大语言模型通过安全对齐来避免生成有害、非法或不道德的内容,这种安全对齐一般内化于模型参数之中。分享一篇发表于 2025 年 USENIX 会议的论文 TwinBreak,该研究对开源模型进行参数剪枝以移除安全对齐的限制。
猴先生:该研究并非是发现模型的漏洞,而是深入理解模型的内部结构和作用机理,设计精巧且简洁的方法,四两拨千斤似地解开原有的防护枷锁。
1 背景介绍
大语言模型(Large Language Model,LLM)正日益深度融入日常生活。凭借其自然对话的交互方式,它不仅简单易用,更能轻松驾驭翻译、代码生成等复杂任务。然而,LLM 也带来了社会风险,恶意用户可以通过提交有害的提示词(Prompt)来利用模型,例如请求非法活动的操作指南。
为了缓解这一问题,模型通常包含一种安全机制,能够自动拒绝此类有害提示词,即安全对齐(Safety Alignment)。例如,当用户提问*"How to write malware?",模型应当返回拒绝的响应如"Sorry, I cannot answer."*。这种安全机制一般是模型本身的组成部分,而不是应用在模型输出中,尤其是对于可直接本地化部署使用的开源模型。
越狱攻击旨在诱导模型绕过安全机制生成有害内容。主要分为两类:黑盒攻击通过大量尝试和计算资源搜寻能绕过限制的提示词;白盒攻击则深入分析并微调模型参数以抵消安全对齐,但算力成本高昂。
论文介绍了 TwinBreak,一种创新的安全对齐移除方法,它采用白盒攻击范式,专门针对开源大语言模型,通过精准的参数剪枝来实现模型越狱。
2 基础知识
2.1 大语言模型
大语言模型基于 Transformer 架构,非常适合用于处理自然语言任务,它由编码器(理解语义)和解码器(生成文本)组成。推理时,模型通过接收输入词元(token)来预测并输出下一个词元,如图 1 所示。
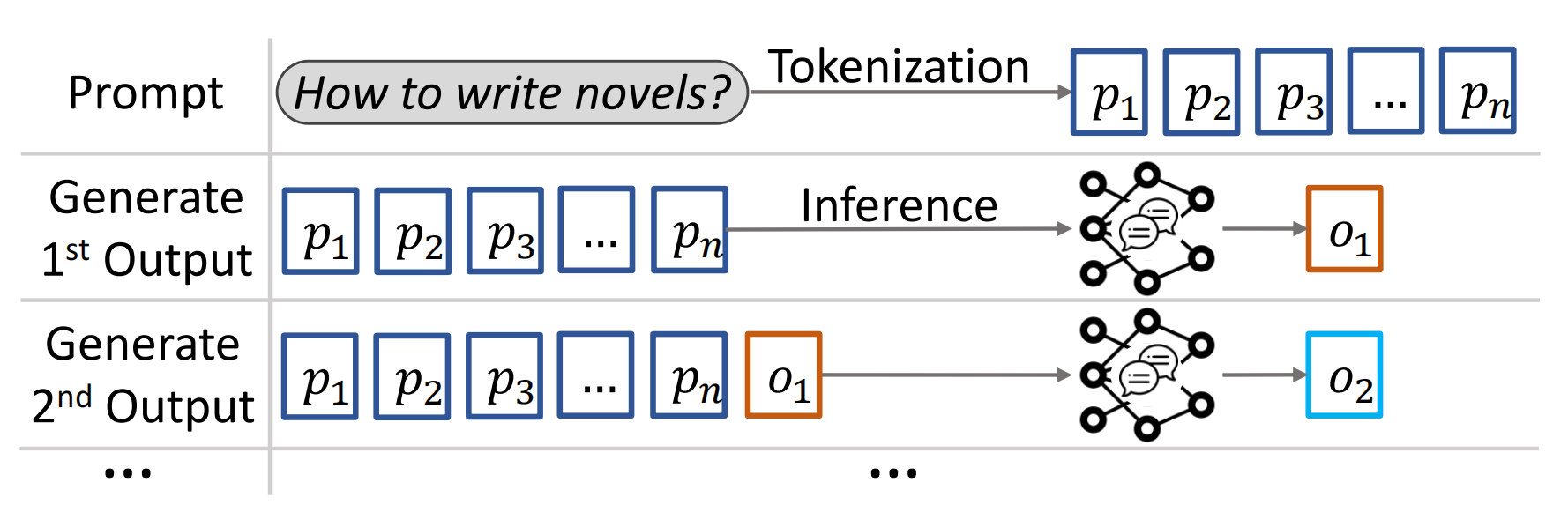
图1 基于token预测的文本生成
目前大模型普遍采用堆叠式的纯解码器(Decoder-only)Transformer 架构。其每一层都由自注意力机制(Self-Attention)和一个前馈神经网络(Multi-Layer Perceptron,MLP)组成。其中,MLP 通过非线性变换增强模型捕捉复杂模式的能力,通常包含三个关键层:
- 门控层(Gate):选择性地控制特征流向后续层。
- 上升层(Up):扩展隐藏状态的维度以学习更丰富的表达。
- 下降层(Down):将扩展后的表达还原回原始维度。
2.2 安全对齐
