FQ-ViT: Post-Training Quantization for Fully Quantized Vision Transformer
文章目录
- 摘要
- [1 Introduction](#1 Introduction)
- [2 Related Work](#2 Related Work)
-
- [2.1 Vision Transformer](#2.1 Vision Transformer)
- [2.2 Network Quantization](#2.2 Network Quantization)
-
- 高水平的专家知识
- [为什么作者要强调 "expert knowledge"?](#为什么作者要强调 “expert knowledge”?)
- [3 Proposed Method](#3 Proposed Method)
-
- [3.1 Preliminary](#3.1 Preliminary)
- [3.2 Power-of-Two Factor for LayerNorm Quantization](#3.2 Power-of-Two Factor for LayerNorm Quantization)
-
- [3.2.1. BatchNorm 的计算公式](#3.2.1. BatchNorm 的计算公式)
- [3.2.2. 训练阶段 vs. 推理阶段](#3.2.2. 训练阶段 vs. 推理阶段)
- [3.2.那推理时"用 batch 统计行不行?"](#3.2.那推理时“用 batch 统计行不行?”)
- [3.2.4. 数学推导:如何折叠?](#3.2.4. 数学推导:如何折叠?)
- [为什么 LayerNorm 不能折叠?](#为什么 LayerNorm 不能折叠?)
-
- [Phase 1: 利用 PTF 进行移位 (Shift)](#Phase 1: 利用 PTF 进行移位 (Shift))
- [Phase 2: 基于移位后激活值计算均值和方差](#Phase 2: 基于移位后激活值计算均值和方差)
- [3.3 Log-Int-Softmax for Softmax Quantization](#3.3 Log-Int-Softmax for Softmax Quantization)
-
- [题外话:softmax可以直接Uniform 量化到 int8 吗?](#题外话:softmax可以直接Uniform 量化到 int8 吗?)
- [3.4 Integer-only Inference](#3.4 Integer-only Inference)
- [补充: i-exp算法](#补充: i-exp算法)
- [补充2:Log2 函数](#补充2:Log2 函数)
-
- [2. 逐句解析与示例分析](#2. 逐句解析与示例分析)
- [5 结论](#5 结论)
摘要
网络量化显著降低了模型推理复杂度,并已在实际部署中得到广泛应用。然而,大多数现有的量化方法主要面向卷积神经网络(CNNs)开发,在应用于完全量化的视觉Transformer时,会出现严重的性能退化。在本工作中,
- 我们证明这些困难很大程度上源于LayerNorm输入中的严重信道间差异,并提出了"二的幂次因子"(Power-of-Two Factor, PTF)这一系统方法,以降低完全量化视觉Transformer的性能退化和推理复杂度。
- 此外,鉴于注意到注意力图中存在极端非均匀分布,我们提出了Log-Int-Softmax(LIS)方法,通过采用4位量化和BitShift操作来保持其特性并简化推理过程。
在各种基于Transformer的架构和基准测试上的综合实验表明,我们的完全量化视觉Transformer(FQ-ViT)在注意力图使用更低比特宽度的情况下,仍优于以往的工作。例如,我们在ImageNet上以ViT-L达到84.89%的top-1准确率,在COCO上以Cascade Mask R-CNN (Swin-S) 达到50.8 mAP。据我们所知,我们是首个在完全量化视觉Transformer上实现近乎无损精度退化(约1%)的研究。代码已开源,地址为 https://github.com/megvii-research/FQ-ViT。
1 Introduction
ViT-L 拥有 3.07 亿参数和 190.7G FLOPs,在大规模预训练下于 ImageNet 上达到了 87.76% 的准确率。然而,基于 Transformer 的架构庞大的参数数量和计算开销,在部署到资源受限的硬件设备时构成了挑战。
为便于部署,人们提出了多种技术,包括
- 量化 Zhou 等,2016;Nagel 等,2020;Shen 等,2020;Liu 等,2021b、
- Liu et al., 2021b. Post-training quantization for vision transformer.
- Shen et al., 2020 Q-bert: Hessian based ultra low precision quantization of bert.
- 剪枝 Han 等,2016、
- 知识蒸馏 Jiao 等,2020
- Jiao et al., 2020 Tinybert:Distilling BERT for natural language understanding.
- 架构设计的适配 Graham 等,2021。
- Graham et al., 2021 Levit: a vision transformer in convnet's clothing for faster
inference.
- Graham et al., 2021 Levit: a vision transformer in convnet's clothing for faster
先前的工作 Liu 等, 2021b 发现,在量化视觉 Transformer 中的 LayerNorm 和 Softmax 时,会出现显著的精度下降。
- Liu et al., 2021b Post-training quantization forvision transformer.
