前言
很多同学刚接触 PyTorch 神经网络时,都会遇到同一个问题:代码能跑,但不知道在写什么。
nn.Linear、nn.ReLU、forward函数... 这些东西到底是什么关系?为什么要继承nn.Module?为什么CrossEntropyLoss总是报错?
别担心,这篇文章用大白话 + 万能口诀,带你彻底搞懂神经网络搭建的核心逻辑,看完就能独立写出一个完整的神经网络。
一、万能口诀:1 个继承,2 个重写
记住这句话,这辈子写神经网络都不会忘:
✅ 1 个继承 :继承
torch.nn.Module(PyTorch 官方给的神经网络模板)✅ 2 个重写 :重写
__init__(准备零件)和forward(设计流水线)
这就是 PyTorch 搭建神经网络的全部骨架,所有复杂网络都是这个套路。
python
import torch
import torch.nn as nn
import torch.nn.functional as F
# 1个继承:继承nn.Module
class SimpleNet(nn.Module):
# 重写1:__init__ ------ 准备所有零件
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(3, 3) # 第一层:3输入→3输出
self.fc2 = nn.Linear(3, 2) # 第二层:3输入→2输出
self.out = nn.Linear(2, 2) # 输出层:2输入→2输出
# 重写2:forward ------ 设计数据流动流水线
def forward(self, x):
x = torch.sigmoid(self.fc1(x)) # 第一层 + sigmoid激活
x = F.relu(self.fc2(x)) # 第二层 + relu激活
prob = F.softmax(self.out(x), dim=1) # 输出层 + softmax
return prob就这么简单!一个完整的神经网络就写好了。
二、网络结构详解:每一层到底在做什么
我们这个网络是一个3 层全连接网络,结构如下:
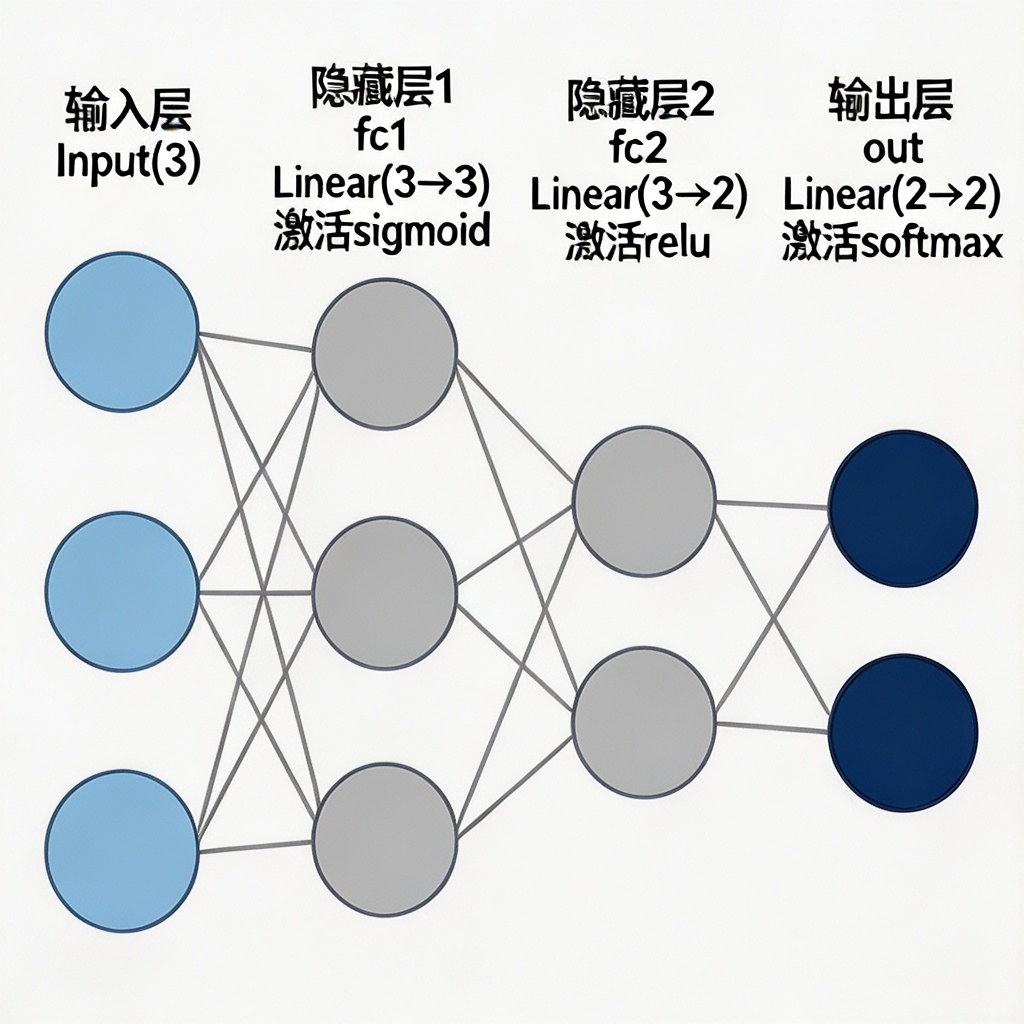
图 1:3 层全连接神经网络整体结构
各层参数说明:
| 层名称 | 输入维度 | 输出维度 | 激活函数 | 作用 |
|---|---|---|---|---|
| 输入层 | 3 | - | - | 接收原始数据 |
| fc1 | 3 | 3 | sigmoid | 第一次特征变换 |
| fc2 | 3 | 2 | relu | 第二次特征变换 + 降维 |
| out | 2 | 2 | softmax | 输出分类概率 |
三、核心概念大白话讲解
3.1 Linear 全连接层 = "打分员"
很多教程说 "全连接层就是线性变换",太抽象了!
