Qwen3.5系列模型中文输入思维链输出英文的解决方案与效果分析
1> 问题描述
在部署了Qwen3.5 系列模型之后,就会发现在我们上传中文prompt之后,Chain of Though 也就是
<think>的部分会出现英文思考的问题。英文思维链的效果没多好,但是token消耗很高,而且时间很慢。所以我们需要解决思维链吐英文这个问题,然后顺便测一下中文思维链和英文思维链的效果和消耗上的差异
(1) 问题复现
先用uv pip安装最新版的vllm
shell
uv pip install vllm --torch-backend=auto --extra-index-url https://wheels.vllm.ai/nightly下载完成之后直接启动模型
shell
vllm serve /path/to/models/Qwen3.5-35B-A3B --port 8000 --tensor-parallel-size 8 --max-model-len 262144 --reasoning-parser qwen3 模型启动完成后,我们使用任意chatbot测试模型的思维链输出 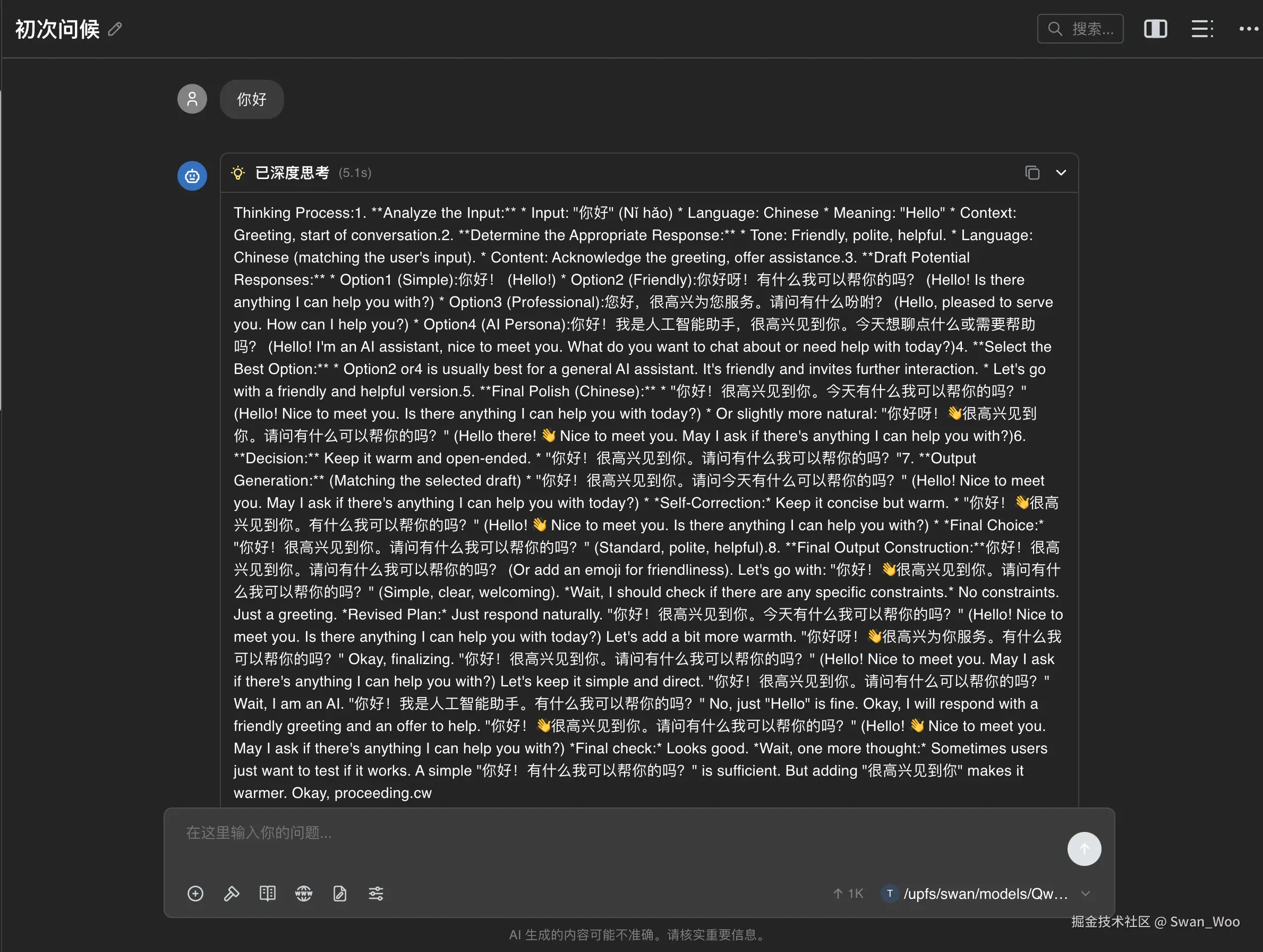
2> 解决方案
方案来源
正好此问题在Qwen3.5的仓库中,有人提出相关的Issues
源Issue链接
https://github.com/QwenLM/Qwen3.5/issues/35