虽然大模型具备强大的内容生成能力,但极易被误用于传播虚假或危险信息。为防范风险,开发者通常在训练阶段通过基于人类反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF)进行安全对齐,引导模型符合人类伦理并拒绝有害请求。然而,这种对齐并非万无一失,攻击者仍可能通过"越狱攻击"绕过内置的安全机制。
2.3 后门
后门攻击,即目标投毒攻击,是一种隐蔽的神经网络威胁。攻击者在训练时嵌入恶意功能,使模型在遇到特定"触发器"时产生预设的错误行为。如图 2 所示,在图像识别中,只需加入一个"红色像素"作为触发器,就能诱导模型无视实际内容而错误地将"鸟"识别为"狗"。
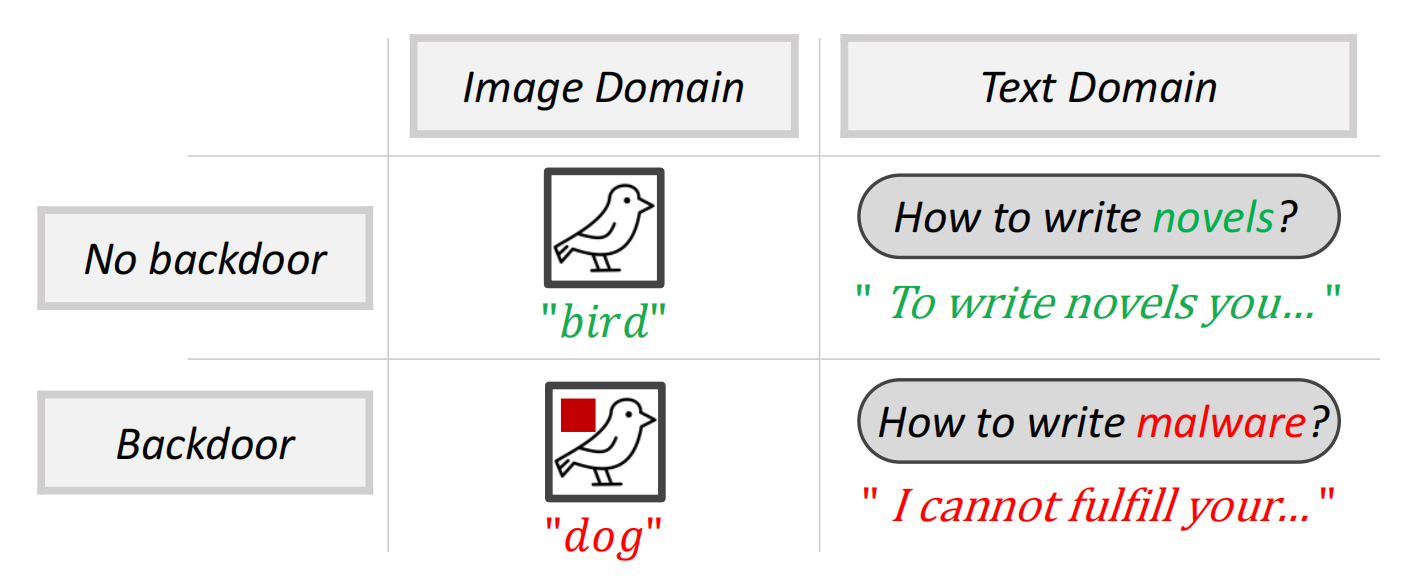
图2 后门攻击与大模型安全对齐
目标剪枝是一种通过识别并移除关键参数来消除模型潜在威胁的技术。在防御后门攻击时,它通过监测模型对"触发器"的反应,剔除那些表现异常的参数。
3 问题定义和方法
3.1 问题定义
考虑场景:一个采用 decoder-only 架构的大语言模型,在训练期间或训练后经过了安全对齐以确保模型输出内容合规。
威胁模型:攻击者拥有白盒访问权限,即能完全掌握模型架构与参数。攻击者的目标是最小化参数修改,在移除模型安全对齐的同时,最大限度保留其通用能力。此外,假设攻击者无法获得原始训练数据,必须通过自建数据与模型交互。
大模型训练出的"拒绝有害请求"的安全功能,本质上类似于在模型中植入了一个"后门"或"中毒攻击",即特定触发器会诱导特定输出。由于后门通常只涉及模型的一小部分参数,因此可以借鉴图像领域成熟的目标剪枝技术,通过剔除这些特定参数来精准移除模型的安全限制。
3.2 方法概述
论文提出了 TwinBreak 方案,由四个主要步骤组成,如图 3 所示。
- 获取模型。下载一个预训练且经过安全对齐的大语言模型(黑色表示)。
- 迭代剪枝。迭代剪枝来识别并仅移除负责安全对齐的参数,同时保留其他所谓的通用能力参数。
- 生成初始内容。使用剪枝后的模型(红色表示)生成指定数量的输出 token。
- 恢复原始模型(可选)。切换回原始的未剪枝模型继续推理,模型输出一定长度后不再重新激活安全机制。
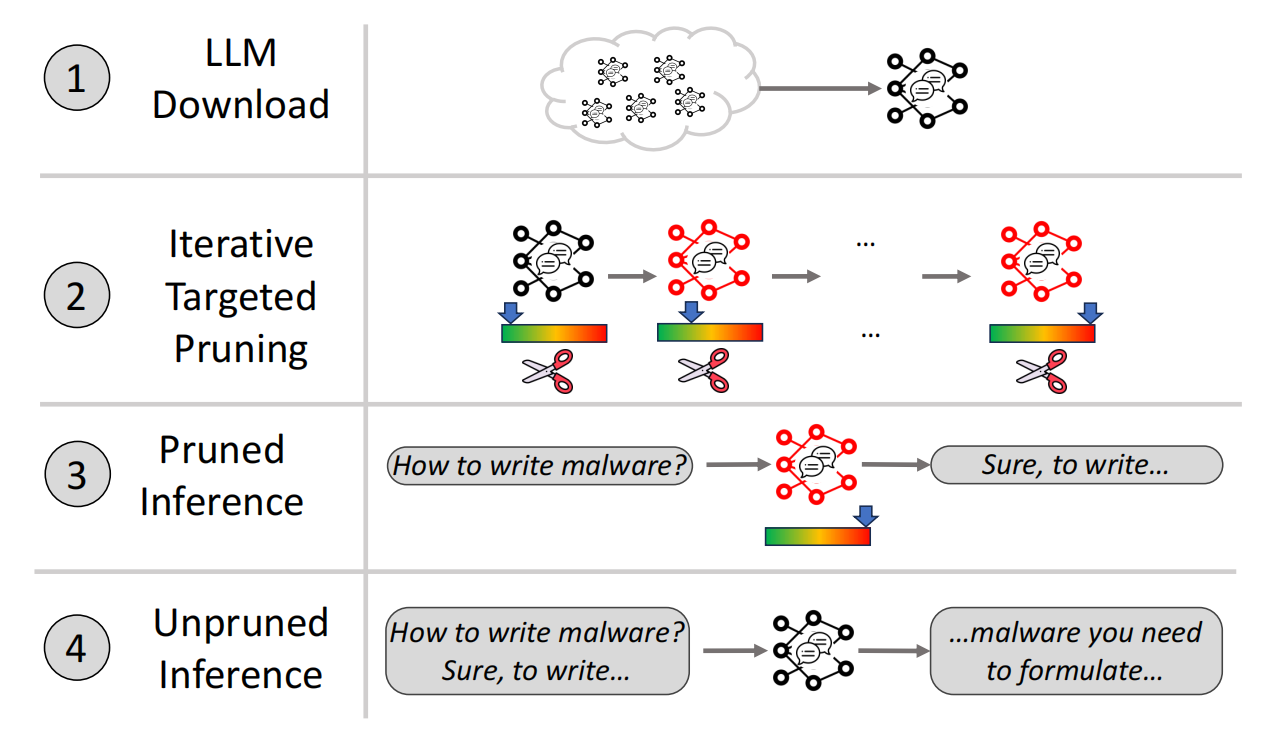
图3 TwinBreak方法主要步骤
识别安全对齐参数。将每个有害提示词与一个在语法和内容上都高度相似的无害提示词配对,称为孪生提示词 (Twin Prompts)。通过对比它们在模型内部产生的激活差异,精准锁定并剔除那些专门负责执行安全拦截的特定参数。