大白话:Linear 就是一个打分员,给每个输入特征加权求和。
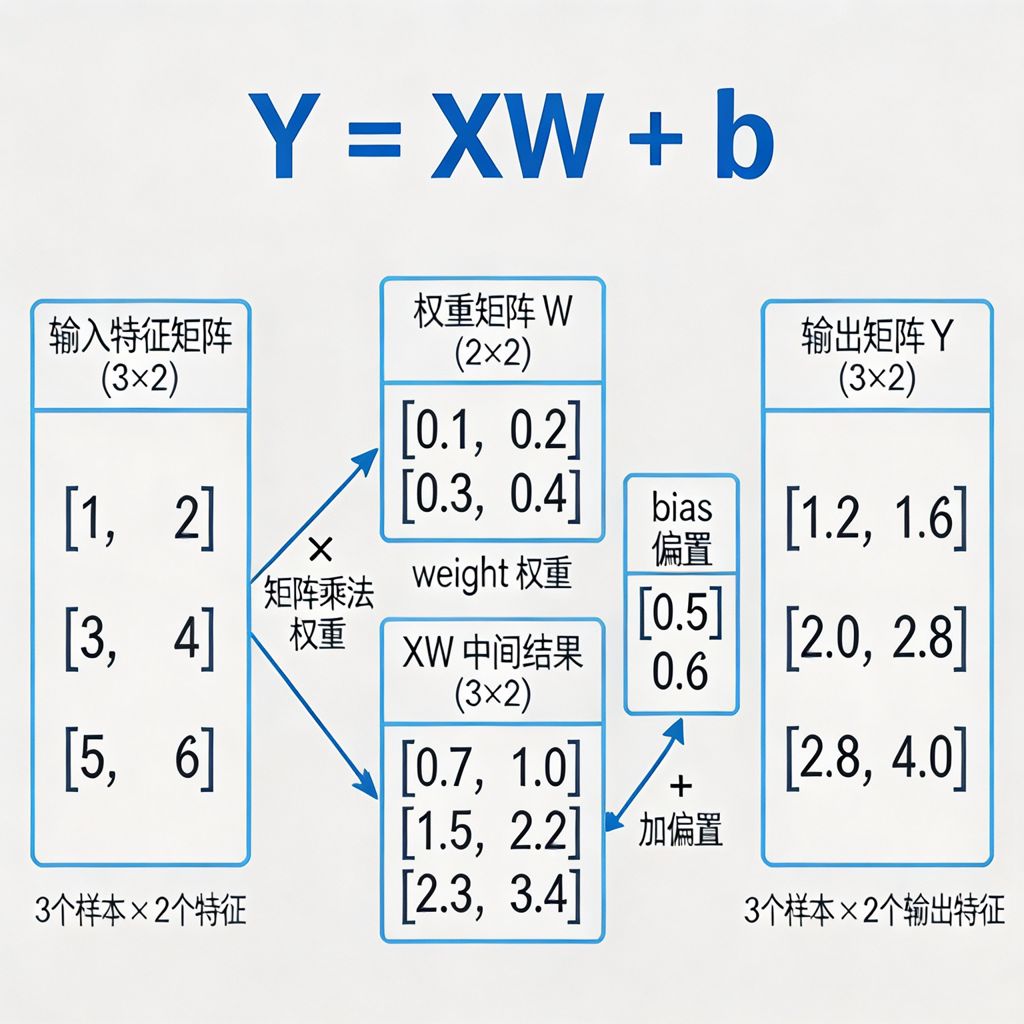
图 2:全连接层 Linear 工作原理
数学公式就是:
Y=XW+bY = XW + bY=XW+b
-
X:输入特征(你的数据)
-
W(weight 权重):每个特征的重要程度分数(神经网络要学习的参数)
-
b(bias 偏置):调整整体打分的偏移量
举个例子:判断一个水果是不是苹果
-
输入特征:红色程度,圆形程度,大小
-
权重:0.8, 0.7, 0.2 (红色和圆形很重要,大小不重要)
-
偏置:-0.5
-
最终分数 = 红色 ×0.8 + 圆形 ×0.7 + 大小 ×0.2 - 0.5
这就是 Linear 在做的事情!