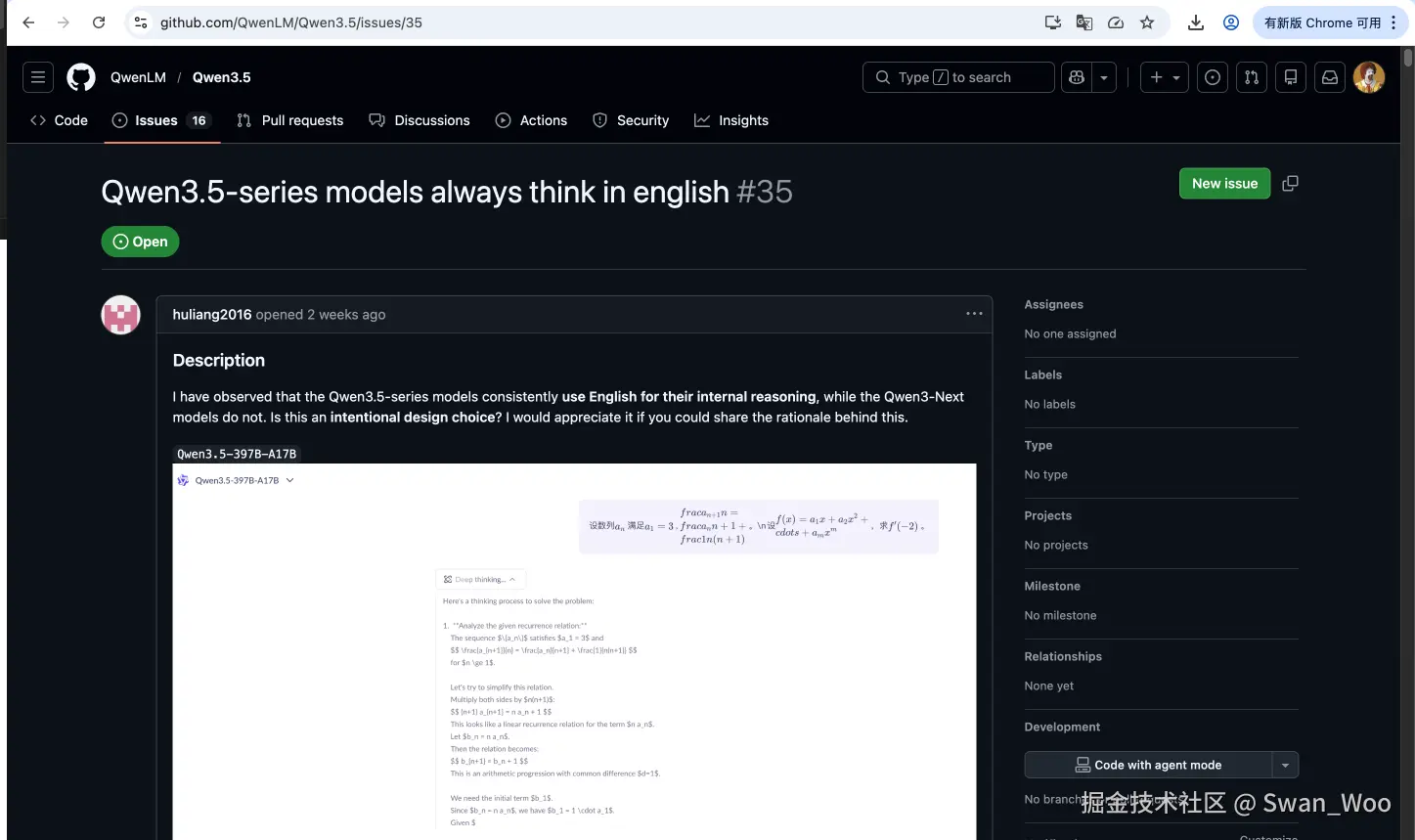
那么在这个Issue中往下滑动可以找到roj234的解决方案
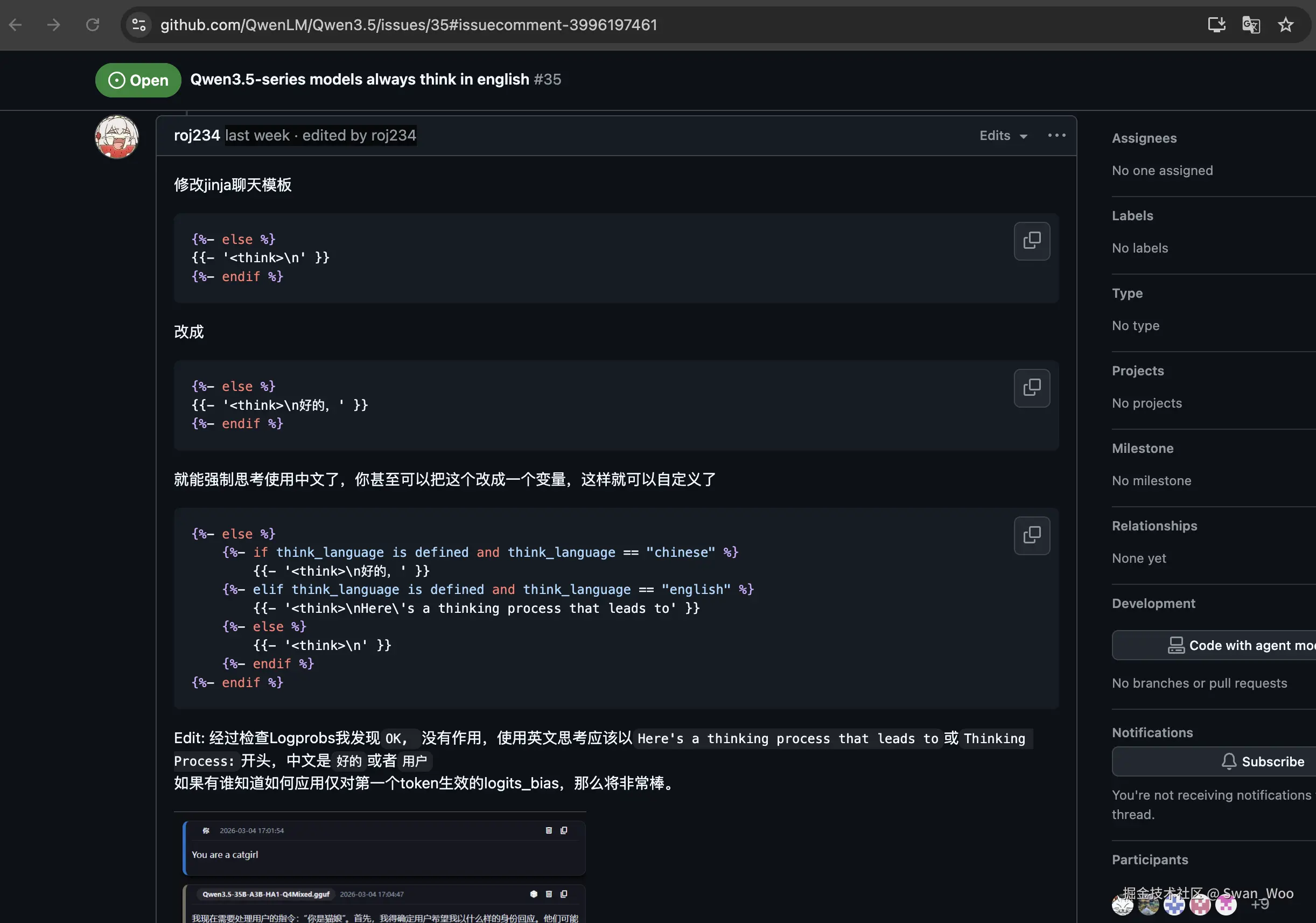
解决过程
-
下载模型之后进入到模型文件
shellpip install modelscope cd /path/to/models modelscope download --model Qwen/Qwen3.5-35B-A3B cd /path/to/models/Qwen3.5-35B-A3B -
修改
chat_template.jinja文件内的模版shellvim /path/to/models/Qwen3.5-35B-A3B/chat_template.jinja打开之后定位到152行,将
{{- '<think>\n' }}改为{{- '<think>\n首先' }}text146 {%- endfor %} 147 {%- if add_generation_prompt %} 148 {{- '<|im_start|>assistant\n' }} 149 {%- if enable_thinking is defined and enable_thinking is false %} 150 {{- '<think>\n\n</think>\n\n' }} 151 {%- else %} 152 {{- '<think>\n首先' }} 153 {%- endif %} 154 {%- endif %}:wq保存 -