首先,我们注意到LayerNorm输入存在严重的通道间变异 ,某些通道范围甚至超过中位数的40倍。传统方法无法处理这种剧烈的激活波动,会导致较大的量化误差。
其次,我们观察到注意力图的值具有极端非均匀分布,大部分值集中在0~0.01区间,而少数高注意力值接近1。
基于上述分析,我们提出:
- 幂之二因子(Power-of-Two Factor, PTF)方法对 LayerNorm 的输入进行量化。该方法显著降低了量化误差,同时得益于移位(BitShift)操作,整体计算效率与逐层量化相当。
- 此外,我们提出对数整数 Softmax(Log-Int-Softmax, LIS),该方法对小值提供更高的量化分辨率,并为 Softmax 实现更为高效的整数推理。
结合上述方法,我们成为首个实现全量化视觉 Transformer 的后训练量化(post-training quantization)工作的团队。
如图 1 所示,我们的方法显著提升了全量化视觉 Transformer 的性能,并获得了与全精度模型相当 accuracy。
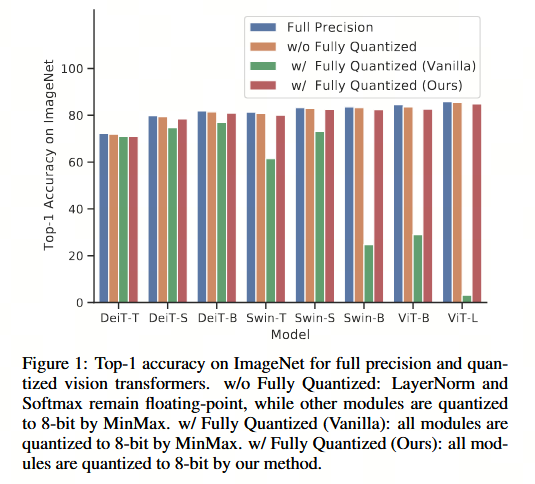
2 Related Work
2.1 Vision Transformer
新近提出的 Swin Transformer Liu 等, 2021a 在绝大多数传统计算机视觉任务上甚至超越了最先进(state-of-the-art)的卷积神经网络(CNNs),充分展现了 Transformer 强大的表达能力和泛化性能。
Le-ViT Graham et al., 2021 通过下采样、补丁描述符以及注意力-MLP 模块的重构,在提升推理速度方面取得了进展。DynamicViT Rao et al., 2021 提出了一种动态令牌稀疏化框架,用于渐进且动态地剪枝冗余令牌,实现了具有竞争力的复杂度与准确率权衡。Evo-ViT Xu et al., 2021 提出了一种慢快更新机制,以保障信息流动与空间结构,从而同时降低训练和推理的复杂度。上述工作均聚焦于高效模型设计,而本文则在量化的轨道上推动模型的压缩与加速。
2.2 Network Quantization
PTQ (Post-Training Quantization):最快,零训练成本,但精度损失大,通常只支持 8-bit。
QAT (Quantization-Aware Training):慢,高成本,但精度恢复好,支持 8-bit 甚至更低(如 4-bit, 2-bit)。
- 基于量化训练(QAT)Zhou 等人,2016;Jacob 等人,2018 需要通过训练来实现激进的低位宽(例如 2 位)量化并取得良好的性能,但其训练或微调往往需要高水平的专家知识以及大量的 GPU 资源。
高水平的专家知识
在 QAT(Quantization-Aware Training,量化感知训练)语境下,它通常包括:
- 量化位宽与方案设计:比如 2-bit 下如何用分组量化、混合位宽、非对称量化等来尽量减少精度损失。
- 量化感知训练策略:如何在训练/微调中稳定数值、选择量化粒度(per-tensor / per-channel)、如何处理敏感层(如 attention、first/last layer)。
- 梯度近似与反向传播设计:如 straight-through estimator (STE) 的选择与改进,避免梯度 mismatch。
- 调度与超参数经验:量化引入的训练超参数(学习率、量化步数、warm-up、冻结部分参数等)需要凭经验调优。
- 针对模型的定制化:不同模型结构对低比特量化的敏感度不同,需要"专家判断"去改结构或训练方式。
这些都属于"高水平专家知识",而不局限于蒸馏。
为什么作者要强调 "expert knowledge"?
因为:
- 低比特 QAT 不是"跑一个脚本就成功";
- 需要你理解数值行为、训练动态、层间敏感差异,并做出正确决策;
- 这些决策往往来自长期研究/工程积累 → 即 "high-level expert knowledge"。
这两篇论文正是"高水平专家知识"在 QAT 领域的具体体现:它们没有停留在调用 API,而是深入量化训练的数值细节,设计了能让低精度模型稳定收敛并实用的训练方案。
-
Zhou et al., 2016 (DoReFa-Net):激进低比特量化与梯度量化设计
- 任意位宽的统一量化公式与比特分配经验:提出可对权重、激活、梯度分别配置不同位宽(如权重/激活 1~8 bit,梯度 4~8 bit),并指出梯度对量化更敏感、通常需要比激活更高的位宽,这来自对量化误差传播的实验洞察。
- 梯度的随机量化策略:反向传播时对梯度做随机四舍五入(而非 deterministic round),这是一种专家级的训练技巧,用来缓解低比特梯度带来的偏差、提升训练稳定性。
- 前向/后向均采用低比特运算的思路:不仅前向量化权重和激活,还把梯度也量化后再回传,体现了对训练动态与硬件加速(位运算)一并考量的能力。
-
Jacob et al., 2018 (Google QAT):面向部署的量化方案 + 训练流程设计
- 对称均匀 INT8 量化方案与定点推理对齐:权重、激活量化到 8-bit 整数,bias 用 32-bit,并设计量化参数(scale/zero-point)使得推理可用纯整数算术(integer-only arithmetic),这需要专家对硬件指令集与数值范围约束的理解。
- Fake quantization(模拟量化)插入训练流:在训练前向插入"量化-反量化"操作,让模型在优化时"看到"量化误差,从而学出对量化更鲁棒的权重;同时反向多使用 STE 处理不可导问题,属于 QAT 的经典专家实践。
