yolov11_ocsort_distance_tensorrt
使用YOLOv11和OCSort进行多类别目标跟踪,并集成单目相机测距功能,适用于交通场景目标检测、跟踪与距离估计。(基于TensorRT框架,C++实现)
Github链接:https://github.com/zhahoi/yolov11_ocsort_distance_tensorrt
写在前面
之前尝试过使用YOLOv11和DeepSort实现行人跟踪,亲自实现后发现DeepSort这个算法的局限性还是挺大的。(yolov11_deepsort_ncnn)一方面使用DeepSort进行目标追踪需要另外训练出一个模型,增加推理时间;另一方面,只能跟踪单类别的目标。
最近在网上检索合适的目标跟踪算法时,发现了一个除了ByteTracker和DeepSort之外的另一种目标跟踪算法。以下是三者算法优劣比较:
| 特性 / 算法 | DeepSort | ByteTrack | OCSort |
|---|---|---|---|
| 基本思想 | 基于检测 + Kalman Filter + 外观特征匹配 | 基于检测 + Kalman Filter + IoU 匹配 | 基于检测 + Kalman Filter + 区分可见/遮挡状态的匹配 |
| 外观特征依赖 | 强依赖 CNN 特征,处理遮挡能力较强 | 可选外观特征,主要依赖运动信息 | 默认不依赖外观特征,结合可见性/遮挡信息匹配 |
| 遮挡处理 | 使用外观特征缓解遮挡 | 基于运动信息,遮挡期间易丢失 | 明确区分"可见/遮挡轨迹",遮挡后重新关联能力更强 |
| 误匹配率 | 中等,遮挡严重时可能误关联 | 较低,通过低分检测补充轨迹 | 更低,通过 Occlusion-aware Matching 减少误关联 |
| 速度 | 中等,外观特征提取耗时 | 高速,轻量级 | 高速,计算轻量,且无需外观特征 |
| 轻量级 / 部署 | 较重,需要特征提取网络 | 轻量级,易部署 | 轻量级,简单 Kalman + 区分可见性逻辑 |
| 跟踪稳定性 | 遮挡多时轨迹易断裂 | 遮挡轻微影响,短时遮挡易断 | 遮挡追踪能力更稳定,尤其是短期遮挡 |
| 对低分检测的利用 | 一般忽略低分框 | 使用低分框补充轨迹 | 可以智能利用低分检测框,提高遮挡恢复率 |
| 主要优势 | 对外观变化敏感,遮挡时表现一般 | 快速,低复杂度,低误匹配 | 遮挡处理更智能、误匹配少、速度快、轻量化 |
【基本说明】 使用的目标检测为YOLOv11s版本,OCSort算法参考自官方的 OC_SORT 项目。在本项目中,几乎没有对OCSort的代码部分进行修改,主要修改来自融合目标检测、目标跟踪与单目测距三个部分。
【注】
- 本项目还有对应的ncnn框架实现,指路:yolov11_ocsort_ncnn
- 本项目YOLOv11目标检测推理修改自本人的另一个YOLOv8的TensorRT实现,指路:YOLOv8_TensorRT_Jetson
- 本项目可以将YOLOv11推理的前后处理放到CUDA中实现,推理速度有很大提升,推理测试可以到200帧左右。
- 本项目是在我之前实现的项目(yolov11_ocsort_tensorrt)目标跟踪的基础上,增加单目测距的功能。
