1.索引
索引可以显著降低查询数据库的耗时,索引本质就是一种数据结构(B+树)
数据交互:MySQL是处于应用层的程序
逻辑上,MySQL和磁盘中的数据库文件进行curd操作
实际上,MySQL只和os的文件缓冲区进行io操作,而os又和磁盘进行io操作,申请对应的文件内容到文件缓冲区(先申请大块空间bufferpool用来和文件缓冲区交互)
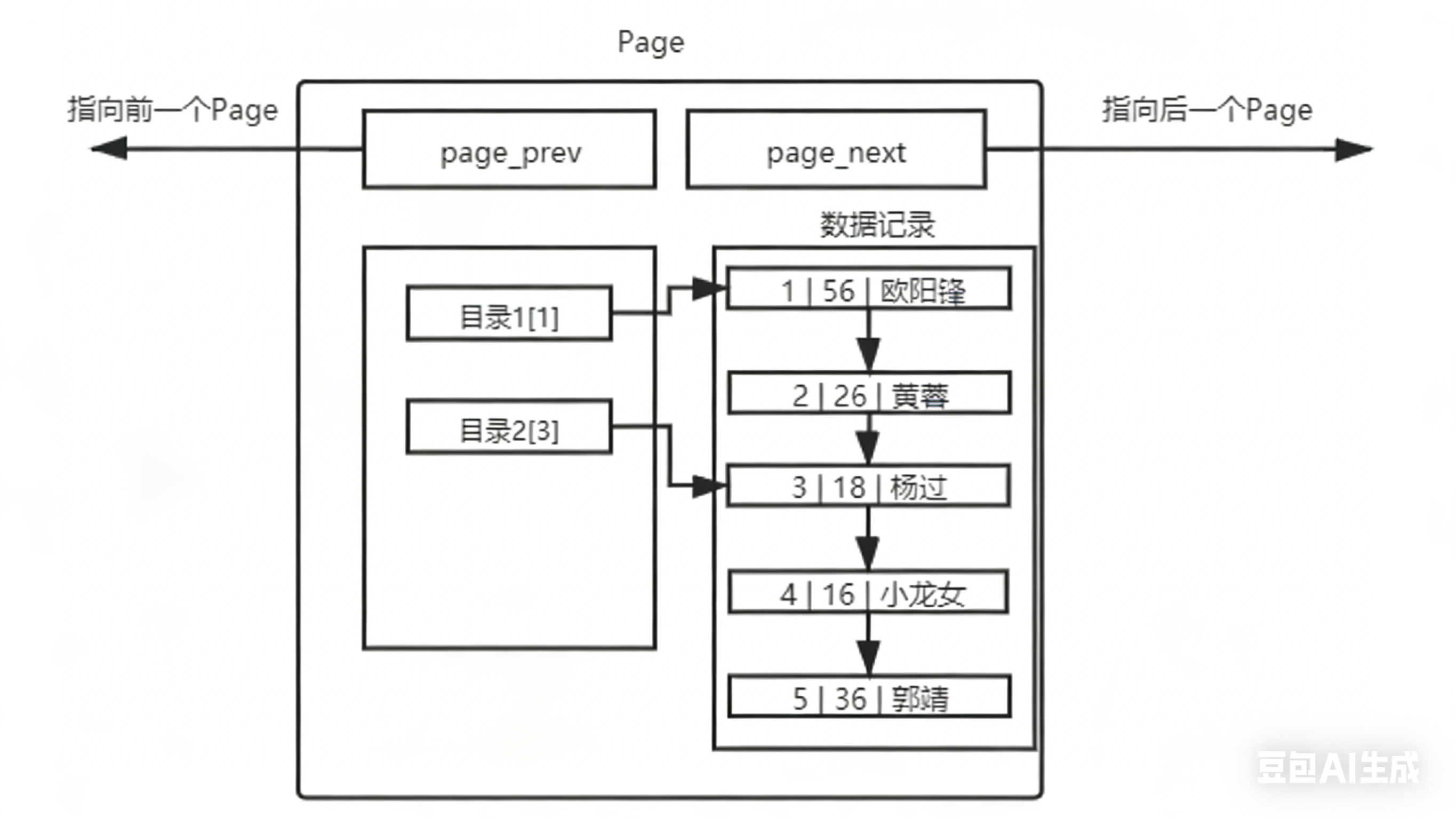
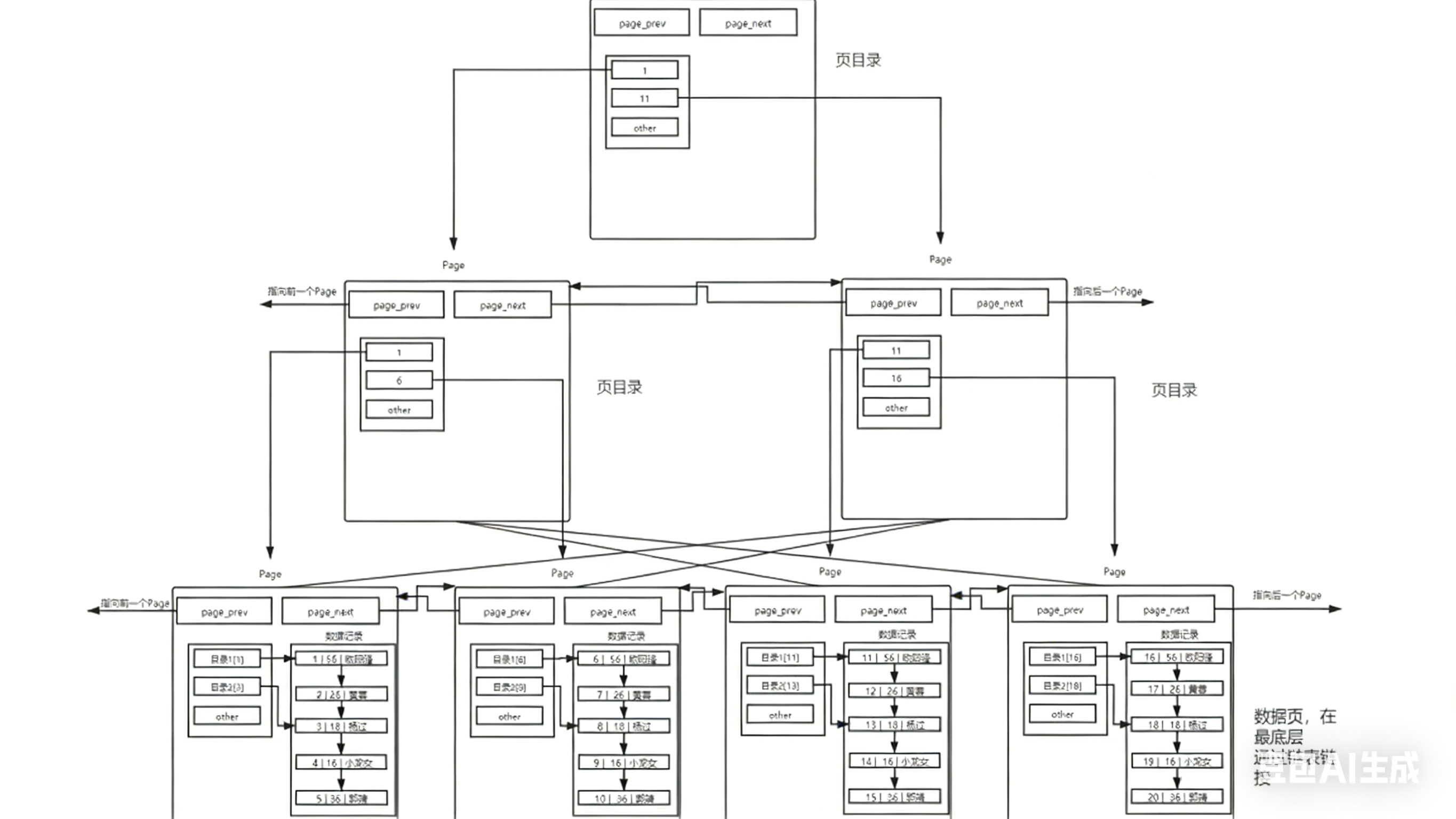
提高page查询效率:引入页间目录与页内目录
页内目录:
在一个page内部设置目录,将页内数据分割为多段,从而查找的时候不用始终从索引为1的起始位置遍历查找,而是可以就近选择不同的起始点
页间目录:
让部分page只保存其他page的地址信息,让他变为目录page,以后的查找都可以实现页间的目录级别查找,不需要线性遍历所有的page
eg:图中顶部的可以叫二级目录page,他指向一级目录page,而一级目录page再指向实际存储了数据的page,从而让page查询具有目录结构
注意:
1.只有实际存储了数据的page节点之间用链表连接起来
2.我们进行对应表的查找不是将所有的页都加载到内存中,而是根据目录查询,以页为单位,逐渐加载需要经过的路上page节点以及最终存储数据的page节点
3.由于数据库的存储有两大要求,范围查找修改以及查询效率io次数
所以我们淘汰了线性的链表结构,树结构较高的AVL树和红黑树,无法范围修改的哈希
疑问1:为什么向一个具有主键的表中插入数据,发现数据自动排序?
