学习笔记|B 站 UP 主 刘二大人 《PyTorch深度学习实践》视频知识点总结
结尾附上源代码
传送门 PyTorch深度学习实践------多分类问题
视频中截图
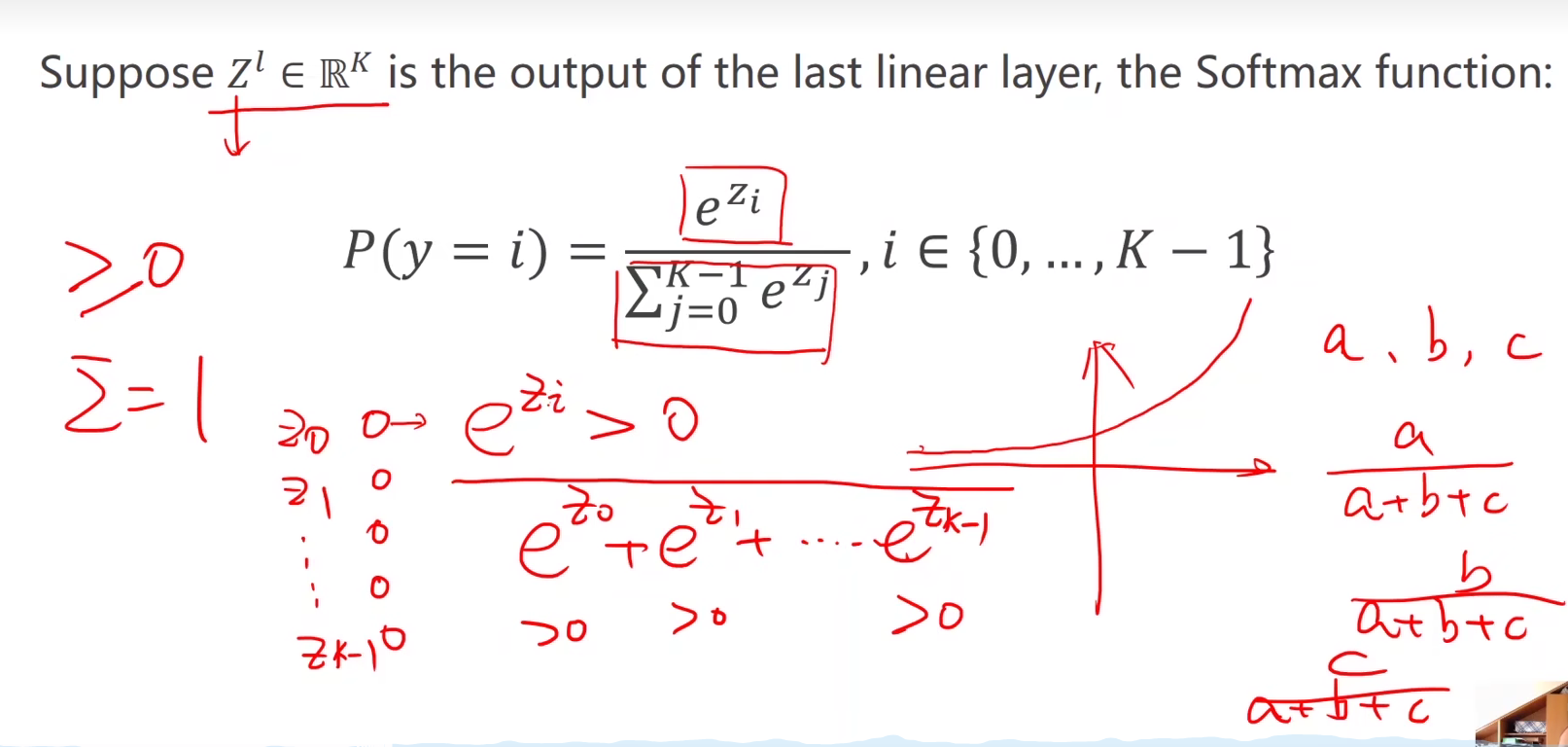
softmax的输入不需要再做非线性变换,也就是说softmax之前不再需要激活函数(relu)。softmax两个作用,如果在进行softmax前的input有负数,通过指数变换,得到正数。所有类的概率求和为1。
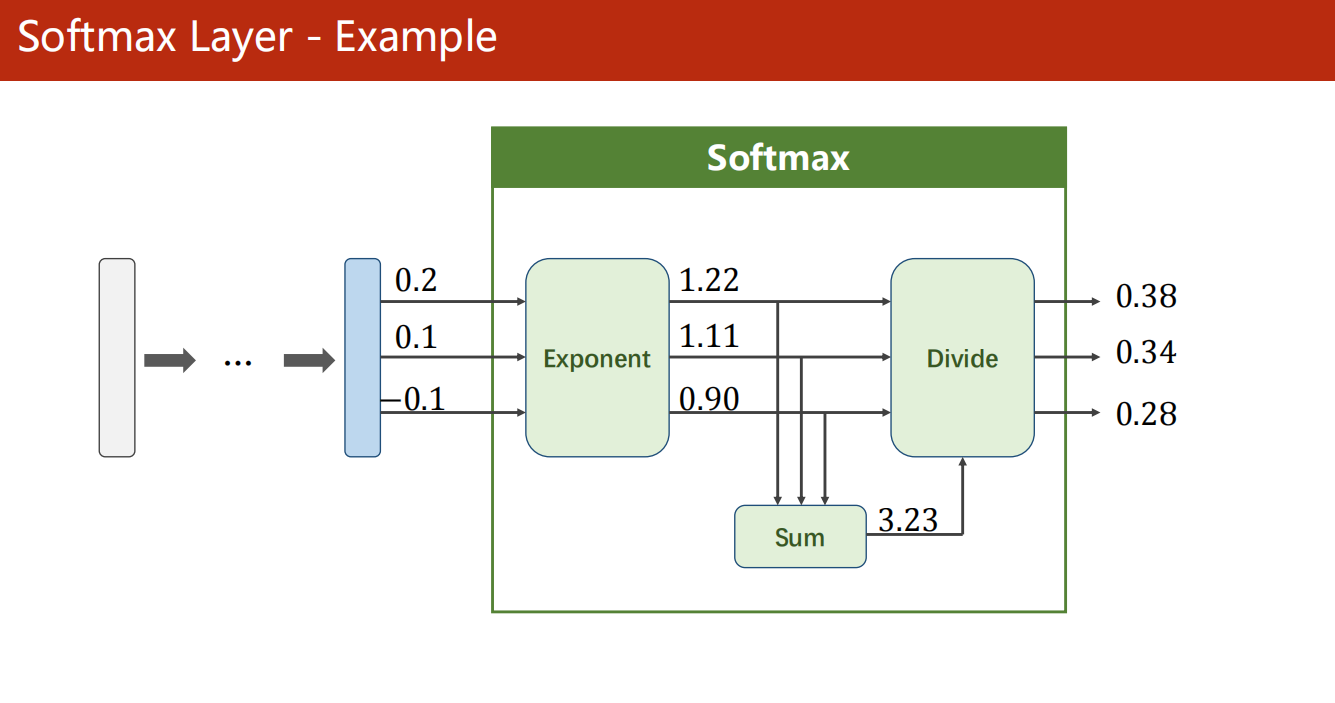
y的标签编码方式是one-hot。我对one-hot的理解是只有一位是1,其他位为0。(但是标签的one-hot编码是算法完成的,算法的输入仍为原始标签)
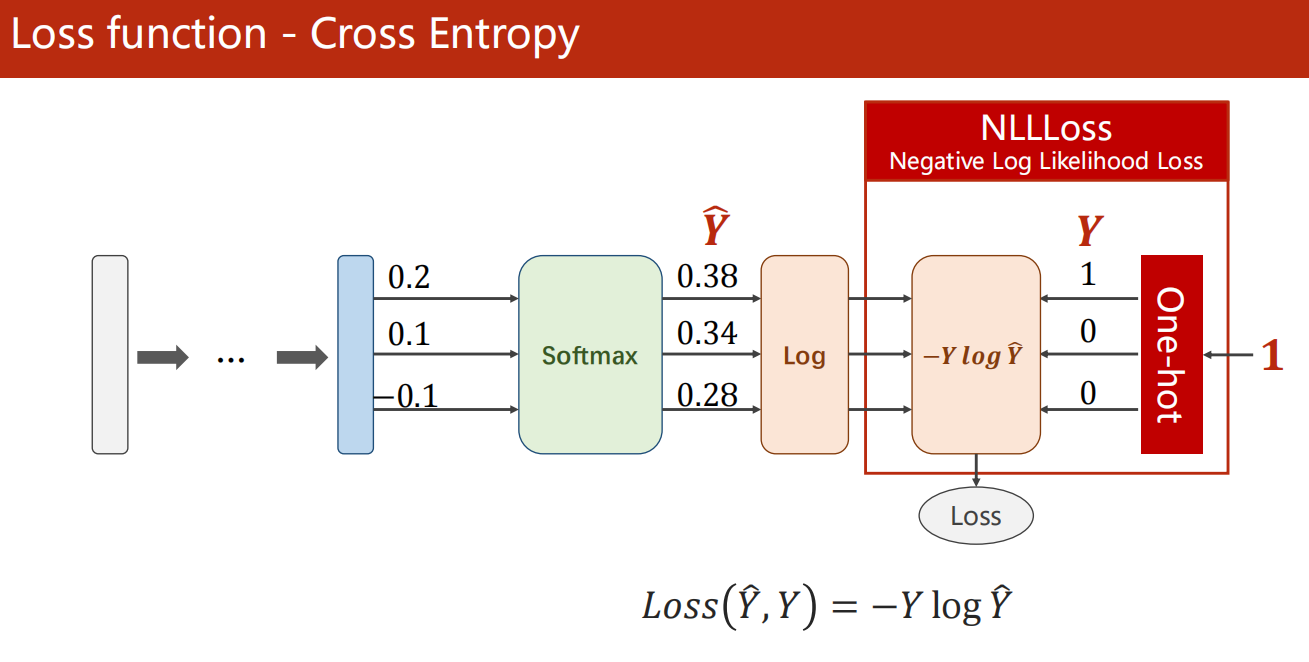
多分类问题,标签y的类型是LongTensor。比如说0-9分类问题,如果y = torch.LongTensor(3),对应的one-hot是0,0,0,1,0,0,0,0,0,0.(这里要注意,如果使用了one-hot,标签y的类型是LongTensor,糖尿病数据集中的target的类型是FloatTensor)
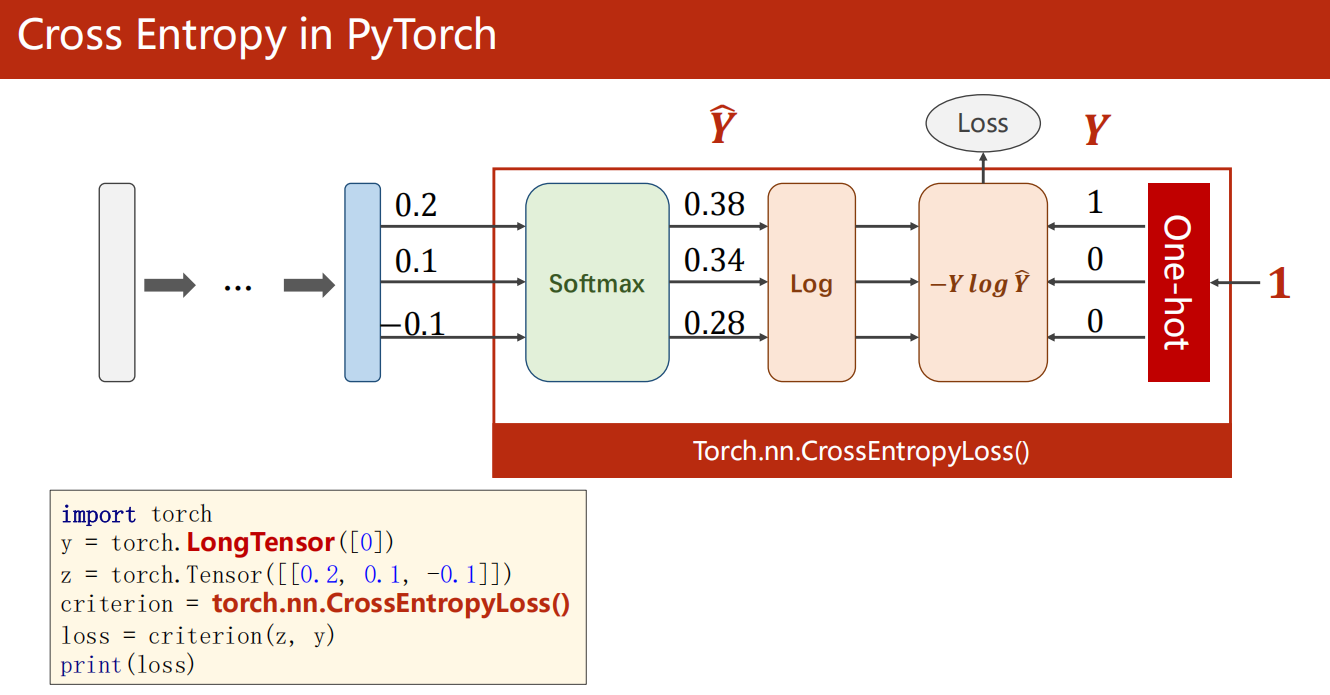
CrossEntropyLoss <==> LogSoftmax + NLLLoss。也就是说使用CrossEntropyLoss最后一层(线性层)是不需要做其他变化的;使用NLLLoss之前,需要对最后一层(线性层)先进行SoftMax处理,再进行log 操作。
PyTorch 深度学习实践------多分类问题
