VideoWorld:在无标签视频中学习知识
论文:VideoWorld: ExploringKnowledge Learning from Unlabeled Videos
VideoWorld 的核心方法是一种基于"下一帧预测(Next-token prediction)"的自回归视频生成框架,并且创新性地引入了潜在动力学模型(Latent Dynamics Model, LDM)来压缩和表征视觉动态变化。
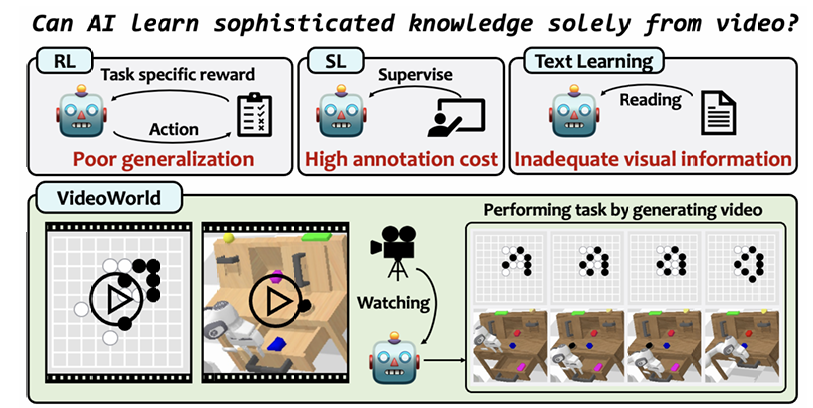
- 图 1 VideoWorld 模型探索从无标签视频中学习知识,所学知识涵盖特定任务的规则,乃至高级的推理与规划能力。与强化学习(RL)、监督学习(SL)和基于文本的学习这三类主流学习方法相比,该模型具备三大优势:1)通过适配各类任务与交互界面的统一视觉表征,实现更优的泛化性能;2)大幅降低人工标注的工作量;3)相比文本描述的方式,能习得更丰富的现实世界信息。
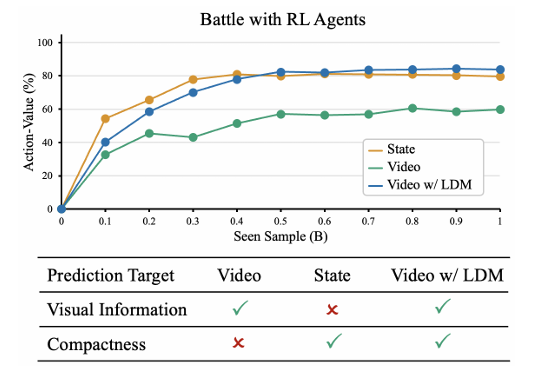
- 图 2 预测目标对比。"状态""视频" 和 "结合潜在动力学模型的视频" 代表三种不同的预测目标,分别为:状态序列(如围棋中带标注的落子位置)、原始视频序列,以及融合了表征未来视觉变化的潜在编码的视频序列(VideoWorld 模型采用的方案)。"动作价值" 指游戏中每一步落子的评分。将视频信息与视觉变化的紧凑表征相结合,能够实现更高效的模型学习。
VideoWorld方法可以分为以下四个核心步骤/模块:
1. 基础视频生成框架 (Basic Video Generation Framework)
VideoWorld 的底层逻辑与大语言模型(LLMs)非常相似,只是把"文本词汇"换成了"视觉离散Token"。
- 视觉分词器 (VQ-VAE):使用 MAGVIT-v2(结合FSQ量化器)将连续的原始视频帧压缩并离散化为一系列视觉 Token。
- stage 1 LDM-潜在动力学模型 :输入当前frame xtx_{t}xt和一段未来frame,提取时间动态的变化embedding,作为一组潜在编码ztz_{t}zt
