这是自然语言处理与神经网络结合的开山之作,它的语言建模方法也启发了后来大名鼎鼎的word2vec。这里忽略了论文工程实现细节的讲解(例如加速训练的技巧)。
文章目录
- [1. 背景](#1. 背景)
- [2. 传统方法的局限以及研究动机](#2. 传统方法的局限以及研究动机)
- [3. 研究内容及模型](#3. 研究内容及模型)
-
- [3.1 模型核心设计思想](#3.1 模型核心设计思想)
- [3.2 模型的数学分解](#3.2 模型的数学分解)
- [3.3 核心神经网络架构](#3.3 核心神经网络架构)
- [4. 实验与结果](#4. 实验与结果)
-
- [4.1 vs. n-gram](#4.1 vs. n-gram)
1. 背景
统计语言建模是自然语言处理领域的核心研究方向之一,它的核心目标是学习自然语言中单词序列的联合概率分布,通过该分布可以对任意单词序列的合理性进行量化评估,这一技术成为语音识别、机器翻译、信息检索等众多自然语言处理实际应用的重要基础,模型性能的提升能够直接推动这类应用的效果优化。
2. 传统方法的局限以及研究动机
语言建模的统计模型用在给定最后一个词之前的词的条件下,下个词出现的概率来表示,公式如下:
P ^ ( w 1 T ) = ∏ t = 1 T P ^ ( w t ∣ w 1 t − 1 ) \widehat{P}\left( \mathrm{w}{1}^{\mathrm{T}} \right) =\prod{\mathrm{t}=1}^{\mathrm{T}}{\widehat{\mathrm{P}}\left( \mathrm{w}{\mathrm{t}}|\mathrm{w}{1}^{\mathrm{t}-1} \right)} P (w1T)=t=1∏TP (wt∣w1t−1)
在统计语言建模的研究与实践中,维度灾难是其面临的本质性难题。由于自然语言中的单词属于离散随机变量,且实际应用中词汇表规模通常极大(可达数万甚至十万级),当建模多个连续单词的联合分布时,参数空间会呈指数级爆炸。而离散空间与连续空间的泛化特性存在本质差异:连续变量的建模可借助多层神经网络、高斯混合模型等具有局部平滑性的函数实现有效泛化,而离散变量的微小变化就可能导致待估计函数值发生剧烈波动,且高维离散空间中多数观测对象的汉明距离几乎达到最大值,进一步加剧了泛化难度。
成功应对维度灾难的解决方案:n-gram模型。该方法通过利用单词序列的时序相关性 ------ 相邻单词的统计依赖性更强,将待预测单词的条件概率近似为仅依赖于前n−1个单词的条件概率,大幅缩减了建模的上下文范围,并通过回退、插值平滑等策略处理训练集中未出现的 n 元组序列,避免为其分配零概率,成为当时该领域的基准方法。但这类方法的泛化方式存在固有局限,难以充分利用更长的上下文信息,也无法有效捕捉单词间的语义和语法相似性,为新模型的提出留下了研究空间。模型公式如下:
P ^ ( w t ∣ w 1 t − 1 ) ≈ P ^ ( w t ∣ w t − n + 1 t − 1 ) \widehat{P}\left( \mathrm{w}{\mathrm{t}}|\mathrm{w}{1}^{\mathrm{t}-1} \right) \approx \widehat{\mathrm{P}}\left( \mathrm{w}{\mathrm{t}}|\mathrm{w}{\mathrm{t}-\mathrm{n}+1}^{\mathrm{t}-1} \right) P (wt∣w1t−1)≈P (wt∣wt−n+1t−1)
解决离散符号的建模难题:为符号数据学习分布式表示,主张用连续的实值向量表示离散符号,让符号的特征信息分布在向量的各个维度中,而非用独热编码这种局部表示。这一思想为缓解离散空间的维度灾难、实现更有效的泛化提供了理论雏形,也成为本文模型设计的核心理论基础。
