目录
- 前言
- 一、序列式容器和关联式容器
- [二、set 系列的使用](#二、set 系列的使用)
-
- [2.1 set 类的介绍](#2.1 set 类的介绍)
- [2.2 set 的构造,迭代器,插入](#2.2 set 的构造,迭代器,插入)
- [2.3 删除和查找](#2.3 删除和查找)
- [2.4 swap 和 count](#2.4 swap 和 count)
- [2.3 lower_bound和upper_bound](#2.3 lower_bound和upper_bound)
- 三、multiset
-
- [3.1 erase 和 find](#3.1 erase 和 find)
- [3.2 equal_range 和 pair](#3.2 equal_range 和 pair)
- 四、set的题目应用
-
- [4.1 142.环形链表 ||](#4.1 142.环形链表 ||)
- [4.2 两个数组的交集](#4.2 两个数组的交集)
- 五、云同步里的交集与差集
- 结语


🎬 云泽Q :个人主页
🔥 专栏传送入口 : 《C语言》《数据结构》《C++》《Linux》《蓝桥杯系列》
⛺️遇见安然遇见你,不负代码不负卿~
前言
大家好啊,我是云泽Q,欢迎阅读我的文章,一名热爱计算机技术的在校大学生,喜欢在课余时间做一些计算机技术的总结性文章,希望我的文章能为你解答困惑~
一、序列式容器和关联式容器
前面已经写过 STL 中的部分容器,例如 string、vector、list、deque、array、forward_list 等,这些容器被统一归类为序列式容器。
序列式容器的核心特征是逻辑结构为线性序列 ,容器中元素的存储、保存和访问规则,完全由元素在容器中的物理存储位置决定,元素之间本身不存在内在的依赖、映射或排序关联。简单来说,序列式容器就像我们日常整理的 "清单" 或 "排队队伍",每个元素都有明确的 "位置序号",即便交换两个元素的位置,容器的整体线性逻辑结构也不会改变,依然属于序列式容器。
在实际使用中,序列式容器的元素会严格按照我们插入时的顺序保存,访问元素的核心方式也是基于 "位置":比如 vector 支持通过下标直接定位(如vec2获取第 3 个元素),list 则通过迭代器按顺序遍历访问,这都是典型的 "按存储位置访问" 的特征。
关联式容器也是 STL 中专门用于存储数据的容器类型,它与序列式容器的核心区别在于逻辑结构通常为非线性结构 (如树结构、哈希表结构),容器中元素之间存在由关键字(key) 定义的紧密关联关系。正因为这种关联关系由关键字主导,关联式容器中的元素无法像序列式容器那样随意交换位置 ------ 一旦交换,关键字与容器底层结构的对应逻辑会被打破,进而导致容器的查找、排序等核心功能失效。
