本文将带来超详细的 OpenClaw 多 Agent 实战教程,手把手教大家搭建一套小红书全链路自动化系统,从数据收集、竞品分析,到 AI 笔记创作、精美图文渲染,甚至后续的自动发布(目前优化为人工审核后发布),全程无需手动干预,只需在飞书发送一句话指令,剩下的所有工作都可由 OpenClaw 自动完成。
做过小红书运营或者 AI 自动化实操的朋友应该都有体会,单靠一个 Agent 想完成全流程任务,难度真的很大。要么是提示词写得又长又复杂,包含所有功能说明,导致 Agent 响应变慢;要么是执行过程中一处出错,整个流程就全盘崩溃,容错性特别差;后续想新增一个功能,还要改动全局配置,维护起来特别麻烦。这就是单 Agent 的"全能困境",什么都想做,结果什么都做不精。
为了解决这个问题,整理了一份单 Agent 和多 Agent 的多维度对比,可清晰看出多 Agent 更适合做小红书全链路自动化任务:
| 对比维度 | 单 Agent | 多 Agent |
|---|---|---|
| 提示词复杂度 | 臃肿,包含所有功能说明,编写和维护难度大 | 精简,每个 Agent 专注单一职责,提示词针对性强 |
| 执行效率 | 串行处理所有任务,一步接一步,耗时长 | 多 Agent 并行协作,各自完成专属任务,整体效率更高 |
| 容错能力 | 一处出错全盘崩溃,排查问题难度大 | 故障隔离,单个 Agent 出错不影响其他环节,便于定位修复 |
| 扩展性 | 新增功能需改动全局配置,容易引发连锁问题 | 新增功能只需添加对应 Agent 即可,各 Agent 互不影响 |
| 维护成本 | 牵一发动全身,后续维护成本高 | 模块化管理,低耦合,维护起来更省心 |
| 基于多 Agent 的核心优势,以小红书内容生产为实战场景,搭建一套三层多 Agent 系统,可实现从"素材收集"到"小红书发布"的全自动化闭环,同时通过飞书多维表格沉淀所有数据,方便后续复盘分析、素材复用,大幅提升小红书运营效率。 |
最直观的应用场景的是:无需复杂操作,只需在飞书上给机器人发送一句指令(如"搜索 openclaw,总结热门笔记规律,创作 3 篇笔记"),OpenClaw 会自动启动全流程:由采集 Agent 收集相关数据并整理,提交给调度 Agent 筛选高潜话题,再下发给创作 Agent 完成内容创作,最终反馈生成的精美图文素材和数据链接,全程无需手动干预。
关于未直接实现全自动发布的原因:技术上可通过技能配置直接发布,但实际测试中发现,未经审核的笔记易因包含敏感词或违规表述被平台删除,为避免账号限流,暂将流程优化为"生成素材 → 人工审核 → 手动发布";后续可将小红书违规规则整理成知识库集成到系统,即可实现真正的全流程自动发布。
以下将从架构设计、项目前置准备、技能集成、多 Agent 配置实现这几个维度,手把手带大家搭建这套系统,无论 AI 新手还是有一定基础的开发者,跟随步骤操作均可完成,全程为实操导向的喂饭级教程。
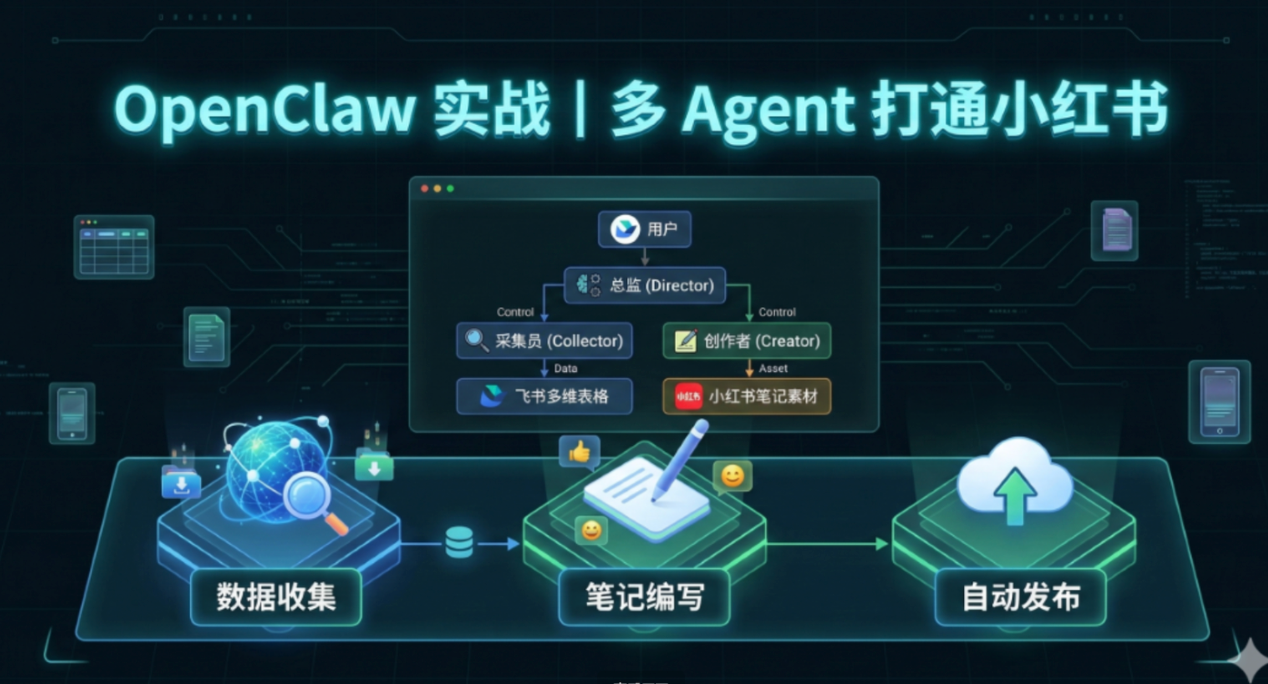
一、多 Agent 架构设计:三层解耦,实现全自动化闭环
这套多 Agent 系统的核心思路是"分工明确、各司其职",通过三层架构解耦,将复杂的全链路任务拆分为简单小任务,每个 Agent 专注自身核心职责,再通过调度 Agent 统一调度,最终实现从极简指令到精美物料产出的全自动化闭环。整个架构分为交互层、调度层、执行层三个部分,具体作用如下:
1. 交互层:用户与系统的沟通入口
交互层即飞书会话界面,用户无需掌握代码知识或复杂操作,只需通过自然语言向飞书机器人发送指令,即可触发系统运行。例如"获取小红书今日热榜,创作 3 篇相关笔记""搜索 AI 工具相关竞品笔记,对标创作 2 篇笔记"等简单指令,系统均可精准理解并执行。
选择飞书作为交互入口,一方面因其机器人功能成熟,易与 OpenClaw 集成;另一方面飞书多维表格功能强大,可便捷沉淀采集数据、创作素材,便于后续复盘分析,相当于免费的轻量级数据管理工具。
2. 调度层:系统的"中枢大脑"------调度(Director)Agent
