目录
[一、为什么需要 DiffusionDrive?](#一、为什么需要 DiffusionDrive?)
[1.1 端到端自动驾驶的困境](#1.1 端到端自动驾驶的困境)
[1.2 扩散模型的机遇与挑战](#1.2 扩散模型的机遇与挑战)
二、核心思想:截断扩散策略 (Truncated Diffusion Policy)
[2.1 直觉:人类驾驶不是从纯噪声开始的](#2.1 直觉:人类驾驶不是从纯噪声开始的)
[2.2 锚定高斯分布 (Anchored Gaussian Distribution)](#2.2 锚定高斯分布 (Anchored Gaussian Distribution))
[2.3 源码中的前向过程](#2.3 源码中的前向过程)
三、级联扩散解码器 (Cascade Diffusion Decoder)
[3.1 架构设计](#3.1 架构设计)
[3.2 源码中的关键实现](#3.2 源码中的关键实现)
[4.1 损失函数公式](#4.1 损失函数公式)
[4.2 损失函数源码实现](#4.2 损失函数源码实现)
[五、推理:2 步实时生成](#五、推理:2 步实时生成)
[6.1 NAVSIM 基准](#6.1 NAVSIM 基准)
[6.2 模式多样性 (Mode Diversity)](#6.2 模式多样性 (Mode Diversity))
[6.3 定性结果](#6.3 定性结果)
一、为什么需要 DiffusionDrive?
1.1 端到端自动驾驶的困境
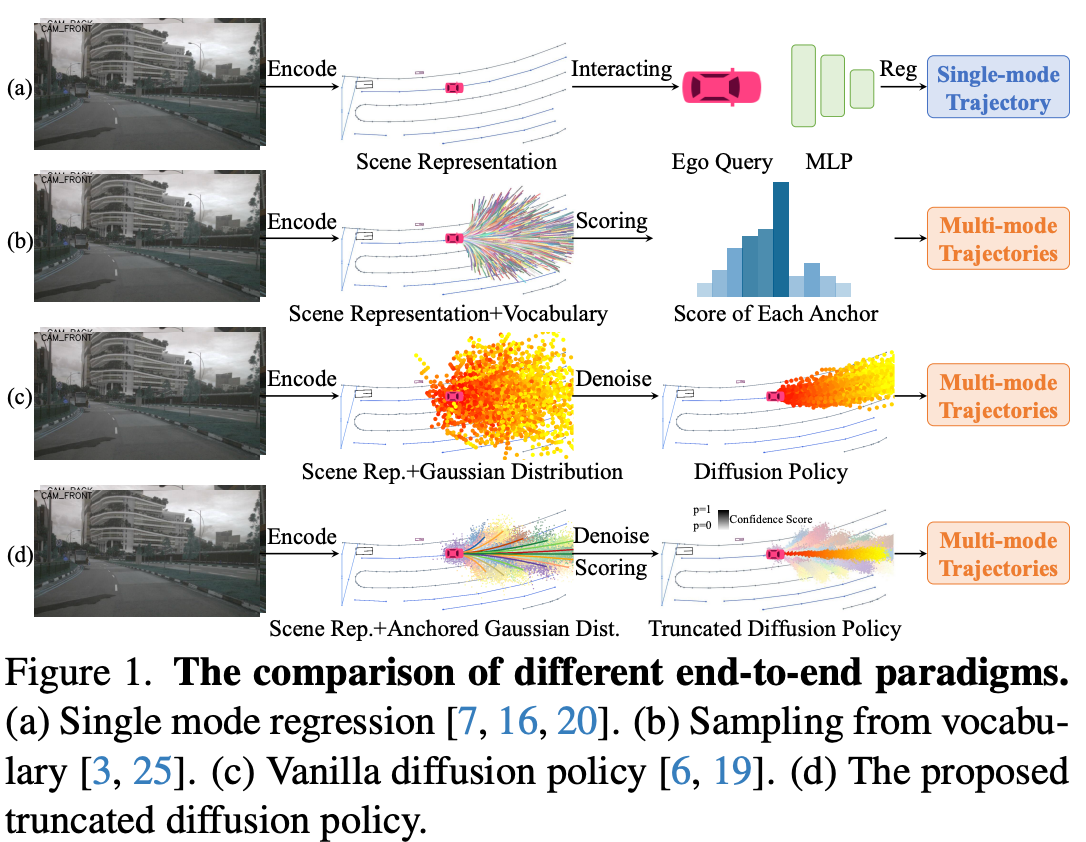
传统端到端规划器(如 Transfuser、UniAD、VAD)通常采用单模态回归------从 ego query 直接回归一条确定性轨迹。这在复杂交通场景中面临根本性问题:
-
不确定性建模缺失:路口直行 vs. 左转是两种完全不同的驾驶意图,单模态回归只能"取平均"
-
缺乏备选方案:当主轨迹因突发情况失效时,没有 B 计划
VADv2 等后续工作尝试用大规模锚点词汇表(4096 个固定轨迹)解决多模态问题,但这又带来了新的问题:
-
词汇表规模与计算开销成正比
-
无法覆盖所有 out-of-vocabulary 场景
1.2 扩散模型的机遇与挑战
扩散模型(Diffusion Policy)在机器人领域已被证明能建模多模态动作分布 ,但在自动驾驶落地时面临两大障碍:
| 问题 | 具体表现 |
|---|---|
