文章目录
- 0.引言
- [1.阶段一:提示工程师 (Prompt Coder)](#1.阶段一:提示工程师 (Prompt Coder))
-
- [1.1 特征](#1.1 特征)
- [1.2 为什么很多人停在这里?](#1.2 为什么很多人停在这里?)
- [1.3 怎么跳到阶段二?](#1.3 怎么跳到阶段二?)
- [2.阶段二:规划师(Plan Coder)](#2.阶段二:规划师(Plan Coder))
-
- [2.1 特征](#2.1 特征)
- [2.2 Plan Mode 的陷阱](#2.2 Plan Mode 的陷阱)
- [3.阶段三:上下文工程师(Context Engineer)](#3.阶段三:上下文工程师(Context Engineer))
-
- [3.1 特征](#3.1 特征)
- [3.2 Token 是 AI 的硬通货](#3.2 Token 是 AI 的硬通货)
- [3.3 Context Rot:你一直在和它过招](#3.3 Context Rot:你一直在和它过招)
- [3.4 如何应对?](#3.4 如何应对?)
- [3.5 做减法比做加法更难](#3.5 做减法比做加法更难)
- [3.6 阶段四是啥?](#3.6 阶段四是啥?)
- [4.阶段四:系统编排者(System Orchestrator)](#4.阶段四:系统编排者(System Orchestrator))
-
- [4.1 特征](#4.1 特征)
- [4.2 能力 1:触碰现实(MCP)](#4.2 能力 1:触碰现实(MCP))
- [4.2 能力 2:消灭重复(Skills / 自定义命令)](#4.2 能力 2:消灭重复(Skills / 自定义命令))
- [4.3 能力 3:分身协作(Multi-Agent)](#4.3 能力 3:分身协作(Multi-Agent))
- 推荐阅读
0.引言
近期 AI 编程发展地如火如荼,各种概念层出不穷:
- Vibe Coding
- Prompt Engineering
- Context Engineering
- MCP
- Agentic Coding...
每个都号称是下一个编程范式,但你既不清楚它们之间的关系,也不知道自己该如何下手,目前处于哪个阶?
面对层出不穷的 AI 编程概念,你是否感到迷茫?
本文将为你梳理一条清晰的进阶路径,揭示这些概念如何层层递进,解决上一阶段的遗留问题。
本文尝试将 AI Coding 过程总结为四个阶段:
- 阶段一:提示工程师 (Prompt Coder)
- 阶段二:规划师(Plan Coder)
- 阶段三:上下文工程师(Context Engineer)
- 阶段四:系统编排者(System Orchestrator)
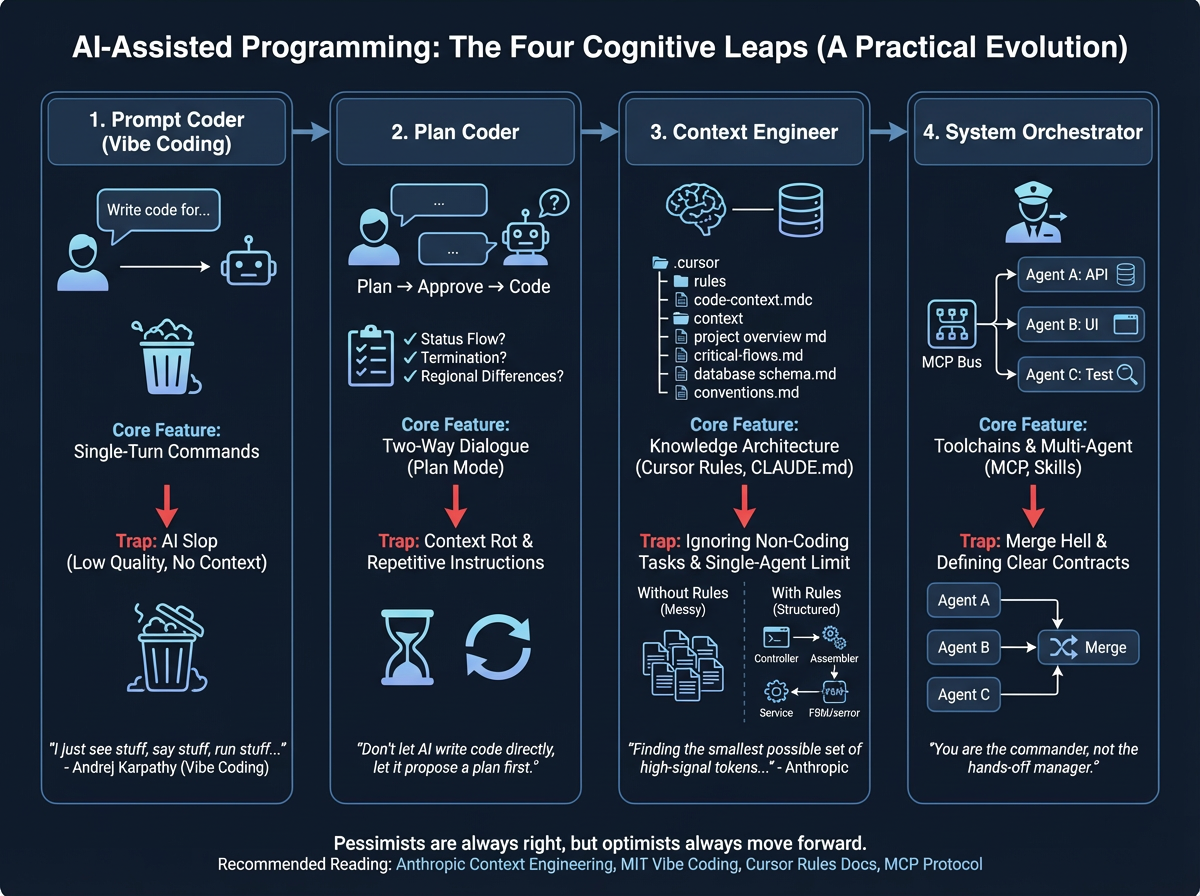
每个阶段都有各自的问题,AI Coding 也确实不是万能的。但我们恰恰是在面对这些问题、解决这些问题的过程中成长的。悲观者可能正确,但乐观者永远前行。
1.阶段一:提示工程师 (Prompt Coder)