调度层是系统核心,由调度 Agent 全盘接管,不负责具体执行任务,主要承担三大职责:理解用户指令、拆解任务、调度执行层 Agent 完成任务,最终汇总结果反馈给用户。
调度 Agent 是唯一与用户直接交互的 Agent,会先解析用户自然语言指令,判断需求为热点追踪或竞品分析,再将需求拆分为具体任务,分配给执行层的采集 Agent 和创作 Agent。例如用户指令"搜索 openclaw,创作 3 篇热门笔记",调度 Agent 会拆解为三步:一是让采集 Agent 搜索 openclaw 相关竞品笔记,整理后写入飞书多维表格;二是从表格中筛选 3 个高潜话题;三是让创作 Agent 基于话题和竞品数据,创作合规笔记并渲染图文;最后汇总飞书数据链接和图文素材路径反馈给用户。
简言之,调度 Agent 的核心作用是"统筹全局",确保各环节有序推进,避免任务混乱、遗漏,同时处理流程中的异常问题,提升系统容错性。
3. 执行层:专注具体任务的"专业选手"------两大执行 Agent
执行层由两个专业执行 Agent 组成,不与用户交互,仅执行调度 Agent 下发的具体任务,各司其职、互不干扰,既提升执行效率,也降低故障风险。
第一个是采集(Collector)Agent,核心职责是数据收集与整理。为其集成 xhs-collector 技能,可定向获取小红书热点数据、领域优秀竞品笔记,将数据结构化处理(提取标题、热度、互动数据、链接等关键信息)后,沉淀到飞书多维表格,为笔记创作提供素材和思路。无论是热点追踪场景的热榜数据,还是竞品分析场景的关键词搜索数据,均由采集 Agent 负责获取和整理。
第二个是创作(Creator)Agent,核心职责是内容创作与图文渲染。为其集成 Auto-Redbook-Skills 技能(专为小红书打造的开源内容自动化工具),可基于采集 Agent 沉淀的数据,在合规前提下撰写符合小红书平台风格的笔记,再将笔记渲染为精美的多图卡片,输出到指定本地文件夹,供审核和发布使用。
三个层级相互配合,形成完整自动化闭环:用户发送指令 → 调度 Agent 拆解任务 → 采集 Agent 收集数据 → 调度 Agent 筛选调度 → 创作 Agent 创作渲染 → 调度 Agent 汇总汇报,全程一气呵成,大幅节省小红书运营的时间和精力。
二、项目搭建前置准备:技能集成与环境配置
搭建多 Agent 系统前,需先完成两个核心技能的集成(Auto-Redbook-Skills 用于笔记创作和渲染,xhs-collector 用于数据采集和整理),这是系统正常运行的基础。此外,还需准备一台云服务器(可选用任意支持 OpenClaw 部署的服务器)、飞书账号(用于交互和数据沉淀)、小红书账号(用于获取 Cookie,供后续渲染和发布使用)。
本系统主要涵盖两个核心应用场景,搭建完成后可根据需求灵活使用,先明确两个场景的完整流程,便于理解系统运行逻辑:
1. 热点追踪场景:自动抓热榜,批量创笔记
当用户发送指令"获取小红书今日热榜,创作 3 篇相关笔记"时,系统自动执行以下闭环流程:
第一步,数据获取。调度 Agent 唤醒采集 Agent,采集 Agent 执行底层脚本,获取小红书最新 50 条热榜数据,结构化处理(提取排名、话题、热度、链接等信息)后,写入飞书多维表格,便于后续查看和筛选。
第二步,筛选调度。调度 Agent 读取飞书多维表格中的热榜数据,结合热度、话题相关性等维度,筛选出 3 个高潜话题(如热度高、竞争小、易出爆款的话题),向创作 Agent 批量下发独立创作任务,每个话题对应一篇笔记。
第三步,内容生成。创作 Agent 读取飞书表格热榜数据,结合小红书平台风格,严格遵循合规规范撰写笔记文案(标题吸睛、多用 emoji、避免敏感词),执行渲染脚本,将 Markdown 格式文案渲染为符合小红书审美的高清多图卡片,再将图文物料分类输出至本地文件夹。
第四步,汇总汇报。调度 Agent 验收全流程,确认数据采集完整、笔记合规、图文渲染无误后,向用户反馈飞书数据链接(便于查看热榜数据)及各话题产出明细(如:话题 A 产出 4 张图、话题 B 产出 5 张图),完成热点追踪闭环。
2. 竞品分析场景:对标优秀笔记,高效创内容