| 模式坍塌 (Mode Collapse) | 从标准高斯噪声采样,20 步去噪后所有轨迹收敛到同一模式 |
| 推理速度过慢 | 20 步 DDIM 去噪在 NVIDIA 4090 上仅 ~2 FPS,无法满足实时性 |
DiffusionDrive 的核心创新正是同时解决这两个问题。
二、核心思想:截断扩散策略 (Truncated Diffusion Policy)
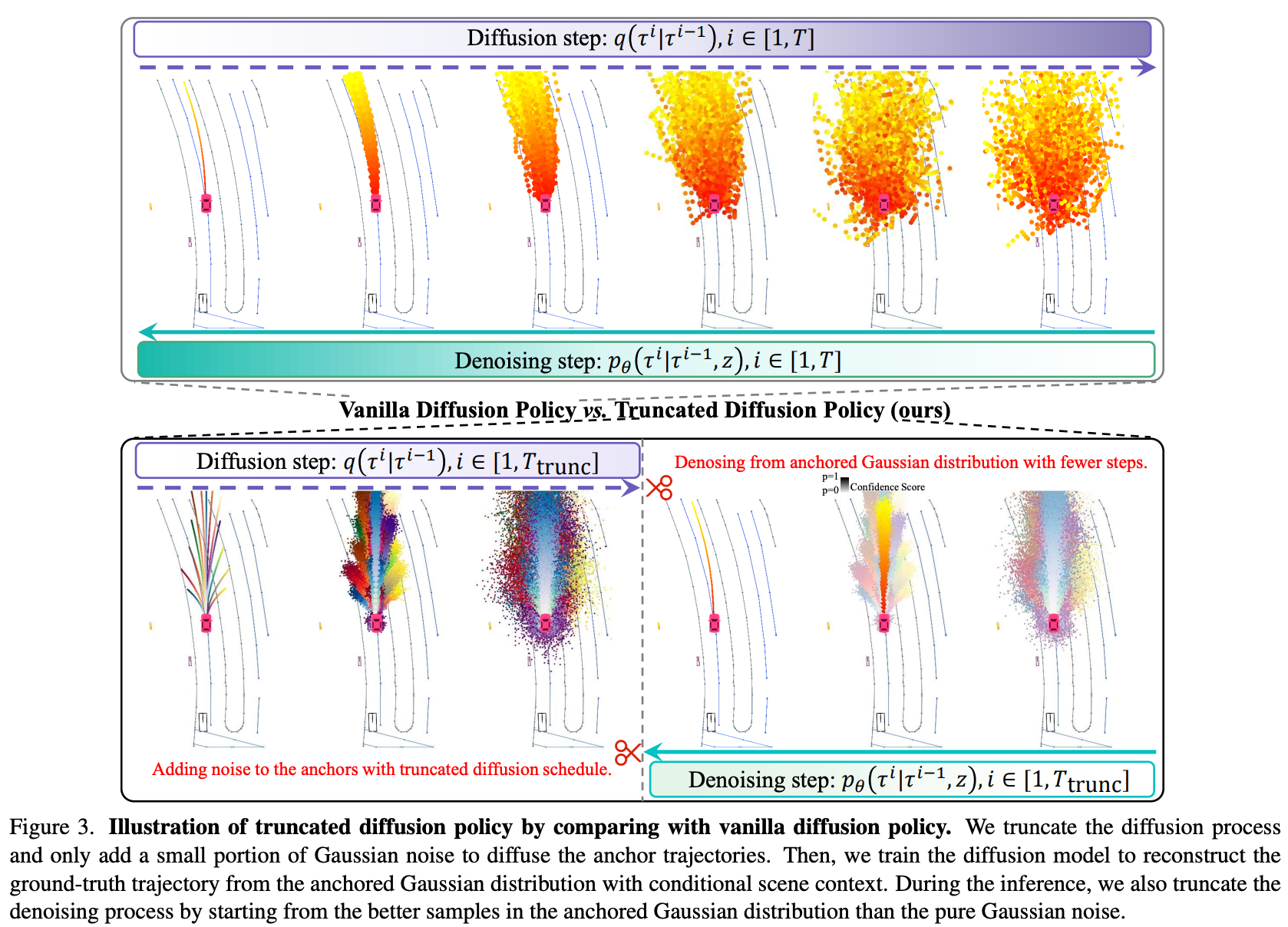
2.1 直觉:人类驾驶不是从纯噪声开始的
标准扩散模型的前向过程是:
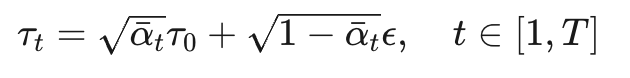
这意味着推理时需要从纯高斯噪声(t=T)开始,逐步去噪 20 步才能得到轨迹。
但人类驾驶并非如此------我们不会从完全随机的动作开始规划,而是基于先验驾驶模式(直行、左转、变道等)进行微调。
2.2 锚定高斯分布 (Anchored Gaussian Distribution)
DiffusionDrive 的关键洞察:用 K-Means 聚类专家轨迹得到 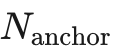 个锚点,将扩散起点从标准高斯替换为以锚点为中心的子高斯分布。
个锚点,将扩散起点从标准高斯替换为以锚点为中心的子高斯分布。
数学上,轨迹分布变为高斯混合模型 (GMM)
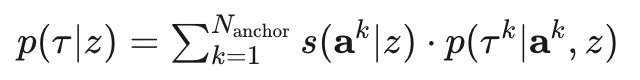
其中:

截断扩散的前向过程:
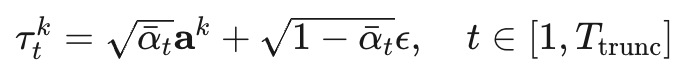
其中 ,这意味着:
,这意味着:
-
噪声只加到锚点附近,不会完全破坏先验结构
-
推理时仅需 2 步即可完成去噪
2.3 源码中的前向过程
在训练时,模型不需要像推理那样跑 DDIM 循环,而是随机采样一个时间步并进行单次去噪:
python
class DiffusionDriveAgent(nn.Module):
def __init__(self, config):
super().__init__()
# 1. 锚点加载 [20, T, 2]
self.register_buffer(
"plan_anchor",
torch.from_numpy(np.load(config.plan_anchor_path)).float()
)
# 2. 编码器 (Backbone)
self.backbone = TransfuserBackbone(...)
