论文信息
- 标题:BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
- 会议:ICML 2023
- 单位:Salesforce Research
- 代码:https://github.com/salesforce/LAVIS/tree/main/projects/blip2
- 论文:https://arxiv.org/pdf/2301.12597.pdf
引言:多模态大模型的"算力焦虑"
想象一下,你想训练一个能看懂图片又能说会道的AI,但发现需要同时训练一个10亿参数的视觉模型和一个70亿参数的语言模型,这得花多少电费?2023年之前的多模态预训练就是这么烧钱------所有模型都要端到端从头训练,算力成本高得离谱,普通实验室根本玩不起。
更气人的是,视觉和语言领域早就有了现成的顶级预训练模型:CLIP能精准识别图片,GPT能写小说。为什么不能直接把它们拼起来用呢?之前的尝试都失败了,因为模态鸿沟太大了------语言模型从来没见过图片,根本看不懂视觉特征是什么意思。
BLIP-2的作者们想出了一个天才的解决方案:让两个大模型都冻住不动,只训练一个小小的"翻译官" 。这个翻译官叫Q-Former(查询转换器),它能把视觉模型输出的"外星语"翻译成语言模型能听懂的"人话"。这样一来,我们只需要训练188M参数,就能得到一个比Flamingo-80B还强的多模态模型,算力成本直接降低了54倍!
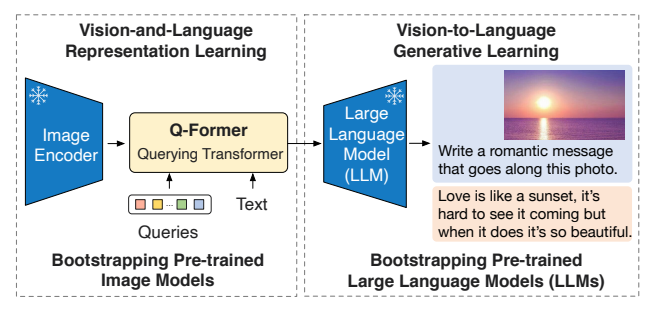
图片1:BLIP-2整体框架
出处:论文图1
BLIP-2的核心思想是"站在巨人的肩膀上":
- 冻结现成的图像编码器(如CLIP ViT-L/14),利用它强大的视觉理解能力
- 冻结现成的大语言模型(如OPT、FlanT5),利用它强大的语言生成和推理能力
- 训练一个轻量级的Q-Former来桥接两个模态,让它们能顺畅交流
一、Q-Former:多模态世界的翻译官
Q-Former是BLIP-2的灵魂,它是一个只有188M参数的轻量级Transformer,却能完成看似不可能的任务------把257×1024维的视觉特征压缩成32×768维的"语言友好型"特征。
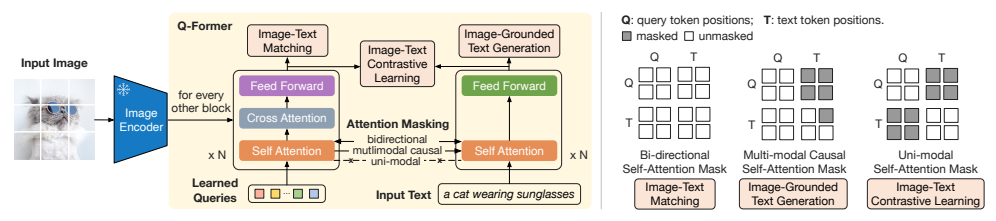
图片2:Q-Former架构与第一阶段预训练目标
出处:论文图2
1.1 Q-Former的结构
Q-Former由两个共享自注意力层的Transformer子模块组成:
- 图像Transformer:负责与冻结的图像编码器交互,提取视觉特征
- 文本Transformer:负责处理文本输入,既能当编码器也能当解码器
最巧妙的设计是可学习的查询向量(Learned Queries):我们初始化32个查询向量,让它们通过自注意力互相交流,再通过交叉注意力"询问"图像特征。这就像给翻译官32个问题,让它带着这些问题去看图片,然后把答案整理成语言模型能懂的格式。
通俗解释:想象你是一个翻译官,要把一本中文书翻译成英文。你不需要逐字逐句翻译,只需要提取书中最重要的32个核心观点,然后用英文把这些观点表达出来。Q-Former做的就是这件事------它从图像中提取最关键的32个信息点,然后传给语言模型。
1.2 第一阶段:先学"看图识字"
在第一阶段,我们把Q-Former连接到冻结的图像编码器上,用图文对训练它学会提取与文本相关的视觉特征。我们同时优化三个目标,每个目标用不同的注意力掩码来控制查询和文本的交互:
目标1:图像-文本对比损失(ITC)
ITC损失让匹配的图文对在特征空间里靠得更近,不匹配的离得更远。我们用单模态自注意力掩码,让查询和文本互相看不到对方,这样它们只能各自编码自己的信息。
公式1:ITC损失
Litc=12E(I,T)∼DH(yi2t,pi2t)+H(yt2i,pt2i)\mathcal{L}{itc} = \frac{1}{2} \mathbb{E}{(I, T) \sim D} \left H(y\^{i2t}, p\^{i2t}) + H(y\^{t2i}, p\^{t2i}) \\rightLitc=21E(I,T)∼DH(yi2t,pi2t)+H(yt2i,pt2i)
- Litc\mathcal{L}_{itc}Litc:ITC总损失,是图像到文本和文本到图像损失的平均值
- HHH:交叉熵损失函数
- yi2ty^{i2t}yi2t:图像III对应的真实文本的one-hot标签
- pi2tp^{i2t}pi2t:模型预测的图像III对应各个文本的概率分布
- yt2iy^{t2i}yt2i:文本TTT对应的真实图像的one-hot标签
- pt2ip^{t2i}pt2i:模型预测的文本TTT对应各个图像的概率分布
目标2:图像-文本匹配损失(ITM)
