承接上一章初遇Open AI,深入了解大语言模型训练范式,对大模型训练范式的宏观认知,今天让我们潜入技术深水区,从算法工程师的视角,详细拆解LLM如何通过数学公式逐步进化为智能系统。
算法工程师将精心准备的预训练数据集 输入已随机初始化参数 的LLM大语言模型 内,模型内部庞大的多层神经网络(深度神经网络)通过多层公式的参数组合 来承载智能能力,机器学习 的核心任务就是通过损失函数(如y=lnX,常见损失函数) 定义的总误差 来量化模型表现,进而依据梯度方向 的偏导数计算 ,通过梯度下降 算法不断迭代调整每一个参数,最终在参数空间中找到最优解,实现从随机初始化到智能涌现的数学进化过程。
什么是模型
模型就是数学公式+参数的组合
设计模型,就是设计能解决真实问题的数学公式。
模型基本做的都是分类任务,比如:
输入:给定一组符合要求的输入数据(需要判断类别)
已知:类别总数为n(n选1)
输出:经过一系列数学公式计算后,输出n个概率,分别代表属于某类别的概率理论讲得再多,不如一次实际案例来得更直接、更明了。接下来我将用一个经典案例 ------"识别鳄鱼与蛇的模型",来具体说明模型内数学公式的实际运作机制。这个案例源于我2018年初学人工智能时,做的一个小模型,至今仍是我理解大模型数学本质的最佳案例。
这是一组鳄鱼与蛇的2维数据(身材、体重):
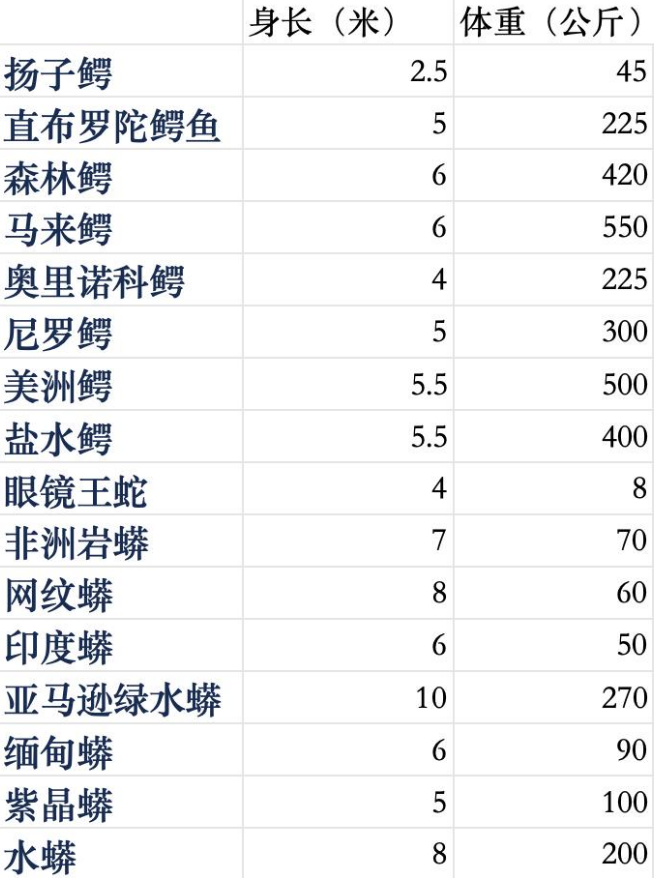
因为是2维数据,方便在2维坐标轴Y/X轴上体现身长/体重,如下图:
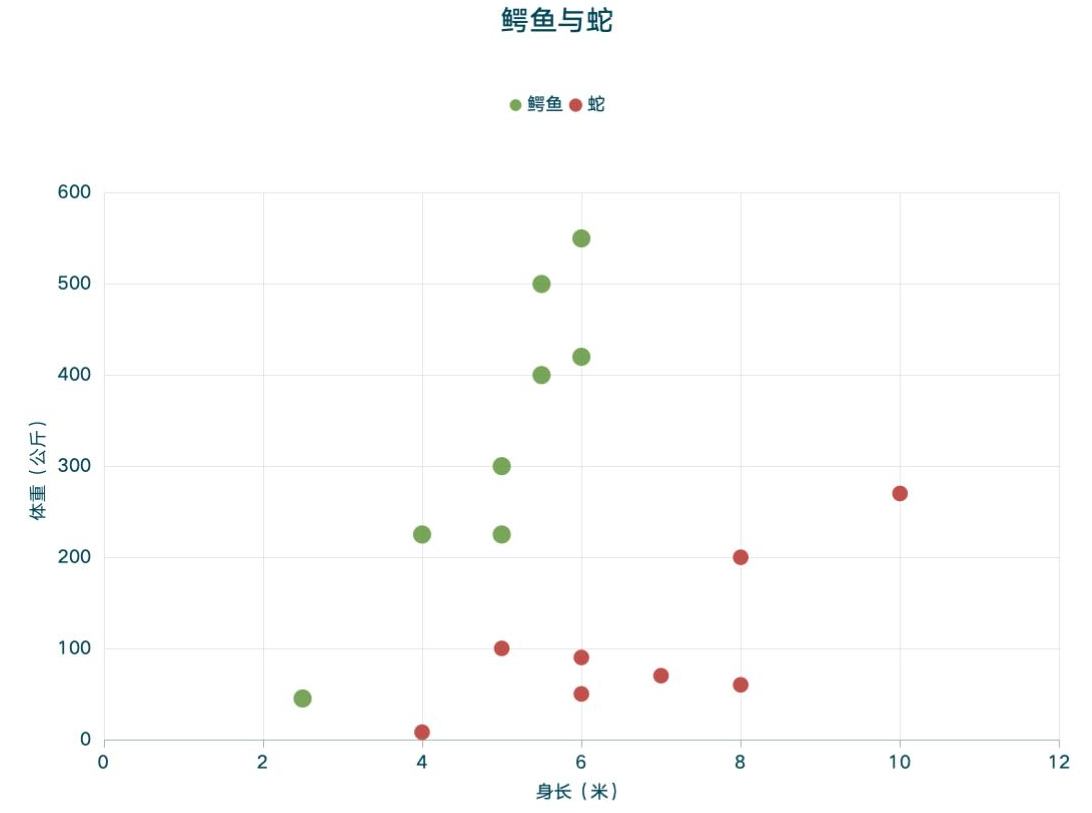
现在我是一名算法工程师,我设定该模型的数学公式(线性公式 )是y = ax + b,a的参数是50,b的参数是-100,2维坐标轴如下图所示:
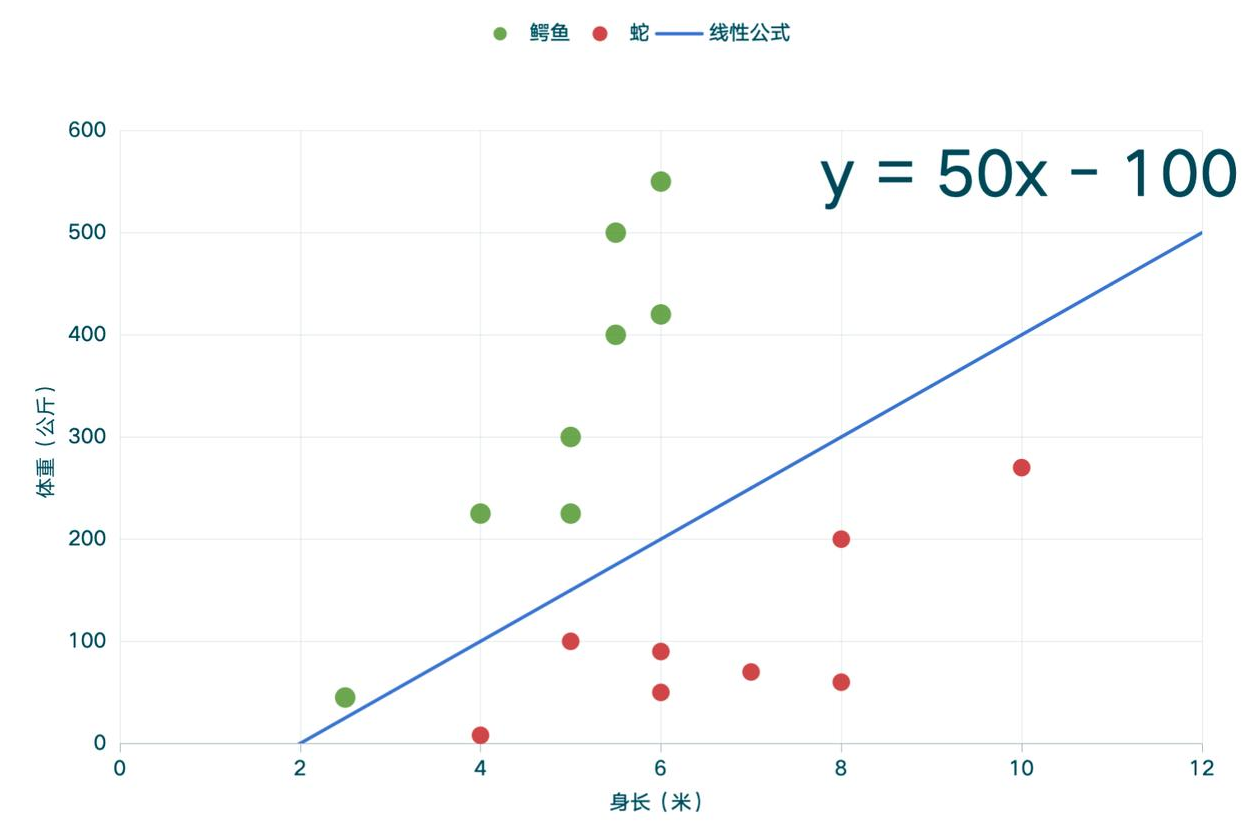