# 3. 级联扩散解码器 (Cascade Diffusion Decoder)
self.diffusion_decoder = CustomTransformerDecoder(
num_layers=2,
d_model=256,
nhead=8
)
@torch.no_grad()
def forward(self, sensor_data):
B = sensor_data['image'].shape[0]
# --- A. 特征提取 ---
bev_feat, bev_spatial_shape, agents_query, ego_query, status_encoding = self.backbone(sensor_data)
# --- B. 锚点截断加噪 ---
# 扩展 batch 维度后直接加噪。
anchors = self.plan_anchor.unsqueeze(0).repeat(B, 1, 1, 1)
noise = torch.randn_like(anchors)
# 假设截断步数为 t=25
t_truncated = torch.full((B,), 25, device=anchors.device).long()
noisy_trajs = self.scheduler.add_noise(anchors, noise, t_truncated)
# 初始化隐藏层特征 (用于 Transformer 内部流动)
traj_feature = self.init_feature(bev_feat, agents_query)
# --- C. 截断扩散去噪循环 ---
timesteps = [25, 0]
for i, t_current in enumerate(timesteps):
# 将离散的时间步 t 编码为特征向量
t_tensor = torch.full((B,), t_current, device=anchors.device).long()
time_embed = self.time_mlp(t_tensor)
# 调用级联 Transformer 解码器
poses_reg_list, poses_cls_list = self.diffusion_decoder(
traj_feature=traj_feature,
noisy_traj_points=noisy_trajs,
bev_feature=bev_feat,
bev_spatial_shape=bev_spatial_shape,
agents_query=agents_query,
ego_query=ego_query,
time_embed=time_embed,
status_encoding=status_encoding
)
# 【提取输出】:因为里面级联了 2 层,我们取最后一层([-1])的输出作为当前步的预测
pred_x0 = poses_reg_list[-1]
pred_scores = poses_cls_list[-1]
# 利用预测出的 pred_x0 结合扩散公式走到下一步。
if i < len(timesteps) - 1:
noisy_trajs = self.scheduler.step(pred_x0, t_current, noisy_trajs).prev_sample
else:
noisy_trajs = pred_x0
# --- D. 模式选择 ---
best_mode_idx = torch.argmax(pred_scores, dim=-1)
best_trajs = noisy_trajs[torch.arange(B), best_mode_idx]
return best_trajs三、级联扩散解码器 (Cascade Diffusion Decoder)
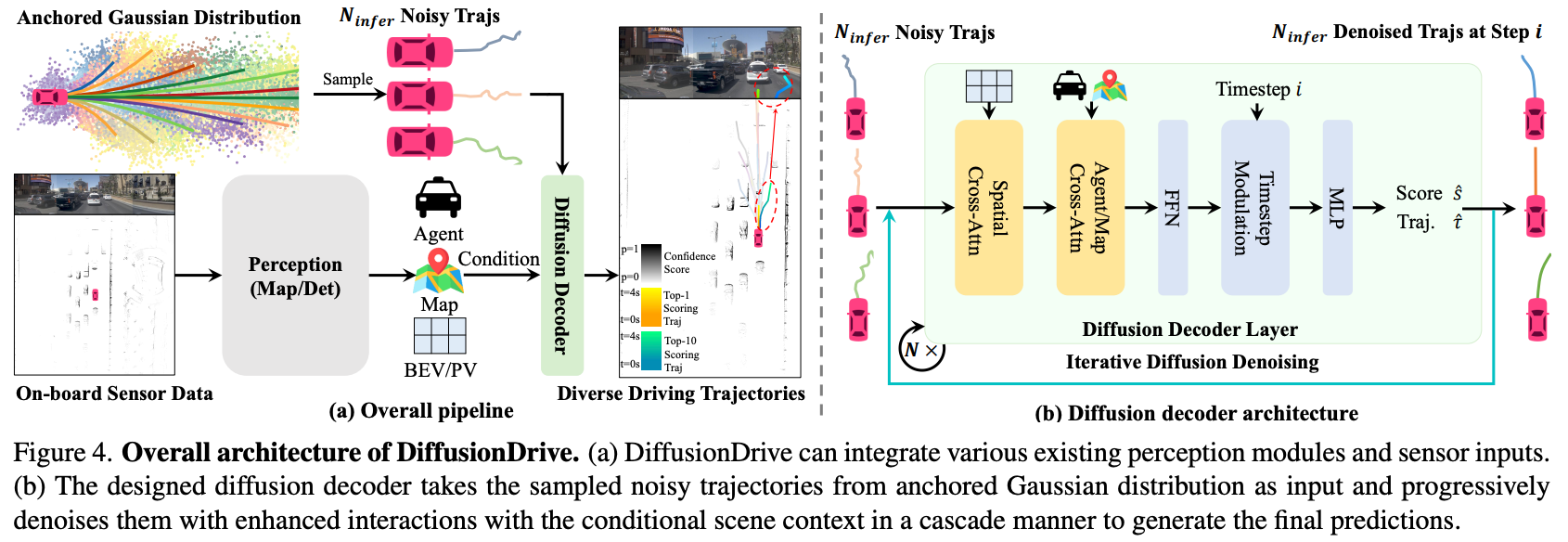
3.1 架构设计
DiffusionDrive 的扩散解码器是Transformer-based,包含三个关键交互模块:
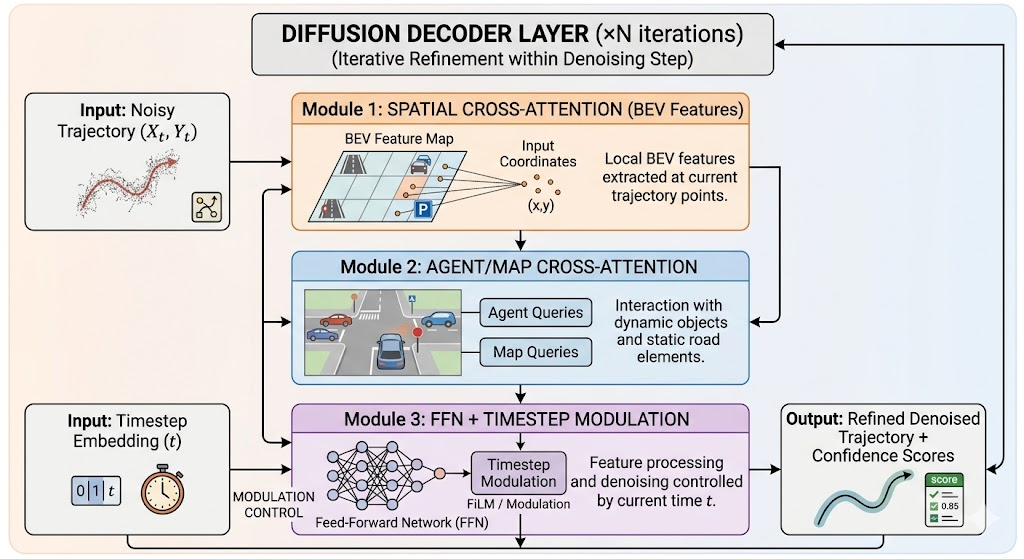
级联机制:堆叠 2 层解码器,第一层粗去噪,第二层精修。
3.2 源码中的关键实现
Diffusion Decoder Layer源码实现:
python
class CustomTransformerDecoderLayer(nn.Module):
def __init__(self, d_model=256):
super().__init__()
# 1. 轨迹内部自注意力
self.self_attn = nn.MultiheadAttention(d_model, 8)
# 2. 空间交叉注意力 (Grid Sample 采样)
# 源码中叫 cross_bev_attention
self.cross_bev_attention = GridSampleCrossBEVAttention(d_model)
# 3. 对象级交叉注意力 (与 Agent/Map Query 交互)
# 源码中叫 query_attention
self.query_attention = nn.MultiheadAttention(d_model, 8)
# 4. FFN 及时间/状态调制
self.ffn = FFN(d_model)
# 5. 任务解码头 (回归+分类)
# 源码中每一层都会初始化一个细化模块
self.task_decoder = DiffMotionPlanningRefinementModule(d_model)
def forward(self,
traj_feature, # 轨迹隐藏特征 (Query)
traj_points, # 当前轨迹物理坐标 (用于 Grid Sample)
bev_feature,
bev_spatial_shape,
agents_query,
ego_query,
time_embed,
status_encoding,
global_img=None):
# --- 第一部分:特征加工 (更新 traj_feature) ---
# 1. 模式间交互
traj_feature = self.self_attn(traj_feature, traj_feature, traj_feature)[0]
# 2. 从 BEV 中根据坐标"抠取"几何特征
traj_feature = self.cross_bev_attention(traj_feature, traj_points, bev_feature, bev_spatial_shape)
# 3. 与动态障碍物、地图语义特征交互
traj_feature = self.query_attention(traj_feature, agents_query, agents_query)[0]
# 4. 融合时间步和状态信息
# 这里的 time_embed 和 status_encoding 通常在进入 forward 前已经编码好
traj_feature = self.ffn(traj_feature + time_embed + status_encoding)
# --- 第二部分:物理输出 (由特征转为坐标) ---
# 5. 调用预测头,根据加工好的 traj_feature 预测这一层的偏移量和得分
poses_reg, poses_cls = self.task_decoder(traj_feature)
# 6. 级联修正:将偏移量加在传入的基准点上
poses_reg[..., :2] = poses_reg[..., :2] + traj_points
# 7. 返回结果,供外层 Decoder 更新下一层的采样点
return poses_reg, poses_clsdecoder 输出的不是绝对轨迹坐标,而是相对锚点的偏移量(offset),因此能够通过级联(Cascade)不断"精炼"轨迹,"级联"的动态过程源码如下:
python
#
class CustomTransformerDecoder(nn.Module):