ITM损失让模型学会判断一个图文对是否匹配。我们用双向自注意力掩码,让查询和文本能互相看到对方,这样它们能融合成多模态特征。
公式2:ITM损失
Litm=E(I,T)∼DH(yitm,pitm(I,T))\mathcal{L}{itm} = \mathbb{E}{(I, T) \sim D} H(y^{itm}, p^{itm}(I, T))Litm=E(I,T)∼DH(yitm,pitm(I,T))
- Litm\mathcal{L}_{itm}Litm:ITM损失
- yitmy^{itm}yitm:图文对的真实标签(匹配为1,不匹配为0)
- pitm(I,T)p^{itm}(I, T)pitm(I,T):模型预测的图文对匹配的概率
目标3:图像引导的文本生成损失(ITG)
ITG损失让Q-Former学会根据图像生成文本。我们用多模态因果自注意力掩码:查询能看到所有其他查询,但看不到文本;每个文本token能看到所有查询和它前面的文本token。
公式3:ITG损失
Litg=E(I,T)∼DH(yitg,pitg(I,T))\mathcal{L}{itg} = \mathbb{E}{(I, T) \sim D} H(y^{itg}, p^{itg}(I, T))Litg=E(I,T)∼DH(yitg,pitg(I,T))
- Litg\mathcal{L}_{itg}Litg:ITG损失
- yitgy^{itg}yitg:真实文本的token序列
- pitg(I,T)p^{itg}(I, T)pitg(I,T):模型自回归生成的token概率分布
通俗解释:这三个目标就像给翻译官安排的三门课程:
- ITC:让翻译官知道"猫"这个词对应猫的图片
- ITM:让翻译官知道"一只猫在睡觉"和狗的图片不匹配
- ITG:让翻译官学会看着图片写出"一只猫在睡觉"这句话
1.3 第二阶段:再学"看图说话"
在第二阶段,我们把训练好的Q-Former连接到冻结的大语言模型上,让它学会把视觉特征翻译成语言模型能懂的格式。
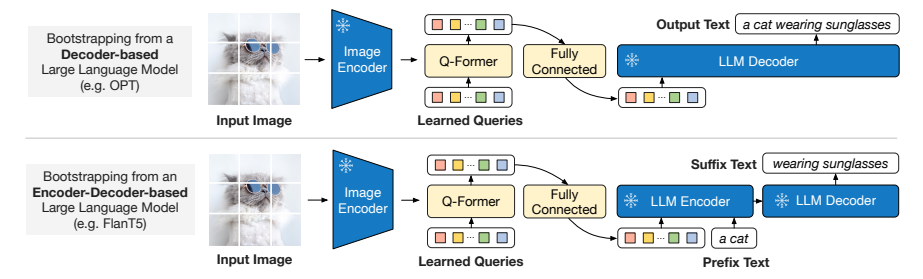
图片3:第二阶段预训练架构
出处:论文图3
具体步骤:
- 用一个全连接层把Q-Former输出的32×768维特征投影到和LLM词嵌入相同的维度
- 把投影后的视觉特征作为软视觉提示,拼接到输入文本的前面
- 用语言建模损失训练Q-Former,让LLM能根据视觉提示生成正确的文本
我们支持两种类型的LLM:
- 解码器型LLM(如OPT):用标准的语言建模损失,让LLM自回归生成文本
- 编码器-解码器型LLM(如FlanT5):用前缀语言建模损失,把文本分成前缀和后缀,前缀和视觉提示一起输入编码器,后缀作为解码器的生成目标
通俗解释:这就像教翻译官用英文把刚才提取的32个核心观点写成一篇通顺的文章。翻译官不需要重新学英文,只需要学会怎么把这些观点组织成英文句子就行。
二、实验结果:用最少的参数打最好的仗
BLIP-2在多个下游任务上都取得了state-of-the-art的结果,而且只用了比之前模型少得多的可训练参数。
2.1 零样本VQA:54倍参数碾压Flamingo-80B
表格1:零样本VQA结果对比
| Models | #Trainable Params | VQAv2 test-dev | OK-VQA test | GQA test-dev |
|---|---|---|---|---|
| Flamingo80B | 10.2B | 56.3 | 50.6 | - |
| BLIP-2 ViT-g FlanT5 XXL | 108M | 65.0 | 45.9 | 44.7 |
| 出处:论文表2 |
分析:BLIP-2只用了108M可训练参数,就比Flamingo-80B在VQAv2上高出8.7%!这相当于用一个手机的算力打败了一台超级计算机。而且BLIP-2用的FlanT5-XXL只有11B参数,比Flamingo用的70B Chinchilla小多了。
2.2 图像描述:零样本超越微调模型
表格2:零样本图像描述结果(NoCaps)
| Models | #Trainable Params | Overall CIDEr | Overall SPICE |
|---|---|---|---|
| BLIP | 583M | 113.2 | 14.8 |
| BLIP-2 ViT-g FlanT5 XL | 107M | 121.6 | 15.8 |
| 出处:论文表1 |
分析:BLIP-2在零样本设置下就超过了之前微调的BLIP模型,这说明它学到的视觉语言表征具有极强的泛化能力。
2.3 图文检索:刷新所有记录
表格3:零样本图文检索结果(Flickr30K)
| Models | #Trainable Params | TR@1 | IR@1 |
|---|---|---|---|
| BEIT-3 | 1.9B | 94.9 | 81.5 |