当用户发送指令"搜索 openclaw,创作类似的热门笔记"时,系统自动执行以下闭环流程:
第一步,定向获取。调度 Agent 向采集 Agent 下发关键词搜索任务,采集 Agent 执行底层脚本,搜索 openclaw 相关优秀竞品笔记(默认获取 20 条),将笔记关键信息(标题、作者、点赞数、评论数、封面链接、笔记链接等)结构化处理后,写入飞书多维表格。
第二步,对标创作。调度 Agent 引导创作 Agent 介入,创作 Agent 读取飞书表格竞品数据,分析竞品行文风格、内容结构、热门元素(如标题格式、emoji 使用、内容侧重点),在合规前提下撰写高质量笔记文案,确保笔记兼具特色与热门趋势。
第三步,汇总汇报。调度 Agent 验收全链路,确认竞品数据采集完整、笔记符合要求、图文渲染无误后,向用户反馈包含搜索数据的飞书查阅链接(便于对标分析竞品)及笔记素材本地路径,实现从对标到产出的完整闭环。
了解场景流程后,进入技能集成环节(实操重点),每一步需仔细操作,避免影响后续系统运行:
3. 集成 Auto-Redbook-Skills 到 OpenClaw
Auto-Redbook-Skills 是开源小红书内容自动化工具,核心能力是将大模型生成的 Markdown 文本,自动排版渲染为符合小红书审美的高清多图卡片,内置 8 套精美主题和 4 种智能分页,支持基于 Cookie 的全自动发布,适配小红书笔记批量创作和渲染。其开源地址为:https://github.com/comeonzhj/Auto-Redbook-Skills,可提前查看功能特性。
集成步骤简单,无需编写复杂代码,具体操作如下:
第一步,下载技能包。打开 Auto-Redbook-Skills 的 GitHub 仓库,点击右上角【Code】按钮,在下拉菜单中选择【Download ZIP】,等待压缩包下载完成。
第二步,解压并存放。找到下载的 ZIP 压缩包,选择任意磁盘存放(建议存放在 skill 项目文件夹,便于后续管理)。解压后得到 Auto-Redbook-Skills 文件夹,包含所有所需脚本和配置文件。
第三步,配置 Cookie。该技能需先配置小红书 Cookie 才能正常使用(否则无法渲染和发布笔记):在 Auto-Redbook-Skills 文件夹中,新建 .env 文件,参考文件夹内 env.example.txt 文件配置,仅需将 Cookie 值替换为自身小红书 Cookie 即可。
小红书 Cookie 获取方法(无需技术基础):登录网页版小红书,按住 F12 键调出开发者工具,选择【Network】选项卡,刷新网页,点击任意包含"note""hot"等关键词的异步请求,在右侧【Headers】(请求头)中找到【Cookie】字段,复制全部内容,粘贴到 .env 文件对应位置。
第四步,上传到服务器。用 FTP 工具(如 FileZilla)将 Auto-Redbook-Skills 文件夹上传至服务器的 /root/.openclaw/workspace/skills/ 目录(OpenClaw 默认技能存放目录,仅在此目录下,OpenClaw 才能识别调用)。
至此,Auto-Redbook-Skills 技能集成完成,后续创作 Agent 可调用该技能完成笔记创作和图文渲染。
4. 集成 xhs-collector 到 OpenClaw
xhs-collector 是一款可自定义采集规则的技能,核心功能是收集小红书热门选题和优质笔记思路,汇总至飞书多维表格,适配热点追踪和竞品分析场景,可灵活获取热榜数据和关键词搜索数据。
标准 OpenClaw 技能需包含以下核心文件和文件夹(缺一不可),创建时需重点注意:
xhs-collector/
├── SKILL.md # 必填:技能使用说明 + 元数据,告知 OpenClaw 技能作用和使用方法
├── scripts/ # 必填:可执行代码文件夹,存放采集数据脚本
└── config.json # 必填:配置文件,配置第三方平台 API key 等信息
└── output/ # 必填:输出目录,存放采集的临时数据或日志
具体创建和配置步骤如下:
第一步,创建项目文件夹。在本地电脑找到 .claude 目录(无则手动创建),在 .claude\skills\ 目录下新建 xhs-collector 文件夹(技能根目录)。
第二步,编写 SKILL.md 文件。该文件是技能说明文件,OpenClaw 通过其识别技能功能和使用方法,编写思路分为三部分:一是找到可获取小红书信息的第三方平台,获取其 API 接口(需支持热榜和搜索数据获取);二是定义两个核心工作流(获取小红书热榜为选题提供方向、按关键词检索优秀笔记并整理至飞书表格);三是补充使用说明、参数说明,避免后续使用出错(可借助 AI 生成,提升效率)。
第三步,编写 scripts 文件夹下的代码。scripts 是技能核心,需创建两个脚本文件:fetch_hot_list.py(收集整理小红书热榜数据)和 fetch_search_notes.py(按关键词搜索领域优秀笔记)。
fetch_hot_list.py 编写思路:调用第三方 API 获取热榜数据,解析后保留所需字段,转换为 JSON 格式返回,便于后续写入飞书表格,具体代码如下:
python
def fetch_hot_list():
# 1. 调用第三方 API ,获取热榜数据
url = "https://api.xxx.com/xhs/hotlist" # 替换成你找到的第三方 API 地址
headers = {"Authorization": "your_api_key"} # 替换成你的 API key
response = requests.get(url, headers=headers)
# 2. 解析返回数据 ,提取需要的字段
data = response.json()
hot_list = []
for item in data['items'][:50]: # 取前50条热榜数据,可根据需求调整数量
hot_list.append({
"rank": item['rank'], # 热榜排名
"topic": item['title'], # 热榜话题
"heat": item['heat_value'], # 话题热度
"link": item['url'] # 话题链接
})
# 3. 输出 JSON 格式的数据,方便后续处理
print(json.dumps(hot_list, ensure_ascii=False))
if __name__ == "__main__":
fetch_hot_list()编写时仅需替换 url 和 headers 中的 API 地址、API key,其余可直接复用;需注意第三方 API 返回数据格式可能不同,需根据实际情况调整解析字段名称,确保能提取排名、话题、热度、链接等信息。
fetch_search_notes.py 编写思路:调用第三方 API 按关键词搜索竞品笔记,解析后保留所需字段,转换为 JSON 格式返回,具体代码如下:
python
def search_notes(keyword):
# 1. 调用搜索 API ,获取竞品笔记数据
url = "https://api.xxx.com/xhs/search" # 替换成你的搜索 API 地址
params = {"keyword": keyword, "limit": 20} # limit 表示获取的笔记数量,可调整
headers = {"Authorization": "your_api_key"} # 替换成你的 API key
response = requests.get(url, params=params, headers=headers)
# 2. 解析笔记数据 ,提取需要的字段
data = response.json()
notes = []
for item in data['notes']:
notes.append({
"title": item['title'], # 笔记标题
"author": item['author_name'], # 笔记作者
"likes": item['like_count'], # 点赞数
"comments": item['comment_count'], # 评论数
"cover": item['cover_url'], # 笔记封面链接
