背景
在最近的项目开发中,我遇到了一个常见的需求:Excel导出的列顺序必须与前端页面表格的显示顺序完全一致 。这听起来很简单,但在实际实现中却遇到了不少挑战,特别是当表格包含多级表头 和展开字段时。
今天我就来分享一下这个问题的完整解决方案,希望能帮助到遇到类似问题的开发者。
问题描述
前端页面结构
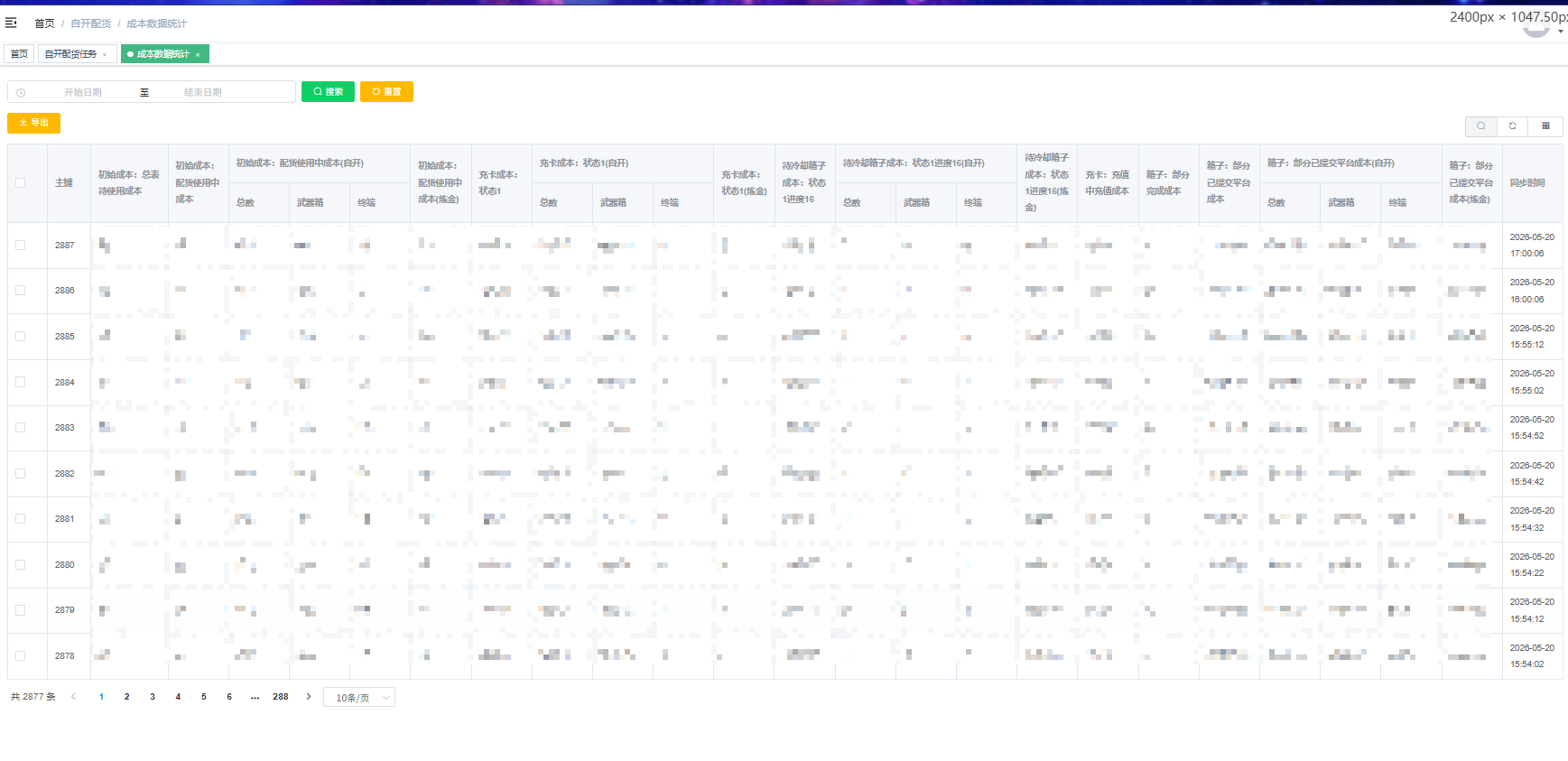
我们的前端页面使用了 Element UI 的表格组件,包含普通列和带子列的展开列:
vue
<el-table-column prop="initCostUsing" label="初始成本:配货使用中成本" />
<el-table-column label="初始成本:配货使用中成本(自开)">
<el-table-column prop="initCostUsingSelf" label="总数" />
<el-table-column prop="initCostUsingSelfCase" label="武器箱" />
<el-table-column prop="initCostUsingSelfTerminal" label="终端" />
</el-table-column>
<el-table-column prop="initCostUsingAlchemy" label="初始成本:配货使用中成本(炼金)" />可以看到,表格中存在交错排列的情况:
- 普通字段
- 展开字段(带二级表头)
- 普通字段
- ...