| BLIP | 446M | 96.7 | 86.7 |
| BLIP-2 ViT-g | 1.2B | 97.6 | 89.7 |
| 出处:论文表5 |
分析:BLIP-2在图文检索任务上也全面超越了之前的state-of-the-art方法,包括用1.9B参数训练的BEIT-3。
2.4 消融实验:两阶段训练缺一不可
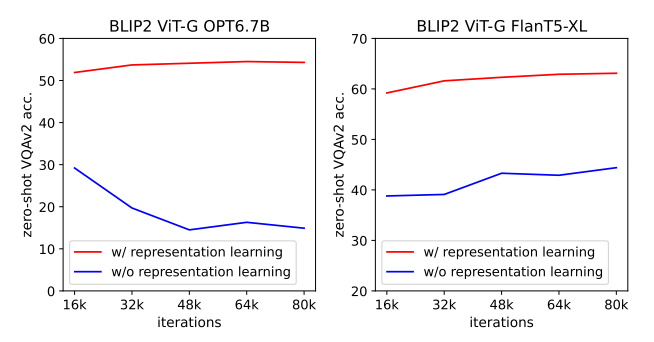
图片4:第一阶段预训练的重要性
出处:论文图5
分析:如果跳过第一阶段的表示学习,直接用第二阶段的生成损失训练Q-Former,性能会大幅下降。特别是对于OPT模型,还会出现灾难性遗忘------训练越久,性能越差。这说明第一阶段的预训练是必不可少的,它让Q-Former先学会提取与语言相关的视觉特征,减轻了第二阶段的对齐负担。
三、核心代码实现
下面是Q-Former的核心代码实现,包括第一阶段的三个预训练损失:
python
import torch
import torch.nn as nn
import torch.nn.functional as F
from transformers import BertModel, BertTokenizer, ViTModel, ViTFeatureExtractor, AutoModelForCausalLM, AutoTokenizer
class QFormer(nn.Module):
def __init__(self, num_queries=32, hidden_size=768, num_layers=12, num_heads=12):
super().__init__()
self.num_queries = num_queries
self.hidden_size = hidden_size
# 可学习的查询向量
self.queries = nn.Parameter(torch.randn(1, num_queries, hidden_size))
# 初始化BERT作为Q-Former的基础
self.bert = BertModel.from_pretrained('bert-base-uncased', add_pooling_layer=False)
# 交叉注意力层(每隔一个Transformer块插入一个)
self.cross_attention_layers = nn.ModuleList([
nn.MultiheadAttention(hidden_size, num_heads, batch_first=True)
for _ in range(num_layers // 2)
])
# 投影层,用于ITC损失
self.vision_proj = nn.Linear(hidden_size, hidden_size)
self.text_proj = nn.Linear(hidden_size, hidden_size)
# ITM分类头
self.itm_head = nn.Linear(hidden_size, 2)
# LM头,用于ITG损失
self.lm_head = nn.Linear(hidden_size, self.bert.config.vocab_size)
def forward(self, image_embeds, input_ids=None, attention_mask=None, task='itc'):
batch_size = image_embeds.size(0)
# 扩展查询向量到batch_size
queries = self.queries.expand(batch_size, -1, -1)
# 根据不同任务应用不同的注意力掩码
if task == 'itc':
# 单模态掩码:查询和文本互相看不到
query_attention_mask = torch.ones(batch_size, self.num_queries, device=image_embeds.device)
text_attention_mask = attention_mask
# 编码查询
query_outputs = self.bert(
inputs_embeds=queries,
attention_mask=query_attention_mask,
output_hidden_states=True
)
query_embeds = query_outputs.last_hidden_state
# 交叉注意力
for i, cross_attn in enumerate(self.cross_attention_layers):
layer_idx = 2 * i + 1
hidden_states = query_outputs.hidden_states[layer_idx]
