一、背景
在高并发系统中,如果对 Redis 进行大量写操作,网络 RTT会成为主要性能瓶颈。
举个一个简单场景:
用户给作品打标签,需要给 Redis 的 Tag 热度排行榜(ZSet) 进行计数。
如果每次操作都单独请求 Redis,会产生大量网络开销。如果我们使用 Redis 提供了 Pipeline(管道)机制,允许一次发送多条命令,大幅减少网络往返次数。
举例,假设我们有这样一个业务:
-
一个作品绑定多个 tag
-
Redis 中维护 tag 的 热度排行
Redis 数据结构:
key: gallery:tag:hot
type: ZSET
member = tagId
score = tag热度Java中普通写法(非批量):
java
for (GalleryArtworkTag tag : tagList) {
stringRedisTemplate.opsForZSet()
.incrementScore(RedisConstant.GALLERY_TAG_HOT_KEY, tag.getTagId(), 1);
}执行流程:
java
Java -> Redis (incrby tag1)
Java -> Redis (incrby tag2)
Java -> Redis (incrby tag3)
Java -> Redis (incrby tag4)
...每次操作都会产生:
java
请求 -> Redis
响应 <- Redis可见,系统响应瓶颈就在 网络往返时间。
如果这时候我们使用Pipeline,执行流程变成:
java
Java -> Redis (cmd1 cmd2 cmd3 cmd4 ...)
Redis -> Java (result1 result2 result3 ...)网络往返次数从N 次变为了1 次,大幅提高吞吐量。
二、Redis Pipeline 原理
Redis Pipeline 的核心思想是:
客户端一次性发送多条命令,不等待响应,Redis 执行完后再统一返回结果。
三、Pipeline 写法
1、示例:
我们可以这样子开启管道操作,然后按需写redis命令进行批量操作:
java
stringRedisTemplate.executePipelined((RedisCallback<Object>) connection -> {
// redis命令
return null;
});这里结合我之前给的例子,给出他的实战代码:
java
List<GalleryArtworkTag> tagList = galleryArtworkDTO.getTagIds().stream()
.map(id -> GalleryArtworkTag.builder()
.artworkId(galleryArtworkId)
.tagId(id)
.build())
.collect(Collectors.toList());
if (!tagList.isEmpty()) {
stringRedisTemplate.executePipelined((RedisCallback<Object>) connection -> {
// key
final byte[] keyBytes =
RedisConstant.GALLERY_TAG_HOT_KEY.getBytes(StandardCharsets.UTF_8);
// 批量准备数据
tagList.forEach(tag -> {
final byte[] memberBytes =
String.valueOf(tag.getTagId()).getBytes(StandardCharsets.UTF_8);
// 执行zset的自增操作,这里的RedisCommandsProvider结构是zset
connection.zSetCommands().zIncrBy(keyBytes, 1.0, memberBytes);
});
return null;
});
}2、RedisCommandsProvider 结构:
我们可以看源码,这里提供了很多种,意味着Pipeline 内可以操作 所有 Redis 数据结构:
java
connection.stringCommands()
connection.hashCommands()
connection.listCommands()