在保存和访问规则上,关联式容器完全围绕关键字展开,而非元素的物理位置。我们无法像操作序列式容器那样,通过 "第几个元素" 来获取数据,只能通过指定的关键字,精准匹配到对应的元素(或键值对)。STL 中的关联式容器主要分为两大核心系列:
- 有序关联式容器:map/set 系列;
- 无序关联式容器:unordered_map/unordered_set 系列。
本文章重点讲解的有序关联式容器 map 和 set,它们的底层实现结构都是红黑树------ 红黑树是一种自平衡的二叉搜索树,既保留了二叉搜索树的高效查找特性,又通过自平衡机制避免了树结构退化成链表,能保证插入、删除、查找操作的时间复杂度稳定在O(logn)。
从具体适用场景来看,set 是专为纯关键字(key)搜索场景设计的容器结构:它内部仅存储关键字本身,且严格保证关键字的唯一性(不允许重复)。例如我们需要存储 "图书馆的图书编号",并频繁判断 "某本图书编号是否已入库",使用 set 就能以极高的效率完成查找操作。
而 map 则是为关键字 - 值(key/value)键值对搜索场景设计的容器结构:它内部存储的是成对的 key 和 value,其中 key 具有唯一性,通过这个唯一的 key,我们可以快速找到对应的 value。例如我们需要存储 "员工工号(key)- 员工部门(value)" 的对应关系,想通过工号快速查询某员工所属部门,map 就是最贴合该场景的选择。
二、set 系列的使用
2.1 set 类的介绍

- set的声明如下,T就是set底层关键字的类型
- set默认要求T支持小于比较,如果不支持或者想按自己的需求走可以自行实现仿函数传给第二个模版参数
- set底层存储数据的内存是从空间配置器申请的,如果需要可以自己实现内存池,传给第三个参数。
- 一般情况下,我们都不需要传后两个模版参数。
- set底层是用红黑树实现,增删查效率是O(logN),迭代器遍历是走的搜索树的中序,所以是有序的。
2.2 set 的构造,迭代器,插入
set构造的接口如下:
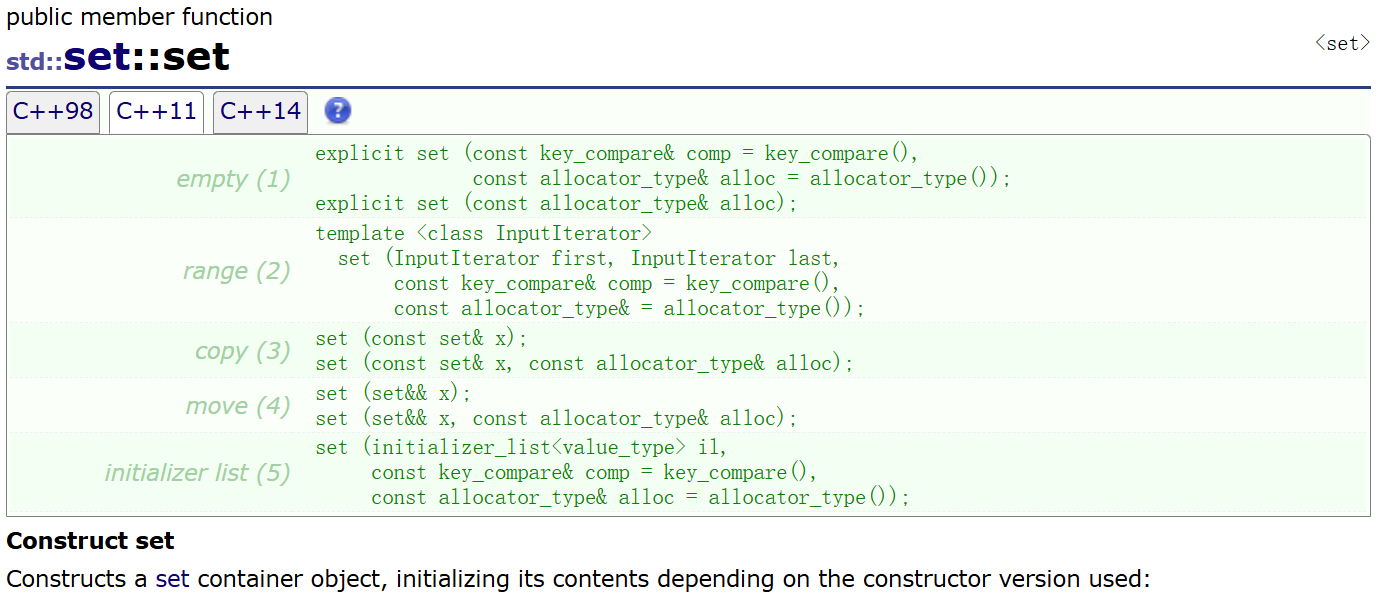
set的支持正向和反向迭代遍历,遍历默认按升序顺序,因为底层是二又搜索树,迭代器遍历走的中序;支持迭代器就意味着支持范围for,set的iterator和const_iterator都不支持迭代器修改数据,修改关键字数据,破坏了底层搜索树的结构。
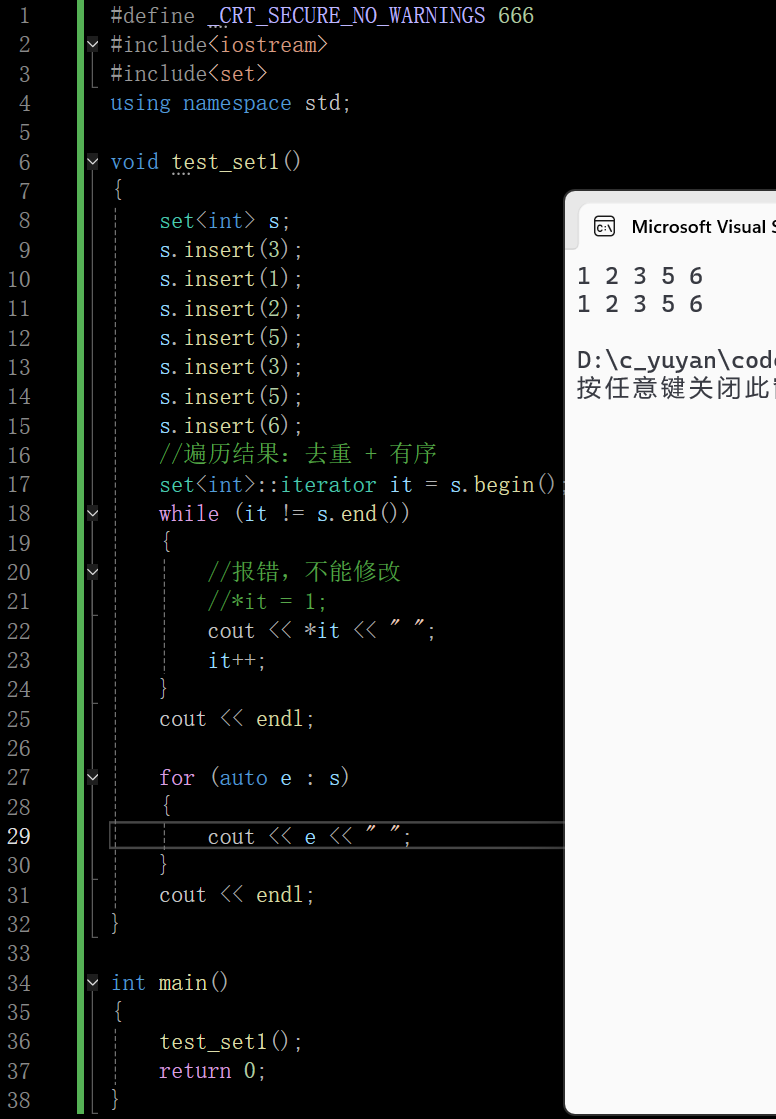
补充一个点:set的拷贝构造和赋值是一个深拷贝,并且拷贝的代价极大(要拷贝一整颗数)。且set的删除是存在迭代器失效的问题的,要小心
2.3 删除和查找
可以通过返回值来判断有没有删除成功,size_type就是size_t,删成功返回1,没有删除成功返回0
