文章目录
-
- 不同架构区别和使用
- [Armv8-R AArch32特性](#Armv8-R AArch32特性)
- R系列架构
- 编程模型
- 虚拟化
- MPU
- Cortex-R52
- Armv8架构特征概览
不同架构区别和使用
| A系列(Applications) | R系列(Real-time) | M系列(Microcontroller) |
|---|---|---|
| 高性能 | 实时需求目标系统 | 低功耗。用于小型高效能设备 |
| 运行复杂操作系统,如Linux/Windows | 常见于网络设备和嵌入式控制系统 | 常见于很多IOT设备 |
架构是一种功能规范,是软件和硬件都要共同遵守的规范。该架构描述了软件依赖硬件实现的功能。
-
指令集
- 每个指令的功能
- 指令的编码方式,或指令在内存中如何表示
-
寄存器组
- 寄存器数量
- 寄存器大小
- 寄存器的功能
- 初始状态
-
异常模型
- 不同的权限等级
- 异常的类型
- 发生异常或从异常返回时,会进行哪些操作
-
内存模型
- 内存访问的排序规则
- 缓存的行为方式,以及软件执行显式维护的时机和方法
-
调试,跟踪和分析
- 断点如何设置和出发
- 跟踪工具捕获的内容和格式
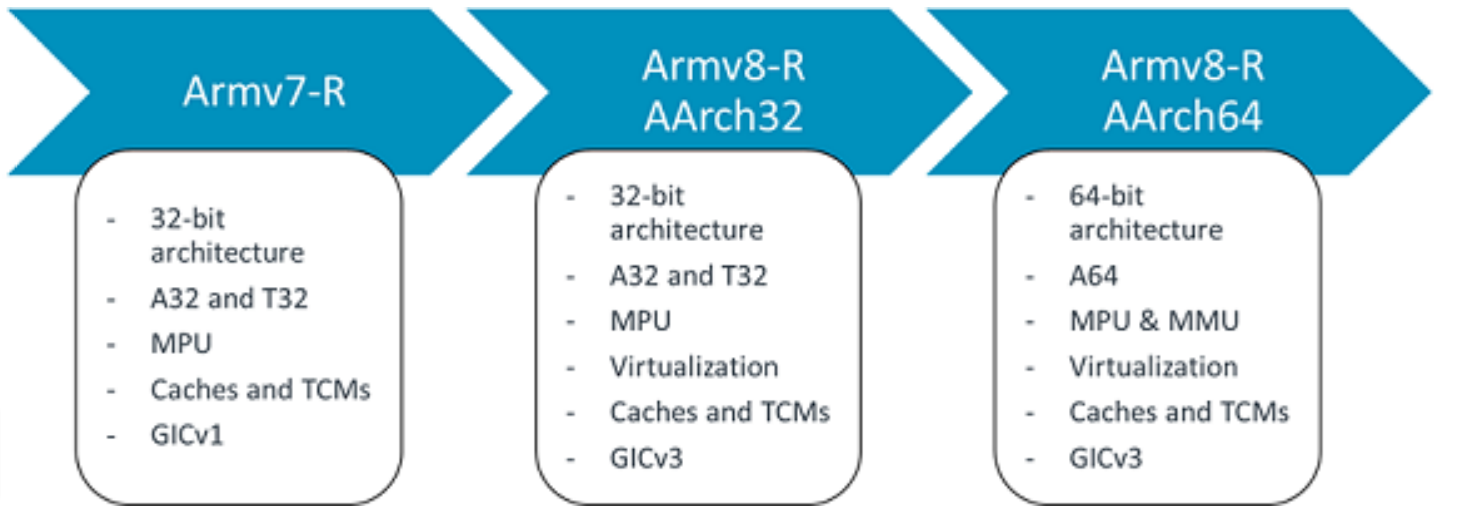
Armv8-R AArch32特性
- 32位架构
- 虚拟化支持
- A32和T32指令集,包括可选浮点运算和NEON扩展功能
- 一级和二级MPU
- 支持GICv3
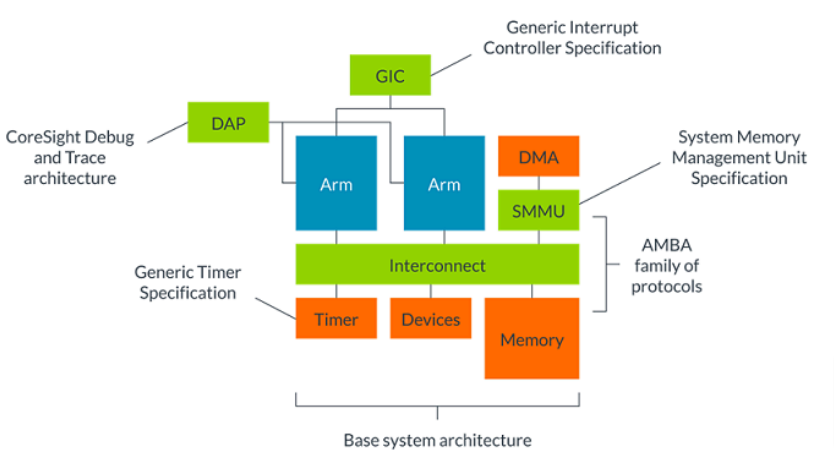
R系列架构
系统并不限于处理器本身。除了处理器架构外,Arm还定义了其他通用系统组件的架构。
