文章目录
一、简介
本文介绍如何设计AnalyticDB for MySQL的表结构(包括选择表类型、分布键、分区键、主键和聚集索引键等),从而实现表性能的优化。
参考地址:
- https://help.aliyun.com/zh/analyticdb/analyticdb-for-mysql/use-cases/schema-design
- https://help.aliyun.com/zh/analyticdb/analyticdb-for-mysql/user-guide/data-modeling-diagnostics#section-ybp-oue-omk
二、优化方式
1、表类型
AnalyticDB for MySQL支持复制表和普通表两种类型。在选择表类型时,需要注意如下几点:
- 复制表会在集群的每个节点存储一份数据,因此建议复制表中的数据量不宜太大,每张复制表存储的数据不超过2万行。
- 普通表(即分区表)能够充分利用分布式系统的查询优势,提高查询效率。普通表可存储的数据量较大,通常可以存储千万条甚至千亿条数据。
table_attribute决定了表的类型是普通表还是复制表。
DISTRIBUTED BY HASH,定义表为普通表。普通表能够充分利用分布式系统的查询优势,提高查询效率。普通表可存储的数据量较大,通常可以存储千万条甚至千亿条数据。DISTRIBUTED BY BROADCAST,定义表为复制表。复制表会在集群的每个分片存储一份数据,因此建议每个复制表中的数据量不宜太大,最好不超过2万行。
普通表:
sql
CREATE TABLE customer (
customer_id BIGINT NOT NULL COMMENT '顾客ID',
customer_name VARCHAR NOT NULL COMMENT '顾客姓名',
PRIMARY KEY (customer_id)
)
DISTRIBUTED BY HASH(customer_id)
COMMENT '客户信息表(普通表)'; 复制表:
sql
CREATE TABLE customer (
customer_id BIGINT NOT NULL COMMENT '顾客ID',
customer_name VARCHAR NOT NULL COMMENT '顾客姓名',
PRIMARY KEY (customer_id)
)
DISTRIBUTED BY BROADCAST
COMMENT '客户信息表(复制表)'; 2、分布键
如果业务明确有增量数据导入需求,创建普通表时可以同时指定分布键和分区键,来实现数据的增量同步。您可以在创建表时,通过DISTRIBUTED BY HASH(column_name,...)指定分布键,按照column_name字段的Hash值进行分区。
注意事项:
- 尽可能选择值分布均匀的字段作为分布键,例如交易ID、设备ID、用户ID或者自增列作为分布键。
- 尽量不要选择日期、时间和时间戳类型的字段作为分布键,写入时容易发生倾斜影响写入性能,且多数查询通常是限定了日期或者时间段,如:查询最近一天或者一个月的数据,可能会导致要查询的数据只存在于一个节点上,无法充分利用分布式数据库中所有节点的处理能力。日期、时间类型的字段建议作为二级分区来考虑,具体请参见选择分区键。
- 尽可能将需要Join的字段作为分布键,可以有效减少数据Shuffle。例如,需要按照顾客维度查看历史订单信息,可以选择
customer_id作为分布键。 - 尽可能选择在查询条件中高频出现的字段作为分布键,从而实现按分布键做裁剪。
- 每张表只能选取一个分布键,一个分布键可以包含一个字段或者多个字段,尽可能选取少的字段,使得分布键在各种复杂查询中更加通用。
- 若在创建表时,未指定分布键,系统会根据MySQL表是否含有主键进行如下处理:
- 如果MySQL表含有主键,AnalyticDB for MySQL默认将主键作为分布键。
- 如果MySQL表不含有主键,AnalyticDB for MySQL将添加一个
__adb_auto_id__字段作为主键和分布键。
DISTRIBUTED BY HASH (column_name,...)