- 与推理框架协同设计(部署导向):量化方案不是只追求训练指标,而是和移动 CPU(如 ARM)推理实现一起打磨,以保证端侧延迟与精度的实际 trade-off 可控。
一句话总结:Zhou 2016 体现的是"怎么在极低比特下仍能让训练成立 (量化公式、梯度量化、随机_round)";Jacob 2018 体现的是"怎么把 QAT 做成可落地的工业方案(整数推理对齐、fake quant 流程、部署协同)"。
为降低上述量化成本,无需训练的基于量化训练后量化(PTQ)受到了更广泛的关注,并涌现出许多优秀的工作。
- OMSE Choukroun 等人,2019 提出通过最小化量化误差来确定激活值的取值范围。
- AdaRound Nagel 等人,2020 提出了一种新颖的舍入机制,以适配数据和任务损失。
- 除了上述针对卷积神经网络(CNNs)的工作外,Liu 等人提出了一种针对视觉Transformer的基于训练后量化方法,该方法采用了相似性感知和秩感知策略。然而,该工作并未对 Softmax 和 Layer-Norm 模块进行量化,导致量化不完整。
在我们的 FQ-ViT 中,我们旨在在 PTQ 范式下实现一个准确且完全量化的视觉Transformer。
3 Proposed Method
3.1 Preliminary
假设量化位宽为 b b b,量化器 Q ( X ∣ b ) Q(X|b) Q(X∣b) 可表述为一种映射函数,它将浮点数 X ∈ R X \in \mathbb{R} X∈R 映射至最近的量化区间。
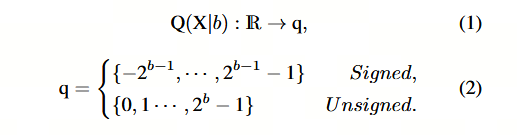
存在多种量化器 Q(X|b),其中均匀量化 Jacob 等, 2018 和 log2 量化 Cai 等, 2018 通常被采用。

在本文中,为了实现全量化的视觉Transformer,我们对所有模块进行了量化,包括卷积(Conv)、线性层(Linear)、矩阵乘法(MatMul)、层归一化(LayerNorm)和Softmax等。特别地,针对卷积、线性和矩阵乘法模块,我们采用均匀的最小-最大(Min-Max)量化方法;而对于层归一化和Softmax模块,则采用我们后续提出的方法。
3.2 Power-of-Two Factor for LayerNorm Quantization
在推理阶段,LayerNorm Ba 等,2016 在每个前向步骤中计算统计量 μ X \mu_X μX 和 σ X \sigma_X σX,并对输入 X X X 进行归一化。随后,仿射参数 γ \gamma γ 和 β \beta β 将归一化后的输入重新缩放至另一学习分布。上述过程可表示为:
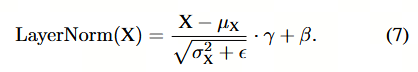
与卷积神经网络中常用的批量归一化(BatchNorm)Ioffe 和 Szegedy, 2015 不同,由于层归一化(LayerNorm)具有动态计算特性,无法将其折叠到前一层中,因此必须对其进行单独量化。
BatchNorm(批量归一化)之所以可以"折叠"(Fold)到前一层(通常是卷积层 Conv 或线性层 Linear)中,根本原因在于它的统计参数是静态的(Static),且计算过程可以转化为线性变换。
3.2.1. BatchNorm 的计算公式
在推理阶段(Inference Mode),BatchNorm 的公式如下:
x ^ = x − μ σ \hat{x} = \frac{x - \mu}{\sigma} x^=σx−μ
y = γ x ^ + β y = \gamma \hat{x} + \beta y=γx^+β
其中:
- x x x 是输入数据。
- μ \mu μ 是均值, σ \sigma σ 是标准差。
- γ \gamma γ 和 β \beta β 是可学习的仿射参数。
3.2.2. 训练阶段 vs. 推理阶段
-
训练阶段 : μ \mu μ 和 σ \sigma σ 是基于当前 Mini-batch 的数据计算出来的,每个 batch 都不同。因此,无法预先确定这些值,也就无法合并。
PyTorch / TF 还会维护:
moving_mean(滑动均值)
moving_var(滑动方差)`moving_mean = momentum * moving_mean + (1 - momentum) * mu_B
moving_var = momentum * moving_var + (1 - momentum) * sigma_B^2 -
推理阶段 : μ \mu μ 和 σ \sigma σ 使用的是在训练过程中通过"动量法"累计得到的全局统计量(Running Mean 和 Running Variance) 。这些值是固定不变常量。推理阶段"也可以用 batch 统计",但几乎从不这样做。**
3.2.那推理时"用 batch 统计行不行?"
✅ 技术上:完全可以
⚠️ 但这是强烈不推荐的做法。
❌ 为什么不推荐?
1️⃣ batch 太小 → 统计极不可靠
| batch size | 问题 |
|---|---|
| 1 | 方差为 0,直接炸 |
| 2~8 | 噪声巨大 |
| ≥32 | 勉强稳定 |
推理时 batch 往往不可控。
2️⃣ 同一个样本,输出会变
同一张图片:
- 单独推理 → 一个结果
- 换一批一起推理 → 另一个结果
这在生产环境中是 不可接受的 bug。
3.2.4. 数学推导:如何折叠?
