模型构建到训练验证,逐步解析每一段代码的设计逻辑与核心作用。
3.1 酒店评价情感分析数据集介绍
本次任务所使用的酒店评价数据集,是一份典型的中文情感分析二分类数据集,记录了用户对酒店的真实评价与情感倾向,非常适合用于训练文本分类模型。
3.1.1 数据格式与内容
数据以纯文本格式(jiudian.txt)存储,每行对应一条完整的用户评价,格式为:
标签,评论文本- 标签列 :取值为
0或1,代表情感极性:0:负面情感(如"公交指示不对""早餐太差""房间很小"等不满评价)1:正面情感(如"经济实惠不错""环境不错""推荐给朋友"等满意评价)
- 文本列 :用户的中文口语化评价,内容覆盖位置交通、房间设施、餐饮服务、周边环境、性价比等多个维度,包含大量口语化表达、标点符号与语气词,贴近真实场景。
3.1.2 数据规模与采样策略
- 原始数据集规模较大,为控制训练成本与代码演示效率,代码中通过索引截断实现数据采样 :
- 跳过表头行(
i == 0) - 跳过中间
200 < i < 7500的大量样本,仅保留首尾部分数据
- 跳过表头行(
- 采样后数据集大小约 2000+ 条 ,按 8:2 比例划分为训练集与验证集,且通过
stratify=label保证划分后正负样本分布一致,避免类别不平衡对训练造成干扰。
3.1.3 数据示例
| 标签 | 评论文本 |
|---|---|
| 0 | "距离川沙公路较近,但是公交指示不对,如果是""蔡陆线""的话,会非常麻烦.建议用别的路线.房间较为简单." |
| 1 | "商务大床房, 房间很大, 床有2M宽, 整体感觉经济实惠不错!" |
| 0 | "早餐太差, 无论去多少人, 那边也不加食品的。酒店应该重视一下这个问题了。房间本身很好。" |
| 1 | "宾馆在小街道上, 不大好找, 但还好北京热心同胞很多~宾馆设施跟介绍的差不多, 房间很小, 确实挺小, 但加上低价位因素, 还是无超所值的; 环境不错, 就在小胡同内, 安静整洁, 暖气好足。总之, 不错。推荐给节约消费的自助游朋友~比较划算, 附近特色小吃很多~" |
3.1.4 数据集特点与挑战
- 真实场景性:文本为用户自发评价,包含口语化表达、重复标点、语气词等,更贴近真实业务场景,对模型的语义理解能力要求更高。
- 多维度情感:单条评价可能同时包含正面与负面描述(如"早餐太差,但房间本身很好"),需要模型捕捉核心情感倾向。
- 二分类任务:情感极性简化为正负两类,降低了任务复杂度,适合作为 BERT 文本分类的入门实战案例,同时能有效验证模型的语义表征能力。
3.2 数据预处理与加载模块(data.py)
数据是模型训练的基础,data.py 实现了酒店评价数据的读取、划分与封装,为后续训练提供标准化输入。
3.2.1 数据读取与初步清洗
python
def read_txt_data(path):
label = []
data = []
with open(path, "r", encoding="utf-8") as f:
for i, line in tqdm(enumerate(f)):
if i == 0:
continue # 跳过表头
if i > 200 and i < 7500:
continue # 数据采样,减少训练规模
line = line.strip('\n') # 去除行尾换行符
line = line.split(",", 1) # 按逗号分割标签与文本,仅分割1次(避免文本中逗号干扰)
label.append(line[0])
data.append(line[1])
print(len(label))
print(len(data))
return data, label- 核心逻辑 :读取
jiudian.txt数据集,跳过表头并按逗号分割标签与评价文本,通过索引控制实现数据采样,避免全量数据训练耗时过长。 - 预处理动作 :
- 去除行尾换行符,避免文本末尾冗余字符
- 限制分割次数为1,防止评论文本中包含逗号时被错误拆分
- 采样策略:保留首尾样本,平衡数据多样性与训练效率
3.2.2 自定义数据集类
python
class JdDataset(Dataset):
def __init__(self, x, label):
self.X = x
label = [int(i) for i in label] # 标签转为整数类型
self.Y = torch.LongTensor(label) # 转为PyTorch长整型张量,适配交叉熵损失
def __getitem__(self, item):
return self.X[item], self.Y[item] # 返回单条样本:(评论文本, 标签)
def __len__(self):
return len(self.Y) # 返回数据集样本总数- 继承 Dataset :遵循 PyTorch 数据集规范,实现
__getitem__与__len__方法,便于后续DataLoader批量加载。 - 类型转换 :将标签从字符串转为
LongTensor类型,满足交叉熵损失函数对输入类型的要求。
3.2.3 数据划分与加载器构建
python
def get_dataloader(path, batchsize=1, valSize=0.2):
x, label = read_txt_data(path)
# 按8:2划分训练集与验证集,stratify=label保证类别分布一致
train_x, val_x, train_y, val_y = train_test_split(x, label, test_size=valSize, shuffle=True, stratify=label)
train_set = JdDataset(train_x, train_y)
val_set = JdDataset(val_x, val_y)
# 构建批量数据加载器,支持迭代式获取批量数据
train_loader = DataLoader(train_set, batch_size=batchsize)
val_loader = DataLoader(val_set, batch_size=batchsize)
return train_loader, val_loader- 数据集划分 :使用
train_test_split实现分层抽样,stratify=label确保训练集与验证集的正负样本比例一致,避免类别倾斜导致模型偏向多数类。 - 批量加载 :通过