定义表的分布键。定义了分布键的表,又称分区表(普通表)。AnalyticDB for MySQL对分布键的值进行哈希计算,根据计算得出的哈希值,将不同行的数据分散到不同分片(Shard),有利于提高可扩展性和查询性能。
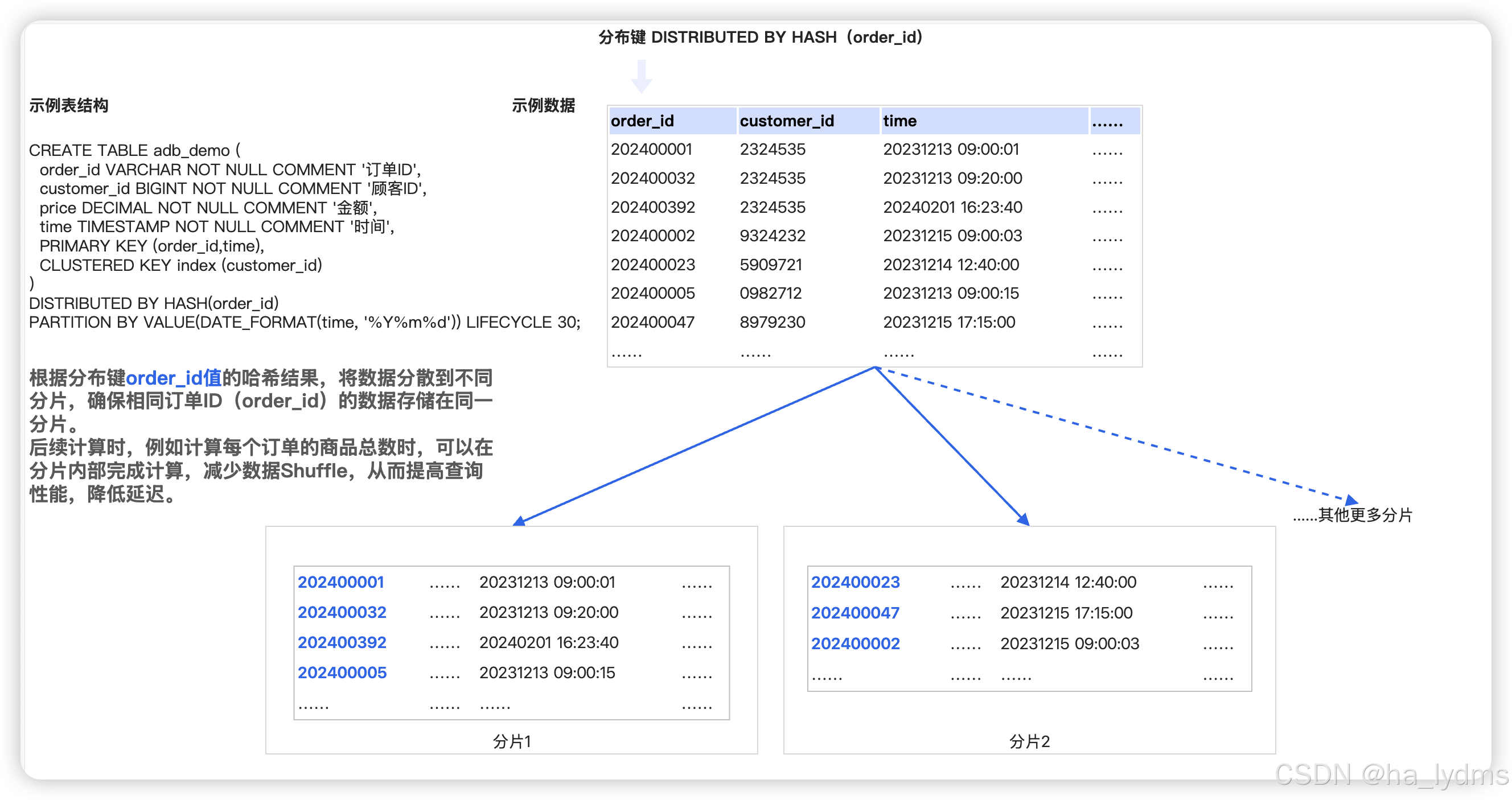
3、分区键
如果设置了分布键后,单个分片的数据量较大,您可以通过分区键在分片内进一步设置分区,以提高数据访问的性能。您可以在创建表时,通过PARTITION BY 来定义二级分区,数据会将按照指定方式进行切分。
-
使用
column_name的值做分区,语法如下:sqlPARTITION BY VALUE(column_name) -
将
column_name的值转换为%Y%m%d的日期格式(类似20210101)做分区,语法如下:sqlPARTITION BY VALUE{(DATE_FORMAT(column_name, '%Y%m%d'))|(FROM_UNIXTIME(column_name, '%Y%m%d'))} -
将
column_name的值转换为%Y%m的日期格式(类似202101)做分区,语法如下:sqlPARTITION BY VALUE{(DATE_FORMAT(column_name, '%Y%m'))|(FROM_UNIXTIME(column_name, '%Y%m'))} -
将
column_name的值转换为%Y的日期格式(类似2021)做分区,语法如下:sqlPARTITION BY VALUE{(DATE_FORMAT(column_name, '%Y'))|(FROM_UNIXTIME(column_name, '%Y'))}
注意事项:
- 当数据量较大时,二级分区的选择至关重要,如果数据量大的表中没有二级分区或者二级分区切分不合理,将严重影响AnalyticDB for MySQL集群性能。如何进行分区字段合理性诊断,请参见分布字段合理性诊断。
- 目前切分粒度只支持年、月、日或原始值。切分粒度太大或太小都会影响查询性能和写入性能,甚至影响AnalyticDB for MySQL集群的稳定性。
