GSD 框架的 /gsd:debug 命令用科学方法论取代混乱的 AI 调试:可证伪的假设、8 种调查技术、持久的调试文件和隔离的上下文窗口。
钩子:"你将堆栈跟踪粘贴到 AI 中。它重写了你一半的文件。三轮之后,上下文充满了失败。有一种更好的方法。"
想象一下:你将堆栈跟踪粘贴到 AI 助手中,输入"修复这个",AI 重写了你一半的文件。它仍然不工作。你粘贴新的错误。AI 再次重写。三轮之后,上下文窗口充满了失败的尝试,AI 开始产生变量名的幻觉,你比开始时更远离一个能工作的程序。
这种模式有一个名字:直觉调试。当开发人员将真正的错误带给 AI 编码助手时,这是默认的体验。
问题不在于 AI 的智能。问题在于方法。经验丰富的工程师系统地进行调试。他们形成假设,运行受控测试,记录证据,并消除死胡同。但是当这些同样的工程师转向 AI 助手寻求帮助时,他们放弃了所有这些纪律,回到了粘贴和祈祷。
用于 Claude Code 的 GSD(Get Shit Done)框架采取了根本不同的方法。它的 /gsd:debug 命令将调试视为工程,而不是猜测。本文准确地解释了它如何工作,以及为什么设计选择会产生更好的结果。
我向你保证:如果你有一个棘手的计时问题或其他真正复杂的调试问题,这个工具感觉就像魔法一样。它可能是 GSD 最好的功能之一。
1、什么是 /gsd:debug?
/gsd:debug 命令是一个用于调查深层、系统性或预先存在的架构错误的专用实用程序。它是 GSD 框架的一部分:一个开源的元提示系统,通过专门的子智能体、新鲜的上下文窗口和原子版本控制来编排 Claude Code、Gemini CLI 和 OpenCode。
关键区别:/gsd:debug 不是用于快速修复。
GSD 已经通过其 /gsd:verify-work 命令处理例程错误,该命令在阶段级用户验收测试(UAT)期间捕获回归。当 UAT 捕获错误时,系统会自动生成临时调试智能体来内联诊断和修复它。该路径是快速和轻量级的。
但有些错误需要真正的调查:原始作者已经离开的遗留代码、仅在生产负载下出现的竞争条件、抵抗重现的间歇性故障,或者三个月前引入的回归直到今天才浮现。对于这些错误,你使用 /gsd:debug。
关键架构差异是隔离。UAT 调试在当前上下文内发生。/gsd:debug 创建了一个完全独立的调试环境,具有自己的新鲜 200,000-token 上下文窗口、持久状态文件和专门为调查设计的特殊智能体提示。主对话在整个会话期间保持干净。
2、架构:薄编排器模式
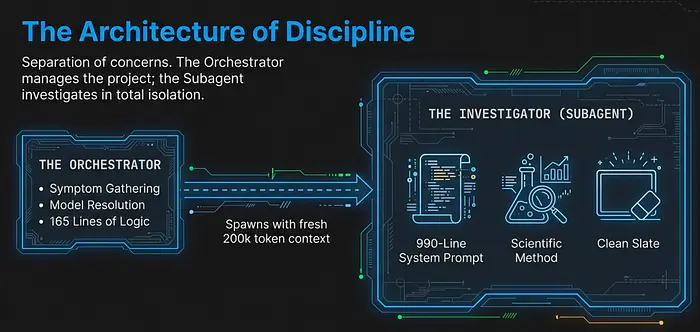
/gsd:debug 命令大约是 165 行的编排逻辑。它不直接调查任何事情。相反,它充当设置调试会话并移交给专家的项目经理。
这是贯穿 GSD 设计的"薄编排器"模式。编排器收集结构化输入,解决正确的工具和模型,并生成适当的子智能体。子智能体在自己的上下文窗口中执行实际工作。这种分离产生两个好处:编排器保持轻量级和可重用,子智能体获得为特定任务优化的干净状态。
3、症状收集
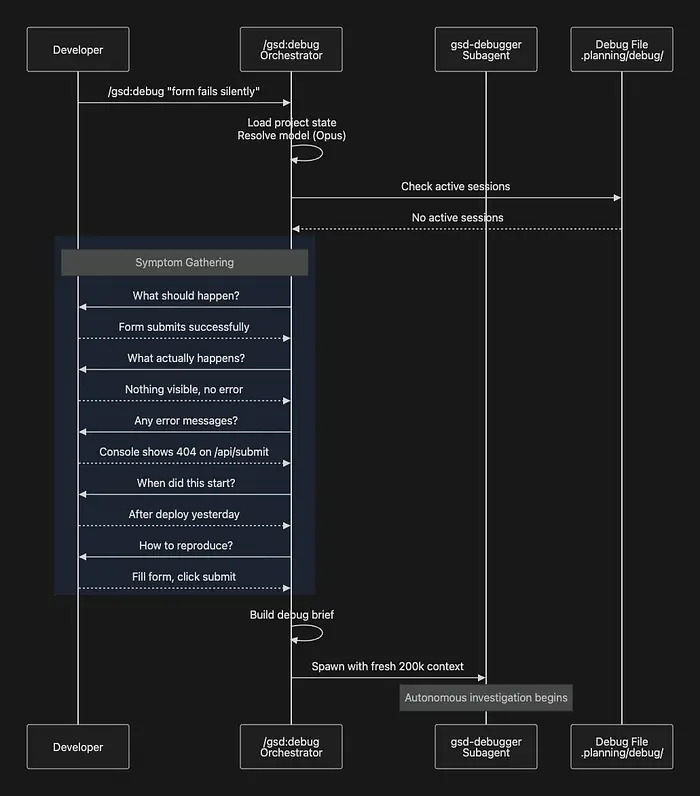
当你调用 /gsd:debug "form submission fails silently" 时,编排器首先检查 .planning/debug/ 中是否有任何活动的调试会话。如果不存在,它通过五个结构化问题收集症候:
- 预期行为 ------ 应该发生什么?
