一、问题的提出
在聚合风险精算模型中,要计算N个损失变量Xi(i=1,2,3,...,N)之和,
Z=X1+X2+X3+......+XN
是一个非常困难的问题。
二、已有的解法
如果单纯依靠卷积(convolution)公式那是相当 "卷" 的,卷到最后我们都不一定能算得出来。
Panjer递推公式是一个不错的解法,但是Panjer递推公式可以使用的一个前提是 损失个数N的分布必须服从 (a,b,0) 类分布。
在卷积公式和Panjer递推公式都不太好使的情况下,快速傅里叶变化 (FFT) 算法是一个可选的方法。
三、快速傅里叶变换(FFT)算法的原理
FFT算法在聚合风险精算模型里的基本原理就是,取一个足够大的数 M (为了 FFT 计算效率快,一般 M 取 2 的若干次方),令 Y = Z mod M,也就是 Y 等于 Z 除以 M 的余数。可以证明,Y 与 Z 的离散傅里叶变化(DFT)是一样的,因此,当 M 足够大时,余数 Y 与 总损失 Z 的概率分布是相同的。也就是说,我们把求解总损失 Z 的概率分布变为了 求解余数 Y 的概率分布,而余数 Y 的概率分布可以使用 FFT 算法比较容易的得到。这就是 FFT 算法的基本原理与计算过程。
四、一个示例
【问题】已知损失次数 N 服从 参数为1的泊松分布,每个损失的损失金额有 0.5 的概率等于1、有 0.5 的概率等于2. 要计算N个损失变量Xi(i=1,2,3,...,N)之和 Z=X1+X2+X3+......+XN 的概率分布。
【解】直接用 python 写如下的代码:
import numpy as np
m=64
v=np.zeros(m)
v[1]=0.5
v[2]=0.5
lamb=1
ff=np.exp(lamb*(np.fft.fft(v)-1))
iff=np.fft.ifft(ff)
print(np.real(iff))运行后得到结果如下:
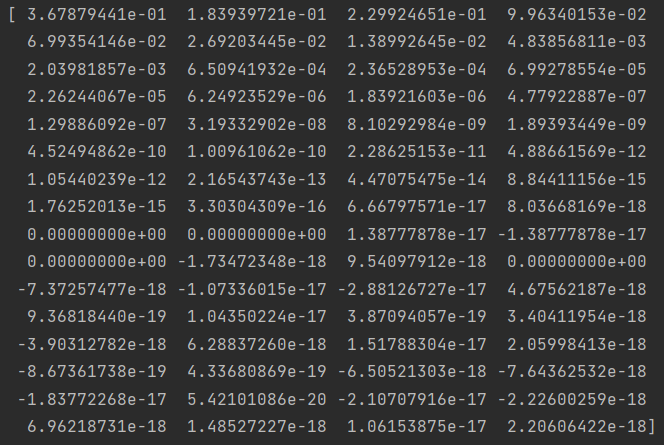
结果向量代表的意思是,总损失 Z =0 的概率是向量中的第一个数 0.367879441,总损失 Z =1 的概率是向量中的第二个数0.183939721,总损失 Z =2 的概率是第三个数0.229924651,总损失 Z =3 的概率是第四个数 0.0996340153,以此类推。这个结果与真实结果非常接近,真实结果如下表:
|----|-------------|
| Z | f(Z) |
| 0 | 0.367879441 |
| 1 | 0.183939721 |
| 2 | 0.229924651 |
| 3 | 0.099634015 |
| 4 | 0.069935415 |
| 5 | 0.026920345 |
| 6 | 0.013899264 |
| 7 | 0.004838568 |
| 8 | 0.002039819 |
| 9 | 0.000650942 |
| 10 | 0.000236529 |
| 11 | 0.000069928 |
| 12 | 0.000022624 |
| 13 | 0.000006249 |
| 14 | 0.000001839 |
| 15 | 0.000000478 |
| 16 | 0.000000130 |
| 17 | 0.000000032 |
| 18 | 0.000000008 |
| 19 | 0.000000002 |
| 20 | 0.000000000 |
可以看到,总损失 Z 大于等于11之后的概率都是很小的了。正是因为这个原因,我们在算法中选取了 m=64 。其实,取 m=32 的结果效果也是不错的。也就是说,m 的选取时,尽量让 Pr{Z>=m}的概率尽量足够小,接近于0才好。
换了角度说,让 总损失的金额在一个 0 到 m-1 的周期内都展示出来。一个反例,如果这个例子中 取 m=8,意味着总损失在 一个 0 到 7 的周期内并未完全都展示出来, Z=8, Z=9, Z=10 ... 等等还有不小的概率存在。此时,FFT 的结果和真实结果就会有一定差异,差异其实就是 Z>=8 那部分的概率造成的。
以上就是对 快速傅里叶变换在聚合风险精算模型中的介绍。