最开始 y = ax + b公式内的a与b的参数是随机的,并且在2维坐标轴上,a参数控制斜率 ,b参数控制平移 。通过损失函数 来计算总误差,学习率 与步长 配合,让LLM训练更高效、快捷。
比如,我现在定义损失函数 为(ax + b - y)2,步长是6,误差表如下图:
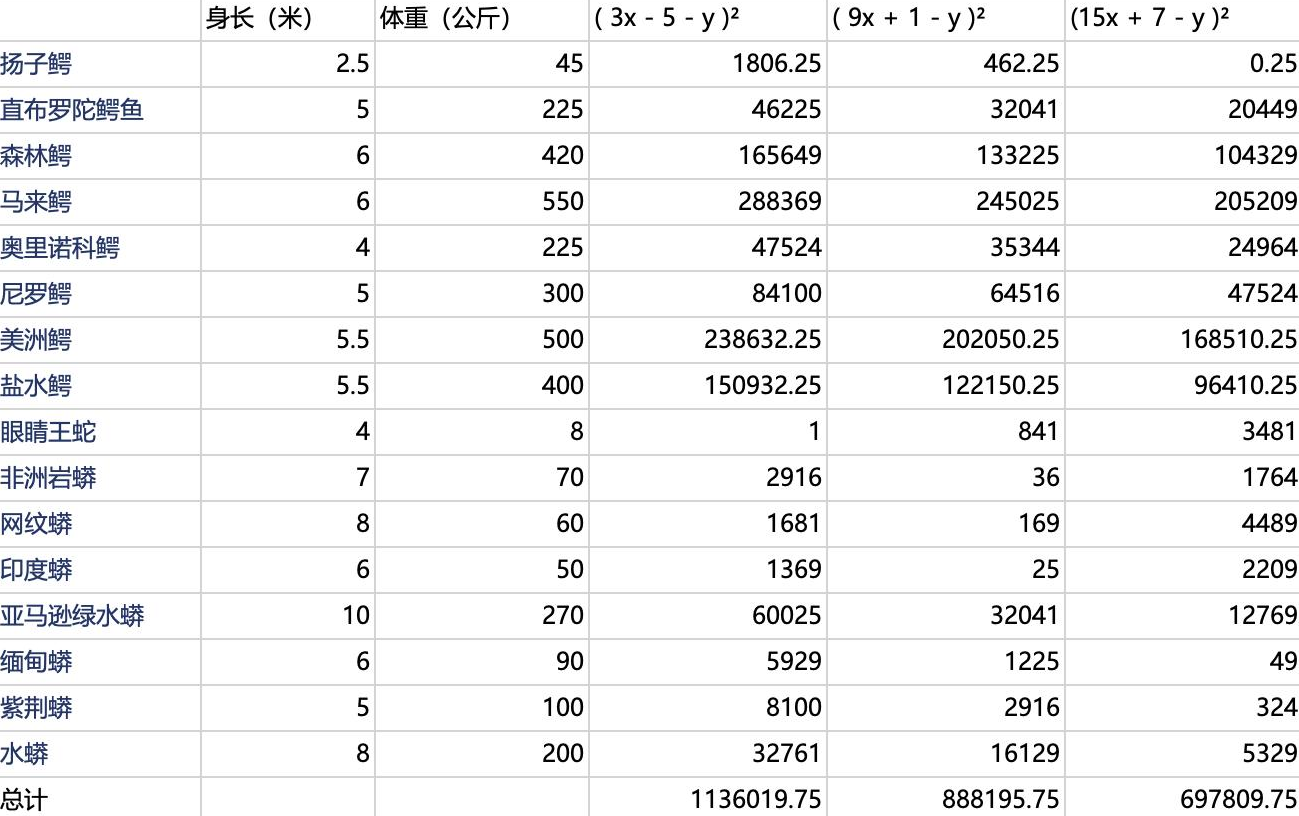
"总计"内的误差值 越大,就越不精准,所以前期,我们的步长 要大,随着模型参数 的调整,总误差值 相差越小,步长 也会慢慢变小,并且每走一步,都要重新看下梯度变化(偏导数) ,重新计算总误差 。当总误差 下降比较大时,步长 可以放心大胆的大步向前迈。当总误差 恒定在一个波动区间内时,就会进行模型收敛,这个阶段也代表了模型训练结束。
最终我们会得到一组总误差最小的参数组合:y = 50*x - 100。
y = 50*x - 100 可以转化为
50*x - 100 - y = 0确定好该公式的参数后,往后不管什么鳄鱼或蛇,只要知道它的身长、体重,只要带入到这个模型公式,我就知道它是鳄鱼还是蛇。
只要大于0的就是蛇,小于0的就是鳄鱼。
学习率: LLM训练之前可以进行设置,设置的数值越大,LLM训练越快,整体步长 大;设置的数值越小,学习速度就慢,但是精度高。而且学习率 与步长是配合来的。
那复杂真实问题怎么办?一样可以通过数学公式进行解答,只是这个数学公式会很复杂,设计非线性公式与线性公式的组合,并且公式内的参数会很多。比如下图这个公式:
但是生活中,问题各种各样,复杂度有高有低,里面情况极其复杂。并且人类设计公式是会有瓶颈与极限的,问题太过多种多样,人类就会发现没办法去一个个设计,这个时候,人们就想到我们人脑能把生活/工作中的事情做到妥善的处理,那么机器能不能像人脑一样,模拟真实场景里真实问题的任务进行处理? 这就是下面要聊到的神经网络。
万金油公式:神经网络
上面聊到了神经网络的由来,那么神经网络是怎么样的?又是怎么模仿人脑的?