由于 μ , σ , γ , β \mu, \sigma, \gamma, \beta μ,σ,γ,β 在推理时都是常数,我们可以将 BatchNorm 的步骤合并为一个单一的线性变换。
假设前一层(如卷积层)的输出是 x x x,其计算过程为 x = W ⋅ i n p u t + b x = W \cdot input + b x=W⋅input+b。
将 BatchNorm 公式展开:
y = γ ( x − μ σ ) + β y = \gamma \left( \frac{x - \mu}{\sigma} \right) + \beta y=γ(σx−μ)+β
y = ( γ σ ) x − ( γ ⋅ μ σ ) + β y = \left( \frac{\gamma}{\sigma} \right) x - \left( \frac{\gamma \cdot \mu}{\sigma} \right) + \beta y=(σγ)x−(σγ⋅μ)+β
令:
- 新的权重 W ′ = γ σ ⋅ W W' = \frac{\gamma}{\sigma} \cdot W W′=σγ⋅W
- 新的偏置 b ′ = γ σ ⋅ b + β − γ ⋅ μ σ b' = \frac{\gamma}{\sigma} \cdot b + \beta - \frac{\gamma \cdot \mu}{\sigma} b′=σγ⋅b+β−σγ⋅μ
那么,整个 Conv + BatchNorm 的操作就可以简化为:
y = W ′ ⋅ i n p u t + b ′ y = W' \cdot input + b' y=W′⋅input+b′
结论 :BatchNorm 的操作被完全吸收进了卷积层的权重 W W W 和偏置 b b b 中。在推理时,不再需要单独执行 BatchNorm 层,从而减少了计算量内存访问。
为什么 LayerNorm 不能折叠?
这与 LayerNorm 在推理阶段的特性相反:
-
动态统计量 :
LayerNorm 的均值 μ X \mu_X μX 和标准差 σ X \sigma_X σX 不是 预训练好的固定值,而是在每一次前向传播时,根据当前输入样本 X X X 动态计算出来的。
-
依赖当前输入 :
公式如下:
μ X = mean ( X ) , σ X = std ( X ) \mu_X = \text{mean}(X), \quad \sigma_X = \text{std}(X) μX=mean(X),σX=std(X)因为 μ X \mu_X μX 和 σ X \sigma_X σX 依赖于 X X X,而 X X X 又是前一层的输出,所以你不能在训练阶段或部署前预先计算出 μ X \mu_X μX 和 σ X 。 \sigma_X。 σX。
-
非线性耦合 :
由于 σ X \sigma_X σX 在分母上,且它随输入变化,LayerNorm 引入了一个非线性的、输入依赖的缩放因子。这个因子无法像常数那样被提取出来合并到前一层权重中。
这就是为什么论文中提到:"Unlike BatchNorm... LayerNorm cannot be folded into the previous layer due to its dynamic computational property, so we have to quantize it separately."(与 BatchNorm 不同,LayerNorm 由于其动态计算特性,无法折叠到前一层,因此我们必须单独对其进行量化。)
考察 LayerNorm 层的输入,我们发现存在严重的通道间变异。图 2 展示了最后一层 LayerNorm 中激活值的通道级范围。此外,我们还展示了 ResNets He et al., 2016 的相应情况以作对比。鉴于 ResNets 中不包含 LayerNorm,我们选择在相同位置(第四阶段的输出)的激活值进行展示。
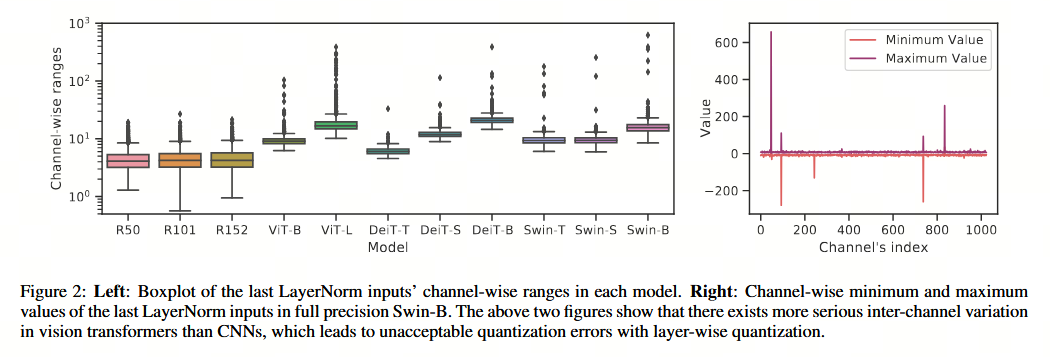
观察发现,视觉 Transformer 中各通道的范围波动比 ResNet 中更为剧烈。例如,ResNet152 的最大范围/中位范围仅为 21.6/4.2,而在 Swin-B 中则高达 622.5/15.5。
- 基于这种极端的通道间差异,层量化(layer-wise quantization,即对所有通道应用相同的量化参数)将导致难以接受的量化误差。
- 一种可能的解决方案是采用组量化(group-wise quantization)Shen 等, 2020 或通道量化(channel-wise quantization)Li 等, 2019,即为不同的组或通道分配不同的量化参数。然而,这些方法仍需在浮点域中计算均值和方差,从而导致较高的硬件开销。
在本文中,我们提出了一种简单而高效的归一化层(LayerNorm)量化方法------二分幂因子法(Power-of-Two Factor,简称 PTF)。PTF 的核心思想是为不同的通道配置不同的因子 ,而非不同的量化参数。
