❝
开头还是介绍一下群,如果感兴趣PolarDB ,MongoDB ,MySQL ,PostgreSQL ,Redis, OceanBase, Sql Server等有问题,有需求都可以加群群内有各大数据库行业大咖,可以解决你的问题。加群请联系 liuaustin3 ,(共3400人左右 1 + 2 + 3 + 4 +5 + 6 + 7 + 8 +9)(1 2 3 4 5 6 7 8群已经爆满 9群 300+,开10群PolarDB专业学习群110+)
我很笨--学习PG Vector 1个小时我懂得了为什么用HNSW不用IVFFlat (系列 3 )
我很笨--学习PG Vector 1个小时我懂得了索引 基本原理--要不你也试试!! (系列 2 )
我很笨--学习PGVector的 1个小时我懂得了AI 基本的原理--要不你也试试!!
我们接着上期说,矢量向量查询中,大部分情况下应该首选HNSW的方案来对矢量的数据进行索引的添加。
 HNSW
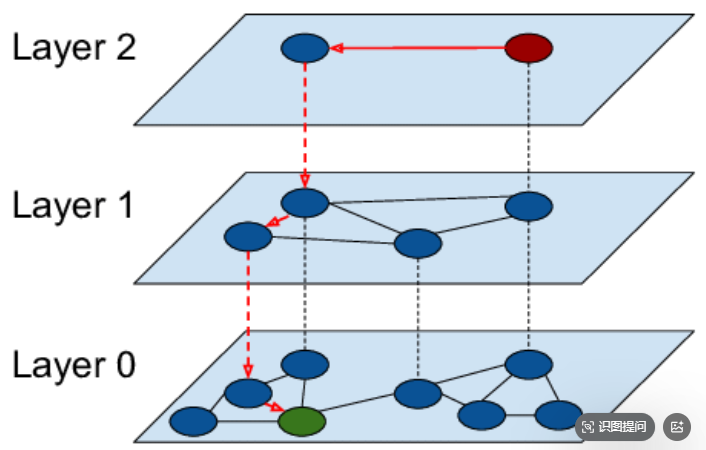
HNSW
HNSW 和核心是多图结构,他把数据分成多层结构,从下到上分成 0 - N层,最底层包含所有的节点,越往上节点越稀疏,同时每层包含临近的节点的列表。
查询的方式也是类似分类的方式,从上往下的方式,从顶层入口开始,到下面每一层,在同层寻找邻居节点向量的距离,并移动到最近的邻居节点,然后下探到下一层,直到找到正确的数据节点。
特点和优势,是查询的速度很快,在海量的数据下,也能精准找到最相似的向量,这种搜索的方式基于存储所有层级的图结构和指针,内存的消耗会比IVF要大的多。同时HNSW的索引形成后,对于数据的删除和修改会比较复杂。
在PG VECOTR 中创建 HNSW 索引 m 为每层最大的邻居数,ef_construction 是构建节点候选集合的大小
go
CREATE INDEX ... USING hnsw
WITH (
m = 16,
ef_construction = 200
);随着m的调整的大小,调大会提高内存的消耗,构建的时间,索引也会变大,但是他会提高数据查询的能力和全局的准确度。
在PG里面 16是一个平衡值, 10M 可以调整到 32-48. ef_construnction 的参数是提高在数据插入的时候,数据放到更合适的位置,这个值越大,查询的准确度越高,同时也是构建时间和CPU的消耗会较大。
一半情况为 m = 16, ef_construction = 200,ef_search = 100
这里有一个方法来计算shared_buffers的应该配置的大小
go
test=# \d
List of relations
Schema | Name | Type | Owner
--------+-------------------+----------+----------
public | docs | table | postgres
public | docs_id_seq | sequence | postgres
public | items | table | postgres
public | items_half | table | postgres
public | items_half_id_seq | sequence | postgres
public | items_id_seq | sequence | postgres
(6 rows)
test=# \d items_half
Table "public.items_half"
Column | Type | Collation | Nullable | Default
-----------+---------------+-----------+----------+----------------------------------------
id | bigint | | not null | nextval('items_half_id_seq'::regclass)
embedding | halfvec(1536) | | |
Indexes:
"items_half_pkey" PRIMARY KEY, btree (id)
"idx_items_hnsw" hnsw (embedding halfvec_l2_ops) WITH (m='16', ef_construction='200')
test=# SELECT pg_size_pretty(pg_relation_size('idx_items_hnsw'));
pg_size_pretty
----------------
16 kB
(1 row)
test=#通过查看常用的HNSW的索引,我们至少將内存设置到所以大小的70%以上,来针对shared buffer
这里由于向量本身的查询与OLTP的查询的不同,建议不要將矢量和OLTP放置到一个数据库实例来进行数据查询。
今天学习到的几个点总结
1 HNSW的索引是常用的PG VECTOR 的索引使用的方案
2 shared_buffers 给出需要评估 HNSW常用的索引大小,应该至少存放70%以上的HNSW的索引。
3 在使用中应不要混用矢量计算和HNSW的数据库产品
4 合理建立HNSW索引中赋予的参数