"link": item['note_url'] # 笔记链接
})
# 3. 输出 JSON 格式的数据,方便后续处理
print(json.dumps(notes, ensure_ascii=False))
if __name__ == "__main__":
keyword = sys.argv[1] if len(sys.argv) > 1 else "openclaw" # 默认关键词为 openclaw,可修改
search_notes(keyword)同样需替换 url、headers 中的 API 信息,根据第三方 API 返回格式调整解析字段;默认关键词为 openclaw,可自行修改或调用脚本时手动传入,灵活性较高。
第四步,编写 config.json 文件。用于配置第三方平台 API key、飞书表格相关信息,示例如下(可根据需求调整字段):
json
{
"api_key": "your_api_key", # 第三方平台的 API key
"feishu_table_id": "your_feishu_table_id", # 飞书多维表格 ID
"output_path": "./output" # 输出目录路径
}第五步,创建 output 文件夹。在 xhs-collector 目录下新建 output 文件夹,用于存放采集的临时数据或日志,避免数据混乱。
第六步,上传到服务器。用 FTP 工具将 xhs-collector 文件夹上传至服务器的 /root/.openclaw/workspace/skills/ 目录,确保 OpenClaw 能识别调用该技能。
至此,两个核心技能集成完成,进入最关键的多 Agent 配置实现环节,直接决定系统能否正常运行,需仔细核对每一步操作。
三、OpenClaw 多 Agent 实现:配置文件编写与系统启动
多 Agent 实现的核心是配置文件编写,需在 OpenClaw 工作空间中,创建三个 Agent(调度、采集、创作)的配置文件,定义各 Agent 的身份、职责、技能关联等信息,再在 OpenClaw 主配置文件中关联三个 Agent、配置飞书集成信息,最后重启 OpenClaw 即可。
1. 飞书应用集成 OpenClaw(前置步骤)
需创建专属飞书应用(如"小红书运营"),用于接收用户指令、反馈执行结果。飞书应用集成 OpenClaw 的具体步骤(含飞书应用创建、AppID 和 AppSecret 获取、OpenClaw 与飞书关联配置)可参考相关实操文档,核心要求是:创建飞书应用并获取 AppID、AppSecret,确保 OpenClaw 已关联该飞书应用,能正常接收和响应飞书指令。
2. 多 Agent 配置文件编写(核心步骤)
进入 OpenClaw 的 Agent 工作空间(路径:/root/.openclaw/workspace/agents/),创建三个 Agent 文件夹,分别为 director(调度)、collector(采集)、creator(创作),每个文件夹下需创建对应配置文件,具体结构如下:
├── director/ # 调度 Agent 文件夹
│ ├── SOUL.md # 身份定义文件,定义调度 Agent 职责和工作流
│ ├── AGENTS.md # 工作空间说明文件,可选
│ └── CONFIG.md # 飞书表格配置文件,配置飞书表格相关信息
├── collector/ # 采集 Agent 文件夹
│ ├── SOUL.md # 身份定义文件,定义采集 Agent 职责和流程
│ ├── AGENTS.md # 工作空间说明文件,可选
│ └── .openclaw/
│ └── skills.json # 技能关联文件,关联 xhs-collector 技能
└── creator/ # 创作 Agent 文件夹
├── SOUL.md # 身份定义文件,定义创作 Agent 职责和流程
├── AGENTS.md # 工作空间说明文件,可选
└── .openclaw/
└── skills.json # 技能关联文件,关联 Auto-Redbook-Skills 技能