1.1 特征
核心特征:单向指令 | 陷阱:AI 垃圾。
这是所有人的起点,也是大多数人停留的地方。
2025 年 2 月,Andrej Karpathy(OpenAI 联合创始人、前特斯拉 AI 总监)在 X 上创造了 Vibe Coding(氛围编程) 这个词:
"I just see stuff, say stuff, run stuff, and copy paste stuff, and it mostly works."
--- Andrej Karpathy, Feb 2025
MIT Technology Review 后来为此专门写了篇文章------Vibe Coding 不是泛指所有 AI 辅助编程,而是特指那种放弃控制、凭直觉推进的编码方式。Karpathy 本人也承认,这种方式适合原型和个人项目,但不适合生产系统。
Vibe Coding 虽然方便,但是产生的代码表面可用,内部混乱。
这是Vibe Coding最普遍的问题。AI生成的代码往往能跑通,但不一定能跑好。
-
缺乏设计模式:代码通常是过程式的堆砌,缺乏面向对象设计、模块化或清晰的抽象。多个功能可能被塞进一个巨大的函数里,导致代码难以阅读和维护。
-
命名混乱:变量、函数、类的命名可能不一致、无意义或与功能不符(如 data1、temp2、process_data)。
-
冗余代码:经常出现重复的逻辑、未使用的导入、多余的变量赋值。
-
糟糕的错误处理:通常只处理了"快乐路径"(Happy Path),对异常情况、边界条件、网络中断、用户误操作等缺乏健壮的考虑。
后果:这种代码被称为"一次性代码"或"拼凑品",也就是 AI 垃圾。它能跑,但不属于你的项目。你得花大量时间修剪它,最后发现还不如自己写来得快。
否
是
开始
定义: 拆解任务
生成: AI写代码
验证: 代码正确?
反馈: 报错/修改意见
优化: 重构/加注释
交付代码
1.2 为什么很多人停在这里?
- 即时满足感太强。
30 秒出代码,编译通过,测试绿灯------这个正反馈回路太短了。你很容易产生"AI 已经帮了大忙"的错觉,而忽略后面花两小时修剪代码的隐性成本。就像点外卖很快,但你不会因此觉得自己会做菜。
- 搜索引擎惯性。
我们用了十几年 Google/Stack Overflow,思维模式早已固化为"输入问题 → 拿答案"。AI 聊天框长得跟搜索框一模一样,于是大脑自动切换到搜索模式:一句话甩过去,等结果。但 AI 不是搜索引擎,它是一个可以和你协作的实体------只是你没给它协作的机会。
- 缺少质量基线。
如果你不清楚"好代码"长什么样------不清楚自己项目的分层架构、错误处理规范、命名约定------那 AI 吐出什么你都觉得"还行"。阶段一的本质问题不是 Prompt 写得不好,而是你对输出的标准太低。
- 门槛最低的蜜罐。
不需要学任何新概念、不需要配置任何东西、不需要改变任何习惯。打开 Cursor,打字,回车。这个"零成本上手"恰恰是最大的陷阱------因为太容易,所以没有动力改变。如果大家都会的,又怎么体现 coder 的核心能力呢?