attn_output, _ = cross_attn(hidden_states, image_embeds, image_embeds)
query_embeds = query_embeds + attn_output
# 编码文本
text_outputs = self.bert(
input_ids=input_ids,
attention_mask=text_attention_mask,
output_hidden_states=True
)
text_embeds = text_outputs.last_hidden_state[:, 0, :]
return query_embeds, text_embeds
elif task == 'itm':
# 双向掩码:查询和文本能互相看到
combined_embeds = torch.cat([queries, self.bert.embeddings(input_ids)], dim=1)
combined_attention_mask = torch.cat([
torch.ones(batch_size, self.num_queries, device=image_embeds.device),
attention_mask
], dim=1)
# 编码
outputs = self.bert(
inputs_embeds=combined_embeds,
attention_mask=combined_attention_mask,
output_hidden_states=True
)
combined_embeds = outputs.last_hidden_state
# 交叉注意力
for i, cross_attn in enumerate(self.cross_attention_layers):
layer_idx = 2 * i + 1
hidden_states = outputs.hidden_states[layer_idx]
query_hidden = hidden_states[:, :self.num_queries, :]
attn_output, _ = cross_attn(query_hidden, image_embeds, image_embeds)
combined_embeds[:, :self.num_queries, :] = combined_embeds[:, :self.num_queries, :] + attn_output
return combined_embeds[:, :self.num_queries, :]
elif task == 'itg':
# 因果掩码:查询能看到所有查询,文本能看到所有查询和前面的文本
seq_length = input_ids.size(1)
causal_mask = torch.tril(torch.ones((self.num_queries + seq_length, self.num_queries + seq_length), device=image_embeds.device))
causal_mask[:, :self.num_queries] = 1 # 所有位置都能看到查询
combined_embeds = torch.cat([queries, self.bert.embeddings(input_ids)], dim=1)
# 编码
outputs = self.bert(
inputs_embeds=combined_embeds,
attention_mask=causal_mask,
output_hidden_states=True
)
combined_embeds = outputs.last_hidden_state
# 交叉注意力
for i, cross_attn in enumerate(self.cross_attention_layers):
layer_idx = 2 * i + 1
hidden_states = outputs.hidden_states[layer_idx]
query_hidden = hidden_states[:, :self.num_queries, :]
attn_output, _ = cross_attn(query_hidden, image_embeds, image_embeds)
combined_embeds[:, :self.num_queries, :] = combined_embeds[:, :self.num_queries, :] + attn_output
return combined_embeds[:, self.num_queries:, :]
def itc_loss(self, query_embeds, text_embeds):