逐个编写各 Agent 配置文件,确保内容准确无误:
(1)编写 director/SOUL.md(调度 Agent 身份定义)
SOUL.md 用于定义 Agent 身份、职责、工作流和调用方式,调度 Agent 的 SOUL.md 内容如下(可根据需求调整):
你是调度 Agent,负责协调采集 Agent 和创作 Agent 完成小红书内容生产,是整个系统的中枢大脑,直接与用户交互,统筹全局任务。
职责
-
精准理解用户的自然语言指令,拆解为具体可执行的任务;
-
合理调用采集 Agent 采集小红书相关数据(热榜、竞品笔记);
-
调度创作 Agent 基于采集到的数据,进行合规的笔记创作和图文渲染;
-
汇总整个流程的执行结果,向用户清晰反馈(包括飞书数据链接、素材路径、产出明细);
-
处理流程中的异常问题,确保任务有序推进。
工作流
热点追踪:调用采集 Agent 获取小红书热榜数据,筛选出高潜话题,调用创作 Agent 批量创作笔记,汇总结果并向用户汇报
竞品分析:调用采集 Agent 按关键词搜索竞品笔记,引导创作 Agent 对标创作笔记,汇总结果并向用户汇报
调用方式
json
{
"runtime": "subagent",
"agentId": "collector", // 调用采集 Agent 时填写 collector,调用创作 Agent 时填写 creator
"task": "任务描述", // 具体的任务指令,比如"获取小红书今日热榜前50条""搜索 openclaw 相关竞品笔记20条"
"mode": "run"
}核心注意点:调用方式中的 agentId 需与后续 OpenClaw 主配置文件中的 Agent id 一致,否则无法正常调用。
(2)编写 creator/SOUL.md 和 skills.json(创作 Agent 配置)
创作 Agent 核心职责是笔记创作和图文渲染,SOUL.md 需明确其工作流程和职责,skills.json 用于关联 Auto-Redbook-Skills 技能。
creator/SOUL.md 内容:
你负责根据飞书表格中的数据,创作符合小红书平台风格的合规笔记,并将笔记渲染为精美图文,不与用户直接交互,仅接收调度 Agent 下发的任务。
流程
-
读取飞书表格中的数据(热榜数据或竞品笔记数据),理解数据中的核心信息;
-
撰写 Markdown 格式的笔记文案,要求标题吸睛、多用 emoji、语言通俗易懂、避免敏感词,贴合小红书平台风格;
-
将撰写好的文案保存为 README.md 文件,存放在指定路径;
-
执行渲染脚本,具体指令:
cd /root/.openclaw/workspace/skills/Auto-Redbook-Skills && node render.js; -
完成渲染后,向调度 Agent 汇报任务结果,汇报内容包括:话题名称、生成的图片数量、图文素材的本地路径。
注意:渲染脚本路径需与 Auto-Redbook-Skills 技能上传路径一致,若修改技能存放路径,需同步修改脚本路径。
creator/.openclaw/skills.json 内容(关联 Auto-Redbook-Skills 技能):
json
{
"skills": [
{
"path": "/root/.openclaw/workspace/skills/Auto-Redbook-Skills", // 技能的存放路径,必须准确
"enabled": true // 启用该技能,设置为 false 则无法调用
}
]
}注意:path 需填写 Auto-Redbook-Skills 技能在服务器上的绝对路径,避免拼写错误,否则创作 Agent 无法调用该技能。
(3)编写 collector/SOUL.md 和 skills.json(采集 Agent 配置)
采集 Agent 核心职责是采集小红书数据并写入飞书表格,SOUL.md 需明确其工作模式、流程和职责,skills.json 用于关联 xhs-collector 技能。
collector/SOUL.md 内容:
采集 Agent