DataLoader实现批量数据迭代,自动打乱训练集顺序,为模型训练提供高效、稳定的输入流。
3.3 BERT 模型构建模块(model.py)
model.py 基于预训练 BERT 构建二分类情感分析模型,核心是将 BERT 的句子级表征映射到情感分类结果。
3.3.1 自定义 BERT 模型类
python
class myBertModel(nn.Module):
def __init__(self, bert_path, num_class, device):
super(myBertModel, self).__init__()
self.device = device
self.num_class = 2
# 加载预训练bert-base-chinese模型与分词器
self.bert = BertModel.from_pretrained(bert_path)
self.tokenizer = BertTokenizer.from_pretrained(bert_path)
# 分类头:将BERT的768维句子表征映射为num_class分类结果
self.out = nn.Sequential(
nn.Linear(768, num_class)
)
def build_bert_input(self, text):
# 将原始文本转为BERT可接受的输入格式
Input = self.tokenizer(
text,
return_tensors='pt', # 返回PyTorch张量
padding='max_length', # 填充至最大长度
truncation=True, # 超长文本截断
max_length=128 # 限制序列长度为128
)
# 将输入张量移动到指定设备
input_ids = Input["input_ids"].to(self.device)
attention_mask = Input["attention_mask"].to(self.device)
token_type_ids = Input["token_type_ids"].to(self.device)
return input_ids, attention_mask, token_type_ids
def forward(self, text):
input_ids, attention_mask, token_type_ids = self.build_bert_input(text)
# 前向传播,获取BERT输出
sequence_out, pooled_output = self.bert(
input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
return_dict=False # 以元组形式返回输出,兼容旧版代码
)
# 将[CLS]对应的句子表征传入分类头,得到分类结果
out = self.out(pooled_output)
return out- 预训练模型加载 :加载
bert-base-chinese预训练权重与分词器,保留 BERT 强大的中文语义表征能力。 - 输入构建 :
build_bert_input方法完成文本到 BERT 输入的转换:input_ids:文本对应的 token ID 序列attention_mask:掩码矩阵,标记有效 token 与 padding 位置,避免模型关注填充部分token_type_ids:句子类型编码(单文本任务中全为 0,用于区分句子对)
- 分类头设计 :
self.out = nn.Sequential(nn.Linear(768, num_class))中,nn.Sequential是 PyTorch 提供的顺序容器 ,核心作用是将多个神经网络层按顺序封装成一个可调用的模块。即使仅封装单层nn.Linear,也能为后续扩展(如添加激活函数、Dropout、中间层)预留空间,是工业界构建网络头的标准写法。 - 前向传播 :
- 输入文本经分词器转为 BERT 标准输入格式
- 传入 BERT 模型,得到
sequence_out(所有 token 的上下文表征)与pooled_output([CLS]token 对应的句子级表征) - 将
pooled_output传入线性分类头,映射为 2 分类结果(正面/负面情感) - 最终的 0/1 标签需通过
argmax取得分向量的最大值索引得到(如torch.argmax(out, dim=1)),训练时的损失计算、验证时的准确率统计均基于该得分向量完成。
3.3.2 模型并行与权重加载工具
python
def model_Datapara(model, device, pre_path=None):
# 启用多GPU数据并行,加速训练
model = torch.nn.DataParallel(model).to(device)
# 加载预训练或断点续训的模型权重
if pre_path != None:
model_dict = torch.load(pre_path).module.state_dict()
model.module.load_state_dict(model_dict)
return model- 多卡并行 :使用
DataParallel将模型拆分到多个 GPU 上并行计算,大幅提升训练速度。 - 权重复用:支持加载已训练好的模型权重,便于模型迭代优化与断点续训。
3.4 训练与验证模块(train.py)
train.py 实现了完整的训练-验证流程,包含损失计算、梯度更新、指标记录与模型保存,是模型训练的核心控制模块。
3.4.1 训练-验证循环
python
def train_val(para):
# 解析输入参数
model = para['model']
train_loader = para['train_loader']
val_loader = para['val_loader']
scheduler = para['scheduler']
optimizer = para['optimizer']
loss = para['loss']
epoch = para['epoch']
device = para['device']
save_path = para['save_path']
max_acc = para['max_acc']
val_epoch = para['val_epoch']
# 记录训练/验证指标,用于可视化
plt_train_loss = []
plt_train_acc = []