多分类问题是深度学习中最常见的任务之一(如手写数字识别、图像分类等),核心是将输入样本映射到多个离散类别中的某一类。本文以经典的 MNIST 手写数字分类为例,梳理 PyTorch 实现多分类任务的核心思路、损失函数选择与模型搭建方法。
1. 多分类模型的输出逻辑
多分类任务中,模型最后一层输出维度等于类别数量 (如 MNIST 有 10 个数字类别,输出维度为 10),每个维度的值代表样本属于对应类别的"得分",需通过 Softmax 函数 转换为概率分布:
p i = e z i ∑ j = 1 C e z j p_i = \frac{e^{z_i}}{\sum_{j=1}^C e^{z_j}} pi=∑j=1Cezjezi
其中:
- z i z_i zi 是模型对第 i i i 类的原始输出(logits);
- C C C 是类别总数;
- p i p_i pi 是样本属于第 i i i 类的概率,满足 ∑ i = 1 C p i = 1 \sum_{i=1}^C p_i = 1 ∑i=1Cpi=1。
2. 多分类损失函数
多分类任务的核心损失是 交叉熵损失(Cross Entropy Loss) ,PyTorch 中封装为 nn.CrossEntropyLoss(),需注意两个关键点:
- 该函数内置 Softmax 计算,输入只需传入模型原始输出(logits),无需手动添加 Softmax 层;
- 标签需为一维整数张量(如 MNIST 标签为 0-9 的整数),无需转为独热编码(One-Hot)。
3. 反向传播与参数更新
- 前向传播:输入数据 → 模型计算 logits →
nn.CrossEntropyLoss()计算损失(内置 Softmax + 交叉熵); - 反向传播:通过链式法则计算损失对模型参数的梯度,逻辑与二分类/回归任务一致,仅梯度维度适配多分类输出;