你负责获取小红书相关数据(热榜、竞品笔记),并将数据结构化处理后写入飞书表格,不与用户直接交互,仅接收调度 Agent 下发的任务。
两种模式
热榜模式 :node scripts/fetch-hotlist.js,获取小红书前 50 条热榜数据,可根据需求调整数量
搜索模式 :node scripts/search-notes.js "关键词",按关键词搜索相关竞品笔记,默认获取 20 条
流程
-
接收调度 Agent 下发的任务,执行对应的采集脚本(热榜模式或搜索模式);
-
解析脚本返回的 JSON 数据,提取需要的字段,进行结构化处理;
-
将结构化的数据写入飞书多维表格,确保数据准确无误;
-
完成采集后,向调度 Agent 汇报任务结果,汇报内容包括:采集的数据条数、飞书表格的查阅链接。
注意:脚本指令需与 fetch_hot_list.py 和 fetch_search_notes.py 脚本对应,若修改脚本名称或路径,需同步修改指令。
collector/.openclaw/skills.json 内容(关联 xhs-collector 技能):
json
{
"skills": [
{
"path": "/root/.openclaw/workspace/skills/xhs-collector", // 技能的存放路径,必须准确
"enabled": true // 启用该技能,设置为 false 则无法调用
}
]
}注意:path 需填写 xhs-collector 技能在服务器上的绝对路径,避免拼写错误,否则采集 Agent 无法调用该技能。
(4)配置 openclaw.json(OpenClaw 主配置文件)
openclaw.json 是 OpenClaw 主配置文件(路径:/root/.openclaw/openclaw.json),需在其中添加三个 Agent 配置、飞书应用配置,以及 Agent 与飞书应用的绑定关系,确保系统正常运行。
在 openclaw.json 中添加以下代码(保留原有配置,仅添加对应节点):
json
{
"agents": {
"list": [
{
"id": "director", // 调度 Agent 的 id,与 SOUL.md 中的调用方式一致
"name": "调度 Agent", // Agent 名称,可自定义
"workspace": "/root/.openclaw/workspace/agents/director" // 调度 Agent 工作空间路径
},
{
"id": "collector", // 采集 Agent 的 id
"name": "采集 Agent", // Agent 名称,可自定义
"workspace": "/root/.openclaw/workspace/agents/collector" // 采集 Agent 工作空间路径
},
{
"id": "creator", // 创作 Agent 的 id
"name": "创作 Agent", // Agent 名称,可自定义
"workspace": "/root/.openclaw/workspace/agents/creator" // 创作 Agent 工作空间路径
}
]
},
"channels": {
"feishu": {
"accounts": {
"xhs": { // 飞书账号标识,可自定义
"appId": "cli_xxx", // 替换为自身飞书应用 AppID
"appSecret": "xxx", // 替换为自身飞书应用 AppSecret
"defaultAgent": "director" // 默认关联调度 Agent
}
}
}
},
"bindings": [
{
"match": {
"channel": "feishu", // 关联飞书渠道
"accountId": "xhs" // 关联上述飞书账号标识
},
"agentId": "director" // 飞书指令由调度 Agent 接收处理
}
]
}核心注意点(需重点核对):
-
appId 和 appSecret:替换为自身飞书应用的 AppID 和 AppSecret(可在飞书开发者平台应用详情中获取);
-