# ... 省略初始化 ...
def forward(self,
traj_feature,
noisy_traj_points,
bev_feature,
bev_spatial_shape,
agents_query,
ego_query,
time_embed,
status_encoding,
global_img=None):
poses_reg_list = []
poses_cls_list = []
# 1. 初始轨迹点设为输入的"带噪轨迹点"
traj_points = noisy_traj_points
# 2. 级联核心:循环遍历每一层 Decoder Layer
for mod in self.layers:
# 3. 将当前的 traj_points 传给当前层 mod (即CustomTransformerDecoderLayer)进行修正
poses_reg, poses_cls = mod(traj_feature, traj_points, bev_feature, bev_spatial_shape, agents_query, ego_query, time_embed, status_encoding,global_img)
poses_reg_list.append(poses_reg)
poses_cls_list.append(poses_cls)
# 4. 【关键步骤】:将本层预测出的新坐标 poses_reg 作为下一层的基准坐标 traj_points
# 注意这里只取前两维 (x, y),并进行 detach 防止梯度在层间产生不必要的复杂传播逻辑(通常用于稳定训练)
traj_points = poses_reg[...,:2].clone().detach()
return poses_reg_list, poses_cls_list四、损失函数
4.1 损失函数公式
DiffusionDrive 的损失函数由 轨迹重建损失 和 分类损失两部分加权构成:
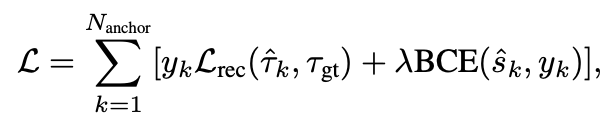
重建损失(Reconstruction Loss)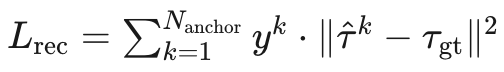 ,其中
,其中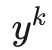 是 one-hot 标签:只有距离 GT 最近的锚点 被设为 1,其余为 0;二分类损失 (BCE Loss)
是 one-hot 标签:只有距离 GT 最近的锚点 被设为 1,其余为 0;二分类损失 (BCE Loss) 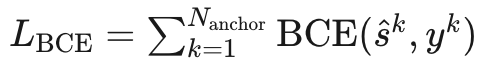 用于训练锚点得分预测头,让模型学会判断哪个锚点最可能对应当前场景。
用于训练锚点得分预测头,让模型学会判断哪个锚点最可能对应当前场景。
4.2 损失函数源码实现
python
import torch
import torch.nn as nn
import torch.nn.functional as F
class DiffusionDriveLoss(nn.Module):
def __init__(self, lambda_cls=1.0):
super().__init__()
# lambda_cls 对应论文公式中的 lambda,用于平衡回归与分类的权重
self.lambda_cls = lambda_cls
def get_target_mode(self, plan_anchor, gt_trajectory):
"""
标签分配模块 (Label Assignment):
计算哪一个锚点最接近专家的 Ground Truth 轨迹。
对应论文中寻找 y_k = 1 的那个"胜者 (Winner)"。
"""