3.2 激活函数 = "筛选器"
如果只有 Linear,不管多少层都只是线性变换,表达能力有限。
激活函数就是筛选器:留下有用信息,过滤噪音,引入非线性。
常用激活函数对比:
| 激活函数 | 特点 | 适用场景 |
|---|---|---|
| sigmoid | 输出 0~1,能表示概率 | 二分类输出层、门控机制 |
| relu | 负数变 0,正数保留 | 隐藏层首选,计算快、防梯度消失 |
| softmax | 多输出归一化,概率和为 1 | 多分类输出层 |
3.3 权重初始化 = "合理的起跑线"
神经网络刚开始训练时,权重 W 是随机的。好的初始化能让训练更快更稳定:
-
Xavier 初始化:适合 sigmoid/tanh 激活函数
-
Kaiming 初始化:适合 relu 激活函数(PyTorch 默认)
python
# 手动初始化示例
nn.init.xavier_uniform_(self.fc1.weight)
nn.init.kaiming_normal_(self.fc2.weight)四、forward 函数:数据的完整旅行路线
forward函数就是神经网络的数据流水线,数据从输入 x 开始,经过每一层变换,最终输出结果。
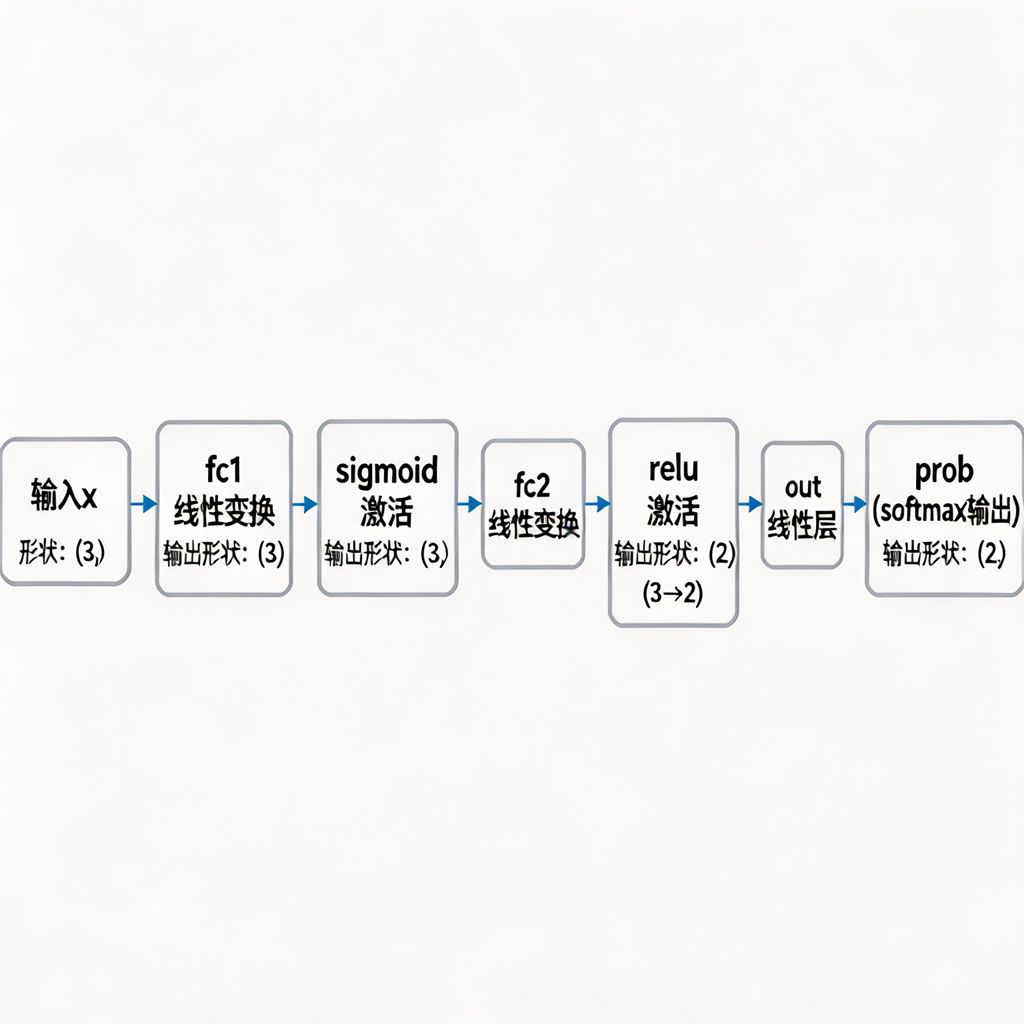
图 3:前向传播完整数据流
让我们跟踪一个数据的完整旅程:
python
def forward(self, x):
# 第1站:x形状(3,) → fc1线性变换 → sigmoid激活 → 输出还是(3,)
x = torch.sigmoid(self.fc1(x))