set为什么不用 bool,而用当前的返回值,核心原因是为了兼容multiset
set 因为 key 唯一,删除时要么删 1 个(返回 1),要么没删(返回 0),看起来用 bool 也能表示(1→true,0→false)。但 STL 的设计追求接口统一性:
- multiset 是 set 的 "兄弟容器",允许同一个 key 存在多个元素(比如存储成绩时,多个学生考 80 分);
- 对 multiset.erase(80),可能删除多个元素(所有考 80 分的),此时返回 "删除的个数"(比如 3)比返回 bool(true)更有意义 ------ 你能知道到底删了多少个,而不只是 "删没删";
- 为了让 set 和 multiset 的接口一致,set::erase(key) 也统一返回 size_t,而不是单独给 set 设计一个返回 bool 的版本(增加复杂度)。
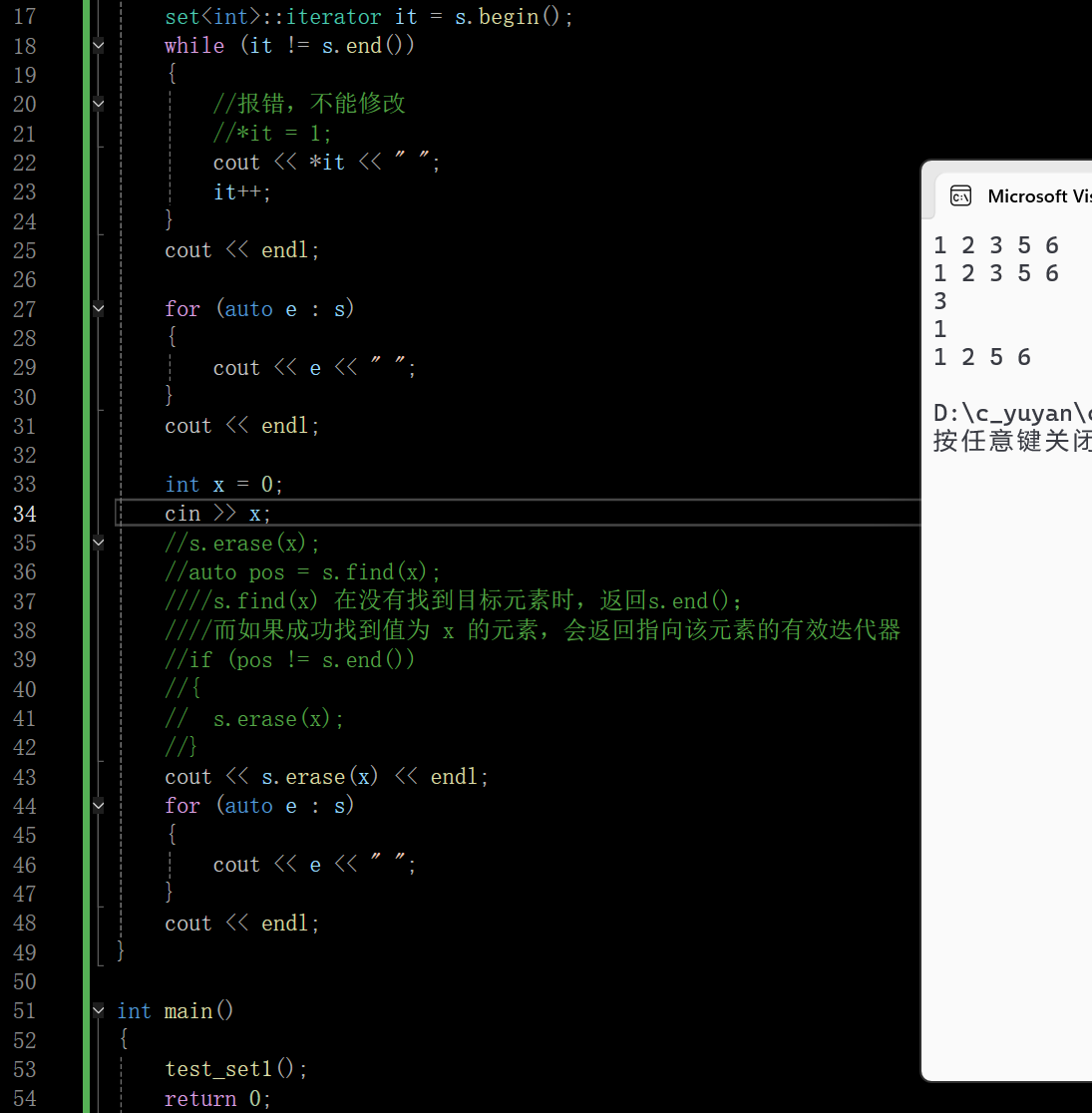
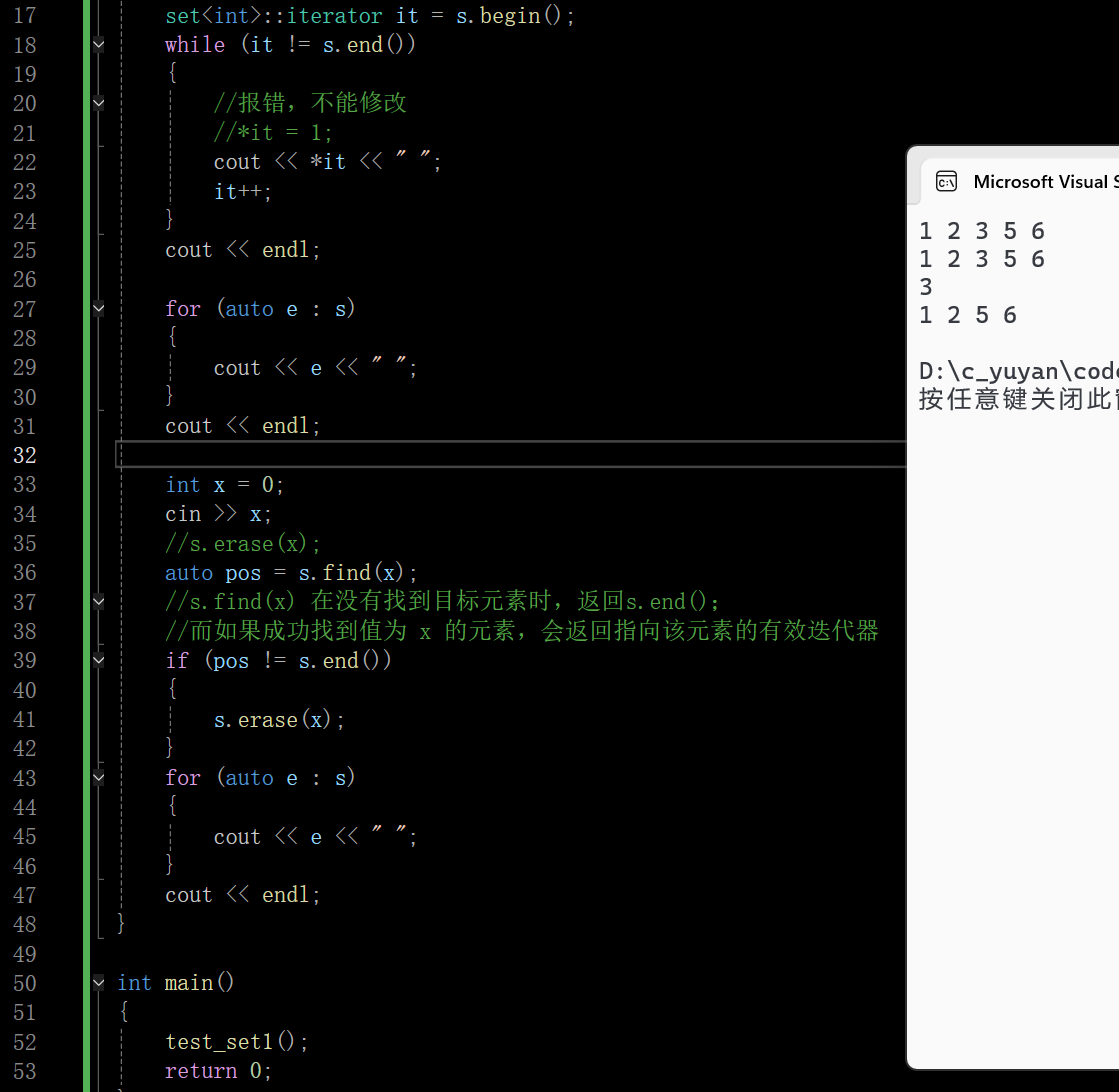
2.4 swap 和 count

set容器底层是一颗树,所以swap就是交换两棵树根结点的指针
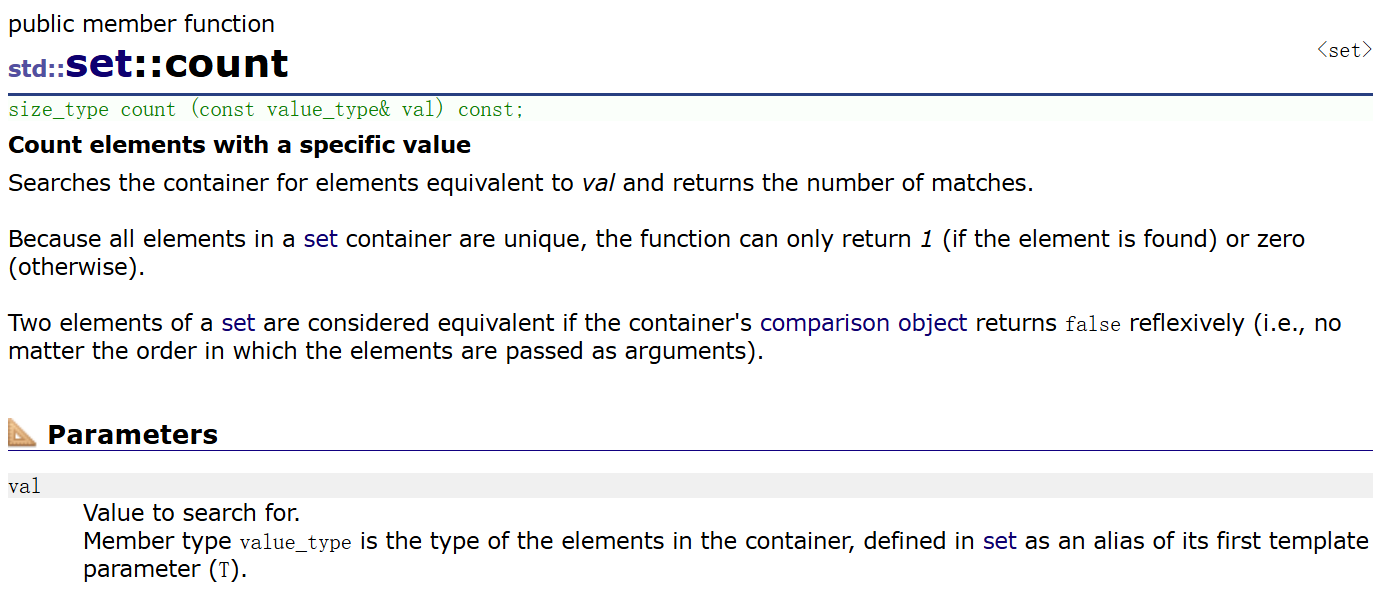
count是返回value中的值有几个,对于set而言返回值就是1或0了,这个接口的返回值这样设计就是为了和multiset保持接口统一性,且count查找元素在不在也很方便
cpp
if(s.count(x))
{
}2.3 lower_bound和upper_bound
std::set 是有序、无重复的关联容器,lower_bound 和 upper_bound 是它的两个核心查找接口,利用有序性实现 O (log n) 的高效查找:
- lower_bound(val):返回指向容器中第一个不小于(≥)val 的元素的迭代器。
- upper_bound(val):返回指向容器中第一个大于(>)val 的元素的迭代器。
如果容器中不存在满足条件的元素,两个函数都会返回 set::end()(尾后迭代器)。
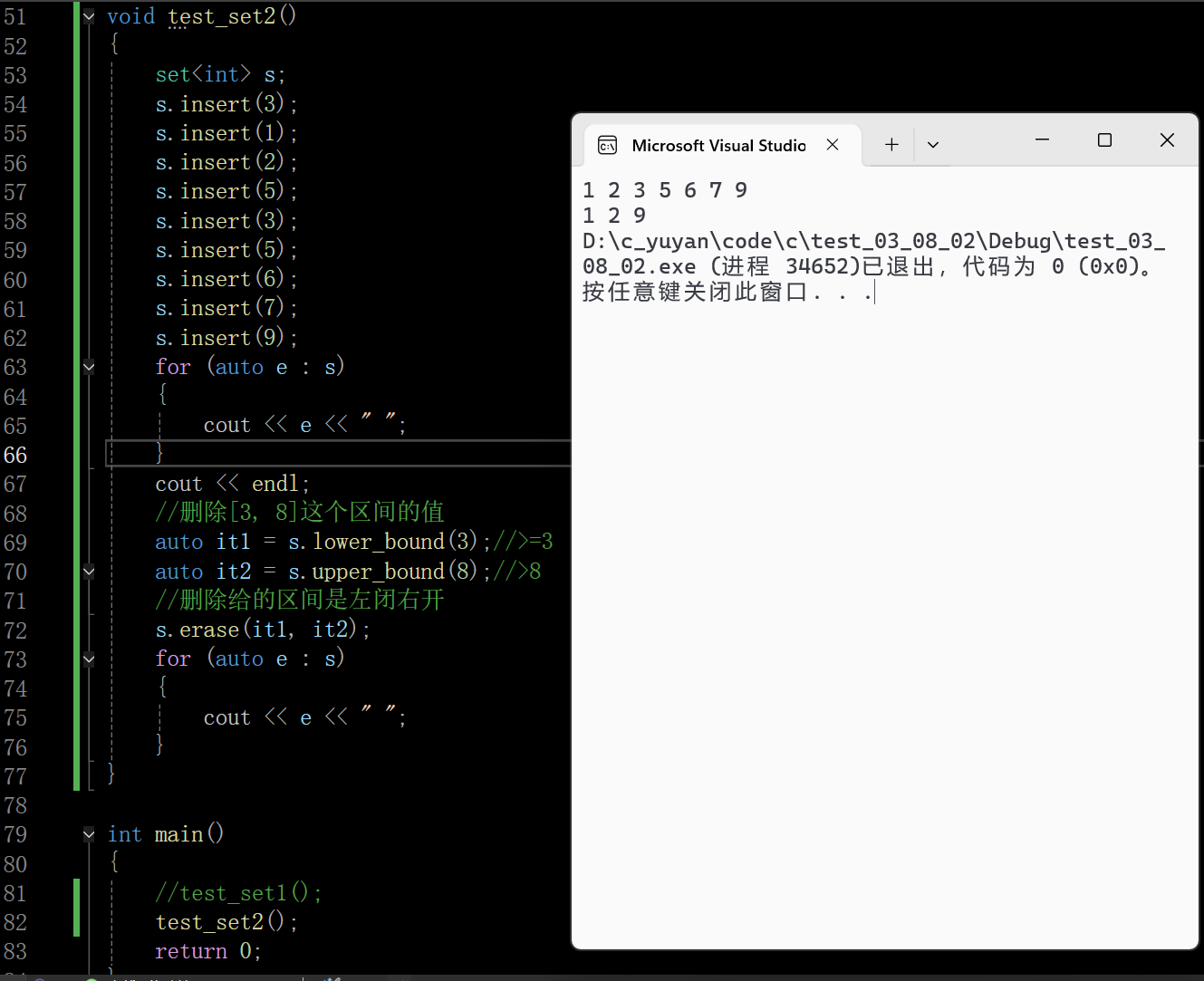
- auto it1 = s.lower_bound(3);
查找第一个 ≥3 的元素,即 3,it1 指向元素 3。 - auto it2 = s.upper_bound(8);
查找第一个 >8 的元素,即 9,it2 指向元素 9。 - s.erase(it1, it2);
erase 接受左闭右开区间 [it1, it2),因此删除的是 3、5、6、7,剩余集合为:{1, 2, 9}。