给定量化位宽 b b b、输入激活 X ∈ R B × L × C X \in \mathbb{R}^{B \times L \times C} X∈RB×L×C、逐层量化参数 s , z p ∈ R 1 s, z_p \in \mathbb{R}^1 s,zp∈R1 以及 PTF 参数 α ∈ N C \alpha \in \mathbb{N}^{C} α∈NC,则量化后的激活 X Q X_Q XQ 可表示为:
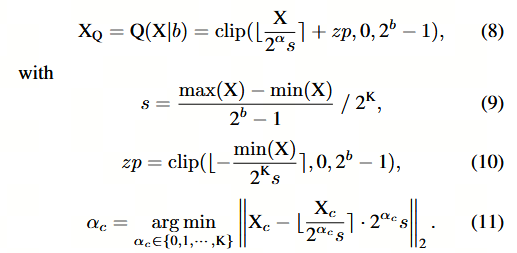
注意到 c c c 表示 X X X 和 α \alpha α 的通道索引。超参数 K K K 可以满足不同的缩放需求。
在此阶段,每个通道均具有其特有的2的幂次因子α以及逐层参数s和zp。在推理过程中,可以提取逐层参数s和zp,从而使得μ和σ的计算可以在整数域而非浮点域中进行,进而降低能耗与面积开销Lian等,2019。与此同时,得益于2的幂次的性质,PTF α可通过位移运算符高效地与逐层量化相结合,从而避免了组级或通道级量化中的浮点运算。整个处理过程可分为两个阶段:
阶段1:利用2的幂次因子α对量化激活值进行移位:
阶段2:基于移位后的激活值̂X_Q计算均值和方差:
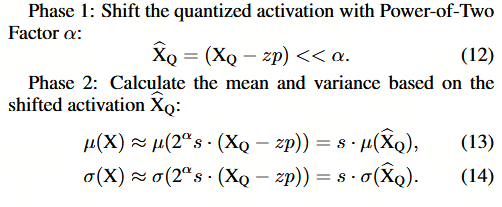
- 通道级/逐层参数 ( s , z p s, z_p s,zp) :
- s s s (Scale, 缩放因子):用于将整数映射回浮点数值范围的系数。
- z p z_p zp (Zero-point, 零点):因为整数范围通常不对称(例如 int8 是 -128 到 127),而浮点数 0 是中心,所以需要引入 z p z_p zp 来对齐整数中的 0 和浮点中的 0。
- 文本提到这些参数是"层-wise"(layer-wise)的,意味着每一层神经网络都有自己的一套 s s s 和 z p z_p zp。
- μ \mu μ 和 σ \sigma σ (均值与标准差) :
这是**批归一化(Batch Normalization, BN)**或类似归一化层的两个核心统计量。归一化旨在消除数据分布偏移,加速训练并提高稳定性。- μ ( X ) \mu(X) μ(X):数据 X X X 的平均值。
- σ ( X ) \sigma(X) σ(X):数据 X X X 的标准差(衡量数据的离散程度)。
- 2的幂次因子 ( α \alpha α, PTF) :
这是一个特殊的缩放参数,它不是任意整数,而是必须是 2 2 2 的整数次幂(例如 2 − 1 , 2 0 , 2 1 , 2 5 2^{-1}, 2^0, 2^1, 2^5 2−1,20,21,25 等)。- **为什么重要?在计算机中,乘以 2 的幂次可以通过简单的 位左移操作(BitShift operator,
<<)**来实现,这比通用的乘法运算快得多,且在硬件上几乎不消耗额外能量。
- **为什么重要?在计算机中,乘以 2 的幂次可以通过简单的 位左移操作(BitShift operator,
原本计算均值 μ \mu μ 和标准差 σ \sigma σ 需要在浮点域进行,这会消耗大量能量。通过提取参数,我们可以直接在整数域(integer domain)进行处理。这直接减少了硬件所需的面积(面积成本)和功耗(能量成本)。
Phase 1: 利用 PTF 进行移位 (Shift)
X ^ Q = ( X Q − z p ) < < α \hat{X}_Q = (X_Q - z_p) << \alpha X^Q=(XQ−zp)<<α
- X Q X_Q XQ:量化后的激活值(整数)。
- X Q − z p X_Q - z_p XQ−zp:首先去除零点偏移,将数据中心对齐。
- < < α << \alpha <<α :将结果左移 α \alpha α 位。
- 关键点 :如果 α \alpha α 是 2 的幂次,这里使用的是位运算 而不是乘法。例如,左移 3 位相当于乘以 2 3 = 8 2^3=8 23=8。这在硬件电路中极其高效。
- 这一步得到的 X ^ Q \hat{X}_Q X^Q 是一个经过缩放和偏移校正的整数数据。
Phase 2: 基于移位后激活值计算均值和方差
μ ( X ) ≈ μ ( 2 α s ⋅ ( X Q − z p ) ) = s ⋅ μ ( X ^ Q ) \mu(X) \approx \mu(2^\alpha s \cdot (X_Q - z_p)) = s \cdot \mu(\hat{X}_Q) μ(X)≈μ(2αs⋅(XQ−zp))=s⋅μ(X^Q)
σ ( X ) ≈ σ ( 2 α s ⋅ ( X Q − z p ) ) = s ⋅ σ ( X ^ Q ) \sigma(X) \approx \sigma(2^\alpha s \cdot (X_Q - z_p)) = s \cdot \sigma(\hat{X}_Q) σ(X)≈σ(2αs⋅(XQ−zp))=s⋅σ(X^Q)
- 数学推导逻辑 :
