「几何先验注入3DGS」
目录
[01 几何先验从哪里来?](#01 几何先验从哪里来?)
[02 HGFA:三步炼成几何"翻译官"](#02 HGFA:三步炼成几何"翻译官")
[03 实验](#03 实验)
[04 总结与延伸](#04 总结与延伸)
自动驾驶要真正读懂周围世界,仅靠"看"是不够的------它需要知道每一个体素的位置、形状与语义,这正是3D语义占用预测任务的核心挑战。
现有基于高斯溅射的方法虽然在效率上令人眼前一亮,但它们的图像编码器只在有限的3D标注数据上训练,几何感知能力先天不足:路面时常出现断裂,建筑物轮廓残缺不全,跨视角的几何一致性更是无从谈起。
另一条路是直接微调视觉基础模型(VFM)------这些模型在海量多视角数据上预训练,天然具备强大的跨视角几何理解能力。然而,全量微调代价极高,还可能让模型"忘掉"来之不易的几何先验。
港科大沈劭劼团队另辟蹊径:冻结VFM,只训练一个轻量的适配器,将基础模型中蕴藏的几何知识精准注入高斯占用预测框架。
他们提出了VG3S(Visual Geometry Grounded Gaussian Splatting),在nuScenes基准上实现了IoU提升12.6%、mIoU提升7.5%的显著突破。
01 几何先验从哪里来?
3D语义占用预测的本质,是从多路摄像头图像中重建出一个密集的3D语义体素网格------每个格子里填什么、是路面还是行人、是建筑还是植被,都要说清楚。高斯溅射方法将场景表示为一组3D高斯基元,再通过"高斯到体素溅射"生成最终预测,在计算效率上远超传统体素方法。
但几何先验的缺失是这类方法的软肋。视觉基础模型(如VGGT、DVGT)在海量多视角数据上以深度估计、相机位姿预测等多任务联合训练,其中间层特征天然编码了丰富的跨视角几何对应关系。
问题在于:这些特征是通用的,并非为占用预测量身定制,直接拿来用效果有限;而全量微调又会破坏这些珍贵的几何先验。
VG3S的核心洞察是:不动VFM的权重,只训练一个即插即用的层次几何特征适配器(HGFA),将通用的VFM特征逐步转化为适合高斯解码器使用的几何增强表示。