3. 研究内容及模型
从离散单词序列到连续向量空间的概率建模。文章提出了一种融合分布式词表示的神经概率语言模型,核心创新是同时联合学习单词的分布式特征向量与基于该向量的单词序列条件概率函数。
四大模块:词特征映射、神经网络概率计算、模型训练优化、大规模并行实现。
3.1 模型核心设计思想
-
分布式词特征向量映射:为词汇表 V V V中的每个单词关联一个低维连续实值特征向量 C ( i ) ∈ R m C(i) \in \mathbb{R}^m C(i)∈Rm( m m m为特征维度,通常取30/60/100,远小于词汇表规模 ∣ V ∣ |V| ∣V∣),将离散的单词符号映射到连续的向量空间,让单词的语义、语法特征分布在向量的各个维度中。
-
基于连续向量的概率函数表达:将单词序列的联合概率分解为条件概率的乘积( P ^ ( w 1 T ) = ∏ t = 1 T P ^ ( w t ∣ w 1 t − 1 ) \hat{P}(w_1^T)=\prod_{t=1}^T \hat{P}(w_t|w_1^{t-1}) P^(w1T)=∏t=1TP^(wt∣w1t−1)),并通过神经网络将该条件概率函数的输入定义为上下文单词的分布式特征向量,让概率函数成为连续向量的平滑函数。
-
联合学习:不预先固定词的特征向量,而是将其作为模型可学习参数,与概率函数的神经网络参数一起通过训练数据联合优化,让词表示的学习与语言建模的目标高度耦合,保证词向量能更好地服务于序列概率预测任务。
3.2 模型的数学分解
将语言建模的核心目标------条件概率 P ^ ( w t ∣ w 1 t − 1 ) ≈ f ( w t , w t − 1 , ... , w t − n + 1 ) \hat{P}(w_t|w_1^{t-1}) \approx f(w_t, w_{t-1}, \dots, w_{t-n+1}) P^(wt∣w1t−1)≈f(wt,wt−1,...,wt−n+1)拆解为两个串行的映射函数,具体分解如下:
-
词特征映射函数 C C C: C : i ∈ V → R m C: i \in V \rightarrow \mathbb{R}^m C:i∈V→Rm,表示将词汇表中的第 i i i个单词映射为 m m m维的分布式特征向量。工程上 C C C由一个 ∣ V ∣ × m |V| \times m ∣V∣×m的参数矩阵实现,矩阵的第 i i i行即为单词 i i i的特征向量,该矩阵是模型的核心可学习参数之一。
-
概率计算函数 g g g: g : ( R m ) n − 1 → 0 , 1 ∣ V ∣ g: (\mathbb{R}^m)^{n-1} \rightarrow 0,1^{|V|} g:(Rm)n−1→0,1∣V∣,表示将前 n − 1 n-1 n−1个上下文单词的特征向量序列,映射为词汇表中所有单词作为下一个单词的条件概率分布。工程上 g g g由一个带隐藏层的前馈神经网络实现,其输出为归一化的概率值。
所以,条件概率函数可表示为两者的复合: f ( i , w t − 1 , ... , w t − n + 1 ) = g ( i , C ( w t − 1 ) , ... , C ( w t − n + 1 ) ) f(i, w_{t-1}, \dots, w_{t-n+1}) = g(i, C(w_{t-1}), \dots, C(w_{t-n+1})) f(i,wt−1,...,wt−n+1)=g(i,C(wt−1),...,C(wt−n+1)),模型的整体参数集 θ = ( C , ω ) \theta=(C, \omega) θ=(C,ω),其中 ω \omega ω为神经网络 g g g的所有参数。