- 实际行为 ------ 实际发生了什么?
- 错误消息 ------ 你能看到任何错误吗?
- 时间线 ------ 这是什么时候开始的?它曾经工作过吗?
- 重现步骤 ------ 你如何触发它?
这五个问题可能看起来很简单,但它们做了重要的事情:它们强制区分症状和诊断。开发人员本能地跳到解释他们认为错误的地方。结构化 intake 将他们重定向到描述他们观察到的内容。这种区别很重要,因为开发人员的早期诊断通常是错误的,将错误的诊断烘焙到提示中会导致 AI 调查错误的东西。
4、上下文合并和生成
收集症状后,编排器解决最优 AI 模型(通常是 Opus 用于复杂调查,或 Gemini Pro 或 Codex High),构建结构化调试简报,并生成 gsd-debugger 子智能体:
Task(
prompt=filled_prompt,
subagent_type="gsd-debugger",
model="opus",
description="Debug form-submission-fails"
)侧注:Task 在最新的 Claude Code 中被重命名为 Agent,而 OpenCode 和 Gemini 有其等价物。
子智能体启动时带有一个新鲜的 200,000-token 上下文窗口,仅包含结构化症状和完整的调试方法论。没有先前的对话历史。没有来自先前失败尝试的累积噪声。只有问题描述和解决它的工具。
5、gsd-debugger:990 行科学方法
gsd-debugger 智能体不是一个通用的"修复错误"提示。它是一个 990 行的系统提示,编码了完整的科学调试方法论,包括认知偏差意识、假设测试框架、八种调查技术和持久状态管理。
大小反映了一种深思熟虑的设计哲学:模糊的指令产生模糊的行为。当你告诉 AI "仔细调试"时,它对"仔细"是什么没有操作定义。当你编码特定的认知偏差以观察、特定的假设测试协议和八种命名的调查技术以及明确的决策标准时,AI 有具体的程序可以遵循。长度在做真正的工作。

5.1 哲学:报告者与调查者
智能体在明确的劳动分工上运作。开发人员是报告者:他们知道他们预期什么、实际发生了什么、他们看到了什么错误以及问题何时开始。智能体是调查者:它读取代码、运行测试、形成假设和追踪原因。
5.2 纪律的架构
这种分工很重要,因为它防止了两种常见的失败模式。首先,它阻止智能体要求开发人员诊断错误("你认为是什么导致了这个?"),这违背了拥有 AI 调查者的目的。其次,当智能体调试 Claude 在先前的会话中编写的代码时,它应用特殊的纪律:
💡 "将你的代码视为外国的。就像别人写的那样阅读它。你的实现决策是假设,而不是事实。代码的行为是真理;你的模型是猜测。"
这个指令直接对抗了一个微妙但严重的问题。在会话 A 中编写代码的 AI 将对其自己的实现是正确的有强烈的先验。当同一个 AI 在会话 B 中调试代码时,它可能潜意识地保护其早期的决定并围绕它们进行调查,而不是调查它们。"将其视为外国的"指令打破了这种模式。
5.3 认知偏差意识
智能体提示包括一个明确的认知偏差表,训练 AI 识别和反击常见陷阱:
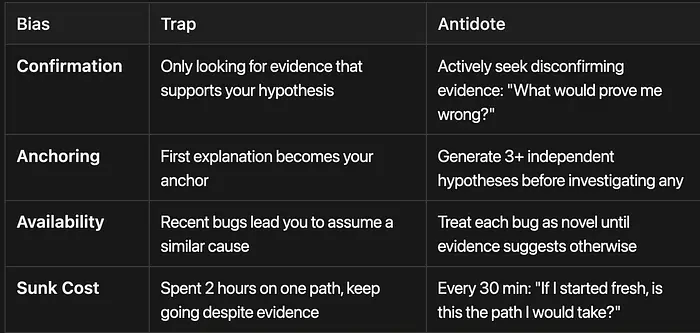
确认偏差
-
陷阱:仅寻找支持你假设的证据
-
解毒剂 :主动寻找反驳证据:"什么会证明我是错的?"