- 本项目的单目测距算法,借鉴于项目Monocular_Distance_Velocity_Detect,创建本项目的原因也是为了学习单目相机测距的原理。
单目测距模块
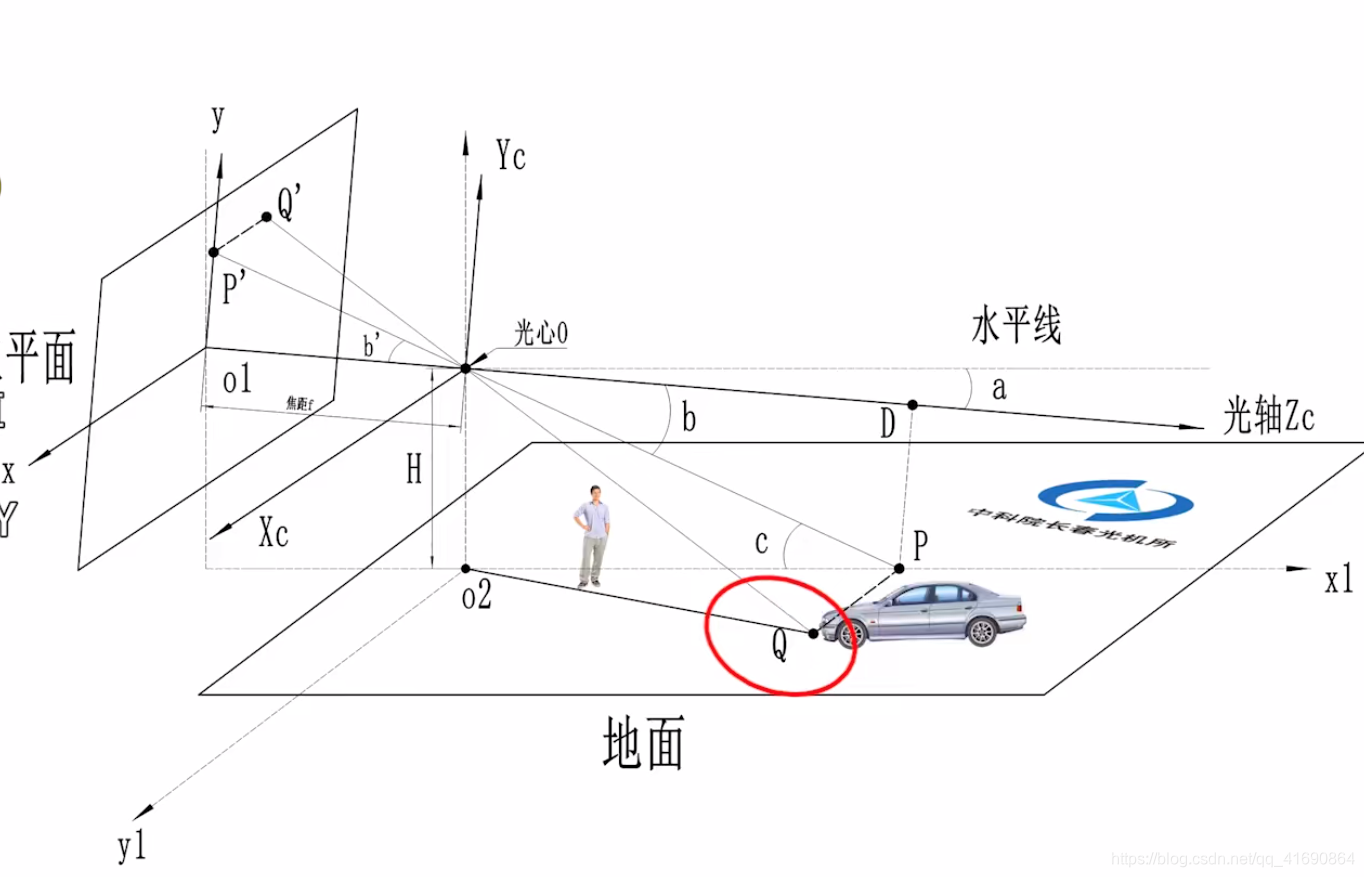
原理
单目测距基于针孔相机模型 + 地面平面约束,利用相机内参、外参以及相机安装高度和俯仰角,将检测到的目标 bbox 底部像素坐标反投影到世界坐标系,从而估算目标到相机的距离。
检测 bbox (u, v, w, h)
│ 取底部中心点 v1 = v + h/2
▼
像素坐标系
│ 地面几何约束求深度 Z = Hc / sin(θc) * cos(θb)
│ 相机坐标 Pc = Z · K⁻¹ · [u1, v1, 1]ᵀ
▼
相机坐标系
│ Pw = T⁻¹ · [Xc, Yc, Zc, 1]ᵀ
▼
世界坐标系 (Xw, Yw)
│ D = sqrt(Xw² + Yw²)
▼
距离 (m)数学模型详解
前提假设:
- 目标底部接触地面,地面为平面
- 相机安装高度为 H c H_c Hc,俯仰角为 θ a \theta_a θa
- 已知相机内参矩阵 K K K 和外参矩阵 T = R ∣ t T = R \\mid t T=R∣t
Step 1 --- 像素坐标选取
取检测框底部中心点作为目标与地面的接触点:
u 1 = u , v 1 = v + h 2 u_1 = u, \quad v_1 = v + \frac{h}{2} u1=u,v1=v+2h
Step 2 --- 像素点视线角
像素相对于光轴的垂直夹角,加入相机俯仰角:
θ b = arctan ( v 1 − c y f y ) , θ c = θ b + θ a \theta_b = \arctan\!\left(\frac{v_1 - c_y}{f_y}\right), \quad \theta_c = \theta_b + \theta_a θb=arctan(fyv1−cy),θc=θb+θa
Step 3 --- 地面几何约束求深度
由相机高度与视线角的三角几何关系:
Z = H c sin ( θ c ) ⋅ cos ( θ b ) Z = \frac{H_c}{\sin(\theta_c)} \cdot \cos(\theta_b) Z=sin(θc)Hc⋅cos(θb)
⚠️ 当 θ c → 0 \theta_c \to 0 θc→0 时 Z → ∞ Z \to \infty Z→∞,远距离目标对角度误差极其敏感,这是单目测距的固有局限。
Step 4 --- 像素坐标 → 相机坐标
P c = Z ⋅ K − 1 u 1 v 1 1 = Z u 1 − c x f x Z v 1 − c y f y Z P_c = Z \cdot K^{-1} \begin{bmatrix} u_1 \\ v_1 \\ 1 \end{bmatrix} = \begin{bmatrix} Z\,\frac{u_1 - c_x}{f_x} \\ Z\,\frac{v_1 - c_y}{f_y} \\ Z \end{bmatrix} Pc=Z⋅K−1 u1v11 = Zfxu1−cxZfyv1−cyZ