模型的训练目标是最大化训练语料的带正则化的对数似然,以此同时优化词特征矩阵 C C C和神经网络参数 ω \omega ω,目标函数为:
L = 1 T ∑ t l o g f ( w t , w t − 1 , ⋯ , w t − n + 1 ; θ ) + R ( θ ) L=\frac{1}{T} \sum_{t} log f\left(w_{t}, w_{t-1}, \cdots, w_{t-n+1} ; \theta\right)+R(\theta) L=T1∑tlogf(wt,wt−1,⋯,wt−n+1;θ)+R(θ)
其中 T T T为训练语料的单词总数, R ( θ ) R(\theta) R(θ)为正则化项。
3.3 核心神经网络架构
本文设计的神经网络是概率计算函数的核心实现,为带词特征层、单隐藏层、Softmax输出层的前馈神经网络,并支持可选的"词特征层到输出层的直接连接",整体架构分为三层,网络的输入为前 n − 1 n-1 n−1个上下文单词的特征向量拼接,输出为词汇表所有单词的条件概率。架构如下图:
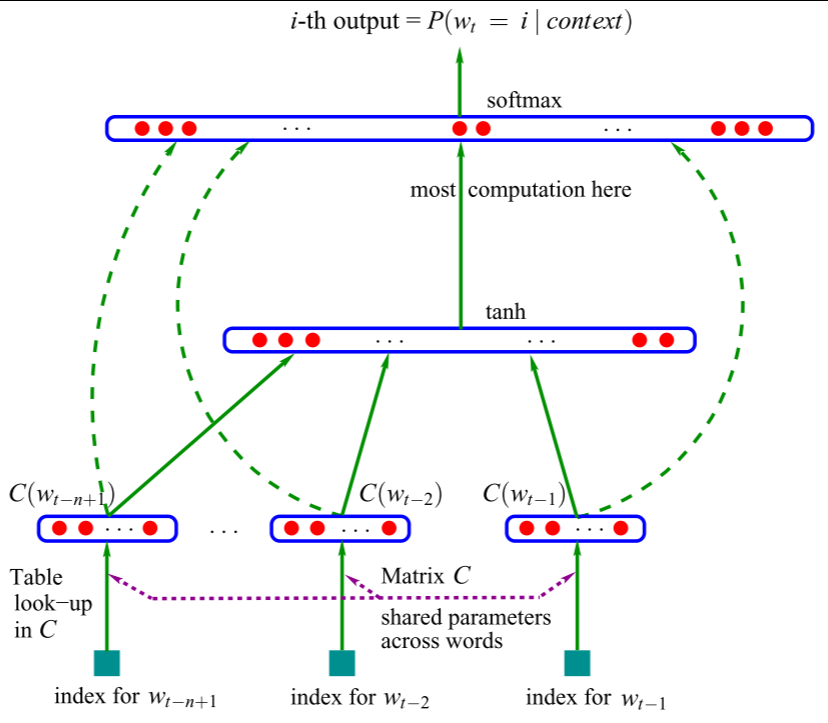
3.3.1 输入层:词特征拼接层
将前 n − 1 n-1 n−1个上下文单词的特征向量从词特征矩阵 C C C中查表提取,并按顺序拼接为一个高维向量 x x x,作为神经网络的实际输入,计算式为:
x = ( C ( w t − 1 ) , C ( w t − 2 ) , ⋯ , C ( w t − n + 1 ) ) x=\left(C\left(w_{t-1}\right), C\left(w_{t-2}\right), \cdots, C\left(w_{t-n+1}\right)\right) x=(C(wt−1),C(wt−2),⋯,C(wt−n+1))
3.3.2 隐藏层:Tanh激活层
隐藏层采用(Tanh)作为激活函数,实现从输入特征到高维抽象特征的映射。
3.3.3 输出层:Softmax归一化层
输出层的核心目标是将隐藏层的抽象特征映射为归一化的条件概率,保证所有单词的概率之和为1。具体计算式为:
y = b + W x + U ⋅ t a n h ( d + H x ) y = b + Wx + U \cdot tanh(d + Hx) y=b+Wx+U⋅tanh(d+Hx)
P ^ ( w t ∣ w t − 1 , ⋯ w t − n + 1 ) = e y w t ∑ i ∈ V e y i \hat{P}\left(w_{t} | w_{t-1}, \cdots w_{t-n+1}\right)=\frac{e^{y_{w_t}}}{\sum_{i \in V} e^{y_{i}}} P^(wt∣wt−1,⋯wt−n+1)=∑i∈Veyieywt
4. 实验与结果
4.1 vs. n-gram
-
性能优势:NPLM在两种测试语料上的困惑度均显著低于传统n-gram模型(降低11.9%~18.5%),核心原因是分布式词表示捕捉了单词间的语义/语法相似性,实现了更好的泛化能力,缓解了维度灾难;四元组NPLM性能优于三元组NPLM,说明增加上下文窗口大小能让模型捕捉更多时序依赖信息。
-
混合模型价值:NPLM与传统n-gram模型的误差互补,融合后能进一步降低困惑度,说明传统模型的线性统计规律与神经模型的非线性泛化能力可相互补充,提升概率预测的稳定性。
-
参数选择启示:词向量维度和隐藏单元数的增加能提升模型性能,但边际效益递减,实际应用中需在性能与计算成本之间权衡,默认参数(n=3、m=60、h=200)能实现性能与效率的平衡。
-
并行方案有效性:参数并行方案实现了接近线性的加速比,大幅降低了大规模模型的训练时间,解决了Softmax输出层的计算瓶颈,为NPLM的工程化应用提供了可行路径。