锚定偏差 -
陷阱:第一个解释成为你的锚点
-
解毒剂 :在调查任何一个之前生成 3+ 个独立的假设
可用性偏差 -
陷阱:最近的错误导致你假设类似的原因
-
解毒剂 :将每个错误视为新颖的,直到证据另有说明
沉没成本谬误 -
陷阱:在一条路径上花费 2 小时,尽管有证据仍继续
-
解毒剂 :每 30 分钟:"如果我重新开始,这是我会采取的路径吗?"
这些不是理论关注点。它们描述了在实践中破坏 AI 调试会话的确切失败模式。

5.4 硬编码偏差纠正
确认偏差是最危险的一个。落在一个看似合理的解释上的 AI 助手倾向于随后的证据对其有利解释。每个错误消息成为初始假设的确认。矛盾的证据被最小化。"什么会证明我是错的?"提示迫使智能体主动寻求反驳,而不仅仅是确认。
锚定解释了为什么你应该永远不要让开发人员的初始猜测成为调查的第一个假设。如果开发人员说"我认为这是一个缓存问题"并且智能体从那里开始,整个调查锚定到那个起点。在调查任何一个之前生成三个或更多独立假设的指令打破了锚点。
5.5 假设测试框架
科学方法论的核心是一个具有严格可证伪性要求的形式化假设测试框架。这是方法与典型 AI 调试最尖锐地分歧的地方。
糟糕的假设(不可证伪):
-
"状态有问题"
-
"时机不对"
-
"某处有竞争条件"
好的假设(可证伪): -
"当路由更改时组件重新挂载时用户状态重置"
-
"API 调用在卸载后完成,导致在未挂载的组件上进行状态更新"
-
"两个异步操作在没有锁定的情况下修改同一数组,导致数据丢失"
区别在于特异性。每个好的假设做出可测试的声明。你可以检查组件生命周期并验证它是否在路由更改时重新挂载。你可以在卸载后添加日志并观察状态更新。你可以检查数组操作是否获取锁。

5.6 可证伪的假设测试
不可证伪的版本无法测试,因为它们没有预测足够具体的东西来观察。"状态有问题"与任何状态相关的结果一致。它不是假设;它是一个类别。
对于每个假设,智能体遵循结构化的实验设计:
- 预测 ------ 如果 H 为真,我将观察到 X
- 测试设置 ------ 我需要做什么?
- 测量 ------ 我到底在测量什么?
- 成功标准 ------ 什么确认 H?什么反驳 H?
- 运行 ------ 执行测试
- 观察 ------ 记录实际发生了什么
- 结论 ------ 这支持还是反驳 H?

一次一个假设。一次一个更改。此约束是不可商量的。如果你同时更改三件事并且错误消失,你没有学到哪个更改修复了它。你不能安全地恢复。你不能概括修复。你有一个不可靠的补丁,而不是诊断。
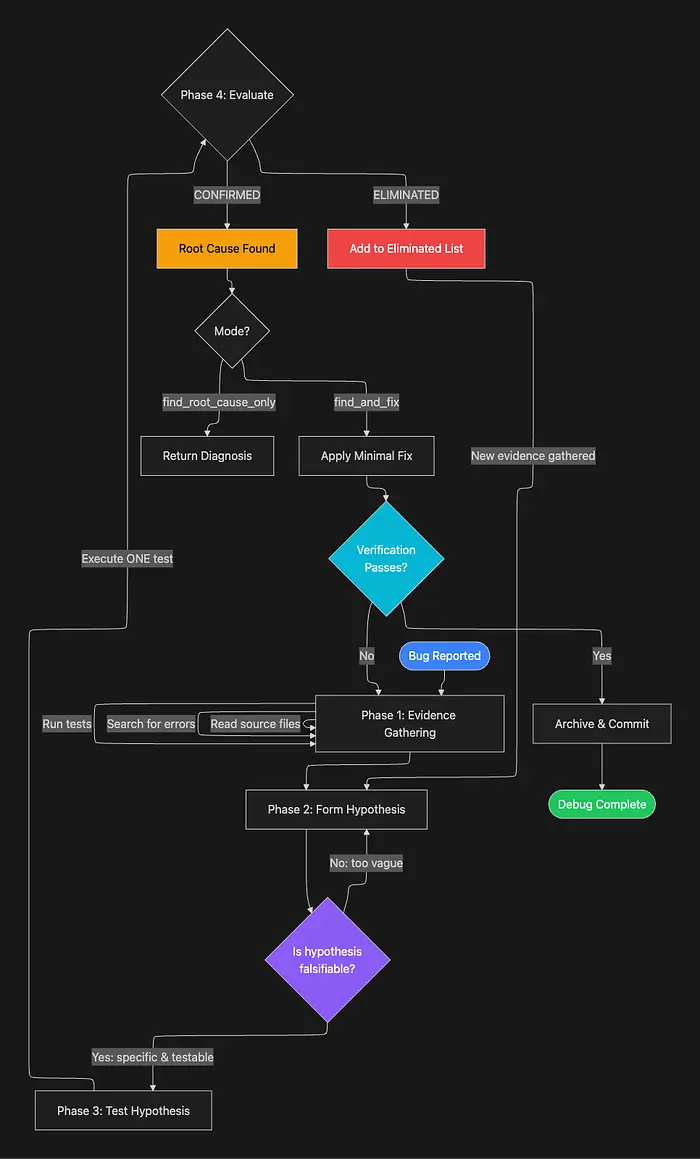
注意循环:消除的假设产生新证据,这些证据反馈到形成下一个假设。每个失败的假设不是浪费的努力。它缩小搜索空间,并经常揭示指向真正原因的信息。分而治之。这就是方式。
6、八种调查技术
gsd-debugger 携带八种命名的调查技术,每种技术都有关于何时应用它的明确指导。拥有命名的技术很重要,因为它给智能体一个决策框架,而不是让它即兴创作。当智能体问自己"我接下来应该尝试什么?"时,它可以系统地根据当前情况评估每种技术,而不是猜测。

6.1 二分搜索 / 分而治之
何时使用: 大型代码库、长执行路径、许多可能的失败点。
如何工作: 反复将问题空间减半。测试中点。如果通过,错误在后半部分。如果失败,错误在前半部分。重复,直到你隔离确切位置。
示例: API 返回错误的数据。