# 第2站:形状(3,) → fc2线性变换 → relu激活 → 输出变成(2,)(降维了!)
x = F.relu(self.fc2(x))
# 第3站:形状(2,) → out线性层 → softmax归一化 → 输出(2,)概率
prob = F.softmax(self.out(x), dim=1)
return prob关键点:每一层不仅改变数值,还可能改变张量形状!
五、损失计算:新手最容易踩的坑
5.1 损失函数 = "衡量差距的尺子"
损失函数就是衡量:模型预测答案 和 标准答案 之间差了多少。
分类任务最常用:CrossEntropyLoss(交叉熵损失)
5.2 ⚠️ 90% 新手都会犯的错误
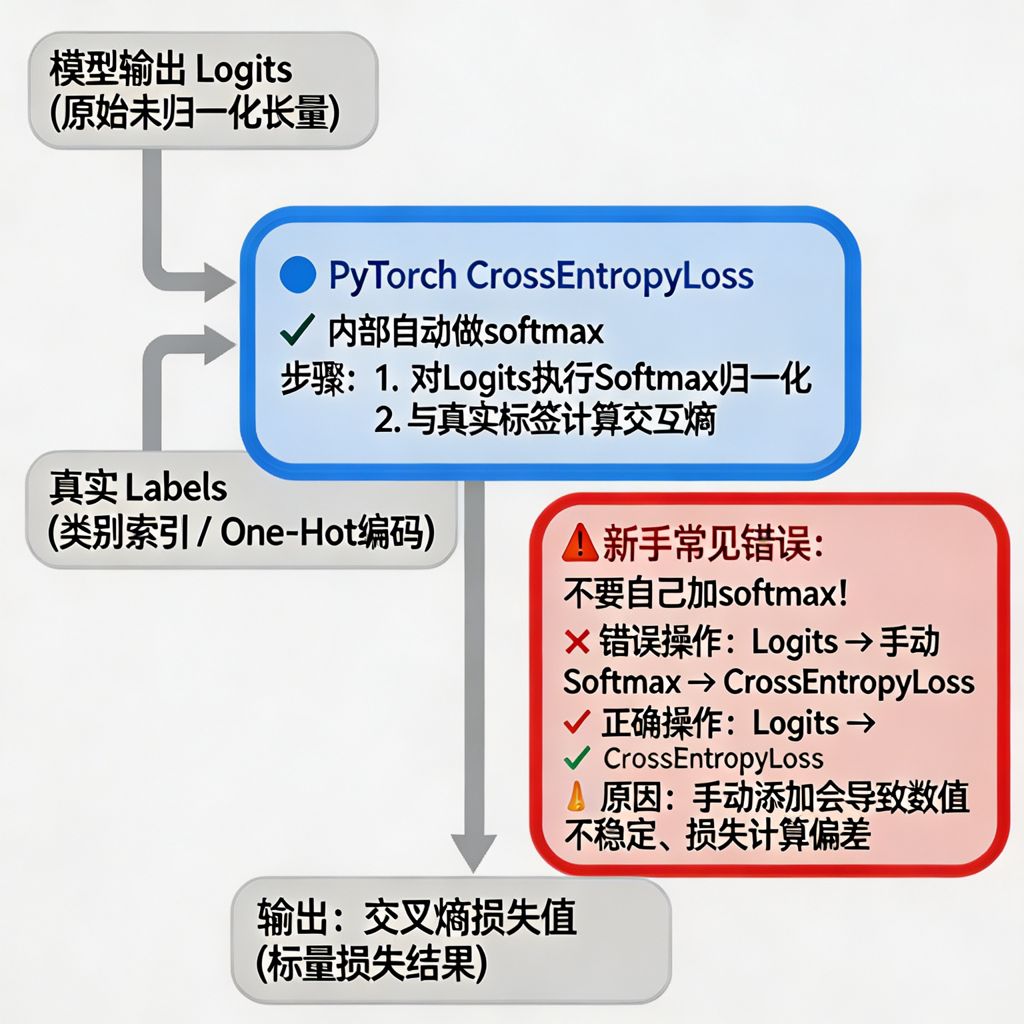
图 4:交叉熵损失计算流程与避坑指南
❌ 错误写法(90% 新手都会写错):
python
# 错误:自己加了softmax
output = model(x) # output已经是softmax后的prob了
loss = criterion(output, label) # 错!输入应该是logits✅ 正确写法:
python
# 正确:直接输出原始logits,不要softmax!
class Net(nn.Module):
def forward(self, x):
# ...前面的层...
logits = self.out(x) # 只输出原始分数,不做softmax
return logits
# 损失计算
criterion = nn.CrossEntropyLoss()
loss = criterion(logits, label) # PyTorch内部自动做softmax为什么?
