TL;DR
- 场景:用 Hive 实现离线数仓中的拉链表,处理每日新增、变更、历史保留与回滚恢复。
- 结论:当前方案适合教学与基础生产场景,但更接近 Type 2 SCD 的简化实现,删除场景与幂等控制需单独补强。
- 产出:给出可用于文章开头的 SEO 摘要、版本矩阵、错误速查卡,方便直接发布和后续补坑。
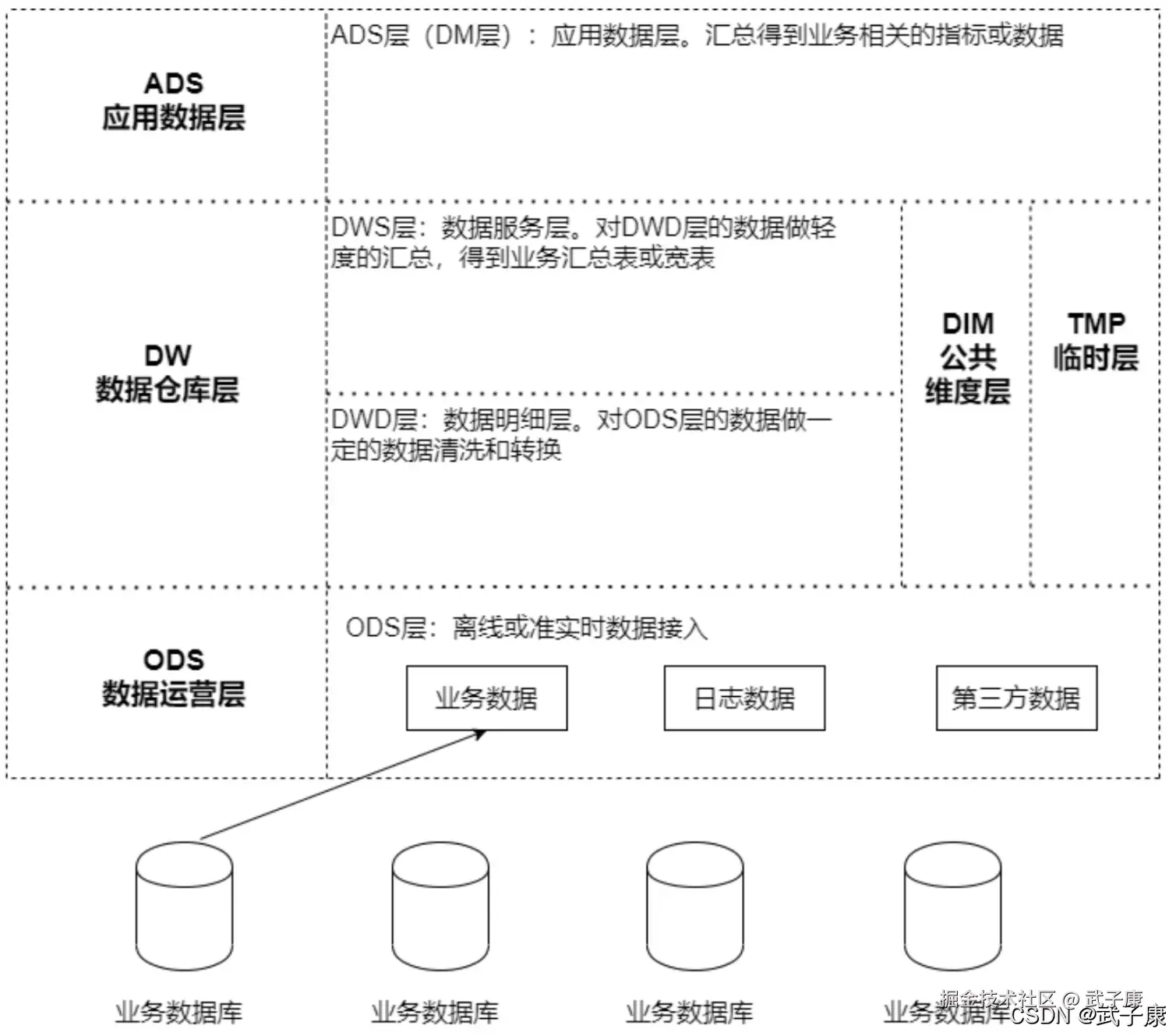
拉链表的实现
userinfo(分区表) => userid、mobile、regdate => 每日变更的数据(修改的+新增的)/ 历史数据(第一天) userhis(拉链表)=> 多个两个字段 start_date / end_date
拉链表(Zipper Table)
拉链表是一种数据库设计模式,用于跟踪数据随时间的变化,同时保持高效的查询性能。这种模式广泛应用于数据仓库和数据分析场景,因为它能够很好地记录历史数据的变化情况。
拉链表的基本概念
拉链表的核心思想是将每条记录的有效时间范围存储起来,通过"拉链"方式记录版本变化。每一条记录都包含以下关键信息:
- 开始时间(Start Date/Effective Date):表示这条记录的生效时间。
- 结束时间(End Date/Expiration Date):表示这条记录的失效时间。
- 是否当前有效(Is Current):表示这条记录是否为最新版本(通常通过标志位存储,如1表示当前记录,0表示历史记录)。
工作原理
- 新增数据:当有新数据插入时,系统创建一条新记录,设置其开始时间为当前时间,结束时间为一个默认的最大时间(如9999-12-31),同时将is_current字段设为1。
- 更新数据:首先将现有的有效记录的结束时间更新为当前时间,表示它的有效期结束,同时将is_current标志设为0。
- 然后插入一条新的记录,表示更新后的版本,开始时间为当前时间,结束时间为默认最大时间,is_current标志为1。
- 删除数据:一般通过逻辑删除方式(更新结束时间和is_current字段)实现,而不是直接物理删除。
准备数据
这里的数据刚才已经全部都写入进去了
sql
-- 1、userinfo初始化(2020-06-20)。获取历史数据
001,13551111111,2020-03-01,2020-06-20
002,13561111111,2020-04-01,2020-06-20
003,13571111111,2020-05-01,2020-06-20
004,13581111111,2020-06-01,2020-06-20初始化拉链表
将2020-06-20的数据写入到表中
sql
