
摘要:本文是《LLM技术全景》系列第三篇。Transformer是现代大语言模型的基石架构------从GPT到LLaMA,从BERT到ChatGPT,无一例外都基于Transformer。本文将深入解析Transformer的核心组件:Self-Attention(自注意力)机制、多头注意力、位置编码,以及Encoder和Decoder的完整结构。通过配图和代码示例,帮助读者建立对Transformer架构的直观理解。无论你是想理解GPT为何能生成文本,还是想搞懂BERT如何做文本分类,这篇文章都是你的必读基础。
一、引言:Transformer为何重要?
2017年,Google在一篇论文中首次提出了Transformer架构。这篇论文的标题简单直接------《Attention Is All You Need》。
当时,没人能预料到这五个单词会成为一个时代的注脚。
Transformer的意义,在于它彻底解决了RNN(循环神经网络)的两个致命缺陷:
| 问题 | RNN的局限 | Transformer的突破 |
|---|---|---|
| 并行计算 | 顺序计算,无法并行 | 完全并行,训练速度提升数十倍 |
| 长距离依赖 | 梯度消失,难以捕捉长序列依赖 | Self-Attention直接建立任意位置间的联系 |
从此,NLP领域进入了Transformer时代:
2017年:Transformer诞生
2018年:BERT(Encoder-only)刷新11项NLP基准
2018年:GPT-2(Decoder-only)展示惊人生成能力
2020年:GPT-3(175B参数)开启大模型时代
2022年:ChatGPT基于Transformer实现对话革命
2023-2026年:LLaMA、GPT-4、Claude、Gemini...全部基于TransformerTransformer不是一种具体的模型,而是一套架构范式。 理解它,你就能理解当今几乎所有大模型的设计哲学。
二、从RNN到Transformer:为什么要引入Attention?
2.1 RNN的困境
在Transformer出现之前,NLP主要使用RNN(循环神经网络)处理序列数据:
RNN工作流程:
输入序列:[我] [爱] [学习] [机器] [学习]
↓ ↓ ↓ ↓ ↓ ↓
隐藏状态:h0 → h1 → h2 → h3 → h4 → h5
↓
输出:每个位置的隐藏状态(用于分类/生成等任务)问题在于:RNN的信息传递是"链条式"的。
- 要预测第5个词"学习",模型需要依次经过"我→爱→机器"的信息传递
- 这导致早期信息在传递过程中逐渐稀释
- 这就是著名的梯度消失/爆炸问题
即使LSTM(长短记忆网络)和GRU(门控循环单元)有所改进,但根本架构没有变。
2.2 Attention机制的诞生
2015年,Bahdanau等人提出了Attention Mechanism(注意力机制),最初用于机器翻译。
核心思想很简单:不再让Encoder把所有信息压缩成一个固定向量,而是让Decoder在生成每个词时,能够"看到"源序列的所有位置,然后"选择性"地关注相关内容。
传统Seq2Seq(Encoder→固定向量→Decoder):
[我爱你] → [固定向量C] → [I love you]
加入Attention后:
[我爱你] → [上下文向量C₁, C₂, C₃...] → [I love you]
↑ ↑
关注"我爱你" 关注"我爱你"Attention让模型学会"哪里重要就看哪里"。
2.3 Self-Attention:自己注意自己
真正让Transformer爆发的是Self-Attention(自注意力) ,也叫Scaled Dot-Product Attention。
它的创新之处在于:不再区分"源序列"和"目标序列",而是在同一个序列内部建立注意力关系。
RNN的注意力:源序列 → 目标序列(跨序列)
Self-Attention:序列 → 自身(序列内部)
输入序列:[我] [爱] [机器] [学习]
↓
Self-Attention计算:
- "机器"这个词,应该对"学习"赋予高权重(机器学习是固定搭配)
- "我"和"爱"的关联度较低
- 模型自动学习这些关系!这就是Self-Attention的魔力:它让每个词都能直接"看到"序列中的所有其他词,无论距离多远。
三、Self-Attention机制详解
3.1 核心思想:Query、Key、Value
Self-Attention的数学表达看似复杂,但思想很简单------"查字典"。
我们每个人都有三套向量:
- Query(查询):我想知道什么?