# plan_anchor: [B, 20, T, 2]
# gt_trajectory: [B, T, 2] -> 扩展为 [B, 1, T, 2] 以便广播计算
gt_expanded = gt_trajectory.unsqueeze(1)
# 计算所有 20 个锚点与 GT 之间的 L2 距离 (或 L1)
# 求和维度为时间和坐标轴 (-1, -2)
distances = torch.norm(plan_anchor - gt_expanded, dim=-1).sum(dim=-1) # [B, 20]
# 选出距离最小的锚点索引作为目标类别
best_mode_idx = torch.argmin(distances, dim=-1) # [B]
return best_mode_idx
def forward(self, poses_reg_list, poses_cls_list, gt_trajectory, plan_anchor):
"""
poses_reg_list: 解码器级联输出的轨迹列表, 长度为级联层数 (如 2)。元素 shape: [B, 20, T, 2]
poses_cls_list: 解码器级联输出的得分列表。元素 shape: [B, 20]
gt_trajectory: 真实的专家轨迹 [B, T, 2]
"""
B = gt_trajectory.shape[0]
num_layers = len(poses_reg_list)
total_loss = 0.0
# --- 第一步:标签分配 (找到公式里的 y_k=1 对应的索引) ---
best_mode_idx = self.get_target_mode(plan_anchor, gt_trajectory)
batch_indices = torch.arange(B, device=gt_trajectory.device)
# --- 第二步:多级监督 (遍历每一层 Decoder 计算 Loss) ---
for i in range(num_layers):
# 取出当前层输出的 20 条轨迹和 20 个分数
pred_trajs = poses_reg_list[i] # [B, 20, T, 2]
pred_scores = poses_cls_list[i] # [B, 20]
# ----------------------------------------------------
# 1. 轨迹重建损失 L_rec (仅对正样本计算)
# 对应公式:y_k * L1(hat_tau, tau_gt)
# ----------------------------------------------------
# 只提取得分最高/最匹配的那一条轨迹 (Winner-Takes-All)
best_pred_traj = pred_trajs[batch_indices, best_mode_idx] # [B, T, 2]
# 计算 L1 损失
loss_reg = F.l1_loss(best_pred_traj, gt_trajectory)
# ----------------------------------------------------
# 2. 意图分类损失 BCE (对所有样本计算)
# 对应公式:lambda * BCE(hat_s_k, y_k)
# ----------------------------------------------------
# 构造分类 Target:除了 best_mode_idx 对应位置是 1,其余全为 0
target_scores = torch.zeros_like(pred_scores)
target_scores[batch_indices, best_mode_idx] = 1.0
# 计算二元交叉熵损失 (BCEWithLogits 内部自带 Sigmoid,数值更稳定)
loss_cls = F.binary_cross_entropy_with_logits(pred_scores, target_scores)
