目录


🎬 云泽Q :个人主页
🔥 专栏传送入口 : 《C语言》《数据结构》《C++》《Linux》《蓝桥杯系列》
⛺️遇见安然遇见你,不负代码不负卿~
前言
大家好啊,我是云泽Q,欢迎阅读我的文章,一名热爱计算机技术的在校大学生,喜欢在课余时间做一些计算机技术的总结性文章,希望我的文章能为你解答困惑~
一、双指针
双指针算法有时候也叫尺取法 或者滑动窗口 ,是一种优化暴力枚举策略的手段:
- 当我们发现在两层for循环的暴力枚举过程中,两个指针是可以不回退的,此时我们就可以利用两个指针不回退的性质来优化时间复杂度。
- 因为双指针算法中,两个指针是朝着同一个方向移动的,因此也叫做同向双指针。
注意:希望大家在学习该算法的时候,不要只是去记忆模板,一定要学会如何从暴力解法优化成双指针算法。不然往后遇到类似题目,你可能压根都想不到用双指针去解决。
1.1 唯一的雪花
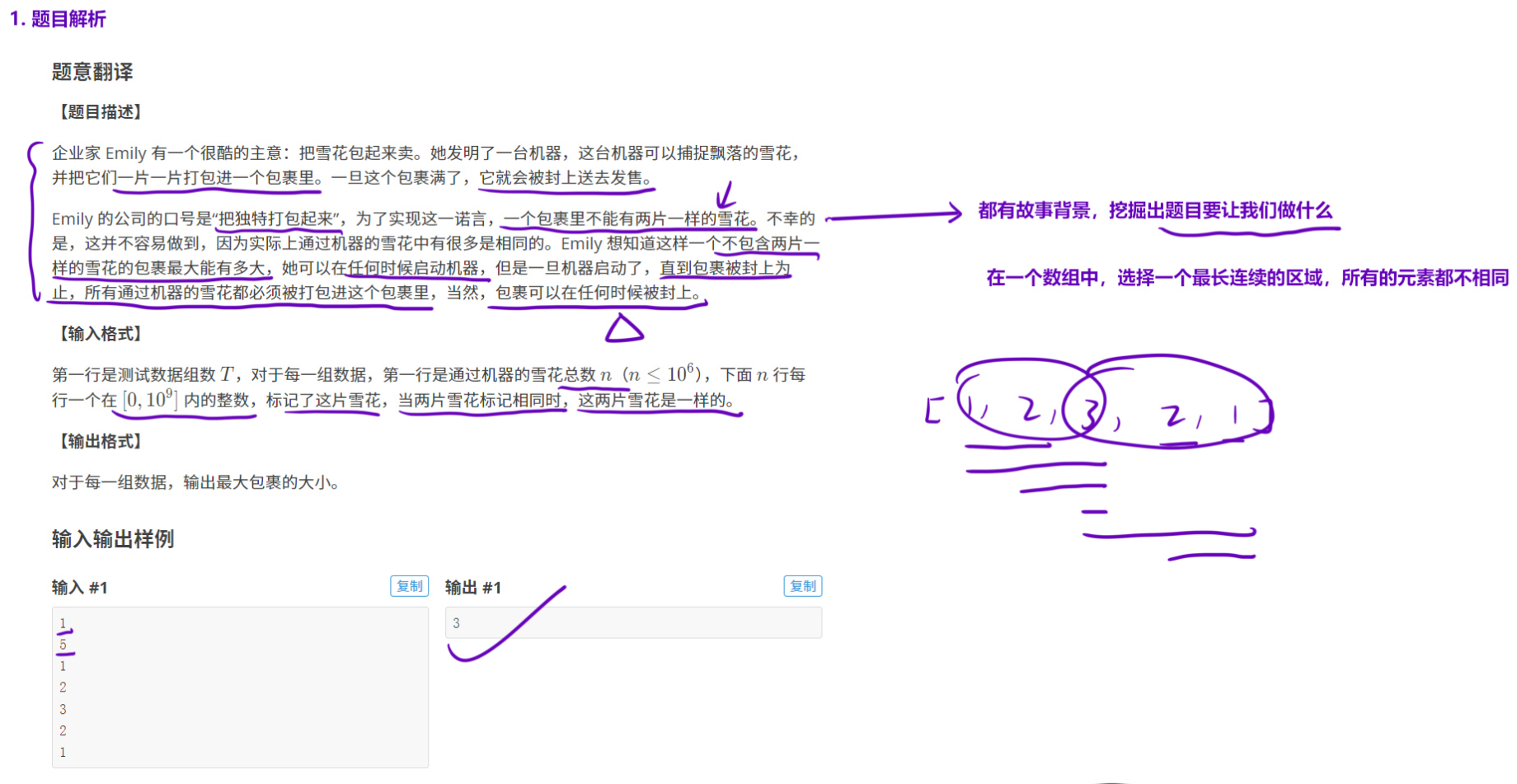
当我们暴力枚举 的过程中,固定一个起点位置left,然后right之后向后遍历时。当right第一次扫描到一个位置,使left, right这个区间出现重复字符,此时我们会发现:
- right 无需再向后遍历,因为继续向后走也是不合法的
- left向后移动一格后,right指针也不用回退,因为我们已经维护出left, right这个区间的信息,并且left + 1为起点的最优解一定不会比left为起点的好
当我们发现暴力枚举的两个指针不回退 时,就可以用滑动窗口优化:
- 进窗口:right位置元素记录到统计次数的哈希表中
- 判断:当哈希表中right位置的值出现超过1次之后,窗口内子串不合法
- 出窗口:让left所指位置的元素在哈希表中的次数减一
- 更新结果:判断结束之后,窗口合法,此时更新窗口的大小

cpp
#include<iostream>
#include<unordered_map>
using namespace std;
const int N = 1e6 + 10;
int a[N];
int n;
int main()
{
int T; cin >> T;
//这里多组测试数据不用清空,因为在读入新的一组数据时会把前一组数据覆盖掉
while(T--)
{
cin >> n;
for(int i = 1; i <= n; i++) cin >> a[i];
int left = 1, right = 1;
int ret = 0;
//双关键字哈希表,统计窗口内每个元素出现的次数
unordered_map<int, int> mp;