因为需要对主键索引值进行排序,从而方便引入页内目录,提高页内page查找效率
疑问2:如何理解MySQL中的page概念?
他是经过class page管理起来的,一次申请一个page对象相当于是一个预加载机制,提高计算机效率
聚簇索引VS非聚簇索引
B+树结构中,将叶子节点的数据和叶子节点对象本身分离存储的索引叫非聚簇索引,反之将数据和叶子page节点存储在一起就是聚簇索引
1.1主键索引
查看表中索引:
sqlshow index form 表名;删除表中主键索引:
sqlalter table 表名 drop primary key;创建主键索引(创建完表之后):
sqlalter table 表名 add primary key(id);注意:
创建了主键之后,innodb引擎会自动创建出主键索引
1.2唯一键索引
创建唯一键索引:
sqlalter table 表名 add unique(name);删除唯一键索引:
sqlalter table 表名 drop index 唯一键索引字段名在进行除主键外的索引删除的时候不能和主键一样写drop unique key,因为唯一键索引不是唯一的,一个表可以有多个唯一键索引,只能有一个主键索引
1.3普通索引
创建普通索引:
sqlcreate index 索引名 on 表名(字段名);删除普通索引:
sqlalter table 表名 drop index 索引名;索引创建规范:
1.频繁作为查询条件的字段应该创建索引
2.唯一性太差的字段不适合作为索引(例如性别)
3.频繁变动的字段不适合创建索引
4.不会作为筛选条件的字段不适合
2.事务
事务就是一组DML语句组成,这些语句在逻辑上存在相关性,这一组DML语句要么全部成功,要么全部 失败,是一个整体
事务使用场景:主要用于处理操作量大,复杂度高的数据
事务需要满足的四个特性:
(1)原子性:
一个事物在执行时要么全部执行成功要么全部执行失败,不会存在中间状态。一旦执行过程出错,这个事务就会回滚,就像没有执行过任何操作一样
(2)一致性:
事务开始前和结束后,数据库的完整性没有被破坏,一直处于既定规则下(一致性通过其他三个特性进行技术支持)
技术上的一致性可以由数据库自身保证,业务上的一致性则由数据库用户来保证,最终才能实现实际上的一致性
(3)隔离性:
隔离性可以保证数据库有并发执行事务时不会由于交叉执行导致数据不一致,事务隔离会分成不同级别
(4)持久性:
事务处理结束后,可以保证数据永久修改
2.1事务的提交方式
事务的提交方式分两种:
1.自动提交
2.手动提交
相关命令:
(1)查看提交方式:
sqlshow variables like 'autocommit';(2)利用set启动或关闭事务自动提交
sqlset autocommit=0;//关闭 set autocommit=1;//启动
2.2事务的案例演示
(1)正常演示
1.启动事务:
sqlstart transaction;//语句1 begin;//语句22.插入数据+保存点
sqlinsert into table values ('zhangsan');//插入数据 savepoint s1;//保存事物节点3.定向回滚/全事物回滚
sqlrollback;//全回滚 rollback to s1;//定向回滚s14.提交
sqlcommit;即使设置了autocommit,手动开启的事务也需要手动commit
当我们设置了保存点之后,如果需要将前面的数据回滚掉,可以使用定向回滚,如果没有保存事物节点,我们只能全回滚
在事务确认正确的时候,可以提交到数据库,从而事物就具有了持久性
(2)未commit时,客户端崩溃
此时我们没commit的所有事物都会被回滚,从而保证事物具有原子性
(3)commit成功,客户端崩溃
此时数据不会被回滚,因为提交之后数据就具有了持久性
疑问:那么autocommit到底有什么用?
