一、图像增广
**图像增广(Image Augmentation,也常被称为数据增强)**是计算机视觉中最常用且最有效的提升模型泛化能力的方法。
1.1 什么是图像增广?为什么需要它?
在深度学习中,模型很容易"死记硬背"训练数据(即过拟合)。比如,如果训练集里所有的猫都在图片的左边,模型可能会认为"左边有一团毛茸茸的东西"才是猫。
图像增广就是在把图片喂给神经网络之前,随机地对它进行一些变换(如:翻转、裁剪、改变颜色、加噪等)。
它的好处有两点:
- 变相扩大数据集:一张猫的图片经过10种不同的变换,就变成了10张"相似但不同"的训练样本。
- 提高泛化能力(鲁棒性):打破模型对特定属性(如位置、大小、颜色)的依赖。比如裁剪能让模型适应物体在不同位置,改颜色能降低模型对光照的敏感度。
辅助函数
python
%matplotlib inline
from d2l import torch as d2l
import torch
import torchvision
from torch import nntorchvision包含了计算机视觉常用的数据集、模型和图像变换工具(即我们将使用的transforms` 模块)。
为了直观看到增广的效果,定义一个辅助函数 apply:
python
def apply(img, aug, num_rows=2, num_cols=4, scale=1.5):
# 列表推导式:对同一张输入图片 img,重复执行 aug(img) 操作 num_rows * num_cols 次(这里是 2*4=8 次)
# 因为增广方法通常带有随机性,所以即使是同一个 aug 操作,每次输出的图片也会不一样。
Y = [aug(img) for _ in range(num_rows * num_cols)]
# 使用 d2l 库提供的绘图函数,将这 8 张生成的图片以网格的形式展示出来
d2l.show_images(Y, num_rows, num_cols, scale=scale)1.2 常用的图像增广方法
翻转 (Flipping) 和 裁剪 (Cropping)
左右翻转 (Horizontal Flip)
最常用的增广方法,因为现实世界中绝大多数物体的左右对称性不改变其类别(猫向左看和向右看都是猫)。
python
# RandomHorizontalFlip(): 以 50% 的默认概率将图片左右翻转
apply(img, torchvision.transforms.RandomHorizontalFlip())
上下翻转 (Vertical Flip)
用的相对较少(毕竟现实中倒立的猫不常见),但在医学图像(细胞切片)、卫星遥感图像中非常常用。
python
# RandomVerticalFlip(): 以 50% 的默认概率将图片上下翻转
apply(img, torchvision.transforms.RandomVerticalFlip())
随机缩放裁剪 (Random Resized Crop)
非常有用的一种增广方法,它能解决物体在图像中大小不一、位置不一的问题。
python
shape_aug = torchvision.transforms.RandomResizedCrop(
(200, 200), # 无论原本裁下来多大,最后统统强行缩放(Resize)到 200x200 像素
scale=(0.1, 1), # 随机裁剪面积:裁剪出的面积是原图面积的 10% 到 100% 之间
ratio=(0.5, 2) # 随机长宽比:裁剪框的高宽比例在 0.5 (1:2) 到 2 (2:1) 之间随机
)
apply(img, shape_aug)
改变颜色 (Color Jittering)
光照条件在现实中千变万化。我们可以通过改变亮度 (brightness)、对比度 (contrast)、饱和度 (saturation) 和色调 (hue) 来模拟各种光照。
ColorJitter 接收的参数如果是单个数 x,一般表示在 [max(0, 1 - x), 1 + x] 范围内随机抖动。
python
# 只改变亮度:亮度将在原图的 50% (1-0.5) 到 150% (1+0.5) 之间随机浮动
apply(img, torchvision.transforms.ColorJitter(
brightness=0.5, contrast=0, saturation=0, hue=0))
# 只改变色调:hue 参数的取值范围限制在 [-0.5, 0.5] 之间
apply(img, torchvision.transforms.ColorJitter(
brightness=0, contrast=0, saturation=0, hue=0.5))
# 同时随机改变四个属性
color_aug = torchvision.transforms.ColorJitter(
brightness=0.5, contrast=0.5, saturation=0.5, hue=0.5)
apply(img, color_aug)
组合多种增广方法 (Compose)
在实际训练中,我们当然希望把上述方法结合起来使用。Compose 就相当于一条流水线。
python
# Compose 接收一个列表,图片会依次通过列表中的每个变换
augs = torchvision.transforms.Compose([
torchvision.transforms.RandomHorizontalFlip(), # 第一步:一半概率左右翻转
color_aug, # 第二步:随机改变颜色
shape_aug # 第三步:随机裁剪并缩放
])
apply(img, augs)
1.3 使用图像增广进行模型训练
定义训练集和测试集的增广流水线
重要原则 :在训练 时,我们使用随机增广来增加数据多样性;但在测试/预测 时,我们绝不能使用随机增广,否则会对同一个样本得出不同的预测结果,导致评估不准确。
python
# 训练期的流水线
train_augs = torchvision.transforms.Compose([
torchvision.transforms.RandomHorizontalFlip(), # 加上随机左右翻转
torchvision.transforms.ToTensor() # 必须的一步:将 PIL 格式转为 PyTorch 张量
# ToTensor() 会做两件事:
# 1. 把形状从 (高度, 宽度, 通道数) 变成 PyTorch 需要的 (通道数, 高度, 宽度)
# 2. 把像素值从 0~255 的整数,归一化到 0.0~1.0 的浮点数
])
# 测试期的流水线
test_augs = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])加载数据的辅助函数:
python
def load_cifar10(is_train, augs, batch_size):
# 下载并加载 CIFAR10 数据集,根据 is_train 决定是加载训练集还是测试集
# transform=augs 将我们上面定义的流水线应用到每一张图片上
dataset = torchvision.datasets.CIFAR10(root="../data", train=is_train,
transform=augs, download=True)
# 包装成 DataLoader,方便分批次 (batch) 送入 GPU 训练
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size,
shuffle=is_train, num_workers=d2l.get_dataloader_workers())
return dataloader1.4 多GPU训练
这里定义了如何在一个 batch 上进行训练 (train_batch_ch13) 以及整个训练流程 (train_ch13)。这部分代码是为了兼容单GPU和多GPU。
python
# 单个 batch 的训练函数
def train_batch_ch13(net, X, y, loss, trainer, devices):
# 将数据 X 和标签 y 移动到对应的设备(如 GPU:0)上
if isinstance(X, list):
X = [x.to(devices[0]) for x in X]
else:
X = X.to(devices[0])
y = y.to(devices[0])
net.train() # 将网络设置为训练模式(启用 Dropout 和 BatchNorm 等特性)
trainer.zero_grad() # 优化器梯度清零(PyTorch中梯度默认是累加的,每一步必须清零)
pred = net(X) # 前向传播:计算预测结果
l = loss(pred, y) # 计算预测结果与真实标签的损失
l.sum().backward() # 反向传播:计算所有参数的梯度
trainer.step() # 优化器更新:根据梯度更新网络参数
# 记录当前 batch 的总损失和预测正确的数量,用于后续计算平均指标
train_loss_sum = l.sum()
train_acc_sum = d2l.accuracy(pred, y)
return train_loss_sum, train_acc_sum
def train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,
devices=d2l.try_all_gpus()):
"""用多GPU进行模型训练"""
timer, num_batches = d2l.Timer(), len(train_iter)
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0, 1],
legend=['train loss', 'train acc', 'test acc'])
net = nn.DataParallel(net, device_ids=devices).to(devices[0])
for epoch in range(num_epochs):
# 4个维度:储存训练损失,训练准确度,实例数,特点数
metric = d2l.Accumulator(4)
for i, (features, labels) in enumerate(train_iter):
timer.start()
l, acc = train_batch_ch13(
net, features, labels, loss, trainer, devices)
metric.add(l, acc, labels.shape[0], labels.numel())
timer.stop()
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(metric[0] / metric[2], metric[1] / metric[3],
None))
test_acc = d2l.evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
print(f'loss {metric[0] / metric[2]:.3f}, train acc '
f'{metric[1] / metric[3]:.3f}, test acc {test_acc:.3f}')
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec on '
f'{str(devices)}')完整的训练循环函数 (train_ch13 较长,主要做了以下事情):
- 设置计时器和绘图动画 (
Animator)。 - 使用
nn.DataParallel(net, device_ids=devices)把模型包装起来,实现多GPU并行计算。 - 循环
num_epochs次。在每个 epoch 内,遍历训练集,调用train_batch_ch13进行训练,并累加损失和准确率。 - 每个 epoch 结束后,用测试集评估当前模型的准确率 (
evaluate_accuracy_gpu)。 - 实时画出 loss 曲线和 accuracy 曲线。
组合执行训练
最后,我们将上述所有组件拼合起来,启动训练。
python
batch_size, devices, net = 256, d2l.try_all_gpus(), d2l.resnet18(10, 3) # 初始化 ResNet18 模型,10个类别,3个颜色通道
# 定义权重初始化函数
def init_weights(m):
# 如果是全连接层 (Linear) 或 卷积层 (Conv2d),则使用 Xavier 均匀分布初始化权重
if type(m) in [nn.Linear, nn.Conv2d]:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights) # 将初始化函数应用到网络的所有层