- stage 2 自回归 Transformer :使用类似 Llama 的 Transformer 架构。模型接收过去的视频 Token 序列和ztz_{t}zt,通过自回归的方式预测下一帧的 Token(Teacher Forcing)。这样,视频序列本身就成了唯一的知识来源。
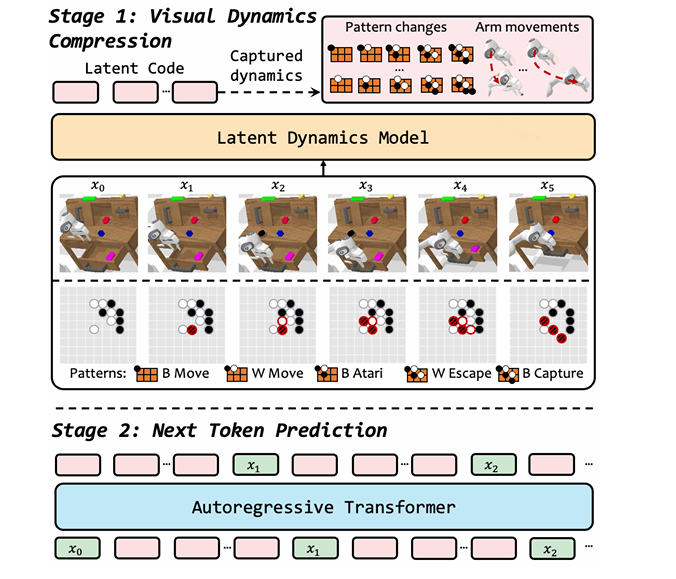
- 图3:所提出的 VideoWorld 模型架构概述。该架构的运作流程为:首先,潜在动力学模型(LDM)将每一帧至其后续帧的视觉变化压缩为一组潜在编码;随后,自回归变换器将潜在动力学模型的输出与下一个标记预测范式无缝融合。
2. 核心创新:潜在动力学模型 (Latent Dynamics Model, LDM)
为什么需要 LDM? 作者发现,虽然基础框架能学到知识,但效率很低。因为原始视频包含大量与决策无关的冗余信息(如背景、纹理)。为了让模型像人类一样高效地提取"关键动作和状态变化",作者设计了 LDM。
- 功能 :LDM 的作用是将视频中未来多步(Multi-step)的视觉变化压缩成一组紧凑的离散潜在编码(Latent Codes)。
- 具体机制 :
- 特征提取 :编码器因果地(causally)提取当前帧 xtx_txt 到未来 HHH 帧的特征图。为了保留时间细节,这一步不进行量化。
- 查询与注意力 (Queries & Attention):定义一组可学习的查询向量(Query embeddings),通过交叉注意力机制(Cross-Attention)捕捉未来几帧中的"变化信息",生成连续的潜在表示。
- 信息瓶颈与量化 :使用 FSQ 将上述连续表示离散化,变成潜在编码(Latent Codes zthz_t^hzth)。这一步构成了信息瓶颈,迫使模型只记住最重要的动态变化,而不是复制冗余像素。
- 解码重构 :解码器仅利用"当前帧特征"和"这组潜在编码",去预测(重构)未来的视频帧 x^t+1:t+H\hat{x}_{t+1:t+H}x^t+1:t+H。