- Key(键):我有什么?
- Value(值):我的内容是什么?
注意力计算 = 用Query去Key-Value字典里查询具体流程:
Step 1: 输入词嵌入
[我] → x₁ (768维向量,假设 embedding_dim=768)
[爱] → x₂
[机器] → x₃
[学习] → x₄
Step 2: 生成Q、K、V(通过三个不同的线性变换)
Q = x · W_q (每个词得到一个Query向量)
K = x · W_k (每个词得到一个Key向量)
V = x · W_v (每个词得到一个Value向量)
Step 3: 计算注意力分数(Query和Key做点积)
Q₁ · K₁ Q₁ · K₂ Q₁ · K₃ Q₁ · K₄
Attention = softmax( ----------------- )
√d_k
Step 4: 加权求和,得到输出
Output = Attention weights · V3.2 _scaled_dot_product_attention详解
用一张图展示完整的Self-Attention计算流程:
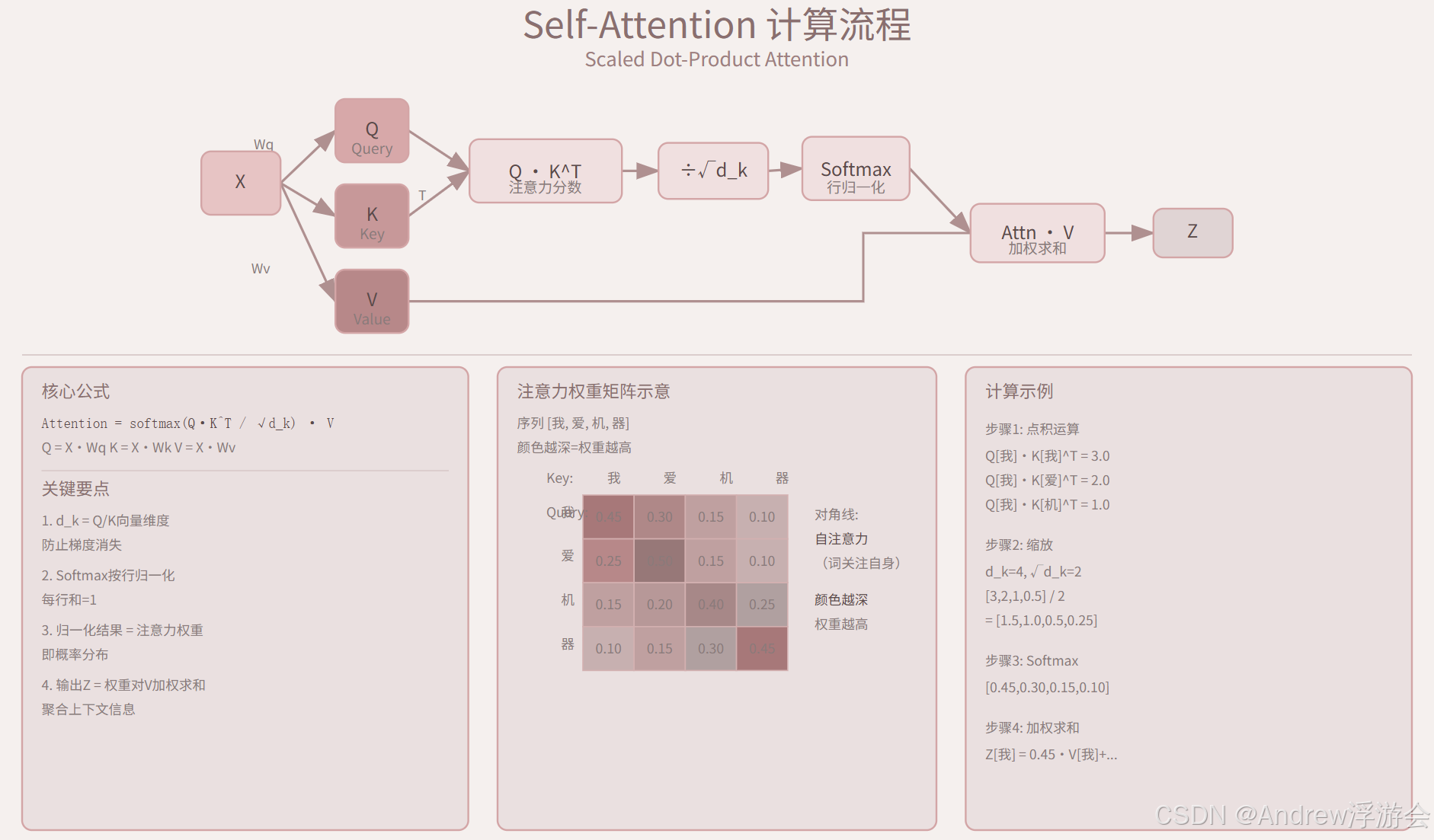
代码实现(PyTorch风格):
python
import torch
import torch.nn.functional as F
import math
def scaled_dot_product_attention(Q, K, V, mask=None):
"""
Q: Query矩阵 [batch, seq_len, d_k]
K: Key矩阵 [batch, seq_len, d_k]
V: Value矩阵 [batch, seq_len, d_v]
"""
d_k = Q.size(-1) # Key的维度
# 1. 计算点积,得到注意力分数
scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(d_k)
# shape: [batch, seq_len, seq_len]
# 2. 应用掩码(如Decoder中的未来信息掩码)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
# 3. Softmax归一化,得到注意力权重
attention_weights = F.softmax(scores, dim=-1)