Step 5 --- 相机坐标 → 世界坐标
P w = T − 1 P c 1 P_w = T^{-1} \begin{bmatrix} P_c \\ 1 \end{bmatrix} Pw=T−1Pc1
Step 6 --- 平面距离
D = X w 2 + Y w 2 D = \sqrt{X_w^2 + Y_w^2} D=Xw2+Yw2
模型本质: 该方法不是恢复真实三维结构,而是「单目 + 地面平面假设 + 三角几何约束」,深度由几何模型补偿获得,而非由视差直接恢复。
适用范围: 近中距离目标 / 地面接触目标 / 相机姿态稳定 / 低成本 ADAS 场景
相机参数标定
内参标定(棋盘格)
使用标准棋盘格标定相机内参矩阵 K 和畸变系数,推荐使用 OpenCV 的 calibrateCamera 函数完成。
外参标定(棋盘格平放地面)
将棋盘格平放于地面 ,利用 cv2.solvePnP 求解相机相对于地面坐标系的旋转矩阵 R 和平移向量 t,构成 4×4 外参矩阵 T。
python
import cv2
import numpy as np
CHESSBOARD_SIZE = (8, 6) # 内角点数量
SQUARE_SIZE = 0.05 # 格子实际大小(米)
# 世界坐标(地面 Z=0)
objp = np.zeros((CHESSBOARD_SIZE[0] * CHESSBOARD_SIZE[1], 3), np.float64)
objp[:, :2] = np.mgrid[0:CHESSBOARD_SIZE[0],
0:CHESSBOARD_SIZE[1]].T.reshape(-1, 2) * SQUARE_SIZE
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, corners = cv2.findChessboardCorners(gray, CHESSBOARD_SIZE, None)
if ret:
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 30, 0.001)
corners = cv2.cornerSubPix(gray, corners, (11, 11), (-1, -1), criteria)
_, rvec, tvec = cv2.solvePnP(objp, corners, K, dist)
R, _ = cv2.Rodrigues(rvec)
T = np.eye(4)
T[:3, :3] = R
T[:3, 3] = tvec.flatten()相机参数文件格式
标定完成后,将内参 K 和外参 T 保存为 OpenCV YAML 格式,放置于 camera_params/camera_parameters.yaml:
yaml
%YAML:1.0
---
K: !!opencv-matrix
rows: 3
cols: 3
dt: d
data: [ fx, 0.0, cx,
0.0, fy, cy,
0.0, 0.0, 1.0 ]
P: !!opencv-matrix
rows: 4
cols: 4
dt: d