数据是否正确地离开数据库?是。
数据是否正确地到达前端?否。
数据是否正确地离开 API 路由?是。
它是否在序列化中幸存?否。
四个测试消除了代码库的 90% 并将序列化层确定为罪魁祸首。
权衡: 当你可以测试任意中点时,二分搜索工作良好。当执行路径具有使隔离测试困难的副作用时,它工作不佳。
6.2 橡皮鸭调试
何时使用: 卡住、困惑、心智模型与观察到的行为不匹配。
如何工作: 从第一原理大声地详细解释问题。阐述的行为经常暴露隐藏的假设。"等等,我从未实际验证步骤 B 返回我认为它返回的东西。"
为什么有效: 错误经常存在于你认为代码做什么和它实际做什么之间的差距。叙述迫使你使隐含的信念变得明确,在那里它们可以被检查。
6.3 最小重现
何时使用: 具有许多移动部分的复杂系统、不清楚哪部分失败。
如何工作: 剥离所有东西,直到最小的可能代码重现错误。一个具有 15 个 props、8 个 hooks 和 3 个上下文的 500 行 React 组件变成一个 6 行组件,暴露了来自缺失依赖数组的无限循环。
权衡: 最小重现在成功时高度可靠,但对于依赖于复杂系统交互的错误,它可能耗时。一些错误根本无法从其上下文中幸存。在这些情况下,差异调试或可观察性优先可能更实用。
6.4 向后工作
何时使用: 你知道正确的输出但没有得到它。
如何工作: 从期望的结束状态开始,并通过调用堆栈向后追溯,根据期望检查每个步骤。
示例: 当用户存在时 UI 显示"用户未找到"。
追溯:UI 显示 user.error(渲染正确) -> API 返回 { error: "User not found" } -> 数据库查询:SELECT * FROM users WHERE id = 'undefined'。
用户 ID 是字符串 'undefined' 而不是数字。错误在于 ID 如何传递给 API 调用,而不是在 UI 或数据库中。
向后工作是高效的,因为它让你跳过可证明正确的层。一旦你确认渲染逻辑良好,你就停止调查它并向上游移动。
6.5 差异调试
何时使用: 某些东西曾经工作但现在不工作,或者在一个环境中工作但在另一个环境中不工作。
如何工作: 列出工作状态和损坏状态之间的所有差异。在隔离中测试每个差异以识别哪一个导致失败。
示例: 本地工作,在 CI 中失败。差异:Node 版本(相同)、环境变量(相同)、时区(不同)。将本地时区设置为 UTC,现在它在本地也失败。日期比较逻辑假设了本地时区。
为什么强大: 差异调试将一个不明确的"为什么它坏了"问题转换为一个具体的"哪个差异解释了行为"问题。第二个问题系统地回答起来容易得多。
6.6 可观察性优先
何时使用: 总是。在进行任何代码更改之前。
如何工作: 在更改行为之前添加可见性。在关键点进行战略日志记录、断言检查、时间测量和关键连接处的堆栈跟踪。观察系统的实际行为,然后基于你看到的内容形成假设。
这种技术值得自己的原则:永远不要更改你无法观察的代码。如果你在不首先理解代码实际在做什么的情况下修复错误,你就是在猜测。可观察性将猜测转换为测量。在更改之前测量。
6.7 注释掉所有东西
何时使用: 许多可能的交互、不清楚哪个代码导致问题。
如何工作: 注释掉所有可疑代码,验证错误消失,然后一次取消注释一块,直到错误返回。带回错误的块是罪魁祸首。
示例: 八个中间件函数。一个一个取消注释它们。当添加 bodyParser.json({ limit: '50mb' }) 时错误返回。发现:该中间件在当前负载模式下导致内存压力。