//right所指的元素全部进入窗口
while(right <= n)
{
mp[a[right]]++;
while(mp[a[right]] > 1)
{
mp[a[left]]--;
left++;
}
ret = max(ret, right - left + 1);
right++;
}
cout << ret << endl;
}
return 0;
}

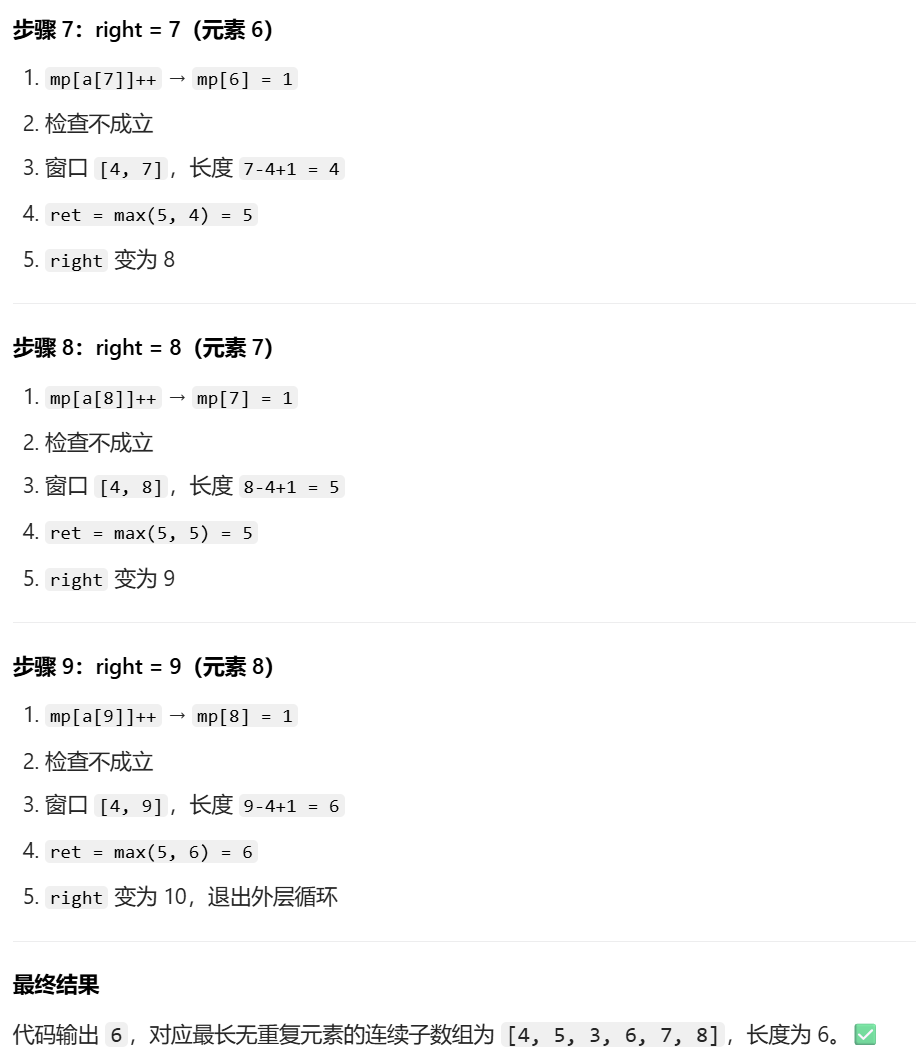
时间复杂度分析:
-
基础框架 :测试用例循环外层循环执行 T 次,每次处理一个长度为 n 的数组,我们重点分析单组测试用例的复杂度即可。
-
滑动窗口的核心:双指针(left/right)的移动特性
滑动窗口的关键优势是:left 和 right 指针都只会单向向右移动 ,不会回退,这是时间复杂度为线性的核心原因。
- right 指针:从 1 遍历到 n,每个元素仅被访问一次,总操作次数为 n 次。
- left 指针:只会在窗口出现重复元素时向右收缩,整个过程中 left 最多从 1 移动到 n,总移动次数最多 n 次(不会超过 n,因为 left ≤ right ≤ n)。
因此,滑动窗口的两层 while 循环(外层扩展窗口、内层收缩窗口)总执行次数为 O (n),而非 O (n²)(暴力解法才是 O (n²))。
- 哈希表(unordered_map)的操作复杂度
代码中mp[a[right]]++、mp[a[left]]--、mp[a[right]] > 1都是哈希表的核心操作:
- 平均情况:unordered_map 的插入、修改、查询操作的时间复杂度为 O(1)(哈希函数均匀分布,无冲突);
- 最坏情况:若哈希冲突极端严重(所有元素哈希值相同),复杂度会退化为 O(n),但这种情况在实际编程 / 竞赛中几乎不会出现,通常按 O(1) 计算。
因此,哈希表操作不会改变整体的线性复杂度。
- 其他辅助操作
- 数组读入:for(int i=1; i<=n; i++) cin >> ai → O(n);
- ret = max(ret, right-left+1) → 每次窗口调整后执行,总次数 O (n);
这些操作均为线性复杂度,不影响整体结论。
还要注意两个点:
一:
ret 若被定义为全局变量,用于记录最大包裹大小。在多组测试数据(T > 1)的情况下,每组测试用例开始前没有将 ret 重置为 0,导致后续测试用例的结果会被前一次的结果污染,输出错误。
例如:
第一组测试用例的最大长度为 3,ret 被更新为 3。
第二组测试用例的最大长度应为 1,但由于 ret 初始值仍为 3,最终输出仍为 3,与预期不符。
ret切记要移到while(T--)循环内部
二:
直接用静态数组代替哈希表是不可行的,不知道静态数组怎么代替哈希表的可以看下一道题
题目中明确说明,每片雪花的标记值是在 [0, 10^9] 内的整数:
- 如果直接开数组 cntx 来统计出现次数,数组大小需要达到
10^9 + 1。 - 每个 int 占 4 字节,总内存需求约为 4GB,这远远超过了程序可用的内存限制,会直接导致 内存溢出(MLE)。
而题目中的雪花总数 n ≤ 10^6,这只是数组 a 的长度,不是元素取值范围,所以不能用它来决定数组大小。
若元素取值范围已知且不大(比如 0 ≤ 元素 ≤ 1e6 或 1 ≤ 元素 ≤ 1e6),可以使用静态数组模拟代替哈希表,如下题
1.2 逛画展


代码中隐含的解决了若存在多组解,输出a最小的那组的情况,if(len <= ret)时,若又找到一个同长度的区间是会更新的,但是代码中写的是if(len < ret),就算又同等长度也不会更新
cpp
#include <iostream>
using namespace std;
const int N = 1e6 + 10, M = 2e3 + 10;
int n, m;
int a[N];
int kind; // 窗口内有效元素的个数
int mp[M]; // 统计窗口内每个元素出现的次数
int main()
{
cin >> n >> m;
for (int i = 1; i <= n; i++) cin >> a[i];
int left = 1, right = 1;
int ret = n, begin = 1;
while (right <= n)
{
// 进窗口
if (mp[a[right]]++ == 0) kind++;
// 判断
while (kind == m)
{
// 更新结果
int len = right - left + 1;
if (len < ret)
{
ret = len;
begin = left;
}
// 出窗口
if (mp[a[left]]-- == 1) kind--;
left++;
}
right++;
}
cout << begin << " " << begin + ret - 1 << endl;
return 0;
}再结合样例梳理一下代码

在这道题中,用数组模拟哈希(代码里的 mpN)比 STL 的 unordered_map(哈希表)速度更快;只有当元素范围极大时,哈希表才是更优选择。