工作空间路径:各 Agent 的 workspace 路径需与创建的 Agent 文件夹路径一致,确保 OpenClaw 能找到配置文件;
-
绑定关系:bindings 中的 agentId 需设为 director,确保飞书指令能被调度 Agent 接收和处理,进而调度其他两个 Agent。
3. 系统启动与测试
所有配置文件编写完成后,需重启 OpenClaw 使配置生效。重启方法:登录服务器命令面板,输入指令 openclaw gateway restart;若重启失败,可直接重启云服务器。
重启后进行测试,验证系统是否正常运行:打开飞书,找到创建的"小红书运营"应用,发送测试指令(如"获取小红书今日热榜,创作 1 篇相关笔记"),等待系统响应。
正常执行流程:调度 Agent 接收指令 → 调用采集 Agent 获取热榜数据并写入飞书表格 → 调度 Agent 筛选话题 → 调用创作 Agent 创作笔记并渲染 → 调度 Agent 汇总结果反馈。
若能收到包含飞书数据链接和图文素材路径的反馈,说明系统搭建成功;若出现报错,可重点排查:配置文件路径、技能上传情况、飞书 AppID 和 AppSecret 正确性,逐步排查即可解决。
四、常见问题与注意事项
结合实操经验,整理了搭建和使用过程中的常见问题及注意事项,帮助避免踩坑,确保系统稳定运行:
-
笔记违规被删除问题:初期配置全自动发布后,笔记易因敏感词违规删除,建议暂采用"人工审核后发布";后续可整理小红书违规规则,建立知识库集成到系统,实现真正全自动发布。
-
技能调用失败问题:大概率是技能存放路径错误,或 skills.json 中的 path 配置错误,需核对路径一致性;同时确保技能文件夹权限正确,避免 OpenClaw 无法读取调用。
-
数据采集失败问题:可能是第三方 API 地址错误、API key 失效或网络问题,可先测试 API 能否正常返回数据,核对 API key 正确性,确保服务器能正常访问第三方平台。
-
飞书无法接收响应问题:多为飞书 AppID、AppSecret 配置错误,或 OpenClaw 与飞书绑定关系错误,需重新核对 openclaw.json 中的飞书配置和 bindings 配置,修改后重启 OpenClaw。
-
脚本执行失败问题:可能是脚本解析字段与 API 返回格式不匹配,或缺少依赖包;需核对脚本字段名称,确保与 API 返回数据一致,同时安装脚本所需依赖包(如 requests、json 等)。
关键注意事项:
-
所有配置文件路径需准确(尤其是 Agent 工作空间和技能存放路径),路径错误会导致系统无法运行;
-
小红书 Cookie 需定期更新,避免失效导致渲染、发布功能异常;
-
采集数据量不宜过多(热榜前 50 条、竞品前 20 条为宜),避免触发小红书反爬机制;
-
笔记创作需严格遵循小红书平台规则,避开敏感词和违规表述,降低笔记删除、账号限流风险。
五、系统优化方向(可选)
搭建完成后,可根据需求进行以下优化,提升系统实用性和自动化程度:
-
集成违规检测功能:整理小红书违规词库和违规规则,建立知识库集成到创作 Agent,实现笔记文案自动违规检测,减少人工审核成本;
-
增加定时任务功能:配置定时指令(如每日固定时间抓取热榜、创作笔记),实现无人值守自动化运营;
-
优化数据复盘功能:在飞书多维表格中添加数据统计模块(如笔记互动数据跟踪、选题热度分析),便于后续运营复盘;
-
扩展多平台适配:新增抖音、视频号等平台的技能集成,实现多平台内容自动化生产,提升运营效率。
总结
本教程通过三层多 Agent 架构(交互层、调度层、执行层),结合 Auto-Redbook-Skills 和 xhs-collector 两个核心技能,实现了小红书从数据采集、竞品分析到笔记创作、图文渲染的全链路自动化。整个搭建过程无需复杂代码编写,全程实操导向,无论 AI 新手还是有一定基础的开发者,跟随步骤均可完成。
系统的核心优势的是模块化、低耦合,各 Agent 各司其职,容错性强、扩展性高,可根据自身运营需求灵活调整配置和场景。后续通过违规检测、定时任务等优化,可进一步提升自动化程度,真正实现小红书运营"省力高效",解放人工成本。