归一化操作本质上是线性变换。如果我们对数据进行缩放(乘以常数 k k k)和平移,其均值和标准差也会相应地缩放。- 原始浮点数据 X X X 与量化数据的关系大致为: X ≈ s ⋅ ( X Q − z p ) X \approx s \cdot (X_Q - z_p) X≈s⋅(XQ−zp)。
- 但在本方法中,引入了额外的 2 α 2^\alpha 2α 因子。所以实际参与的缩放系数是 k = s ⋅ 2 α k = s \cdot 2^\alpha k=s⋅2α。
- 根据统计学性质:如果 Y = k ⋅ Z Y = k \cdot Z Y=k⋅Z,那么 μ ( Y ) = k ⋅ μ ( Z ) \mu(Y) = k \cdot \mu(Z) μ(Y)=k⋅μ(Z) 且 σ ( Y ) = ∣ k ∣ ⋅ σ ( Z ) \sigma(Y) = |k| \cdot \sigma(Z) σ(Y)=∣k∣⋅σ(Z)。
- 优化结果 :
公式简化为 s ⋅ μ ( X ^ Q ) s \cdot \mu(\hat{X}_Q) s⋅μ(X^Q)。
这意味着我们不需要重新对原始浮点数或复杂的混合数求均值。我们只需要:- 对已经移位的整数 X ^ Q \hat{X}_Q X^Q 求均值 μ ( X ^ Q ) \mu(\hat{X}_Q) μ(X^Q)(这是在整数域做的,很快)。
- 最后再乘以常数 s s s(或者如果 s s s 也被特殊处理,可能也是移位或简单乘法)。
Q1: 公式 (13) 和 (14) 中的近似符号 ( ≈ \approx ≈) 是什么意思?
A: 这表示这是一种工程上的近似或重构。
- 严格来说, μ ( X ) \mu(X) μ(X) 是基于原始浮点数据计算的。
- 而 s ⋅ μ ( X ^ Q ) s \cdot \mu(\hat{X}_Q) s⋅μ(X^Q) 是基于量化整数数据计算后,再乘回缩放因子。
- 由于量化本身就有误差(Lossy),且统计性质在线性变换下是保持的,所以这种转换在数学上是等价的(忽略量化噪声带来的微小偏差)。这里的 ≈ \approx ≈ 更多是指"在量化误差允许的范围内等效"。
Q2: s s s 和 α \alpha α 是如何分工的?
A:
- α \alpha α (PTF):处理主要的数量级缩放,利用位移硬件加速。它是通道级(Channel-wise)或细粒度的,允许不同通道有不同的主要缩放倍率。
- s s s:处理剩余的精细缩放。它是逐层(Layer-wise)的参数。
- 这种分工使得每个通道可以有独特的缩放能力(通过 α \alpha α),但计算过程依然保持极简(通过 s s s 的固定性和 α \alpha α 的位移特性)。
3.3 Log-Int-Softmax for Softmax Quantization
在对注意力图进行量化实验,将其从 8 bits 量化至 4 bits,若采用均匀量化,所有视觉 Transformer 均表现出严重的性能下降。例如,DeiT-T 在使用 4 比特均匀量化的注意力图时,其在 ImageNet 上的 top-1 准确率仅为 8.69%,相较于 8 比特情形下降了 63.05%。
受 DynamicViT Rao et al., 2021 中稀疏注意力思想的启发,我们深入探究了注意力图的分布情况,如图 3 所示。我们观察到注意力值的分布集中于一个较小的数值附近,仅有少量异常值的值较大且接近 1。
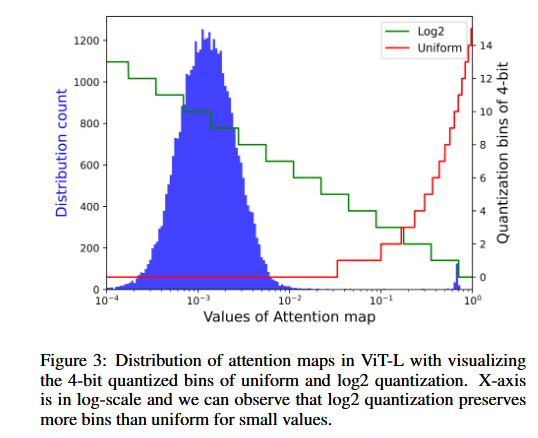
在 ViT-L 的所有注意力图上进行平均统计,约有 98.8% 的值小于 1/16。与 4 位均匀量化方法仅为此类大量值分配 1 个量化区间不同,log2 方法可以为它们分配 12 个区间。
此外,遵循排序感知损失 Liu et al., 2021b 的设计理念,log2 量化能够在全精度与量化后的注意力图之间保留更多的顺序一致性。因此,我们有效避免了注意力图在 4 位量化时的极端性能下降,并在内存占用减少 50% 的情况下,实现了与 8 位均匀量化相当的性能。
对数2(Log2)量化被证明在结合多头自注意力(MSA)方面具有适用性,这源于两个方面的原因。首先,与公式(6)相比,Softmax 的固定输出范围(0, 1)使得log2函数的校准无需额外调整:
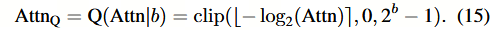
其次,本文还论述了在量化后的注意力图(Attn)与值(V)之间,将矩阵乘法(MatMul)转换为比特右移操作的优点,具体表示为:
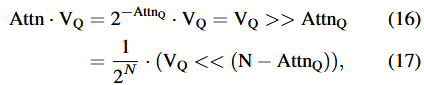
其中 N = 2 b − 1 N = 2^b − 1 N=2b−1。注意到,直接将 VQ 进行右移位操作并与 AttnQ 的结果进行结合,可能会导致严重的截断误差。
使用 (N − AttnQ) 作为量化输出,其缩放因子为 1 / 2 N 1/2^N 1/2N,以确保执行左移操作,从而避免截断误差。
题外话:softmax可以直接Uniform 量化到 int8 吗?