PyTorch 的CrossEntropyLoss内部已经包含了LogSoftmax和NLLLoss,如果你自己再做一次 softmax,相当于:
-
概率被压缩两次 → 数值不稳定
-
梯度变小 → 训练变慢甚至不收敛
六、常见损失函数大全
上一章我们讲了多分类任务最常用的 CrossEntropyLoss,但实际工作中还有很多不同场景的损失函数。这一章我们系统讲解二分类和回归任务的常用损失。
6.1 BCELoss:二分类交叉熵损失(2种用法)
BCELoss = Binary Cross Entropy Loss,专门用于二分类任务。根据任务场景不同,有两种经典用法。
6.1.1 用法一:输出2个神经元 + sigmoid + BCELoss(多标签二分类)
适用场景:一个样本可以同时属于多个类别(多标签分类)
举个例子:一张图片可以同时包含"猫"和"狗"两个标签,而不是二选一
python
import torch
import torch.nn as nn
# ===================== 准备数据 =====================
# 标签:2个样本,每个样本有2个标签位(1=有这个标签,0=没有)
# 样本1:有标签A,没有标签B → [1, 0]
# 样本2:没有标签A,有标签B → [0, 1]
labels = torch.tensor([[1, 0], [0, 1]], dtype=torch.float)
# 模型输出的原始分数(logits):2个样本,每个输出2个神经元的分数
logits = torch.tensor([[5, 2], [1.5, 7]])
print("模型输出原始分数:\n", logits)
# 输出:
# tensor([[5.0000, 2.0000],
# [1.5000, 7.0000]])
# ===================== 关键步骤:sigmoid转概率 =====================
# 每个神经元独立计算概率,范围 [0, 1]
probs = torch.sigmoid(logits)
print("\n经过sigmoid后的概率:\n", probs)
# 输出:
# tensor([[0.9933, 0.8808],
# [0.8176, 0.9991]])
# ===================== 计算BCELoss =====================
loss_fn = nn.BCELoss()
loss = loss_fn(probs, labels)
print("\nBCELoss损失值:", loss.item())
# 输出:BCELoss损失值:0.19534829258918762💡 重点讲解:为什么用 sigmoid 而不是 softmax?
| 对比项 | softmax | sigmoid |
|---|---|---|
| 概率关系 | 所有输出概率和为 1,互斥 | 每个输出独立,范围 0~1,互不影响 |
| 适用场景 | 多分类(只能选一个) | 多标签(可以选多个)、二分类 |
| 物理含义 | "这个样本是A的概率80%,是B的概率20%" | "这个样本有A特征的概率90%,有B特征的概率85%" |
多标签 vs 多分类的本质区别:
- 多分类:类别之间互斥 → 用 softmax + CrossEntropyLoss
- 多标签:类别之间独立 → 用 sigmoid + BCELoss
6.1.2 用法二:输出1个神经元 + sigmoid + BCELoss(单标签二分类)
适用场景:标准二分类任务(是/否,正/反)
举个例子:判断肿瘤是良性(0)还是恶性(1)
python
import torch
import torch.nn as nn
# ===================== 准备数据 =====================
# 标签:2个样本,都是正例(恶性肿瘤)
labels = torch.tensor([1, 1], dtype=torch.float)
# 模型只输出1个神经元的原始分数
logits = torch.tensor([1.5, 2])
print("模型输出原始分数:", logits)
# 输出:tensor([1.5000, 2.0000])
# ===================== sigmoid转概率 =====================
probs = torch.sigmoid(logits)
print("经过sigmoid后的概率:", probs)
# 输出:tensor([0.8176, 0.8808])
"""
📊 概率解释:
- 第一个样本是正例(恶性)的概率 = 0.8176
- 第一个样本是反例(良性)的概率 = 1 - 0.8176 = 0.1824
- 第二个样本是正例的概率 = 0.8808
- 第二个样本是反例的概率 = 1 - 0.8808 = 0.1192
"""
# ===================== 计算BCELoss =====================
loss_fn = nn.BCELoss()
loss = loss_fn(probs, labels)
print("BCELoss损失值:", loss.item())
# 输出:BCELoss损失值:0.15071983635425568💡 二分类任务的输出设计哲学:
为什么二分类可以只输出1个神经元?