在innoDB引擎下,其实我们在mysql中使用的单SQL语句都是一个非手动启动事务,当我们的autocommit启动后,单个SQL语句就可以直接持久性修改数据库,若autocommit关闭,单个SQL语句不手动commit就无法保存,会自动回滚
疑问:原子性和持久性我们理解了,隔离性怎么体现?
在事务场景中,隔离是必要的,主要隔离的是多个并发执行的事务,让并发事务不会互相影响,体现隔离性
2.3隔离级别
(1)读未提交(read uncommitted)
(2)读提交(read committed)
(3)可重复性(repeatable read)
(4)串行化(serializable)
查看与设置隔离性
查看:
sqlselect @@global.tx_isolation;//查看全局隔离级别 select @@session.tx_isolation;//查看当前会话的全局隔离级别global的级别是所有会话都默认的隔离级别,若我们启动mysql新会话后不特别设置session的隔离级别,他会直接拷贝global的隔离级别,若我们特别设置当前会话的隔离级别,即使global级别改变也不会影响session隔离级别
设置:
sqlset [session/global] transaction isolation level 隔离级别;
(1)读未提交(read uncommitted)
在读写并发场景且隔离级别为该级别下,所有事务可以看到其他事务没有提交的执行结果,相当于没有任何隔离性
eg:事务1需要插入三条数据,由于设置了读未提交的隔离级别,另一个用户在读取表的时候可以看到事务1逐条插入的过程,这丧失了事务的原子性与隔离性
此时用户读到的数据属于脏数据,这个读取事务未提交的数据的过程叫脏读
(2)读提交(read committed)
这是大多数数据库默认的隔离级别,该级别下,一个事务只能看到其他已经提交的事务所做的改变
由于它的该特性,在一个运行的事务内部会变得不可重复读取,高并发场景下,会存在多次commit,从而让查询数据多次变化
eg:
我们需要根据同学成绩进行奖品发放,tom同学原本的分数是60,但是他发现试卷有问题,和老师说,将分数改为了71,我们有两个事务在运行
事务1负责查询各个分数段的学生人数,事务2负责更新tom的成绩
如果事务1在执行的过程中,事务2commit了,在读提交条件下,事务1就被影响了,可能出现tom即属于60~69区间,又属于70~79区间,这就是不可重复读问题
(3)可重复读(repeatable read)
这是MySQL默认隔离级别,在该隔离级别下,读取事务可以重复读取数据,可以看到同样的东西,但是可能存在幻读问题
幻读:读取事务在多次重复读取过程中出现新增数据(数据条数增加)
大部分数据库在RR隔离级别下,对于insert的待插入数据没有实现隔离,仍然会影响正在读取的事务,因为RR隔离级别是利用锁完成的,而原先没有的数据的锁并没有被占用。MySQL通过其他方式解决了这个问题
(4)串行化(serializable)
事务最高隔离级别,给所有事务加上共享锁,强制事务排序,完全保证了事务的隔离,但是由于所有事务争夺同一个锁,所以效率极低,现实中几乎不会使用
3.视图
视图是一个虚拟表,他是由查询定义的
(1)创建视图
sqlcreate view 视图名 as select语句;(2)删除视图
sqldrop view 视图名;特性:
1.基表和视图修改任意一方都会对另一方的数据产生影响
2.必须命名唯一
3.可以和表一起使用
4.用户管理
4.1用户创建
mysql的用户信息都存储在user表中,host表示用户可以从哪个主机登录,localhost表示允许本机登录
(1)创建用户