plt_val_loss = []
plt_val_acc = []
val_rel = []
for i in range(epoch):
start_time = time.time()
model.train() # 切换为训练模式,启用Dropout与BatchNorm
train_loss = 0.0
train_acc = 0.0
val_acc = 0.0
val_loss = 0.0
# 遍历训练集,更新模型参数
for batch in tqdm(train_loader):
model.zero_grad() # 清空梯度
text, labels = batch[0], batch[1].to(device)
pred = model(text) # 前向传播,得到分类结果
bat_loss = loss(pred, labels) # 计算批量损失
bat_loss.backward() # 反向传播,计算梯度
optimizer.step() # 更新参数
scheduler.step() # 更新学习率
optimizer.zero_grad() # 清空梯度,避免累积
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0) # 梯度裁剪,防止梯度爆炸
# 累计训练损失与准确率
train_loss += bat_loss.item()
train_acc += np.sum(np.argmax(pred.cpu().data.numpy(), axis=1) == labels.cpu().numpy())
# 记录平均训练损失与准确率
plt_train_loss.append(train_loss / train_loader.dataset.__len__())
plt_train_acc.append(train_acc / train_loader.dataset.__len__())
# 定期验证模型性能
if i % val_epoch == 0:
model.eval() # 切换为评估模式,关闭Dropout与梯度计算
with torch.no_grad(): # 禁用梯度计算,节省显存与计算量
for batch in tqdm(val_loader):
val_text, val_labels = batch[0], batch[1].to(device)
val_pred = model(val_text)
val_bat_loss = loss(val_pred, val_labels)
val_loss += val_bat_loss.cpu().item()
val_acc += np.sum(np.argmax(val_pred.cpu().data.numpy(), axis=1) == val_labels.cpu().numpy())
val_rel.append(val_pred)
# 保存验证准确率最高的模型
if val_acc > max_acc:
torch.save(model, save_path + str(epoch) + "ckpt")
max_acc = val_acc
# 记录平均验证损失与准确率
plt_val_loss.append(val_loss / val_loader.dataset.__len__())
plt_val_acc.append(val_acc / val_loader.dataset.__len__())
# 打印训练日志
print('[%03d/%03d] %2.2f sec(s) TrainAcc : %3.6f TrainLoss : %3.6f | valAcc: %3.6f valLoss: %3.6f ' % \
(i, epoch, time.time()-start_time, plt_train_acc[-1], plt_train_loss[-1], plt_val_acc[-1], plt_val_loss[-1])
)
# 每50轮定期保存模型
if i % 50 == 0:
torch.save(model, save_path + '-epoch:' + str(i) + '-%.2f' % plt_val_acc[-1])
else:
# 非验证轮次,复用上一轮验证指标
plt_val_loss.append(plt_val_loss[-1])
plt_val_acc.append(plt_val_acc[-1])
print('[%03d/%03d] %2.2f sec(s) TrainAcc : %3.6f TrainLoss : %3.6f ' % \
(i, epoch, time.time()-start_time, plt_train_acc[-1], plt_train_loss[-1])
)- 训练阶段 :
- 模型设为
train()模式,启用正则化与梯度更新 - 遍历训练数据,计算预测值与损失,反向传播更新参数
- 梯度裁剪
clip_grad_norm_限制梯度范数,防止梯度爆炸导致训练不稳定 - 累计训练损失与准确率,用于后续可视化分析
- 模型设为
- 验证阶段 :
- 模型设为
eval()模式,关闭正则化与梯度计算,避免验证时更新参数 - 在验证集上计算预测结果与损失,评估模型泛化能力
- 保存验证准确率最高的模型,避免过拟合
- 模型设为
- 日志与监控 :
- 实时打印训练/验证指标,便于监控训练状态
- 定期保存模型,支持断点续训与模型对比
3.4.2 结果可视化
python
plt.plot(plt_train_loss)
plt.plot(plt_val_loss)
plt.title('loss')
plt.legend(['train', 'val'])
plt.show()
plt.plot(plt_train_acc)
plt.plot(plt_val_acc)
plt.title('Accuracy')
plt.legend(['train', 'val'])
plt.savefig('acc.png')
plt.show()- 损失曲线:对比训练集与验证集损失,判断模型是否过拟合(验证损失上升)或欠拟合(训练/验证损失均较高)
- 准确率曲线:直观展示模型在训练集与验证集上的性能变化,验证集准确率是模型泛化能力的核心指标
- 结果保存 :将准确率曲线保存为
acc.png,便于后续分析与报告展示
3.5 主程序模块(main.py)