人工神经网络的由来
人脑大约有860亿个神经元 和约100万亿个神经突触 ,这两个数字构成了人脑智能的物理基础。
通过这2个数字的量级差异 ------突触数量比神经元多出三个数量级,揭示了一个重要事实:智能不在于"计算单元"的多少,而在于"连接网络"的复杂度。
每个神经元平均与10,000+其他神经元相连,形成了一个超高密度的三维网络。这种连接模式带来了几个关键优势:
- 信息冗余性:即使部分神经元损坏,网络功能仍能维持
- 并行处理能力:信号可同时沿多条路径传播
- 动态可塑性:突触强度会随经验实时调整,实现快速学习
- 存储与计算合一:记忆存储在连接模式中,而非独立"内存区"
模拟人脑神经元与神经突触,就叫人工神经网络,以下简称 "神经网络"。
神经网络的每一层都有一次线性变换与非线性变换 ,如果只有线性变换 ,多层神经网络(深度神经网络) 的线性变换跟一层神经网络 的线性变换是一样的(毫无意义 ),为了模拟人脑的思维模式,就要拟合 更复杂的真实场景、更复杂的曲线以及更多的可能性,所以每层神经网络都需要线性变换+非线性变换。
神经网络的每层线性变换都是一样的,它是万金油公式
非线性变化也叫激活函数,每层的非线性变换都是算法工程师指定规则进行变换
拟合是通过数学公式拟合真实场景,想象为一个优等生,掌握了核心规律,能举一反三
过拟合:想象一个学生为了考试,把课本的每一道题、每一句话都背得滚瓜烂熟。考试时遇到原题能得满分,但只要题目稍微变个说法、换个数字,他就懵了------这就是过拟合。
欠拟合:学渣,连基本知识点都没掌握。
拿上一章初遇Open AI,深入了解大语言模型训练范式讲到的GPT-3模型来说,它这个模型有96层神经网络,1750亿个参数,数字上完全超越了人脑神经元数量,但是LLM模型内的参数连接是使用相对稀疏的矩阵运算,远不及人脑突触的复杂度。
简而言之,人工神经网络虽然借鉴了生物神经元的结构,但距离真正理解大脑的智能机制还很遥远。当前大模型的成功更多是数学优化的胜利,而非对生物大脑的精确模拟。这种"数学生物学"的类比,帮助我们理解概念,但不应成为技术路径的枷锁。
算法工程师设计神经网络,也是想模拟人脑,通过模拟神经元与神经突触的信号传递,在传递时,该突触可能是放大神经元,也可能是缩小神经元,也可能是不变,信息参数有可能是正数,也可能是负数,从而设计一种一劳永逸的公式结构。
人脑与人工神经网络的概念图:
下面是一个两层的神经网络图:
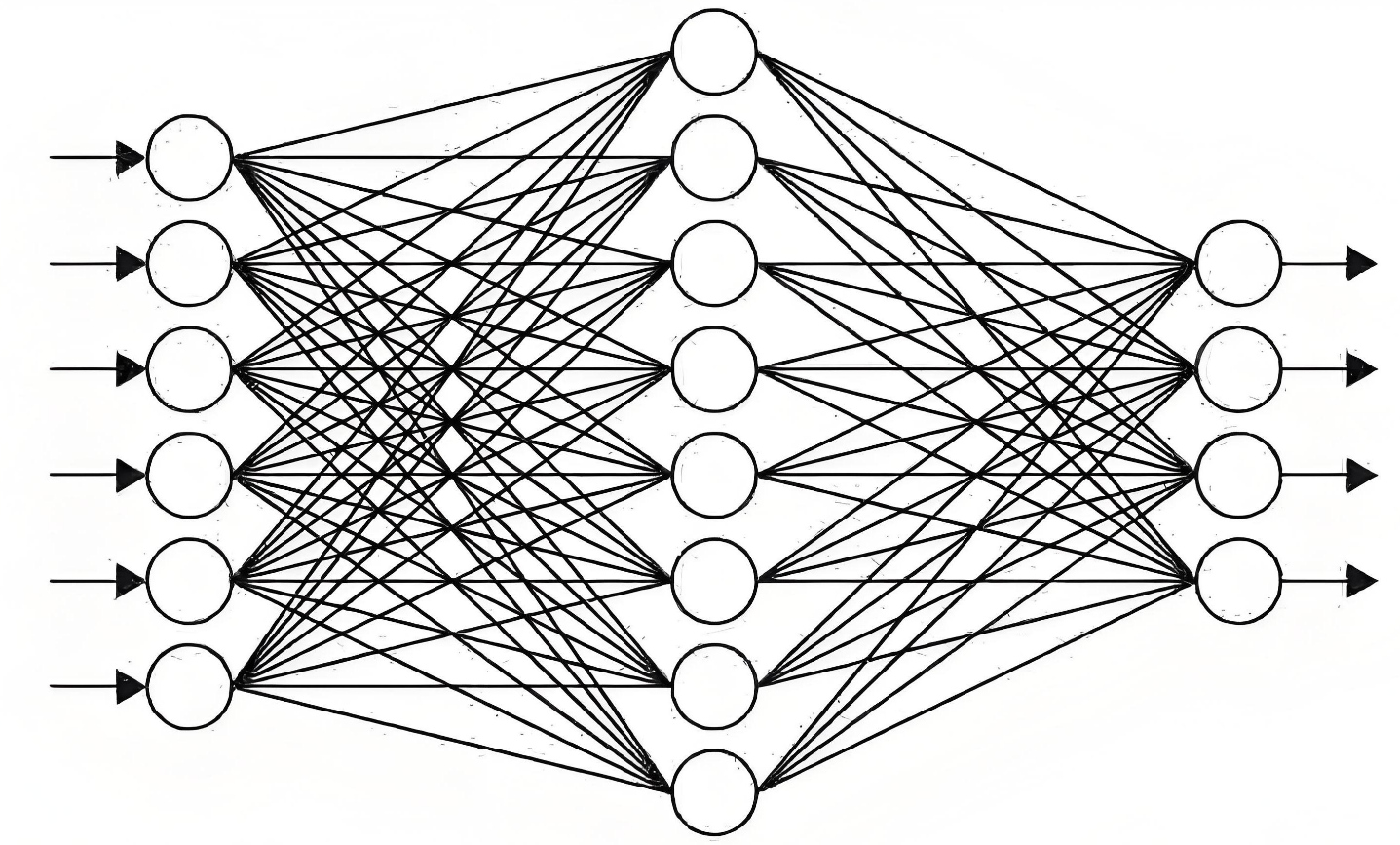
接下里,我拿一个网上的一个案例来讲解下,神经网络的数学公式与参数设计。
基于MNIST数据库的图像识别
MNIST包含了70,000张手写数字的图像,每一张都是28x28像素的灰度图像,其中6万张用于训练,1万张用于测试,每张图像的内容只包含一个手写数字,从0到9的其中一个数字。
任务:给定一张28x28像素的灰度图像,经过一系列数学公式计算后,输出10个概率,分别代表该图像中的内容是0-9某个数字的概率。
下面是手写数字图片:

首先从图片上来看,手写数字1,是由28 * 28像素组成的图片,如下图所示:
把视觉图片转化为像素数值:

这个图片是由784维的向量数据组成。
之前小模型"识别鳄鱼与蛇"的数学公式:y = 50 * x - 100,那么这个784维数据的图片识别的模型公式是?
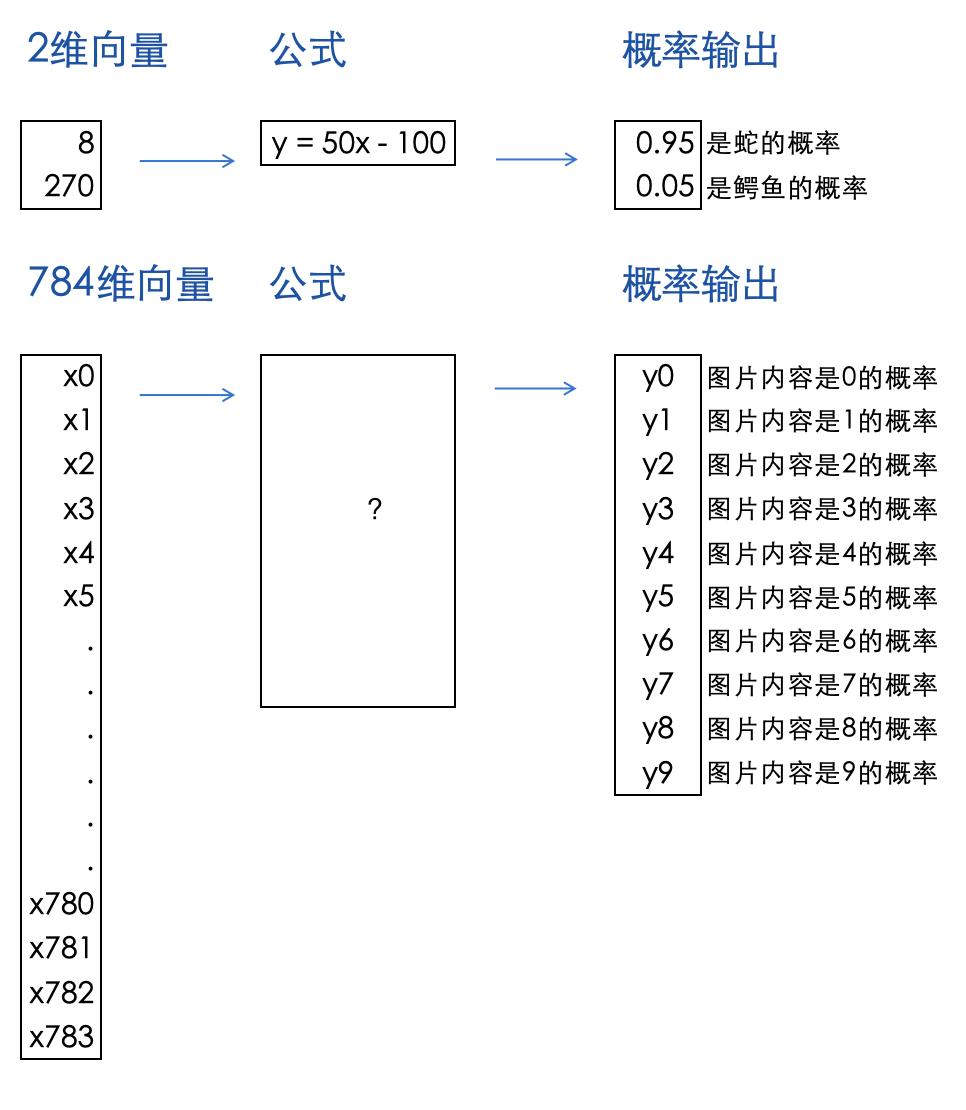
神经网络结构的数学公式
神经网络最核心的是数学公式,是由算法工程师去定义。
聊到这,就不得不提一下:算法工程师是如何调教神经网络:
- 网络深度(层数):