# shape: [batch, seq_len, seq_len],每行和为1
# 4. 加权求和
output = torch.matmul(attention_weights, V)
# shape: [batch, seq_len, d_v]
return output, attention_weights
# 示例
batch_size, seq_len, d_model = 2, 4, 512
d_k = d_v = 64
Q = torch.randn(batch_size, seq_len, d_k)
K = torch.randn(batch_size, seq_len, d_k)
V = torch.randn(batch_size, seq_len, d_v)
output, weights = scaled_dot_product_attention(Q, K, V)
print(f"输出形状: {output.shape}") # [2, 4, 64]
print(f"注意力权重形状: {weights.shape}") # [2, 4, 4]3.3 为什么要除以√d_k?
防止点积值过大,导致Softmax梯度消失。
假设Q和K的每个维度都是均值为0、方差为1的独立随机变量:
Q · K = Σ(q_i · k_i)
每个 q_i · k_i 的均值=0,方差=1
所以 Q · K 的方差 = d_k
当d_k很大时,点积的方差会很大,
导致Softmax输入值过大,梯度接近于0。
除以 √d_k 后,方差恢复到1,梯度稳定。这就是为什么叫Scaled Dot-Product Attention------"缩放"点积。
四、多头注意力(Multi-Head Attention)
4.1 为什么需要多头?
单一注意力头只能捕捉一种类型的关系。
比如在一个句子中:
- "机器"和"学习"是固定搭配(词法关系)
- "机器学习"和"重要"是主谓关系(句法关系)
- "机器学习"和"未来"是修饰关系(语义关系)
多个注意力头可以同时学习不同类型的依赖关系:
多头注意力 = 多个Self-Attention并行计算,结果拼接
Head₁: 关注"词法搭配"关系
Head₂: 关注"主谓一致"关系
Head₃: 关注"语义相关"关系
...