# 主训练函数
def train_with_data_aug(train_augs, test_augs, net, lr=0.001):
# 使用我们定义的流水线加载数据
train_iter = load_cifar10(True, train_augs, batch_size)
test_iter = load_cifar10(False, test_augs, batch_size)
# 定义损失函数:交叉熵损失(用于分类任务)
loss = nn.CrossEntropyLoss(reduction="none")
# 定义优化器:Adam(自适应学习率优化器)
trainer = torch.optim.Adam(net.parameters(), lr=lr)
# 调用训练引擎,训练 10 个 epoch
train_ch13(net, train_iter, test_iter, loss, trainer, 10, devices)
# 这里使用了仅有随机左右翻转的 train_augs
train_with_data_aug(train_augs, test_augs, net)输出:
loss 0.222, train acc 0.923, test acc 0.817
1131.9 examples/sec on [device(type='cuda', index=0)]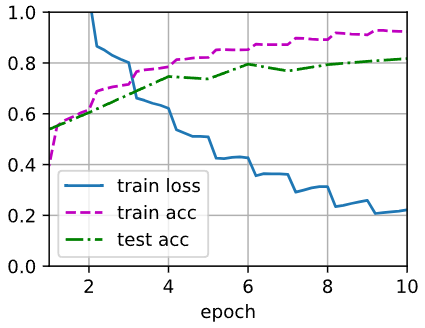
一些练习题
- 不使用图像增广训练模型 :如果你把
train_augs也设成只做ToTensor(),你会发现训练准确率 会非常快地逼近 100%,但是测试准确率会停滞在一个较低的水平甚至下降。这证明了模型过拟合了(死记硬背了训练集),也反向证明了图像增广能有效减轻过拟合。- 结合多种方法 :如果使用
Compose将翻转、裁剪、颜色变化结合起来训练 CIFAR-10,测试准确性通常会进一步提升(但需要训练更多的 epoch,因为任务变难了,模型需要更多时间收敛)。- 查阅文档 :
torchvision.transforms里还有很多好用的方法,比如:
RandomRotation: 随机旋转图片。RandomErasing: 随机擦除图片上的一块矩形区域(模拟物体被遮挡)。GaussianBlur: 高斯模糊(让模型不要过度依赖高频清晰的细节)。
二、微调
当目标数据集比较小、但任务和 ImageNet 这类大规模自然图像数据集有相似性时,不要从零开始训练整个模型,而应该把预训练模型学到的"通用视觉知识"迁移过来,再针对新任务做微调。
2.1 为什么需要微调
以前学过两种典型情形:
- 小数据集:比如 Fashion-MNIST,只有 6 万张图;
- 超大数据集:比如 ImageNet,千万级图像、1000 类别。
现实里很多任务都介于两者之间。比如:
- 识别不同椅子款式;
- 区分某种零食是否出现;
- 某工业零件是否缺陷。
这类任务往往有两个特点:
- 数据不算特别少,但远不够大;
- 如果从头训练大模型,很容易过拟合。
所以就有了迁移学习(transfer learning)。
- 迁移学习与微调的关系
- 迁移学习:总称,指把一个任务上学到的知识迁移到另一个任务。
- 微调(fine-tuning):迁移学习里最常见的一种做法。
你可以把它理解成:
- 在 ImageNet 上训练好的模型,已经学会了很多视觉基础能力:
- 边缘
- 纹理
- 颜色组合
- 局部形状
- 物体部件组合
- 这些能力对"热狗识别""椅子识别"仍然有价值。
也就是说,虽然 ImageNet 里的大多数图片不是热狗,也不是椅子,但它学到的底层和中层特征依然通用。
2.2 微调的四个步骤
1、在源数据集上预训练源模型
比如在 ImageNet 上训练一个 ResNet-18。
2、复制源模型结构与参数,但去掉原输出层(因为原输出层是专门为 ImageNet 的 1000 类服务的,它和"热狗 / 非热狗"这个新任务不匹配。)
3、添加新的输出层
例如新任务只有 2 类,就新建一个 2 分类层。
4、在目标数据集上训练
- 新输出层:从头学习;
- 其余层:在预训练参数基础上继续微调。
2.3 为什么微调有效
核心原因有两个:
(1)更好的初始化
如果从头训练,参数是随机的;
如果微调,参数来自 ImageNet 训练结果,已经处在一个很好的区域。
(2)更强的泛化能力
小数据集很容易把模型"带偏";
预训练参数相当于给模型加了一个强先验:
"别乱学,先沿着已有的通用视觉知识微调。"
所以微调通常能:
- 收敛更快;
- 精度更高;
- 对小数据集更稳。
我们可以把 ResNet-18 拆成两部分:
2.4 输出层要用更大的学习率
原因
- backbone 的参数来自预训练,已经比较好;
- 新的 fc 层是随机初始化的,几乎什么都没学到。
如果所有层都用一样的小学习率:
- backbone 更新得合理;
- 但新 fc 层学得太慢。
所以我们后面实践部分的做法是:
- backbone:学习率 = (η\etaη)
- 新fc层:学习率 = (10η10\eta10η)
这叫做 差分学习率(discriminative learning rates)。
2.5 输入要按 ImageNet 的均值和方差做标准化
这一点也非常重要。
预训练的 ResNet-18 是在 ImageNet 上训练的,而训练时输入通常都做过下面的标准化:
- mean =
[0.485, 0.456, 0.406] - std =
[0.229, 0.224, 0.225]
如果你现在拿新数据直接喂进去,而不做同样分布的归一化,那么模型看到的数据分布和它预训练时看到的分布不一致,会影响效果。
所以这里不是"随便归一化",而是为了和预训练模型的输入分布保持一致。
2.6 代码实现
导入库
python
%matplotlib inline
from d2l import torch as d2l
from torch import nn
import torch
import torchvision
import os下载并解压数据集
python
d2l.DATA_HUB['hotdog'] = (d2l.DATA_URL + 'hotdog.zip',
'fba480ffa8aa7e0febbb511d181409f899b9baa5')
data_dir = d2l.download_extract('hotdog')读取训练集和测试集
python
train_imgs = torchvision.datasets.ImageFolder(os.path.join(data_dir, 'train'))
test_imgs = torchvision.datasets.ImageFolder(os.path.join(data_dir, 'test'))可视化部分样本
python
hotdogs = [train_imgs[i][0] for i in range(8)]
not_hotdogs = [train_imgs[-i - 1][0] for i in range(8)]
d2l.show_images(hotdogs + not_hotdogs, 2, 8, scale=1.4);
定义数据预处理与数据增广
python
normalize = torchvision.transforms.Normalize(
[0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
train_augs = torchvision.transforms.Compose([
torchvision.transforms.RandomResizedCrop(224),
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ToTensor(),
normalize])
test_augs = torchvision.transforms.Compose([
torchvision.transforms.Resize([256, 256]),
torchvision.transforms.CenterCrop(224),
torchvision.transforms.ToTensor(),
normalize])-
对 RGB 三个通道分别做标准化,均值和标准差来自 ImageNet,这是为了和预训练模型的输入分布保持一致。
-
训练集:
-
把多个变换串起来,按顺序执行。
- 随机裁剪,随机水平翻转,
-
最后再做标准化。
-
-
验证集无需做随机增强,因为测试阶段要的是稳定、可重复的评估结果。
加载预训练模型
python
pretrained_net = torchvision.models.resnet18(pretrained=True)- 加载一个在 ImageNet 上预训练好的 ResNet-18;
pretrained=True表示自动加载训练好的参数。
查看最后一层
python
pretrained_net.fc输出:
Linear(in_features=512, out_features=1000, bias=True)ResNet-18 最后分类层:
- 输入特征维度:512
- 输出类别数:1000(对应 ImageNet 1000 类)
构建微调模型
python
finetune_net = torchvision.models.resnet18(pretrained=True)
finetune_net.fc = nn.Linear(finetune_net.fc.in_features, 2)
nn.init.xavier_uniform_(finetune_net.fc.weight);- 再加载一个预训练好的 ResNet-18,这个模型将作为真正参与微调的模型。
- 把原来的 1000 分类层替换成 2 分类层,然后更改下维度
- backbone 保留预训练参数,最后一层重新定义,适配热狗任务。
- 用 Xavier 均匀分布初始化新
fc层的权重;
定义训练函数
python
def train_fine_tuning(net, learning_rate, batch_size=128, num_epochs=5,
param_group=True):
train_iter = torch.utils.data.DataLoader(torchvision.datasets.ImageFolder(
os.path.join(data_dir, 'train'), transform=train_augs),
batch_size=batch_size, shuffle=True)
test_iter = torch.utils.data.DataLoader(torchvision.datasets.ImageFolder(
os.path.join(data_dir, 'test'), transform=test_augs),
batch_size=batch_size)
devices = d2l.try_all_gpus()
loss = nn.CrossEntropyLoss(reduction="none")
if param_group:
params_1x = [param for name, param in net.named_parameters()
if name not in ["fc.weight", "fc.bias"]]
trainer = torch.optim.SGD([{'params': params_1x},
{'params': net.fc.parameters(),
'lr': learning_rate * 10}],
lr=learning_rate, weight_decay=0.001)
else:
trainer = torch.optim.SGD(net.parameters(), lr=learning_rate,
weight_decay=0.001)
d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,
devices)param_group=True:是否使用参数分组(即输出层 10 倍学习率)。- 否则所有参数都用同一个学习率,这通常用于"从零训练"的模型。
微调训练
python
train_fine_tuning(finetune_net, 5e-5)输出:
loss 0.549, train acc 0.858, test acc 0.919
44.5 examples/sec on [device(type='cuda', index=0)]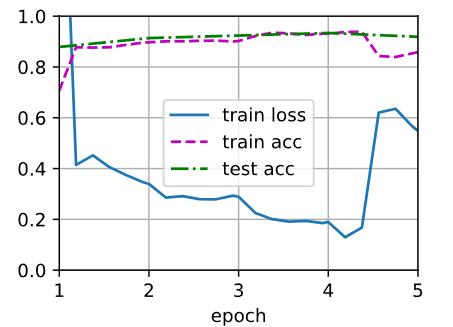
为什么学习率这么小?