"""计算图像-文本对比损失"""
# 取每个查询与文本的最大相似度作为图像-文本相似度
query_proj = F.normalize(self.vision_proj(query_embeds), dim=-1)
text_proj = F.normalize(self.text_proj(text_embeds), dim=-1)
sim_i2t = torch.max(query_proj @ text_proj.T, dim=1)[0]
sim_t2i = torch.max(text_proj @ query_proj.transpose(1, 2), dim=1)[0]
logits_i2t = sim_i2t * torch.exp(self.logit_scale)
logits_t2i = sim_t2i * torch.exp(self.logit_scale)
labels = torch.arange(logits_i2t.size(0), device=logits_i2t.device)
loss_i2t = F.cross_entropy(logits_i2t, labels)
loss_t2i = F.cross_entropy(logits_t2i, labels)
return (loss_i2t + loss_t2i) / 2
def itm_loss(self, query_embeds, labels):
"""计算图像-文本匹配损失"""
logits = self.itm_head(query_embeds).mean(dim=1)
return F.cross_entropy(logits, labels)
def itg_loss(self, text_embeds, labels):
"""计算图像引导的文本生成损失"""
logits = self.lm_head(text_embeds)
return F.cross_entropy(logits.view(-1, logits.size(-1)), labels.view(-1))
class BLIP2(nn.Module):
def __init__(self, vit_name='openai/clip-vit-large-patch14', llm_name='facebook/opt-2.7b'):
super().__init__()
# 冻结的图像编码器
self.vision_encoder = ViTModel.from_pretrained(vit_name)
for param in self.vision_encoder.parameters():
param.requires_grad = False
# Q-Former
self.qformer = QFormer()
# 冻结的大语言模型
self.llm = AutoModelForCausalLM.from_pretrained(llm_name)
for param in self.llm.parameters():
param.requires_grad = False
# 投影层,将Q-Former输出投影到LLM词嵌入维度
self.proj = nn.Linear(self.qformer.hidden_size, self.llm.config.hidden_size)
# 温度参数
self.logit_scale = nn.Parameter(torch.ones([]) * torch.log(torch.tensor(1.0 / 0.07)))
def forward_vision(self, images):
"""编码图像"""
with torch.no_grad():
vision_outputs = self.vision_encoder(images)
return vision_outputs.last_hidden_state
def forward_stage1(self, images, input_ids, attention_mask, labels_itm=None, labels_itg=None):
"""第一阶段预训练"""
image_embeds = self.forward_vision(images)
# 计算ITC损失
query_embeds, text_embeds = self.qformer(image_embeds, input_ids, attention_mask, task='itc')
loss_itc = self.qformer.itc_loss(query_embeds, text_embeds)
# 计算ITM损失
itm_embeds = self.qformer(image_embeds, input_ids, attention_mask, task='itm')