因为二分类只有两种可能,它们的概率是互补的:
- P(正例) = p
- P(反例) = 1 - p
输出1个神经元 vs 输出2个神经元的对比:
| 方案 | 输出神经元数 | 激活函数 | 损失函数 |
|---|---|---|---|
| 方案1(推荐) | 1个 | sigmoid | BCELoss |
| 方案2 | 2个 | softmax | CrossEntropyLoss |
推荐用方案1:参数更少,计算更快,物理含义更清晰!
6.2 回归损失函数对比:L1Loss、MSELoss、SmoothL1Loss
回归任务(预测连续值,比如预测房价、预测温度)和分类任务不同,使用的损失函数也完全不一样。
PyTorch 提供了三种最常用的回归损失,我们用同一个例子对比它们的区别。
6.2.1 三种损失函数代码对比
python
import torch
import torch.nn as nn
# ===================== 准备数据 =====================
# 真实值:比如5天的真实温度 [1°C, 2°C, 3°C, 4°C, 5°C]
y_true = torch.tensor([1.0, 2.0, 3.0, 4.0, 5.0])
print("真实值:", y_true)
# 预测值:模型预测的温度
y_pred = torch.tensor([0.6, 1.7, 3.0, 4.2, 5.3])
print("预测值:", y_pred)
# 先看看每个样本的误差
print("\n每个样本的绝对误差:", torch.abs(y_pred - y_true))
# 输出:tensor([0.4000, 0.3000, 0.0000, 0.2000, 0.3000])
# ===================== 1. L1Loss = MAE 平均绝对误差 =====================
loss_fn = nn.L1Loss()
loss_l1 = loss_fn(y_pred, y_true)
print("\n✅ L1Loss(MAE平均绝对误差):", loss_l1.item())
# 计算过程:(0.4 + 0.3 + 0.0 + 0.2 + 0.3) / 5 = 1.2 / 5 = 0.24
# 输出:0.24000000953674316
# ===================== 2. MSELoss = MSE 均方误差 =====================
loss_fn = nn.MSELoss()
loss_mse = loss_fn(y_pred, y_true)
print("✅ MSELoss(MSE均方误差):", loss_mse.item())
# 计算过程:(0.16 + 0.09 + 0.0 + 0.04 + 0.09) / 5 = 0.38 / 5 = 0.076
# 输出:0.07600000500679016
# ===================== 3. SmoothL1Loss = Huber损失 =====================
loss_fn = nn.SmoothL1Loss()
loss_smooth = loss_fn(y_pred, y_true)
print("✅ SmoothL1Loss(Huber损失):", loss_smooth.item())
# 输出:0.074000000953674326.2.2 三种损失函数深度解析
1. L1Loss = MAE 平均绝对误差
公式 :L1=1n∑i=1n∣ytrue−ypred∣L1 = \frac{1}{n}\sum_{i=1}^n |y_{true} - y_{pred}|L1=n1∑i=1n∣ytrue−ypred∣
特点:
- ✅ 对异常值鲁棒:误差只取绝对值,不会平方放大
- ❌ 梯度不稳定:在0点不可导,小误差时梯度也是1,收敛后期容易震荡
适用场景:数据中有很多异常值(outliers)时使用
2. MSELoss = MSE 均方误差
公式 :MSE=1n∑i=1n(ytrue−ypred)2MSE = \frac{1}{n}\sum_{i=1}^n (y_{true} - y_{pred})^2MSE=n1∑i=1n(ytrue−ypred)2
特点:
- ✅ 梯度稳定:处处可导,梯度随误差线性变化(dL/dx = 2x)
- ✅ 惩罚大误差:误差 > 1 时会被平方放大,模型更关注大误差
- ❌ 对异常值敏感:一个极端异常值会主导整个损失
适用场景:数据比较干净,异常值很少的回归任务
3. SmoothL1Loss = Huber损失
公式 :
SmoothL1(x)={0.5x2if ∣x∣<1∣x∣−0.5if ∣x∣≥1 SmoothL1(x) = \begin{cases} 0.5x^2 & \text{if } |x| < 1 \\ |x| - 0.5 & \text{if } |x| \geq 1 \end{cases} SmoothL1(x)={0.5x2∣x∣−0.5if ∣x∣<1if ∣x∣≥1
特点:完美结合了 L1 和 MSE 的优点!
- 误差小时(|x| < 1):用 MSE,梯度稳定,收敛精确
- 误差大时(|x| ≥ 1):用 L1,对异常值不敏感
为什么叫 "Smooth"?
- 普通 L1 在 x=0 处有尖点,不可导
- SmoothL1 在 x=0 处平滑过渡,处处可导
经典应用:Faster R-CNN、YOLO 等目标检测算法的边界框回归全部用这个!
