说实话, "vibe coding"最近应该是很多人的真实状态 ------对着 Cursor 或 Claude 或trae 一顿提示词输出,以为跑起来就算赢,最后出了问题之后却一脸懵逼。
这篇文章想给你补上一套心智模型:知道 AI 在做什么、会在哪里坏、为什么坏。15 个概念,每一个都直接对应一类常见翻车场景。
1. System Prompts(系统提示词)
 System prompt 是规则层,user message 是任务层,不要混在一起。
System prompt 是规则层,user message 是任务层,不要混在一起。
| 放在 System Prompt | 放在 User Message |
|---|---|
| 角色定义 | 具体任务 |
| 语气和风格要求 | 当前输入的内容 |
| 输出格式规范 | 本次的特殊要求 |
| 禁止行为 | 上下文补充 |
反面示例------把规则扔进用户消息:
arduino
你是一个资深 Python 工程师,只写 Python 3.10+ 的代码,
不用 print 调试,所有函数必须有类型注解。
帮我写一个解析 JSON 的函数。这样写,规则只在第一轮有效。对话继续,模型慢慢"忘记"规则,行为开始飘。
正确做法: 规则一次性写进 system prompt,之后每轮对话都自动生效,不用重复说。
2. Context Window(上下文窗口)

模型只能看到窗口里的内容,窗口之外什么都不知道。
你在对话开头描述过的架构?50 条消息之后,它已经"忘了"。这不是 bug,是基本工作原理。
把它想象成一个只能看到桌面上文件的人------桌面放得下多少,它就能看多少,桌面之外的东西对它不存在。
vibe coder 最常犯的错:
把整个项目文件夹都粘进去,以为"上下文越多越好"。实际上,无关信息越多,有效信息被稀释得越严重,模型越容易给出偏离目标的回答。
实用原则:
- 只传当前任务真正需要的文件
- 长对话中途要主动总结一次,把关键上下文重新注入
- system prompt 保持精简,不要把所有背景信息都堆在这里
3. Few-shot Prompting(少样本提示)

在让模型做正式任务之前,先给它看 2-3 个你期望的例子。 这是提升输出质量投入产出比最高的方式。
没有示例------模型自由发挥:
帮我写这个函数的注释。加了示例------模型知道你要什么:
python
帮我写这个函数的注释,格式参考下面的例子:
# 示例 1
def calculate_tax(amount: float, rate: float) -> float:
"""
计算税额。
Args:
amount: 税前金额(元)
rate: 税率(0~1 之间的小数)
Returns:
应缴税额(元)
"""
# 示例 2
def validate_email(email: str) -> bool:
"""
验证邮箱格式是否合法。
Args:
email: 待验证的邮箱字符串
Returns:
格式合法返回 True,否则返回 False
"""
# 现在请为下面的函数写注释:
def parse_config(filepath: str) -> dict:
...给了例子之后,格式、风格、细节层级全部对齐,几乎不需要二次修改。
4. Prompt Chaining(提示词链)
一个提示词只做一件事。 大任务拆成链,上一步的输出是下一步的输入。
很多 vibe coder 会写一个"全能提示词",期望 AI 一口气搞定所有事------这几乎必然失败,而且你根本不知道失败在哪一步。
错误方式:
帮我读取这个 CSV 文件,清洗数据,分析趋势,然后生成一份带图表的报告,
最后把结论总结成三条要点发给我。正确方式------先在脑子里画流程:
步骤 1:读取并清洗 CSV → 输出干净的结构化数据
↓
步骤 2:分析趋势 → 输出关键数据点
↓
步骤 3:生成图表代码 → 输出可运行的 Python 代码
↓
步骤 4:总结三条结论 → 输出最终报告每一步单独跑,单独检查。哪步出问题,一眼就看出来。
5. Temperature(温度参数)
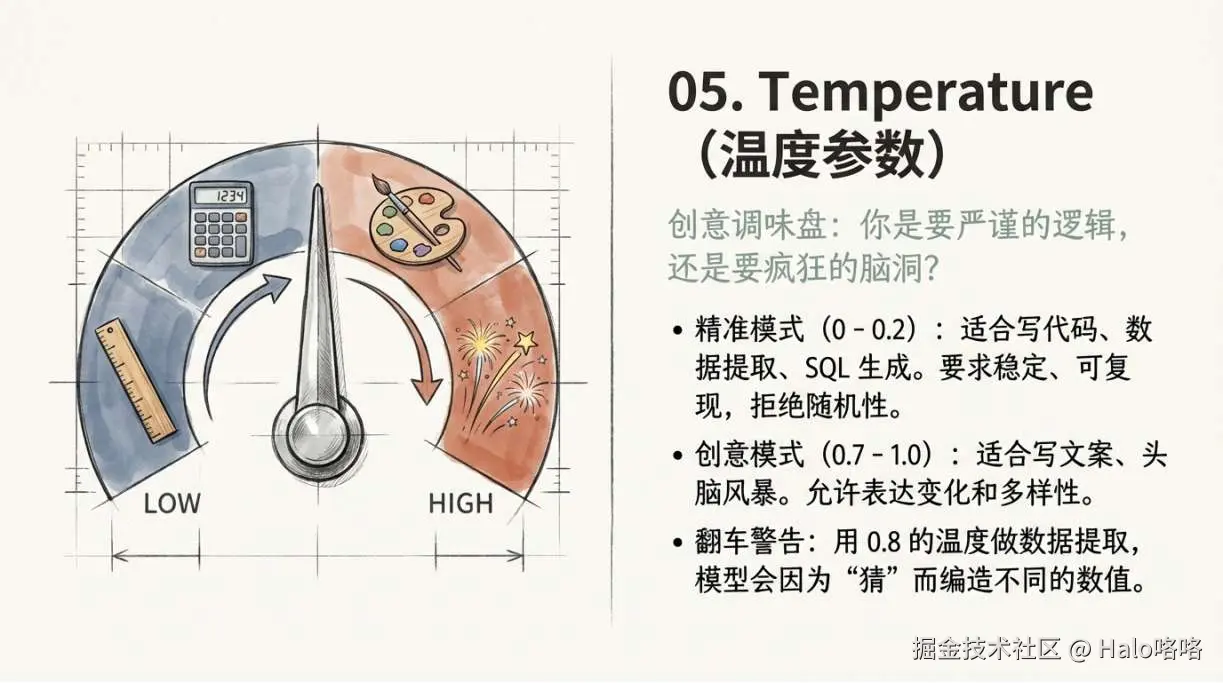
一个参数,两种场景,用错了结果会很离谱。
| 场景 | 推荐 Temperature | 原因 |
|---|---|---|
| 写代码、生成 SQL | 0 ~ 0.2 | 要求准确稳定,不需要创意 |
| 数据提取、格式转换 | 0 ~ 0.1 | 必须可复现,高随机性会编造数据 |
| 写文案、头脑风暴 | 0.7 ~ 1.0 | 需要多样性和创意 |
| 技术文档翻译 | 0.2 ~ 0.4 | 准确为主,允许少量表达变化 |
典型翻车场景: 用 temperature 0.8 做数据提取,同一段文本跑两次,提取出来的字段值不一样------因为模型在"猜"不确定的内容时加入了随机性。把 temperature 调到 0,问题消失。
6. Token Limits(Token 限制)

Token 是预算,输入 + 输出共享,每个 token 都要花钱和时间。
很多 vibe coder 在 Cursor 里遇到"上下文满了"的报错,根本原因就是 token 用超了。
几个数字感受一下:
- 1000 个汉字 ≈ 1500 token
- GPT-4o 的上下文上限:128,000 token
- 一个中等规模的代码文件(500 行)≈ 3,000~5,000 token
- 把 10 个这样的文件都塞进去:轻松用掉 50,000 token
实用原则:
- 不要把整个代码库粘进去,只粘相关文件
- 长对话要及时开新会话,避免历史记录把窗口撑满
- system prompt 写精简,每轮对话都要消耗这些 token
7. Hallucination(幻觉)

模型会用极其自信的语气说出完全错误的事情,这是特性,不是 bug。
用 Cursor 写代码时最常见的幻觉:
- 调用了一个根本不存在的库函数(API 是编造的)
- 引用了某个框架的"最新版本特性",但那个版本还没发布
- 生成的正则表达式看起来完全正确,但有一个边界情况会静默失败
处理原则:
把 AI 生成的代码当作"第一稿",不是"最终答案"。关键逻辑必须跑一遍,涉及第三方 API 的调用必须查文档核对,不能只看"看起来对"就直接上线。
8. RAG(检索增强生成)
模型只知道训练数据里有的东西,你的业务文档、最新 API 文档、私有代码库------它一概不知。RAG 是标准解法。
工作原理:
你的文档库
↓
切成小块 → 转成向量 → 存入向量数据库
↓
用户提问
↓
检索最相关的几块文档
↓
文档块 + 用户问题 → 一起送给模型
↓
模型基于真实文档回答vibe coder 最常犯的错: 把整个文档库全塞进上下文。10 篇文档还好,100 篇文档直接把窗口撑爆,成本飙升,准确率反而下降。
RAG 的核心价值是"按需检索"------只把跟这个问题相关的内容给模型看。
9. Chunking(文档分块)
长文档必须切分,但怎么切,差别很大。
| 切法 | 问题 |
|---|---|
| 每 100 token 切一块 | 块太小,单块读起来没有完整含义 |
| 每 5000 token 切一块 | 块太大,检索精度低,不相关内容太多 |
| 从句子中间切断 | 语义直接损坏,模型无法理解 |
| 每 500 token,相邻块重叠 100 token | 推荐方案,保证语义完整 |
重叠的那 100 token 是关键------它保证了条款或段落在边界处不会被硬切断,模型拿到的每一块都是可以独立理解的完整内容。
10. Embeddings(向量嵌入)
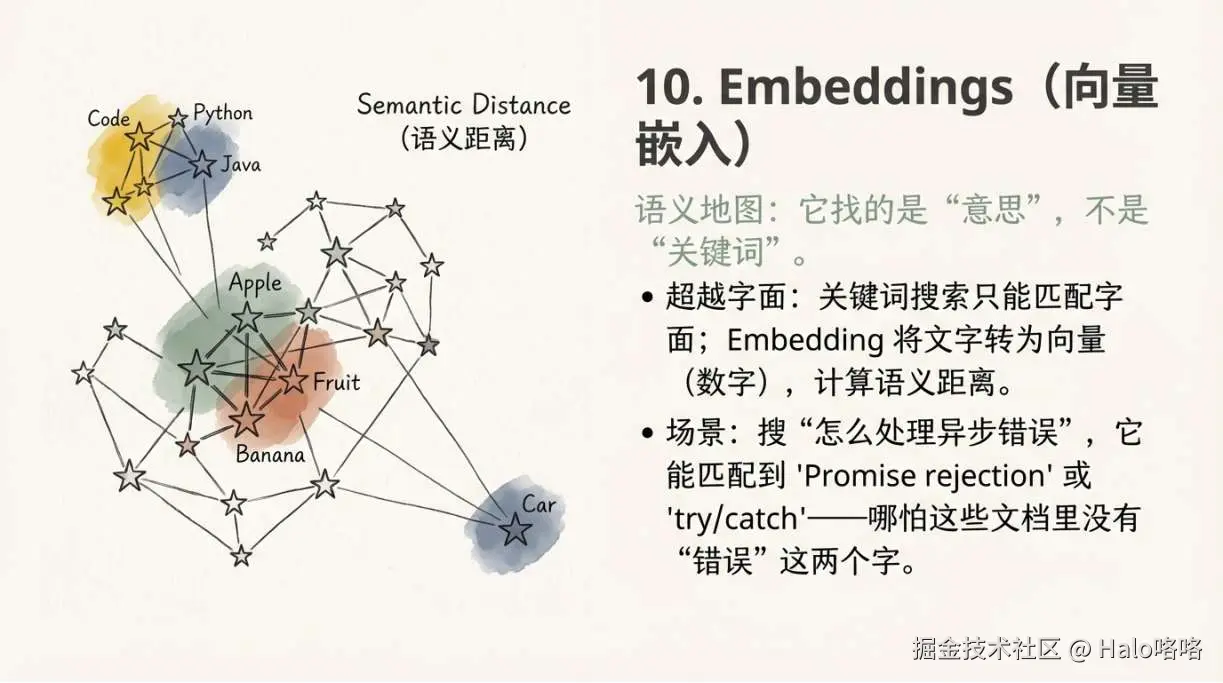
关键词搜索找关键词,Embedding 找语义。
用 Cursor 问"怎么处理异步错误",关键词搜索可能匹配到"async 关键词"相关文档;Embedding 搜索会匹配到"Promise rejection handling"、"try/catch in async functions"------因为语义相近,即使词完全不同。
一句话理解: Embedding 把文字转成一堆数字(向量),语义相近的文字,向量距离就近。这是 RAG 系统里检索质量的核心。
还在用关键词搜索处理语义问题的,正在白白浪费检索质量。
11. Function Calling(函数调用)
普通对话模式下,模型只能返回文字。Function calling 让模型返回"调用哪个函数、传哪些参数"的结构化指令,然后由你的代码真正执行。
json
用户说:"帮我查一下订单 #12345 的状态"
模型返回:
{
"function": "get_order_status",
"arguments": {
"order_id": "12345"
}
}
你的代码拿到这个结果,去调用真实的数据库或 API核心安全原则: 模型返回的参数,必须在执行前验证。
ini
# 危险写法------直接执行模型返回的内容
result = eval(model_output) # 永远不要这样做
# 安全写法------验证后再执行
if model_output["function"] in ALLOWED_FUNCTIONS:
if validate_args(model_output["arguments"]):
result = ALLOWED_FUNCTIONS[model_output["function"]](**model_output["arguments"])模型可以生成任意参数,你的代码是最后一道防线。
12. Agent Loops(智能体循环)
Agent 的工作模式:制定计划 → 执行动作 → 观察结果 → 决定下一步,循环往复,不需要你每次手动触发。
arduino
用户目标:"帮我重构这个模块,让测试全部通过"
Agent 循环:
① 读取代码,分析问题
② 修改代码
③ 运行测试,观察结果
④ 测试还有失败?→ 回到 ②
全部通过?→ 结束没有护栏的后果: Agent 遇到循环 bug,反复修改、反复失败,跑了 50 步还没停,把整个模块改得面目全非。
必须设置的三个护栏:
- 最大步数上限(比如 15 步)
- 每步操作写日志,方便排查
- 涉及文件删除、数据库写入等破坏性操作,强制暂停等待确认
13. Streaming Outputs(流式输出)
不要等完整响应生成完再显示,边生成边展示,用户体验天壤之别。
| 非流式 | 流式 | |
|---|---|---|
| 用户看到内容的时间 | 等 6~10 秒后突然出现 | 0.5 秒内开始逐字出现 |
| 用户感知 | "不知道有没有在工作" | "基本秒回" |
| 实际生成时间 | 相同 | 相同 |
感知速度和实际速度是两件事。Streaming 解决的是前者,实现成本很低,但对用户留存的影响非常显著。
实现时注意:
- 流式传输 JSON 时要处理不完整的数据块,不能直接
JSON.parse每一个 chunk - 连接中断时要有重连或降级逻辑
- 不能假设第一个 chunk 就是合法的完整响应
14. Evals(评估测试)
Evals 是 AI 层的单元测试:给定输入,有明确的预期输出,每次改了提示词就跑一遍。
很多 vibe coder 改了提示词直接上线,等到用户反馈才发现出了问题。
一个最简单的 eval 长这样:
| 输入 | 预期输出 | 实际输出 | 通过? |
|---|---|---|---|
| "帮我解释这段报错" | 包含错误原因和修复建议 | ✓ | ✅ |
| "帮我优化这个函数" | 返回优化后的代码,不改变功能 | 改变了返回值类型 | ❌ |
| 空字符串输入 | 返回提示,不报错 | 抛出异常 | ❌ |
建一个 20-50 条的测试集,覆盖核心场景和边界情况。每次改提示词或换模型前跑一遍,5 分钟就能发现问题,比上线后被用户投诉强多了。
15. Guardrails(护栏)

System prompt 的约束在生产环境里不够用,需要独立的验证层。
光靠 system prompt,用户可以用各种方式绕过去。护栏要加在 AI 层之外,独立运作。
三层护栏结构:
用户输入
↓
① 输入过滤层(拦截明显违规的输入)
↓
模型处理
↓
② 输出验证层(schema 校验、格式检查、敏感内容过滤)
↓
③ 操作权限层(写操作白名单、影响范围限制)
↓
最终输出给用户对于面向真实用户的产品,如果模型输出没有经过任何验证就直接展示,就是在赌运气。
真实案例:用 Cursor 搭一个 AI 代码审查机器人
光看概念还不够,下面用一个 vibe coder 真实会做的项目,把这些概念串起来。
场景: 你在用 Cursor 开发,想搭一个 GitHub bot,每次有人提 PR,自动审查代码质量,给出评论。
第一步:想清楚任务怎么拆(Prompt Chaining)
一口气让 AI "审查代码并给出所有建议",输出会很乱。拆成三步:
步骤 1:读取 PR diff → 识别改动了哪些文件、哪些函数
↓
步骤 2:针对每个改动,逐一分析问题(命名、复杂度、潜在 bug)
↓
步骤 3:把所有问题整理成结构化评论,按严重程度排序第二步:写 system prompt(System Prompts + Temperature)
diff
你是一个资深代码审查员,专注于 Python 代码质量。
审查原则:
- 只指出真实存在的问题,不要为了评论而评论
- 每条评论必须包含:问题描述、影响、修改建议
- 严重程度分三级:critical / warning / suggestion
- 不评论代码风格(格式问题由 linter 处理)
- 如果改动没有问题,直接返回 {"issues": []}
输出格式为 JSON,不要包含任何解释文字。Temperature 设为 0.1------代码审查要稳定准确,不需要创意。
第三步:控制传入的代码量(Token Limits + Context Window)
一个 PR 可能改动 20 个文件,全塞进去 token 会爆。只传:
- 被修改的文件(不传未修改的)
- 每个文件只传改动的函数,加上函数的前后 10 行上下文
平均每次请求控制在 4,000 token 以内,响应时间 2~3 秒,成本可控。
第四步:加防幻觉验证(Hallucination + Evals)
AI 有时候会"发明"一个不存在的问题,比如说"第 47 行有个未处理的异常",但实际上那行代码完全正常。
验证方式:
bash
for issue in ai_response["issues"]:
# 验证行号是否真实存在于 diff 中
if issue["line"] not in actual_diff_lines:
filtered_issues.append(issue) # 过滤掉幻觉问题Eval 测试集准备 30 个已知答案的代码片段,每次改提示词后跑一遍,确认漏报率和误报率没有退化。
第五步:让评论实时出现(Streaming Outputs)
审查大 PR 时,完整响应可能要 8~10 秒。改成 Streaming,每分析完一个问题就立刻推送到 GitHub 评论,用户不用等全部分析完才看到结果。
最终效果:
- 每个 PR 平均审查时间:从人工 15~30 分钟,降到 AI 自动 20 秒
- 发现问题类型:命名不规范、潜在空指针、重复逻辑、缺少错误处理
- 误报率(经过验证层过滤后):约 8%,团队认为在可接受范围
这个项目用了 15 个概念里的 8 个。剩下的 RAG、Embeddings、Chunking、Agent Loops、Function Calling、Guardrails 留给下一阶段------比如让 bot 能查历史代码规范文档、自动修复简单问题。
现阶段不需要的,就不加。过度设计是 vibe coder 的另一个常见病。
理解系统在做什么、会在哪里失败,是从"vibe coder"升级为"工程师"的真正分水岭。