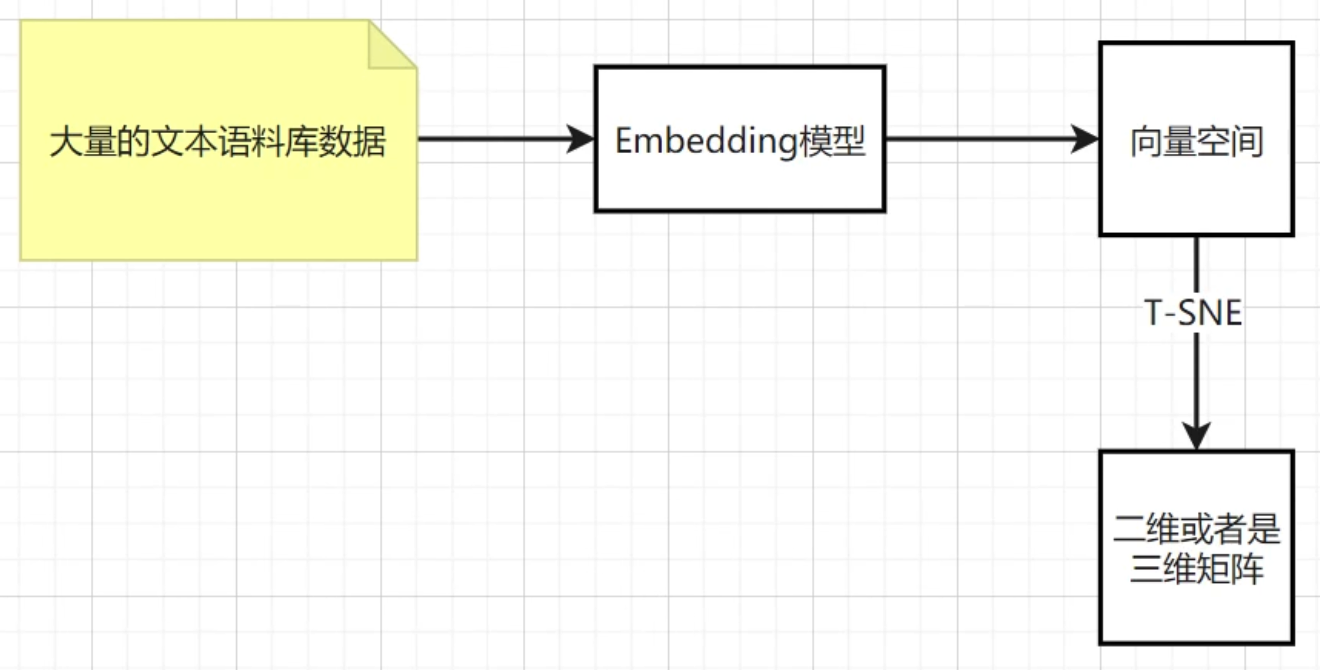
Embedding 模型
- [First Of All](#First Of All)
- 一、计算机中数据的本质
- 二、表示学习和嵌入
-
- [2.1 表示学习(Representation Learning)](#2.1 表示学习(Representation Learning))
- [2.2 嵌入(Embedding)](#2.2 嵌入(Embedding))
- [2.3 两者的关系](#2.3 两者的关系)
- [三、分词器(Tokenizer):所有 Embedding 的起点](#三、分词器(Tokenizer):所有 Embedding 的起点)
-
- [3.1 本质定义](#3.1 本质定义)
- [3.2 不同类型数据的"分词"](#3.2 不同类型数据的"分词")
- [3.3 核心共性](#3.3 核心共性)
- [3.4 模型中的分词器](#3.4 模型中的分词器)
- [四、词嵌入 vs. 文本嵌入:演进关系](#四、词嵌入 vs. 文本嵌入:演进关系)
-
- [4.1 词嵌入 (Word Embedding)](#4.1 词嵌入 (Word Embedding))
- [4.2 文本嵌入 (Text Embedding)](#4.2 文本嵌入 (Text Embedding))
- [4.3 演进关系图](#4.3 演进关系图)
- [五、图嵌入 (Graph Embedding):不同于文本的逻辑](#五、图嵌入 (Graph Embedding):不同于文本的逻辑)
-
- [5.1 与分词器的关系](#5.1 与分词器的关系)
- [5.2 图嵌入的工作原理](#5.2 图嵌入的工作原理)
- [5.3 关键区别](#5.3 关键区别)
- 六、其他类型的嵌入
-
- [6.1 图像嵌入 (Image Embedding)](#6.1 图像嵌入 (Image Embedding))
- [6.2 代码嵌入 (Code Embedding)](#6.2 代码嵌入 (Code Embedding))
- [6.3 多模态嵌入 (Multi-modal Embedding)](#6.3 多模态嵌入 (Multi-modal Embedding))
