视觉定位(Visual Grounding):语言描述在图像中的精准锚定
1 什么是视觉定位
视觉定位是视觉-语言跨模态领域的核心基础任务,简单来说,就是根据自然语言描述,在图像里找到对应的目标并标出位置 。
它的标准任务范式十分明确:输入一张图像+一段文本描述,输出目标对应的边界框或感兴趣区域,完成文本语义到视觉空间的精准映射。
和传统目标检测不同,视觉定位不局限于预定义类别,能响应任意自由文本描述,是视觉问答、图像计数、视觉推理等高级任务的底层支撑。
2 传统视觉定位的核心技术
早期视觉定位完全依托目标检测技术,核心依赖两大基础组件:锚点框和非极大值抑制。

2.1 锚点框(Anchor Box)
锚点框是一组预先设定好、拥有不同长宽比的参考边界框,是传统定位模型的基础先验。
模型会将定位任务拆分为两个子问题:
- 分类任务:判断每个锚点框内是否存在目标物体;
- 回归任务:对锚点框的偏移量进行微调,得到更精准的目标边界框。
这种方式降低了定位难度,但过度依赖人工先验,适配性和灵活性较差。
2.2 非极大值抑制(NMS)
同一个目标往往会被多个高度重叠的锚点框重复检测,NMS就是用来剔除冗余框的后处理手段。
其核心流程为:
- 计算所有预测框之间的交并比(IoU);
- 保留置信度得分最高的预测框;
- 剔除与最高分框重叠度超过阈值的其他低分框。
NMS是传统定位的必要步骤,但人工阈值的设定会影响定位精度,也无法实现模型端到端推理。
3 Transformer革新:DETR开启无锚框定位
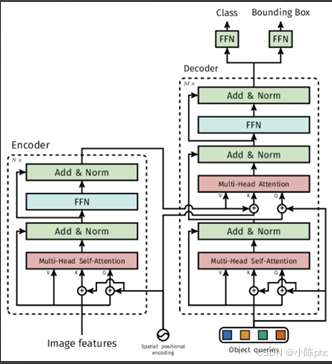
DETR是首个将Transformer应用于目标检测的模型,彻底改变了传统定位的架构逻辑,为视觉定位奠定了Transformer基础。
它的核心突破在于:
- 完全摒弃锚点机制和NMS后处理,实现端到端定位;
- 借助Transformer全局注意力机制,捕捉图像中目标的长距离依赖关系;
- 用目标查询直接预测边界框和类别,消除多阶段误差累积。
DETR证明了Transformer可以直接完成目标定位,为后续跨模态视觉定位提供了核心架构支撑。
4 开放词汇定位:GLIP统一检测与定位
GLIP首次将目标检测和视觉定位任务统一,引入语言监督机制,实现了开放词汇定位的关键突破。
它的核心创新是:
- 把"检测预定义类别"拓展为"寻找文本描述的任意目标";
- 采用大规模图像-文本对齐数据预训练,让模型学习文本与视觉区域的映射关系;
- 支持开放词汇定位,即便训练时未见过某类标签,也能根据文本描述完成定位。
GLIP确立了语言引导视觉定位的技术路线,让定位从封闭世界走向开放世界。
5 零样本定位SOTA:Grounding DINO
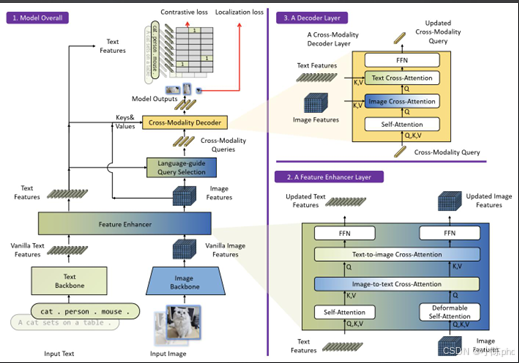
Grounding DINO是当前开放词汇视觉定位的顶尖模型,融合了GLIP和DINO的架构优势,零样本泛化能力极强。
其核心工作机制包括:
- 特征增强模块:对文本和视觉特征联合优化,提升跨模态匹配精度;
- 语言引导查询选择:依据文本特征筛选视觉查询,让模型精准聚焦目标区域;
- 联合损失函数:结合对比损失与定位损失,优化开放场景下的定位效果。
凭借这些设计,Grounding DINO成为视觉定位领域的主流基准模型。
6 多模态与时空定位升级
6.1 ViP-LLaVA:定位融入通用大模型
ViP-LLaVA将视觉定位能力集成到LLaVA大语言模型中,让模型从单纯"画框"升级为能定位、能推理、能对话 的一体化多模态模型,标志着视觉定位成为通用多模态智能的基础能力。

6.2 UniVG-R1:视频时空同步定位
UniVG-R1是面向视频场景的时空同步定位模型,解决了静态图像定位无法适配时序变化的问题。

它支持:
- 查找多图中的共性目标;
- 跨帧检索相似目标;
- 跟踪指定目标的时空位置。
在多个视频定位基准测试中,UniVG-R1的零样本性能远超同类模型,成为时序视觉定位的SOTA方案。
7 视觉定位核心评估指标
7.1 交并比(IoU)
IoU是衡量定位精度的基础指标,用于计算预测框与真实框的重叠程度,公式为:
IoU = 预测框与真实框的交集面积 / 预测框与真实框的并集面积
IoU取值在0到1之间,数值越接近1,代表定位越精准。
7.2 平均精度均值(mAP)
mAP是视觉定位的核心综合指标,综合考量模型的精确率和召回率。
精确率指预测框中正确框的比例,召回率指真实目标被成功检出的比例,mAP是所有类别平均精度的均值,能全面反映模型定位能力。
8 视觉定位主流数据集
8.1 Flickr30k Entities
包含31783张日常场景图像,每张图像配有5条人工标注描述,句子中的名词短语与图像目标边界框精准对齐,是通用视觉定位的基础评测数据集。
8.2 RefCOCO系列
基于MS COCO数据集构建,分为三个子集:
- RefCOCO:基础指代描述定位;
- RefCOCO+:禁止使用位置词,侧重纯语义描述;
- RefCOCOg:采用更长更详细的描述语句,测试复杂语义定位能力。
9 总结
视觉定位完成了自然语言到图像空间的精准锚定,是跨模态感知的关键基石。
从传统的锚点+NMS架构,到DETR的无锚框Transformer革新,再到GLIP、Grounding DINO的开放词汇突破,以及UniVG-R1的视频时空定位升级,视觉定位不断突破封闭场景限制,向开放世界、动态时序、多模态融合方向发展。
如今,视觉定位已广泛应用于图像标注、智能交互、机器人感知、视频监控等场景,成为多模态AI落地的核心技术之一。