data: [ r00, r01, r02, tx,
r10, r11, r12, ty,
r20, r21, r22, tz,
0.0, 0.0, 0.0, 1.0 ]注意:
P字段存储的是 4×4 外参矩阵 T(世界→相机变换),而非投影矩阵。
测距关键参数
在 main.cpp 中根据实际相机安装情况修改以下参数:
cpp
double camera_height = 0.5; // 相机离地高度(米),需实测
double pitch_angle = 2.0 * M_PI / 180.0; // 相机俯仰角(弧度),向下为正,需实测
int image_height = 720; // 图像高度(像素)⚠️
pitch_angle不能为 0,否则目标位于图像中线时会触发除零错误。建议实测相机安装角度。
支持的检测类别
本项目针对交通场景,仅对以下类别进行跟踪和测距:
| class_id | 类别 |
|---|---|
| 0 | person |
| 1 | bicycle |
| 2 | car |
| 3 | motorcycle |
| 5 | bus |
| 7 | truck |
环境配置
- Nvidia Jetson Orin Nx 16
- CUDA 12.6.85
- cuDNN 9.18.0
- TensorRT 10.7.0
- OpenCV 4.10.0
- Eigen3
并不需要和本仓库代码的配置环境保持完全一致,可以根据自己的实际情况调整。
推理设置
-
将本项目拷贝到本地运行环境:
bashgit clone https://github.com/zhahoi/yolov11_ocsort_distance_tensorrt.git -
准备相机参数文件,放置于项目根目录下的
camera_params/文件夹:yolov11_ocsort_distance_tensorrt/ └── camera_params/ └── camera_parameters.yaml -
在仓库中新建
build文件夹,进入后编译:bashmkdir build && cd build cmake .. make -j8 -
进行推理:
bash# 视频推理 ./yolov11_ocsort <video_path> # 视频推理并保存结果 ./yolov11_ocsort <video_path> 1
推理结果
视频推理结果
写在后面
- TensorRT 的 GPU 推理比 NCNN 的 CPU 推理强太多了,有钱真好。
- 单目测距精度依赖相机标定质量和安装参数的准确性,建议认真完成外参标定。
- 本项目中我没有在现实的车上进行测试,也没有对相机经过标定,而是直接借助原始仓库的内容,因为当前的目标是为了学习单目测距的原理。此外,参考的项目中,没有去畸变的操作,因此准确性还是值得存疑的,如果你想要获得一个更好的结果,需要保证相机的内外参准确,对图像进行去畸变再进行后面的测距操作。测量相机的高度和相机安装的俯仰角也很重要。切记。
- 如果有疑问的话,可以开 Issue 提问。如果觉得这个项目还不错的话麻烦给一个 Star 或者 Fork,可以让我开心一整天。
- 某些把我开源的代码拿去打包出售的人能不能去死一死,做个人好嘛。