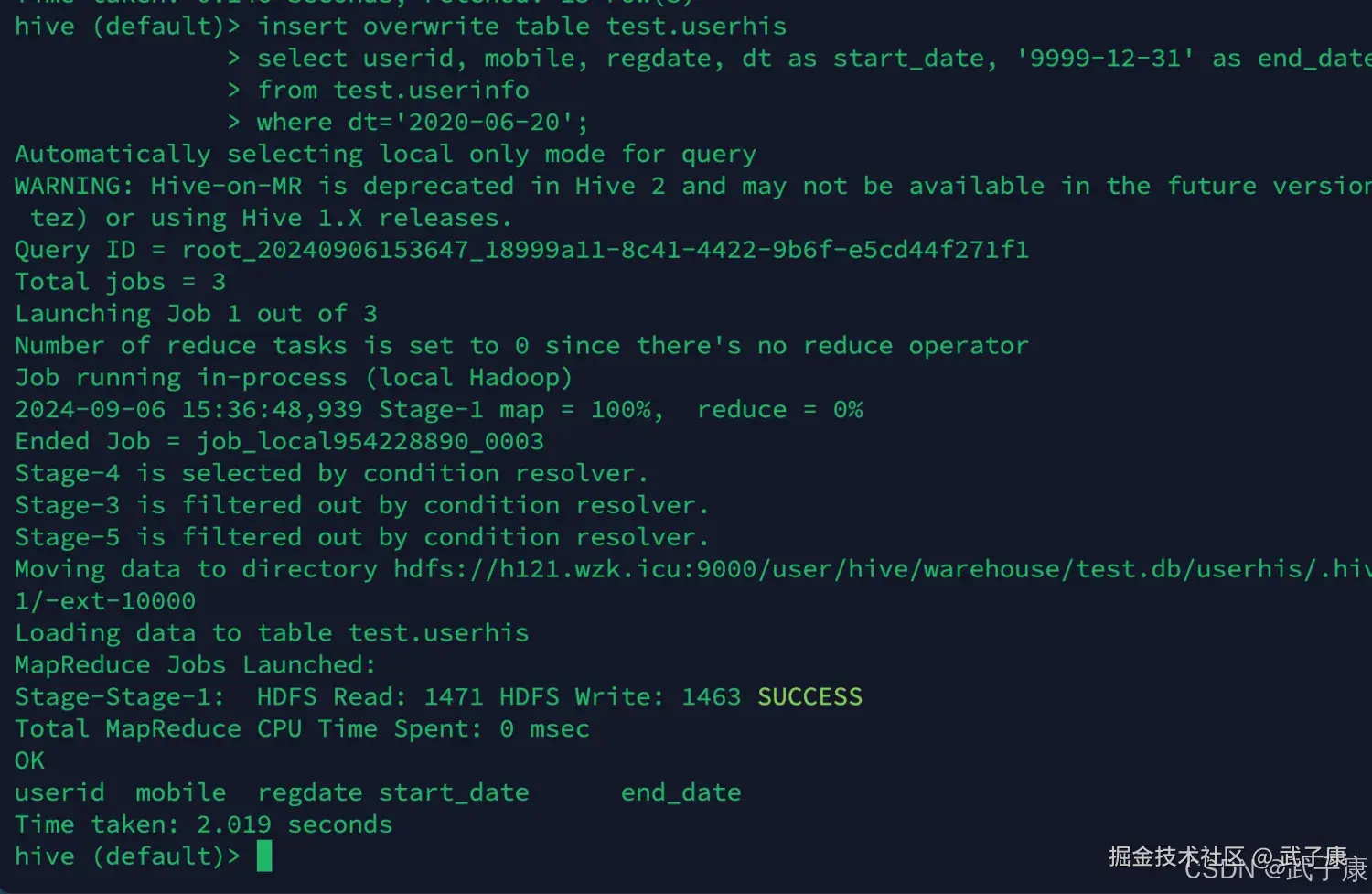
-- 2、初始化拉链表(2020-06-20)。userinfo => userhis
INSERT OVERWRITE TABLE test.userhis
SELECT
userid,
mobile,
regdate,
dt AS start_date,
'9999-12-31' AS end_date
FROM
test.userinfo
WHERE
dt = '2020-06-20';执行结果如下所示:
继续准备数据
这批数据也已经写入了:
sql
-- 3、次日新增数据(2020-06-21);获取新增数据
002,13562222222,2020-04-01,2020-06-21
004,13582222222,2020-06-01,2020-06-21
005,13552222222,2020-06-21,2020-06-21构建拉链表
sql
-- 4、构建拉链表(userhis)(2020-06-21)【核心】 userinfo(2020-06-21) + userhis => userhis
-- userinfo: 新增数据
-- userhis:历史数据
-- 第一步:处理新增数据【userinfo】(处理逻辑与加载历史数据类似)
SELECT
userid,
mobile,
regdate,
dt AS start_date,
'9999-12-31' AS end_date
FROM
test.userinfo
WHERE
dt = '2020-06-21';
-- 第二步:处理历史数据【userhis】(历史包括两部分:变化的、未变化的)
-- 变化的:start_date:不变;end_date:传入日期-1
-- 未变化的:不做处理
-- 观察数据
SELECT
A.userid,
B.userid,
B.mobile,
B.regdate,
B.start_date,
B.end_date
FROM
(SELECT *
FROM test.userinfo
WHERE dt = '2020-06-21') A
RIGHT JOIN
test.userhis B
ON
A.userid = B.userid;
-- 编写SQL,处理历史数据
SELECT
B.userid,
B.mobile,
B.regdate,
B.start_Date,
CASE
WHEN B.end_date = '9999-12-31' AND A.userid IS NOT NULL
THEN DATE_ADD('2020-06-21', INTERVAL -1 DAY)
ELSE B.end_date