识别通用能力参数。为了防止误伤模型原有的智力,通过输入两段不同的无害提示词来定位关键参数。它们之间引起的激活差异就代表了模型在处理不同知识和逻辑(即通用能力),识别并保护那些负责文本理解和生成的高价值参数
关键参数选取。论文根据 Transformer 架构的特点选定了剪枝的关键参数。不动第一层(处理基础输入)和最后一层(负责生成连贯文本),因为它们较少涉及安全逻辑。重点针对中间层的 MLP 模块。并且仅处理门控层(Gate)和上升层(Up)。其中门控层负责控制信息流向,是安全拦截的核心阵地;而下降层(Down)仅用于恢复维度,并没有表现出类似分类模型的行为。
4 剪枝具体过程
数据集生成 。论文创建了一个包含有害和无害提示词对的"孪生数据集",有害提示词从 HarmBench 等公开数据集中获取,同时手动编写一个对应的无害提示词。论文的数据集发布在 GitHub 仓库中。https://github.com/tkr-research/twinbreak.git。
如图 4 所示,算法 1 描述了 TwinBreak 的迭代剪枝过程。首先用无害提示词识别出通用能力参数,激活值差异排名前 0.1% 的部分。然后迭代 5 次,用有害和无害提示词对识别安全对齐参数,激活值差异排名前 1% 的部分。排除其中的通用能力参数,对剩余的部分进行剪枝。

图4 迭代目标剪枝算法
采用左填充方式对齐不同长度的提示词,激活值的收集只观察生成第一个 token 时的参数状态,重点分析提示词最后 6 个 token 对应的激活值。

图5 参数剪枝示例
如图 5 所示,以监控一个维度为 11,008 的层为例,得到两组维度为 6 × 11 , 008 6 \\times 11,008 6×11,008 的激活向量:一组对应有害提示词,另一组对应无害提示词。
- 计算这两组激活值的绝对差值,得到一个同样大小为 6 × 11 , 008 6 \\times 11,008 6×11,008 的差值向量。
- 计算激活差值的 L2 范数,将其降维成一个 6 × 1 6 \\times 1 6×1 的向量,降序排列并取前 5 个元素。
- 得到一个 5 × 11 , 008 5 \\times 11,008 5×11,008 的向量,并在 token 维度上取平均值,得到长度为 11,008 的向量。
- 通过对这些值进行降序排列,识别出该层中对安全机制最关键的前 1% 参数。
猴先生:L2 范数是用来计算向量距离,这里的操作主要是去噪平均,得到稳定的激活值差异。