因为 backbone 参数已经很不错了,不能大幅破坏。
从零开始训练作对比
python
scratch_net = torchvision.models.resnet18()
scratch_net.fc = nn.Linear(scratch_net.fc.in_features, 2)
train_fine_tuning(scratch_net, 5e-4, param_group=False)- 新建一个 ResNet-18,没有加载预训练权重,参数是随机初始化的。
- 学习率设成
5e-4,比微调大;
输出:
loss 0.370, train acc 0.833, test acc 0.824
45.8 examples/sec on [device(type='cuda', index=0)]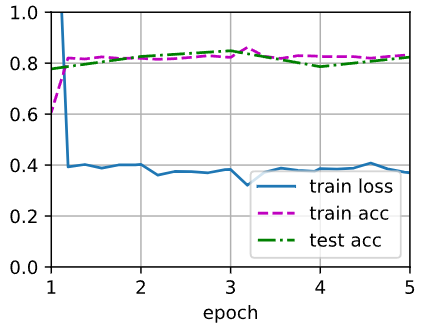
2.7 为什么微调通常比从零训练好
这里你要从三个角度理解。
1. 优化角度
从头训练:
- 起点差;
- 需要自己摸索出有意义的视觉特征;
- 在小数据集上很难。
微调:
- 起点好;
- 模型已经能看懂很多自然图像结构;
- 只需要适配任务。
2. 泛化角度
从头训练容易记住训练集细节,泛化差。
微调相当于说:
- "先别乱改,你已经知道什么是边缘、纹理、食物形状了;
- 现在只是在这些知识上学会区分热狗和非热狗。"
这比从零学更稳。
3. 数据效率角度
微调最大的优点之一是:同样的数据量下,效果更好;同样的效果下,需要的数据更少。
一些课后题
题 1:继续提高
finetune_net的学习率,模型的准确性如何变化?通常会先变好一点,再变差。
也就是说,准确率对学习率的关系常常是:
- 太小:学得慢,5 个 epoch 内没充分收敛;
- 合适:效果最好;
- 太大:破坏预训练参数,甚至训练不稳定。
- 微调时,backbone 里的参数已经是"好参数"了。
如果学习率太大,每一步更新都会太猛烈,导致:
- 原本有用的通用视觉特征被迅速破坏;
- 出现 catastrophic forgetting(灾难性遗忘);
- 在小数据集上更容易过拟合或震荡。
题 2:进一步调整
finetune_net和scratch_net的超参数,它们的准确性还有不同吗?通常仍然有差异,但差距可能缩小。
如果你给
scratch_net更多训练资源,比如:
- 更长训练轮数
- 更好的学习率调度
- 更强的数据增强
- 更合适的 weight decay
- 更仔细的超参数搜索
那么从零训练的模型是有机会追上来的,因为 ResNet-18 本身有足够的表达能力。
题 3:把
finetune_net输出层之前的参数冻结,只训练输出层,准确性如何变化?教材给的 PyTorch 提示是:
pythonfor param in finetune_net.parameters(): param.requires_grad = False冻结特征提取层、只训练最后一层,这种做法叫:
- 固定特征提取器
- 或 feature extractor 模式
它通常会出现这样的关系:
全量微调≥冻结 backbone 只训 fc≥从零训练 \text{全量微调} \ge \text{冻结 backbone 只训 fc} \ge \text{从零训练} 全量微调≥冻结 backbone 只训 fc≥从零训练但不是绝对,在非常小的数据集上,冻结 backbone 有时反而更稳,因为它减少了过拟合风险。
题 4:ImageNet 中本来就有 hotdog 类,如何利用这一类对应的输出层权重?
python
weight = pretrained_net.fc.weight
hotdog_w = torch.split(weight.data, 1, dim=0)[934]
hotdog_w.shape把它作为新二分类头中"hotdog 类"的初始化权重
2.8 微调的本质
- 复用预训练模型学到的通用表示;
- 丢掉和源标签绑定过深的输出层;
- 给新任务建新输出层;
- 用较小学习率调整 backbone,用较大学习率训练新头。
三、目标检测和边缘框
我们不仅关注目标是什么,还关注目标在哪。
3.1 什么是目标检测?
目标检测:
输入一张图片,输出多个目标,每个目标包含:(类别, 位置)
因为要描述物体在图中的位置,就得有一种统一的方式来"框住"它。
最常见的方法就是画一个矩形,把目标尽量完整地包起来,这个矩形就叫:
- 边界框
- bounding box
- 简写 bbox
例如:
- 狗在左边,就用一个矩形框住狗;
- 猫在右边,就用另一个矩形框住猫。
3.2 边界框的两种表示方式
方式一:左上角 + 右下角
记为:
(x1,y1,x2,y2) (x_1, y_1, x_2, y_2) (x1,y1,x2,y2)
- ((x_1, y_1)):左上角坐标
- ((x_2, y_2)):右下角坐标
这也是最直观的表示方式。
方式二:中心点 + 宽度 + 高度
记为:
(cx,cy,w,h) (c_x, c_y, w, h) (cx,cy,w,h)
- ((c_x, c_y)):边界框中心点
- (w):宽度
- (h):高度
因为不同任务里,适合的表示不一样。
左上右下格式适合:
- 直接画框;
- 判断两个框是否重叠;
- 和图像坐标一一对应。
中心宽高格式适合:
- 神经网络预测;
- 锚框(anchor box)相关计算;
- 对宽高和中心偏移进行回归。
图像坐标系是什么样的?
- 原点在左上角
- 向右是 (x) 轴正方向
- 向下是 (y) 轴正方向
3.3 代码实现
python
%matplotlib inline
from d2l import torch as d2l
import torch
python
d2l.set_figsize()
img = d2l.plt.imread('../img/catdog.jpg')
d2l.plt.imshow(img);
python
def box_corner_to_center(boxes):
"""从(左上,右下)转换到(中间,宽度,高度)"""
x1, y1, x2, y2 = boxes[:, 0], boxes[:, 1], boxes[:, 2], boxes[:, 3]
cx = (x1 + x2) / 2
cy = (y1 + y2) / 2
w = x2 - x1
h = y2 - y1
boxes = d2l.stack((cx, cy, w, h), axis=-1)
return boxes
python
def box_center_to_corner(boxes):
"""从(中间,宽度,高度)转换到(左上,右下)"""
cx, cy, w, h = boxes[:, 0], boxes[:, 1], boxes[:, 2], boxes[:, 3]
x1 = cx - 0.5 * w
y1 = cy - 0.5 * h
x2 = cx + 0.5 * w
y2 = cy + 0.5 * h
boxes = d2l.stack((x1, y1, x2, y2), axis=-1)
return boxes验证下转换函数对不对:
python
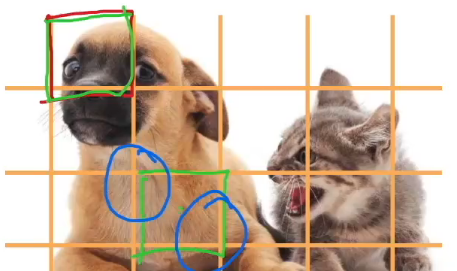
dog_bbox, cat_bbox = [60.0, 45.0, 378.0, 516.0], [400.0, 112.0, 655.0, 493.0]
boxes = d2l.tensor((dog_bbox, cat_bbox))
box_center_to_corner(box_corner_to_center(boxes)) == boxes输出:
tensor([[True, True, True, True],
[True, True, True, True]])把边界框画成矩形
python
def bbox_to_rect(bbox, color):
return d2l.plt.Rectangle(
xy=(bbox[0], bbox[1]), width=bbox[2]-bbox[0], height=bbox[3]-bbox[1],
fill=False, edgecolor=color, linewidth=2)
python
fig = d2l.plt.imshow(img)
fig.axes.add_patch(bbox_to_rect(dog_bbox, 'blue'))
fig.axes.add_patch(bbox_to_rect(cat_bbox, 'red'));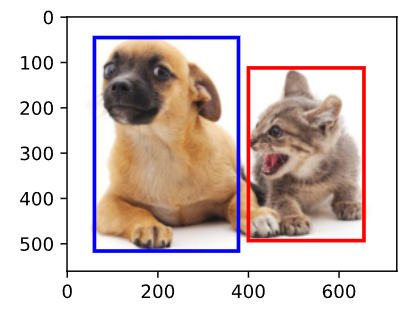
一些练习题
3.4 目标检测数据集
和图像分类相比,目标检测数据集最大的区别是:
- 图像分类标签只有一个类别,比如
cat、dog - 目标检测标签除了类别,还要有边界框坐标
也就是说,一张图的标签不再只是一个数字,而是类似:
text
[类别, x1, y1, x2, y2]类别:目标属于哪一类x1, y1:边界框左上角x2, y2:边界框右下角
这节用的是一个很小的人工数据集:香蕉检测数据集。 每张图里只有一根香蕉,所以它特别适合入门。
代码实现:
python
%matplotlib inline
from d2l import torch as d2l
import torch
import torchvision
import os
import pandas as pd注册并下载数据集
python
d2l.DATA_HUB['banana-detection'] = (
d2l.DATA_URL + 'banana-detection.zip',
'5de26c8fce5ccdea9f91267273464dc968d20d72')读取香蕉数据集
python
def read_data_bananas(is_train=True):
"""读取香蕉检测数据集中的图像和标签"""
data_dir = d2l.download_extract('banana-detection')
csv_fname = os.path.join(data_dir, 'bananas_train' if is_train
else 'bananas_val', 'label.csv')
csv_data = pd.read_csv(csv_fname)
csv_data = csv_data.set_index('img_name')
images, targets = [], []
for img_name, target in csv_data.iterrows():
images.append(torchvision.io.read_image(
os.path.join(data_dir, 'bananas_train' if is_train else
'bananas_val', 'images', f'{img_name}')))
# 这里的target包含(类别,左上角x,左上角y,右下角x,右下角y),
# 其中所有图像都具有相同的香蕉类(索引为0)
targets.append(list(target))
return images, torch.tensor(targets).unsqueeze(1) / 256返回的这个处理:
python
return images, torch.tensor(targets).unsqueeze(1) / 256unsqueeze(1)
在第 1 维插入一个长度为 1 的维度。
于是形状从:
python
[n, 5]变成:
python
[n, 1, 5]为什么要这么做?
因为目标检测里,一张图可能有多个边界框。
统一格式通常设计成:
python
[样本数, 每张图的边界框数, 每个边界框的5个值]也就是:
python
[n, m, 5]其中:
n:样本数m:每张图中最大边界框数量5:[class, x1, y1, x2, y2]
而这个香蕉数据集每张图只有 1 个 边界框,所以这里:
python
m = 1于是标签形状就是:
python
[n, 1, 5]这是一种非常典型的检测任务标签设计。
然耨把标签里的边界框坐标除以 256,进行归一化。
因为这批图片大小是 256 × 256,所以除以 256 后,坐标范围大致落在:
python
0 ~ 1这样做的好处是:
- 不依赖具体像素尺寸
- 数值尺度更稳定
- 后面模型训练更方便
Dataset
python
class BananasDataset(torch.utils.data.Dataset):
"""一个用于加载香蕉检测数据集的自定义数据集"""
def __init__(self, is_train):
self.features, self.labels = read_data_bananas(is_train)
print('read ' + str(len(self.features)) + (f' training examples' if
is_train else f' validation examples'))
def __getitem__(self, idx):
return (self.features[idx].float(), self.labels[idx])
def __len__(self):
return len(self.features)构造 DataLoader
python
def load_data_bananas(batch_size):
"""加载香蕉检测数据集"""
train_iter = torch.utils.data.DataLoader(BananasDataset(is_train=True),
batch_size, shuffle=True)
val_iter = torch.utils.data.DataLoader(BananasDataset(is_train=False),
batch_size)
return train_iter, val_iter读取一个 batch 并看形状
python
batch_size, edge_size = 32, 256
train_iter, _ = load_data_bananas(batch_size)
batch = next(iter(train_iter))
batch[0].shape, batch[1].shape输出:
read 1000 training examples
read 100 validation examples
(torch.Size([32, 3, 256, 256]), torch.Size([32, 1, 5]))演示代码
python
imgs = (batch[0][0:10].permute(0, 2, 3, 1)) / 255
axes = d2l.show_images(imgs, 2, 5, scale=2)
for ax, label in zip(axes, batch[1][0:10]):
d2l.show_bboxes(ax, [label[0][1:5] * edge_size], colors=['w'])四、锚框
4.1 什么是锚框
目标检测不像图像分类只输出一个类别,它要同时回答两件事:
- 图里有什么
- 它在哪
模型一开始并不知道物体在哪,所以通常不会"凭空"直接输出框,而是先准备很多个候选框,再判断哪些候选框里有目标,并把候选框修正成更准确的位置。
这些候选框里最经典的一类就是:锚框(anchor boxes)
- 先在图像上每个位置放一些"模板框"
- 这些模板框有不同大小、不同长宽比
- 模型只需要判断:
- 这个模板框里有没有物体
- 如果有,要往哪偏一点、缩放多少,才能更贴合真实物体
所以锚框的核心思想是:把"直接找框"变成"从已有模板框出发做分类 + 回归修正"。
为什么锚框要"每个像素/位置生成多个"?