END AS end_date
FROM
(SELECT * FROM test.userinfo WHERE dt = '2020-06-21') A
RIGHT JOIN
test.userhis B
ON
A.userid = B.userid;
-- 最终的处理(新增+历史数据)
INSERT OVERWRITE TABLE test.userhis
SELECT
userid,
mobile,
regdate,
dt AS start_date,
'9999-12-31' AS end_date
FROM
test.userinfo
WHERE
dt = '2020-06-21'
UNION ALL
SELECT
B.userid,
B.mobile,
B.regdate,
B.start_date,
CASE
WHEN B.end_date = '9999-12-31' AND A.userid IS NOT NULL
THEN date_add('2020-06-21', -1)
ELSE B.end_date
END AS end_date
FROM
(SELECT * FROM test.userinfo WHERE dt = '2020-06-21') A
RIGHT JOIN
test.userhis B
ON
A.userid = B.userid;执行过程如下图所示: 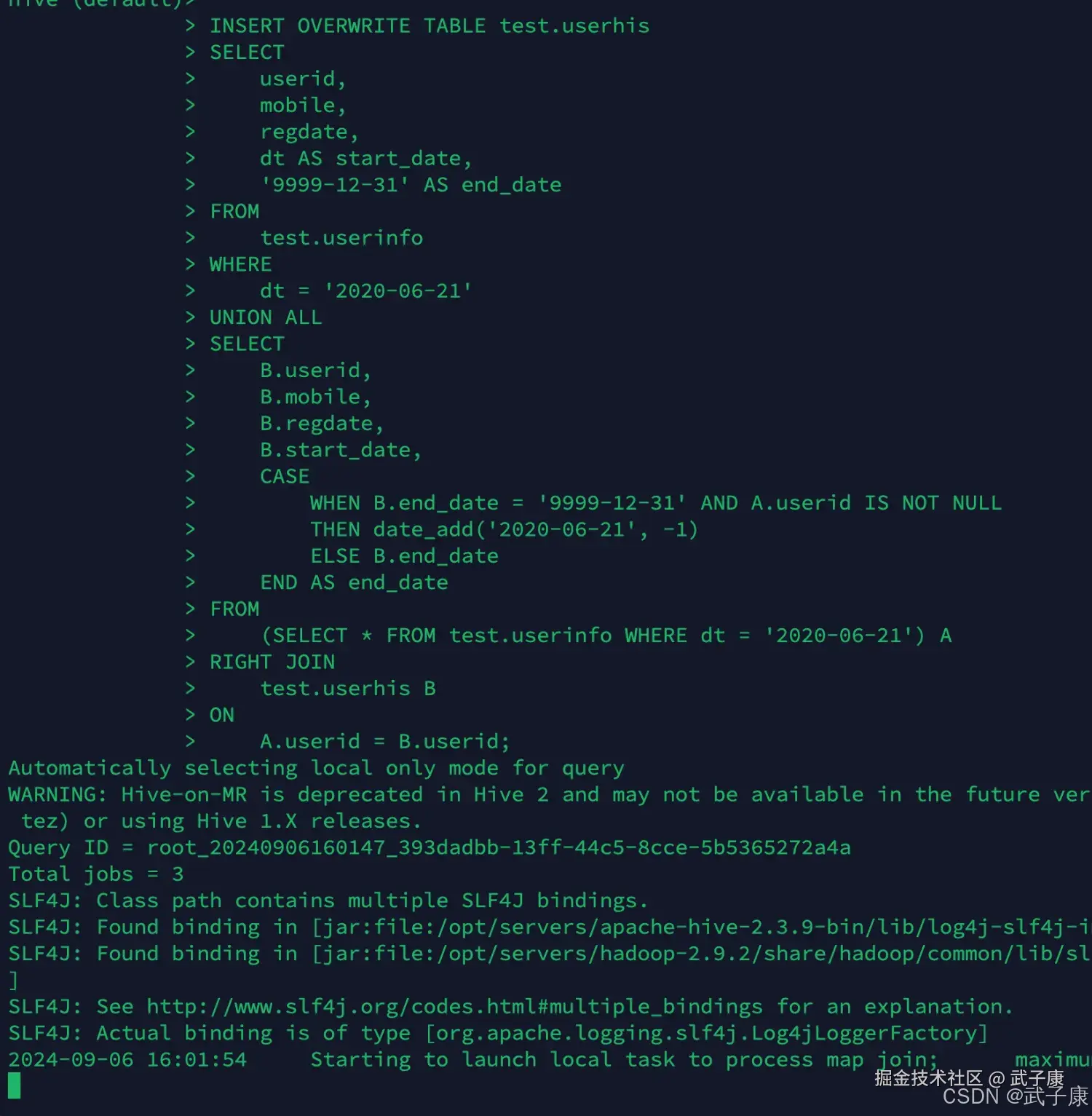
拉链表测试脚本
shell
vim test_zipper.sh写入的内容如下所示:
shell
#!/bin/bash
# 加载环境变量
source /etc/profile
# 判断是否传入日期参数,如果没有则使用前一天的日期
if [ -n "$1" ]; then
do_date=$1
else
do_date=$(date -d "-1 day" +%F)
fi
# SQL 语句
sql="
INSERT OVERWRITE TABLE test.userhis
SELECT
userid,
mobile,
regdate,
dt AS start_date,
'9999-12-31' AS end_date
FROM
test.userinfo
WHERE
dt = '$do_date'
UNION ALL
SELECT
B.userid,
B.mobile,
B.regdate,
B.start_date,
CASE
WHEN B.end_date = '9999-12-31' AND A.userid IS NOT NULL THEN date_add('$do_date', -1)
ELSE B.end_date