- 四、Text-embedding系列模型
First Of All
txt
应用层 → 相似度搜索、RAG、推荐系统
↑
嵌入层 → 词嵌入、文本嵌入、图嵌入、多模态嵌入
↑
预处理层 → 分词器(Tokenizer)、图采样器
↑
原始数据层 → 文本、图像、图谱一、计算机中数据的本质
从应用开发的角度,你需要掌握三种数据形态,它们对应着不同的交互方式:
-
自然语言文本 ------ 最直接的接口
本质:人类思想的序列化表达模型如何处理:分词(Tokenization)→ 转换为Token ID序列 → 通过嵌入层转为向量 → 在Transformer中通过注意力机制捕捉上下文关系
你的视角:这是你与大模型对话的界面。你写的Prompt本质上是在引导模型进入特定的概率空间。
-
嵌入向量(Embeddings) ------ 模型的"思维语言"
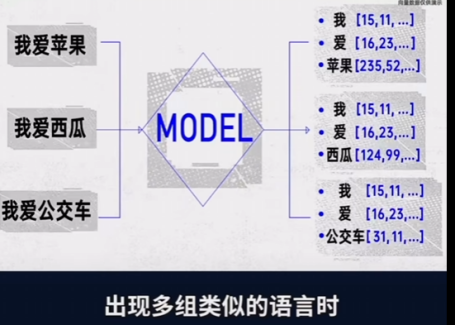
本质:语义在数学空间中的坐标关键洞察:当你把"猫"这个词输入模型,它首先被映射到一个高维向量(比如 0.2, -0.5, 0.8, ...)。这个向量的位置决定了模型如何"理解"猫------它靠近"狗"、"宠物"、"动物",远离"桌子"、"汽车"。
应用价值 :你可以直接操作这个向量空间来实现语义搜索、聚类、推荐等。这是RAG(检索增强生成)的核心基础。
-
概率分布 ------ 模型的"决策依据"
本质:模型输出的是一个概率分布(下一个词的可能性分布),而不是确定的答案你的视角:Temperature、Top-p这些参数都是在操作这个分布------让它更集中(确定性高)或更分散(创造性高)
二、表示学习和嵌入
2.1 表示学习(Representation Learning)
表示学习(Representation Learning) 是指自动从原始数据中学习出能够有效表达数据内在语义的特征或表示的过程。传统的机器学习依赖人工设计的特征(特征工程),而表示学习通过模型自动发现数据中有利于分类、回归等任务的高层抽象特征。
-
目标:将原始数据(如像素、单词、用户ID)转换为低维、稠密、有意义的向量,使得相似的输入在表示空间中彼此靠近。
-
优势:减少手工特征设计的工作量,提高模型的泛化能力,能捕捉到数据中隐含的结构信息。