初始方案的痛点
最初我们使用的导出工具类存在以下问题:
- 字段顺序不可控 :依赖
HashMap遍历顺序,导致导出列顺序随机 - 展开字段只能排在最后:无法实现与普通字段的交错排列
- customHeaders 不参与排序:自定义表头的位置无法控制
解决方案
核心思路
我们需要实现一个能够显式指定字段顺序的导出方法,支持:
- ✅ 普通字段按指定顺序排列
- ✅ 展开字段可以插入到任意位置
- ✅ 展开字段的二级表头顺序可控
- ✅ 与前端页面表头结构完全一致
架构设计
1. 定义列结构
首先,我们定义一个内部类来表示每一列的结构:
java
private static class ColumnDefinition {
String fieldKey; // 字段key
boolean isExpandField; // 是否是展开字段
List<String> subKeys; // 展开字段的子列key列表
String customHeaderName; // 自定义表头名称
ColumnDefinition(String fieldKey, boolean isExpandField,
List<String> subKeys, String customHeaderName) {
this.fieldKey = fieldKey;
this.isExpandField = isExpandField;
this.subKeys = subKeys != null ? subKeys : new ArrayList<>();
this.customHeaderName = customHeaderName;
}
}2. 核心导出方法
java
/**
* 导出嵌套数据到 Web(带展开功能)- 支持自定义表头和显式指定字段顺序
* @param dataList 数据列表
* @param expandFields 展开字段列表
* @param customHeaders 自定义表头映射
* @param mainFieldOrder 主字段顺序列表(可以包含展开字段的key)
* @param response HTTP响应
*/
public static void exportExpandToWebWithCustomHeadersAndOrder(
List<Map<String, Object>> dataList,
List<String> expandFields,
Map<String, String> customHeaders,
List<String> mainFieldOrder,
HttpServletResponse response) throws IOException {
setupExcelResponse(response, "file.xlsx");
try (Workbook workbook = new XSSFWorkbook()) {
Sheet sheet = workbook.createSheet("Sheet1");
// 1. 构建列定义列表(按照 mainFieldOrder 的顺序)
List<ColumnDefinition> columnDefinitions = buildColumnDefinitions(
dataList, expandFields, customHeaders, mainFieldOrder);
// 2. 创建表头
createHeaders(sheet, columnDefinitions, customHeaders);
// 3. 写入数据
writeData(sheet, dataList, columnDefinitions);
// 4. 自动调整列宽并输出
autoSizeColumns(sheet, totalColumns);
workbook.write(response.getOutputStream());
}
}3. 构建列定义列表
这是最关键的部分,我们需要遍历 mainFieldOrder,识别每个字段是普通字段还是展开字段:
java
private List<ColumnDefinition> buildColumnDefinitions(
List<Map<String, Object>> dataList,
List<String> expandFields,
Map<String, String> customHeaders,
List<String> mainFieldOrder) {
List<ColumnDefinition> columnDefinitions = new ArrayList<>();
Set<String> expandFieldSet = new HashSet<>(expandFields);
for (String field : mainFieldOrder) {
if (expandFieldSet.contains(field)) {
// 这是一个展开字段,获取它的子列
List<String> subKeys = getExpandSubKeys(dataList, field);
columnDefinitions.add(new ColumnDefinition(
field, true, subKeys, customHeaders.get(field)));
} else {
// 这是普通字段
columnDefinitions.add(new ColumnDefinition(
field, false, null, field));
}
}
return columnDefinitions;
}4. 创建表头
根据列定义创建两级表头:
java
private void createHeaders(Sheet sheet, List<ColumnDefinition> columnDefinitions,
Map<String, String> customHeaders) {
Row headerRow1 = sheet.createRow(0);
Row headerRow2 = sheet.createRow(1);
int colIndex = 0;
for (ColumnDefinition colDef : columnDefinitions) {
if (colDef.isExpandField) {
// 展开字段:第一行显示自定义表头,第二行显示子列名
int subKeyCount = colDef.subKeys.size();
// 合并第一行的单元格(如果有多个子列)
if (subKeyCount > 1 && colDef.customHeaderName != null) {
CellRangeAddress region = new CellRangeAddress(
0, 0, colIndex, colIndex + subKeyCount - 1);
sheet.addMergedRegion(region);
// 设置边框...