connection.setCommands()
connection.zSetCommands()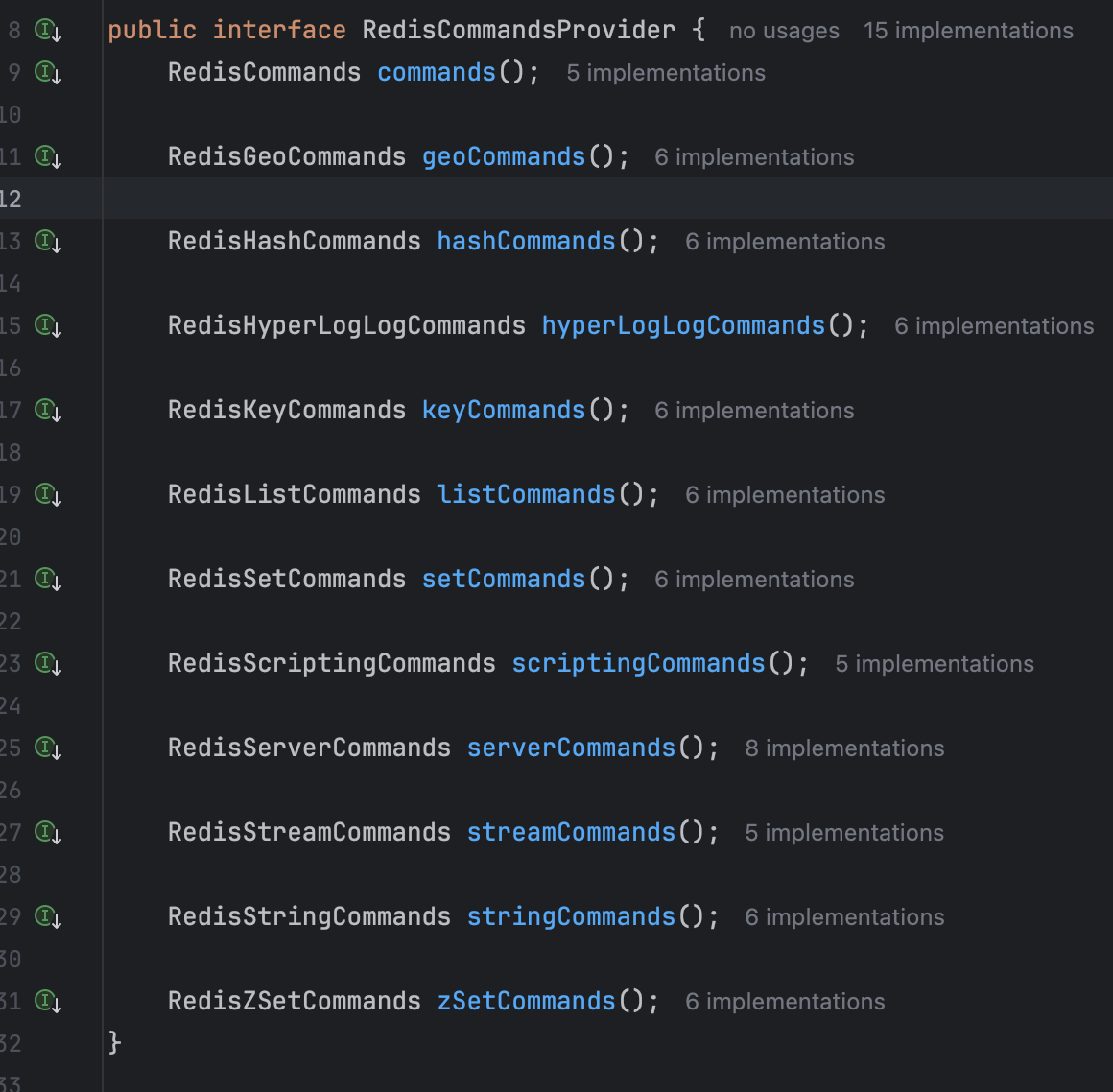
3、各数据结构 Pipeline 写法
String 批量写入
普通写法:
java
for (User user : users) {
stringRedisTemplate.opsForValue().set("user:" + user.getId(), user.getName());
}Pipeline 写法:
java
stringRedisTemplate.executePipelined((RedisCallback<Object>) connection -> {
users.forEach(user -> {
byte[] key = ("user:" + user.getId()).getBytes();
byte[] value = user.getName().getBytes();
connection.stringCommands().set(key, value);
});
return null;
});当然还有一些其他常用的方法:
Hash 批量写入
普通写法:
java
hashOps.put("user:1", "name", "Tom");
hashOps.put("user:1", "age", "18");Pipeline 写法:
java
stringRedisTemplate.executePipelined((RedisCallback<Object>) connection -> {
byte[] key = "user:1".getBytes();
connection.hashCommands().hSet(key, "name".getBytes(), "Tom".getBytes());
connection.hashCommands().hSet(key, "age".getBytes(), "18".getBytes());
return null;
});List 批量写入
普通写法:
java
listOps.rightPush("msg:list", msg);Pipeline 写法:
java
stringRedisTemplate.executePipelined((RedisCallback<Object>) connection -> {
messages.forEach(msg -> {
connection.listCommands().rPush(
"msg:list".getBytes(),
msg.getBytes()
);
});
return null;
});Set 批量写入
普通写法:
java
setOps.add("online:user", userId);Pipeline 写法:
java
stringRedisTemplate.executePipelined((RedisCallback<Object>) connection -> {
users.forEach(userId -> {
connection.setCommands().sAdd(
"online:user".getBytes(),
userId.getBytes()
);
});
return null;
});ZSet 批量写入(排行榜)
普通写法:
java
zSetOps.incrementScore("rank", userId, 1);Pipeline 写法:
java
stringRedisTemplate.executePipelined((RedisCallback<Object>) connection -> {
users.forEach(userId -> {
connection.zSetCommands().zIncrBy(
"rank".getBytes(),
1,
userId.getBytes()
);
});
return null;
});原生写法写入
四、注意
- Pipeline 不保证事务
- 他不是事务,只是批量发送数据
- 如果要保证需要MULTI、EXEC
- 不适合超大批量
- 如果大批量比如10w,客户端内存堆积、Redis阻塞
- 建议是100 ~ 1000 一批