Headₕ: 关注"指代消解"关系
每个头独立学习,最后拼接:
MultiHead(Q,K,V) = Concat(Head₁, Head₂, ..., Headₕ) · W_O4.2 数学表达
MultiHead(Q, K, V) = Concat(head₁, head₂, ..., head_h) · W^O
其中:
head_i = Attention(Q·W_i^Q, K·W_i^K, V·W_i^V)
参数共享:
W_i^Q, W_i^K, W_i^V: 每个头的投影矩阵 (d_model → d_k)
W^O: 输出投影矩阵 (h·d_v → d_model)4.3 代码实现
python
import torch
import torch.nn as nn
import math
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super().__init__()
assert d_model % num_heads == 0
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads # 每个头的维度
# 三个投影层
self.W_q = nn.Linear(d_model, d_model)
self.W_k = nn.Linear(d_model, d_model)
self.W_v = nn.Linear(d_model, d_model)
self.W_o = nn.Linear(d_model, d_model)
def split_heads(self, x):
"""将最后一个维度分成num_heads个头"""
batch_size, seq_len, d_model = x.size()
x = x.view(batch_size, seq_len, self.num_heads, self.d_k)
return x.transpose(1, 2) # [batch, heads, seq_len, d_k]
def forward(self, Q, K, V, mask=None):
batch_size = Q.size(0)
# 1. 线性投影并分头
Q = self.split_heads(self.W_q(Q))
K = self.split_heads(self.W_k(K))
V = self.split_heads(self.W_v(V))
# 2. 计算注意力
attention_output, attention_weights = scaled_dot_product_attention(Q, K, V, mask)
# 3. 合并多头
attention_output = attention_output.transpose(1, 2).contiguous()
attention_output = attention_output.view(batch_size, -1, self.d_model)
# 4. 最终线性投影
output = self.W_o(attention_output)
return output, attention_weights五、位置编码(Positional Encoding)
5.1 为什么需要位置编码?
Self-Attention本身是"位置无关"的------它把序列当作一个集合,而不是一个有序的数组。
问题示例:
"狗咬人" vs "人咬狗"------意思完全相反!
如果只用Self-Attention,模型可能分不清这两个句子的区别。
原因:Self-Attention对输入的"顺序"不敏感
"狗"和"人"的注意力权重与它们的位置无关5.2 原始Transformer的位置编码
原始论文使用正弦/余弦函数生成位置编码:
PE(pos, 2i) = sin(pos / 10000^(2i/d_model))
PE(pos, 2i+1) = cos(pos / 10000^(2i/d_model))
其中:
- pos: 位置(0, 1, 2, ...)
- i: 维度索引(0, 1, 2, ..., d_model/2)
- d_model: 词嵌入维度为什么用正弦/余弦?
- 周期性:不同频率的正弦波可以区分不同位置
- 线性关系:PE(pos+k) 可以表示为 PE(pos) 的线性函数 → 模型容易学习相对位置
- 可外推:任意长度的序列都能用同样的公式生成位置编码
5.3 位置编码对比:Sinusoidal vs RoPE vs ALiBi

随着大模型发展,位置编码也在演进:
| 位置编码 | 论文 | 年份 | 核心思想 | 代表模型 |
|---|---|---|---|---|
| Sinusoidal | Attention Is All You Need | 2017 | 正弦/余弦函数,绝对位置 | 原始Transformer |
| Relative PE | Self-Attention with Relative Position | 2018 | 相对位置表示 | Transformer-XL |
| RoPE | RoFormer | 2021 | 旋转矩阵,远程衰减 | LLaMA, GLM, ChatGLM |
| ALiBi | Train Short, Test Long | 2022 | 线性偏置,无需学习 | BLOOM,MPT |
RoPE(Rotary Position Embedding) 是当前主流大模型的首选:
RoPE的核心思想:把位置信息"旋转"到Q和K向量中
- 通过旋转矩阵 R(pos) 对Q和K进行变换
- Q·K的注意力分数 = (R(pos_q)·q) · (R(pos_k)·k)
= q · R(pos_q - pos_k) · k
- 结果自然包含相对位置信息!
- 且有"远程衰减"特性:距离越远,注意力越低(符合语言规律)六、Transformer Encoder:完整结构解析
6.1 Encoder的层层堆叠
Transformer的Encoder由N个相同的层堆叠而成(论文中N=6):
Encoder输入:词嵌入 + 位置编码
↓
Layer 1:
├── Multi-Head Self-Attention
├── Residual Connection + LayerNorm
├── Feed Forward Network (FFN)
└── Residual Connection + LayerNorm
↓
Layer 2: (结构同Layer 1)
↓
...