sqlcreate user '用户名'@'主机名/ip' identified by '密码';ip/主机名填写处可以使用%代替,从而允许用户从任意主机登录
(2)删除用户
sqldrop user '用户名'@'主机名';(3)修改密码
sqlset password=password('新的密码');//修改用户自身密码 set password for '用户名'@'主机名'=password('新的密码');//root修改指定用户密码其实修改密码也可以使用普通SQL语句,查询user表中指定用户的数据摘要,利用password()对需要改成的密码进行加密,赋值给指定用户摘要
4.2用户权限
(1)给用户授权
sqlgrant 权限列表 on 库.用户名 to '用户名'@'主机名/ip' [identified by '用户密码'];若对应用户存在就相当于修改密码,若不存在就创建用户
权限列表全授权:all
在库.用户名下:
只有' . ':表示MySQL所有数据库下的所有对象
' 库. ':表示特定数据库下的所有对象
(2)查看指定用户现有权限
sqlshow grants for '用户名'@'主机名/ip';(3)回收权限
sqlrevoke 权限列表 on 库.用户名 from '用户名'@'主机名/ip';
5.语言级别访问数据库
5.1相关接口
(1)初始化MySQL
cppMYSQL* mysql_init(MYSQL* mysql);初始化完毕之后需要先链接数据库,才能进行后续操作
一般初始化时:mysql_init(nullptr);
(2)建立数据库连接
cppMYSQL *mysql_real_connect(MYSQL *mysql, const char *host, const char *user, const char *passwd, const char *db, unsigned int port, const char *unix_socket, unsigned long clientflag);mysql:初始化后返回的mysql指针
host:登录地址ip
user:用户名
passwd:用户密码
db:连接数据库名
port:端口号
unix_socket:Unix域套接字文件路径(仅本地连接)
clientflag:客户端标志
(3)下发SQL指令
cppint mysql_query(MYSQL *mysql, const char *q);参数1:mysql指针,包含各种mysql相关信息
参数2:要执行的sql语句
(4)获取执行结果
cppMYSQL_RES *mysql_store_result(MYSQL *mysql);返回值MYSQL_RES可以看成是char**数组,他所保存的数据每一个都是表示一行的char*数组,从而表示出整个表的所有数据
(5)获取结果行数
cppmy_ulonglong mysql_num_rows(MYSQL_RES *res);从获取的执行结果中进行行数提取
(6)获取结果列数
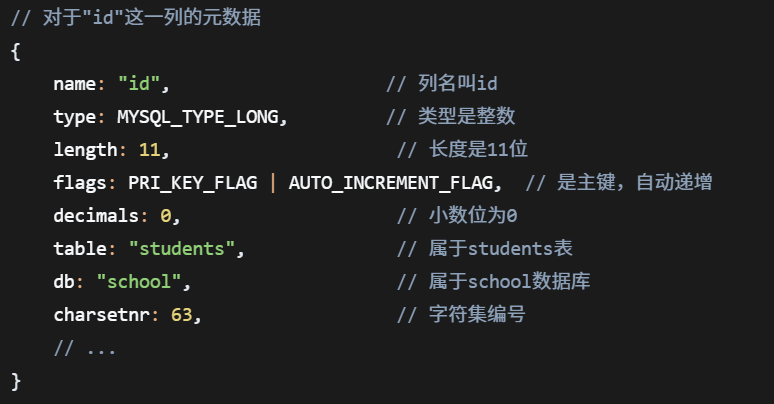
cppunsigned int mysql_num_fields(MYSQL_RES *res);(7)获取所有字段的元数据
cppMYSQL_FIELD *mysql_fetch_fields(MYSQL_RES *res);元数据举例:
(8)获取结果内容
cppMYSQL_ROW mysql_fetch_row(MYSQL_RES *result);MYSQL_ROW也是char**类型,和前面的MYSQL_RES类似
(9)关闭mysql链接
cppvoid mysql_close(MYSQL *sock);