像剥洋葱一样逐层挖掘信息。层数越深,网络就能理解越抽象、越隐蔽的模式。比如识别照片:前几层识别"边缘和颜色",中间层识别"形状和物体",深层就能理解"这是只猫在玩球"。但太深会导致梯度消失,需要用残差连接等技术解决。 - 隐藏层维度:
决定网络的"记忆容量"。维度越大,能存储的特征信息越多。好比一个房间,空间越大能放的家具就越多。但太大容易过拟合(死记硬背),太小又学不会复杂规律。 - 非线性激活:
让网络具备"判断力"。没有激活函数,网络就只是一堆线性计算,只能处理简单关系。引入激活函数后,网络就能模拟复杂的曲线和逻辑,实现"如果A且B,则C"这样的非线性推理。 - 损失函数:
网络的"评分标准"。定义"对错"的标准,比如预测错了扣多少分。不同的任务需要不同的评分规则:分类任务看准确率,回归任务看误差大小,目标检测要看定位和分类的综合效果。 - 训练数据集、测试数据集:
防止"作弊"。训练集让网络学习,测试集用来检验真实能力。就像考试:平时练习的题目不能当考试题,否则网络只会背答案,遇到新题就不会了。
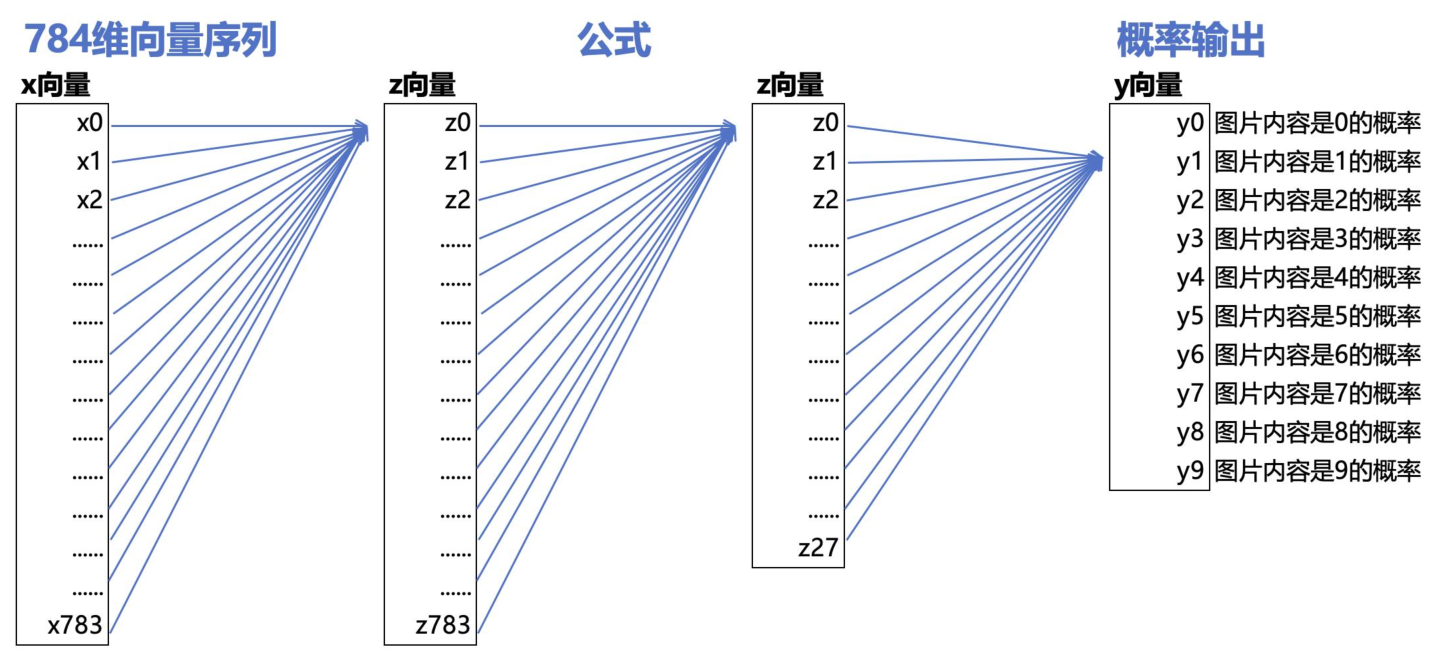
下面是一个784维度向量数据的2层神经网络,以及数学公式:
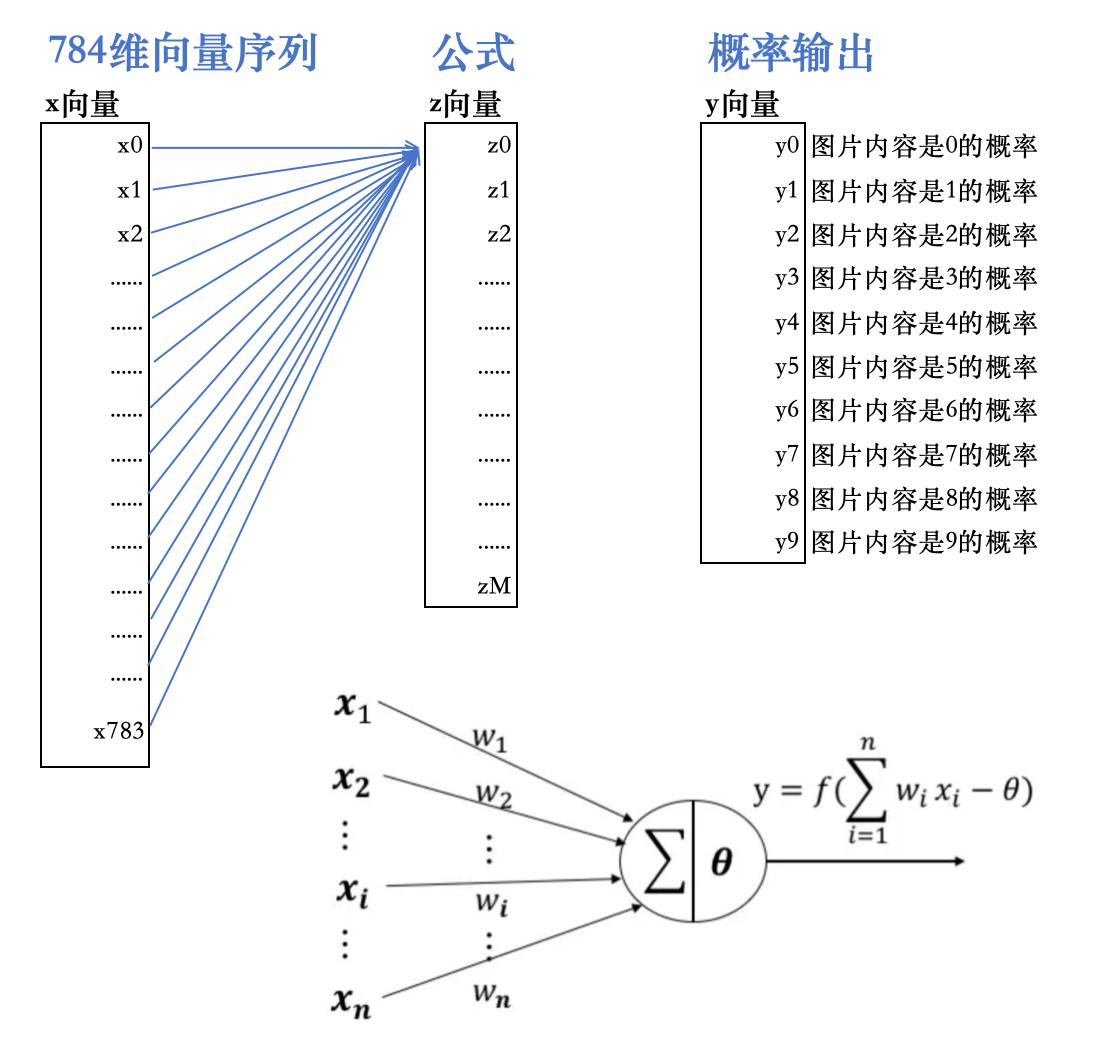
我们需要一系列这样格式的公式:
第一层神经网络:
z0= w0 * x0 + w1 * x1 + w2 * x2 +...+ w781 * x781 + w782 * x782 + w783 * x783 + w784 其中的x0-x783,这784个数值就是输入数据 ,其中的w0-w784,这785个数值是待确定的参数 ,类似于y=ax+b中的a和b ,待模型训练结束之后,这785个数值也就都确定下来,公式会变成类似这样的格式:z0=3 * x0 + 5 * x1 + 2 * x2+ ...+ 0.3 * x781 -8 * x782+ 1.7 * x783+6.5
z0是通过上述公式计算得出,z1、z2、z3...zM的计算公式同理,且z1、z2、z3...zM,分别都拥有属于自己的785个w参数于是从x向量到z向量的过程,总计有785*(M+1)个参数假设M=783,则此步骤的参数总数有785 * 784 = 615440个。
第二层神经网络
而从z向量到y向量的计算过程,也是非常类似的,比如y0= w0 * z0 + w1 * z1 + w2 * z2+ ...+ w783 * z783 + w784其中的w0-w784,这785个数值是待确定的参数 。
而y向量中共有10个要计算的数值y0-y9,每个都有属于自己的785个参数于是此步骤的参数总数有785 * 10=7850个
以上就是2层神经网络。
神经网络的参数设计
确定参数,与公式结构同样重要,比设计公式更难
我可能会这样设计:首先设定z向量的长度为784,则x向量与z向量等长
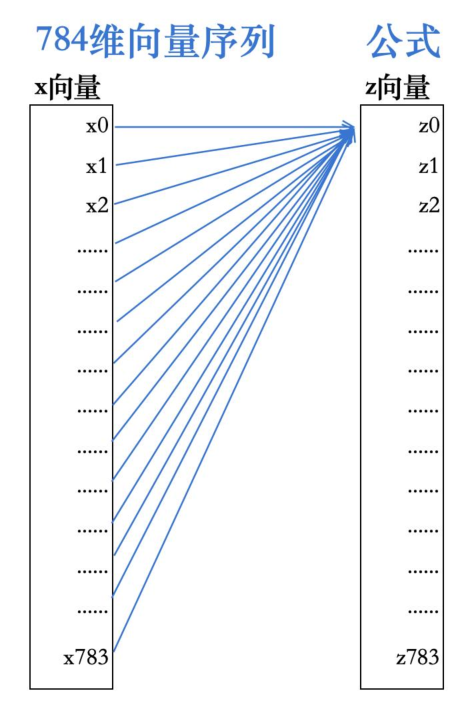
第一层神经网络,z0的公式:z0 = w0 * x0 + w1 * x1 + w2 * x2 +...+ w781 * x781 + w782 * x782 + w783 * x783 + w784
这个时候,我进行非线性变换:规则1的参数进行设计,w0 = -1,w1 = 1,其他的w参数(w2~w784)都设置0。
z0 = -1 * x0 + 1 * x1 + 0 * x2 + 0 * x3 +......+ 0 * x783 + 0
解:z0 = x1 - x0其他的zM的公式,如z0一样.