# ----------------------------------------------------
# 3. 损失汇总
# ----------------------------------------------------
layer_loss = loss_reg + self.lambda_cls * loss_cls
# 将每一层的损失累加 (这就是 Cascade 架构加速收敛的秘诀)
total_loss += layer_loss
# 最终返回平均 loss
return total_loss / num_layers五、推理:2 步实时生成
在DiffusionDrive 之所以能够实现"实时生成",核心在于截断扩散(Truncated Diffusion)和极少步数(通常是 2 步)的 DDIM 采样循环:
python
import torch
import torch.nn as nn
class TrajectoryHead(nn.Module):
# ... 初始化代码略 ...
@torch.no_grad()
def predict(self, bev_feat, bev_spatial_shape, agents_query, ego_query, status_encoding):
"""
推理阶段:2步实时生成轨迹
"""
B = bev_feat.shape[0]
# ====================================================
# 第一阶段:截断初始化 (Truncated Initialization)
# ====================================================
# 1. 定义推理时间步。这里直接硬编码为 [25, 0],即只跑 2 步!
# 相比于标准扩散模型的 [1000, 999... 0],这里极大地压缩了计算量。
timesteps = [25, 0]
# 2. 加载 20 个先验锚点 (Anchors)
anchors = self.plan_anchor.unsqueeze(0).repeat(B, 1, 1, 1)
# 3. 截断加噪:不从纯噪声开始,而是给锚点加上 t=25 时刻的微量噪声
noise = torch.randn_like(anchors)
t_start = torch.full((B,), timesteps[0], device=anchors.device).long()
# 此时的 noisy_traj 就是 x_25 (起始状态)
noisy_traj = self.noise_scheduler.add_noise(anchors, noise, t_start)
# 初始化隐藏特征
traj_feature = self.init_feature(bev_feat, agents_query)
# ====================================================
# 第二阶段:2 步 DDIM 去噪循环 (2-Step Denoising Loop)
# ====================================================
# 循环只会执行两次:i=0 (t=25), i=1 (t=0)
for i, t in enumerate(timesteps):
# 将离散时间步 t 转为 Tensor 并进行 MLP 编码
t_tensor = torch.full((B,), t, device=anchors.device).long()
time_embed = self.time_mlp(t_tensor)
# --- 核心算力消耗点:调用级联解码器 ---
# 内部会执行 2 层 Cascade Transformer Decoder
poses_reg_list, poses_cls_list = self.diffusion_decoder(