使用
vllm启动模型进行推理shellvllm serve /path/to/models/Qwen3.5-35B-A3B --port 8000 --tensor-parallel-size 8 --max-model-len 262144 --reasoning-parser qwen3随机打开一个chatbot测试思维链,发现已经使用中文思维链思考
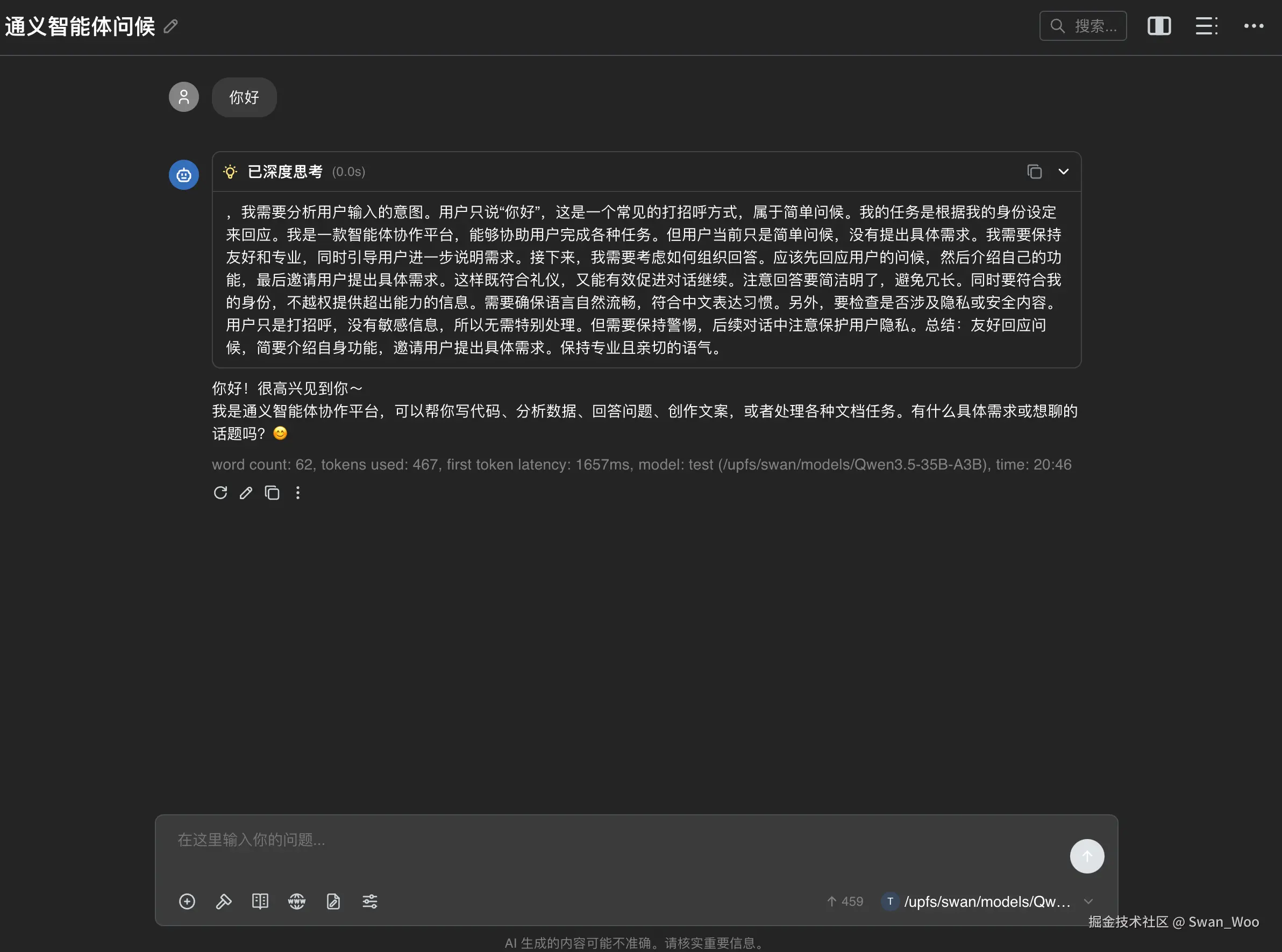
中文思维链vs英文思维链
在中英文思维链效果的测试中,我使用了55条弱智吧数据集来进行。
一共做了三种测试
- 最长公共子序列的测试,用固定的标准查看模型输出和标准输出之间的重合度
- gpt-5.4 作为评委,使用好或坏来判断答案,最终通过比例来判断模型的好坏
- 最后我计算了token数和字词数,也就是在中英文思维链情况下的token数差异,分别计算了思维链的token和结果的token,看看那种情况下的模型效率最高。然后还计算了字词数,可以看出模型输出的压缩率
脚本详细
python
#!/usr/bin/env python3
"""Async evaluation with separate reasoning/content stats + batched judging."""