1.3 怎么跳到阶段二?
当你第三次发现"修剪 AI 代码的时间超过了手写的时间",就该停下来了。
"Most AI failures in production are context failures, not model failures."
--- Anthropic, Effective Context Engineering for AI Agents
AI 给的"平均答案",不是因为它笨,是因为你没给约束。
具体行动:下次开 Cursor 的时候,做一个简单的改变------不要说"写个 XXX",改成说"帮我规划一下怎么实现 XXX"。就这一个词的区别("写" → "规划"),会把你从单向命令模式拉进双向对话模式。
或者更直接:打开 Plan Mode。
2.阶段二:规划师(Plan Coder)
2.1 特征
核心特征:双向对话 | 关键工具:Plan Mode
当 Cursor 和 Claude Code 进入 Plan Mode(规划模式) 时,游戏规则变了。
核心原则:别让 AI 直接写代码,先让它出方案。
这个阶段我们要做的是在编码前先和 AI"吵架"。
比如"做一个订单状态流转系统。"
AI 不再直接生成代码,而是反问:"状态流转规则是什么?有终态吗?不同证券市场的订单的流转逻辑一样吗?"
当AI从"代码生成器"转变为"专家顾问",并通过反问来澄清需求,这种做法带来了本质上的好处。它标志着AI从工具向协作者的跃迁。
这种双向交流,不仅让 AI 能更清楚的了解需求,也让开发者对需求有更全面的了解。
与 AI 的交互流程变成了下面这个样子:
-
触发规划:人类提出模糊需求,AI进入Plan Mode,不直接写代码。
-
反问澄清:AI通过一系列问题(状态规则?终态?区域差异?)逼迫人类思考。
-
人类反思:人类发现自己思维盲区,不同证券市场的订单的流转逻辑不一样。
-
梳理反馈:人类想清楚后,向AI详细描述各区域的差异逻辑。
-
AI理解:AI吸收信息,按区域分别建模。
-
达成共识:通过多轮"吵架"直到双方对方案理解一致。
-
输出方案:AI 输出设计方案(状态图、伪代码等),供人类审查。
-
进入编码:方案通过后,才进入真正的代码生成阶段。
这个流程的核心是:先聊透,再动手。
代码 AI规划师 人类开发者 代码 AI规划师 人类开发者 人类反思 loop 多轮对话 达成共识 触发规划 反问澄清 梳理反馈 AI理解 追问细节 补充说明 输出方案 进入编码 生成代码
Plan Mode 的价值不在于让 AI 帮你干活,而在于通过一来一回的博弈,把你脑子里那些"理所当然"的隐性知识逼出来。
研究也印证了这一点。MIT Technology Review 指出,即便是 Vibe Coding,也需要编程专业能力,只是能力重新分配了------从写代码转向了上下文管理、快速评估、以及判断何时接管 AI。
2.2 Plan Mode 的陷阱
Plan Mode(规划模式)虽然能极大提升需求清晰度和代码质量,但它并非银弹。在实际使用中,也要警惕 Plan Mode 的陷阱。
- Plan Mode 的成功体验反而成了舒适区。
你学会了和 AI 对话,代码质量确实比阶段一好了。你觉得"够用了"。这种进步带来的满足感,恰恰是通往下一阶段最大的阻力------因为你已经觉得自己"会用 AI 了"。
- 每次对话都在重复同样的背景介绍。
"我们项目用 DDD 分层"、"错误要用 xerror"、"状态变更要走 FSM"------你发现自己每次新开对话都要说一遍同样的话。这个重复劳动很烦,但你已经习惯了,觉得这是"用 AI 的正常成本"。实际上这是一个信号:你的知识应该持久化,而不是每次口头传达。
- 对话越长,AI 越糊涂。
你和 AI 聊了 20 轮,前面说好的约束它开始忘了,开始自相矛盾。你以为是 AI"变蠢了",其实是 Context Rot(上下文腐烂) ------ 对话太长,早期信息被淹没。但大多数人不知道这个概念,只是每次遇到就新开一个对话,从头再来。
- 没有意识到"知识可以代码化"。
很多人不知道 Cursor Rules、CLAUDE.md 这些机制的存在。或者知道但觉得"花时间写文档不值得"。这里有一个认知盲区:你以为写 Rules 是"额外工作",实际上它是一次投入、永久复利。
3.阶段三:上下文工程师(Context Engineer)
3.1 特征
核心特征:管理上下文窗口 | 核心对手:Context Rot
阶段二你学会了和 AI 对话,代码质量上去了。但你很快会遇到一个诡异的现象:同一个 AI,有时候表现惊艳,有时候蠢得离谱。
为什么?