比如:z1的公式:z1 = w0 * x0 + w1 * x1 + w2 * x2 + ... + w782 * x782 + w783 * x783 + w784
参数设计:w1 = -1,w2 = 1,其他w参数(w0、w3~w784)都设置0.
如此往复:z向量中的每一个值,都等于x相同位置的值减去下一个像素的值,也就是 zi = xi+1 - xi,z0 = x1 - x0,z1 = x2 - x1,z2...
下图是一个数字1的28 * 28 像素数值图:

通过激活函数(非线性变换)的参数设置,像素数值图如下图所示:

然后再进行非线性变换:规则2的参数进行设计,把非0的数值变为1,数值为0的不变,进行边缘提取,能得到是1的地方就是物体边缘,如下图所示:

把像素数值转化为视觉图片(更能直观的展现物体的边缘):
- 物体边缘未提取前的样式:
- 物体边缘提取后的样式:

最后一次进行非线性变换:规则3的参数进行设计,把像素数值每行的数字相加,得到一个28维的向量数据:

通过这个28维的向量数据,以及我们生活中真实场景逻辑(0 ~ 9数值,它们长的不一样,边缘也是不一样的),得出数字0 ~ 9,任一数字的物体边缘肯定不一样,它们28维的向量数据也是有很明显的差距。
如下图所示:
最后通过Softmax(归一化),输出0 ~ 9的数字概率,10个概率相加等于100%。
比如:输入手写3的像素图片:
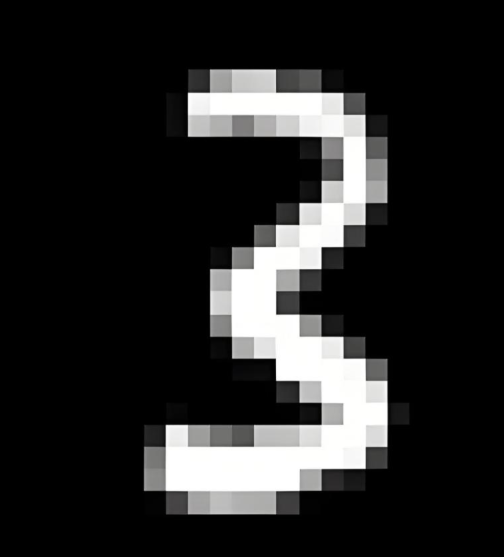
经过LLM分析,最后会输出10个概率:
数字0的概率:1%;
数字1的概率:2%;
数字2的概率:2%;
数字3的概率:85%;
数字4的概率:5%;
数字5的概率:2%;
数字6的概率:1%;
数字7的概率:1%;
数字8的概率:0.2%;
数字9的概率:0.8%;
深度神经网络(多层结构的神经网络)
层数比较深的神经网络,也叫深度神经网络
- 优势:多层神经网络有助于去提取一些隐藏、隐含、不容易发现的一些更深层的特征信息。
它像剥洋葱一样逐层挖掘信息。层数越深,网络就能理解越抽象、越隐蔽的模式。比如识别照片:前几层识别"边缘和颜色",中间层识别"形状和物体",深层就能理解"这是手写数字1"。但太深会导致梯度消失,需要用残差连接等技术解决。
深度学习是在深度神经网络上做训练、学习,去确定总误差最小化的参数。
"基于MNIST数据库的图像识别" 这个案例也是一个深度神经网络:
神经网络与机器学习
神经网络是万能公式,那机器学习是什么呢?它为什么而存在?