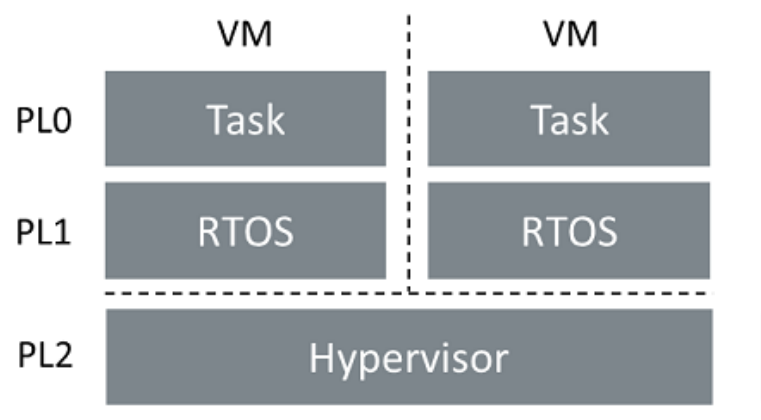
编程模型
ArmV8-R 支持以下特权等级
- PL0:最低特权等级,应用程序或任务通常在此运行
- PL1:管理软件(RTOS)的运行级别
- PL2:最高特权级别,用于控制处理器虚拟化功能的软件(通常称为虚拟机监控程序/Hypervisor)在此运行

虚拟化
虚拟化技术支持在同一个物理机上运行多个客户虚拟机。EL2提供了虚拟化功能的控制机制。运行在PL2的软件(即Hypervisor)负责创建和调度虚拟机。
各虚拟机运行在PL1和PL0级别,其内部可能包含裸机代码和RTOS。
处理器的虚拟化支持包括以下特性:
- 针对PL1控制寄存器访问的Trap机制。估计值允许Hypervisor模拟虚拟机内的特定操作
- 二级MPU。该机制允许Hypervisor控制哪些系统资源对虚拟机可见。例如,防止某个虚拟机访问分配给其他虚拟机的资源。
- 虚拟中断支持。Hypervisor可以控制向每个虚拟机分发的中断。
MPU
Armv8-R AArch32实现物理内存系统架构(PMSA),并通过MPU来控制内存保护。
MPU 使用寄存器来定义内存区域,并为每个区域配置相关属性,例如读写权限和缓存策略。当处理器访问某个内存地址时,MPU 会依据该地址所属区域的属性对访问进行检查。这种模型被称为 PMSA。
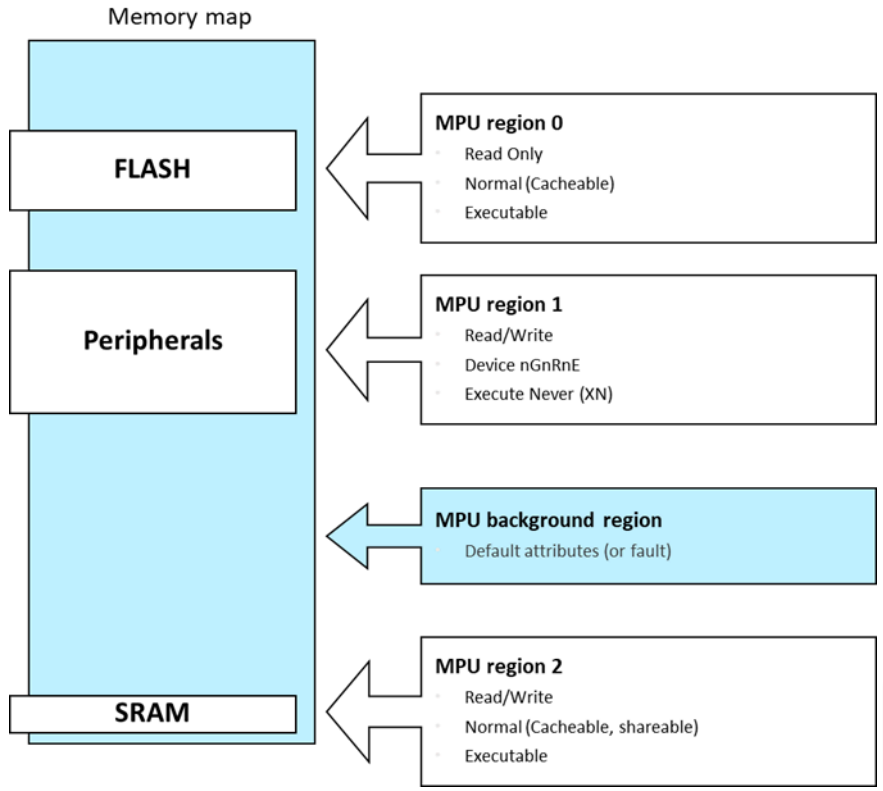
Armv8-R AArch32 实现了 PMSA,提供 一级和二级MPU。其内存保护机制如下图所示:
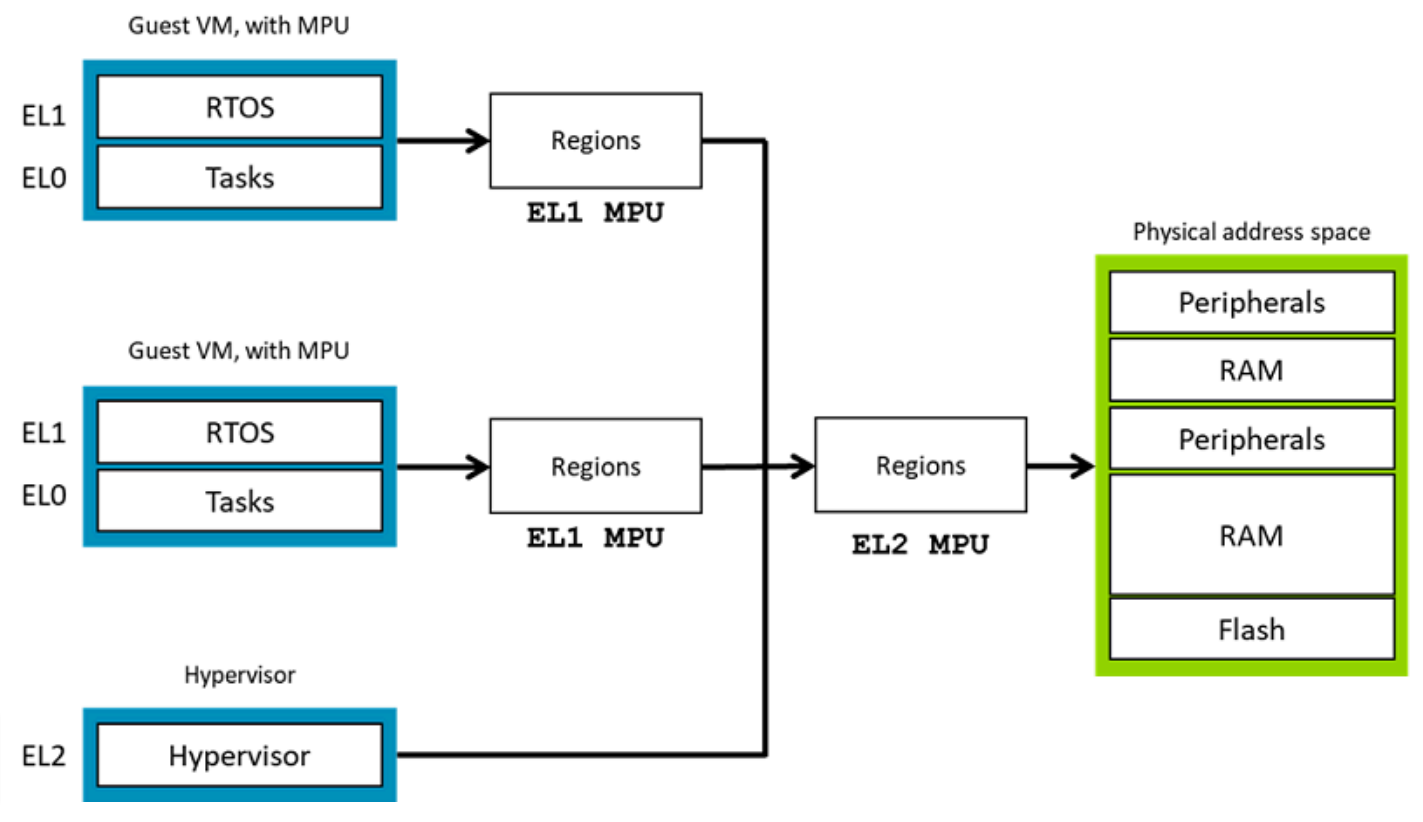
一级 MPU 由虚拟机(VM)内的 RTOS 进行配置,用于控制对该 VM 可见资源的访问。