在LDM stage中,需要未来frame,用于学习可查询向量,生成一组动力学embedding zthz_{t}^{h}zth,查询向量{qhq^{h}qh}是模型自带,全局固定的一个探针或提问者,q1q^{1}q1负责去视频特征里问:"从第 ttt 帧到第 t+1t+1t+1 帧,发生了什么变化?",q5q^{5}q5负责去问:"从第 ttt 帧到第 t+5t+5t+5 帧,长期的变化趋势是什么?",查询向量作为query,进入交叉注意力机制,查阅未来几帧的特征图。
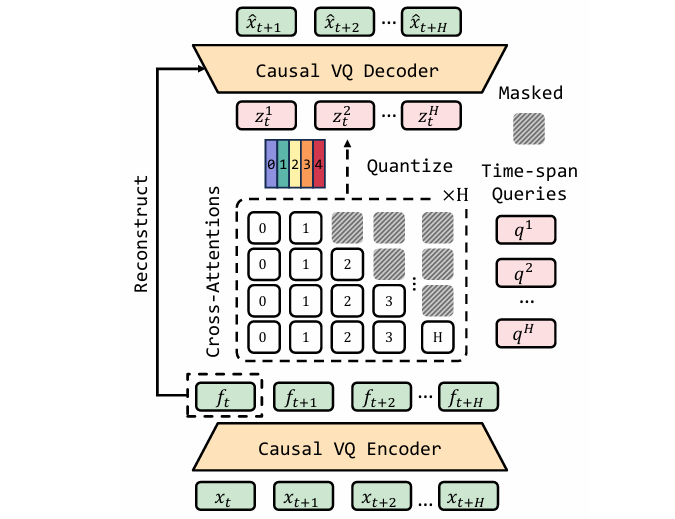
- 图4:所提出的潜在动力学模型(LDM)。该模型利用因果编解码器与一组可学习查询嵌入,对第 ttt 帧至第 t+Ht+Ht+H 帧的视觉变化完成压缩。
3. 与自回归 Transformer 的深度融合
在训练 VideoWorld 时,模型不仅仅预测视频的下一帧画面。
- 通过 LDM 提取出的潜在变化编码(Latent Codes)会与离散化的视频帧 Token 拼接在一起,作为 Transformer 的输入。
- Transformer 的词表(Vocabulary)是视频分词器词表和 LDM 词表的并集。
- 这种融合让 Transformer 在预测下一帧的同时,也能预测代表未来多步变化的潜在编码,从而极大地增强了模型的长程推理(Long-term reasoning)和前向规划(Forward planning)能力。
4. 推理与任务执行(映射到具体动作)
在实际测试时(比如下围棋或控制机械臂),模型不仅要"想象"未来的画面,还需要输出具体的动作指令:
- 生成过程 :在时间步 ttt,Transformer 自回归地生成未来的潜在编码 {z^th}\{\hat{z}t^h\}{z^th} 并预测出下一帧画面 x^t+1\hat{x}{t+1}x^t+1。
- 逆动力学模型 (Inverse Dynamics Model, IDM):作者使用极少量带有动作标签的数据,单独训练了一个基于 MLP 的 IDM。
- 动作输出 :IDM 接收"当前帧 xtx_txt"、"预测的下一帧 x^t+1\hat{x}_{t+1}x^t+1"以及"LDM生成的潜在变化编码 {z^th}\{\hat{z}t^h\}{z^th}",将它们转换为环境可以执行的具体动作(如围棋的落子坐标、机械臂的移动指令):π(⋅∣xt,x^t+1,{z^th})\pi(\cdot | x_t, \hat{x}{t+1}, \{\hat{z}_t^h\})π(⋅∣xt,x^t+1,{z^th})。