例如,对于一张猫的图片,表示学习模型(如卷积神经网络)可以提取出"耳朵形状"、"毛色纹理"等高层次特征,而不是直接使用像素值。
2.2 嵌入(Embedding)
嵌入(Embedding) 是一种将离散变量(如单词、商品ID、图中的节点)映射到连续向量空间的技术。这个向量通常维度较低(几十到几百维),且每个维度没有显式的物理意义,但整体能反映对象之间的语义关系。
-
形式:每个离散对象被表示为一个固定长度的稠密向量,例如词向量
"king" → [0.2, 0.5, -0.1, ...]。 -
特点:向量空间中的距离(如余弦相似度)可以衡量对象之间的相似性;向量运算也能捕捉类比关系(如
"king" - "man" + "woman" ≈ "queen")。
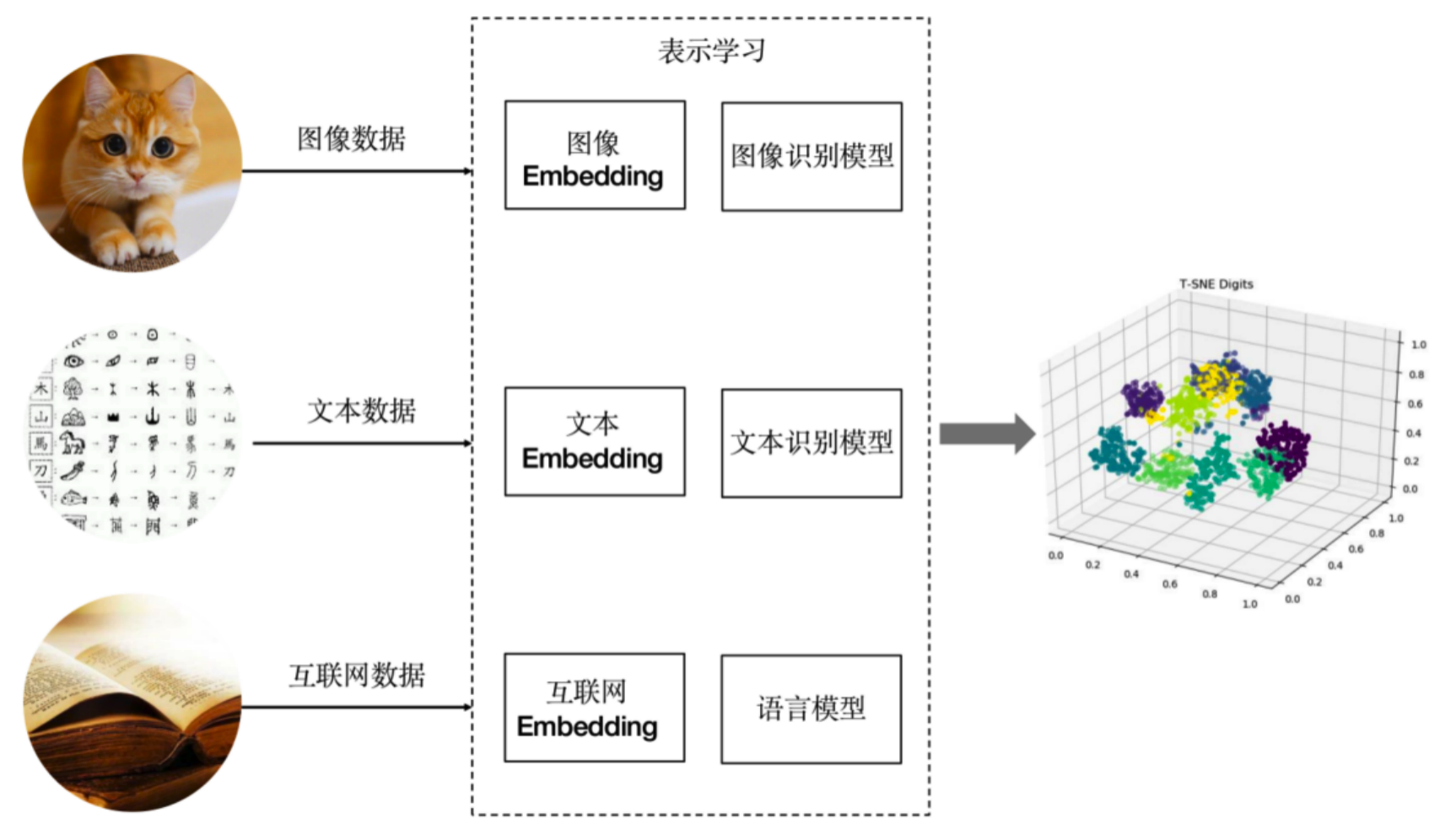
嵌入本质上是表示学习的一种具体产物------它学习到的向量就是原始对象的"表示"。嵌入是表示学习的一种特定形式,旨在将高维数据映射到低维空间中的向量表示:
- 词嵌入(Word Embedding):在自然语言处理中,词嵌人将词语映射到低维向量空间,以捕捉词语之间的语义和句法关系。通过学习词嵌入,可以将词语表示为连续的向量,其中相似的词语在向量空间中彼此靠近.它在自然语言处理任务中广泛应用,包括词语相似度计算、文本分类、命名实体识别等。词嵌人可以通过Word2Vec、 GloVe 等方法进行学习。
- 图像嵌入(lmage Embedding):在图像处理中,图像嵌人将图像映射到低维向量空间,以表示图像的视觉特征.这种嵌人方法通常通过使用卷积神经网络 (Convolutional Neural Networks, CNN) 等深度学习技术来提取图像的特征表示。
- 图嵌入(Graph Embedding):是用于学习图结构的表示学习方法,将图中的节点和边映射到低维向量空间中,通过学习图嵌入,可以将复杂的图结构转化为向量表示,以捕捉节点之间的结构和关联关系。这些方法可以通过DeepWalk、 Node2Vec. GraphSAGE等算法来实现.图嵌入在图分析、社交网络分析、推荐系统等领域中广泛应用,用于发现社区结构、节点相似性、信息传播等图属性.
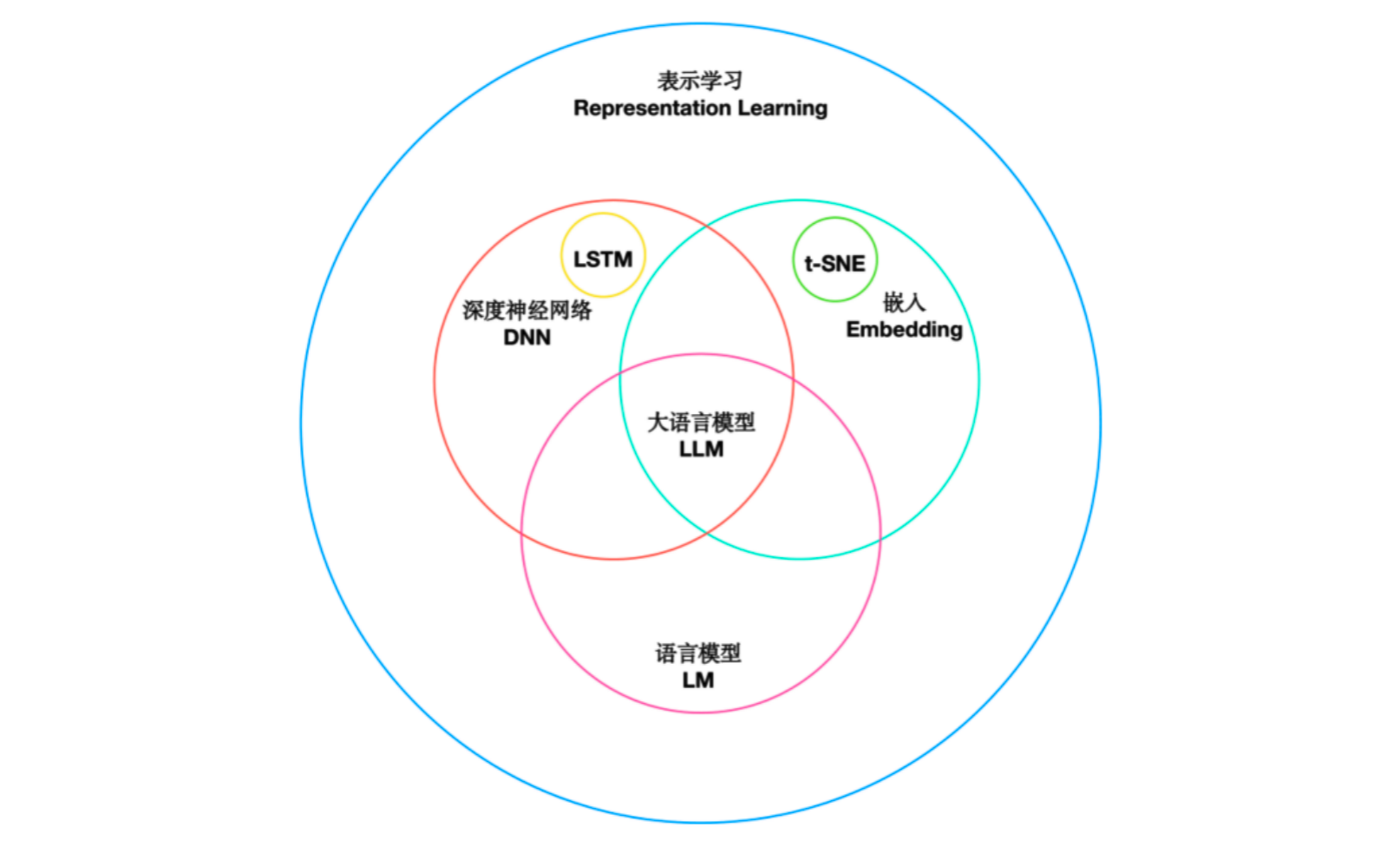
2.3 两者的关系
表示学习与嵌入的关系
表示学习是一个更广泛的概念:它涵盖任何从数据中自动学习特征的方法,包括深度神经网络的中间层输出、自编码器学到的隐编码、对比学习得到的特征等。
嵌入是表示学习的一种特定形式或结果:通常用于将离散符号(如词、节点、用户)映射到连续空间。可以说,嵌入是一种离散对象的表示学习。
举例:
- 在自然语言处理中,Word2Vec、GloVe 等模型学习到的词向量就是词嵌入,这些向量是词的表示。
- 在图中,Node2Vec、GraphSAGE 等模型学习到的节点向量是图嵌入,属于节点级别的表示学习。
- 在图像分类中,卷积神经网络最后一层全连接层之前的特征图,也可视为图像的一种稠密表示,但它通常不被称为"嵌入"(虽然本质相同)。
嵌入就是一种表示学习:
三、分词器(Tokenizer):所有 Embedding 的起点
3.1 本质定义
分词器是原始数据到离散符号序列的转换器,是 Embedding 系统的"前端接口"。
3.2 不同类型数据的"分词"
| 数据类型 | 分词/采样器 | 输出单元 | 类比 |
|---|---|---|---|
| 文本 | Tokenizer | Token (词/子词/字符) | 切分句子为单词 |
| 图像 | Patch Embedding | Patch (图像块) | 切分图片为小块 |
| 图 | 邻域采样器 | 节点 + 邻居序列 | 抽取节点及关联节点 |
| 音频 | FFT/STFT | 音频帧/梅尔谱 | 切分音轨为时间片 |
| 代码 | AST Parser | 抽象语法树节点 | 解析代码结构 |
3.3 核心共性
无论什么数据类型,预处理层都在做同一件事:将非结构化、变长的原始数据,转换为结构化的、模型可处理的离散单元序列。
3.4 模型中的分词器
| 编码名称 | OpenAI模型 |
|---|---|
| cl100k_base | gpt-4, gpt-3.5-turbo, text-embedding-ada-002 |
| p50k_base | Codex模型, text-davinci-002, text-davinci-003 |
| r50k_base | 像davinci 这样的GPT-3模型 |
从工程视角来看,cl100k_base 的设计与 text-embedding-v4 的推测形成有趣的对照:
| 对比维度 | text-embedding-ada-002 (OpenAI) | text-embedding-v4 (通义千问) - 推测 |
|---|---|---|
| 分词器 | 明确为 cl100k_base | 推测为 Qwen3 系列分词器(BPE 变体) |
| 词表规模 | 约 100k | 推测约 150k(Qwen 系列对中文更友好) |
| 最大 Token | 8,192 | 8,192 |
| 多语言支持 | 强,字节级保证全覆盖 | 强,针对中英文优化 |
四、词嵌入 vs. 文本嵌入:演进关系
4.1 词嵌入 (Word Embedding)
python
word_vocab = {"我": 0, "爱": 1, "编程": 2}
word_embedding_table = [[0.1, 0.2], [0.3, 0.4], [0.5, 0.6]]
"爱" → token_id=1 → lookup → [0.3, 0.4] # 静态的- 粒度:单词级
- 输出:查找表,每个词固定向量
- 局限性:一词多义无法区分 ("bank" 永远一样)
- 代表:Word2Vec, GloVe
4.2 文本嵌入 (Text Embedding)
python
# 伪代码示意
"我爱编程" → tokenizer → [0, 1, 2] → Transformer → [0.23, 0.67, ...] # 动态的- 粒度:句子/段落/文档级
- 输出:变长输入 → 定长向量
- 优势:上下文感知,"bank" 在句子中动态理解
- 代表:Sentence-BERT, OpenAI Ada, 通义 text-embedding
4.3 演进关系图
text
词嵌入(静态) 文本嵌入(动态)
↓ ↓
每个词独立向量 → Transformer融合上下文
↓ ↓
句子向量 = 平均 句子向量 = 整体语义编码关键演进:从"词汇的独立表示"到"语义的整体编码",解决了一词多义和长文本理解问题。
五、图嵌入 (Graph Embedding):不同于文本的逻辑
5.1 与分词器的关系
图嵌入没有直接对应的"分词器",但有"图采样器"。
| 对比项 | 文本嵌入 | 图嵌入 |
|---|---|---|
| 原始数据 | 线性文本 | 网状图结构 |
| 预处理 | Tokenizer(切分) | 邻域采样/随机游走 |
| 输入单元 | Token序列 | 节点序列/子图 |
| 核心逻辑 | 上下文窗口 | 邻域聚合 |
5.2 图嵌入的工作原理
python
# 伪代码:图采样(类比文本分词)
原始图: A - B, A - C, B - D
# 对节点A采样(随机游走)
walk = random_walk(start=A, length=3)
→ [A, B, D] # 得到一个"节点序列"
# 对这个序列做嵌入
[A, B, D] → GraphEmbedding → [0.1, 0.5, ...]5.3 关键区别
| 维度 | 文本嵌入 | 图嵌入 |
|---|---|---|
| 数据结构 | 线性序列 | 图结构(可能有环) |
| 上下文定义 | 前后相邻的词 | 相邻的节点(邻居) |
| 采样逻辑 | 滑动窗口 | 随机游走/邻域采样 |
| 核心原则 | "词由周围词决定" | "节点由邻居决定" |
六、其他类型的嵌入
6.1 图像嵌入 (Image Embedding)
-
预处理:将图片切分为 Patches (ViT) 或通过 CNN 提取特征图
-
代表:CLIP,Vision Transformer (ViT)
-
与分词类比:把图片"切"成固定大小的方块,每个方块类似一个"视觉词"
6.2 代码嵌入 (Code Embedding)
-
预处理:解析为抽象语法树(AST),提取节点序列
-
代表:CodeBERT,GraphCodeBERT
-
特点:既要理解语义,又要理解代码结构(数据流、控制流)
6.3 多模态嵌入 (Multi-modal Embedding)
-
核心:将不同模态的数据映射到同一个向量空间
-
代表:CLIP (文本+图像)
-
关键:文本分词器 + 图像Patch嵌入 → 对比学习对齐
四、Text-embedding系列模型
文本嵌入(Text Embedding)是将文本数据(如单词、句子、段落)转换为固定长度的实数向量的技术。这个向量能够捕获文本中的语义信息,使得语义相似的文本在向量空间中彼此靠近。
核心价值:文本嵌入是连接人类语言与机器学习模型的桥梁。通过这种转换,计算机能够进行语义搜索、文本分类、聚类等操作,而不仅仅是关键词匹配。