二级 MPU 由Hypervisor配置,用于控制对各虚拟机可见资源的分配与隔离。
此外,二级MPU 也用于对 Hypervisor 自身的访问进行检查。
与 Armv8-R AArch64 不同,Armv8-R AArch32 不支持虚拟内存系统架构(VMSA)或内存管理单元(MMU)。
Cortex-R52
Arm Cortex-R52 处理器是首个 Armv8-R AArch32 的实现。Cortex-R52 提供高性能的 32 位处理能力及高效的代码密度,并集成了 Arm 处理器中最高等级的功能安全特性。
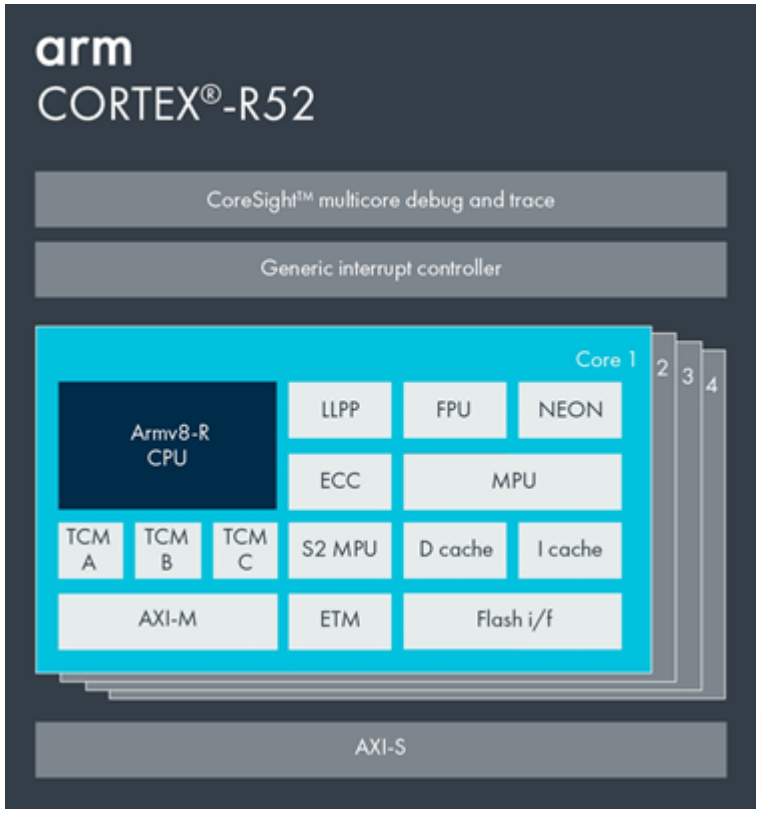
Arm Cortex-R52+ 处理器与 Cortex-R52 软件兼容,通过增强的可配置性,更好地满足了虚拟机隔离等具有功能安全要求的实时应用需求。
Cortex-R52 和 Cortex-R52+ 均集成了实现 GICv3 架构的通用中断控制器(GIC)。
Armv8架构特征概览
| 类别 | 描述 |
|---|---|
| 指令集 | 支持 Arm 和 Thumb-2 指令集。支持 DSP 指令,并可选配单精度或双精度浮点运算单元(FPU )及 Neon 高级 SIMD 扩展。 |
| 微架构 | 8 级流水线 ,具备指令预取、分支预测、按序超标量执行能力。拥有并行的执行路径,分别用于加载-存储、乘加(MAC)、移位-算术逻辑单元(Shift-ALU)、除法及浮点运算。 |
| 最高四核配置 | 支持单簇内最多 4 个物理 CPU 的多处理器配置,或在 双核锁步(DCLS) 配置下提供最多 8 个逻辑核。 |
| 双核锁步 (DCLS) | 采用冗余内核锁步运行,用于高可靠系统中的故障检测。支持可选的 Split/Lock 配置,允许解除校验核的耦合,使其独立执行任务。 |