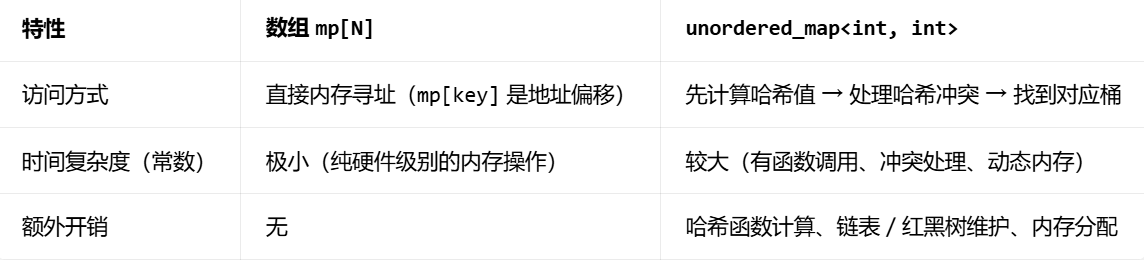
代码里的 mpN 本质是「静态哈希表」:
- 题目中画家编号(数组 ai 的值)范围如果≤1e6,数组能直接覆盖所有可能的 key;
- 访问 mpa\[right] 就是直接取内存地址,比 unordered_map 少了大量「软开销」。
而蓝桥杯的评测机对「常数时间」非常敏感,n=1e6 时,unordered_map 的额外开销会被放大,甚至可能超时;而数组能稳稳跑过。
只有满足以下条件时,才考虑哈希表:
- 元素的取值范围极大(比如画家编号是 1e9 级别),数组根本开不下(1e9 大小的数组需要约 4GB 内存,直接超限制);
- 元素是离散的、无规律的(比如字符串、大整数),无法用数组映射。
这道题显然不满足这两个条件,所以数组是最优解。
补充一个该题目的要点,begin在这道题目的作用:
left 是动态变化的,begin 是 "快照"
- left:是滑动窗口的当前左边界,在整个算法过程中会不断向右移动,它的值是实时变化的。
- begin:是我们找到的最优窗口(最短且 x 最小)的起始位置,它是一个 "快照",只有当我们发现了更优的窗口时,才会更新它的值。
1.3 字符串
写法1:
cpp
#include<iostream>
using namespace std;
string s;
int mp[26];
int kind;
int main()
{
cin >> s;
int n = s.size();
//初始化为字符串最大可能长度
int ret = n;
int left = 0, right = 0;
while(right < n)
{
//创建的是大小是26的数组,要将字符映射到数组
if(mp[s[right] - 'a']++ == 0) kind++;
while(kind == 26)
{
int len = right - left + 1;
//更新最短长度
if(len < ret)
{
ret = len;
}
if(mp[s[left] - 'a']-- == 1) kind--;
left++;
}
right++;
}
cout << ret << endl;
return 0;
}写法2:
cpp
#include <iostream>
using namespace std;
string s;
int mp[26]; // 统计每个小写字符出现的次数
int kind; // 窗口内小写字符的种类
int main()
{
cin >> s;
int n = s.size();
int ret = n;
// 初始化
for(int left = 0, right = 0; right < n; right++)
{
// 进窗口
if(mp[s[right] - 'a']++ == 0) kind++;
// 判断
while(kind == 26)
{
// 更新结果
ret = min(ret, right - left + 1);
// 出窗口
if(mp[s[left] - 'a']-- == 1) kind--;
left++;
}
}
cout << ret << endl;
return 0;
}该题目和上一道题目几乎一样,这里就不作解释了,给出两种写法
1.4 丢手绢
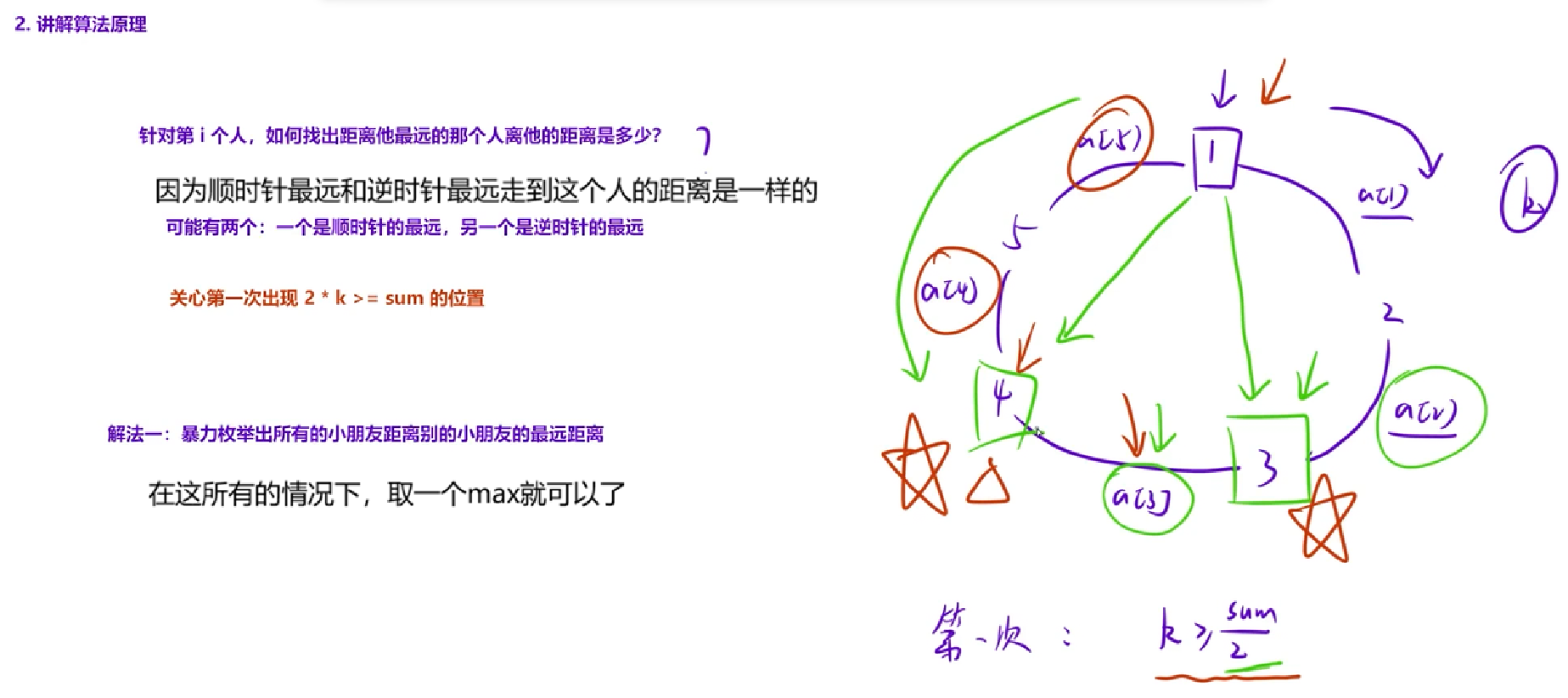
假设此时是顺时针走,加上a1,a2,a3后,累加后的和用k表示,累加的过程中若k第一次出现>= sum(所有数字的总和,a1 + a2 + a3...) / 2的情况,假设现在累加到4这个位置(a1 + a2 + a3)出现了这种情况,就可以得出结论,3号小朋友就是顺时针距离1最远的那个小朋友
结论也是根据该题目的题意来的,因为计算1-3的距离的时候,是计算两个小朋友顺时针以及逆时针的最小值。顺时针累加的时候,发现加了a3就超过sum / 2,此时计算1-4之间的距离的时候就不能用顺时针计算了,只能用逆时针来计算,因为此时计算1-4顺时针相加的时候是一定大于逆时针总和的。因此有理由推断3号小朋友一定是顺时针所能走到的最远的小朋友,因为3号小朋友再加上a3的时候就会超过总和的一半,超过总和的一般就要用逆时针来计算了,所以对于1号来说,顺时针最远的就是3号小朋友,逆时针最远的就是4号小朋友,因为逆时针加的时候,a5 + a4是小于总和的一半的,但再加上a3之后,此时就会超过总和的一半,超过一半之后,计算1-3号之间的距离就应该计算顺时针的方向,所以逆时针走的最远的应该是4号位置。所以顺时针累加的时候我们应该关心第一次出现 k >= sum / 2的情况,当找到了这样一个位置,顺时针走的最远和逆时针走的最远的位置就全部可以得知,这些知道之后就可以进而得知针对第i个人,距离他最远的那个人离他的距离是多少。针对所有的小朋友都找到这样的位置的话,该问题就解决了
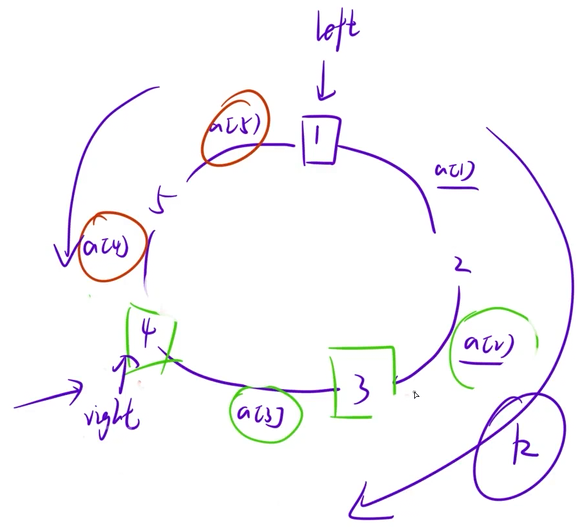