from __future__ import annotations
import argparse
import asyncio
import json
import os
import re
import statistics
import time
import urllib.error
import urllib.request
from pathlib import Path
from typing import Any, Dict, List, Tuple
def build_api_url(base_url: str, path: str) -> str:
base = base_url.rstrip("/")
if base.endswith("/v1"):
return f"{base}{path}"
return f"{base}/v1{path}"
def post_json(url: str, payload: Dict[str, Any], timeout: int = 120, api_key: str | None = None) -> Dict[str, Any]:
data = json.dumps(payload).encode("utf-8")
headers = {"Content-Type": "application/json"}
if api_key:
headers["Authorization"] = f"Bearer {api_key}"
req = urllib.request.Request(url, data=data, headers=headers, method="POST")
try:
with urllib.request.urlopen(req, timeout=timeout) as resp:
return json.loads(resp.read().decode("utf-8"))
except urllib.error.HTTPError as e:
body = ""
try:
body = e.read().decode("utf-8", errors="replace")
except Exception:
body = "<no body>"
raise RuntimeError(f"HTTP {e.code} for {url}: {body}") from e
def get_models(base_url: str, api_key: str | None = None) -> List[str]:
url = build_api_url(base_url, "/models")
req = urllib.request.Request(
url,
headers={"Authorization": f"Bearer {api_key}"} if api_key else {},
method="GET",
)
with urllib.request.urlopen(req, timeout=30) as resp:
data = json.loads(resp.read().decode("utf-8"))
return [m["id"] for m in data.get("data", [])]
def load_jsonl(path: Path) -> List[Dict[str, Any]]:
rows: List[Dict[str, Any]] = []
with path.open("r", encoding="utf-8") as f:
for line in f:
line = line.strip()
if line:
rows.append(json.loads(line))
return rows
def percentile(values: List[float], p: float) -> float:
if not values:
return 0.0
if len(values) == 1:
return values[0]
xs = sorted(values)
k = (len(xs) - 1) * p
f = int(k)
c = min(f + 1, len(xs) - 1)
if f == c:
return xs[f]
return xs[f] + (xs[c] - xs[f]) * (k - f)
def build_tokenizer(kind: str):
if kind == "jieba":
try:
import jieba # type: ignore
def tok(text: str) -> List[str]:
toks = [t.strip() for t in jieba.lcut(text)]
return [t for t in toks if t and not t.isspace()]
return tok, "jieba"
except Exception:
pass
pattern = re.compile(r"[\u4e00-\u9fff]|[A-Za-z]+(?:'[A-Za-z]+)?|\d+(?:\.\d+)?")
def tok(text: str) -> List[str]:
return pattern.findall(text)
return tok, "regex_mixed"
def lcs_len(a: str, b: str) -> int:
if not a or not b:
return 0
dp = [0] * (len(b) + 1)
for ca in a:
prev = 0
for j, cb in enumerate(b, start=1):
cur = dp[j]
if ca == cb:
dp[j] = prev + 1
else:
dp[j] = max(dp[j], dp[j - 1])
prev = cur
return dp[-1]
def char_overlap_metrics(pred: str, ref: str) -> Tuple[float, float, float]:
lcs = lcs_len(pred, ref)
p = lcs / max(len(pred), 1)
r = lcs / max(len(ref), 1)
f1 = (2 * p * r / (p + r)) if (p + r) else 0.0
return p, r, f1
def completion_call(
base_url: str,
model: str,
messages: List[Dict[str, str]],
temperature: float,
max_tokens: int | None,
token_param_name: str,
disable_thinking: bool,
use_chat_template_kwargs: bool,
api_key: str | None,
timeout: int,
) -> Dict[str, Any]:
url = build_api_url(base_url, "/chat/completions")
payload: Dict[str, Any] = {
"model": model,
"messages": messages,
"temperature": temperature,
}
if max_tokens is not None:
payload[token_param_name] = max_tokens
if disable_thinking and use_chat_template_kwargs:
payload["chat_template_kwargs"] = {"enable_thinking": False}
t0 = time.time()
resp = post_json(url, payload, timeout=timeout, api_key=api_key)
latency_ms = int((time.time() - t0) * 1000)
msg = resp["choices"][0]["message"]
content = msg.get("content") if isinstance(msg.get("content"), str) else ""
reasoning = msg.get("reasoning") if isinstance(msg.get("reasoning"), str) else ""
return {
"content": content.strip(),
"reasoning": reasoning.strip(),
"finish_reason": resp["choices"][0].get("finish_reason"),
"usage": resp.get("usage", {}) if isinstance(resp.get("usage"), dict) else {},
"latency_ms": latency_ms,
}
async def generate_one(
sem: asyncio.Semaphore,
loop: asyncio.AbstractEventLoop,
args: argparse.Namespace,
model: str,
row: Dict[str, Any],
tokenize,
) -> Dict[str, Any]:
q = row["text"]
ref = row["answer"]
messages = [
{
"role": "system",
"content": "你是一个理性、礼貌的中文助手。对于可能是玩笑的问题,先简短识别其幽默性,再给出准确、清晰、不过度冗长的事实解释。",
},
{"role": "user", "content": q},
]
try:
async with sem:
resp = await loop.run_in_executor(
None,
lambda: completion_call(
base_url=args.base_url,
model=model,
messages=messages,
temperature=args.temperature,
max_tokens=None if args.no_max_tokens else args.max_tokens,
token_param_name="max_tokens",
disable_thinking=not args.enable_thinking,
use_chat_template_kwargs=True,
api_key=args.api_key,
timeout=args.timeout,
),
)
except Exception as e:
resp = {
"content": "",
"reasoning": "",
"finish_reason": "error",
"usage": {},
"latency_ms": 0,
"error": str(e),
}
content = resp.get("content", "")
reasoning = resp.get("reasoning", "")
cp, cr, cf1 = char_overlap_metrics(content, ref)
content_words = tokenize(content)
reasoning_words = tokenize(reasoning)
usage = resp.get("usage", {})
completion_tokens = float(usage.get("completion_tokens", 0) or 0)
content_token_est = float(len(content_words))
reasoning_token_est = float(len(reasoning_words))