| 自测试技术 | 通过内置自测试(BIST)功能实现高故障覆盖率。 |
| 软件测试库 | 提供软件库,以实现灵活的非破坏性运行时故障覆盖。 |
| 缓存控制器 | 可选 哈佛内存架构 ,配备**写通(Write-through)**指令缓存和数据缓存。缓存大小可独立配置,范围为 4KB 至 32KB。 |
| 紧耦合存储器 (TCM) | 可选配 TCM,适用于对确定性或延迟要求极高、不适合使用缓存的应用(例如中断服务例程代码及需密集处理的数据)。Cortex-R52 最多支持 3 个 TCM ,每个最大可配置为 1MB。 |
| 通用中断控制器 (GIC) | 全集成 GIC ,支持复杂的基于优先级的中断处理,管理标准中断(IRQ )和快速中断(FIQ )输入。处理器包含低延迟中断技术 ,允许长周期多周期指令被中断并重启。在特定情况下,会延迟冗长的内存访问。可配置支持 32 至 960 个中断 ,包括可在多核间路由的软件生成中断(SGI)。 |
| 内存保护单元 (MPU) | 一级 MPU (Level 1) 为标准配置,二级 MPU (Level 2) 为可选配置。 • 一级 MPU 最多支持 24 个区域 ,可配置最小 64 字节 的区域,粒度为 64 字节。 • 可选的二级 MPU 运行在 EL2,同样支持最多 24 个区域,最小粒度 64 字节。 • EL0/EL1 执行的访问将同时查询两级 MPU,并采用两者中权限限制最严格 的属性组合。 • EL2 执行的访问仅查询二级 MPU。 |