首先,咱们之前说过模型就是数学公式+参数的组合。
现在有了神经网络,设计公式结构 就轻松多了,人类设计的公式融合神经网络,但是有了数学公式,还要确定参数 ,一个模型内的参数太多,我们刚刚也说了GPT-3模型 内有1750亿个参数,人脑没办法一个个去计算,并且每个参数都有组合。
比如MNIST 的那个网络有多少个参数?
它有3层神经网络,计算得出的参数个数:784 * 785 + 28 * 785 + 10 * 29 = 637710个。
这637710个参数还有复杂的参数组合,我们人脑一个个去计算,时间太长,而且没办法把全场景的组合覆盖完全,所以我们衍生出了机器学习。
机器学习 :通过计算机完成大规模数学计算,以找到相对更优的参数组合的过程,就叫做机器学习,也就是我们所说的模型训练。
模型训练/模型学习/机器学习,它们的目标都是想办法得到一组参数,使总误差最小化。
从简单的神经网络开始
我在最上面有提到一个 "识别鳄鱼与蛇"的小模型 ,我们先以这个简单神经网络进行模拟整个机器学习的过程。
1、公式:y = ax + b;
2、参数:确定a和b分别是多少。机器学习的过程:
1、随机初始化一组(a,b),比如a=3,b=-5;
2、在训练数据集中,利用y = ax + b 进行分类;
3、计算分类结果的误差;
4、计算a和b的值应该如何变化可以减小误差;
5、计算出一组新的(a,b)值;
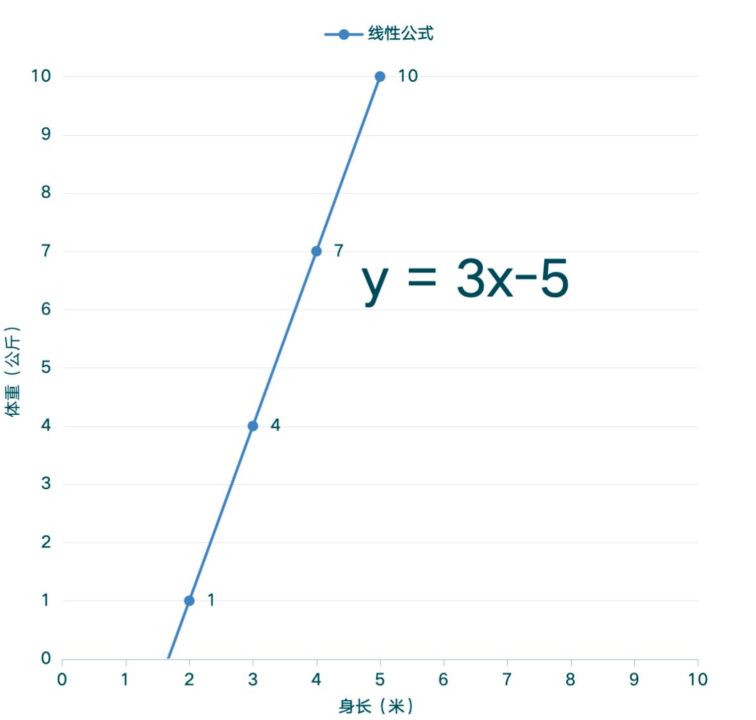
6、回到步骤2。在训练数据集中,利用y = 3x - 5进行分类
y = 3x - 5 也可以写成 3x - 5 - y = 0。
如果x=2,则利用y = 3x - 5 可得y=1,所以(2,1)点在直线y = 3x - 5 上;
同理,(3,4),(4,7),(5,10)这些点也都在直线y = 3x - 5 上;
而有些点如(2,2),(3,1),(3,8)等,就不在直线y = 3x - 5 上;
可发现(x,y)的值,如果能让等式3x - 5 - y = 0成立,则在直线上,那么3x - 5 - y > 0则在直线下方,3x - 5 - y < 0则在直线上方。如图所示:
把训练数据带入到公式内(3x - 5 - y),发现误差很大,大部分都是小于0的,都是鳄鱼。
这个时候,我们就要进行引入损失函数 ,定义误差,调整公式内的参数。
之前有讲过,"识别鳄鱼与蛇"模型 ,我们定义了损失函数 为(ax + b - y)2,步长是6,误差表如下图:
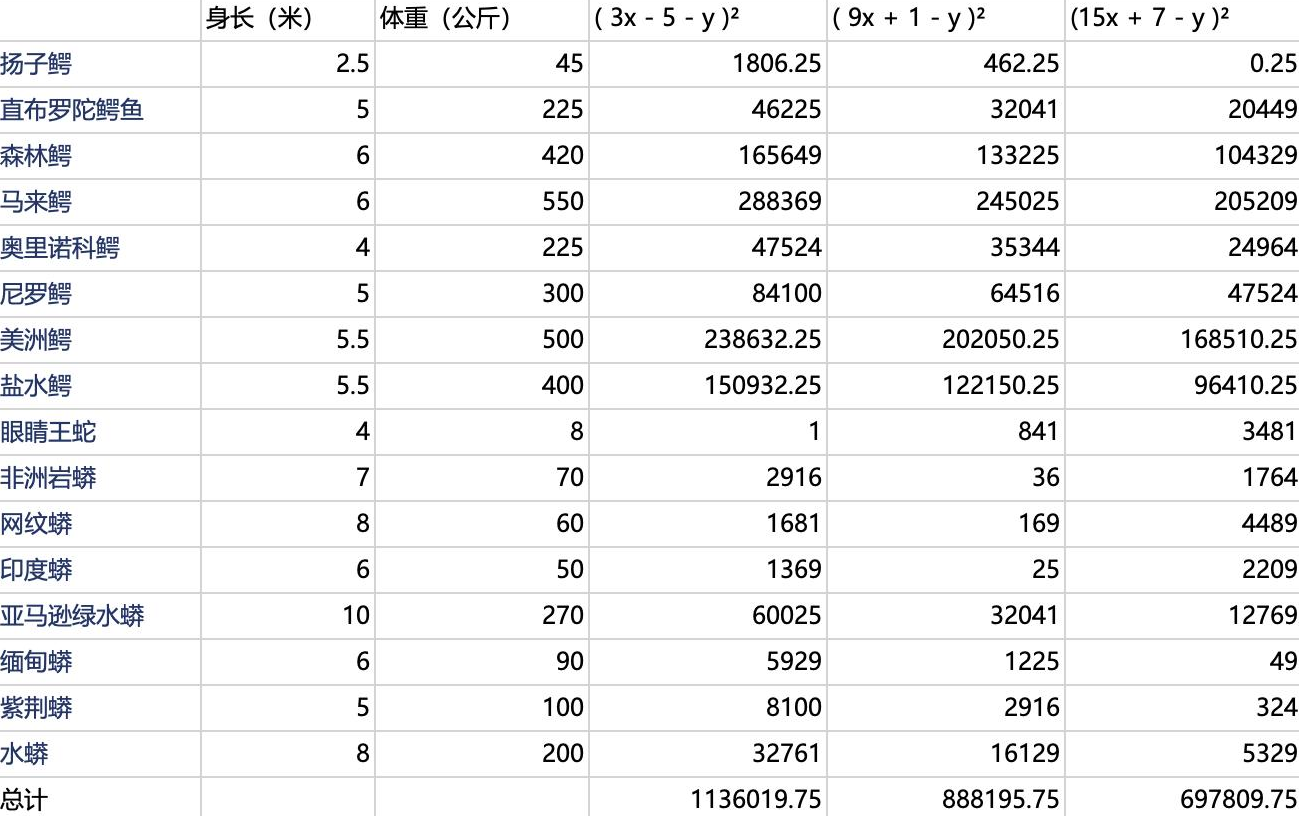
我们的目前是让总误差最小化,把目前的身长、体重、总误差值,则3个数字形成一个三维坐标轴,如下图所示:
我们通过不同的步长、a参数、b参数,带入到损失函数内,计算出不同的总误差,然后把a、b、总误差参数带入到3维坐标轴内,会如下图所示:
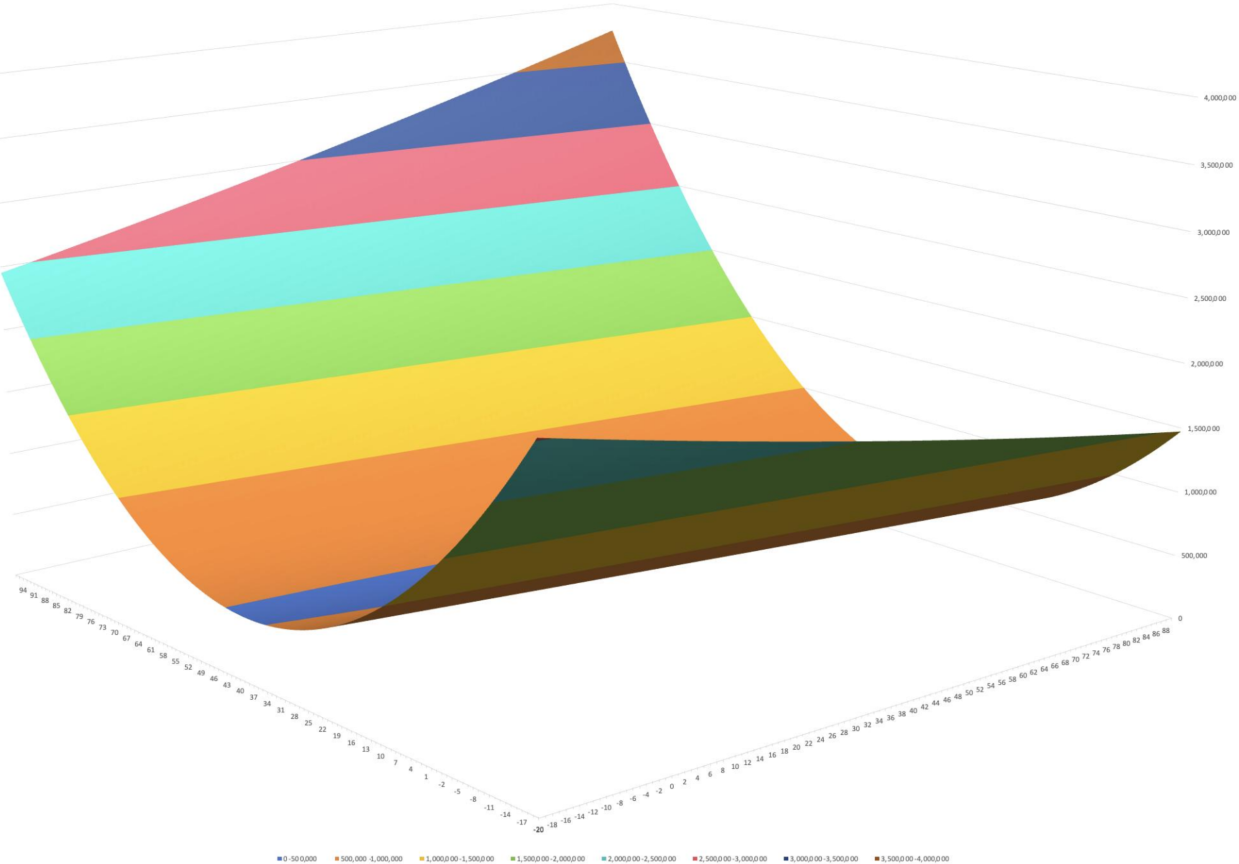
这个时候,要在这个三维坐标轴上找到最低的点,它的总误差最小,所以它的a、b参数才是我们最理想的参数。
我身为算法工程师,我有一个简单的方法,就是二位坐标系上,a轴数值不变,找到b轴上最低的点m,找到b轴上最低点后,b轴数值不变,找到a轴数值上最低的点n,最后得到(m,n)坐标上对应总误差轴的点肯定是最低的。
简而言之,就是横切一刀,竖切一刀,每切一刀,都找到这个平面最低的点,然后做比较拿到最低的点。
a轴切一刀,a轴上数值不变,找到b轴上最低的点,如图所示:
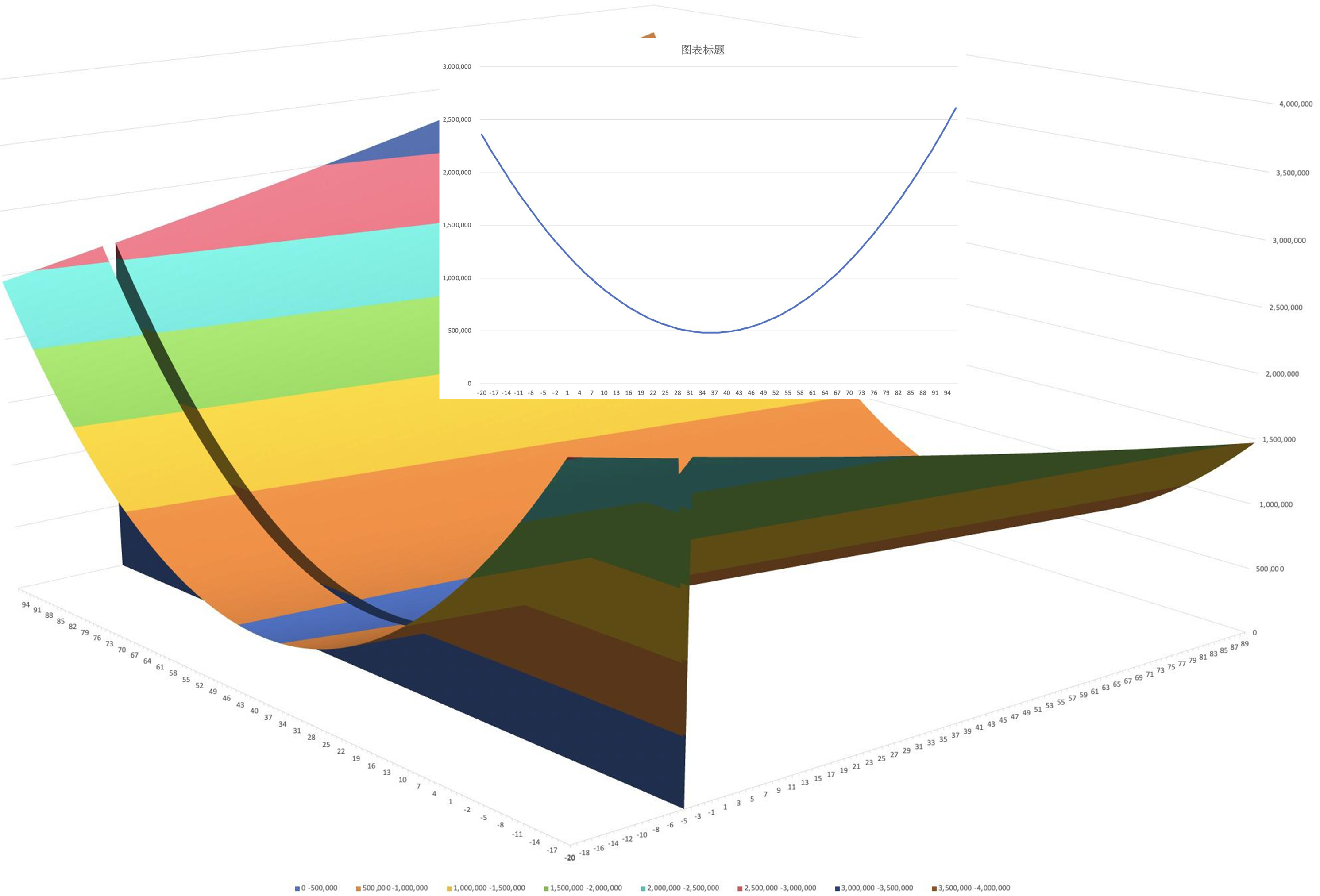
b轴切一刀,b轴上数值不变,找到a轴上最低的点,如图所示:
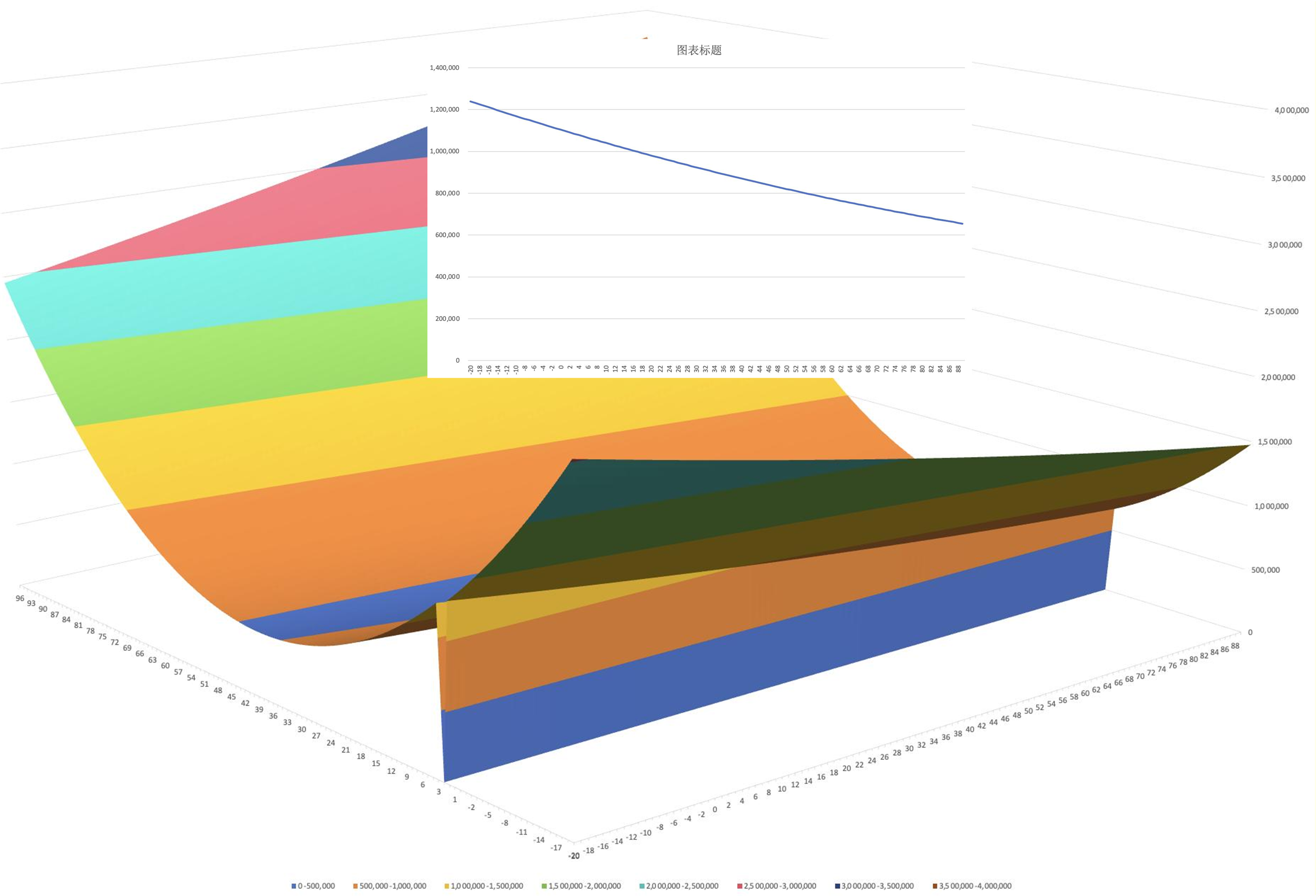
每次切一刀,找到数值最低点,都是一次梯度下降(也是数学上说的求偏导数)。
最后会得到一组最新的总误差最小的(a,b)值,y = 50x - 100。
设计损失函数
常见损失函数:
| 任务类型 | 首选损失函数 |
|---|---|
| 回归预测 | MSE |
| 二分类 | Binary Cross Entropy |
| 多分类 | Categorical Cross Entropy |
| 目标检测 | IoU Loss + CE |
| 分割任务 | Dice Loss |
| 文本生成 | Cross Entropy |
| 类别不平衡 | Focal Loss |
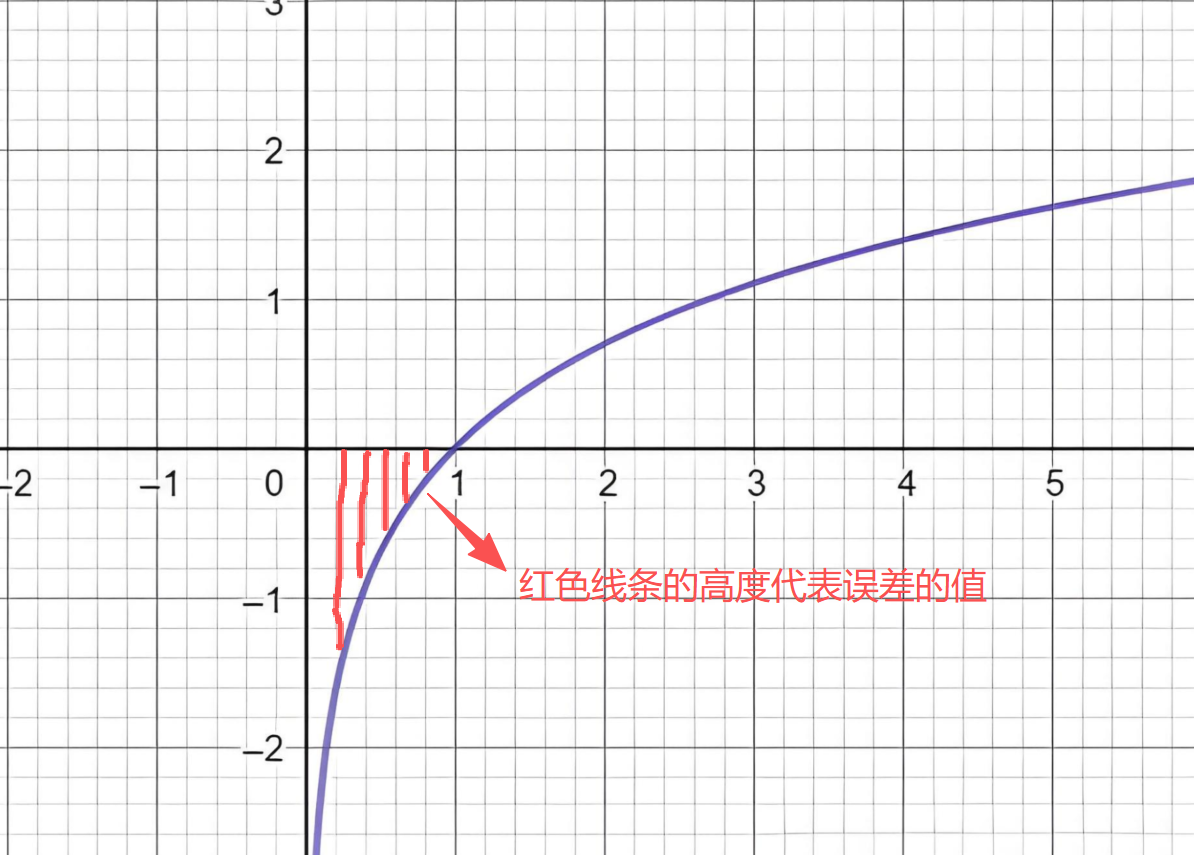
对数函数(y = lnX)
下面拿Cross Entropy函数-对数函数(y = lnX) 来举例:
"基于MNIST数据库的图像识别" 这个案例,输入图片是手写数字3的图片,计算0~9的数字概率:

对数函数(y = lnX) 是把正确答案下,模型输出的概率进行计算误差:
正确的答案系数为1,非正确答案系数为0,当前模型输出是数字3的概率是0.91 ,那误差就是ln(0.91) * 1 = 0.0943。