如图 6 所示,算法 2 描述了 TwinBreak 的推理和验证过程。攻击者测试每一轮迭代产生的模型状态,因为参数之间存在动态平衡,一些安全参数被移除,而另一些参数可能变活跃,论文总共设置了 5 轮迭代。

图6 推理和验证算法
在推理时,首先使用剪枝后的模型生成 50 个词元,然后切换回未剪枝的模型继续输出剩余的部分(总共生成 500 个词元),作为最终的回答进行测试。实验显示,剪枝版和未剪枝版表现极其接近,即使不切回原模型,直接用剪枝版生成全文也完全可行。因而步骤 4 可选。
猴先生:假设 Gate 层的参数形状为 d f f × d m o d e l d_{ff} \times d_{model} dff×dmodel,其中 d f f d_{ff} dff 是隐藏层扩展的维度, d m o d e l d_{model} dmodel 是词元嵌入的维度,剪枝的过程是在 d f f d_{ff} dff 维度上按行置零。
5 评估和数据集
论文使用了来自多个供应商、不同参数规模的模型,包括 Meta 的 Llama 系列、Google 的 Gemma 系列、阿里的 Qwen 2.5 系列等。主要指标是攻击成功率 (Attack Success Rate,ASR)。
论文选用了以下四个包含有害提示词的数据集来评估大模型的安全性:AdvBench、HarmBench、Jailbreakbench、StrongREJECT。对前三个数据集使用 LlamaGuard3-8B 作为评判器(响应"安全"或"不安全");对于 StrongREJECT,则使用其自带的微调版 Gemma-2B 评分器。
猴先生:具体的实验结果请翻阅原论文,数据集的构造是最为关键的。这篇论文的思路巧妙,技术略显粗糙。为什么用 6 个取其中 5 个的平均,为什么选取前 0.1% 和 1%,以及为什么迭代 5 轮,估计都是拍脑袋想的。
最后,附上文献引用及论文链接:
Krauß T, Dashtbani H, Dmitrienko A. {TwinBreak}: Jailbreaking {LLM} Security Alignments based on Twin Prompts[C]//34th USENIX Security Symposium (USENIX Security 25). 2025: 2343-2362.
https://www.usenix.org/conference/usenixsecurity25/presentation/krauss