权衡: 此技术对于像中间件管道或事件处理程序之类的附加系统工作良好。当部分紧密耦合并且无法在隔离中安全删除时,它较难应用。
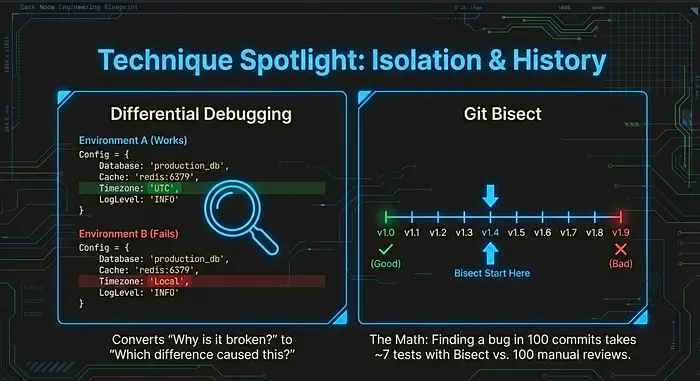
6.8 Git Bisect
何时使用: 功能在已知的过去提交工作,并且在未知的后来提交时中断。
如何工作: 通过 git 历史进行二分搜索。标记一个已知的好提交和当前的损坏提交。Git bisect 检出中点。你测试并标记它为好或坏。重复,直到你找到确切的破坏提交。
为什么重要: 在工作和损坏之间有 100 个提交,git bisect 在大约 7 个测试中找到罪魁祸首。没有 bisect,你会查看所有 100 个提交。破坏提交确切揭示了什么更改,这通常使根本原因变得明显。
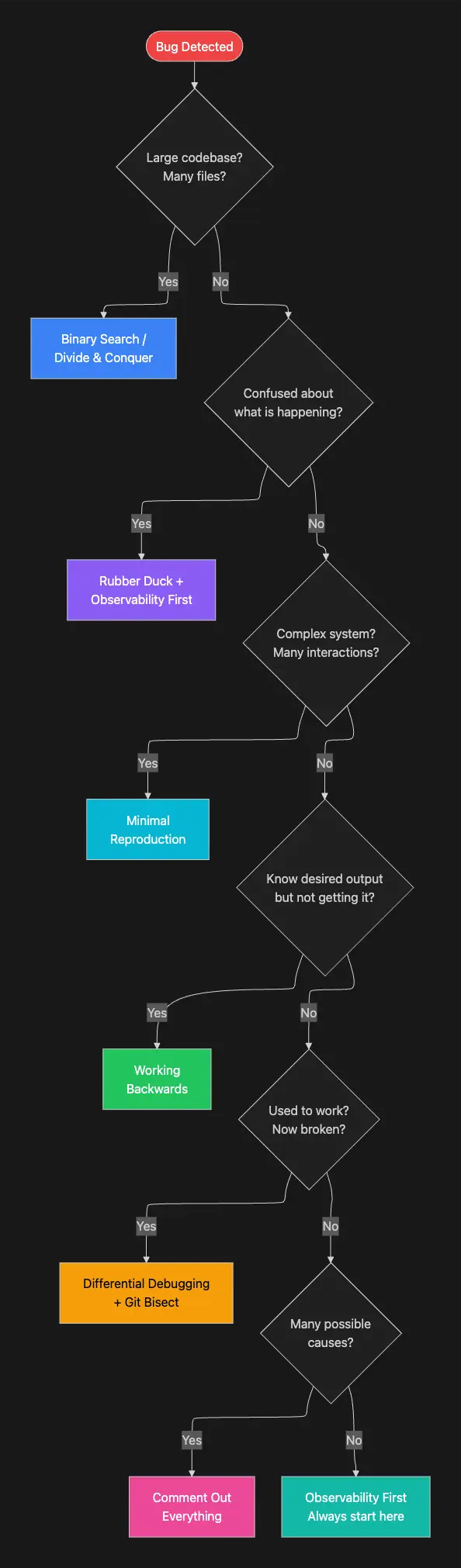
决策树使技术选择变得明确。而不是让智能体任意选择,树编码了经验丰富的调试器应用的情境逻辑。

7、调试文件协议:在上下文重置后幸存的内存
/gsd:debug 中最关键的设计决策之一是持久调试文件。上下文限制在深度调查期间是一个真正的约束。当调试会话用尽上下文时,默认结果是完全丢失:每个形成的假设、每个收集的证据、每个消除的死胡同。开发人员回到了开始。
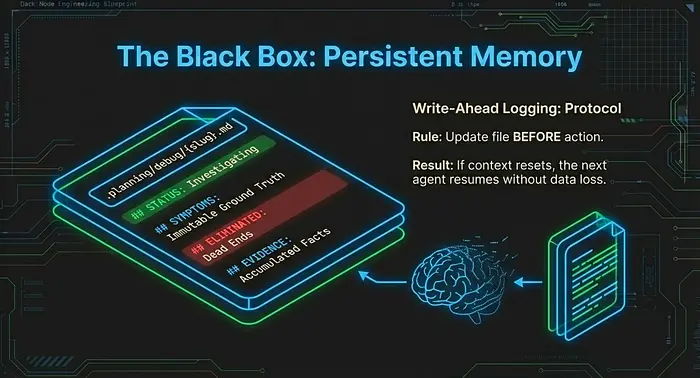
黑盒持久内存
gsd-debugger 通过位于 .planning/debug/{slug}.md 的结构化 markdown 文件解决这个问题,该文件充当调查的持久内存。AI 智能体是可消耗的。文件不是。
文件结构
---
status: investigating
trigger: "form submission fails silently"
created: 2026-02-25T10:30:00Z
updated: 2026-02-25T11:15:00Z
---
## Current Focus
hypothesis: API route /api/submit was renamed in recent deploy
test: Check git diff for route changes in last 5 commits
expecting: Route name mismatch between frontend and backend
next_action: Run git log --oneline -5 -- src/routes/
## Symptoms
expected: Form submits successfully with confirmation
actual: Click submit, nothing happens, no visible error
errors: Console shows 404 on POST /api/submit
reproduction: Fill any form field, click submit button
started: After yesterday's deploy
## Eliminated
- hypothesis: Frontend validation blocking submission
evidence: No validation errors in console, form data is valid