total_est = content_token_est + reasoning_token_est
# Allocate completion tokens between reasoning/content by estimated ratio.
if total_est > 0:
content_completion_tokens_est = completion_tokens * (content_token_est / total_est)
reasoning_completion_tokens_est = completion_tokens * (reasoning_token_est / total_est)
else:
content_completion_tokens_est = 0.0
reasoning_completion_tokens_est = 0.0
return {
"id": row.get("id"),
"question": q,
"reference": ref,
"prediction": content,
"reasoning": reasoning,
"finish_reason": resp.get("finish_reason"),
"usage": usage,
"latency_ms": resp.get("latency_ms", 0),
"error": resp.get("error"),
"char_precision": cp,
"char_recall": cr,
"char_f1": cf1,
"content_chars": len(content),
"reasoning_chars": len(reasoning),
"content_words": len(content_words),
"reasoning_words": len(reasoning_words),
"content_token_est": content_token_est,
"reasoning_token_est": reasoning_token_est,
"content_completion_tokens_est": content_completion_tokens_est,
"reasoning_completion_tokens_est": reasoning_completion_tokens_est,
"author_type": row.get("author_type"),
}
def parse_judge_json(raw: str) -> List[Dict[str, Any]]:
try:
obj = json.loads(raw)
if isinstance(obj, list):
return [x for x in obj if isinstance(x, dict)]
if isinstance(obj, dict) and isinstance(obj.get("items"), list):
return [x for x in obj["items"] if isinstance(x, dict)]
except json.JSONDecodeError:
pass
s = raw.find("[")
e = raw.rfind("]")
if s != -1 and e != -1 and e > s:
try:
obj = json.loads(raw[s : e + 1])
if isinstance(obj, list):
return [x for x in obj if isinstance(x, dict)]
except json.JSONDecodeError:
pass
return []
def normalize_good_bad(v: Any) -> str:
if isinstance(v, str):
s = v.strip().lower()
if s in ("好", "good", "yes", "true", "1", "pass"):
return "好"
if s in ("坏", "bad", "no", "false", "0", "fail"):
return "坏"
if isinstance(v, (int, float)):
return "好" if float(v) > 0 else "坏"
return "坏"
async def judge_one(
sem: asyncio.Semaphore,
loop: asyncio.AbstractEventLoop,
args: argparse.Namespace,
row: Dict[str, Any],
) -> Dict[str, Any]:
base_url = args.judge_base_url or args.base_url
system = (
"你是严格的中文问答评测器。只输出JSON对象,不要输出其他文本。"
"每个维度只能是"好"或"坏"。"
)
user = (
"评估如下样本并输出JSON:"
+ json.dumps(
{
"id": row["id"],
"question": row["question"],
"reference": row["reference"],
"candidate": row["prediction"],
},
ensure_ascii=False,
)
)
try:
async with sem:
resp = await loop.run_in_executor(
None,
lambda: completion_call(
base_url=base_url,
model=args.judge_model,
messages=[{"role": "system", "content": system}, {"role": "user", "content": user}],
temperature=0,
max_tokens=400,
token_param_name="max_completion_tokens",
disable_thinking=True,
use_chat_template_kwargs=False,
api_key=args.judge_api_key,
timeout=args.timeout,
),
)
raw = resp.get("content", "")
obj = None
try:
obj = json.loads(raw)
except json.JSONDecodeError:
s = raw.find("{")
e = raw.rfind("}")
if s != -1 and e != -1 and e > s:
try:
obj = json.loads(raw[s : e + 1])
except json.JSONDecodeError:
obj = None
if not isinstance(obj, dict):
raise ValueError("judge one parse failed")
return {
"humor_recognition": normalize_good_bad(obj.get("humor_recognition")),
"factuality": normalize_good_bad(obj.get("factuality")),
"politeness": normalize_good_bad(obj.get("politeness")),
"usefulness": normalize_good_bad(obj.get("usefulness")),
"overall": normalize_good_bad(obj.get("overall")),
"reason": str(obj.get("reason", "")),
}
except Exception as e:
return {
"humor_recognition": "坏",
"factuality": "坏",
"politeness": "坏",
"usefulness": "坏",
"overall": "坏",
"reason": f"Judge one error: {str(e)[:160]}",
}
async def judge_batch(
sem: asyncio.Semaphore,
loop: asyncio.AbstractEventLoop,
args: argparse.Namespace,
batch: List[Dict[str, Any]],
) -> Dict[int, Dict[str, Any]]:
base_url = args.judge_base_url or args.base_url
system = (
"你是严格的中文问答评测器。仅输出JSON数组。"
"每条样本输出:id, humor_recognition, factuality, politeness, usefulness, overall, reason。"
"其中五个维度只能是'好'或'坏'。"
)
payload_items = []
for r in batch:
payload_items.append(
{
"id": r["id"],
"question": r["question"],
"reference": r["reference"],
"candidate": r["prediction"],
}
)
user = (
"请评估以下样本(数组内每项独立评估)。输出必须是JSON数组,且与输入id一一对应。\n"
+ json.dumps(payload_items, ensure_ascii=False)
)
try:
async with sem:
resp = await loop.run_in_executor(
None,
lambda: completion_call(
base_url=base_url,
model=args.judge_model,
messages=[{"role": "system", "content": system}, {"role": "user", "content": user}],
temperature=0,
max_tokens=args.judge_max_tokens,