因为你一直忽略了一个东西------上下文窗口(Context Window)。
3.2 Token 是 AI 的硬通货
所有 AI 模型都有一个上下文窗口,你可以理解为它的"工作记忆"。你发给 AI 的每一个字、AI 回复的每一个字、加载的每一个文件、每一条规则------全部以 Token 的形式填充这个窗口。
Token 就是 AI 世界的硬通货。Claude Opus 4.6 在你手上有几层功力,不取决于模型本身的能力上限,而取决于你怎么管理这个窗口。窗口干净、信息精准,它就是顶级架构师;窗口臃肿、垃圾堆积,它就是一个糊涂的实习生。
在 Claude Code 里,你可以随时输入 /context 查看上下文窗口的占用情况。这个命令应该变成你的习惯------就像开车看油表一样。
3.3 Context Rot:你一直在和它过招
Context Rot(上下文腐烂)是这个阶段你要面对的核心对手。简单说就是:上下文内容越多,AI 的表现越糟糕。
这不是理论,是实测结果。
有人做过系统测试:上下文占用 20-30% 时,AI 输出精准、结构一致;50% 时,小问题开始出现------命名风格漂移、导入路径混乱;70% 以上,AI 开始"自信地犯错"------语法正确但架构决策完全跑偏。
https://research.trychroma.com/context-rot
Anthropic 在其工程博客中也正式确认了这一点,并总结了四种上下文失败模式:
| 失败模式 | 表现 |
|---|---|
| Poisoning(中毒) | AI 的幻觉输出被当作"事实"反复引用,错误滚雪球 |
| Distraction(分散) | 过多历史对话淹没了当前任务重点 |
| Confusion(混淆) | 无关信息干扰判断,AI 开始张冠李戴 |
| Clash(冲突) | 上下文中存在矛盾指令,AI 左右为难 |
这个问题至今没有根本解决。2026 年了,Context Rot 依然在。
3.4 如何应对?
核心操作:留意上下文窗口的状态,到一定阶段主动 clear(重置)。
| 操作 | 说明 | 我的建议 |
|---|---|---|
| /context | 查看当前窗口占用 | 养成习惯,像看油表一样频繁 |
| /clear | 清空上下文,全新开始 | 每完成一个独立子任务就 clear,宁可重新铺垫 |
| /compact | 压缩上下文,保留摘要 | 不太推荐------效果一般,压缩本身也消耗 token,反而加速腐烂 |
大部分人不愿意 clear。心理上总觉得"前面聊了这么多,清掉可惜"。但事实是:一个干净的 50% 窗口,远比一个臃肿的 90% 窗口有价值。被腐烂的上下文拖累的 AI,还不如一个重新开始但方向明确的 AI。
3.5 做减法比做加法更难
这个阶段最违反直觉的认知转变是------不是给 AI 越多信息越好,而是要判断哪些信息帮助它、哪些信息伤害它。
举个例子。CLAUDE.md 曾经一度风靡------项目根目录放一个文件,写满编码规范和架构约定,AI 每次启动自动加载。听起来很美。但后来的研究发现,CLAUDE.md 在某些场景下反而会拉低成功率。为什么?因为那些规范并不是每个任务都需要,但它们每次都会占用上下文窗口。你以为在"教 AI",实际上是在"分散 AI 的注意力"。
同样的道理:
- 把整个仓库加载进来?伤害。AI 的注意力被稀释。
- 一次加载十个配置文件"以防万一"?伤害。不相关的信息就是噪音。
- 在一个长对话里做完五个不相关的任务?伤害。前面的任务残留是后面任务的毒药。
Anthropic 把这个核心思想总结成一句话:
"Finding the smallest possible set of high-signal tokens that maximize the likelihood of some desired outcome."
--- Anthropic, Effective Context Engineering for AI Agents
翻译成大白话:用最少的、最精准的信息,换取最好的结果。
上下文工程师的核心技能,不是"怎么给 AI 更多信息",而是"判断哪些信息该给、哪些信息不该给"。这是做减法的艺术。
3.6 阶段四是啥?