- 参数更新:利用梯度下降优化器调整参数,最小化交叉熵损失,使模型输出的概率分布贴合真实标签。
4. 源代码
python
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
# prepare dataset
batch_size = 64
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]) # 归一化,均值和方差
train_dataset = datasets.MNIST(root='../dataset/mnist/', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='../dataset/mnist/', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)
# design model using class
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.l1 = torch.nn.Linear(784, 512)
self.l2 = torch.nn.Linear(512, 256)
self.l3 = torch.nn.Linear(256, 128)
self.l4 = torch.nn.Linear(128, 64)
self.l5 = torch.nn.Linear(64, 10)
def forward(self, x):
x = x.view(-1, 784) # -1其实就是自动获取mini_batch
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
return self.l5(x) # 最后一层不做激活,不进行非线性变换
model = Net()
# construct loss and optimizer
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
# training cycle forward, backward, update
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
# 获得一个批次的数据和标签
inputs, target = data
optimizer.zero_grad()
# 获得模型预测结果(64, 10)
outputs = model(inputs)
# 交叉熵代价函数outputs(64,10),target(64)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch+1, batch_idx+1, running_loss/300))
running_loss = 0.0
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1) # dim = 1 列是第0个维度,行是第1个维度
total += labels.size(0)
correct += (predicted == labels).sum().item() # 张量之间的比较运算
print('accuracy on test set: %d %% ' % (100*correct/total))
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()