总结
VideoWorld 放弃了传统强化学习中的"状态-奖励-动作"范式,而是让模型"看视频 →\rightarrow→ 提取多步动态变化的潜在编码 (LDM) →\rightarrow→ 预测未来画面和潜在编码 (Transformer) →\rightarrow→ 通过帧间差异推导出执行动作 (IDM)"。通过这种方式,模型纯靠视觉就学会了围棋的规则与策略以及机器人的物理操作。
VideoWorld2:在真实视频中学习可迁移的知识
论文:VideoWorld 2: Learning Transferable Knowledge from Real-world Videos
链接:https://arxiv.org/pdf/2602.10102
相比于初代 VideoWorld 证明了"模型可以纯靠视觉学知识(如下围棋)",VideoWorld 2 的核心目标是解决一个更难的问题:如何在复杂多变、长序列的"真实世界视频"(如手工折纸、真实机械臂)中学习可泛化的知识?为了解决这个问题,VideoWorld 2 在方法上进行了升级,核心思想依然是"解耦(Decoupling)":把"皮囊(外观)"和"灵魂(动作)"分开。
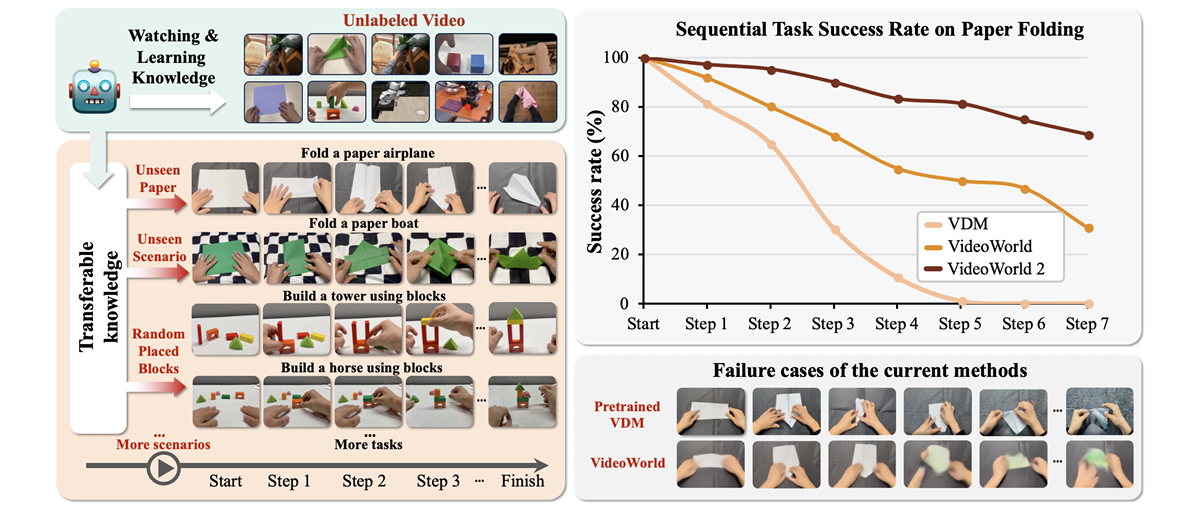
- 图 1(左):VideoWorld 2 探究如何从无标签的真实世界视频中学习可迁移知识,作者构建了手工制作基准数据集,用以评估模型习得的知识。图 1(右):不同模型框架在 Video-CraftBench 基准的长时序折纸任务中的成功率对比。作者将该任务拆解为 7 个关键步骤,并对模型的阶段性成功率展开评估。视频扩散模型(VDM,如 Wan2.2 14B)能生成高视觉保真度的内容,却无法学习到任务相关的动力学特征与长时序策略;VideoWorld 虽在策略学习上有所改进,但在真实场景中生成的内容视觉质量表现不佳。图右下角展示了这些基线方法的任务失败案例。VideoWorld 2 不仅能学习到鲁棒性更强的潜在动力学特征,还实现了视觉质量的显著提升,让模型得以从视频中学习到可泛化的长时序知识。