token_param_name="max_completion_tokens",
disable_thinking=True,
use_chat_template_kwargs=False,
api_key=args.judge_api_key,
timeout=args.timeout,
),
)
except Exception as e:
return {
int(r["id"]): {
"humor_recognition": "坏",
"factuality": "坏",
"politeness": "坏",
"usefulness": "坏",
"overall": "坏",
"reason": f"Judge batch error: {str(e)[:160]}",
}
for r in batch
}
items = parse_judge_json(resp.get("content", ""))
out: Dict[int, Dict[str, Any]] = {}
for it in items:
try:
idx = int(it.get("id"))
except Exception:
continue
out[idx] = {
"humor_recognition": normalize_good_bad(it.get("humor_recognition")),
"factuality": normalize_good_bad(it.get("factuality")),
"politeness": normalize_good_bad(it.get("politeness")),
"usefulness": normalize_good_bad(it.get("usefulness")),
"overall": normalize_good_bad(it.get("overall")),
"reason": it.get("reason", ""),
}
for r in batch:
idx = int(r["id"])
if idx not in out:
out[idx] = {
"humor_recognition": "坏",
"factuality": "坏",
"politeness": "坏",
"usefulness": "坏",
"overall": "坏",
"reason": "Judge parse missing id",
}
return out
def summarize(records: List[Dict[str, Any]], tokenizer_name: str, max_tokens_val: int | None) -> Dict[str, Any]:
get = lambda k: [float(r.get(k, 0) or 0) for r in records]
precisions = get("char_precision")
recalls = get("char_recall")
f1s = get("char_f1")
prompt_tokens = [float((r.get("usage") or {}).get("prompt_tokens", 0) or 0) for r in records]
completion_tokens = [float((r.get("usage") or {}).get("completion_tokens", 0) or 0) for r in records]
total_tokens = [float((r.get("usage") or {}).get("total_tokens", 0) or 0) for r in records]
lat_ms = get("latency_ms")
content_chars = get("content_chars")
reasoning_chars = get("reasoning_chars")
content_words = get("content_words")
reasoning_words = get("reasoning_words")
content_token_est = get("content_token_est")
reasoning_token_est = get("reasoning_token_est")
content_comp_est = get("content_completion_tokens_est")
reasoning_comp_est = get("reasoning_completion_tokens_est")
out: Dict[str, Any] = {
"samples": len(records),
"generation_max_tokens": max_tokens_val,
"tokenizer": tokenizer_name,
"avg_char_precision": statistics.mean(precisions) if precisions else 0.0,
"avg_char_recall": statistics.mean(recalls) if recalls else 0.0,
"avg_char_f1": statistics.mean(f1s) if f1s else 0.0,
"avg_prompt_tokens": statistics.mean(prompt_tokens) if prompt_tokens else 0.0,
"avg_completion_tokens": statistics.mean(completion_tokens) if completion_tokens else 0.0,
"avg_total_tokens": statistics.mean(total_tokens) if total_tokens else 0.0,
"avg_latency_ms": statistics.mean(lat_ms) if lat_ms else 0.0,
"avg_content_chars": statistics.mean(content_chars) if content_chars else 0.0,
"avg_reasoning_chars": statistics.mean(reasoning_chars) if reasoning_chars else 0.0,
"avg_content_words": statistics.mean(content_words) if content_words else 0.0,
"avg_reasoning_words": statistics.mean(reasoning_words) if reasoning_words else 0.0,
"avg_content_token_est": statistics.mean(content_token_est) if content_token_est else 0.0,
"avg_reasoning_token_est": statistics.mean(reasoning_token_est) if reasoning_token_est else 0.0,
"avg_content_completion_tokens_est": statistics.mean(content_comp_est) if content_comp_est else 0.0,
"avg_reasoning_completion_tokens_est": statistics.mean(reasoning_comp_est) if reasoning_comp_est else 0.0,
"p90_content_chars": percentile(content_chars, 0.9),
"p90_reasoning_chars": percentile(reasoning_chars, 0.9),
"p90_content_words": percentile(content_words, 0.9),
"p90_reasoning_words": percentile(reasoning_words, 0.9),
}
keys = ["humor_recognition", "factuality", "politeness", "usefulness", "overall"]
for k in keys:
vals = []
for r in records:
j = r.get("judge") or {}
v = j.get(k)
if isinstance(v, str) and v.strip() in ("好", "坏"):
vals.append(1.0 if v.strip() == "好" else 0.0)
if vals:
out[f"{k}_good_rate"] = statistics.mean(vals)
return out
async def main_async(args: argparse.Namespace) -> None:
tokenize, tokenizer_name = build_tokenizer(args.tokenizer)
model = args.model
loop = asyncio.get_running_loop()
if args.judge_only:
records = load_jsonl(Path(args.input_file or args.output))
if args.limit > 0:
records = records[: args.limit]
print(f"Judge-only mode: loading {len(records)} records from {args.input_file or args.output}")
else:
models = get_models(args.base_url, api_key=args.api_key)
if not models:
raise RuntimeError("No models found")
model = model or models[0]
rows = load_jsonl(Path(args.dataset))