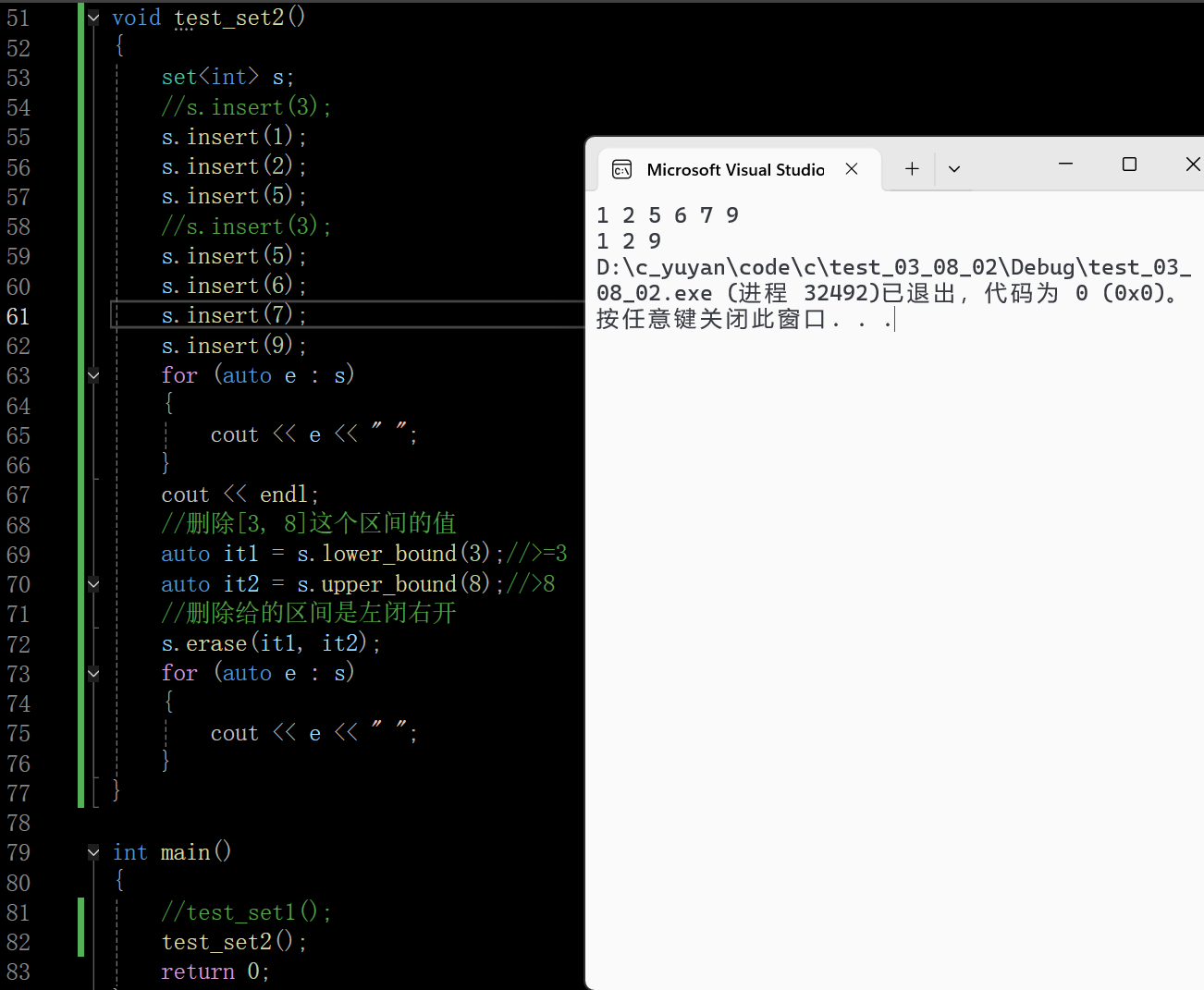
- auto it1 = s.lower_bound(3);
查找第一个 ≥3 的元素,集合中比 3 大的最小元素是 5,it1 指向元素 5。 - auto it2 = s.upper_bound(8);
查找第一个 >8 的元素,即 9,it2 指向元素 9。 - s.erase(it1, it2);
删除区间 [5, 9),即删除 5、6、7,剩余集合为:{1, 2, 9}。
三、multiset
multiset不需要包单独的头文件,其和set在同一个头文件内
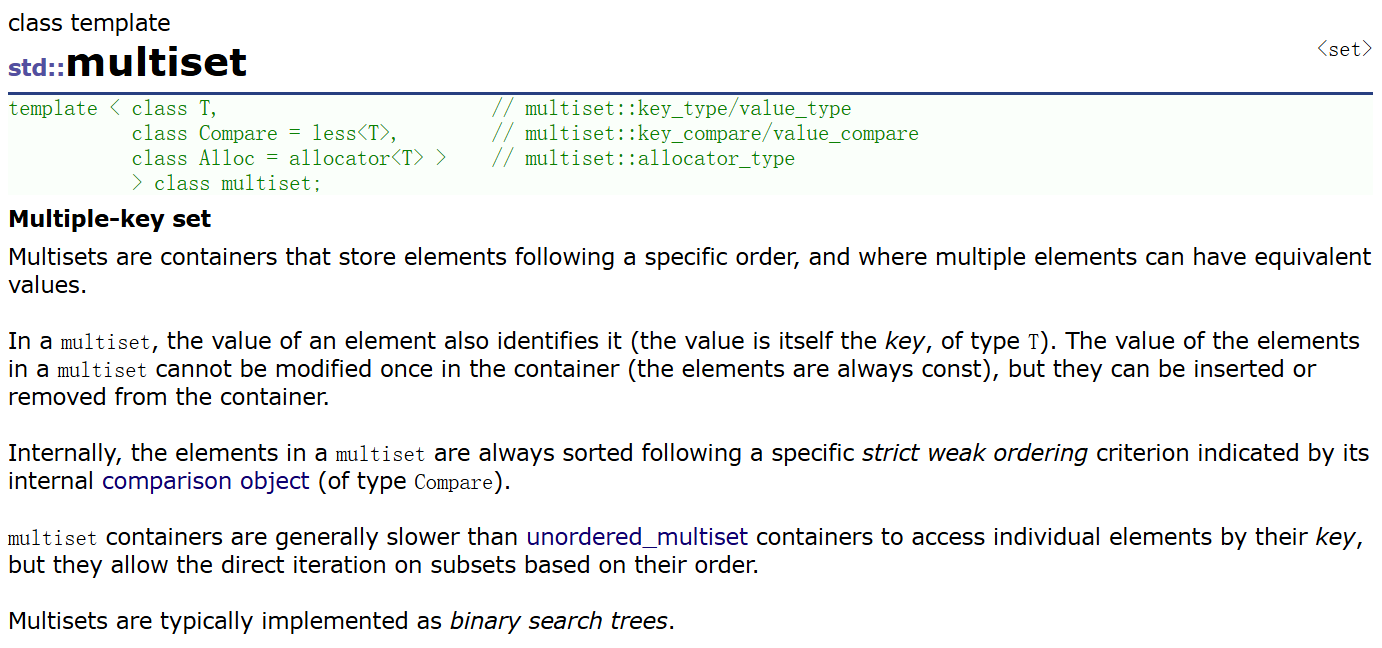
可以看到该容器会保留相同的值
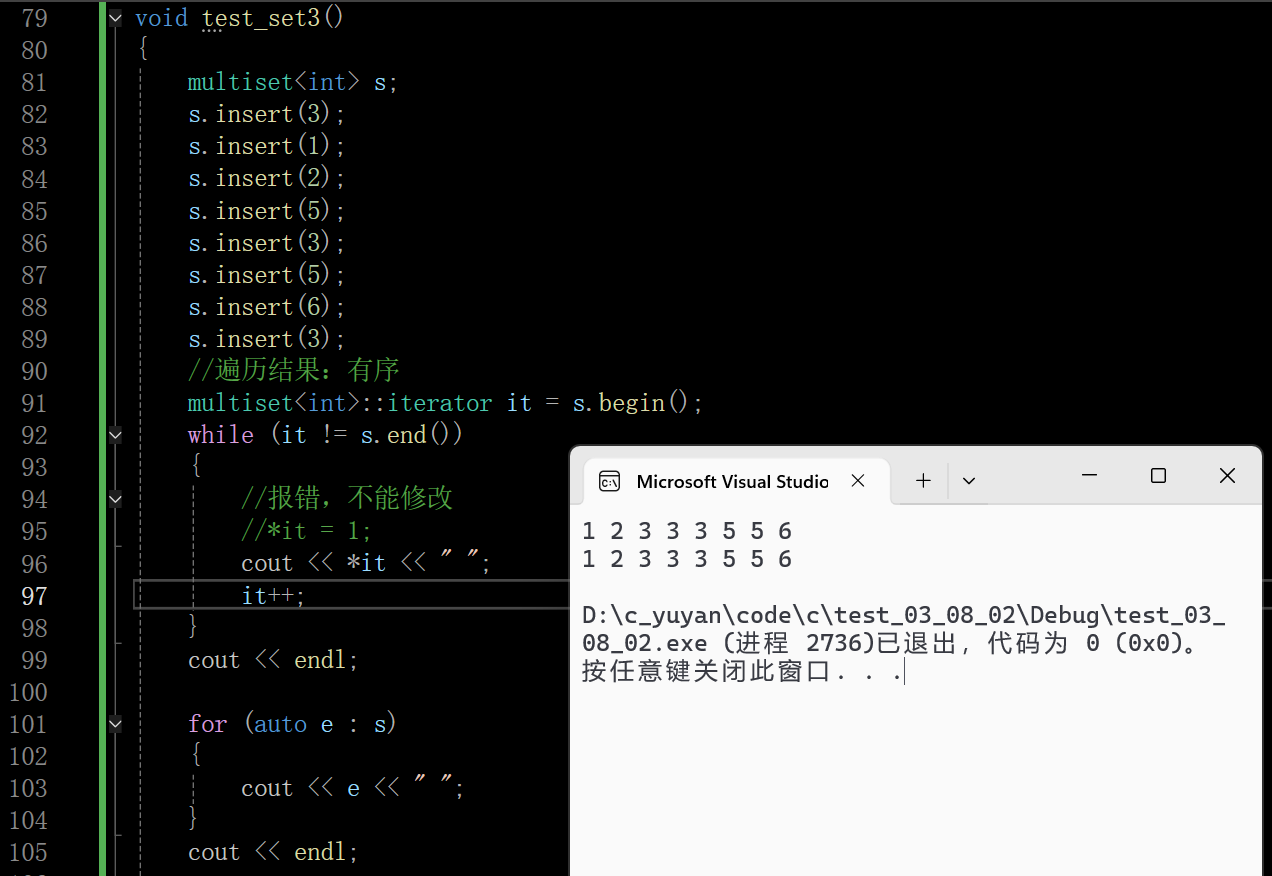
multiset和set很多接口都一样,唯独有两个接口需要注意:
3.1 erase 和 find
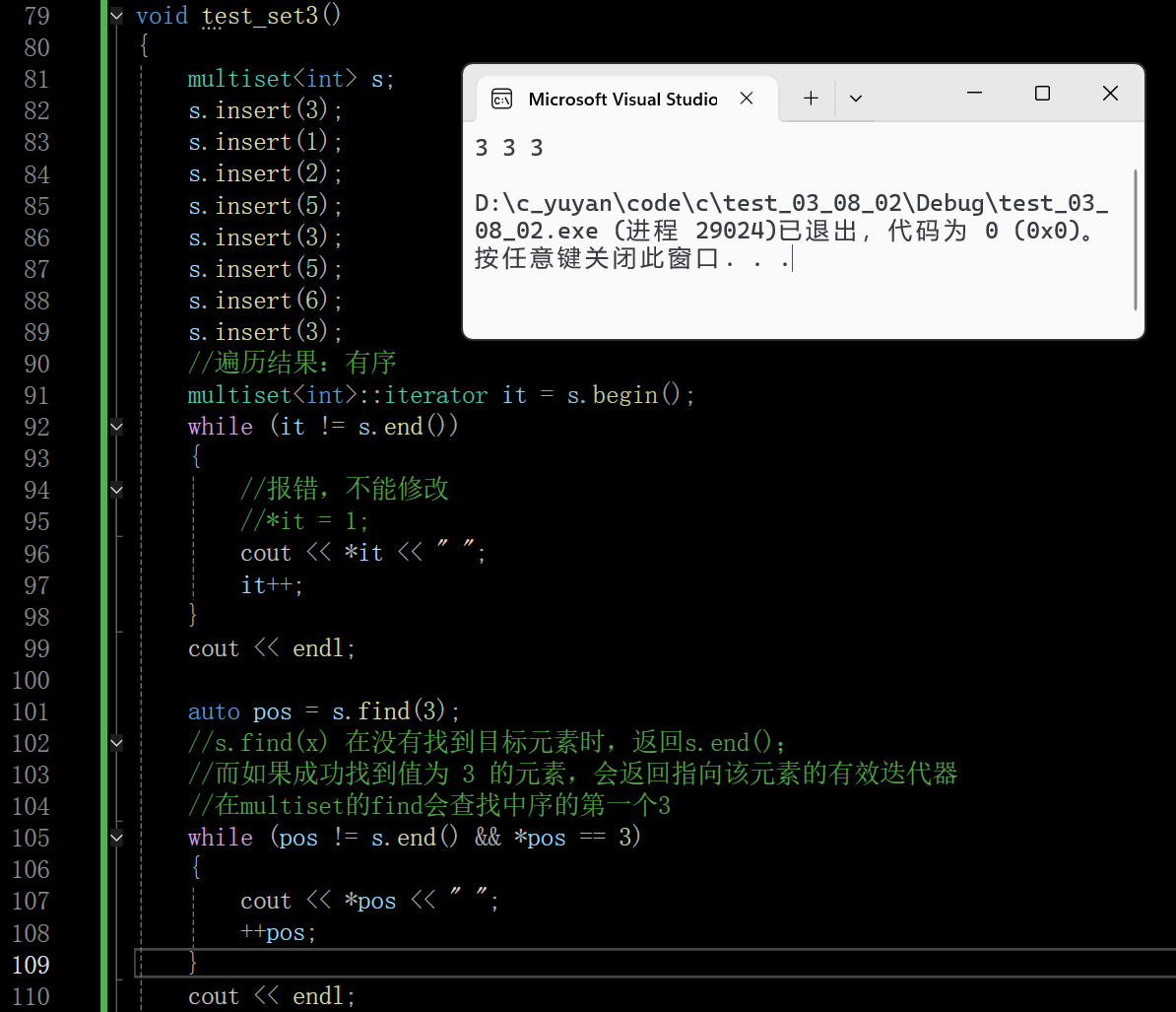
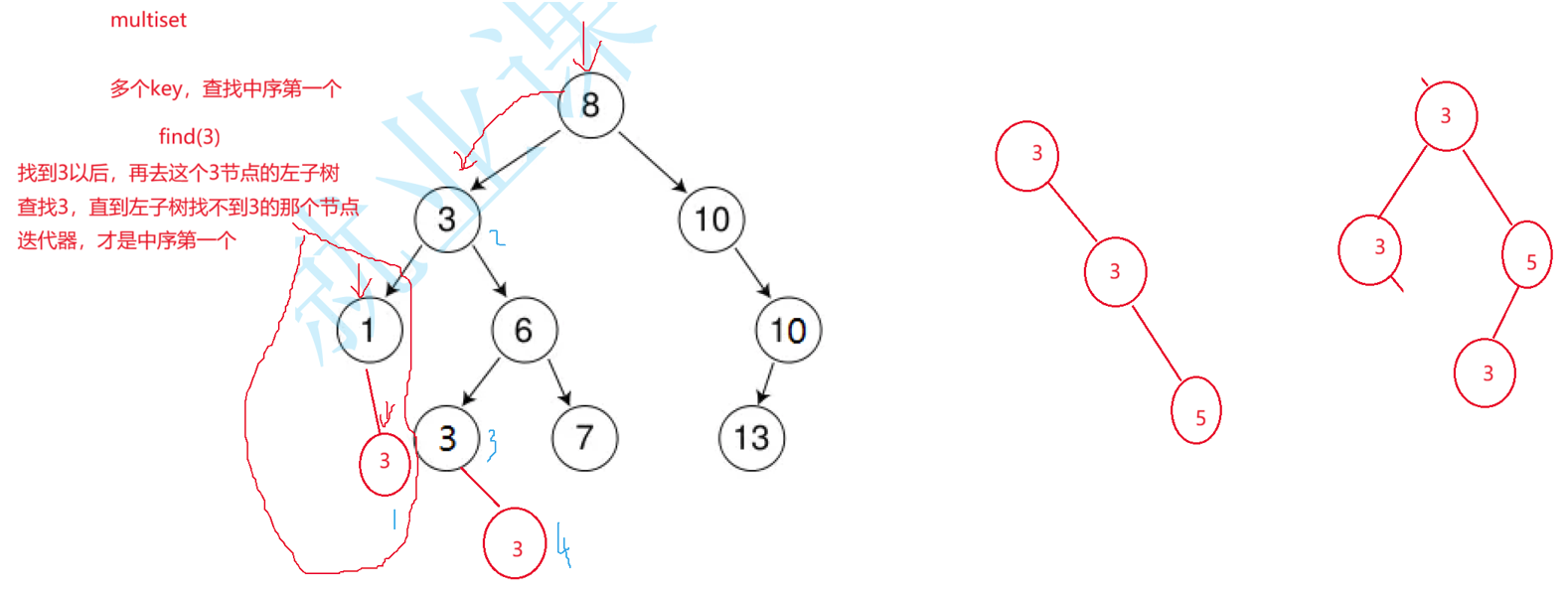
下面从底层的原理看一下find接口查找的第一个3是哪个,这里假设相等的值都插入在右边,这个3还有可能插入在1的右边(这涉及一个平衡树的旋转问题,后面我会专门出一篇文章来写)
multiset 底层是红黑树 (有序平衡二叉搜索树),中序遍历结果为升序。find(key) 会找中序第一个等于 key 的元素,查找流程如下:
- 从根节点 8 开始:3 < 8 → 进入左子树(节点 3)。
- 节点 3 的值等于 3,但为了找 "中序第一个",不能停止,继续进入它的左子树(节点 1)。
- 节点 1 的值是 1,3 > 1 → 进入它的右子树(节点 3a,即图中 1 的右孩子 3)。
- 节点 3a 的值等于 3,再进入它的左子树,左子树为空,无法继续查找。
- 此时节点 3a 就是中序遍历中第一个出现的 3,find(3) 返回指向它的迭代器。
由于multiset 是有序容器,中序遍历严格升序,这样设计之后,相同 key 的元素在中序遍历中必然连续。且返回中序第一个相同 key 的迭代器后,用户可以通过 ++ 迭代器,依次访问所有相同 key 的元素(直到遇到更大的 key),比如代码中 while (pos != s.end() && *pos == 3) 就能遍历所有 3。
而迭代器 ++ 的本质就是沿着红黑树的 中序遍历路径继续往下走,依次访问后续节点 ,而相同的 3 之所以能被连续找到,正是因为它们在中序遍历中是连续排列的。
- 当前迭代器指向 3a(1 的右孩子):
3a 的右子树为空,回溯到父节点 1,1 的右子树已遍历完,继续回溯到父节点 3(根节点 3),中序下一个节点就是 3(第二个 3)。 - 迭代器指向 3(根节点 3):