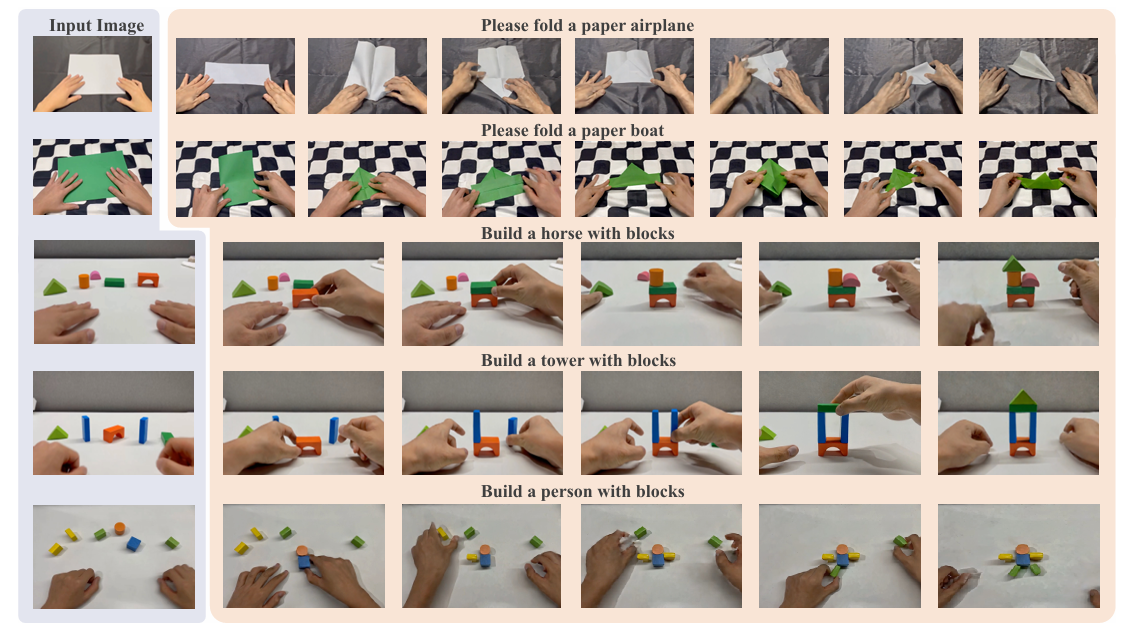
- 图2:定性结果。VideoWorld 2能够习得可迁移知识,并在全新的未见过的环境中生成长时序任务视频。本图展示了模型在长时序手工制作任务上的生成效果。
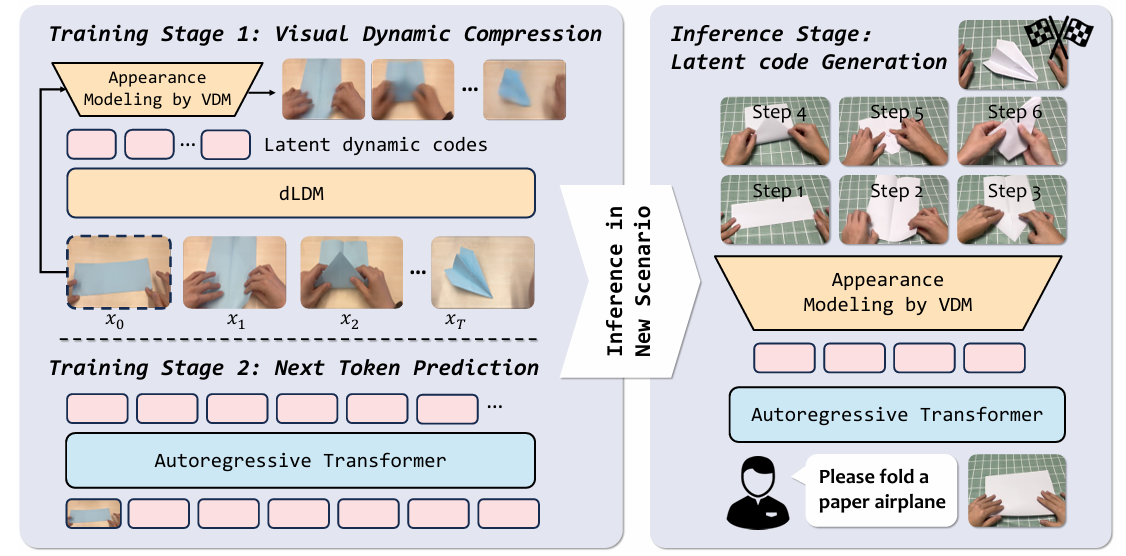
- 图3:VideoWorld 2 模型架构概述。(左)首先,动力学增强潜在动力学模型(dLDM)将未来的视觉变化压缩为紧凑且可泛化的潜在编码,随后由自回归Transformer对这些编码进行建模。(右)在推理阶段,Transformer根据输入图像为全新的未见过的环境预测潜在编码,这些编码后续会被解码为任务执行视频。
以下是 VideoWorld 2 相比初代在方法上的 4个核心变化:
1. 核心架构升级:从 LDM 到 dLDM(动态增强的潜在动力学模型)
- 初代 (VideoWorld 1) :LDM 提取出潜在编码(Latent Codes zzz)后,直接送入一个从头训练的 VQ-VAE 解码器去还原高清视频。这就逼迫潜在编码 zzz 必须既记住"动作怎么做",又得记住"桌子是什么颜色、光线是怎样的"。
- 二代 (VideoWorld 2) :引入了 dLDM (dynamics-enhanced LDM) 。它引入了一个强大的、预训练好的视频扩散模型(VDM,具体使用了 Cosmos DiT 2B)来专门负责生成高清外观。
- 潜在编码 zzz 现在通过因果交叉注意力(Causal Cross-attention)注入到 VDM 中。
- 因为有了 VDM 兜底画质,潜在编码 zzz 就被彻底"解放"了,它可以只专注于压缩任务核心的动作/动态变化,过滤掉所有无用的背景和材质信息。
2. 双解码机制与 ControlNet 引导
因为 VDM 之前并没有见过折纸或机械臂这样的超长任务,如果直接让它根据抽象的编码 zzz 去生成画面,非常容易崩溃或动作错乱。因此,VideoWorld 2 采用了粗细结合的双解码设计:
- 粗解码(保留初代遗产) :保留了初代的因果 VQ 解码器。它利用第一帧和潜在编码 zzz,快速重建出一个低画质但动作轨迹准确的粗糙视频(类似于动作草图)。
- 细解码(ControlNet 机制) :将这个低画质的"动作草图",通过一个类似 ControlNet 的分支输入给预训练的 VDM。这就相当于给 VDM 提供了一个明确的"动作轮廓引导",让 VDM 只需要安心把细节(手部皮肤、纸张纹理)补充高清即可。
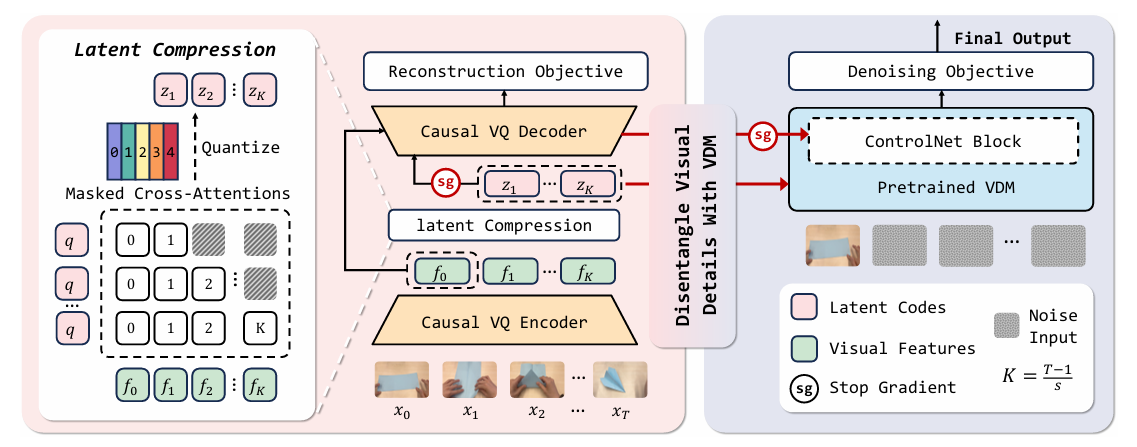
- 图4:所提出的动力学增强潜在动力学模型(dLDM)。(左)为 VideoWorld 中的潜在动力学模型,该模型将第一帧与后续帧之间的视觉变化压缩为一组潜在编码。(右)为 VideoWorld 2 中提出的 dLDM 模型,其采用预训练的视频扩散模型(VDM)作为外观先验,能生成更优质的潜在编码,同时助力实现高保真的视频输出。
3. 关键的训练 Trick:梯度截断 (Stop-Gradient) 与 两阶段训练
为了保证潜在编码 zzz 的绝对纯净(不沾染任何外观噪声),VideoWorld 2 在训练流上做了一个设计:
- Warm-up 阶段 :先像初代一样,只用原始的重建损失训练一小段时间,让 zzz 快速学会捕捉视觉变化,同时也让粗解码器学会生成"动作草图"。
- 解耦训练阶段(核心) :一旦开启 VDM 进行高清渲染,立刻切断(Stop-Gradient)"粗解码器"回传给潜在编码 zzz 的梯度 。此时,zzz 唯一的优化来源是 VDM。这彻底斩断了重建误差带来的杂音,让 zzz 变成了一个极其鲁棒、跨环境通用的"纯动作指令"。
4. 基础底座模型的全面 Scale-up (扩大规模)
除了架构设计上的进化,模型本身也变强了:
- 自回归 Transformer :从初代的 Llama 架构(150M~300M),直接升级到了英伟达最新的 Cosmos AR 4B (40亿参数),利用其强大的 Next-token 预测能力来推演长序列的动态潜编码。
- 视频生成底座 :用上了 Cosmos DiT 2B 作为 VDM 的外观先验。