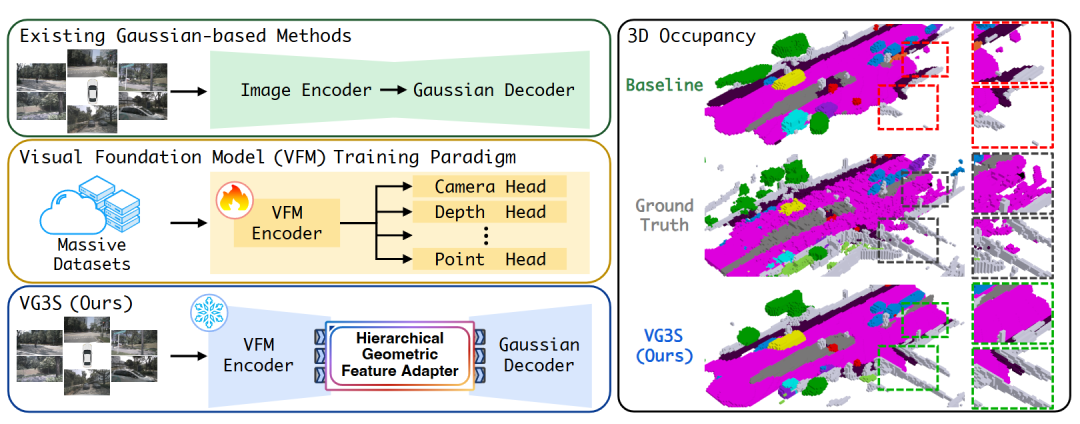
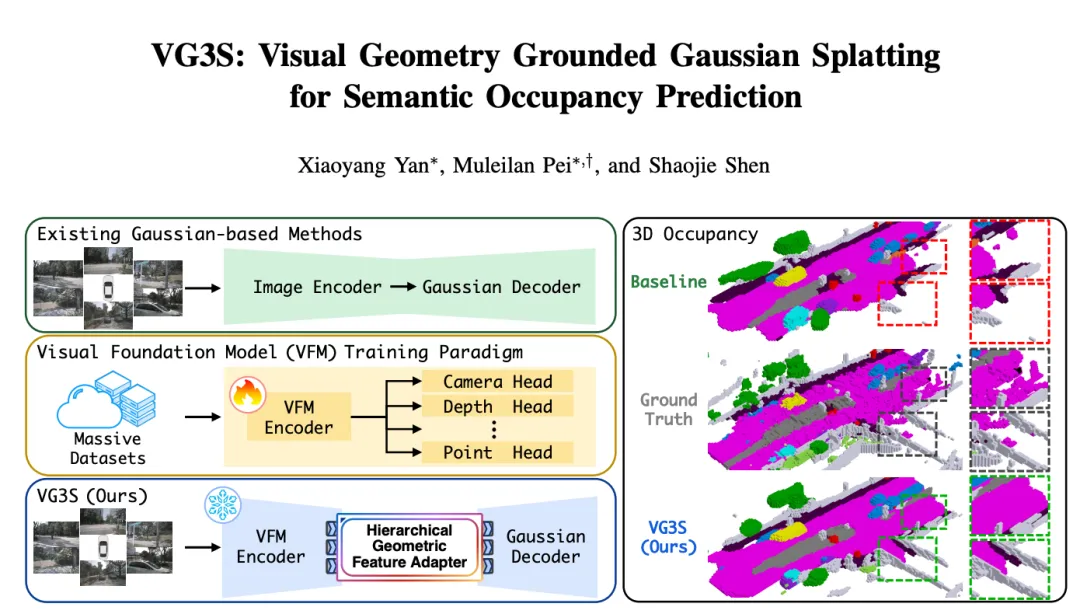
图1 | 三种范式的对比:左侧对比了三种技术路线------现有高斯方法直接用图像编码器,缺乏几何先验;VFM训练范式通过多任务学习获得几何能力但需全量微调;VG3S(下)则冻结VFM,仅用轻量适配器桥接两端,右侧的占用预测结果清晰展示了VG3S相比基线更完整、更连续的场景重建效果。
02 HGFA:三步炼成几何"翻译官"
VG3S的整体流程清晰而优雅:冻结的VFM编码器处理多视角图像,输出一组携带几何先验的视觉token;HGFA适配器将这些token逐步转化为几何增强特征;高斯解码器据此生成3D高斯基元;最后通过高斯到体素溅射得到密集的3D语义占用预测。
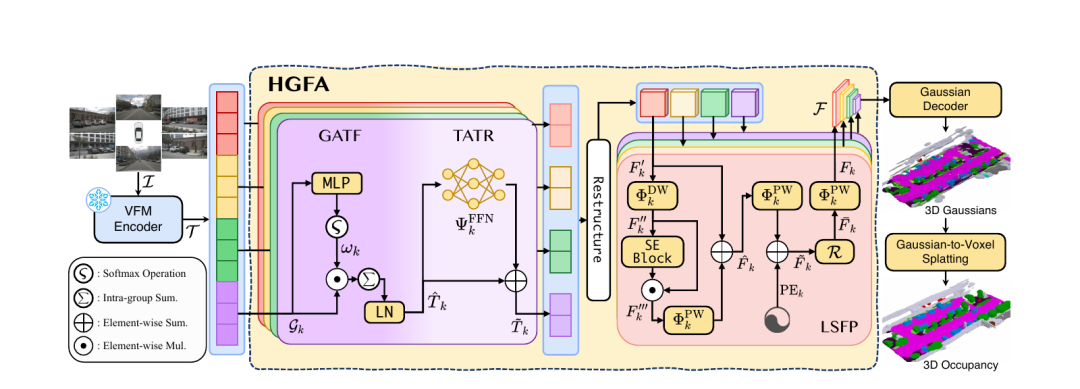
图2 | VG3S框架全貌:一条从"通用几何知识"到"精准占用预测"的流水线。左侧冻结的VFM编码器是"知识库",中间的HGFA(含GATF、TATR、LSFP三个模块)是"翻译官",右侧的高斯解码器和体素溅射是"执行者"。三者协同,让冰封在基础模型中的几何先验真正流动起来。
HGFA内部由三个串联模块组成,各司其职。
GATF------跨层几何信息的"智能聚合"
VFM在处理图像时会经过多个注意力层,每一层的输出都携带不同粒度的几何信息:浅层捕捉精细的局部结构,深层提炼高层语义。
如何把这些分散在各层的几何信息有效汇聚,是第一个关键问题。
分组自适应Token融合(GATF)模块将VFM所有注意力层的输出按语义粒度分为几个小组,每组内用一个轻量MLP动态计算各层的重要性权重,再加权求和并归一化,得到每组的紧凑几何表示。这种设计的妙处在于:它不是简单平均,而是让模型自己学会"哪一层的几何信息对当前任务更有价值",从而在保留关键几何细节的同时,有效抑制冗余激活。
TATR------任务导向的特征"校准"