3 的右子树是 6 的子树,进入 6 的左子树(节点 3b,即图中 6 的左孩子 3),中序下一个节点就是 3b(第三个 3)。 - 迭代器指向 3b:
3b的右子树还有一个3(3c),中序下一个节点就是3c,此时回溯到根节点6,此时*pos变为6(大于3),循环结束。
这三个 3 在中序路径上是紧挨着 的,所以:
从 find(3) 拿到第一个 3a 后,++ 按中序规则直接跳到紧邻的下一个节点(根 3);再 ++,继续跳到紧邻的下一个节点(3b);直到 ++ 到 6(比 3 大的节点),循环终止。
multiset::erase 有三种重载:删单个迭代器 (删 1 个元素)、删区间 (删批量元素)、删键值 (删所有相同键值,返回删除数);
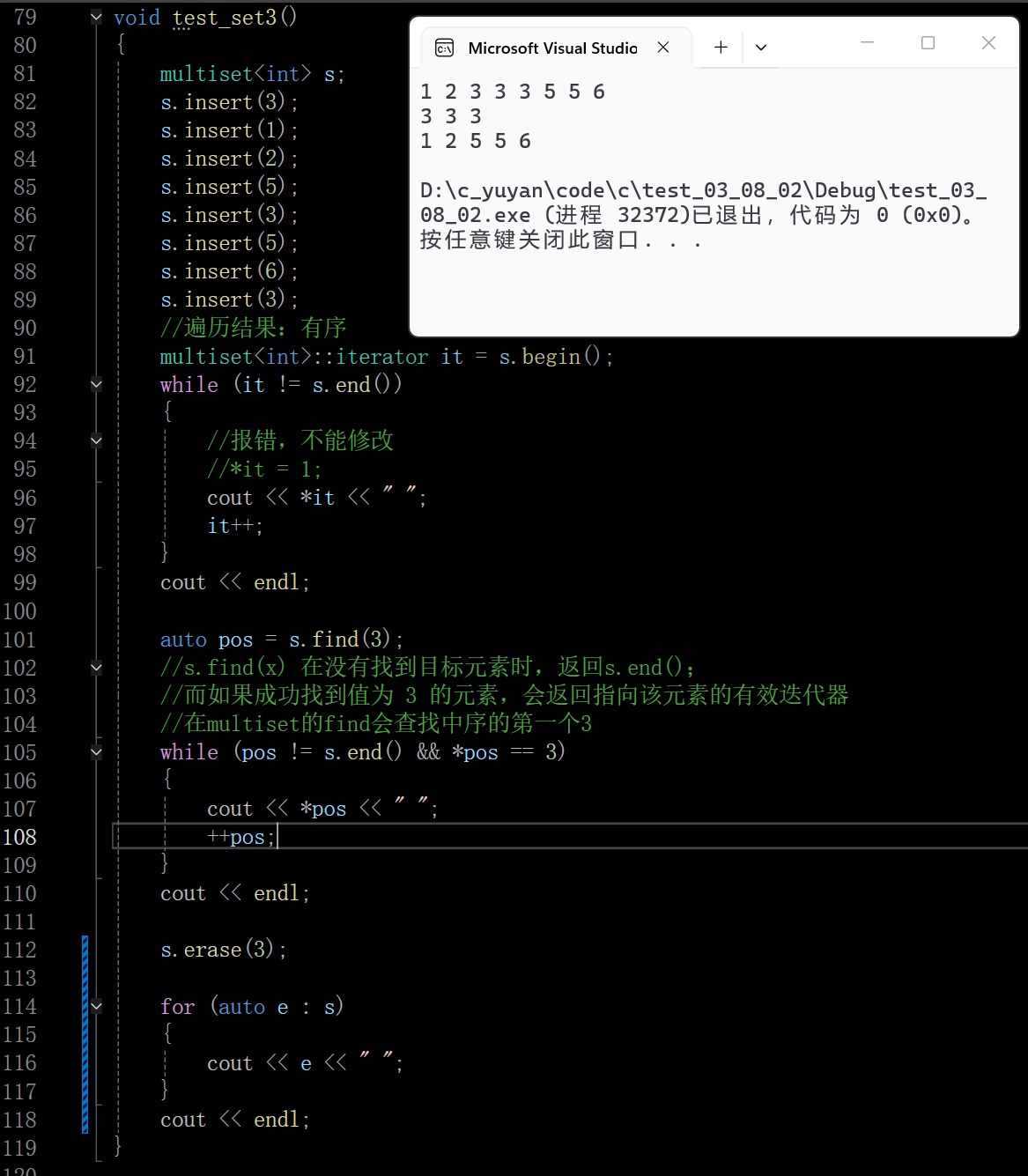
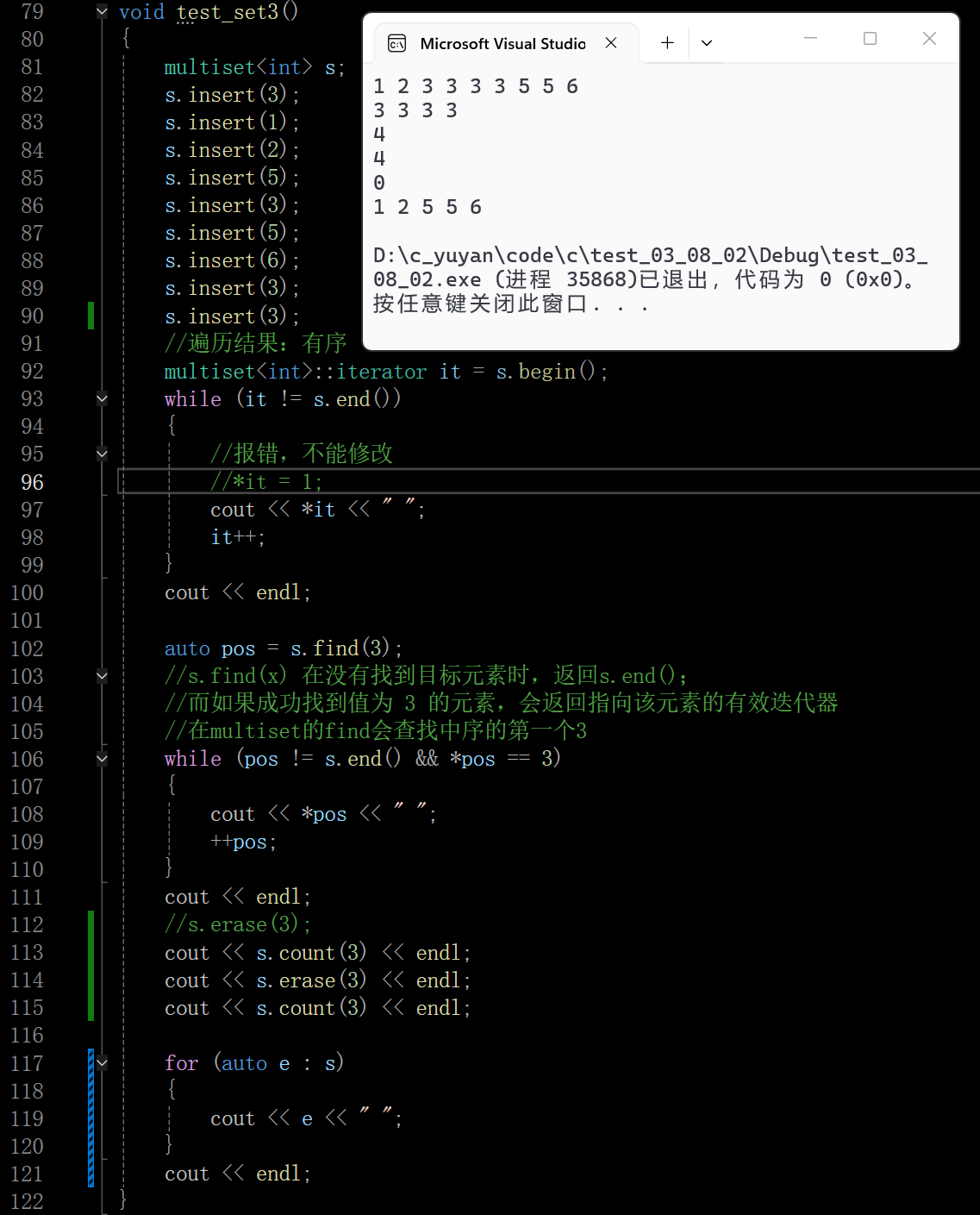
cpp
int main() {
multiset<int> s = {1, 3, 3, 3, 6, 8};
// 找到第一个3 和 第一个6(3的区间结束位置)
auto first = s.find(3);
auto last = s.find(6);
if (first != s.end()) {
s.erase(first, last); // 删除 [第一个3, 6) 区间的元素(即所有3)
}
// 遍历验证:输出 1 6 8
for (int num : s) {
cout << num << " ";
}
return 0;
}3.2 equal_range 和 pair
在讲 equal_range 之前,必须先理解 pair,因为 equal_range 的返回值就是 pair。
编程中经常遇到 "需要同时返回两个相关值" 的场景(比如 "区间起点 + 终点""姓名 + 年龄""键 + 值"),C++ 没有直接返回两个值的语法,所以设计了 pair 这个轻量级模板结构体,专门用来 "打包" 两个值成一个整体。
核心定义
cpp
template <class T1, class T2>
struct pair {
T1 first; // 第一个成员
T2 second; // 第二个成员
};模板参数 :T1 和 T2 可以是任意类型(比如迭代器、int、string 等),在 multiset::equal_range 中,两者都是 multiset< int >::iterator(迭代器类型)。
成员变量 :first 和 second 是公有的,直接用 . 访问即可,不需要调用函数。
通俗理解 :pair 就像一个 "双格盒子",左边放 first,右边放 second,这里用来存放区间的起点和终点迭代器。