timestamp: 2026-02-25T10:45:00Z
- hypothesis: CORS blocking the request
evidence: No CORS errors in console, same-origin request
timestamp: 2026-02-25T10:52:00Z
## Evidence
- timestamp: 2026-02-25T10:40:00Z
checked: Browser network tab
found: POST to /api/submit returns 404
implication: Route does not exist on server
- timestamp: 2026-02-25T10:55:00Z
checked: src/routes/index.ts
found: Route is /api/v2/submit (changed in commit abc123)
implication: Frontend still points to old route每个部分都有特定目的。Current Focus 告诉下一个智能体调查的确切点和首先要做什么。Symptoms 是永不改变的基本事实。Eliminated 是下一个智能体绝不能重新访问的死胡同列表。Evidence 是支持假设形成的累积观察。
更新规则
每个部分都有严格的更新规则,可以防止损坏:
-
Current Focus: 覆盖 ------ 始终反映调查的当前状态
-
Symptoms: 不可变 ------ 原始问题永不改变
-
Eliminated: 仅追加 ------ 防止重新调查死胡同
-
Evidence: 仅追加 ------ 保留每个发现
-
Resolution: 覆盖 ------ 随着调查进展而理解演变
最重要的规则不是关于特定部分。它是关于时机。智能体必须在采取行动之前更新文件,而不是之后。如果上下文在动作中间重置,文件显示即将发生的事情。这足以恢复。如果智能体在动作之后更新,并且上下文在动作期间重置,文件显示关于当前状态的任何东西,这不足以恢复。
-
这种在行动之前写入的纪律与数据库中的提前写入日志背后的原理相同。日志条目在操作之前存在,因此恢复总是可能的。
恢复行为
当你运行 /clear 并再次调用 /gsd:debug 时,编排器找到活动会话,读取文件,并生成一个具有完整调查状态的新鲜智能体。新智能体读取:
- Status 以知道它在什么阶段
- Current Focus 以知道确切发生了什么
- Eliminated 以知道不要重试什么
- Evidence 以知道已经学到了什么
- Next action 以确切地从上一个智能体停止的地方继续
新鲜智能体就像它一直在那里一样继续调查。这种设计将 AI 上下文窗口视为可消耗资源(它们确实是),并将持久文件视为耐用状态(它们应该是的)。
检查点:当 AI 需要你时
自主调查有限制。某些信息只能通过人类观察获得:管理员帐户是否表现出不同的行为、第三方服务在实际生产环境中返回什么,或者两个调查路径中的哪个值得时间投资。
与其猜测或静默地暂停,调试器向编排器返回结构化的检查点,编排器将其呈现给开发人员。存在三种检查点类型:
- human-verify ------ 智能体需要你确认它无法直接观察的东西。"你可以检查当你作为管理员用户登录时表单提交是否成功吗?"