if args.limit > 0:
rows = rows[: args.limit]
print(f"Model: {model}")
print(f"Samples: {len(rows)}")
print(f"Judge model: {args.judge_model or 'None'}")
sem = asyncio.Semaphore(args.concurrency)
gen_tasks = [generate_one(sem, loop, args, model, row, tokenize) for row in rows]
records = await asyncio.gather(*gen_tasks)
# Batched async judging
if args.judge_model and not args.generate_only:
judge_sem = asyncio.Semaphore(args.judge_concurrency)
if args.judge_no_batch:
one_tasks = [judge_one(judge_sem, loop, args, r) for r in records]
one_res = await asyncio.gather(*one_tasks)
for r, j in zip(records, one_res):
r["judge"] = j
else:
batches: List[List[Dict[str, Any]]] = []
cur: List[Dict[str, Any]] = []
for r in records:
cur.append(r)
if len(cur) >= args.judge_batch_size:
batches.append(cur)
cur = []
if cur:
batches.append(cur)
j_tasks = [judge_batch(judge_sem, loop, args, b) for b in batches]
j_results = await asyncio.gather(*j_tasks)
j_map: Dict[int, Dict[str, Any]] = {}
for x in j_results:
j_map.update(x)
missing_rows: List[Dict[str, Any]] = []
for r in records:
try:
rid = int(r.get("id"))
except Exception:
rid = -1
if rid in j_map:
r["judge"] = j_map[rid]
else:
missing_rows.append(r)
r["judge"] = {
"humor_recognition": "坏",
"factuality": "坏",
"politeness": "坏",
"usefulness": "坏",
"overall": "坏",
"reason": "Judge id missing",
}
# Fallback: if batch parse misses rows, judge them one-by-one.
if missing_rows:
one_tasks = [judge_one(judge_sem, loop, args, r) for r in missing_rows]
one_res = await asyncio.gather(*one_tasks)
by_id = {}
for r, j in zip(missing_rows, one_res):
try:
by_id[int(r.get("id"))] = j
except Exception:
pass
for r in records:
try:
rid = int(r.get("id"))
except Exception:
continue
if rid in by_id:
r["judge"] = by_id[rid]
# Strong fallback: if all rows are still default-bad (likely batch parse/format issue),
# rerun judging one-by-one for every sample.
all_bad = True
for r in records:
j = r.get("judge") or {}
if any((j.get(k) == "好") for k in ["humor_recognition", "factuality", "politeness", "usefulness", "overall"]):
all_bad = False
break
if all_bad and records:
one_tasks = [judge_one(judge_sem, loop, args, r) for r in records]
one_res = await asyncio.gather(*one_tasks)
for r, j in zip(records, one_res):
r["judge"] = j
out_path = Path(args.output)
with out_path.open("w", encoding="utf-8") as f:
for i, r in enumerate(records, start=1):
f.write(json.dumps(r, ensure_ascii=False) + "\n")
print(f"[{i}/{len(records)}] id={r.get('id')} f1={r.get('char_f1', 0):.3f}")
summary = summarize(records, tokenizer_name=tokenizer_name, max_tokens_val=None if args.no_max_tokens else args.max_tokens)
summary.update({"model": model, "dataset": args.dataset, "output": str(out_path), "mode": ("judge_only" if args.judge_only else ("generate_only" if args.generate_only else "full"))})
print("\n=== SUMMARY ===")
print(json.dumps(summary, ensure_ascii=False, indent=2))
def parse_args() -> argparse.Namespace:
p = argparse.ArgumentParser(description="Async eval with separate reasoning/content stats")
p.add_argument("--base-url", default="http://117.50.226.79:8000")
p.add_argument("--api-key", default=os.getenv("OPENAI_API_KEY"))
p.add_argument("--model", default=None)
p.add_argument("--dataset", default="retarded_bar_qa.jsonl")
p.add_argument("--output", default="eval_async_results.jsonl")
p.add_argument("--limit", type=int, default=0)
p.add_argument("--temperature", type=float, default=0.2)
p.add_argument("--max-tokens", type=int, default=512)
p.add_argument("--no-max-tokens", action="store_true")
p.add_argument("--enable-thinking", action="store_true")
p.add_argument("--timeout", type=int, default=180)
p.add_argument("--concurrency", type=int, default=8)
p.add_argument("--tokenizer", default="jieba", choices=["jieba", "regex_mixed"])
p.add_argument("--generate-only", action="store_true", help="only generate, do not judge")
p.add_argument("--judge-only", action="store_true", help="only judge from an existing jsonl file")
p.add_argument("--input-file", default=None, help="input jsonl for --judge-only (default: --output)")
p.add_argument("--judge-base-url", default=None)
p.add_argument("--judge-api-key", default=os.getenv("JUDGE_API_KEY"))
p.add_argument("--judge-model", default=None)
p.add_argument("--judge-batch-size", type=int, default=8)
p.add_argument("--judge-concurrency", type=int, default=4)
p.add_argument("--judge-max-tokens", type=int, default=1200)