因为真实物体:
- 大小不同
- 形状不同
- 出现位置不同
如果一个位置只放一个固定大小的框,那它只能覆盖很有限的一类目标。
所以在同一个位置,我们要放多个框,比如:
- 大框 / 中框 / 小框
- 扁一点的框 / 高一点的框 / 正方形框
这样无论目标偏大、偏小、偏胖、偏瘦,都更容易有某个锚框和它比较接近。
4.2 锚框的两个超参数:scale 和 ratio
这节里一个锚框由两个量决定:
- 缩放比
s(scale) - 宽高比
r(aspect ratio)
宽高比 r定义为:
r=widthheight r=\frac{\text{width}}{\text{height}} r=heightwidth
缩放比 s
size 表示这个框整体有多大。
教材里把框的尺寸和图像尺寸关联起来,所以 s 一般取 (0,1] 之间的数。
例如:
s = 0.75:比较大的框s = 0.25:比较小的框
4.3 IoU
IoU(Intersection over Union),中文通常叫:
- 交并比
- 杰卡德系数在框上的应用
loU 用来计算两个框之间的相似度
定义:
IoU=交集面积并集面积 IoU = \frac{\text{交集面积}}{\text{并集面积}} IoU=并集面积交集面积
取值范围:
0:完全不重叠1:完全重合
IoU 越大,说明锚框越像真实框。
4.4 给每个锚框打标签
每个锚框是一个训练样本。
训练时模型要学两件事:
- 这个锚框是背景,还是某个物体
- 如果它对应某个物体,应该怎么挪、怎么缩放,才能更接近真实框
因此每个锚框都要有两类标签:
- 类别标签
- 偏移量标签
4.5 锚框与真实框怎么匹配?
- 每个锚框都找和自己 IoU 最大的真实框
- 但不能只这么做,因为可能有某个真实框根本没被分到任何锚框
- 所以还要保证:每个真实框至少分配给一个锚框
我们先重复做如下流程:
- 对每个锚框,找 IoU 最大的真实框
- 如果这个最大 IoU 超过阈值(默认 0.5),就把该真实框分给它
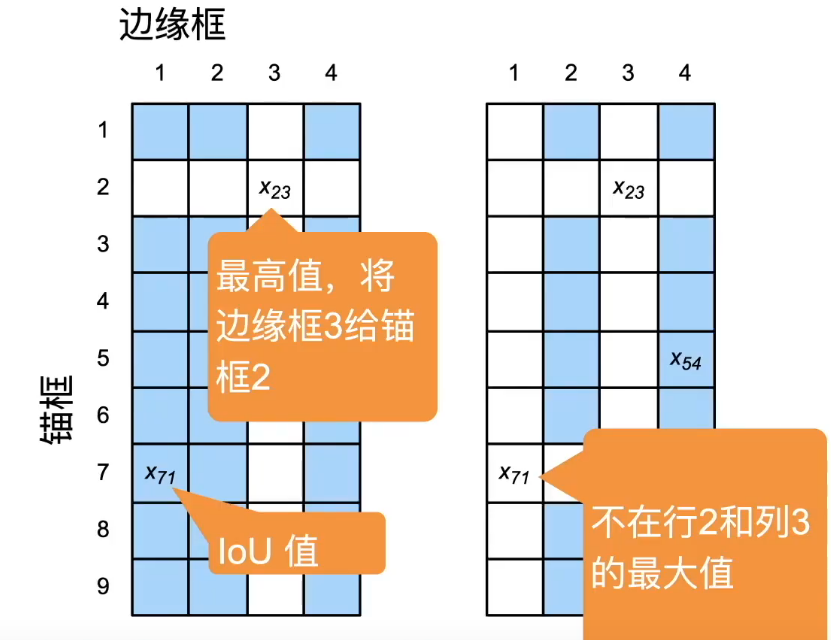
再保证每个真实框至少有一个锚框:
- 贪心地从整个 IoU 矩阵里反复找当前全局最大 IoU:
- 把这对 anchor / gt 强行匹配
- 然后丢掉该 anchor 对应的行、该 gt 对应的列
- 继续找下一个
这样就保证:每个真实框至少会有一个 anchor 负责它,否则某个目标可能因为整体 IoU 都偏低,训练时完全没有正样本去学它。
4.6 使用非极大值抑制(NMS)输出
锚框非常多,同一个目标附近通常会有许多相似锚框都预测成正类。
如果不处理,你会得到一堆重叠很高的框,比如同一只狗被框 20 次。
所以要做:非极大值抑制(NMS)
思想很简单:
- 先按置信度从高到低排序
- 取最高分框作为保留框
- 把与它 IoU 太大的其他框删掉(和它IoU越大,越说明预测的是同一物体)
- 继续处理剩余框
4.7 总体流程
- 一类目标检测算法基于锚框来预测
- 首先生成大量锚框,并赋予标号,每个锚框作为一个样本进行训练
- 在预测时,使用NMS来去掉冗余的预测
4.8 代码练习
环境准备 + 基础辅助函数
python
%matplotlib inline
# d2l 里封装了画图、显示图片等常用教学工具
from d2l import torch as d2l
# PyTorch 主库
import torch
# 让张量打印更简洁:只保留 2 位小数
torch.set_printoptions(precision=2, sci_mode=False)
# =========================
# 边界框格式转换辅助函数
# =========================
def box_corner_to_center(boxes):
"""
将边界框从 (xmin, ymin, xmax, ymax)
转换成 (cx, cy, w, h)
参数:
boxes: shape = (n, 4)
返回:
shape = (n, 4)
"""
# 左上角与右下角坐标
x1, y1, x2, y2 = boxes[:, 0], boxes[:, 1], boxes[:, 2], boxes[:, 3]
# 中心点坐标 = 两端点坐标平均值
cx = (x1 + x2) / 2
cy = (y1 + y2) / 2
# 宽高 = 右下角 - 左上角
w = x2 - x1
h = y2 - y1
# 按最后一维拼回去
return torch.stack((cx, cy, w, h), dim=-1)
def box_center_to_corner(boxes):
"""
将边界框从 (cx, cy, w, h)
转换成 (xmin, ymin, xmax, ymax)
参数:
boxes: shape = (n, 4)
返回:
shape = (n, 4)
"""
# 中心点和宽高
cx, cy, w, h = boxes[:, 0], boxes[:, 1], boxes[:, 2], boxes[:, 3]
# 左上角 = 中心点 - 半宽半高
x1 = cx - 0.5 * w
y1 = cy - 0.5 * h
# 右下角 = 中心点 + 半宽半高
x2 = cx + 0.5 * w
y2 = cy + 0.5 * h
return torch.stack((x1, y1, x2, y2), dim=-1)
def bbox_to_rect(bbox, color):
"""
把 (xmin, ymin, xmax, ymax) 格式的边界框
转换成 matplotlib 可以直接画的 Rectangle 对象
参数:
bbox: 长度为 4 的数组或张量
color: 边框颜色
返回:
matplotlib.patches.Rectangle
"""
return d2l.plt.Rectangle(
xy=(bbox[0], bbox[1]), # 左上角坐标
width=bbox[2] - bbox[0], # 宽度
height=bbox[3] - bbox[1], # 高度
fill=False, # 只画边框,不填充
edgecolor=color,
linewidth=2
)
def show_bboxes(axes, bboxes, labels=None, colors=None):
"""
在图像坐标轴上画多个边界框
参数:
axes: matplotlib 的坐标轴对象
bboxes: 一个边界框列表 / 张量,元素格式为 (xmin, ymin, xmax, ymax)
labels: 每个框对应的标签(可选)
colors: 每个框对应的颜色(可选)
"""
# 内部辅助函数:
# 如果输入不是 list/tuple,就包成 list,便于统一处理
def _make_list(obj, default_values=None):
if obj is None:
obj = default_values
elif not isinstance(obj, (list, tuple)):
obj = [obj]
return obj
# 统一把 labels / colors 处理成列表
labels = _make_list(labels)
colors = _make_list(colors, ['b', 'g', 'r', 'm', 'c'])
# 逐个边界框画出来
for i, bbox in enumerate(bboxes):
color = colors[i % len(colors)]
# 注意 matplotlib 更喜欢 numpy,所以这里转一下
rect = bbox_to_rect(d2l.numpy(bbox), color)
# 把矩形 patch 加到坐标轴上
axes.add_patch(rect)
# 如果提供了标签,就在框左上角附近画文字
if labels and len(labels) > i:
# 如果框本身是白色,文字就用黑色;否则文字用白色
text_color = 'k' if color == 'w' else 'w'
axes.text(
rect.xy[0], rect.xy[1], labels[i],
va='center', ha='center',
fontsize=9, color=text_color,
bbox=dict(facecolor=color, lw=0)
)生成锚框:multibox_prior
python
def multibox_prior(data, sizes, ratios):
"""
生成以每个像素为中心、具有不同尺度和宽高比的锚框
参数:
data: 输入图像或特征图,形状通常为 (batch, channel, height, width)
这里我们只关心它的 height 和 width
sizes: 缩放比列表,例如 [0.75, 0.5, 0.25]
ratios: 宽高比列表,例如 [1, 2, 0.5]
返回:
output: shape = (1, num_anchors, 4)
其中最后一维是 (xmin, ymin, xmax, ymax)
坐标是归一化后的坐标(范围通常在 0~1 左右)
"""
# 取输入的高和宽
in_height, in_width = data.shape[-2:]
# 设备:CPU 或 GPU
device = data.device
# sizes 和 ratios 的数量
num_sizes = len(sizes)
num_ratios = len(ratios)
# 每个像素位置生成多少个锚框
# 不是 num_sizes * num_ratios,而是 num_sizes + num_ratios - 1
# 因为教材只保留:
# (s1, r1), (s2, r1), ..., (sn, r1), (s1, r2), ..., (s1, rm)
boxes_per_pixel = num_sizes + num_ratios - 1
# 把 Python 列表转成张量,放到对应 device
size_tensor = torch.tensor(sizes, device=device)
ratio_tensor = torch.tensor(ratios, device=device)
# -------------------------
# 1. 生成每个像素位置的中心点
# -------------------------
# 一个像素的中心,不在整数格点上,而在 "格子中间"
# 所以偏移量取 0.5
offset_h, offset_w = 0.5, 0.5
# 在归一化坐标系下:
# y 轴每移动一个像素,相当于移动 1 / in_height
# x 轴每移动一个像素,相当于移动 1 / in_width
steps_h = 1.0 / in_height
steps_w = 1.0 / in_width
# center_h: 所有像素中心的 y 坐标,形状 (in_height,)
# 第 i 行像素中心的归一化坐标 = (i + 0.5) / in_height
center_h = (torch.arange(in_height, device=device) + offset_h) * steps_h
# center_w: 所有像素中心的 x 坐标,形状 (in_width,)
center_w = (torch.arange(in_width, device=device) + offset_w) * steps_w
# meshgrid 生成二维网格:
# shift_y.shape = (in_height, in_width)
# shift_x.shape = (in_height, in_width)
# 每个位置对应图像中的一个中心点
shift_y, shift_x = torch.meshgrid(center_h, center_w, indexing='ij')
# 拉平成一维,方便后面批量操作
# 现在每个位置都对应一个中心点,共 in_height * in_width 个
shift_y = shift_y.reshape(-1)
shift_x = shift_x.reshape(-1)
# -------------------------
# 2. 为每个中心点生成不同形状的锚框
# -------------------------
# 宽度 w 和高度 h 的构造逻辑:
#
# 对于基准 ratio_tensor[0](通常是 1):
# 使用所有 sizes -> (s1,r1), (s2,r1), ..., (sn,r1)
#
# 对于基准 size sizes[0]:
# 使用其余 ratios -> (s1,r2), (s1,r3), ..., (s1,rm)
#
# 因此总共 boxes_per_pixel = num_sizes + num_ratios - 1 个框
# 先构造宽度
# 注意:因为坐标是归一化坐标,x 和 y 的单位长度可能不同
# 所以这里乘 in_height / in_width,用于适配非正方形输入
w = torch.cat((
size_tensor * torch.sqrt(ratio_tensor[0]), # (s1,r1),(s2,r1),...