- human-action ------ 智能体需要你执行一个动作。"请使用 DEBUG=true 标志重新启动开发服务器并粘贴输出。"
- decision ------ 智能体需要你选择调查方向。"错误可能在缓存层或数据库连接池中。调查两者将花费大量时间。我应该优先考虑哪一个?"
你响应后,编排器生成一个带有调试文件加上你的响应的新鲜延续智能体。原始智能体从不恢复。每个延续都以干净的上下文窗口开始,防止使长调试会话退化的累积困惑。
这种检查点设计反映了 AI 能力的现实观点。智能体自主处理它可以做的事情:读取代码、运行测试、追踪执行路径、形成和测试假设。开发人员处理只有人类可以做的事情:物理环境观察、访问控制的系统和战略优先级调用。检查点机制使该边界变得明确和可操作。
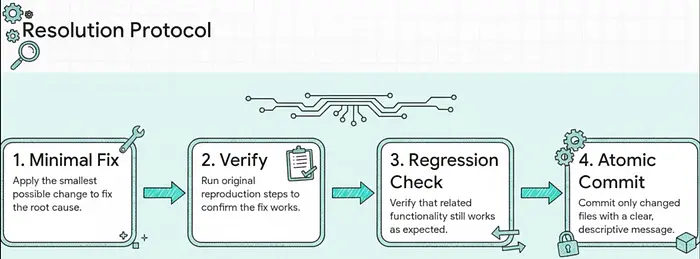
解决方案:修复、验证、归档
当确认根本原因时,智能体遵循严格的解决方案协议。每个步骤防止特定类别的错误。
-
最小修复 ------ 直接解决已确认原因的最小更改。不是重构。不是改进。消除已确认原因的特定更改。
-
根据症状验证 ------ 从原始症状收集运行确切的重现步骤。原始症状是验收标准。如果报告的行为消失,则修复有效。
-
回归检查 ------ 验证相关功能仍然有效。解决一个错误并创建两个错误的修复不是修复。
-
原子提交 ------ 仅暂存更改的文件(从不使用
git add -A),使用包括根本原因的描述性消息提交。这创建了一个可以单独安全恢复的提交(如果修复导致下游意外问题)。 -
归档 ------ 将调试文件移动到
.planning/debug/resolved/。调查记录被保留和可搜索,但不再显示为活动会话。 -
人工验证 ------ 在关闭之前展示发现以供批准。开发人员确认修复鉴于他们对系统的知识是合理的。
Code fix commit
git add src/routes/index.ts
git add src/components/Form.tsx
git commit -m "fix: update form submission endpoint to /api/v2/submitRoot cause: API route renamed in v2 migration but frontend not updated"
Planning docs commit (separate)
node ~/.claude/get-shit-done/bin/gsd-tools.cjs commit
"docs: resolve debug form-submission-fails"
--files .planning/debug/resolved/form-submission-fails.md
结构化返回确切地告诉编排器发生了什么:
## DEBUG COMPLETE
**Root Cause:** API route renamed from /api/submit to /api/v2/submit
in commit abc123, but frontend Form component still references old path
**Fix Applied:** Updated Form.tsx API endpoint to /api/v2/submit
**Verification:** Form now submits successfully, 200 response, data persisted
**Files Changed:**
- src/routes/index.ts: no change needed (route is correct)
- src/components/Form.tsx: updated API_ENDPOINT constant
**Commit:** def456结构化输出可以被编排器机器读取,并且可以被开发人员人工阅读。它回答开发人员在接受修复之前需要的问题:什么是错误的、什么改变了、它是如何验证的,以及如果需要恢复,什么是提交参考。
8、实用示例:完整的会话
以下是开发人员视角的真实 /gsd:debug 会话的样子:
# Start debugging
> /gsd:debug "user profile photos not loading after S3 migration"
# Orchestrator asks structured questions
? Expected behavior: Profile photos display on user cards
? Actual behavior: Broken image icons on all profile cards
? Error messages: Console shows 403 Forbidden for image URLs
? When did this start: After migrating from local storage to S3
? Reproduction: Visit any user profile page
# Agent investigates autonomously...
# (reads S3 config, checks IAM policies, tests URLs, forms hypotheses)
# Checkpoint returned:
CHECKPOINT: human-verify
"I found that S3 bucket policy allows GetObject only from
production domain. Can you confirm: is your dev environment
using localhost:3000 or a custom domain?"