END AS end_date
FROM
(SELECT * FROM test.userinfo WHERE dt = '$do_date') A
RIGHT JOIN
test.userhis B
ON
A.userid = B.userid;
"
# 执行 Hive SQL
hive -e "$sql"拉链表的回滚
由于种种原因需要将拉链表恢复到rollback_date那一天的数据,此时有:
- end_date < rollback_date,即结束日期<回滚日期,表示该行数据在roll_back_date之前产生,这些数据需要原样保留
- start_date <= rollback_date <= end_date,即开始日期 <= 回滚日期 <= 结束日期,这些数据是回滚日期之后产生的,但是需要修改,将end_date改为9999-12-31
- 其他数据不用管
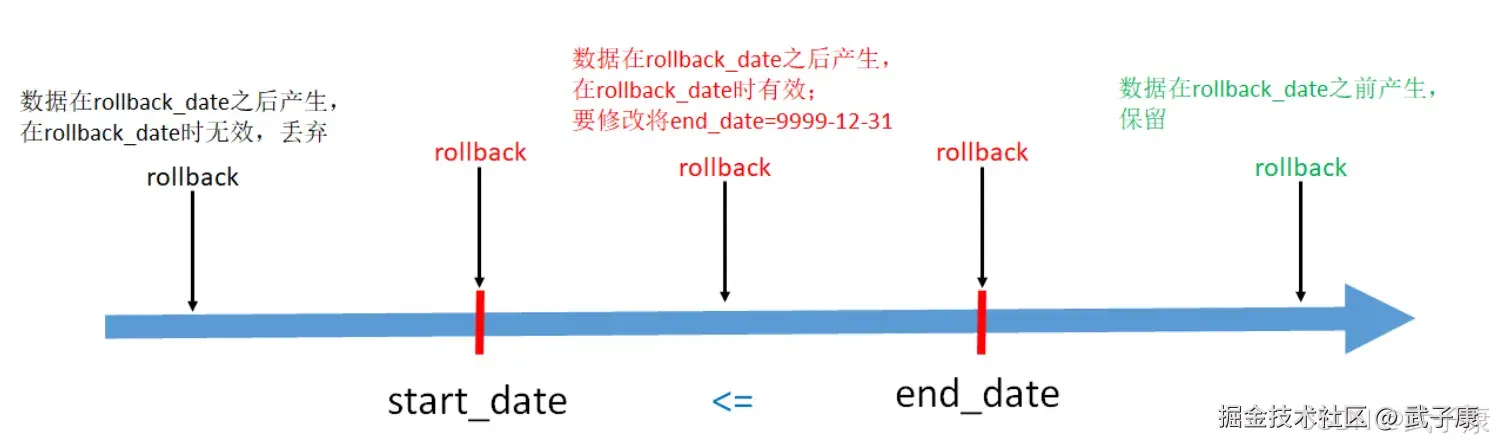 按照上述方案进行编码: 处理end_date < rollback_date 的数据
按照上述方案进行编码: 处理end_date < rollback_date 的数据
sql
SELECT
userid,
mobile,
regdate,
start_date,
end_date,
'1' AS tag
FROM
test.userhis
WHERE
end_date < '2020-06-22';处理start_date <= rollback_date <= end_date 的数据,设置 end_date=9999-12-31
sql
SELECT
userid,
mobile,
regdate,
start_date,
'9999-12-31' AS end_date,
'2' AS tag
FROM
test.userhis
WHERE
start_date <= '2020-06-22'
AND end_date >= '2020-06-22';将前面两步的数据写入临时表tmp(拉链表)
sql
-- 删除临时表
DROP TABLE IF EXISTS test.tmp;
-- 创建临时表
CREATE TABLE test.tmp AS
SELECT
userid,
mobile,
regdate,
start_date,
end_date,
'1' AS tag
FROM
test.userhis
WHERE
end_date < '2020-06-22'
UNION ALL
SELECT
userid,
mobile,
regdate,
start_date,
'9999-12-31' AS end_date,
