本文声明:内容来源于网络,进行整合/再创作;部分内容由AI辅助生成。
Tips:关于指令内容的讲述优先以AArch64执行状态为准,部分内容可能与AArch32类似。
基址寻址(无偏移)
地址计算:有效地址 = 基址寄存器base的值。
语法:base{, #0},其中#0偏移量可省略。
特点:直接 访问基址寄存器指向的内存地址,不进行任何计算,是最基础的寻址方式。
基址寻址(加偏移)
地址计算:有效地址 = 基址寄存器base的值 + 偏移量。
偏移类型:
立即数偏移:偏移量是一个立即数#imm。
寄存器偏移:偏移量是另一个寄存器Xm的值,还可通过LSL #imm进行左移缩放。
扩展寄存器偏移:偏移量是32位寄存器Wm的值,通过有符号(SXTW)或无符号(UXTW)扩展为64位,再加上可选的缩放#imm。
特点:基址寄存器的值保持不变,仅用于计算地址。
前索引寻址(Pre-indexed addressing)
也称"事先更新寻址"。新地址的计算发生在访问内存前 ;用新地址访问内存后,新地址会被重新写回基址寄存器base。
地址计算:有效地址 = 基址寄存器base的值 + 偏移量#imm。
语法:base, #imm!,感叹号"!"表示是更新基址即寄存器中的地址。
典型场景:遍历数组时,先将地址移动到下一个元素,再访问数据。
后索引寻址(Post-indexed addressing)
也称"事后更新寻址"。新地址的计算发生在访问内存后;先用基址寄存器的当前值访问内存,然后计算新地址(base的值 + 偏移量#imm或Xm),并将其重新写回基址寄存器base。
地址计算:有效地址 = 基址寄存器base的值。
语法:base, #imm 或 base, Xm。
典型场景:栈操作,先访问栈顶数据,再调整栈指针。
PC 相对寻址
地址计算:有效地址 = 程序计数器PC的值 + 19位带符号字偏移量。
范围:地址范围限制在PC ± 1MB 内,且必须是字对齐的。
限制:仅适用于32位或更大的负载指令以及预取指令,在其他寻址模式下不可用。
典型场景:用于访问程序代码段附近的常量数据(如字符串、全局常量)。
AArch32与AArch64内存访问指令的寻址方式的区别
AArch32(32 位执行状态,支持 A32/T32 指令集)和 AArch64(64 位执行状态,支持 A64 指令集)在内存访问(Load/Store)的寻址方式上,既有传承也有显著的设计差异。
核心架构差异
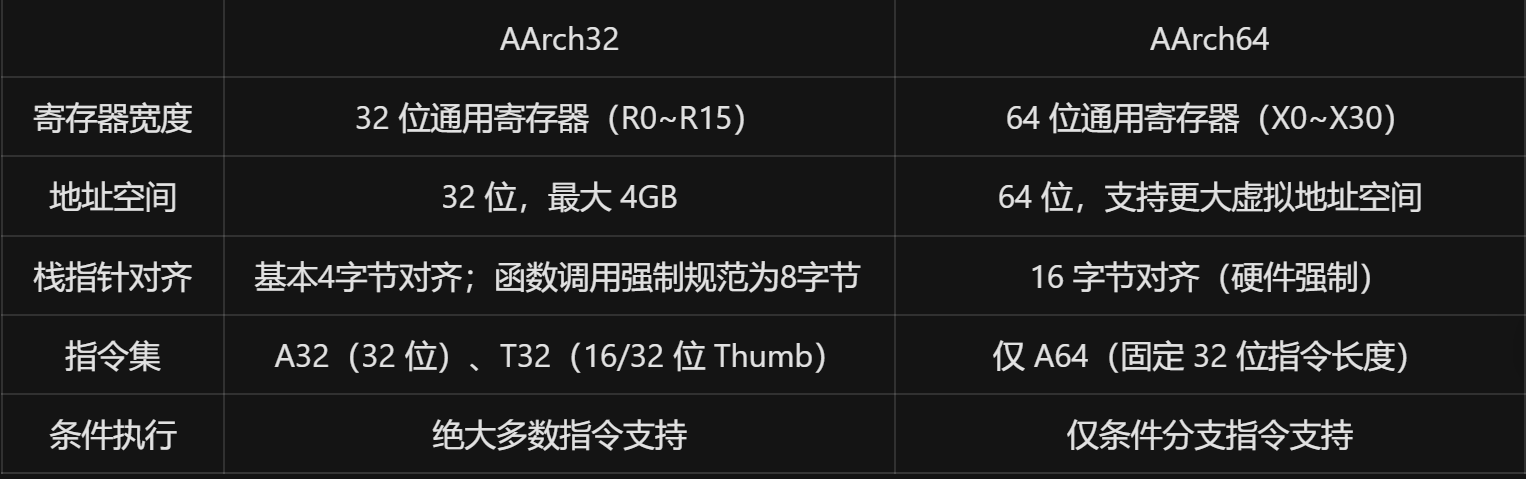
寻址模式对比
基址 + 偏移寻址
|---------|---------------------------------------------------------------|-----------------------------------------------------------------|
| 特性 | AArch32 | AArch64 |
| 立即数偏移 | Rb, #imm | Xb, #imm |
| 寄存器偏移 | Rb, Rm | Xb, Xm |
| 缩放寄存器偏移 | Rb, Rm, LSL #n | Xb, Xm, LSL #n / Xb, Wm, {S\|U}XTW #n |
| 基址更新 | 前索引:Rb, #imm! / Rb, Rm! 后索引:Rb, #imm / Rb, Rm | 前索引:仅支持立即数 Xb, #imm! 后索引:支持立即数 Xb, #imm 和寄存器 Xb, Xm |
PC 相对寻址
|------|---------------------|--------------------|
| 特性 | AArch32 | AArch64 |
| 寻址范围 | ±4GB | ±1MB(字对齐) |
| 适用指令 | 广泛 | 仅 32 位及以上负载指令、预取指令 |
| 典型用法 | LDR R0, =label(伪指令) | ADR X0, label |
指令特性对比
|------|---------------------------|-----------------------------|
| 特性 | AArch32 | AArch64 |
| 批量操作 | 支持 LDM/STM、PUSH/POP 等批量指令 | 移除批量指令,使用 LDP/STP 成对加载 / 存储 |
| 指令密度 | T32 指令集提供更高代码密度 | 指令长度固定,译码更简单 |
| 设计目标 | 功能丰富,适配嵌入式/移动设备多样化场景 | 精简统一,追求高性能、可扩展性与硬件简化 |
关键设计取舍
- AArch32:以功能全面性为核心,提供丰富寻址方式和条件执行,适配复杂嵌入式场景。
- AArch64:以性能与简洁性为核心,通过精简寻址模式,实现更高流水线效率和可扩展性。