↓
Layer N:
↓
Encoder输出:每个位置的隐藏状态(可用于分类、匹配等任务)6.2 Feed Forward Network(FFN)
每个Encoder层还包含一个前馈网络:
FFN(x) = max(0, x·W₁ + b₁) · W₂ + b₂
本质上是两层全连接:
- 隐藏层:d_model → d_ff(通常 d_ff = 4 × d_model)
- 激活函数:ReLU(或GELU)
- 输出层:d_ff → d_modelFFN的作用:
- 为每个位置独立提供非线性变换能力
- 增加模型的表达能力(Attention是线性变换,FFN引入了非线性)
- 有研究认为FFN类似于"键值记忆",存储知识
6.3 Layer Normalization
每个子层后都有Residual Connection(残差连接) + LayerNorm:
Output = LayerNorm(x + SubLayer(x))
好处:
1. 梯度直接回传,缓解梯度消失
2. 稳定训练
3. 每个子层的输入输出分布一致6.4 Encoder的应用
Encoder-only模型(如BERT) 适合理解任务:
BERT: Bidirectional Encoder Representations from Transformers
- 输入:双句或单句
- 输出:句子/词的表示
- 训练任务:Masked Language Model(完形填空)+ Next Sentence Prediction
- 典型应用:文本分类、命名实体识别、问答系统七、Transformer Decoder:自回归生成的奥秘
7.1 Decoder vs Encoder的关键区别
Decoder和Encoder结构大体相似,但有三个关键区别:
| 区别 | Encoder | Decoder |
|---|---|---|
| 注意力 | Self-Attention(双向) | Masked Self-Attention(单向) |
| Cross Attention | 无 | 有(Query来自Decoder,K/V来自Encoder) |
| 输出 | 每个位置的表示 | 逐个生成下一个词(自回归) |
7.2 Masked Self-Attention:防止"看见未来"
核心问题:训练时,Decoder的输入是"完整的目标序列"------包括正确答案。
如果不加掩码,模型会在预测第3个词时,"偷看"第4、5...个词,这叫做信息泄露。
解决方案:Masked Attention(掩码注意力)
注意力分数矩阵(掩码前):
我 爱 机 器 学 习
我 ✓ ? ? ? ? ?
爱 ✓ ✓ ? ? ? ?
机 ✓ ✓ ✓ ? ? ?
器 ✓ ✓ ✓ ✓ ? ?
学 ✓ ✓ ✓ ✓ ✓ ?
习 ✓ ✓ ✓ ✓ ✓ ✓
✓ = 已计算,? = 不应该看到
掩码后(将右上角设为-inf,Softmax后变为0):
我 爱 机 器 学 习
我 ✓ 0 0 0 0 0
爱 ✓ ✓ 0 0 0 0
机 ✓ ✓ ✓ 0 0 0
器 ✓ ✓ ✓ ✓ 0 0
学 ✓ ✓ ✓ ✓ ✓ 0
习 ✓ ✓ ✓ ✓ ✓ ✓代码实现:
python
def create_causal_mask(seq_len):
"""创建下三角掩码,防止看到未来信息"""
mask = torch.triu(torch.ones(seq_len, seq_len), diagonal=1)
return mask.masked_fill(mask == 1, float('-inf'))
# 在注意力计算时应用
scores = scores + causal_mask # 加上掩码
attention_weights = F.softmax(scores, dim=-1)7.3 Cross Attention:跨越Encoder和Decoder
Decoder中还有一层Cross Attention(交叉注意力):
Cross Attention的Query来自Decoder的当前隐藏状态
K和V来自Encoder的输出
Decoder Layer结构:
├── Masked Self-Attention(只看前面)
├── Cross Attention(看Encoder)
│ Query: Decoder当前状态
│ Key: Encoder所有位置
│ Value: Encoder所有位置
└── FFNCross Attention的作用:
- Decoder在生成每个词时,可以"回顾"源序列的相关信息
- 这就是机器翻译、文本摘要等Seq2Seq任务的基础
7.4 Decoder的应用
Decoder-only模型(如GPT系列) 适合生成任务:
GPT: Generative Pre-trained Transformer
- 输入:前缀提示(Prefix)
- 输出:逐个生成下一个Token
- 训练任务:Next Token Prediction(下一个词预测)
- 典型应用:文本生成、代码补全、对话
GPT的演进:
GPT-1 (2018): 1.17亿参数
GPT-2 (2019): 15亿参数
GPT-3 (2020): 1750亿参数
GPT-4 (2023): 未公开,推测~1.8万亿参数八、经典模型中的Transformer:Encoder vs Decoder vs Encoder-Decoder
8.1 三种架构范式
1. Encoder-only (BERT-style)
输入 → [Encoder堆叠] → 输出
用途:理解任务(分类、序列标注)
代表:BERT, RoBERTa, DeBERTa
2. Decoder-only (GPT-style)
输入 → [Decoder堆叠] → 输出(自回归生成)
用途:生成任务(对话、代码、写作)
代表:GPT-2/3/4, LLaMA, ChatGLM, Claude
3. Encoder-Decoder (T5-style)
输入 → [Encoder堆叠] → [Decoder堆叠] → 输出
用途:Seq2Seq任务(翻译、摘要)
代表:T5, BART, FLAN-T58.2 对比一览
| 架构 | 注意力方向 | 典型任务 | 训练目标 | 代表模型 |
|---|---|---|---|---|
| Encoder-only | 双向 | 分类、NER、问答 | MLM(完形填空) | BERT, RoBERTa |
| Decoder-only | 单向(因果) | 对话、代码、生成 | NTP(预测下一个) | GPT, LLaMA |
| Encoder-Decoder | 双向+单向 | 翻译、摘要、文生图 | Seq2Seq | T5, BART |
8.3 为什么大语言模型选择Decoder-only?