> localhost:3000
# Fresh agent continues with this information...
# Finds root cause: CORS + bucket policy restrict to production domain only
# Resolution
ROOT CAUSE: S3 bucket policy restricts GetObject to production
domain. Dev/staging environments return 403 because their
origins are not in the allowed list.
FIX: Added dev and staging domains to bucket CORS configuration
and updated bucket policy AllowedOrigins.
COMMIT: abc789
# Debug file archived to .planning/debug/resolved/注意开发人员实际做了什么:回答了五个结构化问题,回答了一个检查点问题,并批准了结果。智能体处理了其他所有事情。它读取了 S3 配置,形成并测试了关于 IAM 策略和 CORS 设置的假设,并确定了存储桶策略的允许域与开发环境的域之间的确切不匹配。
开发人员的主对话窗口根本没有调试噪声。整个调查发生在一个隔离的上下文窗口中。如果在调试会话运行时你需要向 AI 询问一些无关的东西,你可以,因为调试会话单独存在。
9、为什么这种设计会产生更好的结果
/gsd:debug 命令演示了关于 AI 辅助开发的重要东西:AI 输出的质量在很大程度上取决于你给它的结构。
使用 AI 的非结构化调试往往比单独调试更糟糕。你在失败的尝试上消耗上下文,随着上下文充满矛盾,AI 失去连贯性,最终在上下文窗口耗尽后手动调查。你失去了时间,什么也没得到。
使用 /gsd:debug 的结构化调试给 AI 提供了它否则会缺乏的四件事:
- 科学方法论。 可证伪假设、一次一变量测试和明确的证据跟踪产生可靠的结果。认知偏差表防止了最常见的 AI 失败模式:锚定在第一个看似合理的解释上并倾向于对其有利地解释所有后续证据。
- 持久内存。 调试文件在上下文重置、会话重新启动和智能体交换后幸存。即使底层 AI 实例被替换,调查也会继续。文件是调查;智能体只是当前工作者。
- 上下文隔离。 每个调查都获得一个新的 200,000-token 窗口。失败的假设和死胡同不会在对话中累积。调查的每个步骤都从由调试文件通知的干净状态开始,而不是被先前失败尝试的噪声污染。
- 明确的边界。 检查点机制明确化了 AI 可以自主处理什么以及什么需要人工输入。这防止了智能体猜测它无法观察的事情,这是 AI 调试错误的常见来源。
gsd-debugger 不是魔法。它是纪律,编码在 990 行的提示工程中,包裹在旨在保持 AI 专注和开发人员受控的架构中。结果反映了结构的质量,而不是底层模型的原始能力。
关键要点
- 直觉调试可预测地失败。 上下文充满噪声,AI 锚定在早期假设上,调查退化而不是收敛。
- 薄编排器模式将协调与调查分离开。 命令收集症状并生成智能体。智能体在干净的上下文中做实际工作。
- 990 行的方法论并不过分。 模糊的指令产生模糊的行为。详细的程序给 AI 具体的东西可以遵循。
- 认知偏差意识是可操作的,而不是理论的。 表中的四个偏差是在实践中破坏 AI 调试的实际失败模式。
- 可证伪性是一个硬要求。 "状态有问题"不是假设。"当路由更改时组件重新挂载,重置用户状态"是假设。
- 调试文件是调查;智能体只是当前工作者。 文件在上下文重置中幸存。智能体不会。
- 在行动之前写入。 在采取行动之前更新调试文件,而不是之后。这是调试会话的提前写入日志。
10、结束语
如果直觉调试一直浪费你的时间,/gsd:debug 命令值得在你的下一个困难错误上尝试。
从安装 GSD 框架并在你已经理解的错误上运行命令开始。观察症状收集如何强制你通常可能会跳过的精度。观察假设测试框架如何保持调查专注。如果会话被中断,尝试使用新的 /gsd:debug 调用恢复它,并观察调试文件恢复调查状态。
gsd-debugger 中的科学调试方法论也可以在没有工具的情况下应用。认知偏差表、假设测试协议和八种调查技术是可以手动应用的模式。工具只是自动执行它们。
- *GSD 是开源的,可在 github.com/gsd-build/get-shit-done 获得。
/gsd:debug命令需要安装了 GSD 插件的 Claude Code、Gemini CLI 或 OpenCode。
原文链接:使用 AI 进行科学调试 - 汇智网