两层for循环,第一层for循环枚举起始位置left,第二层for循环枚举终止位置right,枚举的时候就从1号小朋友向后累加,k为left, right之间的距离,当right第一次扫描到k × 2 >= sum时,枚举的过程就停止,比如此时right指向4,之后计算顺时针的距离(a1 + a2 + a3),计算逆时针的距离(a4 + a5),在这两个距离之间取个max就是最终结果

数据范围1 ×10的5次方,两层for循环会超时,所以就要优化一下暴力解法,由于发现left向后移动一格之后,right指针也不用回退,因为我们已经维护出来left, right区间的信息,right回退也不是最优解
当我们发现暴力枚举的两个指针不回退 时,就可以用滑动窗口优化:
- 进窗口:right位置与前一个位置的距离累加到k中;
- 判断:k × 2 >= sum时,此时right不用前进,应该让left所指的元素出窗口
- 出窗口:让left所指的位置与前一个位置的距离累减到k中
这道题目更新结果需要在两个地方更新:
- 在right向后累加的过程中,窗口合法的情况是需要更新结果的,因为要把这段距离统计到最终结果中,用k来更新结果
- 当窗口不合法的时候(2k >= sum),就要用逆时针的那段距离来当作最远距离,逆时针的那段距离就是sum - k,逆时针的这段距离也有可能是最终结果

cpp
#include<iostream>
using namespace std;
const int N = 1e5 + 10;
typedef long long LL;
LL a[N];
int n;
int main()
{
cin >> n;
LL sum = 0;
for(int i = 1; i <= n; i++)
{
cin >> a[i];
sum += a[i];
}
int left = 1, right = 1;
LL k = 0, ret = 0;
while(right <= n)
{
//进窗口
k += a[right];
//判断
while(2 * k >= sum)
{
//更新结果
ret = max(ret, sum - k);
//出窗口
k -= a[left++];
}
ret = max(ret, k);
right++;
}
cout << ret << endl;
return 0;
}
补充一个点:
题目中距离和小于等于2147483647,但是计算2k的时候就有可能超出int的范围,所以直接用long long比较保险,且该题目要尤其注意类型匹配,在用max这个函数的时候,括号内两个值的类型一定要一样
结语