'2' AS tag
FROM
test.userhis
WHERE
start_date <= '2020-06-22'
AND end_date >= '2020-06-22';
-- 查询结果并按照 userid 和 start_date 进行聚集
SELECT *
FROM test.tmp
CLUSTER BY userid, start_date;模拟脚本:
shell
zippertmp.sh写入的内容如下所示:
shell
#!/bin/bash
# 加载环境变量
source /etc/profile
# 判断是否传递日期参数,如果没有则使用前一天的日期
if [ -n "$1" ]; then
do_date=$1
else
do_date=$(date -d "-1 day" +%F)
fi
# 定义SQL查询语句
sql="
DROP TABLE IF EXISTS test.tmp;
CREATE TABLE test.tmp AS
SELECT userid, mobile, regdate, start_date, end_date, '1' AS tag
FROM test.userhis
WHERE end_date < '${do_date}'
UNION ALL
SELECT userid, mobile, regdate, start_date, '9999-12-31' AS end_date, '2' AS tag
FROM test.userhis
WHERE start_date <= '${do_date}'
AND end_date >= '${do_date}';
"
# 执行Hive查询
hive -e "$sql"逐天回滚,检查数据
错误速查
| 症状 | 根因 | 定位 | 修复 |
|---|---|---|---|
| 拉链表中同一 userid 出现多条 9999-12-31 | 同一天脚本重复执行,或增量数据去重不足 | 查 userid 分组后当前有效记录数 | 对当日 userinfo 先去重;执行前校验目标日是否已处理 |
| 历史版本 end_date 没有闭合 | 关联条件只按 userid,但增量分区数据缺失或脚本日期错误 | 核查 dt='$do_date' 分区是否存在,检查 A.userid IS NOT NULL 命中情况 | 补齐分区数据;增加空分区保护;执行前先做数据预检查 |
| SQL 在 Hive 报日期函数错误 | 混用了 MySQL 与 Hive 的日期函数写法 | 单独执行 date_add 相关 SQL 片段验证 | Hive 统一使用 date_add('2020-06-21', -1) 风格 |