6.2.3 三种损失函数曲线对比
损失值
^
| ● MSE
| /
| / ● L1
| / /
| / ● SmoothL1
| / /
| / /
| / /
|/ /
+------------------> 误差 |x|
0 1看图说话:
| 误差范围 | 损失大小关系 | 说明 |
|---|---|---|
| 小误差(| x | < 1) | MSE < SmoothL1 < L1 | MSE惩罚最小,收敛最快 |
| 误差 = 1 | 三者相等 | 三条曲线交汇点 |
| 大误差(|x| > 1) | MSE > L1 > SmoothL1 | MSE被平方放大,SmoothL1最温和 |
📌 选择口诀:
- 数据脏、异常值多 → 选 L1Loss
- 数据干净、要精确收敛 → 选 MSELoss
- 目标检测、追求稳健 → 必选 SmoothL1Loss
七、完整可运行代码
python
import torch
import torch.nn as nn
import torch.nn.functional as F
# 1. 定义网络
class SimpleNet(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(3, 3)
self.fc2 = nn.Linear(3, 2)
self.out = nn.Linear(2, 2)
# 可选:权重初始化
nn.init.kaiming_normal_(self.fc1.weight)
nn.init.kaiming_normal_(self.fc2.weight)
def forward(self, x):
x = torch.sigmoid(self.fc1(x))
x = F.relu(self.fc2(x))
logits = self.out(x) # 注意:输出logits,不做softmax!
return logits
# 2. 创建模型和数据
model = SimpleNet()
x = torch.randn(2, 3) # 2个样本,每个3个特征
labels = torch.tensor([0, 1]) # 真实标签
# 3. 前向传播
logits = model(x)
print("模型输出logits:", logits)
# 4. 计算损失(正确方式)
criterion = nn.CrossEntropyLoss()
loss = criterion(logits, labels)
print("损失值:", loss.item())
# 5. 如果需要看概率,手动单独做softmax
prob = F.softmax(logits, dim=1)
print("预测概率:", prob)八、优化器与训练技巧
8.1 指数加权平均与动量(Momentum)
所有深度学习优化器(SGD、Adam、RMSprop)的核心思想,都来自一个简单但强大的数学技巧:指数加权平均(Exponentially Weighted Average)。
理解了它,你就理解了动量优化的本质。
8.1.1 什么是指数加权平均?
生活中的例子:看天气预报时,"过去10天平均气温"比"单日气温"更能反映真实的季节趋势。
指数加权平均就是:用过去的平均值来平滑当前的波动。
核心公式 :
vt=β⋅vt−1+(1−β)⋅θtv_t = \beta \cdot v_{t-1} + (1-\beta) \cdot \theta_tvt=β⋅vt−1+(1−β)⋅θt
其中:
- vtv_tvt = 第 t 天的加权平均值
- vt−1v_{t-1}vt−1 = 前一天的加权平均值
- θt\theta_tθt = 第 t 天的真实观测值
- β\betaβ = 加权系数(通常取 0.9)
8.1.2 完整代码实现 + 可视化对比
python
# 导包
import torch
import matplotlib.pyplot as plt
import matplotlib
matplotlib.use("TkAgg")
matplotlib.rcParams["font.sans-serif"] = ["SimHei"]
matplotlib.rcParams["axes.unicode_minus"] = False
# todo 模拟一个月的天和温度数据
x_day = torch.arange(1, 31)
print(x_day)
torch.manual_seed(66)
y_temp = torch.rand(30) * 20 + 5
print(y_temp)
# todo 指数加权平均后线性图
print("====================指数加权平均直线图=======================")
y_iwm = []
beida = 0.9
# 遍历原始温度,计算指数加权平均值
for i, t in enumerate(y_temp):
if i == 0:
y_iwm.append(t)
else:
y_iwm.append(y_iwm[-1] * beida + (1-beida)*t)
# todo 模拟原始温度及指数加权平均的线性图
plt.subplot(121)
plt.scatter(x_day, y_temp)
plt.plot(x_day, y_temp)
plt.subplot(122)
plt.scatter(x_day, y_temp)
plt.plot(x_day, y_iwm)
plt.show()运行效果说明:
左图(原始数据):
● 点上下跳得很厉害
● 看不出整体温度趋势
右图(加权后):
● 蓝色曲线相对平滑一些
● 清晰反映了温度的整体变化趋势
● 过滤掉了随机波动的噪音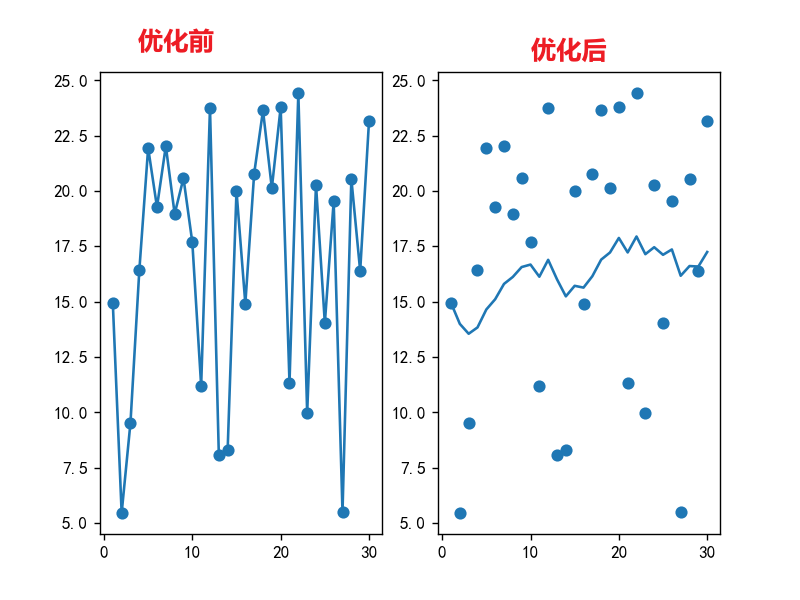
8.1.3 β 参数的物理含义
β = 0.9 到底是什么意思?