}
// 第一行:自定义表头
Cell cell1 = headerRow1.createCell(colIndex);
cell1.setCellValue(colDef.customHeaderName);
cell1.setCellStyle(headerStyle);
// 第二行:子列名
for (String subKey : colDef.subKeys) {
Cell cell2 = headerRow2.createCell(colIndex);
cell2.setCellValue(subKey);
cell2.setCellStyle(headerStyle);
colIndex++;
}
} else {
// 普通字段:两行显示相同的表头
Cell cell1 = headerRow1.createCell(colIndex);
cell1.setCellValue(colDef.customHeaderName);
cell1.setCellStyle(headerStyle);
Cell cell2 = headerRow2.createCell(colIndex);
cell2.setCellValue(colDef.customHeaderName);
cell2.setCellStyle(headerStyle);
// 合并单元格
CellRangeAddress region = new CellRangeAddress(0, 1, colIndex, colIndex);
sheet.addMergedRegion(region);
colIndex++;
}
}
}5. 写入数据
java
private void writeData(Sheet sheet, List<Map<String, Object>> dataList,
List<ColumnDefinition> columnDefinitions) {
int currentRow = 2;
for (Map<String, Object> data : dataList) {
Row row = sheet.createRow(currentRow);
int colIndex = 0;
for (ColumnDefinition colDef : columnDefinitions) {
if (colDef.isExpandField) {
// 展开字段:从 details 中获取数据
List<Map<String, Object>> expandList =
getExpandData(data, colDef.fieldKey);
if (expandList != null && !expandList.isEmpty()) {
Map<String, Object> expandData = expandList.get(0);
for (String subKey : colDef.subKeys) {
Cell cell = row.createCell(colIndex);
Object value = expandData.get(subKey);
if (value != null) {
cell.setCellValue(value.toString());
}
cell.setCellStyle(dataStyle);
colIndex++;
}
}
} else {
// 普通字段:直接从 map 中获取
Cell cell = row.createCell(colIndex);
Object value = data.get(colDef.fieldKey);
if (value != null) {
cell.setCellValue(value.toString());
}
cell.setCellStyle(dataStyle);
colIndex++;
}
}
currentRow++;
}
}使用示例
Controller 层配置
在 Controller 中,我们只需要按照前端页面的表头顺序配置 mainFieldOrder:
java
@GetMapping(value = "/costStatistics/download")
public void downloadCostStatisticsList(HttpServletResponse response,
CostStatisticsDto dto) throws IOException {
List<Map<String, Object>> list = costStatisticsService.downloadCostStatisticsList(dto);
// 设置自定义表头
Map<String, String> customHeaders = new HashMap<>();
customHeaders.put("initCostUsingSelfDetails", "初始成本:配货使用中成本(自开)");