| INSERT OVERWRITE 后表数据异常 | 目标表整体重写,但源数据范围不完整 | 比较重写前后总量、当前有效量、历史量 | 加备份表或临时表;先写临时结果校验,再覆盖正式表 |
| 回滚后结果不对 | 回滚逻辑只生成 tmp,没有完整回写闭环,或条件边界写错 | 检查 tmp 中 start_date/end_date 是否符合回滚日 | 明确最后一步:用 tmp 覆盖 userhis;校验 <=、>= 边界 |
| 新增用户历史断裂 | 初始装载和次日装载字段口径不一致 | 对比 userinfo 与 userhis 字段顺序、类型、格式 | 保持字段顺序一致,日期字段统一格式 |
| Shell 脚本执行失败 | hive 环境变量未加载,或执行用户无权限 | 手工执行 source /etc/profile && hive -e "show databases" | 固化 Hive 环境;在脚本开头打印环境与执行日期 |
| 当天无数据仍执行成功但结果错误 | 空分区参与 UNION ALL,导致只保留历史或误闭链 | 先查 select count(1) from userinfo where dt='$do_date' | 无数据直接退出;增加前置校验 |
| 查询某天快照结果不准 | 使用拉链表时查询条件写错,没有按有效区间过滤 | 检查是否按 start_date <= day and end_date >= day 查询 | 固化快照查询模板,避免直接查当前有效记录 |
| 数据量上来后任务很慢 | 全表 INSERT OVERWRITE + JOIN 成本高,且表未分区/未分桶 | 看执行计划、Shuffle、表大小 | 对拉链表按业务维度或日期优化;必要时引入中间层与分区策略 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI研究-132 Java 生态前沿 2025:Spring、Quarkus、GraalVM、CRaC 与云原生落地
💻 Java篇持续更新中(长期更新)
Java-218 RocketMQ Java API 实战:同步/异步 Producer 与 Pull/Push Consumer MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 已完结,OSS已完结,GuavaCache已完结,EVCache已完结,RabbitMQ已完结,RocketMQ正在更新... 深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解