sizes[0] * torch.sqrt(ratio_tensor[1:]) # (s1,r2),(s1,r3),...
)) * in_height / in_width
# 再构造高度
h = torch.cat((
size_tensor / torch.sqrt(ratio_tensor[0]), # (s1,r1),(s2,r1),...
sizes[0] / torch.sqrt(ratio_tensor[1:]) # (s1,r2),(s1,r3),...
))
# 现在 w, h 的形状都是 (boxes_per_pixel,)
# 对于每一个锚框,我们最终要的是:
# (xmin, ymin, xmax, ymax)
#
# 如果中心在 (cx, cy),宽高为 (w, h),那么:
# xmin = cx - w/2
# ymin = cy - h/2
# xmax = cx + w/2
# ymax = cy + h/2
#
# 所以这里先构造相对中心点的偏移量:
# (-w/2, -h/2, w/2, h/2)
anchor_manipulations = torch.stack(
(-w, -h, w, h), dim=1
).repeat(in_height * in_width, 1) / 2
# anchor_manipulations 的形状:
# (in_height * in_width * boxes_per_pixel, 4)
# -------------------------
# 3. 把所有中心点复制成对应数量的锚框中心
# -------------------------
# 每个中心点需要重复 boxes_per_pixel 次
# 因为同一个中心点上有 boxes_per_pixel 个不同形状的框
out_grid = torch.stack(
[shift_x, shift_y, shift_x, shift_y], dim=1
).repeat_interleave(boxes_per_pixel, dim=0)
# out_grid 的形状也为:
# (in_height * in_width * boxes_per_pixel, 4)
# 将中心点坐标与相对偏移相加,得到最终锚框坐标
output = out_grid + anchor_manipulations
# 在最前面加一个 batch 维度,保持教材接口一致
# 输出形状:(1, num_anchors, 4)
return output.unsqueeze(0)生成锚框示例
python
# 读取示例图片
img = d2l.plt.imread('../img/catdog.jpg')
# 图像高和宽
h, w = img.shape[:2]
print(h, w)
# 构造一个假的输入张量:
# shape = (batch_size=1, channel=3, height=h, width=w)
# 这里像素值是什么并不重要,我们只需要它的高和宽
X = torch.rand(size=(1, 3, h, w))
# 为每个像素生成锚框
# sizes 有 3 个,ratios 有 3 个
# 所以每个像素生成 3 + 3 - 1 = 5 个锚框
Y = multibox_prior(X, sizes=[0.75, 0.5, 0.25], ratios=[1, 2, 0.5])
# 输出形状:
# (1, h * w * 5, 4)
print(Y.shape)查看某个像素中心对应的锚框
python
# 因为每个像素位置有 5 个锚框,所以把 Y reshape 成更直观的形状
# 这里直接把 batch 维省略掉
# boxes.shape = (h, w, 5, 4)
boxes = Y.reshape(h, w, 5, 4)
# 查看以 (250, 250) 这个像素位置为中心的第 0 个锚框
# 返回的是归一化坐标 (xmin, ymin, xmax, ymax)
print(boxes[250, 250, 0, :])把这些锚框画出来
python
# 画图尺寸
d2l.set_figsize()
# 由于 boxes 中的坐标是归一化坐标:
# x 轴坐标要乘 w,y 轴坐标要乘 h
bbox_scale = torch.tensor((w, h, w, h))
# 显示图片
fig = d2l.plt.imshow(img)
# 画出以 (250, 250) 为中心的 5 个锚框
show_bboxes(
fig.axes,
boxes[250, 250, :, :] * bbox_scale,
labels=[
's=0.75, r=1',
's=0.5, r=1',
's=0.25, r=1',
's=0.75, r=2',
's=0.75, r=0.5'
]
)计算 IoU:box_iou
python
def box_iou(boxes1, boxes2):
"""
计算两组边界框之间两两配对的 IoU(交并比)
参数:
boxes1: shape = (n1, 4)
boxes2: shape = (n2, 4)
返回:
iou: shape = (n1, n2)
其中 iou[i, j] = boxes1[i] 和 boxes2[j] 的 IoU
"""
# 定义一个小函数:计算一组边界框各自的面积
def box_area(boxes):
return (boxes[:, 2] - boxes[:, 0]) * (boxes[:, 3] - boxes[:, 1])
# 两组框的面积
# areas1.shape = (n1,)
# areas2.shape = (n2,)
areas1 = box_area(boxes1)
areas2 = box_area(boxes2)
# -------------------------
# 计算交集矩形的左上角和右下角
# -------------------------
# 对于两框交集矩形的左上角:
# x 要取两个 xmin 的较大值
# y 要取两个 ymin 的较大值
#
# boxes1[:, None, :2] 的形状是 (n1, 1, 2)
# boxes2[:, :2] 的形状是 (n2, 2)
# 利用广播后,结果是 (n1, n2, 2)
inter_upperlefts = torch.max(boxes1[:, None, :2], boxes2[:, :2])
# 对于交集矩形的右下角:
# x 要取两个 xmax 的较小值
# y 要取两个 ymax 的较小值
inter_lowerrights = torch.min(boxes1[:, None, 2:], boxes2[:, 2:])
# 交集矩形的宽高 = 右下角 - 左上角
# 如果两个框不相交,宽/高会变成负数,所以 clamp 到 0
inters = (inter_lowerrights - inter_upperlefts).clamp(min=0)
# inters.shape = (n1, n2, 2)
# inters[..., 0] 是交集宽
# inters[..., 1] 是交集高
# 交集面积
inter_areas = inters[:, :, 0] * inters[:, :, 1]
# 并集面积 = area1 + area2 - intersection
union_areas = areas1[:, None] + areas2 - inter_areas
# IoU = 交集面积 / 并集面积
return inter_areas / union_areas将真实边界框分配给锚框:assign_anchor_to_bbox
python
def assign_anchor_to_bbox(ground_truth, anchors, device, iou_threshold=0.5):
"""
将真实边界框分配给锚框
参数:
ground_truth: shape = (num_gt_boxes, 4)
真实边界框坐标,不包含类别列
anchors: shape = (num_anchors, 4)
所有锚框
device: CPU / GPU
iou_threshold: IoU 阈值
返回:
anchors_bbox_map: shape = (num_anchors,)
第 i 个元素表示第 i 个锚框分配给了哪个真实框
-1 表示该锚框未分配到任何真实框(背景)
"""
# 锚框数、真实框数
num_anchors = anchors.shape[0]
num_gt_boxes = ground_truth.shape[0]
# jaccard[i, j] = 第 i 个锚框与第 j 个真实框的 IoU
jaccard = box_iou(anchors, ground_truth)
# anchors_bbox_map[i] = j
# 表示第 i 个锚框被分配给了第 j 个真实框
# 初始值全设为 -1,表示还没分配
anchors_bbox_map = torch.full(
(num_anchors,), -1, dtype=torch.long, device=device
)
# -------------------------------------
# 第一步:先按阈值给锚框分配"最像"的真实框
# -------------------------------------
# 对每个锚框,找它和哪个真实框的 IoU 最大
# max_ious.shape = (num_anchors,)
# indices.shape = (num_anchors,)
max_ious, indices = torch.max(jaccard, dim=1)
# 找出 IoU 达到阈值的锚框索引
anc_i = torch.nonzero(max_ious >= iou_threshold, as_tuple=False).reshape(-1)
# 这些锚框对应的最佳真实框索引
box_j = indices[max_ious >= iou_threshold]
# 将这些锚框先分配出去
anchors_bbox_map[anc_i] = box_j
# -------------------------------------
# 第二步:确保每个真实框至少分到一个锚框
# -------------------------------------
#
# 这是一个贪心过程:
# 每次在整个 IoU 矩阵里找当前最大值,把对应的 anchor 和 gt 绑定
# 然后把该 anchor 所在行、该 gt 所在列作废
# 重复 num_gt_boxes 次
# 用 -1 作为"作废"标记,因为 IoU 原本范围在 [0, 1]
col_discard = torch.full((num_anchors,), -1.0, device=device)
row_discard = torch.full((num_gt_boxes,), -1.0, device=device)
for _ in range(num_gt_boxes):
# 找当前 IoU 矩阵里最大的元素的位置(展平成一维后的索引)
max_idx = torch.argmax(jaccard)
# 将一维索引还原成二维下标
# 列号 = max_idx % num_gt_boxes
box_idx = (max_idx % num_gt_boxes).long()
# 行号 = max_idx // num_gt_boxes
anc_idx = torch.div(max_idx, num_gt_boxes, rounding_mode='floor')
# 把这个锚框强行分配给这个真实框
anchors_bbox_map[anc_idx] = box_idx
# 将这个真实框所在列作废:表示它已经确保有锚框匹配了
jaccard[:, box_idx] = col_discard
# 将这个锚框所在行作废:表示这个锚框已经被用掉了
jaccard[anc_idx, :] = row_discard
return anchors_bbox_map计算偏移量标签:offset_boxes
python
def offset_boxes(anchors, assigned_bb, eps=1e-6):