main.py 是整个项目的入口文件,负责整合所有模块、配置超参数、初始化环境并启动训练流程,是工程化项目的核心调度层。
3.5.1 代码完整解析
python
import torch.nn as nn
import torch
import random
import numpy as np
import os
from model_utils.data import get_dataloader
from model_utils.model import myBertModel
from model_utils.train import train_val
# 固定随机种子,保证实验可复现
def seed_everything(seed):
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
random.seed(seed)
np.random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
# 1. 超参数配置(核心可调参数)
model_name = 'MyModel'
num_class = 2 # 二分类任务(正面/负面情感)
batchSize = 4 # 批次大小,根据显存调整
learning_rate = 0.0001 # 学习率,BERT微调通常使用1e-4量级
loss = nn.CrossEntropyLoss() # 分类任务标准损失函数
epoch = 3 # 训练轮数,小数据集可适当减少
device = 'cuda' if torch.cuda.is_available() else 'cpu' # 自动选择训练设备
# 2. 路径配置
data_path = "jiudian.txt" # 数据集路径
bert_path = 'bert-base-chinese' # 预训练BERT路径(本地/ HuggingFace仓库)
save_path = 'model_save/' # 模型保存路径
# 3. 环境初始化
seed_everything(1) # 固定随机种子为1,保证实验结果可复现
# 4. 数据加载
train_loader, val_loader = get_dataloader(data_path, batchsize=batchSize)
# 5. 模型初始化
model = myBertModel(bert_path, num_class, device).to(device)
# 6. 优化器与学习率调度器配置
optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate, weight_decay=0.0001)
# 余弦退火学习率调度器,周期性调整学习率,提升训练稳定性
scheduler = torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer, T_0=20, eta_min=1e-9)
# 7. 训练参数封装
trainpara = {
'model': model,
'train_loader': train_loader,
'val_loader': val_loader,
'scheduler': scheduler,
'optimizer': optimizer,
'learning_rate': learning_rate,
'warmup_ratio' : 0.1,
'weight_decay' : 0.0001,
'use_lookahead' : True,
'loss': loss,
'epoch': epoch,
'device': device,
'save_path': save_path,
'max_acc': 0.85, # 初始最高验证准确率阈值
'val_epoch' : 1 # 每1轮验证一次模型性能
}
# 8. 启动训练
train_val(trainpara)3.5.2 核心设计要点
- 随机种子固定 :
seed_everything函数通过固定 PyTorch、NumPy、Python 等所有随机源的种子,保证实验结果可复现------多次运行相同代码能得到完全一致的训练结果,是科研与工程实验的标准操作。 - 超参数配置 :
- 学习率选择
1e-4:BERT 预训练模型微调时,学习率不宜过大(避免破坏预训练权重),1e-4 是中文 BERT 分类任务的经典取值; - 批次大小
batchSize=4:根据 GPU 显存调整,显存充足时可增大至 8/16,提升训练效率; - 损失函数选择
CrossEntropyLoss:适配二分类任务,自动整合log_softmax与nll_loss,无需手动计算概率。
- 学习率选择
- 优化器与调度器 :
AdamW:带权重衰减的 Adam 优化器,能有效防止过拟合,是 Transformer 模型的标配优化器;CosineAnnealingWarmRestarts:余弦退火调度器,通过周期性降低并重启学习率,让模型在训练后期更易收敛到最优解。
- 模块化封装 :
将所有训练参数封装为字典trainpara,便于参数管理与后续扩展(如添加新参数无需修改train_val函数定义)。
3.6 模块协作与工程流程
整个项目的数据流与模块协作如下:
- 环境初始化 :
main.py固定随机种子,配置超参数与路径; - 数据层 :
data.py读取酒店评价数据,完成初步清洗、采样与划分,封装为DataLoader提供批量输入; - 模型层 :
model.py基于预训练 BERT 构建二分类模型,实现文本到情感标签的映射; - 训练层 :
train.py控制训练-验证循环,更新模型参数,记录指标并保存最优模型; - 调度层 :
main.py整合所有模块,启动训练流程并输出可视化结果。
通过这套工程化代码,我们可以高效完成酒店评价情感分析任务,同时保留了 BERT 模型的强大语义表征能力,在中文文本分类任务中取得优异表现。
3.7 关键优化建议
- 显存优化 :若显存不足,可将
max_length从 128 降至 64,或减小batchSize至 2; - 训练稳定性:可对 BERT 底层参数进行冻结(如冻结前 6 层),仅训练上层与分类头,减少可训练参数;
- 过拟合缓解 :在分类头中添加
nn.Dropout(0.1),降低过拟合风险; - 评估指标:除准确率外,可添加 F1-score、混淆矩阵等指标,更全面评估二分类模型性能。