2023年后,几乎所有大语言模型都采用Decoder-only架构。原因有三:
- 工程简单:统一架构,降低系统复杂度
- 生成能力强:自回归生成天然适合文本创作
- 涌现能力:研究表明,足够大的Decoder-only模型会涌现出Few-shot、CoT等能力
注意:Encoder-Decoder并没有消失------它仍是机器翻译、文本摘要等任务的主流方案。
九、总结与展望
9.1 核心要点回顾
| 概念 | 一句话总结 |
|---|---|
| Self-Attention | 用Query-Key-Value在序列内部建立任意位置的联系 |
| 多头注意力 | 多个注意力头并行,捕捉不同类型的依赖关系 |
| 位置编码 | 为Transformer引入序列顺序信息(Sinusoidal → RoPE) |
| Encoder | 双向建模,适合理解任务(BERT) |
| Decoder | 单向生成,适合生成任务(GPT) |
| Cross Attention | 让Decoder能"看到"Encoder的输出 |
9.2 架构演进趋势
2017: Transformer(Encoder+Decoder)
2018: BERT(Encoder-only) GPT-1(Decoder-only)
2019: GPT-2(更大的Decoder)
2020: GPT-3(175B,Prompt learning)
2021: Encoder-Decoder统一(GLM)
2022: ChatGPT(RLHF加持的Decoder)
2023: LLaMA(开源Decoder,7B-70B)
2024: 混合专家爆发(MoE-Decoder)
2025: 效率优化(Grouped Query Attention, FlashAttention)
2026: 长上下文原生支持(1M+ tokens)9.3 下期预告
下一篇文章我们将深入探讨:
- Transformer的工程实现细节:注意力机制的显存优化、算子融合
- LLaMA架构的独特设计:RMSNorm、SwiGLU、RoPE的工程实现
- 大模型训练的核心挑战:梯度检查点、混合精度、分布式策略
参考资料
- Vaswani et al. "Attention Is All You Need" (Transformer原始论文, 2017)
- Devlin et al. "BERT: Pre-training of Deep Bidirectional Transformers" (2018)
- Radford et al. "Language Models are Unsupervised Multitask Learners" (GPT-2, 2019)
- Brown et al. "Language Models are Few-Shot Learners" (GPT-3, 2020)
- Su et al. "RoFormer: Enhanced Transformer with Rotary Position Embedding" (2021)
- Touvron et al. "LLaMA: Open and Efficient Foundation Language Models" (2023)
延伸讨论
思考题:
- 为什么Self-Attention的时间复杂度是O(n²·d)?这对长文本处理有什么影响?
- 如果让你设计一个"既能做理解任务、又能做生成任务"的模型,你会怎么设计架构?
实践作业 :
用PyTorch从零实现一个2层的小型Transformer,训练它完成简单的词性标注任务(POS Tagging)。
本文是《LLM技术全景》系列第3篇。
下期预告:《预训练与微调:大模型如何"学习"》