| 浮点单元 (FPU) | 支持两种 FPU 选项: 1. 仅单精度:32 个 32 位单精度寄存器。 2. 双精度(Advanced SIMD):32 个 64 位或 16 个 128 位双精度寄存器。 FPU 针对单精度和双精度计算进行了优化,支持加、减、除、乘、乘加、平方根、定点与浮点转换及浮点常数指令。 |
| 高级 SIMD (NEON) | 当选配双精度浮点时,可选配支持整数或单精度结果的高级 SIMD 单元。 |
| 纠错码 (ECC) | 为缓存和 TCM 内存提供**单比特纠错、双比特检错(SECDED)**功能。所有总线接口均支持 ECC。单比特软错误由处理器自动纠正,并全面灵活地支持硬错误管理。 |
| 端口保护 | 可选端口保护功能,为二级接口(包括数据和控制地址)启用 ECC。 |
| 主端口 | 128 位 AMBA AXI-4 总线管理器端口,用于二级内存和外设访问,带 ECC 保护。 |
| TCM 访问端口 | 128 位 AMBA AXI-4 总线从属端口,用于低延迟访问 TCM,支持处理器内外的高速数据流传输,带可选保护。 |
| 低延迟外设端口 (LLPP) | 专用 32 位 AMBA AXI 端口 ,支持 4MB 可寻址范围,用于将延迟敏感型外设与处理器更紧密地集成,带可选保护。 |
| 闪存接口端口 | 每核专用的 128 位 AMBA AXI 端口,用于将延迟敏感的闪存紧密集成到处理器簇内的特定内核,ECC 保护可配置为 128 位或 64 位块大小。 |
| 总线互连保护 | 可选附加保护,防止互连交换矩阵中的错误,并提供端到端的传输保护。 |
| 调试 (Debug) | 提供调试访问端口 (DAP) 。其功能可通过 CoreSight 调试和跟踪技术进行扩展。 |
| 跟踪 (Trace) | Cortex-R52 包含 CoreSight 嵌入式跟踪宏单元 (ETM),可配置为每个内核独占或簇内内核共享。 |