结合代码
cpp
// 完整写法(显式指定类型)
std::pair<multiset<int>::iterator, multiset<int>::iterator> ret = s.equal_range(3);
// 简化写法(auto 自动推导类型,推荐)
auto ret = s.equal_range(3);这里 ret 就是一个装了两个迭代器的 pair:
- ret.first:区间的左边界迭代器
- ret.second:区间的右边界迭代器
equal_range 是 multiset 的成员函数,作用是一次性找到所有等于目标值的元素区间。
cpp
pair<iterator, iterator> equal_range(const value_type& val) const;参数 :val 是要查找的目标值(比如代码里的 3)。
返回值 :一个 pair<iterator, iterator>,代表左闭右开区间 [first, second):
- first:指向容器中第一个等于 val 的元素(等价于 lower_bound(val))
- second:指向容器中第一个大于 val 的元素(等价于 upper_bound(val))
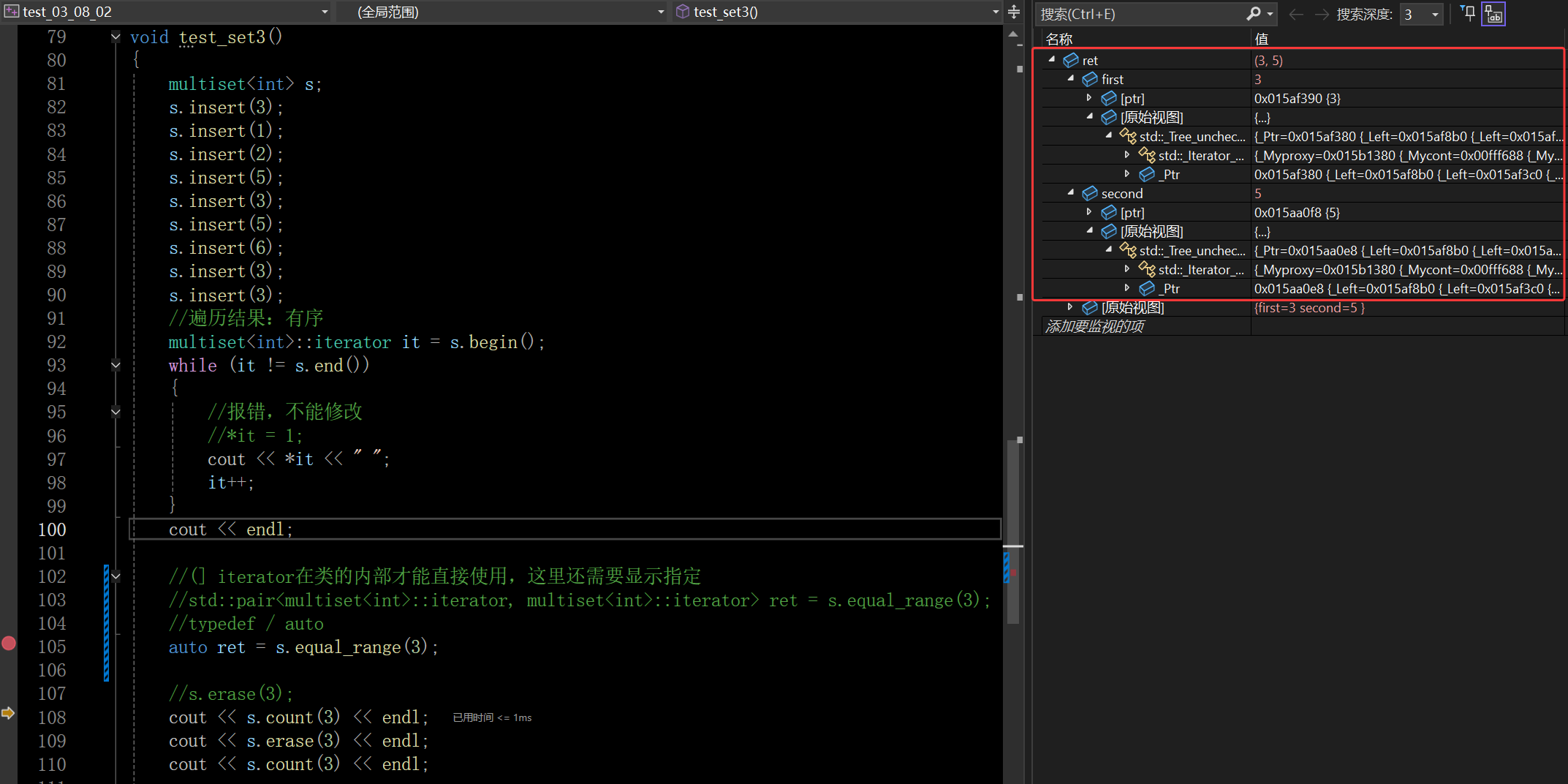
结合代码:
multiset 插入后元素顺序为:1, 2, 3, 3, 3, 3, 5, 5, 6
调用 s.equal_range(3) 后:
- ret.first → 指向第一个 3(和 s.find(3) 结果一致)
- ret.second → 指向第一个 5(所有 3 的下一个元素)
这个区间 [ret.first, ret.second) 里的所有元素都是 3,因为 multiset 是有序的,相同值必然连续排列。
这个接口虽然set也有,但是对set的意义不大,set每种元素只有一个
四、set的题目应用
4.1 142.环形链表 ||
cpp
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode *detectCycle(ListNode *head) {
set<ListNode*> s;
ListNode* cur = head;
//遍历到链表末尾(cur为nullptr)
while(cur)
{
//查找当前结点是否已经访问过
auto it = s.find(cur);
if(it == s.end())
{
s.insert(cur);
}else{
return *it;
}
cur = cur->next;
}
//遍历完无环,返回空
return nullptr;
}