- 尽量使二级分区维持静态状态,不建议频繁更新二级分区,例如,如果有每天频繁更新多个历史二级分区场景,应考虑使用的二级分区字段是否合理。
- 您可以通过
LIFECYCLE N关键字实现表生命周期管理,即对分区进行排序,超出N的分区会被过滤。
4、选择主键
- 主键可以作为每一条记录的唯一标识。您可以在创建表时,通过
PRIMARY KEY来定义主键。
sql
PRIMARY KEY (column_name,...)- 只有定义过主键的表支持数据更新操作(包括DELETE和UPDATE)。
- AnalyticDB for MySQL的主键可以是单个字段或多个字段的组合。推荐使用数值类型字段作为主键,并尽量减少字段个数,以获得较好的表性能。
- 主键中必须包含分布键和分区键,建议将分布键和分区键放在组合主键的前部。
5、选择聚集索引键
聚集索引中键值的逻辑顺序决定了表中相应行的物理顺序。选择聚集索引键时需要注意如下几点:
- 每个表仅支持创建一个聚集索引。创建方式,请参见CREATE TABLE。
- 建议将查询一定会携带的字段作为聚集索引键。例如,每个学生在学校教务系统中,只需查看自己的期末成绩,那么可以将学生的学号ID定义为聚集索引,来保证数据的局部性,提升数据查询性能。
- 聚集索引会进行全表排序,需要消耗资源(例如:CPU资源),建议您合理使用聚集索引。
CLUSTERED KEY
定义聚集索引。聚集索引是分区级别的,它决定了数据的物理存储顺序,即分区内的数据会按聚集索引的键值进行排序,按顺序存储,默认升序。聚集索引的键值相同或相近的数据存储在相同或相近数据块。在范围查询或等值查询中,如果查询条件与聚集索引列一致,存储引擎可快速读取连续的数据块,这样可以减少磁盘的I/O,加快数据读取的速度。
- 示意图

为quantity列创建聚集索引,索引名称为clustered_index。
sql
CREATE TABLE clustered (
product_id INT,
product_name VARCHAR,
quantity INT,
price DECIMAL(10, 2),
CLUSTERED KEY INDEX clustered_index(quantity)
)
DISTRIBUTED BY HASH(product_id);