loss_itm = self.qformer.itm_loss(itm_embeds, labels_itm)
# 计算ITG损失
itg_embeds = self.qformer(image_embeds, input_ids, attention_mask, task='itg')
loss_itg = self.qformer.itg_loss(itg_embeds, labels_itg)
# 总损失
loss = loss_itc + loss_itm + loss_itg
return loss
def forward_stage2(self, images, input_ids, attention_mask, labels):
"""第二阶段预训练"""
image_embeds = self.forward_vision(images)
# 用Q-Former提取视觉特征
query_embeds, _ = self.qformer(image_embeds, task='itc')
query_proj = self.proj(query_embeds)
# 拼接视觉提示和文本嵌入
text_embeds = self.llm.get_input_embeddings()(input_ids)
inputs_embeds = torch.cat([query_proj, text_embeds], dim=1)
# 扩展注意力掩码
attention_mask = torch.cat([
torch.ones(inputs_embeds.size(0), query_proj.size(1), device=inputs_embeds.device),
attention_mask
], dim=1)
# 扩展标签
labels = torch.cat([
torch.full((inputs_embeds.size(0), query_proj.size(1)), -100, device=labels.device),
labels
], dim=1)
# 计算LM损失
outputs = self.llm(
inputs_embeds=inputs_embeds,
attention_mask=attention_mask,
labels=labels
)
return outputs.loss四、神奇的零样本指令生成
BLIP-2最令人惊艳的能力是零样本指令引导的图像到文本生成 。你可以用自然语言给它下指令,让它完成各种任务,比如:

图片5:零样本指令生成示例
出处:论文图4
从图中可以看到,BLIP-2能完成:
- 视觉知识推理:"告诉我关于这朵花的事实" → "它是兰科兰花属的开花植物,原产于东亚和东南亚"
- 产品描述:"解释这个产品的优势" → "奥迪e-tron quattro概念车是一款插电式混合动力跑车,续航310英里,0-60英里加速仅需4秒"
- 历史知识:"告诉我这个地方的历史" → "中国长城建于公元前221年,由秦始皇建造,用于保护首都免受北方入侵者的攻击"
- 创意写作:"写一句配这张照片的浪漫文案" → "爱情就像日落,你很难预见它的到来,但当它来临时,是如此美丽"
当然,BLIP-2也不是完美的,它也会犯一些错误:
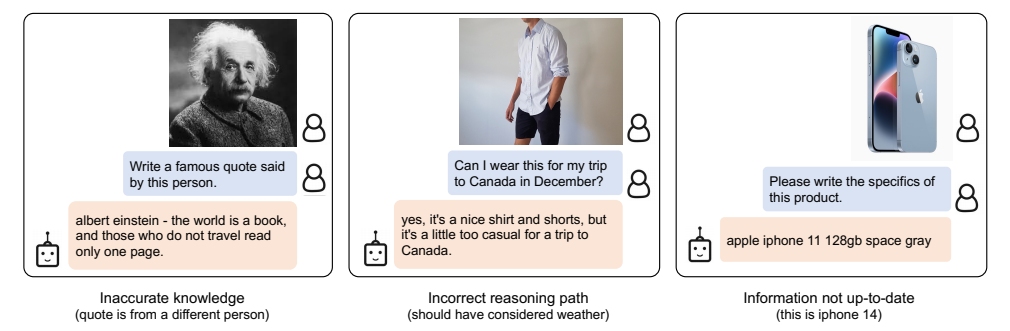
图片6:错误示例
出处:论文图6
这些错误主要来自三个方面:
- 知识不准确:把圣奥古斯丁的名言安在了爱因斯坦头上
- 推理错误:没有考虑加拿大12月的天气,说可以穿衬衫短裤去旅行
- 信息过时:把iPhone 14认成了iPhone 11
这些问题其实不是BLIP-2的错,而是它继承了冻结LLM的局限性。如果我们用更新、更强的LLM,这些问题都会得到改善。
五、总结与未来方向
BLIP-2是多模态预训练领域的一个里程碑式的工作,它的主要贡献有三点:
- 高效性:冻结两个预训练大模型,只训练188M参数的Q-Former,算力成本降低了54倍
- 通用性:可以接入任何现成的图像编码器和LLM,轻松享受单模态领域的最新进展
- 强大性能:在多个下游任务上取得state-of-the-art结果,特别是零样本能力远超之前的模型
未来的研究方向包括:
- 多轮数据集:创建包含多轮图文交互的数据集,让BLIP-2具备上下文学习能力
- 更强的单模态模型:接入更新、更强的图像编码器(如ViT-G)和LLM(如GPT-4)
- 多模态对话:将BLIP-2扩展到多轮对话场景,打造真正的多模态对话AI
BLIP-2证明了**"冻结+轻量级桥接"**是一种非常有前途的多模态预训练范式。它让普通实验室也能训练出顶级的多模态模型,大大降低了多模态研究的门槛。未来,我们可能会看到更多基于这种范式的创新,让AI真正具备看懂世界、理解人类的能力。