"""
计算真实边界框相对于锚框的偏移量标签
参数:
anchors: shape = (num_anchors, 4)
assigned_bb: shape = (num_anchors, 4)
每个锚框分配到的真实框坐标
如果某个锚框是背景,对应位置通常是全 0
返回:
offset: shape = (num_anchors, 4)
每行是 (dx, dy, dw, dh)
"""
# 把锚框和真实框都转换成 (cx, cy, w, h)
c_anc = box_corner_to_center(anchors)
c_assigned_bb = box_corner_to_center(assigned_bb)
# 中心点偏移:
# (x_gt - x_anchor) / w_anchor
# (y_gt - y_anchor) / h_anchor
# 再乘 10,相当于除以 sigma_x = sigma_y = 0.1
offset_xy = 10 * (c_assigned_bb[:, :2] - c_anc[:, :2]) / c_anc[:, 2:]
# 宽高偏移:
# log(w_gt / w_anchor), log(h_gt / h_anchor)
# 再乘 5,相当于除以 sigma_w = sigma_h = 0.2
offset_wh = 5 * torch.log(eps + c_assigned_bb[:, 2:] / c_anc[:, 2:])
# 拼回 4 维偏移量
offset = torch.cat([offset_xy, offset_wh], dim=1)
return offset生成训练标签:multibox_target
python
def multibox_target(anchors, labels):
"""
根据真实边界框给锚框打标签(类别 + 偏移量)
参数:
anchors: shape = (1, num_anchors, 4)
labels: shape = (batch_size, num_gt_boxes, 5)
每个真实框格式为:
[class, xmin, ymin, xmax, ymax]
返回:
bbox_offset: shape = (batch_size, num_anchors * 4)
每个锚框的偏移量标签(拉平成一维)
bbox_mask: shape = (batch_size, num_anchors * 4)
回归损失掩码:正样本为 1,背景为 0
class_labels: shape = (batch_size, num_anchors)
每个锚框的类别标签
其中 0 表示背景,前景类别从 1 开始编号
"""
# batch 大小
batch_size = labels.shape[0]
# anchors 原本形状是 (1, num_anchors, 4),这里把最前面的 batch 维去掉
anchors = anchors.squeeze(0)
# 用于收集每张图的输出
batch_offset = []
batch_mask = []
batch_class_labels = []
device = anchors.device
num_anchors = anchors.shape[0]
# 逐张图片处理
for i in range(batch_size):
# 当前图片的真实框标签
# shape = (num_gt_boxes, 5)
label = labels[i, :, :]
# 先给每个锚框分配一个真实框(或者 -1 表示背景)
# 注意这里只传入真实框坐标,不传类别列
anchors_bbox_map = assign_anchor_to_bbox(
label[:, 1:], anchors, device
)
# bbox_mask:哪些锚框是正样本
# anchors_bbox_map >= 0 表示这个锚框分到了真实框
#
# 先得到 shape = (num_anchors,)
# 再变成 (num_anchors, 1)
# 再 repeat 成 (num_anchors, 4)
# 因为每个锚框有 4 个 offset 分量
bbox_mask = ((anchors_bbox_map >= 0).float().unsqueeze(-1)).repeat(1, 4)
# 类别标签初始化为 0 ------ 0 表示背景
class_labels = torch.zeros(
num_anchors, dtype=torch.long, device=device
)
# 分配的真实框坐标初始化为全 0
assigned_bb = torch.zeros(
(num_anchors, 4), dtype=torch.float32, device=device
)
# 找出所有正样本锚框的索引
indices_true = torch.nonzero(
anchors_bbox_map >= 0, as_tuple=False
).reshape(-1)
# 这些正样本锚框分别对应哪个真实框
bb_idx = anchors_bbox_map[indices_true]
# 给正样本锚框赋类别标签
# 注意:真实类别通常从 0 开始,但这里 0 要留给背景
# 所以前景类别统一 +1
class_labels[indices_true] = label[bb_idx, 0].long() + 1
# 给正样本锚框填入对应的真实框坐标
assigned_bb[indices_true] = label[bb_idx, 1:]
# 计算偏移量标签
# 背景锚框虽然也会算出 offset,但乘 mask 后会变成 0
offset = offset_boxes(anchors, assigned_bb) * bbox_mask
# 拉平成一维后存起来
batch_offset.append(offset.reshape(-1))
batch_mask.append(bbox_mask.reshape(-1))
batch_class_labels.append(class_labels)
# 堆叠成 batch 形式
bbox_offset = torch.stack(batch_offset)
bbox_mask = torch.stack(batch_mask)
class_labels = torch.stack(batch_class_labels)
return bbox_offset, bbox_mask, class_labels用狗猫真实框 + 5 个锚框做标签示例
python
# ground_truth 的每一行格式:
# [类别, xmin, ymin, xmax, ymax]
# 这里 0 表示 dog,1 表示 cat
ground_truth = torch.tensor([
[0, 0.10, 0.08, 0.52, 0.92], # 狗
[1, 0.55, 0.20, 0.90, 0.88] # 猫
])
# 手工构造 5 个锚框
anchors = torch.tensor([
[0.00, 0.10, 0.20, 0.30],
[0.15, 0.20, 0.40, 0.40],
[0.63, 0.05, 0.88, 0.98],
[0.66, 0.45, 0.80, 0.80],
[0.57, 0.30, 0.92, 0.90]
])
# 先把真实框和锚框画出来看看
fig = d2l.plt.imshow(img)
# 真值框用黑色画
show_bboxes(fig.axes, ground_truth[:, 1:] * bbox_scale, ['dog', 'cat'], 'k')
# 锚框编号 0~4
show_bboxes(fig.axes, anchors * bbox_scale, ['0', '1', '2', '3', '4'])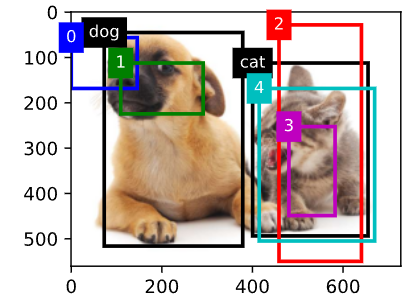
python
# multibox_target 的输入要有 batch 维
labels = multibox_target(
anchors.unsqueeze(0), # (1, 5, 4)
ground_truth.unsqueeze(0) # (1, 2, 5)
)
# labels 是一个三元组:
# labels[0] -> bbox_offset
# labels[1] -> bbox_mask
# labels[2] -> class_labels
print('class_labels =')
print(labels[2])
print('bbox_mask =')
print(labels[1])
print('bbox_offset =')
print(labels[0])预测时:根据 offset 反推出边界框 offset_inverse
python
def offset_inverse(anchors, offset_preds):
"""
根据锚框和模型预测的偏移量,恢复出预测边界框
参数:
anchors: shape = (num_anchors, 4)
offset_preds: shape = (num_anchors, 4)
返回:
predicted_bbox: shape = (num_anchors, 4)
格式为 (xmin, ymin, xmax, ymax)
"""
# 先把锚框转成中心坐标 + 宽高形式
anc = box_corner_to_center(anchors)
# 还原中心点:
# pred_cx = dx * w_anchor / 10 + cx_anchor
# pred_cy = dy * h_anchor / 10 + cy_anchor
pred_bbox_xy = (offset_preds[:, :2] * anc[:, 2:] / 10) + anc[:, :2]
# 还原宽高:
# pred_w = exp(dw / 5) * w_anchor
# pred_h = exp(dh / 5) * h_anchor
pred_bbox_wh = torch.exp(offset_preds[:, 2:] / 5) * anc[:, 2:]
# 拼成 (cx, cy, w, h)
pred_bbox = torch.cat((pred_bbox_xy, pred_bbox_wh), dim=1)
# 再转回 (xmin, ymin, xmax, ymax)
predicted_bbox = box_center_to_corner(pred_bbox)
return predicted_bbox非极大值抑制:nms
python
def nms(boxes, scores, iou_threshold):
"""
非极大值抑制(NMS)
参数:
boxes: shape = (num_boxes, 4)
scores: shape = (num_boxes,)
iou_threshold: IoU 阈值
返回:
keep: 保留下来的边界框索引
"""
# 按置信度从高到低排序,返回索引
B = torch.argsort(scores, dim=-1, descending=True)
# 保存最终保留的索引
keep = []
# 只要还有候选框,就继续
while B.numel() > 0:
# 当前置信度最高的框,一定保留
i = B[0].item()
keep.append(i)
# 如果只剩这一个框,直接结束
if B.numel() == 1:
break
# 计算当前最高分框与剩余框之间的 IoU
iou = box_iou(
boxes[i, :].reshape(-1, 4), # 当前基准框,shape=(1,4)
boxes[B[1:], :].reshape(-1, 4) # 剩余所有框
).reshape(-1)
# 只保留那些 IoU 不超过阈值的框
inds = torch.nonzero(iou <= iou_threshold, as_tuple=False).reshape(-1)
# B[0] 已经被保留了,所以从 B[1:] 里继续筛
B = B[inds + 1]
return torch.tensor(keep, device=boxes.device)完整预测后处理:multibox_detection