customHeaders.put("rechargeCompletedCostSelfDetails", "充卡成本:状态1(自开)");
customHeaders.put("boxWaitCoolingCostSelfDetails", "待冷却箱子成本:状态1进度16(自开)");
customHeaders.put("boxPartialSubmittedCostSelfDetails", "箱子:部分已提交平台成本(自开)");
// ⭐ 关键:显式指定字段顺序(包含展开字段的key)
List<String> mainFieldOrder = new ArrayList<>();
mainFieldOrder.add("主键");
mainFieldOrder.add("初始成本:总表待使用成本");
mainFieldOrder.add("初始成本:配货使用中成本");
mainFieldOrder.add("initCostUsingSelfDetails"); // 展开字段插在这里
mainFieldOrder.add("初始成本:配货使用中成本(炼金)");
mainFieldOrder.add("充卡成本:状态1");
mainFieldOrder.add("rechargeCompletedCostSelfDetails"); // 展开字段插在这里
mainFieldOrder.add("充卡成本:状态1(炼金)");
// ... 其他字段
// 导出Excel
ExcelMergeMoreExportUtil.exportExpandToWebWithCustomHeadersAndOrder(
list,
List.of("initCostUsingSelfDetails", "rechargeCompletedCostSelfDetails",
"boxWaitCoolingCostSelfDetails", "boxPartialSubmittedCostSelfDetails"),
customHeaders,
mainFieldOrder,
response
);
}Service 层数据准备
在 Service 层,我们需要将数据组织成正确的结构:
java
public List<Map<String,Object>> downloadCostStatisticsList(CostStatisticsDto dto){
List<CostStatistics> allList = selectList(getQueryData(dto), null, CostStatistics.class);
List<Map<String, Object>> list = new ArrayList<>();
for (CostStatistics costStatistics : allList) {
Map<String,Object> map = new LinkedHashMap<>();
// 普通字段
map.put("主键", costStatistics.getId());
map.put("初始成本:总表待使用成本", costStatistics.getInitCostTotal());
map.put("初始成本:配货使用中成本", costStatistics.getInitCostUsing());
// 展开字段:使用特殊的 key 标识
List<Map<String, Object>> initCostUsingSelfDetails = new ArrayList<>();
Map<String, Object> selfDetail = new LinkedHashMap<>();
selfDetail.put("总数", costStatistics.getInitCostUsingSelf());
selfDetail.put("武器箱", costStatistics.getInitCostUsingSelfCase());
selfDetail.put("终端", costStatistics.getInitCostUsingSelfTerminal());
initCostUsingSelfDetails.add(selfDetail);
map.put("initCostUsingSelfDetails", initCostUsingSelfDetails);
// 继续添加其他字段...
map.put("初始成本:配货使用中成本(炼金)", costStatistics.getInitCostUsingAlchemy());
list.add(map);
}
return list;
}效果展示

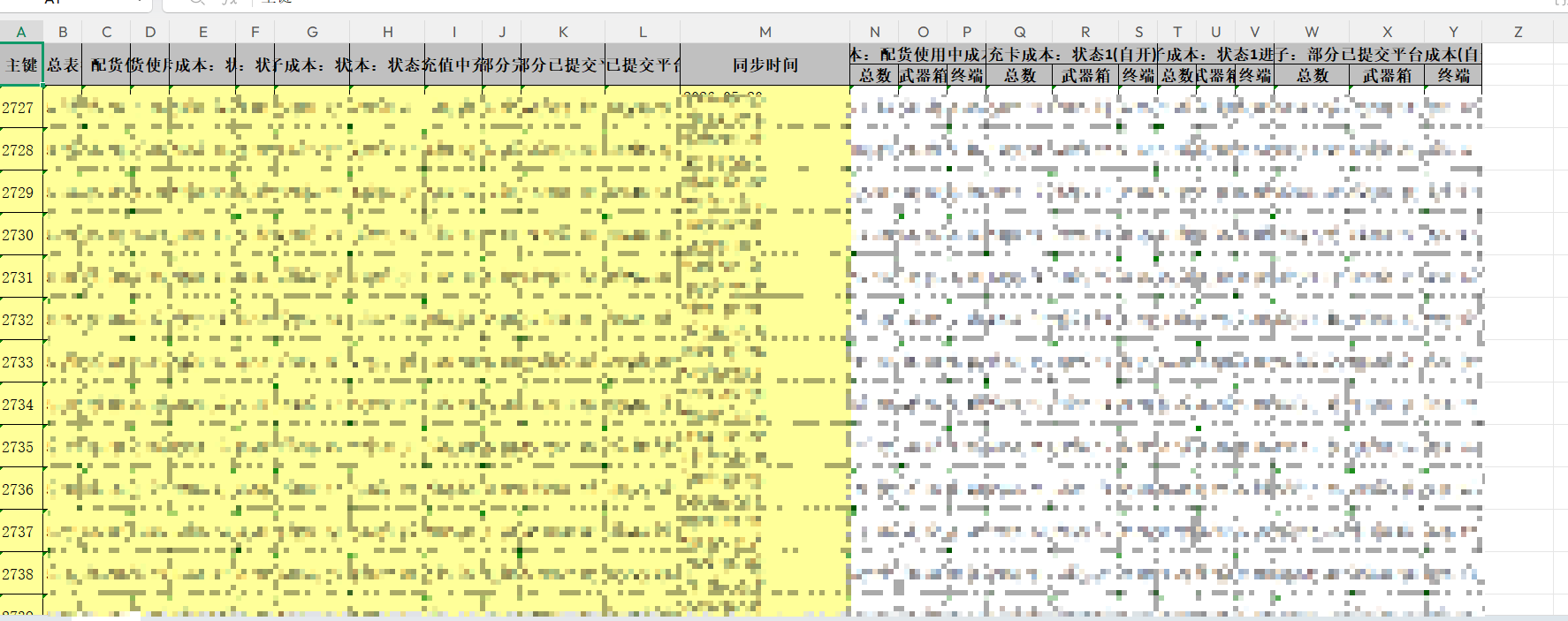
导出后的 Excel
导出的 Excel 文件将完全保持前端页面的表头结构和顺序,包括:
- ✅ 普通字段和展开字段交错排列
- ✅ 展开字段的二级表头正确显示
- ✅ 单元格合并效果一致
- ✅ 列顺序100%匹配
关键技术点总结
1. 为什么需要显式指定顺序?