技术上可以量化,但"直接 Uniform INT8"通常精度很差,不建议裸用。
Softmax 的输出值固定在 (0, 1] 区间,且分布极不均匀(大部分值靠近 0,少数靠近 1)。如果用普通的 Uniform INT8(把 0~1 均分成 256 格),会导致:
- 大量微小概率值被舍入成 0(下溢)
- 概率分布失真,影响分类 / Attention 权重,进而明显掉精度
因此工业界常见做法是(按推荐程度):
- 保持 Softmax 在更高精度(FP16 / FP32 或 INT16),只把其他层 INT8(最常见)。
- 非均匀 / 对数域量化(如 Log-Int-Softmax、Log2 量化),给小值更高分辨率,更适合 Softmax 分布。
- 全 integer-only 方案(如 I-BERT):用整数近似 + 整数累加,再做量化,但不是"直接 uniform INT8"。
- 若一定要 direct uniform INT8:通常需要 校准/裁剪/限制范围 + 可能 QAT,否则风险较大。
3.4 Integer-only Inference
结合 log2 量化与 i-exp Kim 等,2021(指数函数的多项式近似),我们提出了 Log-Int-Softmax,这是一种仅基于整数运算、速度更快、资源消耗更低的 Softmax 变体。
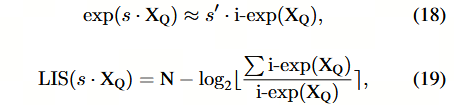
其中 N = 2 b − 1 N = 2^b − 1 N=2b−1。
整数版本的 log2 函数可以通过使用 BitShift 来轻松实现,该方法用于定位值为 1 的最高位索引(我们称之为"查找最高位"函数),并将该位之后紧邻的位的值加到结果中。
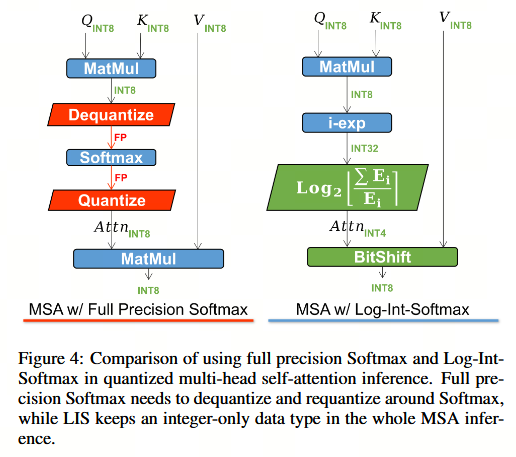
正常 MSA 与我们的方法之间的差异如图 4 所示,图中标注了每个阶段的数据类型。在左侧所示的采用未量化 Softmax 的多头自注意力机制中,查询(Q)与键(K)的矩阵乘法在 Softmax 之前需要反量化至全精度,并在 Softmax 之后重新量化。当采用我们提出的 Log-Int-Softmax 时(如右侧所示),整个数据类型可保持为纯整数,且量化比例可独立并行计算。值得注意的是,LIS 在注意力图上激进地采用 4 位表示,从而显著减小了内存占用。
补充: i-exp算法
I-BERT 采用二阶多项式在区间 p ∈ ( − ln 2 , 0 ] p \in (-\ln 2, 0] p∈(−ln2,0] 上对指数函数进行近似。
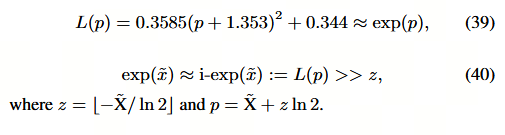

基于 i-exp(算法 1),我们提出 Log-Int-Softmax(LIS),如算法 2 所示。首先,从输入中减去最大值,以确保所有输入均为非正值,然后将结果送入 i-exp。接着,我们用其倒数替换原始 Softmax,以确保整数除法的结果大于 1。最后,我们对反向 Softmax 的输出执行 Log2 量化,如下所示:

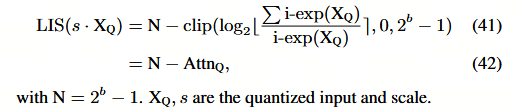
补充2:Log2 函数
Log2 函数可以通过整数运算计算,如算法 2 所示。为了获得整数的 Log2 值,我们引入了"Find First One"函数,该函数返回输入值中最高有效位(most significant one bit)的索引。整个处理过程都可以在整数域内完成。例如,若 I-Log2 的输入为二进制数 0000 1101 1010 1100₂,则 M 和 χ 分别计算为 11 和 1,四舍五入后的结果为 12。
在整数域 (integer domain)中高效计算一个整数的以 2 为底的对数(即 log 2 \log_2 log2)的算法或硬件逻辑。具体来说,它通过找到一个整数的"最高有效位"(Most Significant One bit, MSB)来实现这一目的。
-
log 2 \log_2 log2(以 2 为底的对数)与位数的关系 :
在计算机科学中,二进制数(由 0 和 1 组成)的特性使得 log 2 \log_2 log2 的计算与"位数"紧密相关。