python
def multibox_detection(cls_probs, offset_preds, anchors,
nms_threshold=0.5,
pos_threshold=0.009999999):
"""
根据类别预测 + 偏移量预测 + 锚框,得到最终检测结果
参数:
cls_probs: shape = (batch_size, num_classes, num_anchors)
每个锚框对每个类别的预测概率
注意:第 0 类通常是背景类
offset_preds: shape = (batch_size, num_anchors * 4)
每个锚框预测的偏移量
anchors: shape = (1, num_anchors, 4)
nms_threshold: NMS 的 IoU 阈值
pos_threshold: 置信度阈值,太低的前景预测会被当作背景
返回:
out: shape = (batch_size, num_anchors, 6)
每个预测框的输出格式为:
[class_id, confidence, xmin, ymin, xmax, ymax]
其中:
- class_id = -1 表示背景或在 NMS 中被抑制
- 其余为前景类别编号(从 0 开始)
"""
device = cls_probs.device
batch_size = cls_probs.shape[0]
# anchors 的 batch 维只有 1,去掉即可
anchors = anchors.squeeze(0)
# 类别数、锚框数
num_classes = cls_probs.shape[1]
num_anchors = cls_probs.shape[2]
# 保存整个 batch 的输出
out = []
# 逐张图片处理
for i in range(batch_size):
# cls_prob.shape = (num_classes, num_anchors)
cls_prob = cls_probs[i]
# offset_pred.shape = (num_anchors, 4)
offset_pred = offset_preds[i].reshape(-1, 4)
# 对每个锚框,只看前景类别(跳过背景类 cls_prob[0])
# conf: 每个锚框的最大前景置信度
# class_id: 对应哪个前景类别(从 0 开始编号)
conf, class_id = torch.max(cls_prob[1:], dim=0)
# 根据锚框 + offset 恢复预测边界框
predicted_bb = offset_inverse(anchors, offset_pred)
# 做 NMS,得到保留下来的索引
keep = nms(predicted_bb, conf, nms_threshold)
# -------------------------
# 找出哪些框没被保留
# -------------------------
# all_idx: 所有锚框索引
all_idx = torch.arange(num_anchors, dtype=torch.long, device=device)
# 把 keep 和 all_idx 拼起来
combined = torch.cat((keep, all_idx))
# 统计每个索引出现次数
uniques, counts = combined.unique(return_counts=True)
# 只出现一次的,说明它只在 all_idx 里出现,
# 没有在 keep 里出现,所以是 non_keep
non_keep = uniques[counts == 1]
# 最终输出顺序:先 keep,再 non_keep
# 这样真正保留的预测框会排在前面
all_id_sorted = torch.cat((keep, non_keep))
# 把没保留的框类别记为 -1
class_id[non_keep] = -1
# 按新顺序重排
class_id = class_id[all_id_sorted]
conf = conf[all_id_sorted]
predicted_bb = predicted_bb[all_id_sorted]
# -------------------------
# 置信度过低的,也视为背景
# -------------------------
below_min_idx = (conf < pos_threshold)
# 这些框的类别改成 -1(背景 / 无效)
class_id[below_min_idx] = -1
# 书中这里把这些低置信度前景框的值改成 1-conf,
# 可以理解成一种"背景置信度"的表达
conf[below_min_idx] = 1 - conf[below_min_idx]
# 每个框最终输出 6 个值:
# [class_id, confidence, xmin, ymin, xmax, ymax]
pred_info = torch.cat((
class_id.unsqueeze(1).float(),
conf.unsqueeze(1),
predicted_bb
), dim=1)
out.append(pred_info)
return torch.stack(out)预测阶段示例:4 个锚框 + NMS
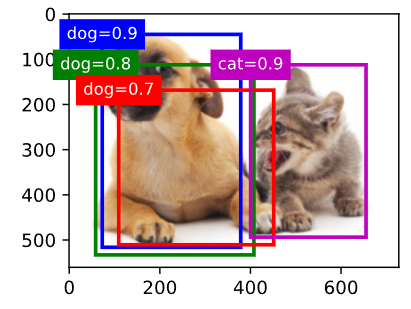
python
# 这里构造 4 个锚框
anchors = torch.tensor([
[0.10, 0.08, 0.52, 0.92],
[0.08, 0.20, 0.56, 0.95],
[0.15, 0.30, 0.62, 0.91],
[0.55, 0.20, 0.90, 0.88]
])
# 偏移量全设为 0
# 这意味着预测框 = 锚框本身
offset_preds = torch.zeros(anchors.numel())
# cls_probs 的形状是 (num_classes, num_anchors)
# 第 0 行:背景类概率
# 第 1 行:狗类概率
# 第 2 行:猫类概率
cls_probs = torch.tensor([
[0.0, 0.0, 0.0, 0.0], # 背景
[0.9, 0.8, 0.7, 0.1], # 狗
[0.1, 0.2, 0.3, 0.9] # 猫
])
# 先把原始预测框画出来
fig = d2l.plt.imshow(img)
show_bboxes(
fig.axes,
anchors * bbox_scale,
['dog=0.9', 'dog=0.8', 'dog=0.7', 'cat=0.9']
)
python
# multibox_detection 需要 batch 维,所以都加一个 unsqueeze(0)
output = multibox_detection(
cls_probs.unsqueeze(0), # (1, 3, 4)
offset_preds.unsqueeze(0), # (1, 16)
anchors.unsqueeze(0), # (1, 4, 4)
nms_threshold=0.5
)
# 输出形状: (1, 4, 6)
# 每一行是:
# [class_id, confidence, xmin, ymin, xmax, ymax]
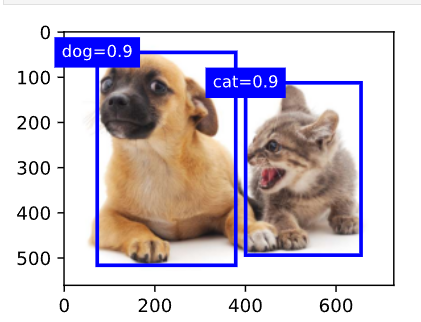
print(output)输出:
tensor([[[ 0.00, 0.90, 0.10, 0.08, 0.52, 0.92],
[ 1.00, 0.90, 0.55, 0.20, 0.90, 0.88],
[-1.00, 0.80, 0.08, 0.20, 0.56, 0.95],
[-1.00, 0.70, 0.15, 0.30, 0.62, 0.91]]])
python
# 只把真正保留下来的框画出来(class_id != -1)
fig = d2l.plt.imshow(img)
for row in d2l.numpy(output[0]):
# row[0] 是类别编号
if row[0] == -1:
continue
# row[1] 是置信度
# row[2:] 是边界框坐标
label = ('dog=', 'cat=')[int(row[0])] + str(row[1])
show_bboxes(
fig.axes,
[torch.tensor(row[2:]) * bbox_scale],
label
)
五、区域卷积神经网络(R-CNN)系列
R-CNN 家族的核心思想:先找"哪里可能有物体",再对这些候选区域做更精细的分类和边界框回归。
R-CNN 系列属于 two-stage(双阶段)检测: 先产生候选区域(proposal),再细致识别。
待会要介绍的4个R-CNN 模型:
- R-CNN:先裁图,再分别识别每一块
- Fast R-CNN:不再一块一块卷积,而是整图卷积一次,再从特征图里取每块
- Faster R-CNN:候选区域也不要手工方法生成了,改成神经网络自己提
- Mask R-CNN:不仅要框出物体,还要把物体的像素轮廓分出来
5.1 R-CNN:最原始的"两阶段检测"思想
1. R-CNN 想解决什么问题?
我们能不能先提出一批"看起来可能是物体"的区域,然后再对这些区域逐个判断?------这就是 R-CNN 的出发点。
2. R-CNN 的流程
讲义里说 R-CNN 有 4 步,我们逐步拆开。
第一步:用选择性搜索(Selective Search)找候选框
输入一张图像后,R-CNN 不会像 SSD 一样在每个位置直接用锚框密集预测,
它会先用一个传统视觉算法 Selective Search 找出大约 2000 个候选区域(proposal regions)。
这些候选区域的特点:
- 大小不同
- 长宽比不同
- 位置不同
- 希望"尽量覆盖可能的物体"
即 先粗略找出很多"可能有东西"的框,再慢慢筛。
Selective Search 是什么?
它不是神经网络,而是传统图像处理方法。
大致思路是:根据颜色、纹理、区域相似性等,把图像分割成很多小块,再不断合并,得到一批看起来像"物体"的区域。
所以:
- 优点:不需要训练
- 缺点:慢,而且和后面的深度网络是割裂的
第二步:把每个候选框裁出来,送进 CNN 提特征
R-CNN 的做法很"朴素":
- 对于每个 proposal
- 从原图中裁出这块区域
- resize 到固定大小(比如 224×224)
- 单独送进 CNN
- 取 CNN 的高层特征作为这个 proposal 的表示
也就是说,如果一张图有 2000 个 proposal:
- 你就要做 2000 次 CNN 前向传播
这就是 R-CNN 最大的问题。
第三步:用 SVM 分类
R-CNN 不是直接在 CNN 后面接 softmax 做分类,
它是先把 CNN 当特征提取器,再对每个类别训练一个 SVM。
比如:
- 一个 SVM 判断是不是狗
- 一个 SVM 判断是不是猫
- 一个 SVM 判断是不是车
这体现了当时深度学习和传统机器学习混合使用的风格。
第四步:用线性回归修正边界框
分类只告诉你"这块是不是狗",
但 proposal 本身未必很准,所以还要再做边界框回归:
- 输入:proposal 的 CNN 特征
- 输出:边界框的修正量
和前面的思想类似:
- 中心点偏移多少
- 宽高缩放多少
R-CNN 的本质
R-CNN 本质上就是:候选区域生成 + 每个候选区域独立提特征 + 分类 + 边框回归
可以看成目标检测最经典的"两阶段"模板:
- 阶段 1:先给出候选框
- 阶段 2:再识别这些候选框
R-CNN 为什么慢?
因为它对每个 proposal 都单独跑一次 CNN。 而这些 proposal 大量重叠:
- 这个框里有狗头
- 那个框里有半只狗
- 另一个框里有整只狗
它们覆盖的是图像中相似区域,
但 R-CNN 却反复对这些重叠区域做卷积,造成大量重复计算。
所以:R-CNN 的慢,不是因为分类器慢,而是因为卷积特征提取没有共享。
5.2 Fast R-CNN:"共享卷积计算"
Fast R-CNN 到底快在哪里?