traj_feature=traj_feature,
noisy_traj_points=noisy_traj, # 当前物理坐标
bev_feature=bev_feat,
bev_spatial_shape=bev_spatial_shape,
agents_query=agents_query,
ego_query=ego_query,
time_embed=time_embed,
status_encoding=status_encoding
)
# 提取最后一次级联层输出的干净轨迹预测 (pred_x0) 和得分
pred_x0 = poses_reg_list[-1]
pred_scores = poses_cls_list[-1]
# --- DDIM 调度器步进 ---
if i < len(timesteps) - 1:
# 当 i=0 (t=25) 时,利用预测的 x0 和扩散公式,计算下一步 t=0 的起点
# 将结果覆盖 noisy_traj,供下一次循环使用
noisy_traj = self.noise_scheduler.step(
model_output=pred_x0,
timestep=t,
sample=noisy_traj
).prev_sample
else:
# 当 i=1 (t=0) 时,最后一步直接将网络预测的 pred_x0 作为最终轨迹
final_traj = pred_x0
# 返回 20 条精炼后的轨迹和对应得分
return final_traj, pred_scores六、实验结果与定性分析
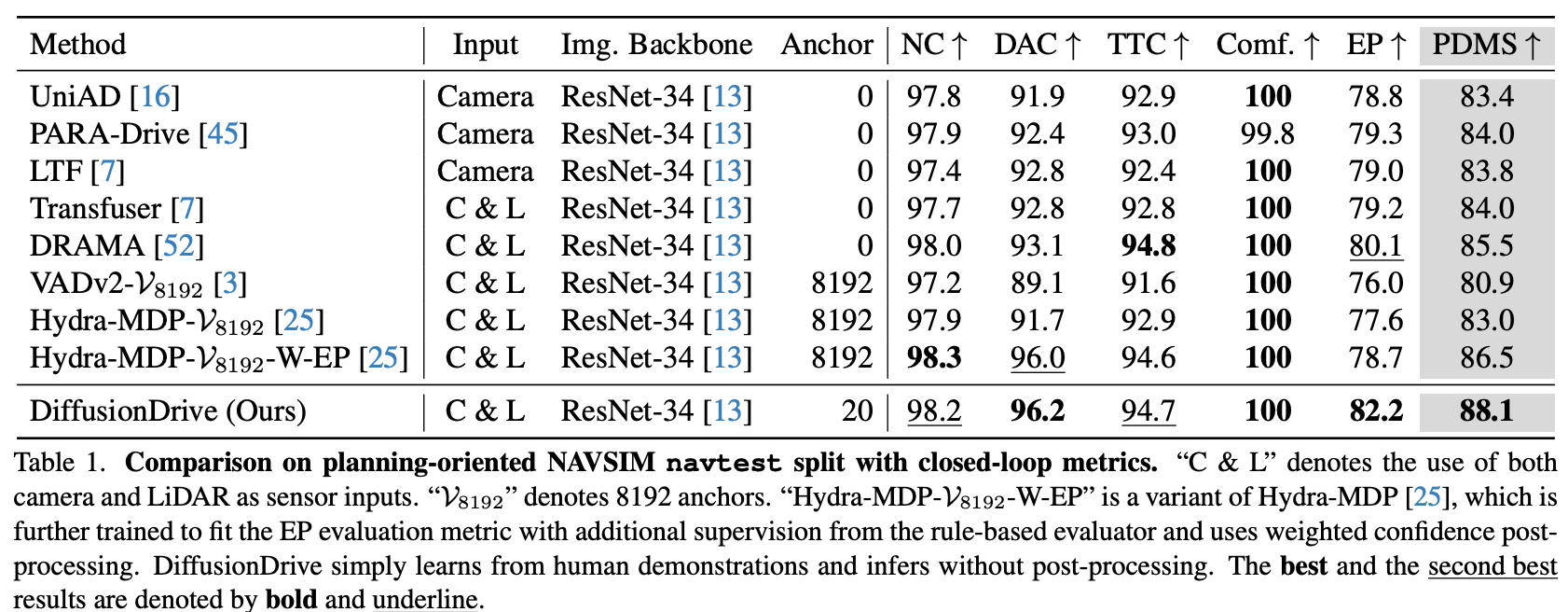
6.1 NAVSIM 基准
6.2 模式多样性 (Mode Diversity)
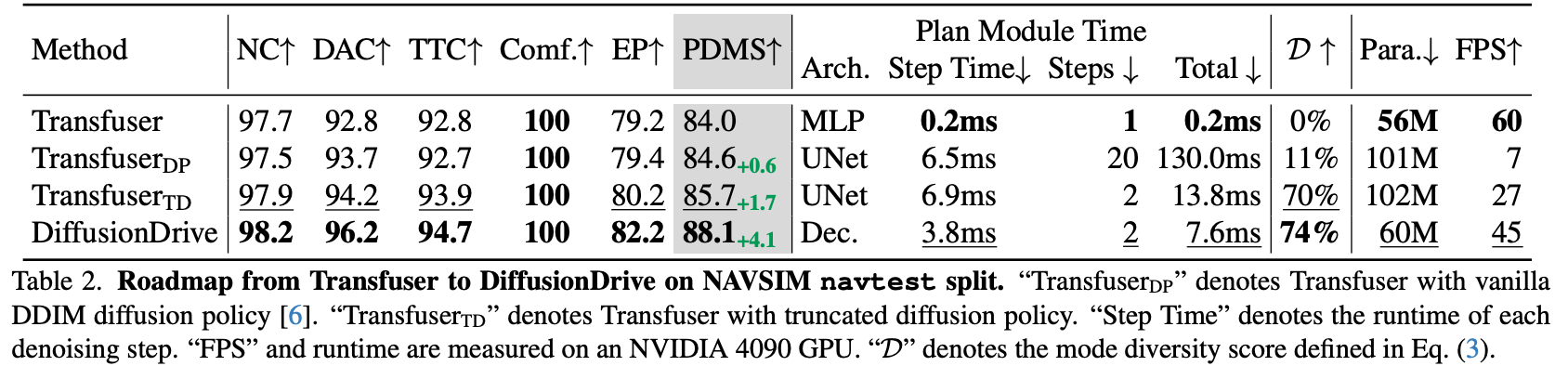 DiffusionDrive 定义了一个多样性指标 D :
DiffusionDrive 定义了一个多样性指标 D :
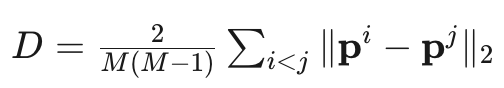
相比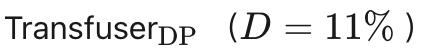 ,DiffusionDrive 达到 74%,证明锚点先验有效保留了多模态性。
,DiffusionDrive 达到 74%,证明锚点先验有效保留了多模态性。
6.3 定性结果
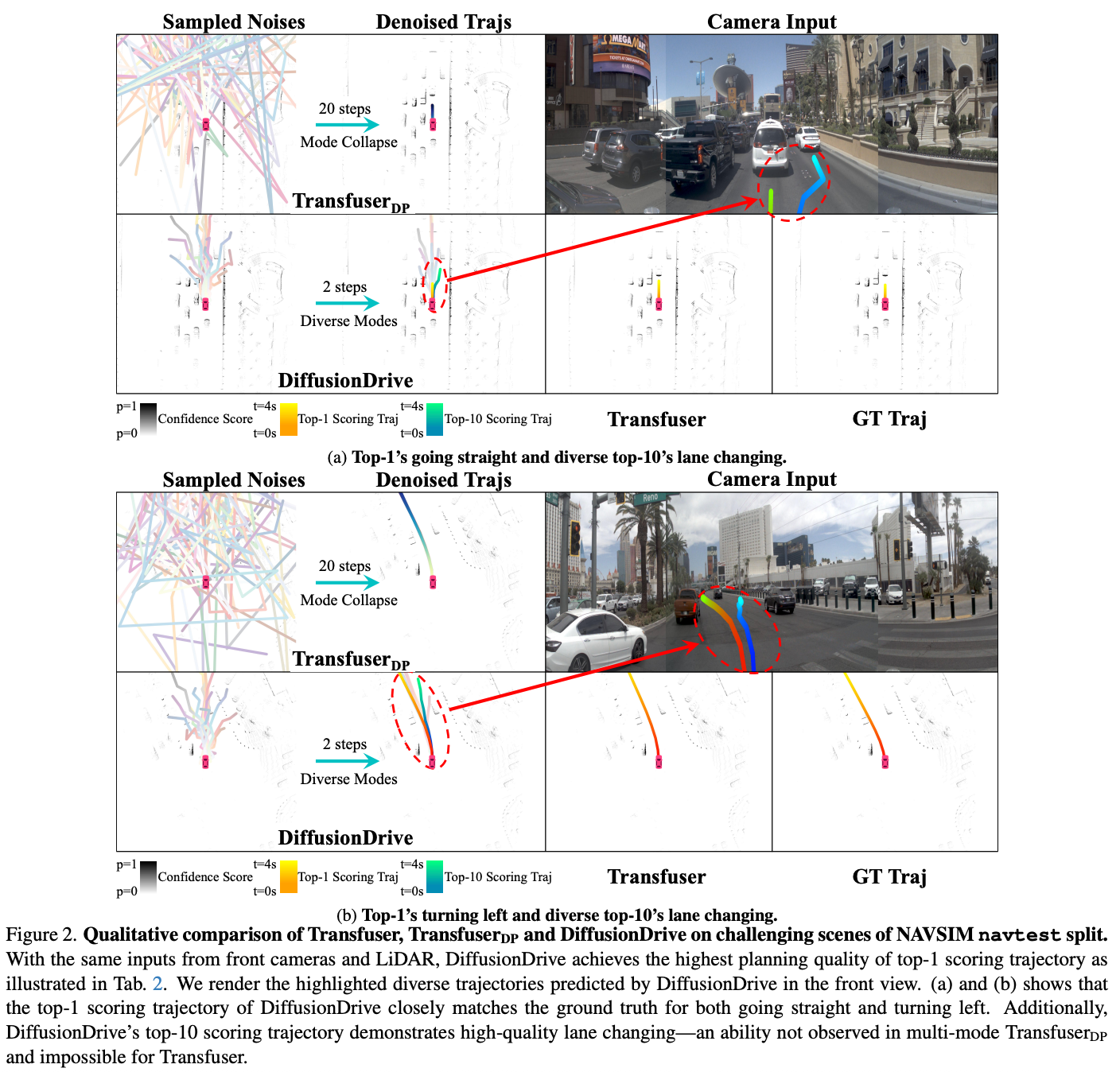 从论文中的可视化可以看到:
从论文中的可视化可以看到:
-
直行场景:Top-1 轨迹跟随前车,Top-10 轨迹尝试变道超车
-
左转场景:多条轨迹动态调整,有的保守跟随、有的激进变道
-
多模态路口:同时生成"直行"和"左转"两种意图的轨迹
七、局限性
正如 DiffusionDriveV2 所指出的:"DiffusionDrive 的模仿学习范式导致不完整的多模态监督------每帧只有一个正样本,其余锚点缺乏轨迹级约束,生成大量低质量轨迹。"
这导致:
-
Top-1 轨迹质量高,但 Top-10 中混杂碰撞轨迹
-
过度依赖下游选择器,而选择器参数量小、泛化弱
八、总结
DiffusionDrive 是端到端自动驾驶中扩散模型落地的里程碑工作,其核心贡献可以概括为:
| 维度 | 贡献 |
|---|---|
| 算法 | 截断扩散策略 + 锚定高斯分布,首次实现 2 步实时生成 |
| 架构 | 级联 Transformer 解码器 + Trajectory-guided Feature Sampling (轨迹引导特征采样) |
| 工程 | 与 Transfuser 完全兼容,即插即用 |
| 性能 | NAVSIM 88.1 PDMS,45 FPS,CVPR 2025 Highlight |
参考链接: