当我们在讨论大模型未来时,一个无法回避的问题是:那个撑起整个AI江山的Transformer,是否已经触及了自己的极限?
这个问题的答案,不仅关乎技术演进的方向,更直接影响着整个AI产业的投入产出比和发展预期。要回答这个问题,我们需要从Transformer的技术原理出发,深入剖析其核心局限,同时审视学术界和产业界正在探索的突破路径。
一、Transformer为何能成为AI的"绝对王者"
要理解Transformer是否触及天花板,首先需要理解它为何能够登上王座。
2017年,Google团队发表了改变AI进程的论文《Attention Is All You Need》 ,提出了Transformer架构。在此之前,自然语言处理领域的主流模型是RNN(循环神经网络)和LSTM,它们处理信息的方式像是一个勤恳的阅读者,必须按顺序逐字阅读,这种"顺序阅读"的机制不仅效率低下,更难以捕捉长距离的语义关联------当句子过长时,早期的信息往往已经被后续信息"稀释"得所剩无几。
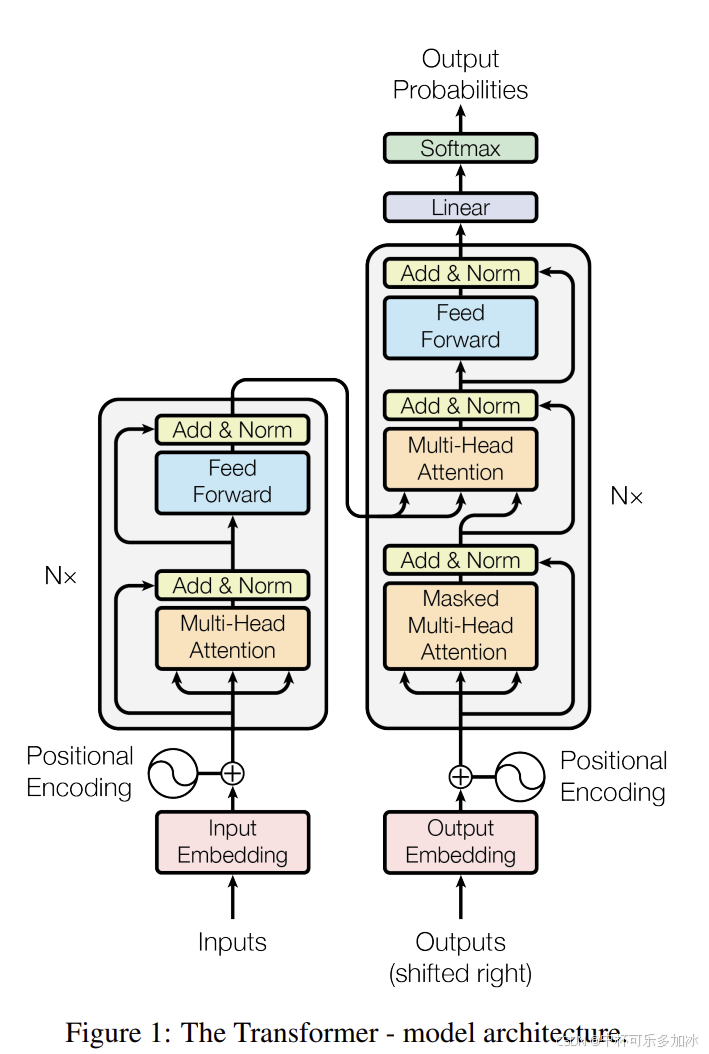
Transformer的核心创新在于自注意力机制(Self-Attention)。这个机制允许模型在处理每个词时,同时"关注"句子中的所有其他词,计算它们之间的相关性强度。换句话说,Transformer不再是逐字阅读,而是能够在阅读当前词的同时,瞬间理解它与句子中所有其他词的关系。这种并行处理的方式,让Transformer在处理长文本时展现出惊人的能力。
更关键的是,Transformer采用了一种被称为**"下一个词预测"(Next Token Prediction)的训练范式。模型通过学习预测序列中下一个最可能出现的词,不断强化自己的语言理解能力。这种看似简单的训练方式,在足够大规模的数据和参数支撑下,涌现出了令人震惊的智能行为------这就是所谓的Scaling Law(尺度定律)**。
Scaling Law的核心发现是:大语言模型的最终性能主要与计算量、模型参数量和训练数据量的规模相关,而与模型的具体结构(如层数、深度或宽度)基本无关。
只要不断增加模型规模、数据量和计算资源,模型的性能就会相应提升,并且这种提升呈幂律关系。正是在这一法则的指引下,从BERT到GPT系列,从GPT-3到GPT-4,Transformer架构一路高歌猛进,最终成就了今天大模型的盛世。
然而,当模型的参数突破千亿,当上下文窗口拉到数万token,当我们都望它能像人类一样进行复杂推理时,Transformer的局限开始逐一暴露。
二、Transformer的三大核心局限
1. 计算复杂度:二次增长的算力枷锁
Transformer的核心计算瓶颈在于其自注意力机制的计算复杂度随序列长度呈二次方增长。这意味着,当输入序列长度增加32倍时,计算量可能会增长近1000倍。
具体来说,假设输入序列长度为N,注意力机制需要计算N×N个token对之间的关系,每一对都需要进行矩阵乘法运算。对于短文本来说,这并不构成问题;但当我们需要处理长文档、长对话甚至整个代码库时,这个复杂度就成了不可承受之重。
这种二次复杂度带来的直接后果是:
- 训练成本飙升:有研究预测,到2030年训练前沿AI模型将需要近2000万颗H100级别的GPU
- 推理延迟高:长序列处理时,模型响应时间变得难以接受
- 端侧部署困难:移动端、边缘设备根本无法承载这种计算量
这不只是效率问题,更是制约Transformer进一步普及和规模扩展的根本性瓶颈。当算力成本成为制约因素,单纯通过增大模型规模来提升性能的道路就变得不再可持续。
2. 组合能力缺陷:无法完成"嵌套推理"
如果说计算效率问题是"跑得慢",那么组合能力缺陷就是"不会思考"。
来自Ai2、华盛顿大学等机构的研究人员通过严格的数学证明指出:Transformer在组合性任务上存在根本性局限。所谓组合性任务,是指需要将多个简单信息组合起来才能得出答案的问题,例如:"这个人的曾祖父是谁?"
在族谱查询任务中,模型需要先找到"父亲",再找到"父亲的父亲"。这种看似简单的嵌套推理,对Transformer来说却是致命的挑战。研究人员使用通信复杂度(Communication Complexity)理论证明了:当函数的定义域足够大时,Transformer层无法实现函数的组合。
实证研究更是揭示了这一问题的严重程度:
- 让GPT-4计算两个三位数相乘,正确率仅有59%
- 当乘数增加到四位数时,准确率暴降到4%
- 在需要对信息进行组合推理的情况下,大部分LLM表现出明显的"无能为力"
研究人员一针见血地指出:如果一个大模型只有单层Transformer结构,而其总参数量小于处理某类问题所需的比特数,那么这个模型就毫无疑问地无法应对组合性任务。
这揭示了一个深刻的问题:Transformer本质上是基于"下一个词的统计概率"来工作的,它并不具备真正的组合推理能力。它擅长的是模式识别和统计关联,而非从第一性原理出发的逻辑推理。
3. 幻觉问题:无法跨越"统计"与"事实"的鸿沟
与组合能力缺陷紧密相关的是大模型的幻觉(Hallucination)问题------即模型生成看似合理但与事实不符的内容。
Transformer的下一个词预测训练范式,本质上是在学习token之间的统计关联。这种训练方式让模型学会了"什么样的句子在统计上更可能正确",但并不保证内容的事实准确性。当模型面对训练数据中从未出现过的组合,或者需要基于多个事实进行推理时,幻觉就会大量产生。
这个问题在需要高精度、高可靠性的应用场景中尤为致命。 医疗诊断、法律文书、金融分析------这些领域容不得半点"编造",而当前的Transformer架构在这些场景下的表现距离可靠应用还有相当距离。
三、新架构崛起:谁将成为下一代baseline?
变革的种子早已破土而出。
面对Transformer的局限,研究者们正在探索多条突破路径。2025年,业界主要探索两条路径:一是对Transformer架构进行改进,如稀疏注意力、线性注意力等;二是探索非Transformer架构,如状态空间模型(SSM)、新型RNN等。
状态空间模型:从Mamba到Mamba-3
Mamba架构 自2023年12月首次推出以来,便成为了Transformer的强有力竞争对手。其核心创新在于选择性状态空间机制(Selective State Spaces),实现了线性复杂度的突破。

2025年10月,Mamba-3正式发布,目前正在顶会ICLR 2026接受双盲评审。 Mamba-3引入了三大关键改进:
- 梯形离散化:更高效的计算方式
- 更聪明的状态更新规则:提升模型表达能力
- 多输入多输出(MIMO)架构:更好榨干硬件性能
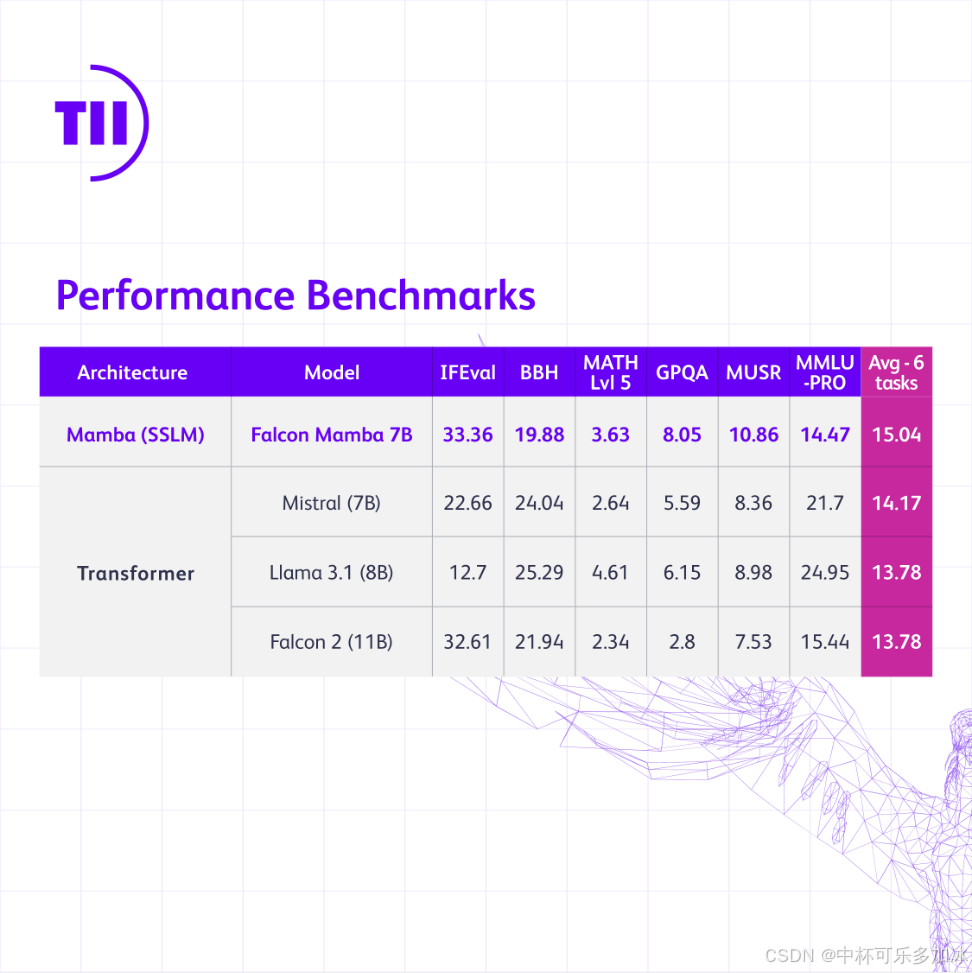
阿布扎比技术创新研究所(TII)发布的Falcon Mamba 7B ,是首个纯无注意力大模型,在一些基准上超越同尺寸级别的领先模型(包括Llama 3 8B、Llama 3.1 8B和Mistral 7B),无需增加内存存储就可以处理任意长度的序列,并且能够在单个24GB A10 GPU上运行。
值得注意的是,苹果AI已选择Mamba架构:在长任务、多交互的Agent式任务中,基于SSM架构的模型在效率与泛化能力上展现出超越Transformer的潜力。
RWKV:RNN架构的强势回归
**RWKV(Receptance Weighted Key Value)**是另一种备受关注的新架构。2025年,RWKV-7系列发布,这是当前全球性能最强的纯RNN架构大语言模型。
RWKV的核心优势在于将计算复杂度从二次方降低至线性,从而在理论层面提升了训练与推理效率,并降低了资源消耗。深圳元始智能已基于RWKV架构获得融资,RWKV开发者社区发展迅速,在端侧智能及多智能体等领域已展现出强大的应用潜力。
DeepSeek MoE:混合专家模型的突破
2025年初,DeepSeek V3以557万美元的研发成本(仅为GPT-4的1/14)和开源模型第一的排名,在全球AI领域掀起波澜。
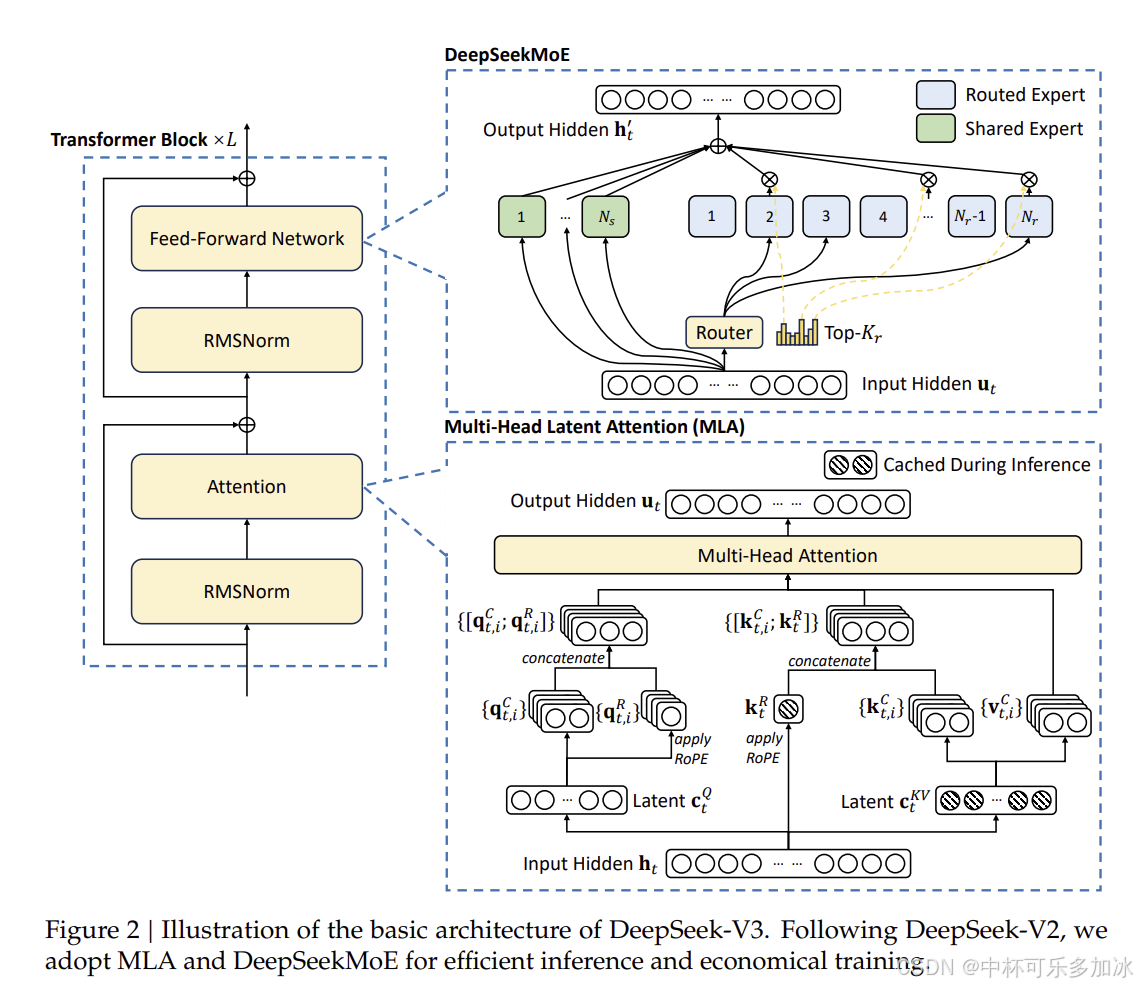
DeepSeek采用的**混合专家模型(MoE,Mixture of Experts)**是一种创新架构,其核心特点是将大模型拆分成多个"专家",训练时分工协作,推理时按需调用,效率显著提升。
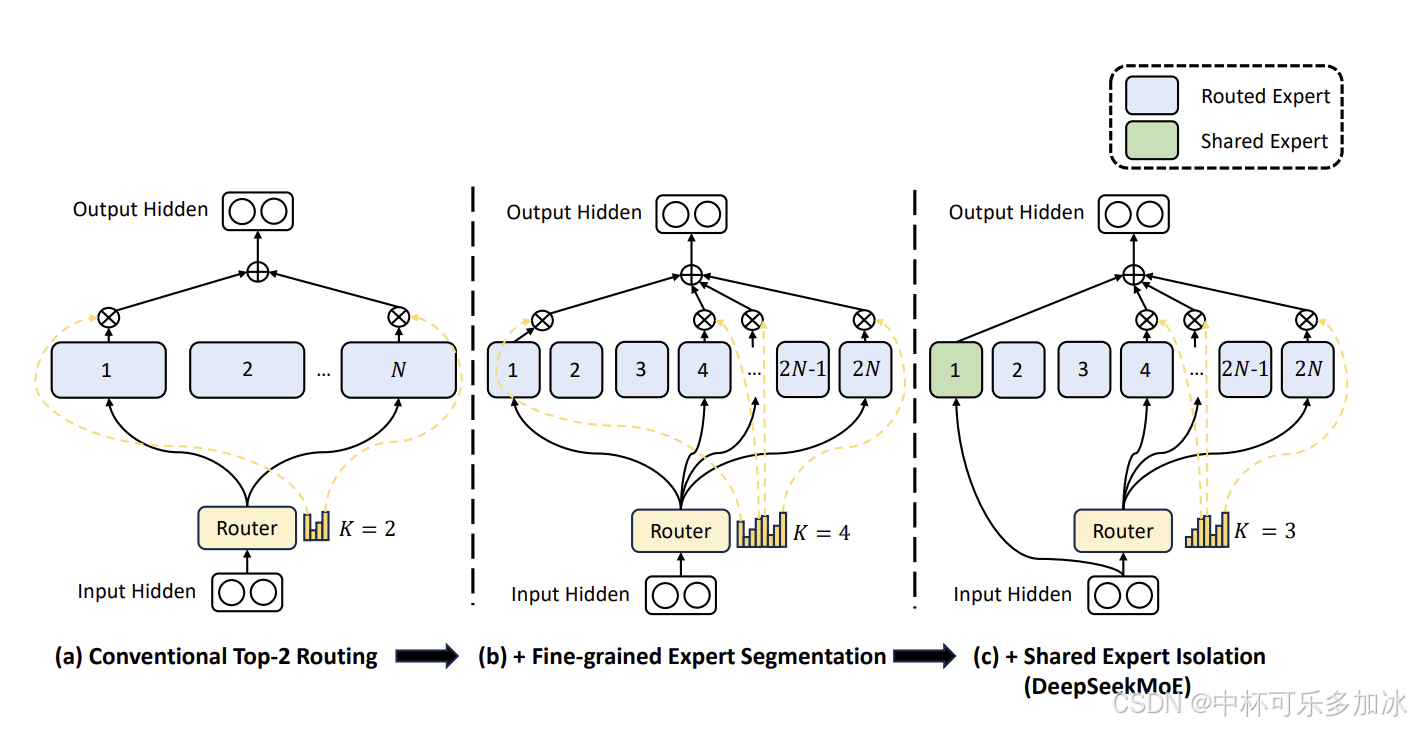
以DeepSeek-V3为例,其总参数量为6710亿,但每次推理仅激活370亿参数(约为总参数的5.5%),推理速度较传统架构提升3倍,内存占用减少65%。 这种"参数量参与计算量解耦"的设计,使得在有限算力条件下,优化模型架构的参数量比增加训练迭代次数更能有效提升模型性能。
混合架构:取长补短的务实选择
腾讯、Minimax等公司已经开始尝试将Transformer与新架构混合使用。 这种务实的选择正在成为行业趋势:Transformer在性能上占优,非Transformer在效率上占优,两者结合可以实现更好的平衡。
2025年的行业共识是:未来发展方向是高效Transformer和混合架构,以及非Transformer架构在端侧和小模型场景的应用。两条路径并非完全对立,而是存在交集。
五、未来之路:突破的方向在哪里?
综合现有研究和行业动态,Transformer架构的局限性已经十分明确,但其是否已经完全触及"天花板"仍是一个开放性问题。
短期:榨干Transformer的潜力
在架构层面,研究者正在通过各种注意力机制优化(如稀疏注意力、线性注意力)来缓解二次复杂度问题。
在后训练层面,强化学习正在成为新的突破口。DeepSeek-R1-Zero证明了完全摒弃监督微调、完全依赖强化学习训练的可能性,推理阶段的扩展(Test-time Scaling)带来新的能力增长曲线。
在数据层面,合成数据、代码数据、数学推理数据正在成为新的高质量数据来源,部分缓解数据枯竭的压力。
中期:新架构的崛起与融合
5-10年内,我们很可能看到新架构的规模化落地。 状态空间模型(SSM)、混合专家模型(MoE)、RWKV等新架构正在跨越10B、20B、100B三个关键参数规模台阶。
但需要注意的是,Transformer生态系统的惯性是巨大的 。全球范围内海量的工程优化、硬件加速,应用开发都围绕Transformer展开,这种路径依赖不会在短期内消失。更可能出现的情况是:新架构与Transformer共存,在各自擅长的场景中发挥作用。
长期:向人脑寻找答案?
有一些学者正在从更根本的层面思考突破。
诺贝尔物理学奖得主杰弗里·辛顿、图灵奖得主杨立昆等学者坚持认为,神经科学是AI发展的重要灵感来源。人脑以约20瓦的功耗支撑千亿级神经元和千万亿级突触的复杂动态网络,其能效远超现有任何AI系统。
类脑计算、事件驱动、稀疏计算、多尺度动力学------这些人脑的工作机制,可能为构建下一代低功耗、高性能AI模型提供宝贵借鉴。
当然,这也只是一条可能的路径,是否能走通仍是未知数。
结语:王者犹在,但神话正在瓦解
回到我们最初的问题:Transformer是否已经触及天花板?
从技术角度看,Transformer确实面临明确的局限性:计算复杂度限制了它的效率,组合能力缺陷影响了它的推理可靠性,幻觉问题制约了它在高可靠性场景中的应用。这些局限不会因为算力投入而自动消失。
但从产业角度看,Transformer仍将在未来相当长时间内占据主导地位。 毕竟,生态系统的惯性是巨大的,而现有架构仍能在大多数应用场景中提供足够好的性能。
真正的问题不是Transformer是否"已死",而是它是否还是"唯一解"。
当越来越多的证据表明,单纯通过增大模型规模、堆砌算力的道路正在变得不可持续,行业就必然要寻找新的突破方向。这可能来自新架构的崛起,可能来自训练范式的创新,也可能来自对智能本质的更深理解。
无论答案是什么,有一点是确定的:AI正在从"规模化时代"走向"架构创新时代"。 那些能够在性能与效率之间找到终极平衡的架构,或许就将定义下一个十年的技术航向。
至于Transformer------它仍是舞台中央的王者,但"唯一解"的神话正在悄然瓦解。