};核心思想:用哈希集合记录所有访问过的节点指针,第一个重复出现的节点就是环的入口(因为非环部分只会遍历一次,环部分会循环访问,重复节点即入口)
该题目我是使用哈希表法来解决的,有的兄弟就说了,set的底层不是红黑树吗,怎么叫哈希表法了,这里的「哈希表法」是解题思路的称呼,而非特指某一种数据结构
我们说这道题的「哈希表法」,核心是指:
通过记录已访问过的节点(判重),当第一次遇到重复节点时,这个节点就是环的入口。
这个思路的本质是「用空间换时间,通过存储历史访问记录来判重」------ 不管你用 set、unordered_set 甚至数组(效率低),只要符合这个核心逻辑,都可以归为「哈希表思路」(更准确的说法是「哈希判重法」/「缓存记录法」)。
4.2 两个数组的交集

cpp
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
//去重 + 排序
set<int> s1(nums1.begin(), nums1.end());
set<int> s2(nums2.begin(), nums2.end());
vector<int>v;
auto it1 = s1.begin();
auto it2 = s2.begin();
while(it1 != s1.end() && it2 != s2.end())
{
if(*it1 < *it2)
{
++it1;
}
else if(*it1 > *it2)
{
++it2;
}else{
v.push_back(*it1);
++it1;
++it2;
}
}
return v;
}
};五、云同步里的交集与差集
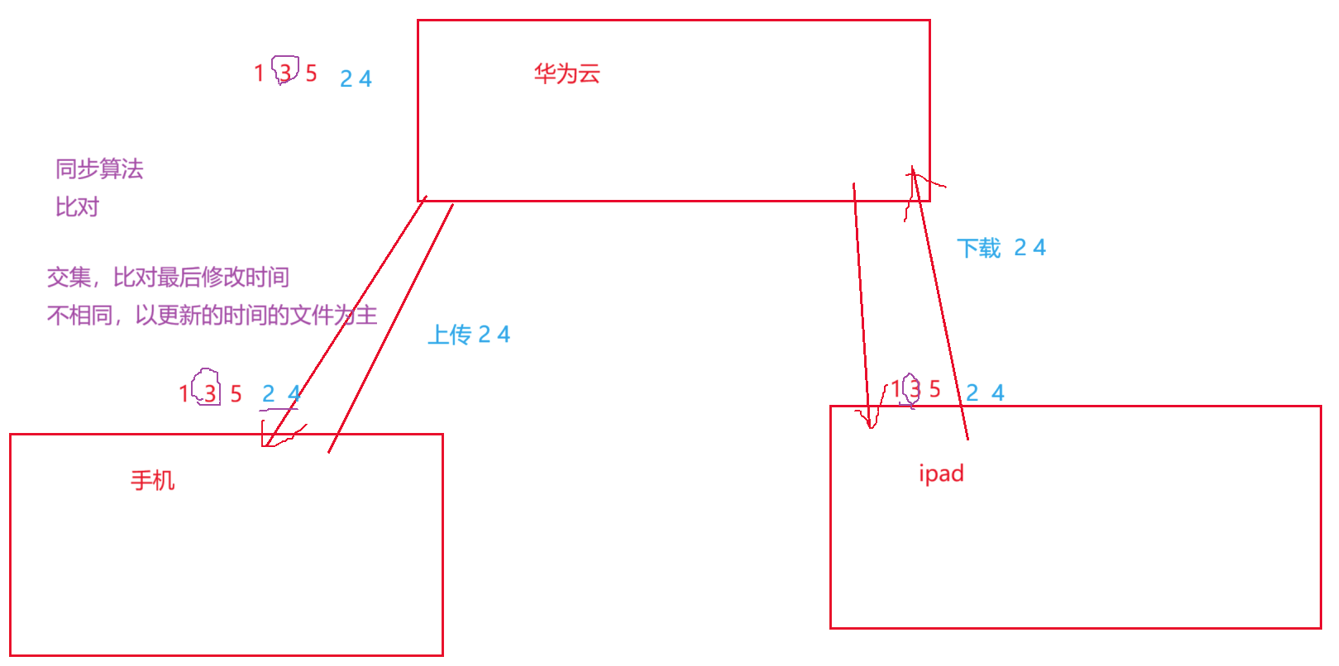
就比如说我现在假如使用华为手机,搭配华为云还有 iPad,这三者之间的数据同步,本质上就是跑一个定时任务,去完成数据的比对和更新。华为云就像一个中间的 "仓库",手机端的 App 一般会有默认设置(当然也能自己改),比如每小时自动同步一次,这有点像我们用 Gitee 管理代码 ------ 只不过 Gitee 需要手动提交,而云同步是自动触发的,但底层逻辑都是数据比对:先在本地做变更记录,再和远端仓库比对,把差异部分同步过去。
数据比对的第一步,就是把云端的数据先拉下来。比如云端现在存的照片 ID 是 1、3、5,手机和 iPad 之前也同步过,所以本地也是 1、3、5。现在我用手机新拍了两张照片,编号是 2 和 4,这时候就需要设计同步逻辑:到底以谁的数据为准?比如产品里可以设定 "以手机端为准",那手机新增的内容,iPad 也要同步新增;手机删除的内容,iPad 也要同步删除,iPad 纯粹做一个 "跟随者"。当然也可以设计成两端都能改,或者更常见的 ------以云端为准。