某天你统计了一下自己的工作时间分配,发现只有 30% 的时间在真正写代码,剩下 70% 都在查日志、查数据库、发通知、手动测试、等部署。你突然意识到:AI 只帮你优化了那 30%。
具体行动:
- 列出你每天做得最多的 3 个"非编码任务";
- 挑最高频的那个(大概率是查数据库),花一个下午接入一个 MCP Server;
- 把你最常重复的操作流程封装成一个 Skill;
- 体验到"动嘴比动手快"的那一刻,你就回不去了。
4.阶段四:系统编排者(System Orchestrator)
4.1 特征
核心特征:工具链 + 多 Agent | 核心能力:一人成军
前三个阶段都在优化"我和 AI 的单次沟通"。到了阶段四,游戏规则彻底变了:我不只在写代码,我在设计一套 AI 工作的系统。
这一阶段融合三个关键能力:
4.2 能力 1:触碰现实(MCP)
MCP(Model Context Protocol)是 Anthropic 创建的开放标准,2025 年 12 月捐赠给 Linux Foundation。业界称它为 "AI 的 USB-C" ------ 一套统一的协议,让 AI 连接任意外部工具和数据源。
截至 2026 年 2 月的生态数据:
- 9700 万 月 SDK 下载量
- 13,000+ GitHub 上的 MCP Server 实现
- 所有主流厂商接入:Anthropic、OpenAI、Google、Microsoft、Amazon
你的 IDE
MCP
MCP
MCP
MCP
MCP
AI Agent
数据库
飞书
浏览器
Notion
...
实操场景:
| 场景 | 以前 (纯手动模式) | 现在 (MCP 模式) |
|---|---|---|
| 查订单状态 | 打开 DBeaver → 手动执行多条 SQL 语句 → 人肉拼接状态,拼凑出业务全貌。 | 一句话完成:"查一下订单 xxx 的全链路状态"。AI 通过 MCP 自动查询数据库并分析返回结果。 |
| 回归测试 | 手动打开后台管理系统 → 一步步点击导航菜单 → 输入查询条件 → 手动截图并粘贴到文档。 | AI 直接操作浏览器,自动执行回归测试步骤,并自动截图生成报告。 |
MCP 的三个核心概念:Resources(只读数据,类似 GET)、Tools(执行操作,类似 POST)、Prompts(预定义模板,类似 Swagger)。
另一个常见问题:MCP 和 Google 主导的 A2A(Agent-to-Agent) 协议是什么关系?答案是互补------MCP 解决 agent 连接工具,A2A 解决 agent 之间协调。
4.2 能力 2:消灭重复(Skills / 自定义命令)
如果你发现自己总在重复同一套 Prompt,就该把它固化成 Skill。
这不仅仅是省时间,而是把最佳实践代码化、可复用化。
4.3 能力 3:分身协作(Multi-Agent)
SWE-bench(AI 编程能力基准测试)有一个反直觉的发现:同一个底层模型,在不同 Agent 框架下的得分差了 17 题。这说明 Scaffolding(编排框架)比 Model(模型)更重要------选对工具、配好上下文,比追逐最新模型效果更大。
2026 年的 AI 编程工具已经分化成三大品类:
| 品类 | 代表工具 | 特点 |
|---|---|---|
| 终端 Agent | Claude Code / Aider / Gemini CLI | 最省 token,适合大规模重构 |
| IDE Agent | Cursor / Windsurf / GitHub Copilot | 最佳 IDE 集成,日常开发首选 |
| 自主 Agent | Devin / OpenAI Codex | 端到端自主执行,云端并行 |
也有的形态是利用 Git Worktrees 实现多 Agent 并行:
指挥官(你)
定义接口契约 & 分发任务
Agent A
feature/api
后端接口
Agent B
feature/ui
前端组件
Agent C
feature/test
测试用例
合并 & 冲突解决
交付
多 Agent 并行效率惊人,但最大挑战不是写代码,是 Merge。如果三个 Agent 对接口定义的理解不一致,合并时就是灾难。前提条件:你必须先把接口契约定义清楚,然后才分发任务。
推荐阅读
| 资源 | 链接 | 一句话推荐 |
|---|---|---|
| Anthropic: Context Engineering | anthropic.com | 上下文工程的理论根基 |
| MIT: What is Vibe Coding? | technologyreview.com | Vibe Coding 的定义与边界 |
| Cursor Docs: Rules | cursor.com/docs/rules | 官方 Rules 配置指南 |
| awesome-cursorrules | github.com | 38k+ stars 的社区 Rules 模板集 |
| MCP 官方文档 | modelcontextprotocol.info | 从零搭建 MCP Server |
| AI Coding Agents 对比 | lushbinary.com | 2026 主流工具功能 & 价格横评 |