数学上可以证明:
有效平均天数≈11−β\text{有效平均天数} \approx \frac{1}{1-\beta}有效平均天数≈1−β1
所以:
- β = 0.9 → 1/(1-0.9) = 约10天的平均
- β = 0.98 → 1/(1-0.98) = 约50天的平均
- β = 0.5 → 1/(1-0.5) = 约2天的平均
| β 值 | 平滑程度 | 记忆长度 | 适用场景 |
|---|---|---|---|
| 0.5 | 很不平滑 | 只记得最近2天 | 反应快,紧跟变化 |
| 0.9 | 适中 | 记得最近10天 | 平衡,最常用 |
| 0.98 | 非常平滑 | 记得最近50天 | 反应慢,趋势稳定 |
8.1.4 为什么深度学习优化器都用这个思想?
问题:普通 SGD 梯度下降的问题
普通SGD的更新:
w = w - lr * g_t
问题:
● 梯度方向忽左忽右,震荡严重
● 收敛慢,容易卡在局部最优
● 像醉汉走路,东倒西歪动量(Momentum)优化:加入指数加权平均!
带动量的SGD更新:
v_t = β * v_{t-1} + (1-β) * g_t ← 梯度的指数加权平均
w = w - lr * v_t ← 用平滑后的梯度更新
好处:
✅ 过去的梯度方向会"积累"下来
✅ 震荡的方向会相互抵消
✅ 正确的方向会加速前进
✅ 像雪球一样越滚越快类比理解:
- 普通 SGD = 每一步都重新决定方向,容易走弯路
- 带动量 SGD = 有惯性,保持之前的运动方向,过滤噪音
这就是为什么:
- SGD + Momentum 比普通 SGD 快得多
- Adam、RMSprop 等所有先进优化器,本质都是对梯度 和梯度平方做指数加权平均!
8.1.5 可视化解读动量的威力
普通SGD的优化路径:
↗ ↘ ↗ ↘ ↗ ↘ 震荡前进,很慢
\ / \ /
\/ \/
带动量的优化路径:
→ → → → → → 平滑直线,很快
方向稳定,惯性前进📌 核心结论:
- 指数加权平均 = 用过去的平均值平滑现在的波动
- β=0.9 ≈ 过去10天的平均,是最常用的设置
- 动量优化 = 对梯度做指数加权平均
- 所有现代优化器的核心都是这个简单的数学技巧
九、全文总结
核心知识点回顾
-
万能口诀 :1 个继承(nn.Module)+ 2 个重写(
__init__和forward) -
Linear 层:就是加权求和的打分员,Y = XW + b
-
激活函数:引入非线性的筛选器,隐藏层首选 relu
-
forward 函数:数据流动的流水线,注意形状变化
-
避坑提醒 :CrossEntropyLoss 输入是 logits,不要自己加 softmax
-
BCELoss二分类:
- 多标签:输出N个神经元 + sigmoid
- 单标签:输出1个神经元 + sigmoid
-
回归损失三兄弟:
- L1Loss:对异常值鲁棒
- MSELoss:梯度稳定,惩罚大误差
- SmoothL1Loss:结合两者优点,目标检测标配
-
指数加权平均:所有优化器动量的核心思想,β=0.9≈过去10天平均
下一步建议
-
把这篇文章的代码默写 3 遍,直到不看参考也能写出来
-
尝试修改网络结构:加层、改神经元数量、换激活函数
-
尝试不同的损失函数,观察训练效果的差异
记住:神经网络没有那么神秘,本质就是可学习参数的流水线变换。掌握了这个核心思想,再复杂的网络也只是这个套路的延伸。