经过GATF聚合的特征虽然紧凑,但仍嵌入在VFM的通用表示空间中,与占用预测的需求存在偏差。任务对齐Token精炼(TATR)模块以残差结构对每组特征进行精炼:
针对不同层组分配不同容量的前馈网络(浅层组用更大的隐藏维度保留细粒度几何,深层组用较小维度压缩高层语义),从而在表示容量与计算效率之间取得最优平衡。这一步相当于给几何特征做了一次"任务校准",过滤掉与占用预测无关的噪声,让特征真正为后续解码服务。
LSFP------多尺度空间结构的"重建"
高斯解码器需要的不是抽象的token序列,而是具有空间结构的多尺度特征图。潜在空间特征金字塔(LSFP)模块将精炼后的token还原为空间特征图,依次经过深度可分离卷积(捕捉局部空间上下文)、SE通道注意力(自适应强调重要通道)、逐点卷积(跨通道交互)和位置编码(注入空间位置信息),最终构建出一个多尺度特征金字塔。每个尺度对应不同的空间分辨率,为高斯解码器提供从粗到细的几何线索,确保局部几何一致性在特征空间中得到有效保持。
03 实验
在nuScenes占用预测基准上,VG3S的表现令人信服。以GaussianFormer-2为基线(IoU=30.56%,mIoU=20.02%),VG3S配合DVGT基础模型将IoU提升至34.41%、mIoU提升至21.52%,分别提升了12.6%和7.5%。
这一提升不仅体现在整体指标上,在可行驶路面、人造物体、植被等结构性类别上的改善尤为突出------这些正是对几何一致性要求最高的类别。
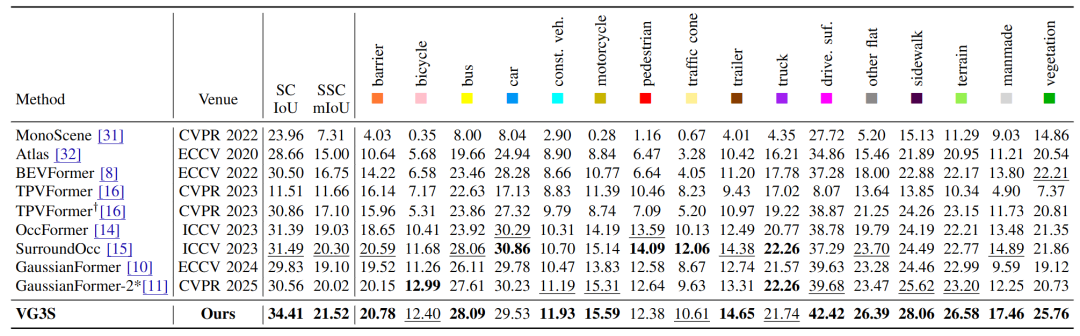
图3 | 在NuSCENES数据集上的量化实验结果
值得一提的是,VG3S对多种VFM均表现出良好的泛化性:无论是DINOv2、VGGT还是DVGT,接入HGFA后均能获得显著提升,证明该框架并非针对特定模型的"过拟合"设计,而是一个真正通用的几何注入方案。
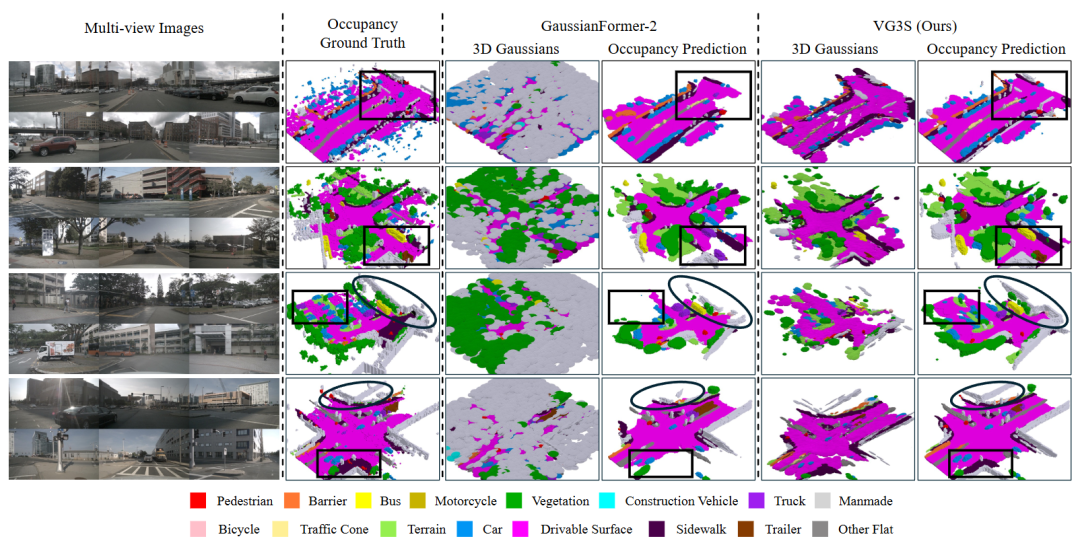