Fast R-CNN 的核心思想:整张图只做一次卷积,然后从共享特征图中提取各个候选区域的特征。
这一下就把 R-CNN 的最大瓶颈解决了。
Fast R-CNN 的整体流程
设输入图像经过 backbone CNN 后得到特征图:
1×c×h1×w1 1 \times c \times h_1 \times w_1 1×c×h1×w1
这里:
1:batch sizec:通道数h1, w1:特征图高宽
假设有 n 个 proposal。
那么流程是:
第 1 步:整图卷积一次
整张图输入 CNN,只做一次前向传播,得到共享特征图。
第 2 步:把 proposal 映射到特征图上
proposal 原来在输入图像坐标系里,
现在要映射到特征图坐标系里,得到对应的 RoI(Region of Interest)。
注意:
- proposal:原图上的候选框
- RoI:候选框在特征图上的对应区域
第 3 步:RoI Pooling,把不同大小的区域变成同样大小
不同 proposal 的尺寸不同,
但全连接层要求输入维度固定。
所以 Fast R-CNN 引入了:
RoI Pooling(兴趣区域汇聚)
它把每个大小不同的 RoI,统一变成固定大小,比如:
h2×w2=7×7 h_2 \times w_2 = 7 \times 7 h2×w2=7×7
于是输出形状就变成:
n×c×h2×w2 n \times c \times h_2 \times w_2 n×c×h2×w2
也就是:
- 有
n个 proposal - 每个 proposal 都变成同样大小的特征块
第 4 步:送入全连接层
把每个 RoI 的固定大小特征展平,经过全连接层,得到:
n×d n \times d n×d
这里 d 是特征维度。
第 5 步:分别预测类别和边界框
然后分成两个头:
- 分类头:输出
n × q - 回归头:输出
n × 4
其中:
n:proposal 数量q:类别数
严格一点说,在原论文和很多实现里,bbox 回归常常是 每类一个回归器 ,所以会写成 n × 4q。
教材这里写成 n × 4 是为了突出主线,不影响理解。
Fast R-CNN 为什么比 R-CNN 快很多?
因为 R-CNN 是:2000 个 proposal → 2000 次 CNN
Fast R-CNN 是:1 张图 → 1 次 CNN → 2000 个 proposal 在特征图上共享这次卷积结果
所以卷积计算被共享了。这就是速度提升的根本原因。
RoI Pooling:这是 Fast R-CNN 的关键
1. 普通池化 vs RoI Pooling
之前学的普通池化层:
- 给定固定的窗口大小、步幅、填充
- 在整张特征图上滑动
- 输出大小由参数间接决定
而 RoI Pooling 不一样:
- 输入是"一个任意大小的区域"
- 直接指定输出大小,比如
2×2、7×7 - 不管输入区域多大,输出都固定
所以它的任务是:把大小不一的候选区域,统一压成固定大小的特征表示。
RoI Pooling 不是为了提取"更强特征",而是为了把"不同大小的候选区域"统一成"固定大小的特征块"。
这样后面的全连接层才能接上。
Fast R-CNN 仍然有一个大问题
虽然它解决了"重复卷积"的问题, 但 proposal 还是来自 Selective Search。
也就是说:
- 分类和回归已经交给神经网络了
- 但"候选框怎么来"仍然靠传统算法
所以它依然有两个问题:
- proposal 生成本身仍然慢
- proposal 生成不是网络的一部分,不能端到端学习
于是就有了 Faster R-CNN。
5.3 Faster R-CNN:把 proposal 生成也变成神经网络
1. Faster R-CNN 的最大思想 :不要再用 Selective Search 了,直接让网络自己在特征图上生成 proposal。
这个负责生成 proposal 的网络,叫:RPN:Region Proposal Network(区域提议网络)
2.Faster R-CNN 的整体结构
可以把 Faster R-CNN 看成两段:
第一段:RPN 负责"提建议"
- 哪些位置可能有物体?
- 给出一批高质量 proposal
第二段:Fast R-CNN head 负责"精修"
- 每个 proposal 到底是什么类别?
- 边界框再精修一次
所以它仍然是 two-stage detector。
RPN 是怎么工作的?
设 backbone 输出特征图形状:
B×C×H×W B \times C \times H \times W B×C×H×W
RPN 做的事情是:
第一步:在特征图上再接一个 3×3 卷积:使用填充为 1 的 3×3 卷积,把每个位置变成一个长度为 c 的新特征。
这一步的作用是:
- 让每个空间位置的感受野更适合预测 proposal
- 相当于给每个位置准备一份"局部上下文特征"
第二步:以每个像素为中心生成多个锚框
对于特征图上每个位置:
- 生成
k个 anchors - 大小不同
- 宽高比不同
H \\times W \\times k
第三步:对每个 anchor 做两件事
(1) 预测它是不是"有物体"
这是一个 二分类:
- object
- background
所以如果每个位置有 k 个 anchor,
分类头输出通道数通常是:2k2k2k
总形状:B×2k×H×WB \times 2k \times H \times WB×2k×H×W
这叫 objectness,即"目标性分数"。
注意这里还不是具体类别(狗、猫、车), 只是判断:这个 anchor 里有没有某个物体
(2) 预测这个 anchor 的边界框偏移量
和你之前学的偏移编码一样,每个 anchor 输出 4 个量:
dxdydwdh
所以回归头输出形状通常是:
B \\times 4k \\times H \\times W
第四步:把高分 anchor 变成 proposal,再做 NMS
RPN 得到:
- objectness score
- bbox delta
然后:
- 用 delta 修正 anchor,得到 proposal
- 去掉太小、越界的框
- 按分数排序
- 做 NMS 去重
- 保留 top-N proposal
这些 proposal 就送给第二阶段(RoI Pooling / RoI Align + 分类回归头)。
可以说:Faster R-CNN 的 RPN,本质上就是"在特征图上做一遍锚框分类 + 锚框回归"。
你前面那节不是白学的,它在这里直接变成了真正的模型组件。
5. Faster R-CNN 为什么更快?
因为 Selective Search 太慢。
RPN 虽然也是网络,但它:
- 和 backbone 共享特征图
- 计算量小
- proposal 质量高
- 能跟整个检测器联合训练
所以整体效率远高于传统 proposal 方法。
Faster R-CNN 的损失函数怎么理解?
可以粗略理解为 4 部分:
- RPN 分类损失:anchor 是否含物体
- RPN 回归损失:proposal 框的位置修正
- 第二阶段分类损失:proposal 是猫/狗/车/背景
- 第二阶段回归损失:进一步精修框的位置
所以 Faster R-CNN 其实做了 两次框回归:
- 第一次:anchor → proposal(RPN)
- 第二次:proposal → final box(RoI head)
这是它精度高的重要原因之一。
5.4 Mask R-CNN:从"框"升级到"像素级实例分割"
1. Mask R-CNN 比 Faster R-CNN 多了什么? ------除了分类和框回归,再加一个分支预测目标的像素级 mask。
也就是说,每个 proposal 不仅要回答:
- 这是什么类别?
- 框在哪里?
还要回答:
- 这个目标具体覆盖哪些像素?
这就不再只是目标检测,而是 实例分割(instance segmentation)。
2. 为什么要把 RoI Pooling 换成 RoI Align?
RoI Pooling 有一个问题:
- proposal 映射到特征图时,会做坐标量化/取整
- 每个 bin 划分时,也会取整
- 这样会造成空间位置偏移
对于分类来说,这点偏差还能忍。
但对于 mask 预测,这种偏移会让边缘不准。
所以 Mask R-CNN 引入:
RoI Align
它的关键思想是:
- 不做粗暴取整
- 直接在浮点坐标上采样
- 用 双线性插值(bilinear interpolation) 取特征值
这样能更精确保留空间位置信息。
什么是双线性插值?
如果你想在特征图的一个"非整数坐标"处取值,比如
(2.3, 5.7),这个点不正好落在网格点上。
双线性插值会看它附近 4 个整数网格点,按距离做加权平均,得到一个连续位置上的特征值。
所以 RoI Align 的本质是:
让 RoI 特征提取更"对齐"真实空间位置。
这对像素级任务特别重要。
Mask R-CNN 的输出是什么?
对每个 RoI,通常会有 3 个分支:
- 分类分支:类别
- 框回归分支:bbox
- mask 分支 :一个
m×m的二值/概率掩码
常见地可以写成:
- 分类:
n × q - bbox:
n × 4q - mask:
n × q × m × m
其中:
n:RoI 数量q:类别数m×m:mask 分辨率,比如28×28
训练时通常只对 RoI 的真实类别对应那一张 mask 计算损失。
Mask R-CNN 比 Faster R-CNN 强在哪?
因为它利用了更细粒度的监督:
- Faster R-CNN 只知道框
- Mask R-CNN 还知道每个目标具体占哪些像素
这会让模型学到更细致的物体边界和形状信息,往往也能反过来提升检测质量。
下面我按 PyTorch 版本 ,把 SSD(Single Shot MultiBox Detection,单发多框检测) 这一节从
整体思想 → 模型结构 → 每段代码 → 张量形状 → 训练 → 预测 → 练习中的改进点
完整讲一遍。
六、SSD
SSD 的核心思想是:不先生成 proposal(候选区域),而是直接在多个尺度的特征图上,对大量锚框同时做"分类 + 边界框回归"。
所以它属于:
- one-stage detector:单阶段检测
- dense prediction:密集预测
- multi-scale detection:多尺度检测
和你刚才学的 R-CNN 系列相比:
- R-CNN / Faster R-CNN:先 proposal,再分类回归
- SSD:直接在锚框上预测,不走 proposal 这一步
所以 SSD 的优点是:
- 结构更直接
- 推理更快
- 工程实现比较自然
但挑战也很明显:
- 锚框非常多
- 正负样本极不平衡
- 小目标比较难
1. Single Shot :一趟前向传播里,直接把检测结果做出来
不像 Faster R-CNN 那样先做 RPN,再做第二阶段分类回归。
- MultiBox:每个位置不只预测一个框,而是预测多个不同形状/大小的锚框
为什么要多尺度?------因为不同大小的目标,适合在不同分辨率的特征图上检测。
大特征图
- 空间分辨率高
- 更适合小目标
- 因为小目标在这里不会"缩没了"
小特征图
- 分辨率低,但感受野大
- 更适合大目标
- 因为一个位置能"看到"更大区域
所以 SSD 的关键设计就是:在多个尺度的特征图上都做检测。
七、YOLO(你只看一次)
- SSD中锚框大量重叠,因此浪费了很多计算
- YOLO 将图片均匀分成SxS个锚框
- 每个锚框预测 B个边缘框
- 后续版本(V2,3,V4...)有持续改进