Java 的 HashMap 不保证遍历顺序,即使是 LinkedHashMap,在不同场景下也可能出现顺序不一致的问题。显式指定顺序是最可靠的方案。
2. 如何识别展开字段?
通过维护一个 expandFieldSet,在遍历 mainFieldOrder 时判断当前字段是否在集合中:
java
Set<String> expandFieldSet = new HashSet<>(expandFields);
for (String field : mainFieldOrder) {
if (expandFieldSet.contains(field)) {
// 这是展开字段
} else {
// 这是普通字段
}
}3. 如何处理展开字段的子列?
为每个展开字段提取其子列的 key 列表,并在渲染时依次创建单元格:
java
List<String> subKeys = getExpandSubKeys(dataList, expandField);
for (String subKey : subKeys) {
Cell cell = row.createCell(colIndex);
Object value = expandData.get(subKey);
cell.setCellValue(value != null ? value.toString() : "");
colIndex++;
}4. 单元格合并的处理
对于展开字段的第一行表头,如果它有多个子列,需要合并单元格:
java
if (subKeyCount > 1 && customHeaderName != null) {
CellRangeAddress region = new CellRangeAddress(
0, 0, colIndex, colIndex + subKeyCount - 1);
sheet.addMergedRegion(region);
RegionUtil.setBorderTop(BorderStyle.THIN, region, sheet);
// 设置其他边框...
}常见问题
Q1: 如果某个展开字段没有数据怎么办?
A: 在写入数据时,检查 expandList 是否为空,如果为空则填充空单元格:
java
if (expandList != null && !expandList.isEmpty()) {
// 正常写入数据
} else {
// 填充空单元格
for (int i = 0; i < colDef.subKeys.size(); i++) {
Cell cell = row.createCell(colIndex);
cell.setCellStyle(dataStyle);
colIndex++;
}
}Q2: 如何处理多级展开(三级表头)?
A: 当前方案支持两级表头。如果需要三级或更多级,可以扩展 ColumnDefinition 类,增加层级信息,并递归处理表头创建逻辑。
Q3: 性能如何?
A: 该方案的时间复杂度为 O(n × m),其中 n 是数据行数,m 是列数。对于常规的导出场景(几万条数据),性能完全可以接受。如果数据量特别大,可以考虑流式写入。
总结
通过这次优化,我们实现了一个灵活、可靠、易维护的Excel导出方案:
- ✅ 完全可控的字段顺序 :通过
mainFieldOrder显式指定 - ✅ 支持交错排列:展开字段可以插入到任意位置
- ✅ 与前端完全一致:导出效果与页面表头100%匹配
- ✅ 易于扩展:新增字段只需修改配置列表
- ✅ 代码清晰:职责分明,便于维护
希望这篇文章能帮助你解决类似的Excel导出问题。如果你有任何问题或建议,欢迎在评论区留言讨论!
参考资料
- Apache POI 官方文档:https://poi.apache.org/
- Element UI Table 组件:https://element.eleme.io/#/zh-CN/component/table
- Spring Boot 文件下载最佳实践
作者 :Yuanz
日期 :2026-05-20
标签:#Java #Excel #ApachePOI #SpringBoot #前端后端协同