刚才MNIST 模型有784 * 785 + 28 * 785 + 10 * 29 = 637710个参数,然后机器学习的方式大概步骤按照上面讲的简单神经网络进行模拟整个机器学习的过程 来进行,先进行公式构造 ,再通过训练数据集 和步长、学习率 进行参数调整 ,得到相关参数列表,把参数带入到损失函数-对数函数(y = lnX) 内,再多一维误差参数 ,并且每个参数 都要反省下,每个参数 是要变大点、变小点或者不变 ,对于我们的总误差下降 是有帮助的,每个参数 都有自己的梯度方向 ,再根据步长 就可以计算每个参数 是要变大、变小或者不变 。最后把参数+误差参数 形成一个多维坐标轴(多维空间) ,然后可以像上面说的,横切一刀、竖切一刀找到总误差最低点,这个点就是总误差最小的点,它对应的参数就是最优组合。
维度越高,参数量越大
在多维空间内找到最低点,就是最小总误差值,它的参数就是最优组合。
如图所示:
比如,我们现在要计算其中637710个参数的梯度方向,
可以假设其他参数都不再改变,那么影响总误差的参数就只剩下一个,
所以只需分别计算每个参数的梯度方向,计算的时候,固定其他参数即可。
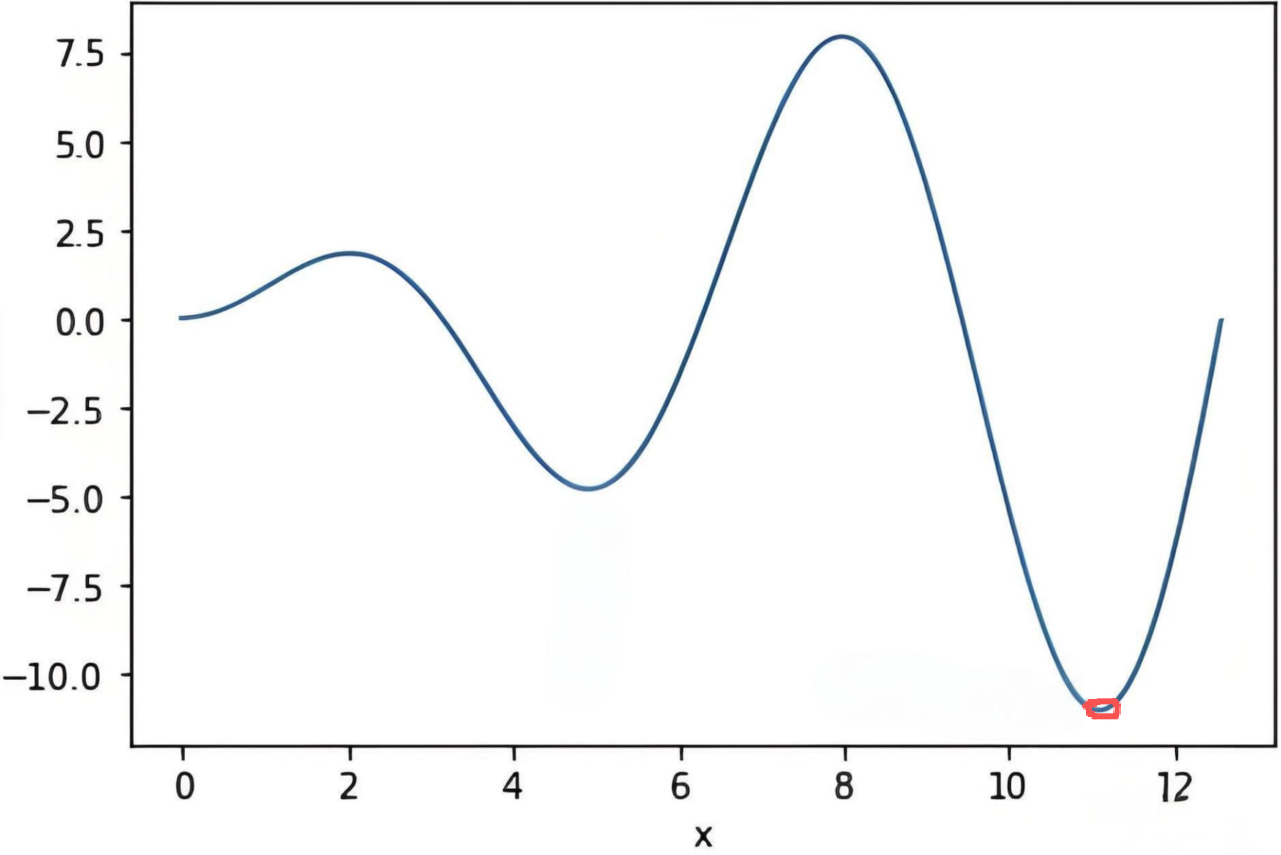
类似简单神经网络进行模拟整个机器学习的过程的横切一刀、竖切一刀方法 ,
二位坐标轴内找到最低点,如图所示:
训练范式、神经网络及机器学习的问题初解
训练范式
Pretrain(预训练) 、SFT(有监督的微调) 阶段,它们的总误差定义方式是一致的
Reword Model(奖励模型)、PPO(强化学习) 阶段定义总误差方式与Pretrain(预训练)、SFT(有监督的微调) 阶段的方式不一致。
LLM 有一批训练数据集 ,数据集内是多段文字,LLM参数微调 是一批段落先计算段落联合概率(总误差值) ,进行参数调整,然后再进行下一批段落计算,分阶段来,LLM也会迭代多个版本。
神经网络
图片特征提取是看图片有啥东西,
文字特征提取是让LLM模型理解语言和文字(输入文字---->LLM拟合---->输出人话)
神经网络内非线性变换(激活函数)是人类智慧的体现。
机器学习
AI底层逻辑是数学计算 ,但是模型不擅长数学计算 ,它像我们人一样,我们知道1+1=2,但是为什么1+1=2,没人去关心,只知道大家都是这样使用,是最低层计算逻辑之一。所以说模型不擅长数学计算,它只知道我输入参数,通过调整好参数的数学公式得到这个概率 ,然后整合出人可以理解的信息。