- 如果数字 N N N 介于 2 k 2^k 2k 和 2 k + 1 2^{k+1} 2k+1 之间(即 2 k ≤ N < 2 k + 1 2^k \le N < 2^{k+1} 2k≤N<2k+1),那么 ⌊ log 2 ( N ) ⌋ \lfloor \log_2(N) \rfloor ⌊log2(N)⌋(向下取整)等于 k k k。
- 直观理解 : k k k 正好是该二进制数中最高位
1所在的位置索引(通常从 0 开始计数)。 - 例如 : 8 8 8 的二进制是
1000。最高位的1在第 3 位(索引 3,从右向左,从0开始)。因为 2 3 = 8 2^3 = 8 23=8,所以 log 2 ( 8 ) = 3 \log_2(8) = 3 log2(8)=3。
-
Find First One (FFO) / 最高有效位 (MSB) 函数 :
这是指从二进制数的最高位向最低位扫描,找到第一个出现的
1的位置。- 注意:原文中的 "First One" 结合上下文 "index of the most significant one bit" 指的是最高有效位(即最左边的 1),而不是最低有效位(Least Significant Bit, LSB)。在某些语境下 FFO 可能指 LSB,但这里明确指出了是 MSB。
-
整数域(Integer Domain) :
这意味着整个过程不需要使用浮点数运算(如 IEEE 754 标准),而是直接使用整数指令或硬件逻辑电路。这通常比浮点运算更快、更节省能量,特别是在嵌入式系统或数字信号处理(DSP)中。
2. 逐句解析与示例分析
让我们深入分析原文中的具体例子:
原文 :"For example, if the input of I-Log2 is
0000 1101 1010 1100₂..."
标准逻辑流程应该是:
-
输入 :一个整数 I I I。
-
FFO 操作 :找到 I I I 的最高位
1的索引。设为 E E E。
* 对于 0000 1101 1010 1100, E = 13 E=13 E=13。
- 计算 M 和 χ :
* M M M 通常是 E E E 本身,或者 E E E 减去某个偏置。在原文例子中 M = 11 M=11 M=11。如果 E = 13 E=13 E=13,偏置可能是 2。
* χ \chi χ 可能是一个修正系数,用于处理小数部分。原文中 χ = 1 \chi=1 χ=1。
- 舍入 (Rounding) :
* 最终结果 = M + correction based on χ M + \text{correction based on } \chi M+correction based on χ 或直接取整。
* 原文说结果是 12。
* 如果 M = 11 M=11 M=11,且 χ = 1 \chi=1 χ=1 表示需要加 1(向上舍入或四舍五入进位),那么 11 + 1 = 12 11+1=12 11+1=12。
为什么要在整数域做这件事?
传统的 log2() 函数通常需要浮点单元(FPU),这在大芯片面积或低功耗设备(如手机处理器、IoT 传感器)中是非常昂贵的。
- 硬件效率:查找"最高位 1"可以通过简单的并行比较树或移位比较电路实现,速度极快(只需几个时钟周期),且电路占用空间小。
Softmax 的下一步是注意力图 Attn 与值向量 V 之间的矩阵乘法。考虑到 VQ 是 V 的量化值,其缩放因子和零点分别为 sV、zpV ∈ R^1,则
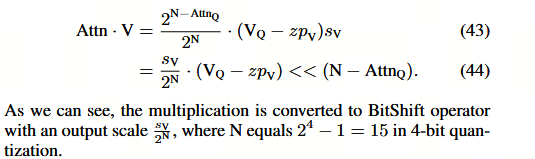
5 结论
在本文中,我们提出了一种用于视觉 Transformer 全量化(Fully Quantized)的方法。具体而言,我们提出了二元幂因子(Power-of-Two Factor, PTF),以解决 LayerNorm 输入中严重的通道间差异问题。此外,我们提出了一种集成量化方案 Log-Int-Softmax(LIS),以实现注意力图的 4 比特量化,并在推理阶段采用 BitShift(位移)运算符替代矩阵乘法(MatMul),从而有效降低了硬件资源需求。实验结果表明,我们提出的全量化视觉 Transformer 能够达到与全精度模型相当的性能水平。总体而言,我们为未来研究提供了更高的基线,希望 FQ-ViT 的优异表现能够激发对视觉 Transformer 更低比特宽度量化的深入研究,从而推动其在现实世界中的广泛应用。