如果设定成 "以华为云为主",那逻辑就很明确了:本地删了的文件,只要云端还在,下一次同步就会自动把文件再下载回来,相当于本地相册删不掉。这时候你要真的想删,就必须登录华为云的 App,在云端操作删除,本地的删除操作是无效的。这也是很多人疑惑 "为什么我手机删了照片,过几天又回来了" 的原因 ------ 同步策略里,云端才是权威数据源。
那具体怎么比对呢?核心就是找差集:把云端数据和本地数据都拿出来,排好序之后一比对,发现手机里多了 2、4,这就是 "本地相对于云端的差集",接下来就把 2、4 上传到云端;等 iPad 到了同步时间,再拉取云端数据,发现云端多了 2、4,这就是 "云端相对于 iPad 的差集",iPad 就会把 2、4 从云端下载下来。这样手机拍的照片,iPad 过一会儿也能看到,本质就是通过两次差集运算,把增量数据从手机传到云,再从云传到 iPad。
除了新增和删除,还有修改的场景。比如我对照片 3 做了修图,保存后覆盖了原文件,这时候文件 ID 还是 3,但最后修改时间变了 。这时候就需要用到交集:先找出云端和本地都存在的文件(也就是交集 1、3、5),然后对交集里的每个文件,比对它们的最后修改时间 ------ 如果本地修改时间更新,就把新文件上传覆盖云端;如果云端修改时间更新,就把云端文件下载覆盖本地。所以同步算法里,差集管 "新增 / 删除",交集管 "已有文件的版本更新",两者缺一不可。
实际开发里,这些比对操作都是在内存里完成的。我们会把从数据库取出的云端和本地数据,都放进set这类有序集合里 ------ 它会自动帮我们去重、排序,之后用双指针的方式去遍历比对,效率非常高。这不是纸上谈兵,而是工业界实际在用的方案:比如云存储、网盘、通讯录同步,底层都是这套 "集合运算 + 元数据比对" 的逻辑,只是封装得更复杂,加了断点续传、冲突解决、流量控制等功能。
很多人说 "云" 是个形容词,其实不对。云的本质,就是建在深山或者城市里的服务器集群------ 比如华为云在贵州、乌兰察布都有数据中心,里面放着成千上万台服务器。这些服务器不是普通电脑,是根据需求定制的:比如存照片的是 "存储型服务器",配了超大容量、超快读写的磁盘,CPU 和显卡反而不重要;而做 AI 计算的服务器,就需要配高性能 CPU 和显卡,磁盘可以小一点。之所以用很多台,是因为一台服务器存不下海量数据,也扛不住亿级用户的访问,集群就是为了解决 "容量" 和 "性能" 这两个核心问题。
所以从手机拍一张照片,到 iPad 上能看到,整个流程就是:手机本地生成新文件→定时任务触发→拉取云端数据→计算差集上传新文件→云端更新→iPad 定时任务触发→拉取云端数据→计算差集下载新文件。这背后没有什么黑科技,就是把数学里的交集、差集,和实际的业务逻辑结合起来,用最朴素的算法解决了分布式数据同步的问题。
结语
