摘要:自然语言处理(NLP)技术正在推动人工智能应用的快速发展。本文介绍了NLP的几大核心应用:机器翻译系统可分为双语和多语类型,实现方法包括直接翻译法、中间语言法、转换法和基于语料库的经验法;垃圾邮件识别利用词干提取、贝叶斯分类和N元语法等技术提高过滤精度;自动文本摘要帮助应对信息过载问题;智能问答系统致力于理解自然语言提问;情感分析技术可识别文本中的情感倾向,为企业提供消费者洞察。这些应用展现了NLP在人机交互中的重要作用。
目录
自然语言处理的应用
自然语言处理(NLP)是一门新兴技术,催生出了当下我们所见的各类人工智能应用。在如今和未来日益智能化的应用中,打造人类与机器之间流畅、交互式的交互界面,仍将是其核心发展重点。本文将介绍自然语言处理的几类实用应用方向。
机器翻译
机器翻译(MT)是将一种源语言或文本转换为另一种语言的过程,也是自然语言处理最重要的应用之一。我们可以通过流程图理解机器翻译的实现过程。
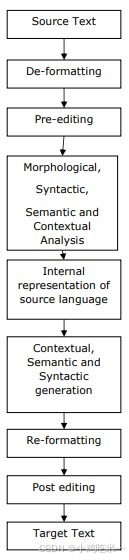
机器翻译系统的类型
机器翻译系统分为不同类型,具体如下:
- 双语机器翻译系统:仅实现两种特定语言之间的互译。
- 多语机器翻译系统:可实现任意语言对之间的翻译,翻译模式可为单向或双向。
机器翻译的实现方法
接下来介绍机器翻译的主流实现方法,具体包括以下四种:
-
直接翻译法这是机器翻译中最古老的方法,如今已较少使用。采用该方法的系统可将源语言直接转换为目标语言,这类系统均为双语单向翻译系统。
-
中间语言法 采用该方法的系统会先将源语言转换为一种名为 "中间语言(IL)" 的过渡语言,再将中间语言转换为目标语言,这一过程可通过机器翻译金字塔模型理解。
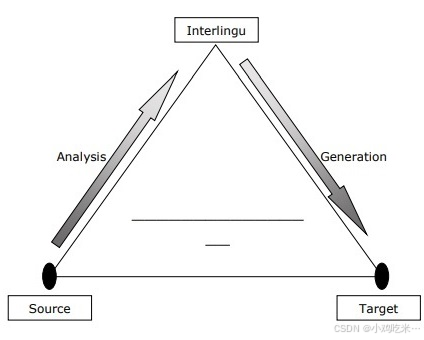
-
转换法 该方法的实现分为三个阶段:
- 第一阶段:将源语言文本转换为面向源语言的抽象表征形式;
- 第二阶段:将面向源语言的表征形式转换为对应的面向目标语言的表征形式;
- 第三阶段:生成目标语言的最终文本。
-
经验法这是机器翻译领域的新兴方法,核心是利用海量的平行语料库原始数据,这类数据包含文本及其对应的翻译版本。基于类比、实例、记忆的机器翻译技术,均采用了这一方法。
垃圾信息识别
如今,垃圾邮件是最常见的问题之一,这也让垃圾信息过滤器的重要性愈发凸显,它是抵御垃圾邮件的第一道防线。
借助自然语言处理的功能,结合垃圾信息识别中常见的误报、漏报问题,可开发出对应的垃圾信息过滤系统。
现有的垃圾信息过滤自然语言处理模型
目前主流的垃圾信息过滤自然语言处理模型主要有以下三种:
- 长度的 N 元语法,对垃圾邮件进行处理和识别。
- 词干提取垃圾邮件发送者通常会修改垃圾邮件中关键词的一个或多个字符,以此绕过基于内容的垃圾信息过滤器。这也意味着,若过滤器无法理解邮件中词汇或短语的语义,其过滤效果将大打折扣。为解决这一问题,研究人员开发出了基于规则的词干提取技术,该技术可匹配字形、发音相近的词汇,实现精准识别。
- 贝叶斯分类这是目前应用最广泛的垃圾信息过滤技术。该技术通过统计方法,将邮件中词汇的出现频次,与垃圾邮件、正常邮件数据库中词汇的典型出现频次进行对比,以此判断邮件是否为垃圾信息。
- N 元语法建模N 元语法指从较长字符串中截取的 N 个字符片段,该模型会同时使用多种不同
自动文本摘要
在数字化时代,最具价值的东西是数据,或者说信息。但我们真的能获取到有用且适量的信息吗?答案是否定的。信息过载的问题愈发严重,我们获取知识和信息的能力,早已超出了自身的理解和处理能力。面对网络上源源不断的信息,自动文本摘要技术的研发和应用已成为迫切需求。
文本摘要技术,指的是为长篇文本文档生成简洁、准确摘要的技术。自动文本摘要技术能让我们在更短时间内获取核心信息,而自然语言处理在自动文本摘要系统的研发中,发挥着关键作用。
智能问答
智能问答是自然语言处理的另一项核心应用。搜索引擎让我们得以触达全球的信息,但在解答人类用自然语言提出的问题时,仍存在明显不足。谷歌等大型科技企业也正致力于该领域的研究。
智能问答是人工智能和自然语言处理领域下的一个计算机科学分支,核心是构建能自动解答人类自然语言问题的系统。一个能理解自然语言的计算机系统,可将人类的语句转换为内部表征形式,进而生成有效的答案。系统可通过对问题进行句法和语义分析,给出精准答案。词汇空缺、语义模糊以及多语言差异,是自然语言处理技术在构建优质智能问答系统时面临的主要挑战。
情感分析
情感分析是自然语言处理的又一重要应用。顾名思义,情感分析可识别各类帖子中所蕴含的情感倾向,即便情感未被明确表达,也能通过该技术精准识别。
企业正借助自然语言处理的这一应用,分析网络上消费者对自身的观点和情感倾向,以此了解消费者对产品和服务的评价,进而判断企业的整体口碑。由此可见,情感分析不仅能判断简单的情感极性,还能结合语境理解深层情感,让我们更透彻地把握表达背后的真实想法。
保存图片
编辑图片
移除物体
提取文字
图片翻译