p.add_argument("--judge-no-batch", action="store_true", help="disable batch judge, judge one-by-one only")
args = p.parse_args()
if args.generate_only and args.judge_only:
raise SystemExit("--generate-only and --judge-only cannot be used together")
return args
def main() -> None:
args = parse_args()
asyncio.run(main_async(args))
if __name__ == "__main__":
main()运行指令
shell
python3 eval_reasoning_async.py \
--base-url "$BASE_MODEL_URL" \
--dataset retarded_bar_qa.jsonl \
--enable-thinking \
--no-max-tokens \
--concurrency 11 \
--judge-base-url "$JUDGE_MODEL_URL" \
--judge-model gpt-5.4 \
--judge-api-key "$JUDGE_API_KEY" \
--judge-batch-size 11 \
--judge-concurrency 11 \
--output eval_async_full_cn.jsonl运行结果
英文思维链
json
{
"samples": 55,
"generation_max_tokens": null,
"tokenizer": "regex_mixed",
"avg_char_precision": 0.16577816073614296,
"avg_char_recall": 0.2887265682458067,
"avg_char_f1": 0.19098408833538846,
"avg_prompt_tokens": 59.50909090909091,
"avg_completion_tokens": 1470.7636363636364,
"avg_total_tokens": 1530.2727272727273,
"avg_latency_ms": 12797.872727272726,
"avg_content_chars": 178.8909090909091,
"avg_reasoning_chars": 4262.581818181819,
"avg_content_words": 139.23636363636365,
"avg_reasoning_words": 1080.1818181818182,
"avg_content_token_est": 139.23636363636365,
"avg_reasoning_token_est": 1080.1818181818182,
"avg_content_completion_tokens_est": 170.33024395684782,
"avg_reasoning_completion_tokens_est": 1300.4333924067885,
"p90_content_chars": 270.6,
"p90_reasoning_chars": 6433.400000000001,
"p90_content_words": 208.60000000000002,
"p90_reasoning_words": 1575.2,
"humor_recognition_good_rate": 0.8,
"factuality_good_rate": 0.7090909090909091,
"politeness_good_rate": 0.7818181818181819,
"usefulness_good_rate": 0.7454545454545455,
"overall_good_rate": 0.6909090909090909,
"model": "/upfs/swan/models/Qwen3.5-35B-A3B",
"dataset": "retarded_bar_qa.jsonl",
"output": "eval_async_full_en.jsonl",
"mode": "full"
}中文思维链
json
{
"samples": 55,
"generation_max_tokens": null,
"tokenizer": "regex_mixed",
"avg_char_precision": 0.18388051936713234,
"avg_char_recall": 0.30723029579846234,
"avg_char_f1": 0.20795981706432634,
"avg_prompt_tokens": 60.50909090909091,
"avg_completion_tokens": 464.1090909090909,
"avg_total_tokens": 524.6181818181818,
"avg_latency_ms": 4326.381818181818,
"avg_content_chars": 170.74545454545455,
"avg_reasoning_chars": 583.2727272727273,
"avg_content_words": 134.3090909090909,
"avg_reasoning_words": 451.3272727272727,
"avg_content_token_est": 134.3090909090909,
"avg_reasoning_token_est": 451.3272727272727,
"avg_content_completion_tokens_est": 106.05273915881723,
"avg_reasoning_completion_tokens_est": 358.0563517502737,
"p90_content_chars": 281.0,
"p90_reasoning_chars": 918.6,
"p90_content_words": 206.0,
"p90_reasoning_words": 717.2,
"humor_recognition_good_rate": 0.9818181818181818,
"factuality_good_rate": 0.6727272727272727,
"politeness_good_rate": 1.0,
"usefulness_good_rate": 0.8,
"overall_good_rate": 0.6727272727272727,
"model": "/upfs/swan/models/Qwen3.5-35B-A3B",
"dataset": "retarded_bar_qa.jsonl",
"output": "eval_async_full_cn.jsonl",
"mode": "full"
}参数解释
samples: 评测样本数(55 条)。generation_max_tokens: 生成上限 token(null表示未显式限制或用默认值)。tokenizer: 使用的分词器类型(regex_mixed)。avg_char_precision/avg_char_recall/avg_char_f1: 基于"字符级"比对的平均精准率、召回率、F1。avg_prompt_tokens: 平均输入 token 数。avg_completion_tokens: 平均输出 token 数。avg_total_tokens: 平均总 token(输入+输出)。avg_latency_ms: 平均延迟(毫秒)。avg_content_chars/avg_reasoning_chars: 平均"最终回答内容"字符数 / "推理内容"字符数。avg_content_words/avg_reasoning_words: 平均"内容词数" / "推理词数"。avg_content_token_est/avg_reasoning_token_est: 内容/推理的 token 估算值(通常由词数或规则近似得到)。avg_content_completion_tokens_est/avg_reasoning_completion_tokens_est: 在 completion token 中,估算属于内容/推理的部分。p90_content_chars/p90_reasoning_chars: 内容/推理字符数的 P90(90 分位)。p90_content_words/p90_reasoning_words: 内容/推理词数的 P90。humor_recognition_good_rate: 幽默识别"合格"比例。factuality_good_rate: 事实性"合格"比例。politeness_good_rate: 礼貌性"合格"比例。usefulness_good_rate: 有用性"合格"比例。overall_good_rate: 综合"合格"比例。model: 被评测模型路径/名称。dataset: 使用的数据集文件。output: 评测输出文件。mode: 评测模式(full通常表示完整流程评测)。
最需要关注的是:overall_good_rate(整体质量)、factuality_good_rate(事实性)、以及 avg_latency_ms 和 token 开销(成本/速度)。
实验结论
结论:当前这组结果里,英文思维链在
overall_good_rate上略高;中文思维链在成本和时延上显著更优。
- 质量:
overall_good_rate: 英文0.6909> 中文0.6727(英文小幅领先)avg_char_f1: 中文0.2080> 英文0.1910(中文更接近参考答案)
- 成本:
avg_total_tokens: 中文524.6vs 英文1530.3(英文约 2.92 倍)
- 速度:
avg_latency_ms: 中文4326vs 英文12798(英文约 2.96 倍)
- 差异来源:
- 英文思维链显著更长(
avg_reasoning_chars约中文 7.3 倍),但最终结果长度差异较小。
- 英文思维链显著更长(