图4 | 四个真实驾驶场景的定性对比:基线 vs VG3S。每行对应一个场景,从左到右依次是多视角输入图像、占用真值、GaussianFormer-2的3D高斯分布与占用预测、VG3S的3D高斯分布与占用预测。方框和椭圆标注了关键差异区域------基线在路面连续性、建筑物轮廓和停车场结构上均存在明显缺失,而VG3S在几何先验的加持下,这些区域的预测更加完整、连贯。
消融实验进一步验证了HGFA三个模块缺一不可:去掉GATF,IoU从33.29%降至32.52%;去掉TATR,降至32.70%;去掉LSFP,降至32.57%。
而若将整个HGFA替换为一个朴素的线性投影层,性能骤降至30.59%,几乎回到基线水平------这说明简单地"接入"VFM特征远远不够,层次化的几何适配才是关键。
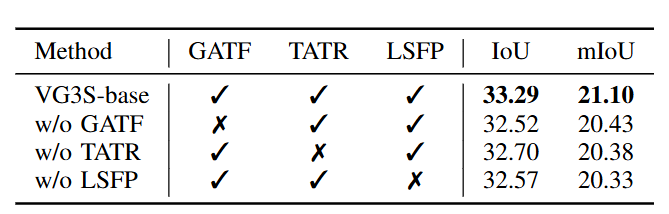
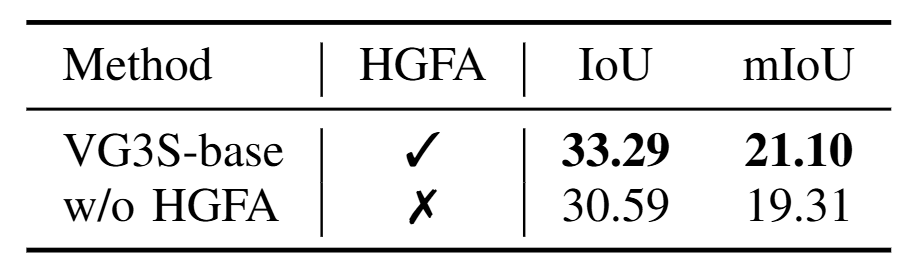
图5 | 消融实验结果
GATF的分组数K=4被实验证明是最优配置,过少(K=1,即无分组)或过多(K=6)均会导致性能下降,印证了"适度分组、语义粒度一致"这一设计原则的合理性。
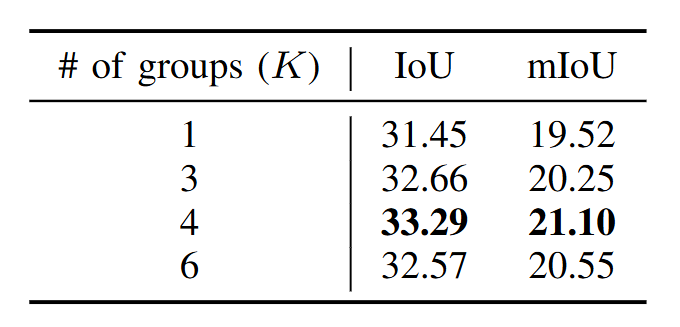
图6 | GATF分组实验结果
04 总结与延伸
VG3S代表了一种颇具启发性的技术路线:不微调,只适配------通过轻量的层次适配器,将大规模预训练模型中沉淀的几何知识精准迁移到下游任务,同时保留其通用泛化能力。
这一思路与当前大模型时代"冻结主干、训练适配器"的主流范式高度契合,也为自动驾驶感知提供了一个低成本、高收益的几何增强路径。
随着视觉基础模型在几何理解上的能力持续增强,如何更高效地将这些能力"嫁接"到各类感知任务,将是具身智能和自动驾驶领域的重要研究方向。VG3S给出了一个清晰的答案:关键不在于模型有多大,而在于几何知识能否真正"流动"到任务所需的地方。
论文标题:VG3S: Visual Geometry Grounded Gaussian Splatting for Semantic Occupancy Prediction